hive-diea-ETL数据截取split,嵌套SQL查询,ETL-SQL表查询中间件解析
1.数据准备
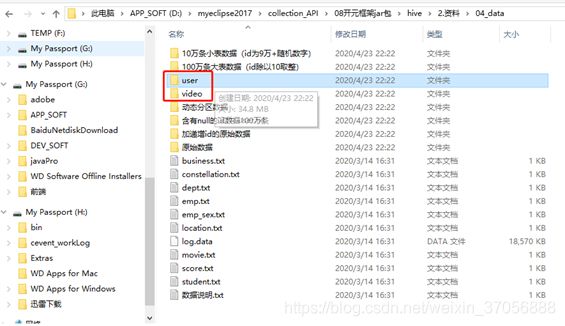
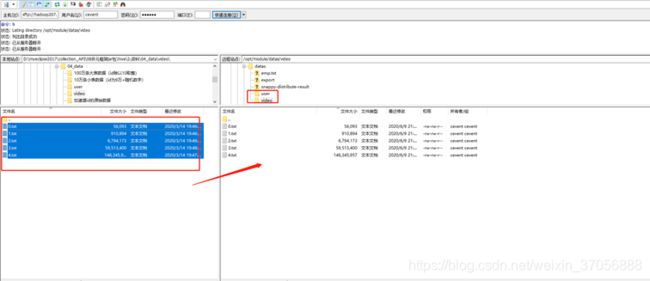
2.上传数据
[cevent@hadoop207 hadoop-2.7.2]$ cd /opt/module/datas/
[cevent@hadoop207 datas]$ ll
总用量
383028
-rw-rw-r--. 1 cevent cevent 147 5月
10 13:46 510test.txt
-rw-rw-r--. 1 cevent cevent 120734753 6月 8 13:31 bigtable
-rw-rw-r--. 1 cevent cevent 266 5月
17 13:52 business.txt
-rw-rw-r--. 1 cevent cevent 129 5月
17 13:52 constellation.txt
-rw-rw-r--. 1 cevent cevent 71 5月
17 13:52 dept.txt
-rw-rw-r--. 1 cevent cevent 78 5月
17 13:52 emp_sex.txt
drwxrwxr-x. 3 cevent cevent 4096 6月
5 14:17 emp.txt
drwxrwxr-x. 4 cevent cevent 4096 5月
22 13:32 export
-rw-rw-r--. 1 cevent cevent 2794 6月
4 22:32 hadoop_hive_userdefinedfunc_plugin-1.0-SNAPSHOT.jar
-rw-rw-r--. 1 cevent cevent 37 5月
17 13:52 location.txt
-rw-rw-r--. 1 cevent cevent 19014993 5月
17 13:52 log.data
-rw-rw-r--. 1 cevent cevent 136 5月
17 13:52 movie.txt
-rw-rw-r--. 1 cevent cevent 118645854 6月 9 13:20 nullid
-rw-rw-r--. 1 cevent cevent 121734744 6月 9 13:16 ori
-rw-rw-r--. 1 cevent cevent 213 5月
17 13:52 score.txt
-rw-rw-r--. 1 cevent cevent 12018355 6月
8 13:31 smalltable
drwxrwxr-x. 3 cevent cevent 4096 6月
5 14:18 snappy-distribute-result
-rw-rw-r--. 1 cevent cevent 165 5月
17 13:52 student.txt
-rw-rw-r--. 1 cevent cevent 301 5月
17 13:52 数据说明.txt
[cevent@hadoop207 datas]$ mkdir user/
[cevent@hadoop207 datas]$ mkdir video/
[cevent@hadoop207 datas]$ ll
总用量
383036
-rw-rw-r--. 1 cevent cevent 147 5月
10 13:46 510test.txt
-rw-rw-r--. 1 cevent cevent 120734753 6月 8 13:31 bigtable
-rw-rw-r--. 1 cevent cevent 266 5月
17 13:52 business.txt
-rw-rw-r--. 1 cevent cevent 129 5月
17 13:52 constellation.txt
-rw-rw-r--. 1 cevent cevent 71 5月
17 13:52 dept.txt
-rw-rw-r--. 1 cevent cevent 78 5月
17 13:52 emp_sex.txt
drwxrwxr-x. 3 cevent cevent 4096 6月
5 14:17 emp.txt
drwxrwxr-x. 4 cevent cevent 4096 5月
22 13:32 export
-rw-rw-r--. 1 cevent cevent 2794 6月
4 22:32 hadoop_hive_userdefinedfunc_plugin-1.0-SNAPSHOT.jar
-rw-rw-r--. 1 cevent cevent 37 5月
17 13:52 location.txt
-rw-rw-r--. 1 cevent cevent 19014993 5月
17 13:52 log.data
-rw-rw-r--. 1 cevent cevent 136 5月
17 13:52 movie.txt
-rw-rw-r--. 1 cevent cevent 118645854 6月 9 13:20 nullid
-rw-rw-r--. 1 cevent cevent 121734744 6月 9 13:16 ori
-rw-rw-r--. 1 cevent cevent 213 5月
17 13:52 score.txt
-rw-rw-r--. 1 cevent cevent 12018355 6月
8 13:31 smalltable
drwxrwxr-x. 3 cevent cevent 4096 6月
5 14:18 snappy-distribute-result
-rw-rw-r--. 1 cevent cevent 165 5月
17 13:52 student.txt
drwxrwxr-x. 2 cevent cevent 4096 6月
9 21:23 user
drwxrwxr-x. 2 cevent cevent 4096 6月
9 21:23 video
-rw-rw-r--. 1 cevent cevent 301 5月
17 13:52 数据说明.txt
[cevent@hadoop207 datas]$ hadoop fs -mkdir /cevent_video_show
[cevent@hadoop207 datas]$ hadoop fs -put user/ /cevent_video_show
[cevent@hadoop207 datas]$ hadoop fs -put video/ /cevent_video_show
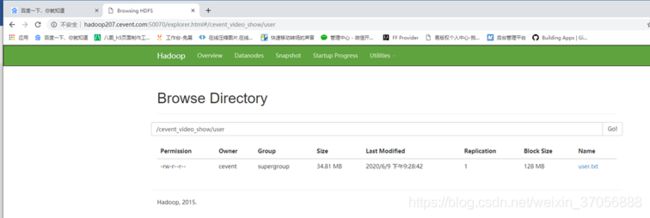
3.查询结果
链接: http://hadoop207.cevent.com:50070/explorer.html#/cevent_video_show/user
4.新建idea工程
5.Log4j解析
//日志输出级别,INFO为级别,输出都会记录到stdout
log4j.rootLogger=INFO, stdout
//appender:控制台追加器consoleAppender 模板布局patternLayout 转换模式conversionPattern
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d
%p [%c] - %m%n
//logfile:文件追加器
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d
%p [%c] - %m%n
6.resources下新建log4j.properties
log4j.rootLogger=INFO,
stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] -
%m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] -
%m%n
7.ETLMapper
package com.cevent.hadoop.hive.etl;
/**
* Created by Cevent on 2020/6/9.
*/
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Counter;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* @author cevent
* @description
* 输入类型 输出类型
* Mapper
* @date 2020/6/9 22:27
*/
public class ETLMapper extends Mapper<LongWritable,Text,Text,NullWritable>{
//单线程累加拼接
private StringBuilder stringBuilder=new StringBuilder();
private Text text=new Text();
//计数器,记录日志数据
private Counter totalData;
private Counter passData;
@Override
protected void setup(Context context) throws IOException, InterruptedException{
//s:groupName
s1:counterName
totalData=context.getCounter("ETL","TotalData");
passData=context.getCounter("ETL","PassData");
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException
{
//1.数据切割
String[] split=value.toString().split("\t");
//获取数据载入total
totalData.increment(1);
//2.按照长度过滤,不符合条件的数组,<9的忽略
if(split.length>=9){
//去除类型的空格:People & Blogs
split[3]=split[3].replace(" ","");
//3.替换分隔符
//拼接前,清除StringBuilder
stringBuilder.setLength(0);
//LKh7zAJ4nwo TheReceptionist 653
Entertainment 424 13021
4.34 1305 744
DjdA-5oKYFQ NxTDlnOuybo c-8VuICzXtU DH56yrIO5nI W1Uo5DQTtzc E-3zXq_r4w0 1TCeoRPg5dE yAr26YhuYNY 2ZgXx72XmoE -7ClGo-YgZ0 vmdPOOd6cxI KRHfMQqSHpk pIMpORZthYw 1tUDzOp10pk heqocRij5P0 _XIuvoH6rUg LGVU5DsezE0 uO2kj6_D8B4 xiDqywcDQRM uX81lMev6_o
// 1 2 3 4 5
6 7 8
9 10 11 12 13 14 15
//字段在末尾,则不拼分隔符,如果字段在末尾前一串,则加入分隔符(前9个<9 | 第10个以后)
for (int i=0;i<split.length;i++){
//4.末尾字段,只拼字段
if(i==split.length-1){
stringBuilder.append(split[i]);
}else if(i<9){
//如果为前9个,需要拼分隔符\t
stringBuilder.append(split[i]).append('\t');
}else{
//如果为后10个,拼&
stringBuilder.append(split[i]).append('&');
}
}
//5.写入
text.set(stringBuilder.toString());
//6.total/pass+1
passData.increment(1);
context.write(text,NullWritable.get());
}
}
}
8.ETLDriver
package com.cevent.hadoop.hive.etl;/**
* Created by Cevent on 2020/6/9.
*/
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* @author cevent
* @description
* @date 2020/6/9 22:26
*/
public class ETLDriver {
public static void
main(String[] args) throws Exception {
Job job= Job.getInstance(new Configuration());
job.setJarByClass(ETLDriver.class);
job.setMapperClass(ETLMapper.class);
job.setNumReduceTasks(0);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
boolean flag=job.waitForCompletion(true);
System.exit(flag?0:1);
}
}
9.打包
10.执行jar-ETL
[cevent@hadoop207 hadoop-2.7.2]$ sbin/start-dfs.sh
Starting namenodes on
[hadoop207.cevent.com]
hadoop207.cevent.com: starting namenode,
logging to /opt/module/hadoop-2.7.2/logs/hadoop-cevent-namenode-hadoop207.cevent.com.out
hadoop207.cevent.com: starting datanode,
logging to
/opt/module/hadoop-2.7.2/logs/hadoop-cevent-datanode-hadoop207.cevent.com.out
Starting secondary namenodes
[hadoop207.cevent.com]
hadoop207.cevent.com: starting
secondarynamenode, logging to
/opt/module/hadoop-2.7.2/logs/hadoop-cevent-secondarynamenode-hadoop207.cevent.com.out
[cevent@hadoop207 hadoop-2.7.2]$ sbin/start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to
/opt/module/hadoop-2.7.2/logs/yarn-cevent-resourcemanager-hadoop207.cevent.com.out
hadoop207.cevent.com: starting
nodemanager, logging to
/opt/module/hadoop-2.7.2/logs/yarn-cevent-nodemanager-hadoop207.cevent.com.out
[cevent@hadoop207 hadoop-2.7.2]$ jps
4494 Jps
4163 SecondaryNameNode
4450 NodeManager
3845 NameNode
3958 DataNode
4336 ResourceManager
[cevent@hadoop207 hadoop-2.7.2]$ cd /opt/module/datas/
[cevent@hadoop207 datas]$ ll
总用量
383044
-rw-rw-r--. 1 cevent cevent 147 5月
10 13:46 510test.txt
-rw-rw-r--. 1 cevent cevent 120734753 6月 8 13:31 bigtable
-rw-rw-r--. 1 cevent cevent 266 5月
17 13:52 business.txt
-rw-rw-r--. 1 cevent cevent 129 5月
17 13:52 constellation.txt
-rw-rw-r--. 1 cevent cevent 71 5月
17 13:52 dept.txt
-rw-rw-r--. 1 cevent cevent 78 5月
17 13:52 emp_sex.txt
drwxrwxr-x. 3 cevent cevent 4096 6月
5 14:17 emp.txt
drwxrwxr-x. 4 cevent cevent 4096 5月
22 13:32 export
-rw-rw-r--. 1 cevent cevent 2794 6月
4 22:32 hadoop_hive_userdefinedfunc_plugin-1.0-SNAPSHOT.jar
-rw-rw-r--. 1 cevent cevent 37 5月
17 13:52 location.txt
-rw-rw-r--. 1 cevent cevent 19014993 5月
17 13:52 log.data
-rw-rw-r--. 1 cevent cevent 136 5月
17 13:52 movie.txt
-rw-rw-r--. 1 cevent cevent 118645854 6月 9 13:20 nullid
-rw-rw-r--. 1 cevent cevent 121734744 6月 9 13:16 ori
-rw-rw-r--. 1 cevent cevent 213 5月
17 13:52 score.txt
-rw-rw-r--. 1 cevent cevent 12018355 6月
8 13:31 smalltable
drwxrwxr-x. 3 cevent cevent 4096 6月
5 14:18 snappy-distribute-result
-rw-rw-r--. 1 cevent cevent 165 5月
17 13:52 student.txt
drwxrwxr-x. 2 cevent cevent 4096 6月
9 21:27 user
drwxrwxr-x. 2 cevent cevent 4096 6月
9 21:27 video
-rw-rw-r--. 1 cevent cevent 4874 6月
10 13:51 video_etl200609-1.0-SNAPSHOT.jar
-rw-rw-r--. 1 cevent cevent 301 5月
17 13:52 数据说明.txt
[cevent@hadoop207 datas]$ mv video_etl200609-1.0-SNAPSHOT.jar video_etl200609-1.0.jar
[cevent@hadoop207 datas]$ 执行jar
hadoop jar
video_etl200609-1.0.jar com.cevent.hadoop.hive.etl.ETLDriver
/cevent_video_show/video
/cevent_video_show/video_etl
20/06/10 13:56:07 INFO client.RMProxy:
Connecting to ResourceManager at hadoop207.cevent.com/192.168.1.207:8032
20/06/10 13:56:07 WARN
mapreduce.JobResourceUploader: Hadoop command-line option parsing not
performed. Implement the Tool interface and execute your application with
ToolRunner to remedy this.
20/06/10 13:56:09 INFO
input.FileInputFormat: Total input paths to process : 5
20/06/10 13:56:09 INFO
mapreduce.JobSubmitter: number of splits:5
20/06/10 13:56:09 INFO
mapreduce.JobSubmitter: Submitting tokens for job: job_1591768379763_0001
20/06/10 13:56:10 INFO
impl.YarnClientImpl: Submitted application application_1591768379763_0001
20/06/10 13:56:10 INFO mapreduce.Job:
The url to track the job:
http://hadoop207.cevent.com:8088/proxy/application_1591768379763_0001/
20/06/10 13:56:10 INFO mapreduce.Job:
Running job: job_1591768379763_0001
20/06/10 13:56:26 INFO mapreduce.Job: Job
job_1591768379763_0001 running in uber mode : false
20/06/10 13:56:26 INFO
mapreduce.Job: map 0% reduce 0%
20/06/10 13:56:58 INFO
mapreduce.Job: map 54% reduce 0%
20/06/10 13:57:01 INFO
mapreduce.Job: map 63% reduce 0%
20/06/10 13:57:05 INFO mapreduce.Job: map 66% reduce 0%
20/06/10 13:57:09 INFO
mapreduce.Job: map 75% reduce 0%
20/06/10 13:57:13 INFO
mapreduce.Job: map 90% reduce 0%
20/06/10 13:57:15 INFO
mapreduce.Job: map 97% reduce 0%
20/06/10 13:57:18 INFO
mapreduce.Job: map 100% reduce 0%
20/06/10 13:57:23 INFO mapreduce.Job:
Job job_1591768379763_0001 completed successfully
20/06/10 13:57:26 INFO mapreduce.Job:
Counters: 32
File System Counters
FILE: Number of bytes read=0
FILE: Number of bytes
written=584515
FILE: Number of read
operations=0
FILE: Number of large read
operations=0
FILE: Number of write
operations=0
HDFS: Number of bytes
read=213621152
HDFS: Number of bytes
written=212238254
HDFS: Number of read
operations=25
HDFS: Number of large read
operations=0
HDFS: Number of write
operations=10
Job Counters
Launched map tasks=5
Data-local map tasks=5
Total time spent by all maps
in occupied slots (ms)=255598
Total time spent by all
reduces in occupied slots (ms)=0
Total time spent by all map
tasks (ms)=255598
Total vcore-milliseconds
taken by all map tasks=255598
Total megabyte-milliseconds
taken by all map tasks=261732352
Map-Reduce Framework
Map input records=749361
Map output records=743569
Input split bytes=635
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=5302
CPU time spent (ms)=21270
Physical memory (bytes)
snapshot=661708800
Virtual memory (bytes)
snapshot=4414775296
Total committed heap usage
(bytes)=310902784
ETL
PassData=743569 转换数量6000+
TotalData=749361
File Input Format Counters
Bytes Read=213620517
File Output Format Counters
Bytes Written=212238254
11.校验结果
链接:http://hadoop207.cevent.com:50070/explorer.html#/cevent_video_show/video_etl
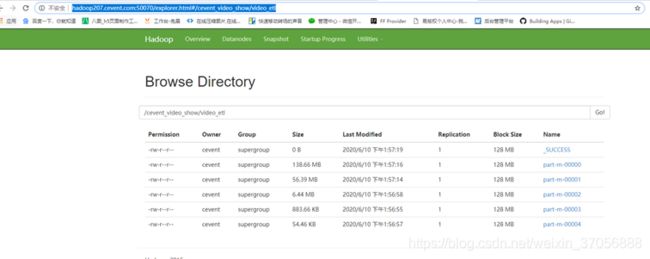

12.统计查询,多嵌套
[cevent@hadoop207 hive-1.2.1]$ bin/beeline
Beeline version 1.2.1 by Apache Hive
0: jdbc:hive2://hadoop.cevent.com:10000
(closed)> !connect
jdbc:hive2://hadoop207.cevent.com:10000
Connecting to
jdbc:hive2://hadoop207.cevent.com:10000
Enter username for
jdbc:hive2://hadoop207.cevent.com:10000: cevent
Enter password for
jdbc:hive2://hadoop207.cevent.com:10000: ******
Connected to: Apache Hive (version 1.2.1)
Driver: Hive JDBC (version 1.2.1)
Transaction isolation:
TRANSACTION_REPEATABLE_READ
1:
jdbc:hive2://hadoop207.cevent.com:10000> use
cevent01;
No rows affected (1.423 seconds)
1:
jdbc:hive2://hadoop207.cevent.com:10000> show
tables;
+------------------------+--+
| tab_name |
+------------------------+--+
| big_join |
| c_dept |
| c_emp |
| emp_gender |
| join_dep_partition |
| join_original |
| join_original_null_id |
| join_original_table |
| join_table |
| locations |
| person_info |
| small_join |
| student |
| student_bucket |
+------------------------+--+
14 rows selected (0.621 seconds) 创建外部表
载入数据
1:
jdbc:hive2://hadoop207.cevent.com:10000> create
external table video_user_info(
1:
jdbc:hive2://hadoop207.cevent.com:10000> uploader
string,
1: jdbc:hive2://hadoop207.cevent.com:10000>
videos int,
1:
jdbc:hive2://hadoop207.cevent.com:10000> friends
int
1:
jdbc:hive2://hadoop207.cevent.com:10000> )
1:
jdbc:hive2://hadoop207.cevent.com:10000> row
format delimited fields terminated by '\t'
1:
jdbc:hive2://hadoop207.cevent.com:10000> location
'/cevent_video_show/user';
No rows affected (0.141 seconds)
1:
jdbc:hive2://hadoop207.cevent.com:10000> select *
from video_user_info limit 5;
+---------------------------+-------------------------+--------------------------+--+
| video_user_info.uploader |
video_user_info.videos |
video_user_info.friends |
+---------------------------+-------------------------+--------------------------+--+
| barelypolitical |
151 | 5106 |
| bonk65 |
89 | 144 |
| camelcars |
26 | 674 |
| cubskickass34 |
13 | 126 |
| boydism08 |
32 | 50 |
+---------------------------+-------------------------+--------------------------+--+
5 rows selected (0.389 seconds) 创建外部video表载入数据
1:
jdbc:hive2://hadoop207.cevent.com:10000> create
external table video_info(
1:
jdbc:hive2://hadoop207.cevent.com:10000> video_id
string,
1:
jdbc:hive2://hadoop207.cevent.com:10000> uploader
string,
1: jdbc:hive2://hadoop207.cevent.com:10000>
age int,
1:
jdbc:hive2://hadoop207.cevent.com:10000> category
array,
1:
jdbc:hive2://hadoop207.cevent.com:10000> length
int,
1:
jdbc:hive2://hadoop207.cevent.com:10000> views
int,
1:
jdbc:hive2://hadoop207.cevent.com:10000> rate
float,
1:
jdbc:hive2://hadoop207.cevent.com:10000> ratings
int,
1:
jdbc:hive2://hadoop207.cevent.com:10000> comments
int,
1:
jdbc:hive2://hadoop207.cevent.com:10000> related_id
array
1: jdbc:hive2://hadoop207.cevent.com:10000>
)
1:
jdbc:hive2://hadoop207.cevent.com:10000> row
format delimited fields terminated by '\t'
1:
jdbc:hive2://hadoop207.cevent.com:10000> collection
items terminated by '&'
1:
jdbc:hive2://hadoop207.cevent.com:10000> location
'/cevent_video_show/video';
No rows affected (0.22 seconds)
1:
jdbc:hive2://hadoop207.cevent.com:10000> select *
from video_info limit 5;
+----------------------+----------------------+-----------------+----------------------+--------------------+-------------------+--------------------+---------------------+----------------------+------------------------+--+
| video_info.video_id |
video_info.uploader |
video_info.age |
video_info.category | video_info.length | video_info.views |
video_info.rate | video_info.ratings | video_info.comments | video_info.related_id |
+----------------------+----------------------+-----------------+----------------------+--------------------+-------------------+--------------------+---------------------+----------------------+------------------------+--+
| LKh7zAJ4nwo |
TheReceptionist | 653 |
["Entertainment"] | 424 | 13021 | 4.340000152587891 | 1305 | 744 |
["DjdA-5oKYFQ"] |
| 7D0Mf4Kn4Xk |
periurban | 583 | ["Music"] | 201 | 6508 | 4.190000057220459 | 687 | 312 |
["e2k0h6tPvGc"] |
| n1cEq1C8oqQ |
Pipistrello | 525 | ["Comedy"] | 125 | 1687 | 4.010000228881836 | 363 | 141 | ["eprHhmurMHg"] |
| OHkEzL4Unck |
ichannel | 638 | ["Comedy"] | 299 | 8043 | 4.400000095367432 | 518 | 371 |
["eyUSTmEUQRg"] |
| -boOvAGNKUc |
mrpitifulband | 639 | ["Music"] | 287 | 7548 | 4.480000019073486 | 606 | 386 |
["fmUwUURgsX0"] |
+----------------------+----------------------+-----------------+----------------------+--------------------+-------------------+--------------------+---------------------+----------------------+------------------------+--+
5 rows selected (0.202 seconds) 创建内部表(在hdfs上显示),记入数据局
1:
jdbc:hive2://hadoop207.cevent.com:10000> create
table video_user stored as orc as select * from video_user_info;
INFO : Number of reduce tasks
is set to 0 since there's no reduce operator
INFO : number of splits:1
INFO : Submitting tokens for
job: job_1591768379763_0002
INFO : The url to track the
job: http://hadoop207.cevent.com:8088/proxy/application_1591768379763_0002/
INFO : Starting Job =
job_1591768379763_0002, Tracking URL =
http://hadoop207.cevent.com:8088/proxy/application_1591768379763_0002/
INFO : Kill Command =
/opt/module/hadoop-2.7.2/bin/hadoop job
-kill job_1591768379763_0002
INFO : Hadoop job information
for Stage-1: number of mappers: 1; number of reducers: 0
INFO : 2020-06-10 16:47:42,449
Stage-1 map = 0%, reduce = 0%
INFO : 2020-06-10 16:48:01,857
Stage-1 map = 100%, reduce = 0%,
Cumulative CPU 6.59 sec
INFO : MapReduce Total cumulative
CPU time: 6 seconds 590 msec
INFO : Ended Job =
job_1591768379763_0002
INFO : Stage-4 is selected by
condition resolver.
INFO : Stage-3 is filtered out
by condition resolver.
INFO : Stage-5 is filtered out
by condition resolver.
INFO : Moving data to:
hdfs://hadoop207.cevent.com:8020/user/hive/warehouse/cevent01.db/.hive-staging_hive_2020-06-10_16-47-23_881_9118723475356633122-1/-ext-10001
from
hdfs://hadoop207.cevent.com:8020/user/hive/warehouse/cevent01.db/.hive-staging_hive_2020-06-10_16-47-23_881_9118723475356633122-1/-ext-10003
INFO : Moving data to:
hdfs://hadoop207.cevent.com:8020/user/hive/warehouse/cevent01.db/video_user
from
hdfs://hadoop207.cevent.com:8020/user/hive/warehouse/cevent01.db/.hive-staging_hive_2020-06-10_16-47-23_881_9118723475356633122-1/-ext-10001
INFO : Table
cevent01.video_user stats: [numFiles=1, numRows=2139109, totalSize=18167783,
rawDataSize=218189118]
No rows affected (41.039 seconds) 创建内部表载入数据
1:
jdbc:hive2://hadoop207.cevent.com:10000> create
table video_store stored as orc as select * from video_info;
INFO : Number of reduce tasks
is set to 0 since there's no reduce operator
INFO : number of splits:1
INFO : Submitting tokens for
job: job_1591768379763_0003
INFO : The url to track the
job: http://hadoop207.cevent.com:8088/proxy/application_1591768379763_0003/
INFO : Starting Job =
job_1591768379763_0003, Tracking URL =
http://hadoop207.cevent.com:8088/proxy/application_1591768379763_0003/
INFO : Kill Command =
/opt/module/hadoop-2.7.2/bin/hadoop job
-kill job_1591768379763_0003
INFO : Hadoop job information
for Stage-1: number of mappers: 1; number of reducers: 0
INFO : 2020-06-10 16:49:01,082
Stage-1 map = 0%, reduce = 0%
INFO : 2020-06-10 16:49:13,566
Stage-1 map = 31%, reduce = 0%,
Cumulative CPU 6.74 sec
INFO : 2020-06-10 16:49:18,810
Stage-1 map = 100%, reduce = 0%,
Cumulative CPU 10.78 sec
INFO : MapReduce Total
cumulative CPU time: 10 seconds 780 msec
INFO : Ended Job =
job_1591768379763_0003
INFO : Stage-4 is selected by
condition resolver.
INFO : Stage-3 is filtered out
by condition resolver.
INFO : Stage-5 is filtered out
by condition resolver.
INFO : Moving data to: hdfs://hadoop207.cevent.com:8020/user/hive/warehouse/cevent01.db/.hive-staging_hive_2020-06-10_16-48-50_581_7964744140492116393-1/-ext-10001
from
hdfs://hadoop207.cevent.com:8020/user/hive/warehouse/cevent01.db/.hive-staging_hive_2020-06-10_16-48-50_581_7964744140492116393-1/-ext-10003
INFO : Moving data to:
hdfs://hadoop207.cevent.com:8020/user/hive/warehouse/cevent01.db/video_store
from
hdfs://hadoop207.cevent.com:8020/user/hive/warehouse/cevent01.db/.hive-staging_hive_2020-06-10_16-48-50_581_7964744140492116393-1/-ext-10001
INFO : Table
cevent01.video_store stats: [numFiles=1, numRows=749361, totalSize=22098531,
rawDataSize=321015240]
No rows affected (34.551 seconds) 执行查询观看数TOP10
1:
jdbc:hive2://hadoop207.cevent.com:10000> select
* from video_info order by views desc limit 10;
INFO : Number of reduce tasks
determined at compile time: 1
INFO : In order to change the
average load for a reducer (in bytes):
INFO : set
hive.exec.reducers.bytes.per.reducer=
INFO : In order to limit the
maximum number of reducers:
INFO : set hive.exec.reducers.max=
INFO : In order to set a
constant number of reducers:
INFO : set mapreduce.job.reduces=
INFO : number of splits:1
INFO : Submitting tokens for
job: job_1591768379763_0004
INFO : The url to track the
job: http://hadoop207.cevent.com:8088/proxy/application_1591768379763_0004/
INFO : Starting Job =
job_1591768379763_0004, Tracking URL =
http://hadoop207.cevent.com:8088/proxy/application_1591768379763_0004/
INFO : Kill Command =
/opt/module/hadoop-2.7.2/bin/hadoop job
-kill job_1591768379763_0004
INFO : Hadoop job information
for Stage-1: number of mappers: 1; number of reducers: 1
INFO : 2020-06-10 17:13:56,985
Stage-1 map = 0%, reduce = 0%
INFO : 2020-06-10 17:14:14,708
Stage-1 map = 21%, reduce = 0%,
Cumulative CPU 5.43 sec
INFO : 2020-06-10 17:14:17,853
Stage-1 map = 67%, reduce = 0%,
Cumulative CPU 7.68 sec
INFO : 2020-06-10 17:14:20,757
Stage-1 map = 100%, reduce = 0%,
Cumulative CPU 9.3 sec
INFO : 2020-06-10 17:14:38,675
Stage-1 map = 100%, reduce = 100%,
Cumulative CPU 12.55 sec
INFO : MapReduce Total
cumulative CPU time: 12 seconds 550 msec
INFO : Ended Job =
job_1591768379763_0004
+----------------------+----------------------+-----------------+-----------------------+--------------------+-------------------+---------------------+---------------------+----------------------+------------------------+--+
| video_info.video_id | video_info.uploader | video_info.age |
video_info.category |
video_info.length |
video_info.views | video_info.rate | video_info.ratings | video_info.comments | video_info.related_id |
+----------------------+----------------------+-----------------+-----------------------+--------------------+-------------------+---------------------+---------------------+----------------------+------------------------+--+
| dMH0bHeiRNg |
judsonlaipply | 415 | ["Comedy"] | 360 | 42513417 | 4.679999828338623 | 87520 | 22718 |
["OxBtqwlTMJQ"] |
| 0XxI-hvPRRA |
smosh | 286 | ["Comedy"] | 194 | 20282464 | 4.489999771118164 | 80710 | 35408 | ["ut5fFyTkKv4"] |
| 1dmVU08zVpA |
NBC | 670 |
["Entertainment"] | 165 | 16087899 | 4.789999961853027 | 30085 | 5945 |
["x0dzQeq6o5Q"] |
| RB-wUgnyGv0 |
ChrisInScotland | 506 |
["Entertainment"] | 159 | 15712924 | 4.78000020980835 | 8222 | 1996 | ["RB-wUgnyGv0"] |
| QjA5faZF1A8 |
guitar90 | 308 | ["Music"] | 320 | 15256922 | 4.840000152587891 | 120506 | 38393 |
["O9mEKMz2Pvo"] |
| -_CSo1gOd48 |
tasha | 190 | ["People ","
Blogs"] | 205 | 13199833 | 3.7100000381469727 | 38045 | 9904 |
["GkVBObv8TQk"] |
| 49IDp76kjPw | TexMachina | 381 | ["Comedy"] | 59 | 11970018 | 4.550000190734863 | 22579 | 5280 | ["brh6KRvQHBc"] |
| tYnn51C3X_w |
CowSayingMoo | 516 | ["Music"] | 231 | 11823701 | 4.670000076293945 | 29479 | 10367 |
["zvzPK1_UkRs"] |
| pv5zWaTEVkI |
OkGo | 531 | ["Music"] | 184 | 11672017 | 4.829999923706055 | 42386 | 10082 |
["W4WdLT6_Hz0"] |
| D2kJZOfq7zk |
mrWoot | 199 | ["People ","
Blogs"] | 185 | 11184051 | 4.820000171661377 | 42162 | 10819 |
["wQ7h-UUT2Rs"] |
+----------------------+----------------------+-----------------+-----------------------+--------------------+-------------------+---------------------+---------------------+----------------------+------------------------+--+
10 rows selected (58.238 seconds) 查询视频分类热度(播放量)TOP10
1:
jdbc:hive2://hadoop207.cevent.com:10000> select
categories,sum(views) hot_view
1:
jdbc:hive2://hadoop207.cevent.com:10000> from
1: jdbc:hive2://hadoop207.cevent.com:10000> (
1:
jdbc:hive2://hadoop207.cevent.com:10000> select
video_id,views,categories
1:
jdbc:hive2://hadoop207.cevent.com:10000> from
video_info
1:
jdbc:hive2://hadoop207.cevent.com:10000> lateral
view explode(category) vtb1 as categories
1:
jdbc:hive2://hadoop207.cevent.com:10000> )vtb2
1:
jdbc:hive2://hadoop207.cevent.com:10000> group by
categories
1:
jdbc:hive2://hadoop207.cevent.com:10000> order by
hot_view desc
1:
jdbc:hive2://hadoop207.cevent.com:10000> limit 10;
INFO : Number of reduce tasks
not specified. Estimated from input data size: 1
INFO : In order to change the
average load for a reducer (in bytes):
INFO : set
hive.exec.reducers.bytes.per.reducer=
INFO : In order to limit the
maximum number of reducers:
INFO : set hive.exec.reducers.max=
INFO : In order to set a
constant number of reducers:
INFO : set mapreduce.job.reduces=
INFO : number of splits:1
INFO : Submitting tokens for
job: job_1591768379763_0005
INFO : The url to track the
job: http://hadoop207.cevent.com:8088/proxy/application_1591768379763_0005/
INFO : Starting Job =
job_1591768379763_0005, Tracking URL =
http://hadoop207.cevent.com:8088/proxy/application_1591768379763_0005/
INFO : Kill Command =
/opt/module/hadoop-2.7.2/bin/hadoop job
-kill job_1591768379763_0005
INFO : Hadoop job information
for Stage-1: number of mappers: 1; number of reducers: 1
INFO : 2020-06-10 17:34:05,334
Stage-1 map = 0%, reduce = 0%
INFO : 2020-06-10 17:34:20,032
Stage-1 map = 21%, reduce = 0%,
Cumulative CPU 3.26 sec
INFO : 2020-06-10 17:34:23,171
Stage-1 map = 100%, reduce = 0%,
Cumulative CPU 4.18 sec
INFO : 2020-06-10 17:34:37,709
Stage-1 map = 100%, reduce = 100%,
Cumulative CPU 6.23 sec
INFO : MapReduce Total
cumulative CPU time: 6 seconds 230 msec
INFO : Ended Job =
job_1591768379763_0005
INFO : Number of reduce tasks
determined at compile time: 1
INFO : In order to change the
average load for a reducer (in bytes):
INFO : set
hive.exec.reducers.bytes.per.reducer=
INFO : In order to limit the
maximum number of reducers:
INFO : set hive.exec.reducers.max=
INFO : In order to set a
constant number of reducers:
INFO : set mapreduce.job.reduces=
INFO : number of splits:1
INFO : Submitting tokens for
job: job_1591768379763_0006
INFO : The url to track the
job: http://hadoop207.cevent.com:8088/proxy/application_1591768379763_0006/
INFO : Starting Job =
job_1591768379763_0006, Tracking URL = http://hadoop207.cevent.com:8088/proxy/application_1591768379763_0006/
INFO : Kill Command =
/opt/module/hadoop-2.7.2/bin/hadoop job
-kill job_1591768379763_0006
INFO : Hadoop job information
for Stage-2: number of mappers: 1; number of reducers: 1
INFO : 2020-06-10 17:34:54,889
Stage-2 map = 0%, reduce = 0%
INFO : 2020-06-10 17:35:04,185
Stage-2 map = 100%, reduce = 0%,
Cumulative CPU 1.36 sec
INFO : 2020-06-10 17:35:13,581
Stage-2 map = 100%, reduce = 100%,
Cumulative CPU 3.13 sec
INFO : MapReduce Total
cumulative CPU time: 3 seconds 130 msec
INFO : Ended Job =
job_1591768379763_0006
+----------------+-------------+--+
|
categories | hot_view
|
+----------------+-------------+--+
| Music | 2426199511 |
| Entertainment | 1644510629 |
| Comedy | 1603337065 |
| Film | 659449540 |
|
Animation | 659449540 |
| Sports | 647412772 |
|
Games | 505658305 |
| Gadgets | 505658305 |
| People | 425607955 |
|
Blogs | 425607955 |
+----------------+-------------+--+
10 rows selected (86.081 seconds)
0:
jdbc:hive2://hadoop207.cevent.com:10000> select
categories,count(1) count_views
0:
jdbc:hive2://hadoop207.cevent.com:10000> from
0:
jdbc:hive2://hadoop207.cevent.com:10000> (select
video_id,categories
0:
jdbc:hive2://hadoop207.cevent.com:10000> from
0:
jdbc:hive2://hadoop207.cevent.com:10000> (select
video_id,category,views from video_store order by views desc limit 20)
0: jdbc:hive2://hadoop207.cevent.com:10000>
top1
0:
jdbc:hive2://hadoop207.cevent.com:10000> lateral
view explode(category) topclass as categories)
0:
jdbc:hive2://hadoop207.cevent.com:10000> top2
0:
jdbc:hive2://hadoop207.cevent.com:10000> group by
categories;
INFO : Number of reduce tasks
determined at compile time: 1
INFO : In order to change the
average load for a reducer (in bytes):
INFO : set
hive.exec.reducers.bytes.per.reducer=
INFO : In order to limit the
maximum number of reducers:
INFO : set hive.exec.reducers.max=
INFO : In order to set a
constant number of reducers:
INFO : set mapreduce.job.reduces=
INFO : number of splits:1
INFO : Submitting tokens for
job: job_1591796204991_0001
INFO : The url to track the
job: http://hadoop207.cevent.com:8088/proxy/application_1591796204991_0001/
INFO : Starting Job =
job_1591796204991_0001, Tracking URL =
http://hadoop207.cevent.com:8088/proxy/application_1591796204991_0001/
INFO : Kill Command =
/opt/module/hadoop-2.7.2/bin/hadoop job
-kill job_1591796204991_0001
INFO : Hadoop job information
for Stage-1: number of mappers: 1; number of reducers: 1
INFO : 2020-06-10 21:50:11,943
Stage-1 map = 0%, reduce = 0%
INFO : 2020-06-10 21:50:27,751
Stage-1 map = 100%, reduce = 0%,
Cumulative CPU 5.16 sec
INFO : 2020-06-10 21:50:39,744
Stage-1 map = 100%, reduce = 100%,
Cumulative CPU 8.64 sec
INFO : MapReduce Total
cumulative CPU time: 8 seconds 640 msec
INFO : Ended Job =
job_1591796204991_0001
INFO : Number of reduce tasks not
specified. Estimated from input data size: 1
INFO : In order to change the
average load for a reducer (in bytes):
INFO : set
hive.exec.reducers.bytes.per.reducer=
INFO : In order to limit the
maximum number of reducers:
INFO : set hive.exec.reducers.max=
INFO : In order to set a
constant number of reducers:
INFO : set mapreduce.job.reduces=
INFO : number of splits:1
INFO : Submitting tokens for
job: job_1591796204991_0002
INFO : The url to track the
job: http://hadoop207.cevent.com:8088/proxy/application_1591796204991_0002/
INFO : Starting Job =
job_1591796204991_0002, Tracking URL =
http://hadoop207.cevent.com:8088/proxy/application_1591796204991_0002/
INFO : Kill Command =
/opt/module/hadoop-2.7.2/bin/hadoop job
-kill job_1591796204991_0002
INFO : Hadoop job information
for Stage-2: number of mappers: 1; number of reducers: 1
INFO : 2020-06-10 21:50:53,760
Stage-2 map = 0%, reduce = 0%
INFO : 2020-06-10 21:51:02,050
Stage-2 map = 100%, reduce = 0%,
Cumulative CPU 1.26 sec
INFO : 2020-06-10 21:51:10,767
Stage-2 map = 100%, reduce = 100%,
Cumulative CPU 3.1 sec
INFO : MapReduce Total
cumulative CPU time: 3 seconds 100 msec
INFO : Ended Job =
job_1591796204991_0002
+----------------+--------------+--+
|
categories | count_views |
+----------------+--------------+--+
|
Blogs | 2 |
|
UNA | 1 |
| Comedy | 6 |
| Entertainment | 6 |
| Music | 5 |
| People | 2 |
+----------------+--------------+--+
6 rows selected (79.887 seconds) 热度前50类别
0:
jdbc:hive2://hadoop207.cevent.com:10000> select
categories,count(1) hot50
0: jdbc:hive2://hadoop207.cevent.com:10000>
from
0:
jdbc:hive2://hadoop207.cevent.com:10000> (select
video_id,categories
0:
jdbc:hive2://hadoop207.cevent.com:10000> from
0:
jdbc:hive2://hadoop207.cevent.com:10000> (select
0:
jdbc:hive2://hadoop207.cevent.com:10000> distinct
top50.video_id,
0:
jdbc:hive2://hadoop207.cevent.com:10000> category
0:
jdbc:hive2://hadoop207.cevent.com:10000> from
0:
jdbc:hive2://hadoop207.cevent.com:10000> (select
0: jdbc:hive2://hadoop207.cevent.com:10000>
explode(related_id) video_id
0:
jdbc:hive2://hadoop207.cevent.com:10000> from
0:
jdbc:hive2://hadoop207.cevent.com:10000> (select
video_id,related_id,views from video_store order by views desc limit 50)
0:
jdbc:hive2://hadoop207.cevent.com:10000> top5)
0:
jdbc:hive2://hadoop207.cevent.com:10000> top50
0:
jdbc:hive2://hadoop207.cevent.com:10000> left join
video_store vs
0:
jdbc:hive2://hadoop207.cevent.com:10000> on
top50.video_id=vs.video_id)
0:
jdbc:hive2://hadoop207.cevent.com:10000> top50s
0: jdbc:hive2://hadoop207.cevent.com:10000>
lateral view explode(category) top50sc as categories)
0:
jdbc:hive2://hadoop207.cevent.com:10000> tops
0:
jdbc:hive2://hadoop207.cevent.com:10000> group by
categories
0:
jdbc:hive2://hadoop207.cevent.com:10000> order by
hot50 desc;
INFO : Number of reduce tasks
determined at compile time: 1
INFO : In order to change the
average load for a reducer (in bytes):
INFO : set
hive.exec.reducers.bytes.per.reducer=
INFO : In order to limit the
maximum number of reducers:
INFO : set hive.exec.reducers.max=
INFO : In order to set a
constant number of reducers:
INFO : set mapreduce.job.reduces=
INFO : number of splits:1
INFO : Submitting tokens for
job: job_1591796204991_0003
INFO : The url to track the
job: http://hadoop207.cevent.com:8088/proxy/application_1591796204991_0003/
INFO : Starting Job =
job_1591796204991_0003, Tracking URL =
http://hadoop207.cevent.com:8088/proxy/application_1591796204991_0003/
INFO : Kill Command =
/opt/module/hadoop-2.7.2/bin/hadoop job
-kill job_1591796204991_0003
INFO : Hadoop job information
for Stage-1: number of mappers: 1; number of reducers: 1
INFO : 2020-06-10 22:15:13,852
Stage-1 map = 0%, reduce = 0%
INFO : 2020-06-10 22:15:26,287
Stage-1 map = 100%, reduce = 0%,
Cumulative CPU 4.82 sec
INFO : 2020-06-10 22:15:36,750
Stage-1 map = 100%, reduce = 100%,
Cumulative CPU 7.59 sec
INFO : MapReduce Total
cumulative CPU time: 7 seconds 590 msec
INFO : Ended Job = job_1591796204991_0003
INFO : Stage-9 is selected by
condition resolver.
INFO : Stage-2 is filtered out
by condition resolver.
ERROR : Execution failed with exit status: 3
ERROR : Obtaining error information
ERROR :
Task failed!
Task ID:
Stage-9
Logs:
ERROR : /opt/module/hive-1.2.1/logs/hive.log
INFO : Number of reduce tasks
not specified. Estimated from input data size: 1
INFO : In order to change the
average load for a reducer (in bytes):
INFO : set
hive.exec.reducers.bytes.per.reducer=
INFO : In order to limit the
maximum number of reducers:
INFO : set hive.exec.reducers.max=
INFO : In order to set a
constant number of reducers:
INFO : set mapreduce.job.reduces=
INFO : number of splits:2
INFO : Submitting tokens for
job: job_1591796204991_0004
INFO : The url to track the
job: http://hadoop207.cevent.com:8088/proxy/application_1591796204991_0004/
INFO : Starting Job =
job_1591796204991_0004, Tracking URL =
http://hadoop207.cevent.com:8088/proxy/application_1591796204991_0004/
INFO : Kill Command =
/opt/module/hadoop-2.7.2/bin/hadoop job
-kill job_1591796204991_0004
INFO : Hadoop job information
for Stage-2: number of mappers: 2; number of reducers: 1
INFO : 2020-06-10 22:15:53,641
Stage-2 map = 0%, reduce = 0%
INFO : 2020-06-10 22:16:06,730
Stage-2 map = 50%, reduce = 0%,
Cumulative CPU 1.26 sec
INFO : 2020-06-10 22:16:09,932
Stage-2 map = 100%, reduce = 0%,
Cumulative CPU 6.23 sec
INFO : 2020-06-10 22:16:20,255
Stage-2 map = 100%, reduce = 100%,
Cumulative CPU 11.0 sec
INFO : MapReduce Total
cumulative CPU time: 11 seconds 0 msec
INFO : Ended Job =
job_1591796204991_0004
INFO : Number of reduce tasks
not specified. Estimated from input data size: 1
INFO : In order to change the
average load for a reducer (in bytes):
INFO : set
hive.exec.reducers.bytes.per.reducer=
INFO : In order to limit the
maximum number of reducers:
INFO : set hive.exec.reducers.max=
INFO : In order to set a
constant number of reducers:
INFO : set mapreduce.job.reduces=
INFO : number of splits:1
INFO : Submitting tokens for
job: job_1591796204991_0005
INFO : The url to track the
job: http://hadoop207.cevent.com:8088/proxy/application_1591796204991_0005/
INFO : Starting Job =
job_1591796204991_0005, Tracking URL =
http://hadoop207.cevent.com:8088/proxy/application_1591796204991_0005/
INFO : Kill Command =
/opt/module/hadoop-2.7.2/bin/hadoop job
-kill job_1591796204991_0005
INFO : Hadoop job information
for Stage-3: number of mappers: 1; number of reducers: 1
INFO : 2020-06-10 22:16:33,666
Stage-3 map = 0%, reduce = 0%
INFO : 2020-06-10 22:16:39,909
Stage-3 map = 100%, reduce = 0%,
Cumulative CPU 0.87 sec
INFO : 2020-06-10 22:16:45,066
Stage-3 map = 100%, reduce = 100%,
Cumulative CPU 2.22 sec
INFO : MapReduce Total
cumulative CPU time: 2 seconds 220 msec
INFO : Ended Job =
job_1591796204991_0005
INFO : Number of reduce tasks
not specified. Estimated from input data size: 1
INFO : In order to change the
average load for a reducer (in bytes):
INFO : set
hive.exec.reducers.bytes.per.reducer=
INFO : In order to limit the
maximum number of reducers:
INFO : set hive.exec.reducers.max=
INFO : In order to set a
constant number of reducers:
INFO : set mapreduce.job.reduces=
INFO : number of splits:1
INFO : Submitting tokens for
job: job_1591796204991_0006
INFO : The url to track the
job: http://hadoop207.cevent.com:8088/proxy/application_1591796204991_0006/
INFO : Starting Job =
job_1591796204991_0006, Tracking URL =
http://hadoop207.cevent.com:8088/proxy/application_1591796204991_0006/
INFO : Kill Command =
/opt/module/hadoop-2.7.2/bin/hadoop job
-kill job_1591796204991_0006
INFO : Hadoop job information
for Stage-4: number of mappers: 1; number of reducers: 1
INFO : 2020-06-10 22:16:56,856
Stage-4 map = 0%, reduce = 0%
INFO : 2020-06-10 22:17:04,043
Stage-4 map = 100%, reduce = 0%,
Cumulative CPU 1.2 sec
INFO : 2020-06-10 22:17:10,240
Stage-4 map = 100%, reduce = 100%,
Cumulative CPU 2.52 sec
INFO : MapReduce Total
cumulative CPU time: 2 seconds 520 msec
INFO : Ended Job =
job_1591796204991_0006
INFO : Number of reduce tasks
determined at compile time: 1
INFO : In order to change the
average load for a reducer (in bytes):
INFO : set
hive.exec.reducers.bytes.per.reducer=
INFO : In order to limit the maximum
number of reducers:
INFO : set hive.exec.reducers.max=
INFO : In order to set a
constant number of reducers:
INFO : set mapreduce.job.reduces=
INFO : number of splits:1
INFO : Submitting tokens for
job: job_1591796204991_0007
INFO : The url to track the
job: http://hadoop207.cevent.com:8088/proxy/application_1591796204991_0007/
INFO : Starting Job =
job_1591796204991_0007, Tracking URL =
http://hadoop207.cevent.com:8088/proxy/application_1591796204991_0007/
INFO : Kill Command =
/opt/module/hadoop-2.7.2/bin/hadoop job
-kill job_1591796204991_0007
INFO : Hadoop job information
for Stage-5: number of mappers: 1; number of reducers: 1
INFO : 2020-06-10 22:17:22,760
Stage-5 map = 0%, reduce = 0%
INFO : 2020-06-10 22:17:31,863
Stage-5 map = 100%, reduce = 0%,
Cumulative CPU 1.01 sec
INFO : 2020-06-10 22:17:38,056
Stage-5 map = 100%, reduce = 100%,
Cumulative CPU 2.46 sec
INFO : MapReduce Total
cumulative CPU time: 2 seconds 460 msec
INFO : Ended Job =
job_1591796204991_0007
+----------------+--------+--+
|
categories | hot50 |
+----------------+--------+--+
| Comedy | 14 |
| Entertainment | 11
|
| Music | 10
|
| Film | 3 |
|
Animation | 3 |
| People | 2 |
|
Blogs | 2 |
| Travel | 1 |
| Sports | 1 |
| Howto | 1 |
|
Places | 1 |
|
DIY | 1 |
+----------------+--------+--+
12 rows selected (156.518 seconds)
0:
jdbc:hive2://hadoop207.cevent.com:10000> select categories,count(1) hot50
0:
jdbc:hive2://hadoop207.cevent.com:10000> from
0:
jdbc:hive2://hadoop207.cevent.com:10000> (select video_id,categories
0:
jdbc:hive2://hadoop207.cevent.com:10000> from
0: jdbc:hive2://hadoop207.cevent.com:10000>
(select
0:
jdbc:hive2://hadoop207.cevent.com:10000> distinct top2.video_id,
0:
jdbc:hive2://hadoop207.cevent.com:10000> category
0:
jdbc:hive2://hadoop207.cevent.com:10000> from
0: jdbc:hive2://hadoop207.cevent.com:10000>
(select
0:
jdbc:hive2://hadoop207.cevent.com:10000> explode(related_id) video_id
0:
jdbc:hive2://hadoop207.cevent.com:10000> from
0:
jdbc:hive2://hadoop207.cevent.com:10000> (select video_id,related_id,views
from video_store order by views desc limit 50)
0:
jdbc:hive2://hadoop207.cevent.com:10000> top1)
0:
jdbc:hive2://hadoop207.cevent.com:10000> top2
0:
jdbc:hive2://hadoop207.cevent.com:10000> left join video_store vs
0:
jdbc:hive2://hadoop207.cevent.com:10000> on top2.video_id=vs.video_id)
0:
jdbc:hive2://hadoop207.cevent.com:10000> top3
0:
jdbc:hive2://hadoop207.cevent.com:10000> lateral view explode(category)
top50 as categories)
0: jdbc:hive2://hadoop207.cevent.com:10000>
top4
0:
jdbc:hive2://hadoop207.cevent.com:10000> group by categories
0:
jdbc:hive2://hadoop207.cevent.com:10000> order by hot50 desc;
INFO : Number of reduce tasks
determined at compile time: 1
INFO : In order to change the
average load for a reducer (in bytes):
INFO : set
hive.exec.reducers.bytes.per.reducer=
INFO : In order to limit the
maximum number of reducers:
INFO : set hive.exec.reducers.max=
INFO : In order to set a
constant number of reducers:
INFO : set mapreduce.job.reduces=
INFO : number of splits:1
INFO : Submitting tokens for
job: job_1591796204991_0008
INFO : The url to track the
job: http://hadoop207.cevent.com:8088/proxy/application_1591796204991_0008/
INFO : Starting Job =
job_1591796204991_0008, Tracking URL =
http://hadoop207.cevent.com:8088/proxy/application_1591796204991_0008/
INFO : Kill Command =
/opt/module/hadoop-2.7.2/bin/hadoop job
-kill job_1591796204991_0008
INFO : Hadoop job information
for Stage-1: number of mappers: 1; number of reducers: 1
INFO : 2020-06-10 22:27:38,317
Stage-1 map = 0%, reduce = 0%
INFO : 2020-06-10 22:27:48,615
Stage-1 map = 100%, reduce = 0%,
Cumulative CPU 4.8 sec
INFO : 2020-06-10 22:27:57,877
Stage-1 map = 100%, reduce = 100%,
Cumulative CPU 7.66 sec
INFO : MapReduce Total
cumulative CPU time: 7 seconds 660 msec
INFO : Ended Job =
job_1591796204991_0008
INFO : Stage-9 is selected by
condition resolver.
INFO : Stage-2 is filtered out
by condition resolver.
ERROR : Execution failed with exit status: 3
ERROR : Obtaining error information
ERROR :
Task failed!
Task ID:
Stage-9
Logs:
ERROR : /opt/module/hive-1.2.1/logs/hive.log
INFO : Number of reduce tasks
not specified. Estimated from input data size: 1
INFO : In order to change the
average load for a reducer (in bytes):
INFO : set
hive.exec.reducers.bytes.per.reducer=
INFO : In order to limit the
maximum number of reducers:
INFO : set hive.exec.reducers.max=
INFO : In order to set a
constant number of reducers:
INFO : set mapreduce.job.reduces=
INFO : number of splits:2
INFO : Submitting tokens for
job: job_1591796204991_0009
INFO : The url to track the
job: http://hadoop207.cevent.com:8088/proxy/application_1591796204991_0009/
INFO : Starting Job =
job_1591796204991_0009, Tracking URL =
http://hadoop207.cevent.com:8088/proxy/application_1591796204991_0009/
INFO : Kill Command = /opt/module/hadoop-2.7.2/bin/hadoop
job -kill job_1591796204991_0009
INFO : Hadoop job information
for Stage-2: number of mappers: 2; number of reducers: 1
INFO : 2020-06-10 22:28:16,085
Stage-2 map = 0%, reduce = 0%
INFO : 2020-06-10 22:28:27,280
Stage-2 map = 50%, reduce = 0%
INFO : 2020-06-10 22:28:32,046
Stage-2 map = 100%, reduce = 0%,
Cumulative CPU 6.44 sec
INFO : 2020-06-10 22:28:43,275
Stage-2 map = 100%, reduce = 100%,
Cumulative CPU 11.15 sec
INFO : MapReduce Total
cumulative CPU time: 11 seconds 150 msec
INFO : Ended Job =
job_1591796204991_0009
INFO : Number of reduce tasks
not specified. Estimated from input data size: 1
INFO : In order to change the
average load for a reducer (in bytes):
INFO : set hive.exec.reducers.bytes.per.reducer=
INFO : In order to limit the
maximum number of reducers:
INFO : set hive.exec.reducers.max=
INFO : In order to set a
constant number of reducers:
INFO : set mapreduce.job.reduces=
INFO : number of splits:1
INFO : Submitting tokens for
job: job_1591796204991_0010
INFO : The url to track the
job: http://hadoop207.cevent.com:8088/proxy/application_1591796204991_0010/
INFO : Starting Job =
job_1591796204991_0010, Tracking URL =
http://hadoop207.cevent.com:8088/proxy/application_1591796204991_0010/
INFO : Kill Command =
/opt/module/hadoop-2.7.2/bin/hadoop job
-kill job_1591796204991_0010
INFO : Hadoop job information
for Stage-3: number of mappers: 1; number of reducers: 1
INFO : 2020-06-10 22:28:59,537
Stage-3 map = 0%, reduce = 0%
INFO : 2020-06-10 22:29:04,869
Stage-3 map = 100%, reduce = 0%,
Cumulative CPU 0.99 sec
INFO : 2020-06-10 22:29:12,157
Stage-3 map = 100%, reduce = 100%,
Cumulative CPU 2.56 sec
INFO : MapReduce Total
cumulative CPU time: 2 seconds 560 msec
INFO : Ended Job =
job_1591796204991_0010
INFO : Number of reduce tasks
not specified. Estimated from input data size: 1
INFO : In order to change the
average load for a reducer (in bytes):
INFO : set
hive.exec.reducers.bytes.per.reducer=
INFO : In order to limit the
maximum number of reducers:
INFO : set hive.exec.reducers.max=
INFO : In order to set a
constant number of reducers:
INFO : set mapreduce.job.reduces=
INFO : number of splits:1
INFO : Submitting tokens for
job: job_1591796204991_0011
INFO : The url to track the
job: http://hadoop207.cevent.com:8088/proxy/application_1591796204991_0011/
INFO : Starting Job = job_1591796204991_0011,
Tracking URL =
http://hadoop207.cevent.com:8088/proxy/application_1591796204991_0011/
INFO : Kill Command =
/opt/module/hadoop-2.7.2/bin/hadoop job
-kill job_1591796204991_0011
INFO : Hadoop job information
for Stage-4: number of mappers: 1; number of reducers: 1
INFO : 2020-06-10 22:29:24,044
Stage-4 map = 0%, reduce = 0%
INFO : 2020-06-10 22:29:29,179
Stage-4 map = 100%, reduce = 0%,
Cumulative CPU 0.8 sec
INFO : 2020-06-10 22:29:36,872
Stage-4 map = 100%, reduce = 100%,
Cumulative CPU 2.3 sec
INFO : MapReduce Total
cumulative CPU time: 2 seconds 300 msec
INFO : Ended Job =
job_1591796204991_0011
INFO : Number of reduce tasks
determined at compile time: 1
INFO : In order to change the
average load for a reducer (in bytes):
INFO : set
hive.exec.reducers.bytes.per.reducer=
INFO : In order to limit the
maximum number of reducers:
INFO : set hive.exec.reducers.max=
INFO : In order to set a
constant number of reducers:
INFO : set mapreduce.job.reduces=
INFO : number of splits:1
INFO : Submitting tokens for
job: job_1591796204991_0012
INFO : The url to track the
job: http://hadoop207.cevent.com:8088/proxy/application_1591796204991_0012/
INFO : Starting Job =
job_1591796204991_0012, Tracking URL =
http://hadoop207.cevent.com:8088/proxy/application_1591796204991_0012/
INFO : Kill Command =
/opt/module/hadoop-2.7.2/bin/hadoop job
-kill job_1591796204991_0012
INFO : Hadoop job information
for Stage-5: number of mappers: 1; number of reducers: 1
INFO : 2020-06-10 22:29:49,880
Stage-5 map = 0%, reduce = 0%
INFO : 2020-06-10 22:29:58,929
Stage-5 map = 100%, reduce = 0%,
Cumulative CPU 0.87 sec
INFO : 2020-06-10 22:30:05,100
Stage-5 map = 100%, reduce = 100%,
Cumulative CPU 2.23 sec
INFO : MapReduce Total
cumulative CPU time: 2 seconds 230 msec
INFO : Ended Job =
job_1591796204991_0012
+----------------+--------+--+
|
categories | hot50 |
+----------------+--------+--+
| Comedy | 14 |
| Entertainment | 11
|
| Music | 10 |
| Film | 3 |
|
Animation | 3 |
| People | 2 |
|
Blogs | 2 |
| Travel | 1 |
| Sports | 1 |
| Howto | 1 |
|
Places | 1 |
|
DIY | 1 |
+----------------+--------+--+
12 rows selected (155.864 seconds) 创建中间表
0:
jdbc:hive2://hadoop207.cevent.com:10000> create
table video_center stored as orc as
0:
jdbc:hive2://hadoop207.cevent.com:10000> select
0: jdbc:hive2://hadoop207.cevent.com:10000> video_id,
0:
jdbc:hive2://hadoop207.cevent.com:10000> uploader,
0:
jdbc:hive2://hadoop207.cevent.com:10000> age,
0:
jdbc:hive2://hadoop207.cevent.com:10000> categories,
0:
jdbc:hive2://hadoop207.cevent.com:10000> length,
0: jdbc:hive2://hadoop207.cevent.com:10000> views,
0:
jdbc:hive2://hadoop207.cevent.com:10000> rate,
0:
jdbc:hive2://hadoop207.cevent.com:10000> ratings,
0:
jdbc:hive2://hadoop207.cevent.com:10000> comments,
0:
jdbc:hive2://hadoop207.cevent.com:10000>
related_id
0: jdbc:hive2://hadoop207.cevent.com:10000>
from video_store
0:
jdbc:hive2://hadoop207.cevent.com:10000> lateral
view
0:
jdbc:hive2://hadoop207.cevent.com:10000> explode(category)
tb1 as categories;
INFO : Number of reduce tasks
is set to 0 since there's no reduce operator
INFO : number of splits:1
INFO : Submitting tokens for
job: job_1591796204991_0013
INFO : The url to track the
job: http://hadoop207.cevent.com:8088/proxy/application_1591796204991_0013/
INFO : Starting Job =
job_1591796204991_0013, Tracking URL =
http://hadoop207.cevent.com:8088/proxy/application_1591796204991_0013/
INFO : Kill Command =
/opt/module/hadoop-2.7.2/bin/hadoop job
-kill job_1591796204991_0013
INFO : Hadoop job information
for Stage-1: number of mappers: 1; number of reducers: 0
INFO : 2020-06-10 22:40:04,820
Stage-1 map = 0%, reduce = 0%
INFO : 2020-06-10 22:40:20,958
Stage-1 map = 100%, reduce = 0%,
Cumulative CPU 12.58 sec
INFO : MapReduce Total
cumulative CPU time: 12 seconds 580 msec
INFO : Ended Job =
job_1591796204991_0013
INFO : Stage-4 is selected by
condition resolver.
INFO : Stage-3 is filtered out
by condition resolver.
INFO : Stage-5 is filtered out
by condition resolver.
INFO : Moving data to:
hdfs://hadoop207.cevent.com:8020/user/hive/warehouse/cevent01.db/.hive-staging_hive_2020-06-10_22-39-57_695_4121069996262157418-1/-ext-10001
from hdfs://hadoop207.cevent.com:8020/user/hive/warehouse/cevent01.db/.hive-staging_hive_2020-06-10_22-39-57_695_4121069996262157418-1/-ext-10003
INFO : Moving data to:
hdfs://hadoop207.cevent.com:8020/user/hive/warehouse/cevent01.db/video_center
from hdfs://hadoop207.cevent.com:8020/user/hive/warehouse/cevent01.db/.hive-staging_hive_2020-06-10_22-39-57_695_4121069996262157418-1/-ext-10001
INFO : Table
cevent01.video_center stats: [numFiles=1, numRows=1019206,
totalSize=25757855, rawDataSize=405083036]
No rows affected (29.661 seconds)
0: jdbc:hive2://hadoop207.cevent.com:10000> select video_id,views
0: jdbc:hive2://hadoop207.cevent.com:10000> from video_center
0: jdbc:hive2://hadoop207.cevent.com:10000> where
categories='music'
0: jdbc:hive2://hadoop207.cevent.com:10000> order by views desc
0: jdbc:hive2://hadoop207.cevent.com:10000> limit 10;
INFO : Number of reduce tasks
determined at compile time: 1
INFO : In order to change the
average load for a reducer (in bytes):
INFO : set hive.exec.reducers.bytes.per.reducer=
INFO : In order to limit the
maximum number of reducers:
INFO : set hive.exec.reducers.max=
INFO : In order to set a
constant number of reducers:
INFO : set mapreduce.job.reduces=
INFO : number of splits:1
INFO : Submitting tokens for
job: job_1591796204991_0014
INFO : The url to track the
job: http://hadoop207.cevent.com:8088/proxy/application_1591796204991_0014/
INFO : Starting Job =
job_1591796204991_0014, Tracking URL =
http://hadoop207.cevent.com:8088/proxy/application_1591796204991_0014/
INFO : Kill Command =
/opt/module/hadoop-2.7.2/bin/hadoop job
-kill job_1591796204991_0014
INFO : Hadoop job information
for Stage-1: number of mappers: 1; number of reducers: 1
INFO : 2020-06-10 22:42:33,022
Stage-1 map = 0%, reduce = 0%
INFO : 2020-06-10 22:42:41,367
Stage-1 map = 100%, reduce = 0%,
Cumulative CPU 3.19 sec
INFO : 2020-06-10 22:42:47,540
Stage-1 map = 100%, reduce = 100%,
Cumulative CPU 4.46 sec
INFO : MapReduce Total
cumulative CPU time: 4 seconds 460 msec
INFO : Ended Job =
job_1591796204991_0014
+-----------+--------+--+
| video_id | views
|
+-----------+--------+--+
+-----------+--------+--+
No rows selected (26.279 seconds) 类别前10热度
0:
jdbc:hive2://hadoop207.cevent.com:10000> select
video_id,views
0:
jdbc:hive2://hadoop207.cevent.com:10000> from
video_center
0:
jdbc:hive2://hadoop207.cevent.com:10000> where
categories="music"
0: jdbc:hive2://hadoop207.cevent.com:10000>
order by views desc
0:
jdbc:hive2://hadoop207.cevent.com:10000> limit 10;
INFO : Number of reduce tasks
determined at compile time: 1
INFO : In order to change the
average load for a reducer (in bytes):
INFO : set hive.exec.reducers.bytes.per.reducer=
INFO : In order to limit the
maximum number of reducers:
INFO : set hive.exec.reducers.max=
INFO : In order to set a
constant number of reducers:
INFO : set mapreduce.job.reduces=
INFO : number of splits:1
INFO : Submitting tokens for
job: job_1591796204991_0015
INFO : The url to track the
job: http://hadoop207.cevent.com:8088/proxy/application_1591796204991_0015/
INFO : Starting Job =
job_1591796204991_0015, Tracking URL =
http://hadoop207.cevent.com:8088/proxy/application_1591796204991_0015/
INFO : Kill Command =
/opt/module/hadoop-2.7.2/bin/hadoop job
-kill job_1591796204991_0015
INFO : Hadoop job information
for Stage-1: number of mappers: 1; number of reducers: 1
INFO : 2020-06-10 22:43:24,251
Stage-1 map = 0%, reduce = 0%
INFO : 2020-06-10 22:43:33,219
Stage-1 map = 100%, reduce = 0%,
Cumulative CPU 2.89 sec
INFO : 2020-06-10 22:43:40,417
Stage-1 map = 100%, reduce = 100%,
Cumulative CPU 4.05 sec
INFO : MapReduce Total
cumulative CPU time: 4 seconds 50 msec
INFO : Ended Job =
job_1591796204991_0015
+-----------+--------+--+
| video_id | views
|
+-----------+--------+--+
+-----------+--------+--+
No rows selected (25.851 seconds)
0:
jdbc:hive2://hadoop207.cevent.com:10000> 类别前10流量
0:
jdbc:hive2://hadoop207.cevent.com:10000> select
video_id,ratings
0:
jdbc:hive2://hadoop207.cevent.com:10000> from
video_center
0:
jdbc:hive2://hadoop207.cevent.com:10000> where
categories="music"
0:
jdbc:hive2://hadoop207.cevent.com:10000> order by
ratings desc
0:
jdbc:hive2://hadoop207.cevent.com:10000> limit 10;
INFO
: Number of reduce tasks determined at compile time: 1
INFO
: In order to change the average load for a reducer (in bytes):
INFO
: set
hive.exec.reducers.bytes.per.reducer=
INFO
: In order to limit the maximum number of reducers:
INFO
: set
hive.exec.reducers.max=
INFO
: In order to set a constant number of reducers:
INFO
: set mapreduce.job.reduces=
INFO
: number of splits:1
INFO
: Submitting tokens for job: job_1591796204991_0016
INFO
: The url to track the job:
http://hadoop207.cevent.com:8088/proxy/application_1591796204991_0016/
INFO
: Starting Job = job_1591796204991_0016, Tracking URL =
http://hadoop207.cevent.com:8088/proxy/application_1591796204991_0016/
INFO
: Kill Command = /opt/module/hadoop-2.7.2/bin/hadoop job -kill job_1591796204991_0016
INFO
: Hadoop job information for Stage-1: number of mappers: 1; number of
reducers: 1
INFO
: 2020-06-10 22:47:26,998 Stage-1 map = 0%, reduce = 0%
INFO
: 2020-06-10 22:47:35,703 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 2.96 sec
INFO
: 2020-06-10 22:47:43,061 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 4.18 sec
INFO
: MapReduce Total cumulative CPU time: 4 seconds 180 msec
INFO
: Ended Job = job_1591796204991_0016
+-----------+----------+--+
| video_id | ratings
|
+-----------+----------+--+
+-----------+----------+--+
No rows selected (24.756 seconds)
13.ETL-SQL解析
//ETL应用
//1)创建user外部表:
create external table video_user_info(
uploader string,
videos int,
friends int
)
row format delimited fields terminated by
'\t'
location '/cevent_video_show/user';
select * from video_user_info limit 5;
//2)创建video外部表
create external table video_info(
video_id string,
uploader string,
age int,
category array<string>,
length int,
views int,
rate float,
ratings int,
comments int,
related_id array<string>
)
row format delimited fields terminated by
'\t'
collection items terminated by '&'
location '/cevent_video_show/video';
select * from video_info limit 5;
//3)创建user内部表,将外部表数据导入内部表
create table video_user stored as orc as
select * from video_user_info;
create table video_store stored as orc as
select * from video_info;
//--查询--
//--1.统计视频观看数TOP-10
select * from video_info order by views
desc limit 10;
//--2.统计视频类别热度TOP10(播放量)
select video_id,views,categories
from video_info
lateral view explode(category) vtb1 as
categories;
//假定上标是vtb1,利用lateral view explode进行分解聚合列
select categories,sum(views) hot_view
from
(
select video_id,views,categories
from video_info
lateral view explode(category) vtb1 as
categories
)vtb2
group by categories
order by hot_view desc
limit 10;
//--3.统计视频观看数最高的TOP20个视频,显示所属类别和类别包含的TOP20视频个数
//top1显示前20视频
select video_id,category,views from
video_store order by views desc limit 20;
//top1炸开类别
select video_id,categories
from
(select video_id,category,views from
video_store order by views desc limit 20)
top1
lateral view explode(category) topclass
as categories;
//top2统计个数
select categories,count(1) count_views
from
(select video_id,categories
from
(select video_id,category,views from
video_store order by views desc limit 20)
top1
lateral view explode(category) topclass
as categories)
top2
group by categories;
//--4.统计视频观看数TOP50所关联视频的所属类别排序
//获取TOP50关联视频
select video_id,related_id,views from
video_store order by views desc limit 50;
//top1炸开关联视频,一万条以内可以使用全局去重distinct,因为已经limit,但由于严格模式,不可用
select
explode(related_id) video_id
from
(select video_id,related_id,views from
video_store order by views desc limit 50)
top1;
//top2关联原表,找类别
select
distinct top2.video_id,
category
from
(select
explode(related_id) video_id
from
(select video_id,related_id,views from
video_store order by views desc limit 50)
top1)
top2
left join video_store vs
on top2.video_id=vs.video_id;
//top3 炸开类别
select video_id,categories
from
(select
distinct top2.video_id,
category
from
(select
explode(related_id) video_id
from
(select video_id,related_id,views from
video_store order by views desc limit 50)
top1)
top2
left join video_store vs
on top2.video_id=vs.video_id)
top3
lateral view explode(category) top50 as
categories;
//top4统计排名
select categories,count(1) hot50
from
(select video_id,categories
from
(select
distinct top2.video_id,
category
from
(select
explode(related_id) video_id
from
(select video_id,related_id,views from
video_store order by views desc limit 50)
top1)
top2
left join video_store vs
on top2.video_id=vs.video_id)
top3
lateral view explode(category) top50 as
categories)
top4
group by categories
order by hot50 desc;
//--5.统计每个类别中的视频热度TOP10,以music为例
//创建中间表
create table video_center stored as orc
as
select
video_id,
uploader,
age,
categories,
length,
views,
rate,
ratings,
comments,
related_id
from video_store
lateral view
explode(category) tb1 as categories;
//插入数据中间层
select
video_id,
uploader,
age,
categories,
length,
views,
rate,
ratings,
comments,
related_id
from video_store
lateral view
explode(category) tb1 as categories;
//t1按热度排序
select video_id,views
from video_center
where categories="music"
order by views desc
limit 10;
//--6.统计每个类别中的视频流量TOP10,以music为例
select video_id,ratings
from video_center
where categories="music"
order by ratings desc
limit 10;