六阶段大数据--day01--hadoop集群环境准备
1 集群环境准备
- 解压CentOS7-bigdata.zip虚拟机,复制成三个虚拟机名为: hadoop01 ,hadoop02,hadoop03文件夹;
- 通过vmware打开这三个虚拟机--bigdata.vmx ,重命名为 hadoop01 ,hadoop02,hadoop03
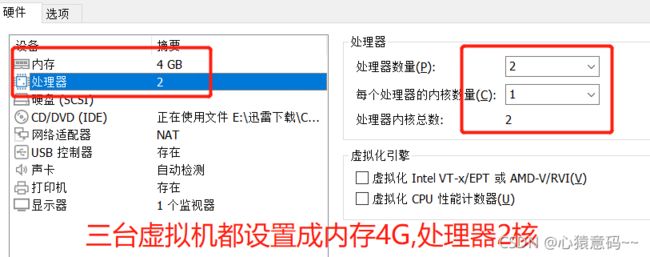
- 对虚拟机进行设备设置:如下图所示
4. 设置虚拟机网络
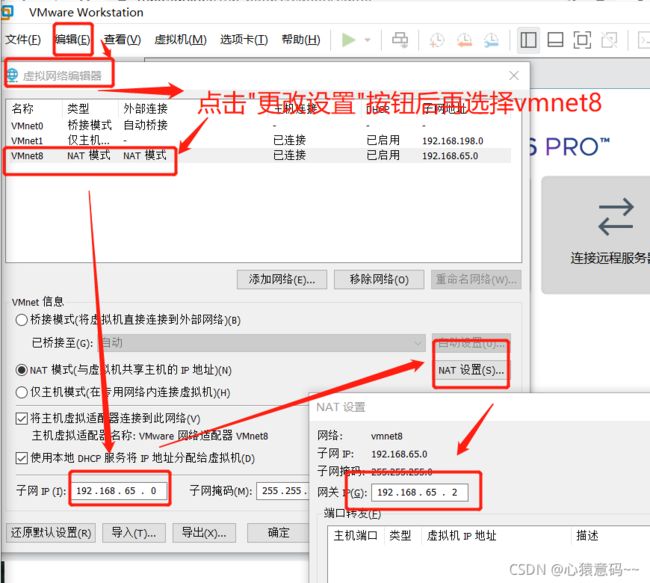
5. 分别启动三台虚拟机

6.登录虚拟机:用户名密码都是root , ip addr命令查看设置的ip,也就是你的网关ip是不是上面设置的

7. 配置文件
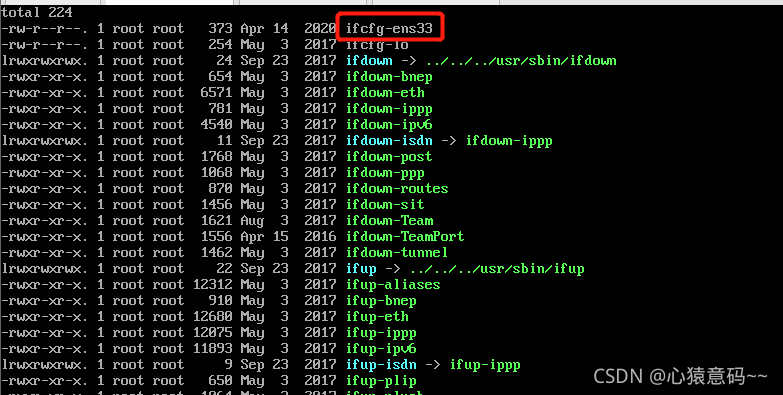
cd /etc/sysconfig/network-scripts #进入网络配置目录(虚拟网卡目录)
ll #查看有没有ifcfg-ens33
dir ifcfg* #找到网卡配置文件
ifcfg-ens33 #找到版本最新的文件并修改
vim ifcfg-ens33
或者
vim /etc/sysconfig/network-scripts/ifcfg-ens33
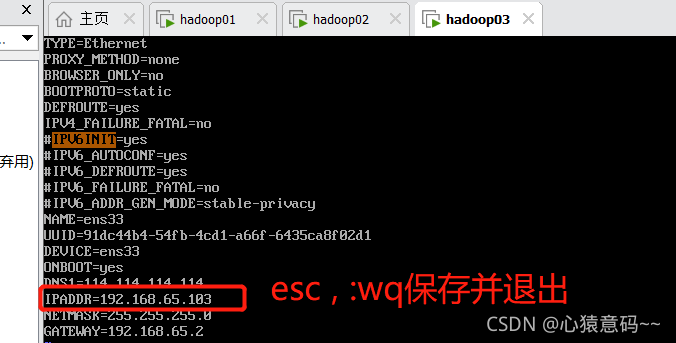
vim ifcfg-ens33 命令,修改网关ip,esc按钮,:wq保存退出

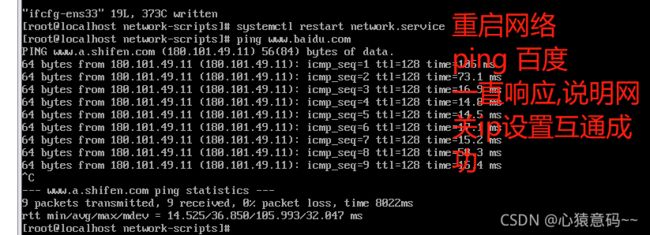
8.重启网络(二选一即可)
service network restart #重启网络
systemctl restart network.service #重启网络centos7

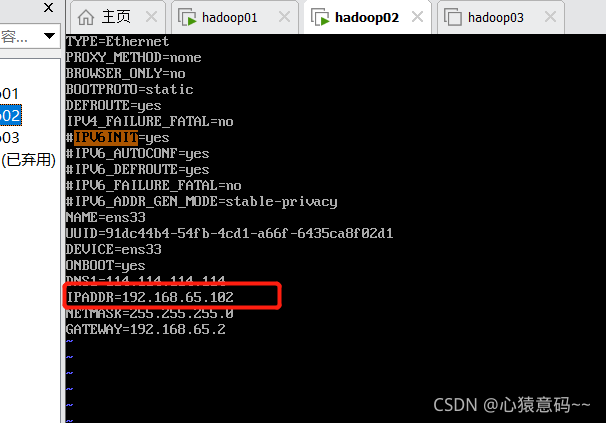
9.hadoop02和03的网络设置也同样操作
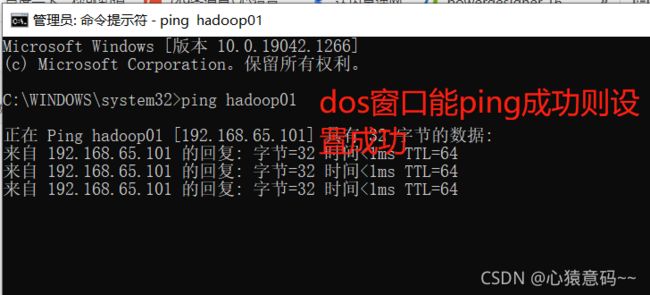
- 重启网络后,分别ping www.baidu.com 连接成功代表设置没问题
10.mobaxTerm连接三台虚拟机


11.关闭三个虚拟机的防火墙
systemctl stop firewalld.service #关闭防火墙服务
systemctl disable firewalld.service #禁止防火墙开启启动
systemctl restart firewalld.service #重启防火墙使配置生效
systemctl enable firewalld.service #设置防火墙开机启动
[root@hadoop01 ~]# firewall-cmd --state #检查防火墙状态
false 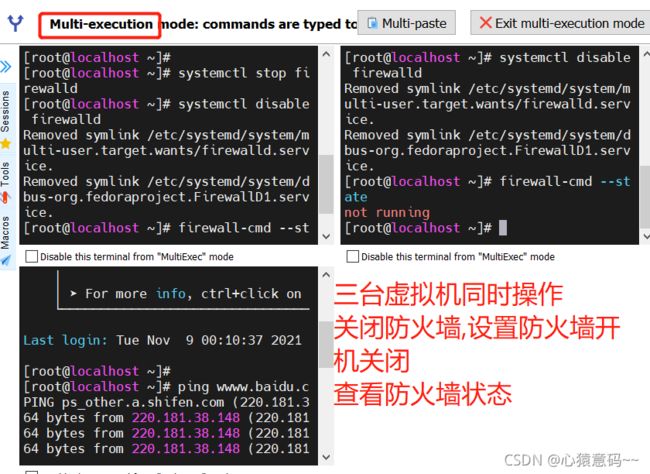
- 点击右上角的exit 退出即可
12. 修改主机名
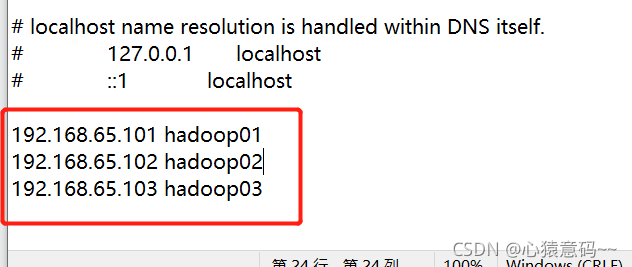
vi /etc/hostname #分别修改三台主机名为hadoop01 hadoop02 hadoop0313. 修改hosts文件


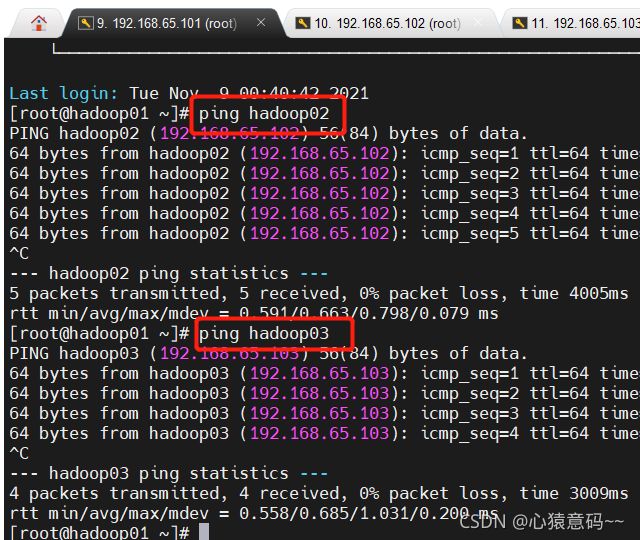
14.reboot 命令重启三个节点服务,重新登录并连接,测试ping命令是否成功
二 设置免密登录
原因:
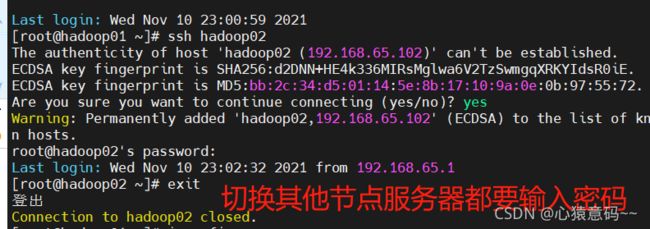
1.生成三台机器的公钥与私钥--使用MultiExec按钮多节点同时操作
ssh-keygen #三个服务器都要执行此命令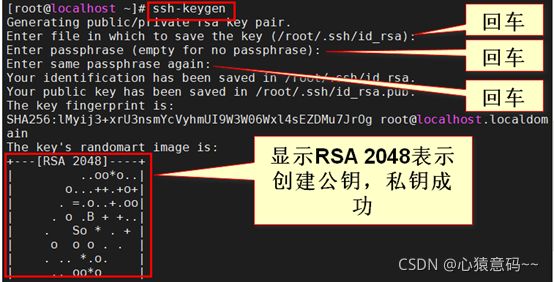
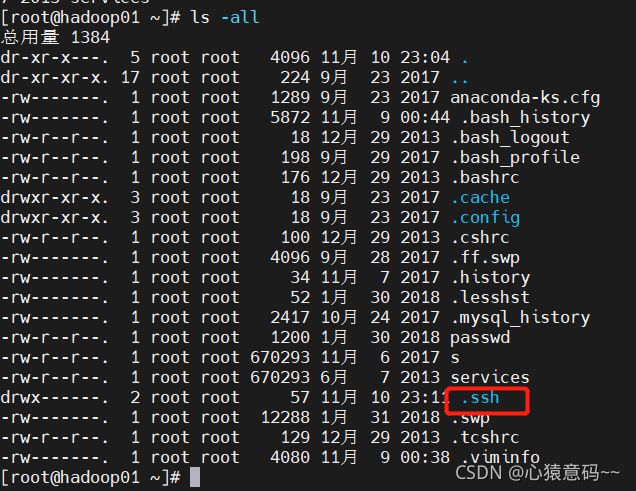
- 每个节点服务器都会生产一下两个数据,pub后缀文件内容就是生成的公钥


2.拷贝公钥到同一台机器,三台机器都执行下面命令:
ssh-copy-id hadoop01

- 回到hadoop01节点服务器查看生成的认证文件
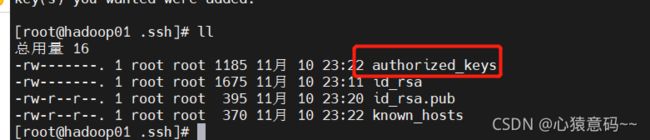
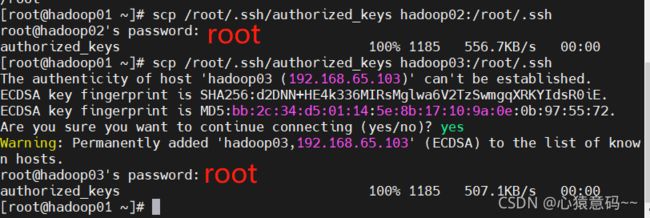
3.复制第一台机器的认证到其他机器
scp /root/.ssh/authorized_keys hadoop02:/root/.ssh #第一台服务器的认证复制到第二台上
scp /root/.ssh/authorized_keys hadoop03:/root/.ssh #第一台服务器的认证复制到第三台上
4.配置完认证后,测试免密登录

三 3台机器时钟同步
1. 不同节点服务器进行时钟同步时,一方面会报错,同步失败,另一方面同步时间会有细微的时差
- 阿里云时钟同步服务器
ntpdate ntp4.aliyun.com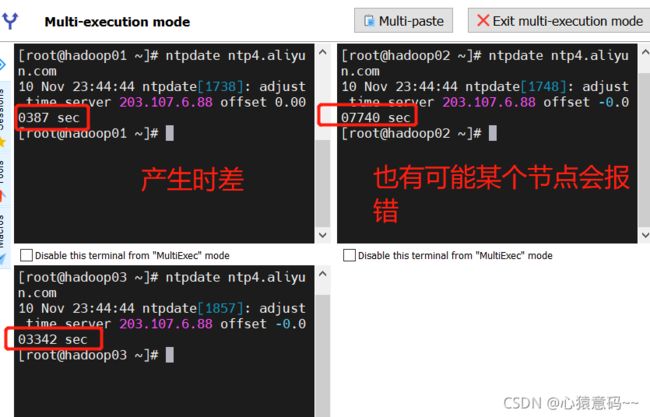
- 三台机器定时任务,操作系统自动完成时间同步
crontab -e
*/1 * * * * /usr/sbin/ntpdate us.pool.ntp.org; #上一命令进入后输入此内容,保存并推出:wq

- 拓展:Linux系统 crontab 时间设置的解释:

四 3台机器安装jdk
1.查看自带的openjdk
rpm -qa | grep java- 如果有,请卸载系统自带的openjdk,方式如下(注:目前系统已经卸载)
rpm -e java-1.6.0-openjdk-1.6.0.41-1.13.13.1.el6_8.x86_64 tzdata-java-2016j-1.el6.noarch java-1.7.0-openjdk-1.7.0.131-2.6.9.0.el6_8.x86_64 --nodeps2. 三台机器创建目录
- 所有软件的安装路径
mkdir -p /opt/servers- 所有软件压缩包的存放路径,进行统一管理
mkdir -p /opt/softwares
3.上传jdk到/opt/softwares路径下去,并解压

tar -xvzf jdk-8u65-linux-x64.tar.gz -C /opt/servers/- 解压后查看

4. 配置环境变量
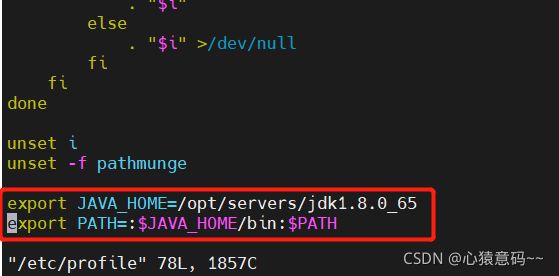
vim /etc/profile #进入该文件目录,配置环境变量
#环境变量内容如下2行,直接粘贴到上面文件的最下方
export JAVA_HOME=/opt/servers/jdk1.8.0_65
export PATH=:$JAVA_HOME/bin:$PATH
# 是配置的环境变量生效
source /etc/profile
![]()
- 测试jdk是否生效,查看jdk的版本
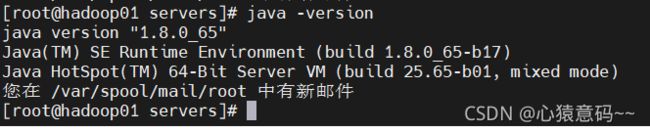
5. 上面只是单独在hadoop01操作,现在要发送(拷贝)jdk文件到hadoop02和hadoop03
scp -r /opt/servers/jdk1.8.0_65/ hadoop02:/opt/servers/
scp -r /opt/servers/jdk1.8.0_65/ hadoop03:/opt/servers/
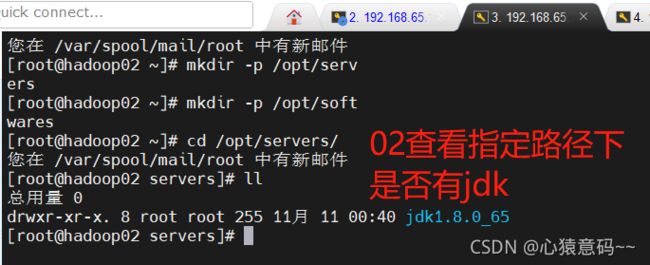
- 03同样操作,并使用source /etc/profile 命令使其生效
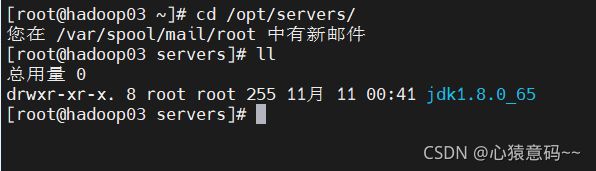
6.复制后,同样都要配置环境变量,source使其生效,查看jdk版本看是否生效



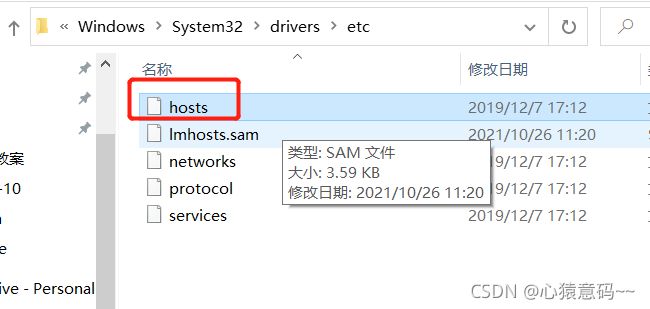
五 修改windows中的hosts文件
- 在windows中的hosts文件里添加如下映射,ip虚拟机和主机的ip的映射,实现windows可以通过主机名(或域名)访问虚拟主机。