Hadoop完全分布式搭建
前言:Hadoop是什么,高可靠,高扩展,高效,高容错,低成本的分布式文件存储系统
Hadoop的框架最核心的设计:HDFS和MapReduce,HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算,MapReduce底层是java走map端reduce端计算引擎
之后会更新大数据相关组件的理论和架构原理----------------------------------------------
分布式需要奇数多台节点,如果是用的自己服务器或虚拟机学习部署的话是需要每台节点配ip,之间配免密,如果是公司服务器去部署的话,服务器之间的配置甩给运维就可以了
我这里是三台节点,分别是aliyun-bigdata-01,aliyun-bigdata-02,aliyun-bigdata-03

一.下载Hadoop组件jar包上传主节点服务器,网盘去下载
涉及组件:
jdk-8u144-linux-x64.tar.gz
hadoop-2.8.5-compile-20.4.4.tar.gz
zookeeper-3.4.6.tar.gz 是实现hadoop高可用的,可以去下面文章去配置zookeeper集群FlinkCdc--Debezium实现Kafka实时监控mysql binlog日志_atguigu_Jack的博客-CSDN博客
链接:https://pan.baidu.com/s/1WZ42cwp6iacBFnCw7Lh1mA
提取码:nb01
1.安装JAVA_JDK和HADOOP因为hadoop_mapreduce计算引擎是基于java底层实现的
上传服务器解压 jdk-8u144-linux-x64.tar.gz,hadoop-2.8.5-compile-20.4.4.tar.gz,相同步骤都解压到相同目录下
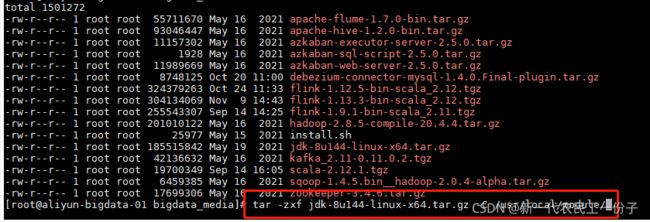
创建软连接或直接修改名称 ln -s jdk-8u144-linux-x64.tar.gz jdk 或 mv jdk-8u144-linux-x64.tar.gz jdk
然后分发后两台节点 scp -r jdk root@aliyun-bigdata-02:/usr/local/module/ scp -r jdk root@aliyun-bigdata-03:/usr/local/module/
下一步编辑环境变量 vim /etc/profile
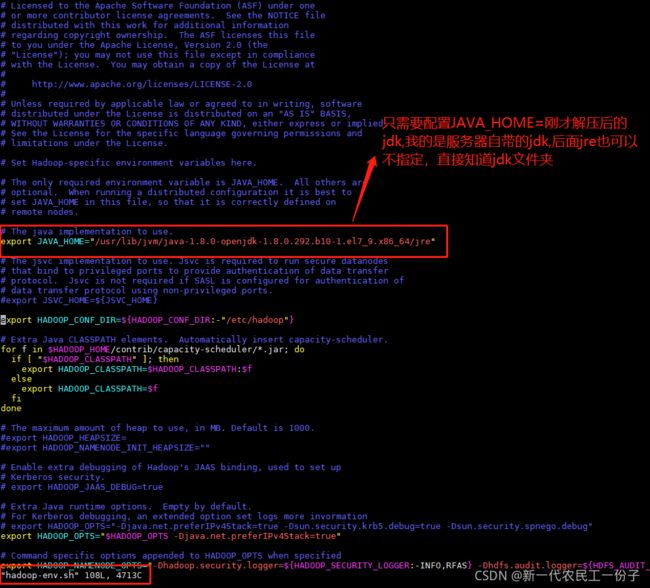
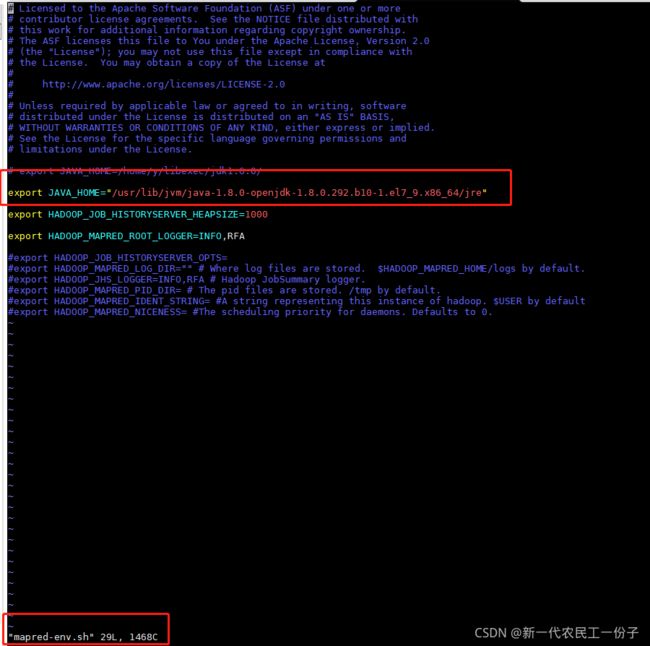
我的jdk是服务器自带的,没有用我自己装的,之所以没有编译环境变量,默认自带的jdk是有的
如果不用自带的话,export JAVA_HOME=/usr/local/module/jdk export PATH=$JAVA_HOME/bin:$PATH

配置完成退出保存,shift+zz两下保存退出,然后分发后两台节点 scp /etc/profile root@aliyun-bigdata-02:/etc/ scp /etc/profile root@aliyun-bigdata-03:/etc/
然后检查是否环境变量配置成功,每台节点先刷新环境变量 source /etc/profile 然后 java -version hadoop version 如果出现版本信息那就说明配置成功
 这个是我自带的jdk版本
这个是我自带的jdk版本
 这个是刚才安装的hadoop版本
这个是刚才安装的hadoop版本
二.配置Hadoop相关文件
1.进入hadoop/etc/hadoop

编辑hadoop-env.sh,mapred-env.sh,yarn-env.sh
编辑core-site.xml,hdfs-site.xml,mapred-site.xml,yarn-site.xml mapred-site.xml一开始是没有的,需要拷贝成新文件 命令:cp mapred-site.xml.template mapred-site.xml
配置文件里面的参数可以去 hadoop三个配置文件的参数含义说明(转) - 悟寰轩-叶秋 - 博客园 进行了解
core-site.xml
fs.defaultFS
hdfs://aliyun-bigdata-01:9000
hadoop.tmp.dir
/data/bigdata/hadoop
io.file.buffer.size
4096
fs.defaultFS 接收Client连接的RPC端口
hadoop.tmp.dir namenode,datenode,SecondaryNameNode 文件路径hdfs-site.xml
dfs.replication
3
dfs.secondary.http.address
aliyun-bigdata-01:50090
dfs.http.address
aliyun-bigdata-01:50070
dfs.namenode.name.dir
/data/bigdata/hadoop/dfs/name
dfs.datanode.data.dir
/data/bigdata/hadoop/dfs/data
dfs.webhdfs.enabled
true
dfs.permissions
false
mapred-site.xml
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
aliyun-bigdata-01:10020
mapreduce.jobhistory.webapp.address
aliyun-bigdata-01:19888
mapreduce.map.java.opts
-Xmx2048m
mapreduce.map.memory.mb
2048
mapreduce.reduce.java.opts
-Xmx4096m
mapreduce.reduce.memory.mb
4096
mapreduce.task.io.sort.mb
512
yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
aliyun-bigdata-01
yarn.resourcemanager.address
aliyun-bigdata-01:8032
yarn.resourcemanager.scheduler.address
aliyun-bigdata-01:8030
yarn.resourcemanager.resource-tracker.address
aliyun-bigdata-01:8031
yarn.resourcemanager.admin.address
aliyun-bigdata-01:8033
yarn.resourcemanager.webapp.address
aliyun-bigdata-01:8088
yarn.log-aggregation-enable
true 编辑子节点文件 vim slaves,我这里三台节点都做子节点,第一台节点即做主节点又做子节点,你们可以自己分配,编辑完退出保存

然后分发hadoop整个文件,scp -r hadoop root@aliyun-bigdata-02:/usr/local/module/ scp -r hadoop root@aliyun-bigdata-03:/usr/local/module/
2.先格式化hadooop,hadoop namenode -format 会让你输入y/n 输入y确认格式化
然后在主节点启动集群,start-all.sh,启动完成后,jps看每个节点的进程,记住不要经常格式化,只有添加修改节点之间主从关系的时候才格式化

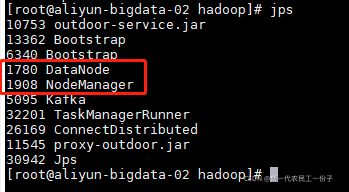
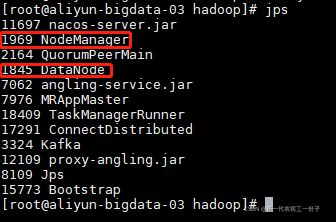
主节点五个进程,Namenode,Datenode,SecondaryNameNode,ResourceManager,NodeManager,两个从节点只有,Datenode,NodeManager
最重要的两个地方,linux系统里面 编译 vim /etc/hosts 做ip映射 Windows系统里面 C:\Windows\System32\drivers\etc\HOSTS


我这里linux系统里面配置的内网地址加服务器主机名
Windows系统里面配置的外网地址加服务器主机名
如果是自己虚拟机的话,Windows系统里面配置跟 linux系统里面配置一致就可以
然后查看网页客户端 主节点ip:50070
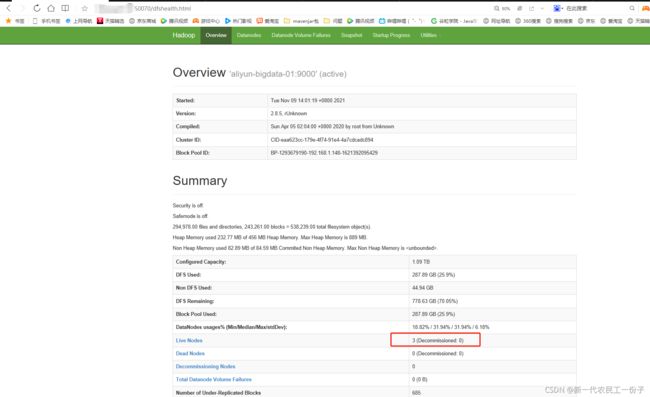

截止到这里Hadoop完全分布式搭建成功
后言:这里我把ResourceManager,SecondaryNameNode都设置到主节点了,也可以自由分配到其他节点,多台节点配置是活的,要灵活运用,我这有三台节点,之所以没必要分散,如果之后集群增加三台总共六台,这时候该你自由分配,可以有两个主节点,之后再配合zookeeper进行hadoop高可用,完美
ResourceManager参数在yarn-site.xml
yarn.resourcemanager.hostname
aliyun-bigdata-01
SecondaryNameNode参数在hdfs-site.xml
dfs.secondary.http.address
lyg-bigdata-01:50090
最后一点,如果hdfs系统里面有数据,但要增加节点修改主从关系,不要急着格式化,因为你hdfs里面有数据格式化之后就相当删库跑路了哈哈哈
每台节点找到hdfs-site.xml 先修改新的namenode,datenode数据存储目录,先把所有hadoop进程停止,然后格式化,格式化之后,看看更改的主从节点是否正确,如果没问题,再把所有hadoop进程停止,再换回来之前的目录,然后再重新启动,这时候就会发现,之前的数据还是在
dfs.namenode.name.dir
/data/bigdata/hadoop/dfs/name
dfs.datanode.data.dir
/data/bigdata/hadoop/dfs/data
say goodbay good lucky