大数据学习环境搭建系列(三)VMware Workstation中创建虚拟机

作者 | CDA数据分析师
概述
Linux是类Unix操作系统,我们现在所谓的Linux操作系统,从严格意义上来说是指拥有Linux内核的操作系统,其中,Ubuntu和CentOS操作系统分别是桌面端和服务器端占比最高的开源操作系统,而这两个操作系统也将是后续文章中主要涉及的两个操作系统。
相比其他Linux系统,Ubuntu操作系统拥有人性化的桌面操作界面,除商业用途外,也非常适合PC用户处理日常事务。该系统每隔6个月,也就是每年4月和10月发布一个新版本,一般以年月标注为版本号,如13.04、13.10等,其中,尾注为LTS(Long Term Support)的版本为长期支持版本,一般隔年的4月版本为长期支持版,如12.04 LTS、14.04LTS、16.04LTS等,同时标注为Kylin的版本为中文支持版,由中文社区维护。
CentOS(Community Enterprise Operating System),中文译为社区企业操作系统,是RHEL(Red Hat Enterprise Linux)源码再编译的操作系统,由于其高稳定性,常用于企业级服务器。新版本CentOS大约每两年发布一次,并且每个新版本会定期(一般为6个月)更新一次。CentOS于2014年宣布加入Red Hat,但仍将保持免费。
Ubuntu与CentOS对比: 对命令行操作系统不太熟悉的分布式集群搭建初学者而言,Ubuntu友善的桌面操作系统将是更好的选择,而对于企业应用来说,更加稳定的CentOS系统无疑是更好的选择,同时抛弃了桌面操作系统的版本在系统资源占用方面也更有优势。后续文章,主要将以Ubuntu操作系统为例进行介绍。

虚拟机软件中安装linux系统大致可分两步:1在虚拟机软件中创建虚拟物理机。2、在虚拟物理机中安装linux系统。后续文章主要应用了Ubuntu操作系统,所以本文先来介绍如何在VMware Workstation中创建Ubuntu操作系统对应的虚拟物理机,然后在下一篇文章中介绍该虚拟物理机安装Ubuntu系统的操作方法。
- VMware Workstation中创建虚拟物理机
为了便于管理创建的虚拟物理机,我们首先在一个空间较大(可用空间大于80G)的磁盘创建VM_HOME文件夹,这里我是在D盘中创建的。后面我们创建的虚拟物理机都放在此文件下。
双击打开虚拟机软件VMware Workstation,单击工具栏“编辑”==>“首选项”
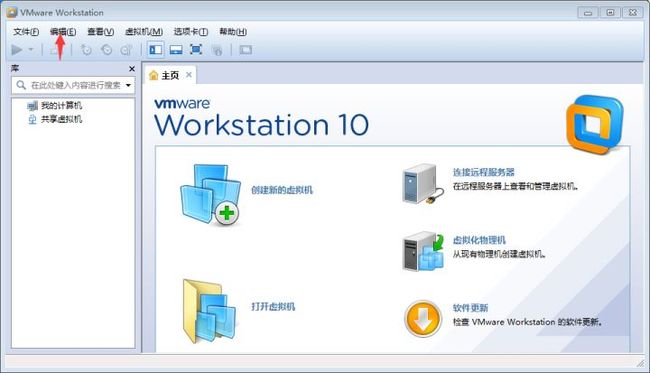
在弹出的首选项窗口中配置虚拟机的默认位置(D)为D:\VM_HOME(原因是我在D盘创建的VM_HOME,大家要按自己创建的路径选择正确的位置),点击确定完成配置。
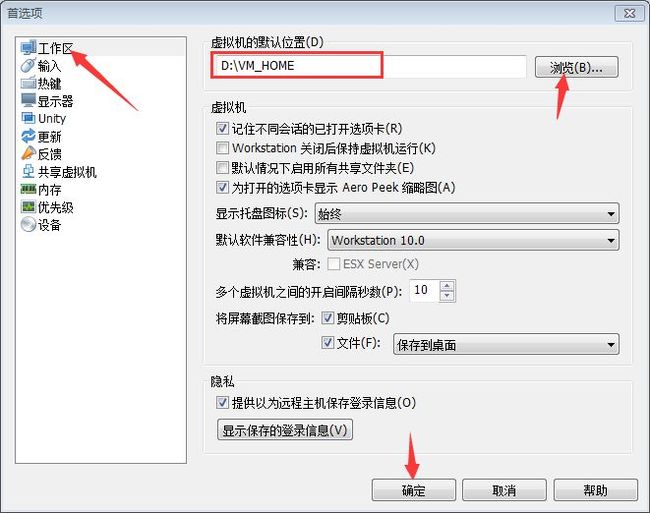
下面我们来创建一个可以安装Ubuntu系统的虚拟机,首先点击下图红框位置进入新建虚拟机向导窗口

在新建虚拟机向导窗口中我们选择自定义(高级)©,然后点击下一步

硬件兼容性选择 Workstation 10.0,单击下一步继续
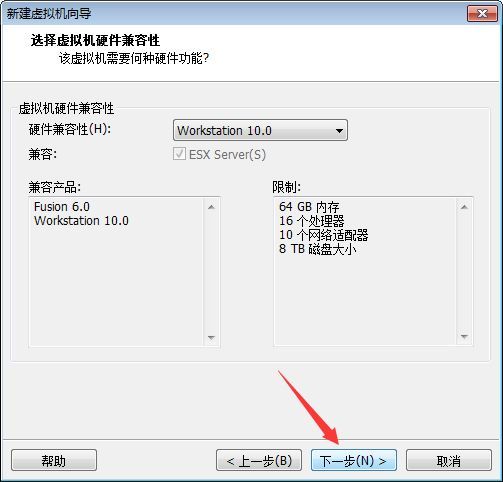
安装来源我们选择稍后安装操作系统,单击下一步
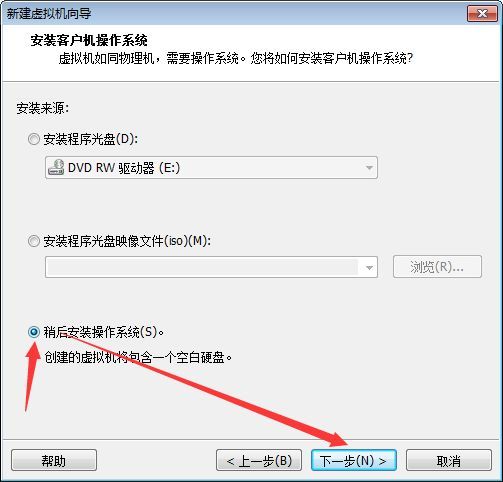
客户机操作系统我们选择Linux,版本选择Ubuntu,然后单击下一步
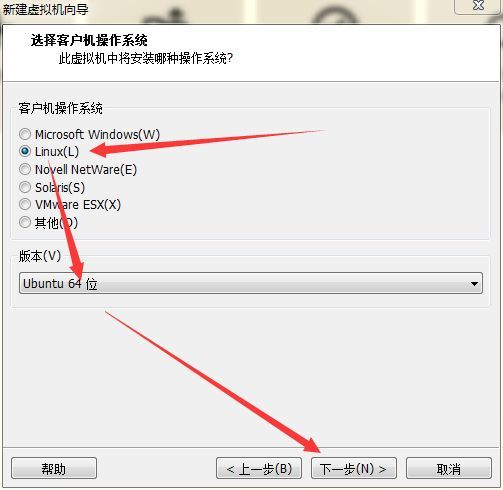
首先在D:\VM_HOME文件夹下创建新的文件夹用来存放虚拟机所有相关文件。这里文件夹名是single_node_cluster,路径为D:\VM_HOME\single_node_cluster点击浏览按钮
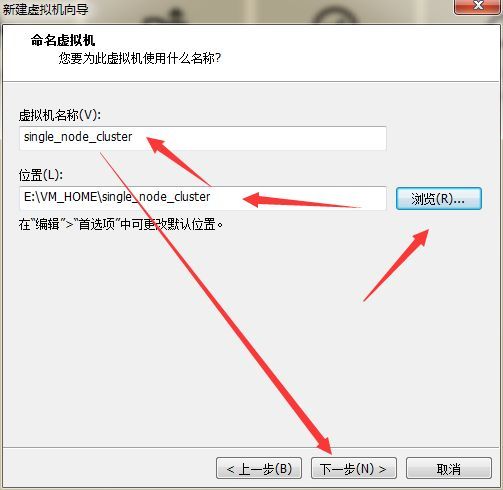
选择D:\VM_HOME\single_node_cluster目录,然后单击“确定”
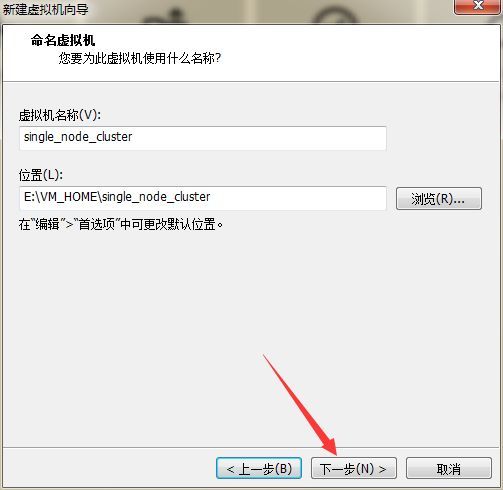
虚拟机名称(V)可以修改,原则是通俗易懂,但是尽量不出现中文及特殊字符,点击下一步继续配置
到下面这一步是要我们为虚拟机配置处理器参数,**处理器数量§**一般选1,,我使用的电脑CPU为2核4线程(可简单认为4核)每个处理器的核心数量©设为1,原因是我们的集群总共三个虚拟机,每个虚拟机分配1核需要占用3核,还有自己电脑也需要使用1核。大家可以根据自己电脑配置合理分配。配置好后单击下一步即可
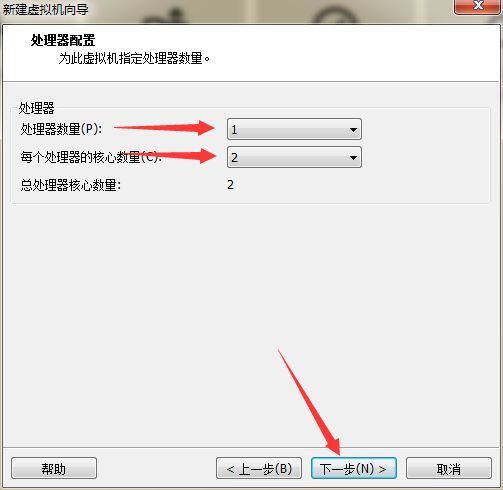
然后对虚拟机内存进行分配,8G内存电脑推荐分配1G-2G内存给虚拟机,具体数值视PC系统优化情况而定,16G内存电脑推荐分配3G-4G给虚拟机,因为Spark采用内存计算机制 ,所以内存大小对于采用Spark计算框架的Hadoop分布式集群至关重要,虚拟环境中内存越大运算速度越快。
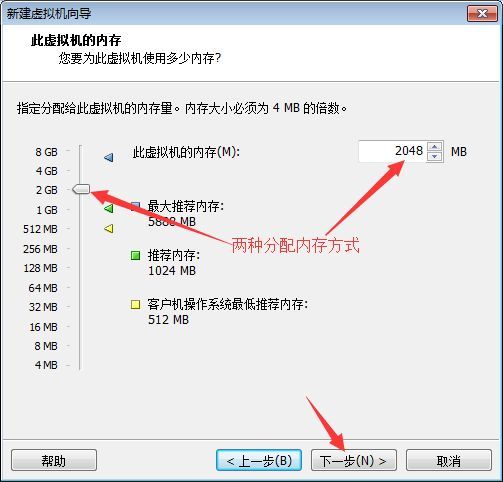
对于网络类型的选择同样需要注意,在创建新虚拟机过程中,可选择初始网络类型,此处选择NAT模式。
以下是对常用网络模式进行简单说明:
桥接模式(Bridge):桥接模式下,虚拟机将分配一个和主机外网网卡同等地位的网卡,此时虚拟机IP能够被主机路由环境下的其他机器识别;
网络地址转换模式(NAT):在网络转换模式下,虚拟机将随机分配一个功能受限的IP,虚拟机通过此IP自动与主机连接,并利用此连接进行网络连接,此时虚拟机IP是否能够被主机识别,视不同虚拟工具而定,在Virtual Box中该IP不能被主机识别,而在VMware Workstation中则能够被主机识别;
仅主机模式(Host-Only):仅主机模式下,主机中安装的所有虚拟机将和主机形成一个局域网,每个虚拟机都将分配一个可以和主机、其他虚拟机(即局域网内)相互通信的IP,但虚拟机无法利用该IP连接主机所在路由环境,即外网。
接下来对于I/O和磁盘相关设置,一般使用默认设置既可

选择创建新虚拟磁盘,单击下一步
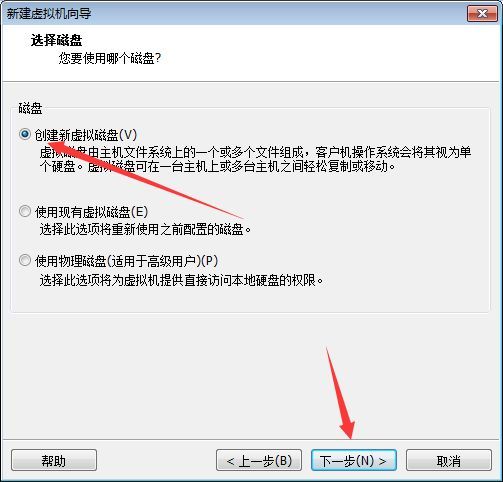
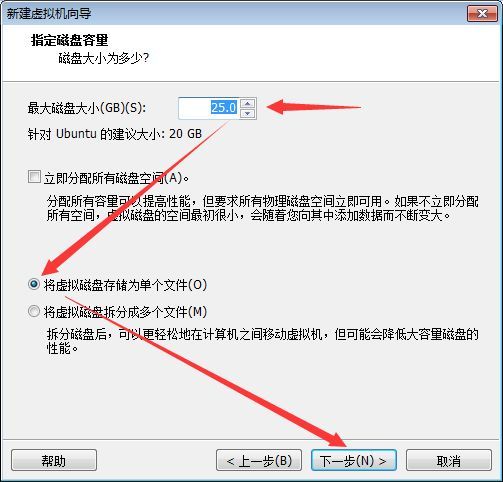
虚拟磁盘设置:最大磁盘大小设置为25G并选择将虚拟磁盘存储为单个文件,单击下一步
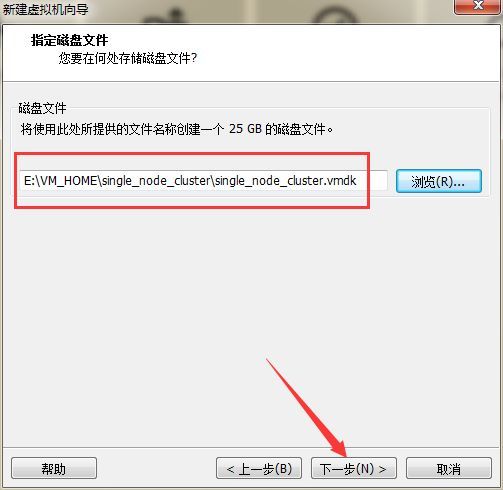
配置好虚拟磁盘参数后设置保存虚拟机磁盘文件,注意修改默认路径建议与虚拟机安装路径一致,即路径选择为“D:\VM_HOME\Ubuntu”,修改方式如下

路径选择完成后,点击保存

单击下一步继续执行
最后确认虚拟机基本信息,确认无误后点击完成。

安装完成后,会自动回到虚拟机控制台界面,在此界面中可查看虚拟机基本信息、启动虚拟机、修改虚拟机基本设置等。

今天的内容就到这里了,下篇文章就可以进行Ubuntu操作系统的安装喽。