Hadoop的安装部署(学习使用)
大数据学习的基础生态圈核心组件。本身的框架分为三个组件,HDFS、MapReduce和Yarn。对应着存储,计算和调度功能。除了计算框架MR被其他许多框架代替,HDFS和YARN在各自领域还是基石般的存在。
安装前提: 有起码3个节点 (可用虚拟机模拟)。
虚拟机模拟分布式的安装部署文档:可参考用VM虚拟机搭建大数据学习集群(3节点)_zhang5324496的博客-CSDN博客
集群的规划:
这是学习了解hadoop框架和简单练习使用命令、API操作框架。这里部署没有采用HA 架构
| 框架 | node121 | node122 | node123 |
| HDFS | NameNode,DataNode | DataNode | SecondaryNameNode、DataNode |
| YARN | NodeManager | NodeManager | NodeManager、ResourceManager |
1- 下载安装包
官网链接
Apache Hadoop
以2.9.2为例
Index of /dist/hadoop/common/hadoop-2.9.2 (apache.org)
2- 解压安装包
以下操作需要在三个节点上操作,
- 你可以使用xshell的全部回话来实现一起编辑配置文件。
- 也可以在一台机子上编辑完毕后,使用SCP拷贝到其他节点。
- 也可以使用rysnc命令
2.1- 登录node121, 创建目录存放解压hadoop
# 软件安装包存放目录
mkdir -p /opt/cluster/software
# 软件安装目录
mkdir -p /opt/cluster/server 2.2- 解压到统一的安装目录 server下
tar -zxvf hadoop-2.9.2.tar.gz -C /opt/cluster/server
2.3- 配置环境变量(方便后续操作)
编辑 /etc/profile ,添加如下内容
export HADOOP_HOME=/opt/cluster/server/hadoop-2.9.2
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbi执行 source /etc/profile, 让配置的环境变量生效
2.4- 验证hadoop
执行命令
hadoop version应该出现hadoop的版本信息

2.5- 配置 JDK路径。
因为hadoop有用java语言开发,需要配置JDK
执行命令
vi /opt/cluster/server/hadoop-2.9.2/etc/hadoop/hadoop-env.sh
## 找到 java_home,并配置为 你机子上的实际路径。我这里也是安装到 server下
export JAVA_HOME=/opt/cluster/server/jdk1.8.0_2313- HDFS集群配置
3.1- 指定 namenode 和 数据存储目录
vi /opt/cluster/server/hadoop-2.9.2/etc/hadoop/core-site.xml
<!-- 指定namenode 地址-->
fs.defaultFS
hdfs://node121:9000
hadoop.tmp.dir
/opt/cluster/server/hadoop-2.9.2/data/tmp
3.2- 指定secondarynamenode节点 和 副本数
vi /opt/cluster/server/hadoop-2.9.2/etc/hadoop/hdfs-site.xml
dfs.namenode.secondary.http-address
node123:50090
dfs.replication
3
3.3- 指定datanode的节点
在hadoop的配置目录下,新建slaves文件,内容是 datanode的节点。我这里是3个节点都安装
vi /opt/cluster/server/hadoop-2.9.2/etc/hadoop/slaves
node121
node122
node123该文件中添加的内容结尾不允许有空格,文件中不允许有空行。
4- MapReduce的集群配置
4.1- 指定MR 的JDK路径
vi /opt/cluster/server/hadoop-2.9.2/etc/hadoop/mapred-env.sh
## 找到 java_home,并配置为 你机子上的实际路径。我这里也是安装到 server下
export JAVA_HOME=/opt/cluster/server/jdk1.8.0_2314.2- 模拟生产环境,指定MR 运行在 yarn资源调度框架上
mv /opt/cluster/server/hadoop-2.9.2/etc/hadoop/mapred-site.xml.template /opt/cluster/server/hadoop-2.9.2/etc/hadoop/mapred-site.xml
vi /opt/cluster/server/hadoop-2.9.2/etc/hadoop/mapred-site.xml
mapreduce.framework.name
yarn
5- Yarn集群配置
5.1- 指定JDK路径
vi /opt/cluster/server/hadoop-2.9.2/etc/hadoop/yarn-env.sh
## 找到 java_home,并配置为 你机子上的实际路径。我这里也是安装到 server下
export JAVA_HOME=/opt/cluster/server/jdk1.8.0_2315.2- 指定 resourceManager的master地址
vi /opt/cluster/server/hadoop-2.9.2/etc/hadoop/yarn-site.xml
yarn.resourcemanager.hostname
node123
yarn.nodemanager.aux-services
mapreduce_shuffle
6- 分发到其他节点
SCP,手动修改,rysnc都可以。
7- 启动验证
7.1-- 第一次启动,需要格式化 namenode
在node121上
hadoop namenode -format7.2- 启动 HDFS
start-dfs.sh7.3- 启动yarn
start-yarn.sh8- 验证是否成功
在所有的节点上执行 jps , 看节点上有没有 相应的组件进程。比如我们这里比较特殊的是
namenode在node121
secondnamenode在 node123
resourceManager在 node123

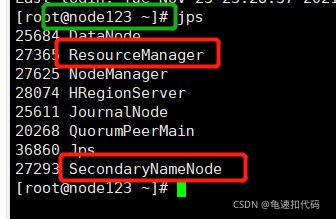
9- 如果出现个别的组件没有启动,可以到规划的节点上单独启动
比如 resourceManger没有启动,那么就去node123上执行
yarn-daemon.sh start resourcemanager yarn和 hdfs 的单独 启/停 组件的命令如下
yarn-daemon.sh start/stop resourcemanager/nodemanagerhadoop-daemon.sh start / stop namenode / datanode / secondarynamenode