基于flinkcdc和superset的实时大屏实践2
准备环境:
1)EMR-Flink-Cluster3.36.1(HDFS2.8.5 YARN2.8.5 Flink1.12-vvr-3.0.2)
2)Rds-Mysql 5.7.26
3)EMR-Kafka-Cluster4.9.0(Kafka_2.12-2.4.1-1.0.0 Zookeeper3.6.2)
4)Debezium-Mysql-Connector 1.2.0
5)EMR-Hadoop-Cluster4.9.0(SuperSet0.36.0)
方案理由及解决问题:
1. Flinkcdc与debezium方案对比:
前者支持:mysql5.7及以上,pgsql9.6及以上
debezium支持:mysql5.5及以上、pgsql、mongodb、oracle、sql server等多种数据源,而下游flink仅需要使用kafka一种中间数据源即可
2. 主要解决问题:
1) 对配置了SSL的EMR-Kafka集群手动添加分布式kafka-connect服务
2) 多种数据源(此文仅验证了mysql)->debezium->kafka->flinksql->mysql-superset实时大屏方案实践
3) 简单描述了kafka-connector-mysql-source的启动流程
注:
flinkcdc官网:About Flink CDC — Flink CDC 2.0.0 documentation
方案架构:

在EMR-Kafka集群中启动kafka-connect服务:
1. 使用分布式配置部署kafka-connect,选用配置文件:
/var/lib/ecm-agent/cache/ecm/service/KAFKA/2.12-2.4.1.1.1/package/templates/connect-distributed.properties
2. 更改connect-distributed.properties配置:
##
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
##
# This file contains some of the configurations for the Kafka Connect distributed worker. This file is intended
# to be used with the examples, and some settings may differ from those used in a production system, especially
# the `bootstrap.servers` and those specifying replication factors.
# A list of host/port pairs to use for establishing the initial connection to the Kafka cluster.
#bootstrap.servers={ {bootstrap_servers}}
bootstrap.servers=emr-header-1.cluster-231710:9092,emr-worker-1.cluster-231710:9092,emr-worker-2.cluster-231710:9092
# unique name for the cluster, used in forming the Connect cluster group. Note that this must not conflict with consumer group IDs
group.id=connect-cluster-stage
# The converters specify the format of data in Kafka and how to translate it into Connect data. Every Connect user will
# need to configure these based on the format they want their data in when loaded from or stored into Kafka
key.converter=org.apache.kafka.connect.json.JsonConverter
value.converter=org.apache.kafka.connect.json.JsonConverter
# Converter-specific settings can be passed in by prefixing the Converter's setting with the converter we want to apply
# it to
key.converter.schemas.enable=true
value.converter.schemas.enable=true
# Topic to use for storing offsets. This topic should have many partitions and be replicated and compacted.
# Kafka Connect will attempt to create the topic automatically when needed, but you can always manually create
# the topic before starting Kafka Connect if a specific topic configuration is needed.
# Most users will want to use the built-in default replication factor of 3 or in some cases even specify a larger value.
# Since this means there must be at least as many brokers as the maximum replication factor used, we'd like to be able
# to run this example on a single-broker cluster and so here we instead set the replication factor to 1.
offset.storage.topic=connect-offsets-stage
offset.storage.replication.factor=2
offset.storage.partitions=5
# Topic to use for storing connector and task configurations; note that this should be a single partition, highly replicated,
# and compacted topic. Kafka Connect will attempt to create the topic automatically when needed, but you can always manually create
# the topic before starting Kafka Connect if a specific topic configuration is needed.
# Most users will want to use the built-in default replication factor of 3 or in some cases even specify a larger value.
# Since this means there must be at least as many brokers as the maximum replication factor used, we'd like to be able
# to run this example on a single-broker cluster and so here we instead set the replication factor to 1.
config.storage.topic=connect-configs-stage
config.storage.replication.factor=2
# Topic to use for storing statuses. This topic can have multiple partitions and should be replicated and compacted.
# Kafka Connect will attempt to create the topic automatically when needed, but you can always manually create
# the topic before starting Kafka Connect if a specific topic configuration is needed.
# Most users will want to use the built-in default replication factor of 3 or in some cases even specify a larger value.
# Since this means there must be at least as many brokers as the maximum replication factor used, we'd like to be able
# to run this example on a single-broker cluster and so here we instead set the replication factor to 1.
status.storage.topic=connect-status-stage
status.storage.replication.factor=2
status.storage.partitions=5
# Flush much faster than normal, which is useful for testing/debugging
offset.flush.interval.ms=10000
# These are provided to inform the user about the presence of the REST host and port configs
# Hostname & Port for the REST API to listen on. If this is set, it will bind to the interface used to listen to requests.
#rest.host.name=
#rest.port=8083
# The Hostname & Port that will be given out to other workers to connect to i.e. URLs that are routable from other servers.
#rest.advertised.host.name=
#rest.advertised.port=
# Set to a list of filesystem paths separated by commas (,) to enable class loading isolation for plugins
# (connectors, converters, transformations). The list should consist of top level directories that include
# any combination of:
# a) directories immediately containing jars with plugins and their dependencies
# b) uber-jars with plugins and their dependencies
# c) directories immediately containing the package directory structure of classes of plugins and their dependencies
# Examples:
# plugin.path=/usr/local/share/java,/usr/local/share/kafka/plugins,/opt/connectors,
#plugin.path=
plugin.path=/usr/lib/kafka-current/connector-plugins
#consumer.interceptor.classes=org.apache.kafka.clients.interceptor.EMRConsumerInterceptorImpl
#producer.interceptor.classes=org.apache.kafka.clients.interceptor.EMRProducerInterceptorImpl
#metric.reporters=org.apache.kafka.clients.reporter.EMRClientMetricsReporter
#emr.metrics.reporter.bootstrap.servers={ {bootstrap_servers}}
#emr.metrics.reporter.zookeeper.connect={ {emr_metrics_reporter_zookeeper_connect}}
#producer.batch.size={ {producer_batch_size}}
#producer.send.buffer.bytes={ {producer_send_buffer_bytes}}
#producer.max.block.ms={ {producer_max_block_ms}}
#producer.request.timeout.ms={ {producer_request_timeout_ms}}
#producer.linger.ms={ {producer_linger_ms}}
#producer.max.request.size={ {producer_max_request_size}}
############################# Additional #############################
#connect-workers
security.protocol=SSL
ssl.keystore.location=/etc/ecm/kafka-conf/keystore
ssl.keystore.password=XXXXXX
ssl.truststore.location=/etc/ecm/kafka-conf/truststore
ssl.truststore.password=XXXXXX
ssl.key.password=XXXXXX
#producers with source-connectors
producer.security.protocol=SSL
producer.ssl.keystore.location=/etc/ecm/kafka-conf/keystore
producer.ssl.keystore.password=XXXXXX
producer.ssl.truststore.location=/etc/ecm/kafka-conf/truststore
producer.ssl.truststore.password=XXXXXX
producer.ssl.key.password=XXXXXX
#consumers with source-connectors
consumer.security.protocol=SSL
consumer.ssl.keystore.location=/etc/ecm/kafka-conf/keystore
consumer.ssl.keystore.password=XXXXXX
consumer.ssl.truststore.location=/etc/ecm/kafka-conf/truststore
consumer.ssl.truststore.password=XXXXXX
consumer.ssl.key.password=XXXXXX
注:
1) consumer.interceptor.classes和producer.interceptor.classes需要注释掉,因为默认kafka集群无kafka-connect module,意味着也没有kafka-connect的监控组件
2) producer.batch.size、producer.send.buffer.bytes至pro ducer.max.request.size参数也应注释掉,或者自行填充自定义参数值,理由同3
3) kafka集群已enable ssl
4) ssl配置见Additional,参考链接:Configure Confluent Platform to use TLS/SSL encryption and authentication | Confluent Documentation
3. 启动kafka-connect:
在emr-worker-1和emr-worker-2上分别执行:
/opt/apps/ecm/service/kafka/2.12-2.4.1-1.0.0/package/kafka_2.12-2.4.1-1.0.0/bin/connect-distributed.sh -daemon /var/lib/ecm-agent/cache/ecm/service/KAFKA/2.12-2.4.1.1.1/package/templates/connect-distributed.properties
注:
1) 调试过程中日志打印位置是:
/opt/apps/ecm/service/kafka/2.12-2.4.1-1.0.0/package/kafka_2.12-2.4.1-1.0.0/logs/connect.log
2) 启动成功打印日志为:
[2021-09-09 16:50:43,023] INFO [Worker clientId=connect-1, groupId=connect-cluster-stage] Session key updated (org.apache.kafka.connect.runtime.distributed.DistributedHerder:1440)
3) kafka集群中会出现3个topic
connect-configs-stage
connect-offsets-stage
connect-status-stage
启动mysql-source-connector抓取mysql变更数据到kafka:
1. Curl方式启动connector:
使用命令:
curl -H "Content-Type: application/json" -X POST -d '{
"name" : "kafka_connector_users-connector-12",
"config" : {
"connector.class" : "io.debezium.connector.mysql.MySqlConnector",
"database.hostname" : "rm-ufXXXXXXlt6q.mysql.rds.aliyuncs.com",
"database.port" : "3306",
"database.user" : "dhour_latest",
"database.password" : "XXXXXX",
"database.server.id" : "184062",
"database.server.name" : "stage.flinkcdc_test",
"database.whitelist" : "z_flinkcdc_test",
"table.whitelist": "z_flinkcdc_test.kafka_connect_users",
"database.history.kafka.bootstrap.servers":"emr-header-1.cluster-231710:9092,emr-worker-1.cluster-231710:9092,emr-worker-2.cluster-231710:9092",
"database.history.kafka.topic":"dbhistory.kafka_connect_users",
"database.history.producer.security.protocol": "SSL",
"database.history.producer.ssl.keystore.location": "/etc/ecm/kafka-conf/keystore",
"database.history.producer.ssl.keystore.password": "XXXXXX",
"database.history.producer.ssl.truststore.location": "/etc/ecm/kafka-conf/truststore",
"database.history.producer.ssl.truststore.password": "XXXXXX",
"database.history.producer.ssl.key.password": "XXXXXX",
"database.history.consumer.security.protocol":"SSL",
"database.history.consumer.ssl.keystore.location":"/etc/ecm/kafka-conf/keystore",
"database.history.consumer.ssl.keystore.password":"XXXXXX",
"database.history.consumer.ssl.truststore.location":"/etc/ecm/kafka-conf/truststore",
"database.history.consumer.ssl.truststore.password":"XXXXXX",
"database.history.consumer.ssl.key.password":"XXXXXX"
}
}' http://emr-worker-2.cluster-231710:8083/connectors
查看所有connector:
curl -get emr-worker-2:8083/connectors
查看状态:
curl -get emr-worker-2:8083/connectors/kafka_connector_users-connector-12/status
[root@emr-worker-2 logs]# {"name":"kafka_connector_users-connector-12","connector":{"state":"RUNNING","worker_id":"xxxxxx:8083"},"tasks":[{"id":0,"state":"RUNNING","worker_id":"xxxxxx:8083"}],"type":"source"}
出现异常状态时查看日志,日志位置:
/opt/apps/ecm/service/kafka/2.12-2.4.1-1.0.0/package/kafka_2.12-2.4.1-1.0.0/logs/connect.log
2. connector启动流程:
1) 开始启动Connector和task:
[2021-09-09 16:51:01,223] INFO [Worker clientId=connect-1, groupId=connect-cluster-stage] Starting connectors and tasks using config offset 17 (org.apache.kafka.connect.runtime.distributed.DistributedHerder:1104)
[2021-09-09 16:51:01,223] INFO [Worker clientId=connect-1, groupId=connect-cluster-stage] Starting task kafka_connector_users-connector-12-0 (org.apache.kafka.connect.runtime.distributed.DistributedHerder:1139)
[2021-09-09 16:51:01,224] INFO Creating task kafka_connector_users-connector-12-0 (org.apache.kafka.connect.runtime.Worker:419)
2) Connector和task启动成功:
[2021-09-09 16:51:01,225] INFO Instantiated task kafka_connector_users-connector-12-0 with version 1.2.0.Final of type io.debezium.connector.mysql.MySqlConnectorTask (org.apache.kafka.connect.runtime.Worker:434)
[2021-09-09 16:51:01,235] INFO Starting MySqlConnectorTask with configuration: (io.debezium.connector.common.BaseSourceTask:95)
[2021-09-09 16:51:01,235] INFO [Worker clientId=connect-1, groupId=connect-cluster-stage] Finished starting connectors and tasks (org.apache.kafka.connect.runtime.distributed.DistributedHerder:1125)
3) 开始快照:
[2021-09-09 16:51:01,627] INFO Found no existing offset, so preparing to perform a snapshot (io.debezium.connector.mysql.MySqlConnectorTask:169)
[2021-09-09 16:51:00,239] INFO Creating thread debezium-mysqlconnector-stage.flinkcdc_test-snapshot (io.debezium.util.Threads:287)
[2021-09-09 16:51:00,240] INFO Starting snapshot for jdbc:mysql://
[2021-09-09 16:51:01,637] INFO MySQL server variables related to change data capture: (io.debezium.connector.mysql.SnapshotReader:969)
[2021-09-09 16:51:00,252] INFO Step 0: disabling autocommit, enabling repeatable read transactions, and setting lock wait timeout to 10 (io.debezium.connector.mysql.SnapshotReader:278)
[2021-09-09 16:51:00,256] INFO Step 1: flush and obtain global read lock to prevent writes to database (io.debezium.connector.mysql.SnapshotReader:312)
[2021-09-09 16:51:00,266] INFO Step 2: start transaction with consistent snapshot (io.debezium.connector.mysql.SnapshotReader:337)
[2021-09-09 16:51:00,267] INFO Step 3: read binlog position of MySQL master (io.debezium.connector.mysql.SnapshotReader:883)
[2021-09-09 16:51:00,269] INFO Step 4: read list of available databases (io.debezium.connector.mysql.SnapshotReader:362)
[2021-09-09 16:51:00,271] INFO Step 5: read list of available tables in each database (io.debezium.connector.mysql.SnapshotReader:381)
[2021-09-09 16:51:00,423] INFO Step 6: generating DROP and CREATE statements to reflect current database schemas: (io.debezium.connector.mysql.SnapshotReader:487)
3) 释放锁并结束快照:
[2021-09-09 16:51:09,461] INFO Step 7: releasing global read lock to enable MySQL writes (io.debezium.connector.mysql.SnapshotReader:557)
[2021-09-09 16:51:09,463] INFO Step 7: blocked writes to MySQL for a total of 00:00:07.811 (io.debezium.connector.mysql.SnapshotReader:563)
[2021-09-09 16:51:09,464] INFO Step 8: scanning contents of 1 tables while still in transaction (io.debezium.connector.mysql.SnapshotReader:580)
[2021-09-09 16:51:09,467] INFO Step 8: - scanning table 'z_flinkcdc_test.kafka_connect_users' (1 of 1 tables) (io.debezium.connector.mysql.SnapshotReader:631)
[2021-09-09 16:51:09,467] INFO For table 'z_flinkcdc_test.kafka_connect_users' using select statement: 'SELECT * FROM `z_flinkcdc_test`.`kafka_connect_users`' (io.debezium.connector.mysql.SnapshotReader:636)
[2021-09-09 16:51:09,471] INFO Step 8: - Completed scanning a total of 6 rows from table 'z_flinkcdc_test.kafka_connect_users' after 00:00:00.004 (io.debezium.connector.mysql.SnapshotReader:672)
[2021-09-09 16:51:09,472] INFO Step 8: scanned 6 rows in 1 tables in 00:00:00.008 (io.debezium.connector.mysql.SnapshotReader:709)
[2021-09-09 16:51:09,472] INFO Step 9: committing transaction (io.debezium.connector.mysql.SnapshotReader:746)
[2021-09-09 16:51:09,473] INFO Completed snapshot in 00:00:07.84 (io.debezium.connector.mysql.SnapshotReader:825)
4)启动debezium-mysqlconnector客户端进程:
[2021-09-09 16:51:09,789] INFO Creating thread debezium-mysqlconnector-stage.flinkcdc_test-binlog-client (io.debezium.util.Threads:287)
[2021-09-09 16:51:09,793] INFO Creating thread debezium-mysqlconnector-stage.flinkcdc_test-binlog-client (io.debezium.util.Threads:287)
[2021-09-09 16:51:09,803] INFO Connected to MySQL binlog at rm-ufxxxlt6q.mysql.rds.aliyuncs.com:3306, starting at GTIDs 98aeeee4-c893xxx16b84:1-703448,98exxxd30ab8a40e:1-1412791,d1b035edxxx599f373e7c:1-5183351,f5149a22-cfe9-xxxf8a00:24-110 and binlog file 'mysql-bin.002194', pos=890486, skipping 0 events plus 0 rows (io.debezium.connector.mysql.BinlogReader:1111)
[2021-09-09 16:51:09,804] INFO Waiting for keepalive thread to start (io.debezium.connector.mysql.BinlogReader:412)
[2021-09-09 16:51:09,804] INFO Creating thread debezium-mysqlconnector-stage.flinkcdc_test-binlog-client (io.debezium.util.Threads:287)
[2021-09-09 16:51:09,904] INFO Keepalive thread is running (io.debezium.connector.mysql.BinlogReader:419)
3. 查看对应kafka主题是否创建成功:
dbhistory.kafka_connect_users
stage.flinkcdc_test
stage.flinkcdc_test.z_flinkcdc_test.kafka_connect_users
注:
stage.flinkcdc_test.z_flinkcdc_test.kafka_connect_users是存放变更数据的topic
4. 查看变更数据是否被捕获到:
变更mysql-sourc表:

查看topic数据:

使用flink-sql对mysql-source数据做统计输出至mysql:
1. 使用到的jar包:
# for mysql-sink
flink-connector-jdbc_2.11-1.12.0.jar
mysql-connector-java-8.0.16.jar
# for kafka-source
flink-sql-connector-kafka_2.11-1.12.3.jar
2. 启动flink sql-client
1) 启动yarn-session cluster
/opt/apps/ecm/service/flink/1.12-vvr-3.0.2/package/flink-1.12-vvr-3.0.2/bin/yarn-session.sh -s 2 -jm 1024 -tm 2048 -nm for_sqlcdc -d
2) 启动sql-client
sql-client.sh embedded -s yarn-session -j lib/flink-connector-jdbc_2.11-1.12.0.jar -j lib/mysql-connector-java-8.0.16.jar -j lib/flink-sql-connector-kafka_2.11-1.12.3.jar
3. 建表语句参考:
1) mysql-source:
kafka_connect_users:
CREATE TABLE `kafka_connect_users` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`name` varchar(20) DEFAULT NULL,
`birthday` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
`ts` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=15 DEFAULT CHARSET=utf8
2) mysql-sink:
CREATE TABLE `kafka_connect_user_cnt` (
`cnt` bigint(20) NOT NULL,
`ts` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP
) ENGINE=InnoDB DEFAULT CHARSET=utf8
3) flink-sql之kafka-source:
CREATE TABLE kafka_connect_users (
`id` INT PRIMARY KEY NOT ENFORCED,
`name` STRING,
`birthday` STRING,
`ts` STRING
) WITH (
'connector' = 'kafka',
'topic' = 'stage.flinkcdc_test.z_flinkcdc_test.kafka_connect_users',
'properties.bootstrap.servers' = 'emr-header-1.cluster-231710:9092,emr-worker-1.cluster-231710:9092,emr-worker-2.cluster-231710:9092',
'properties.group.id' = 'stage.z_flinkcdc_test.kafka_connector_users.test',
'properties.security.protocol' = 'SSL',
'properties.ssl.truststore.location' = '/etc/ecm/kafka-conf/stage/truststore',
'properties.ssl.truststore.password' = 'XXXXXX',
'properties.ssl.keystore.location' = '/etc/ecm/kafka-conf/stage/keystore',
'properties.ssl.keystore.password' = 'XXXXXX',
'scan.startup.mode' = 'earliest-offset',
'value.format' = 'debezium-json',
'value.debezium-json.schema-include' = 'true',
'sink.semantic' = 'exactly-once'
);
注:
因为kafka-connect服务配置我们开启了value.converter.schemas.enable=true,故要解读update消息需新增配置'value.debezium-json.schema-include' = 'true',详见:
Apache Flink 1.12 Documentation: Debezium Format
4) flink-sql之mysql-sink:
CREATE TABLE kafka_connect_user_cnt (
cnt BIGINT PRIMARY KEY NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://rm-ufxxxlt6q.mysql.rds.aliyuncs.com:3306/z_flinkcdc_test?useSSL=false&autoReconnect=true',
'driver' = 'com.mysql.cj.jdbc.Driver',
'table-name' = 'kafka_connect_user_cnt',
'username' = 'dhour_latest',
'password' = 'xxxxxx',
'lookup.cache.max-rows' = '3000',
'lookup.cache.ttl' = '10s',
'lookup.max-retries' = '3'
);
5) flink-sql之sql-transform:
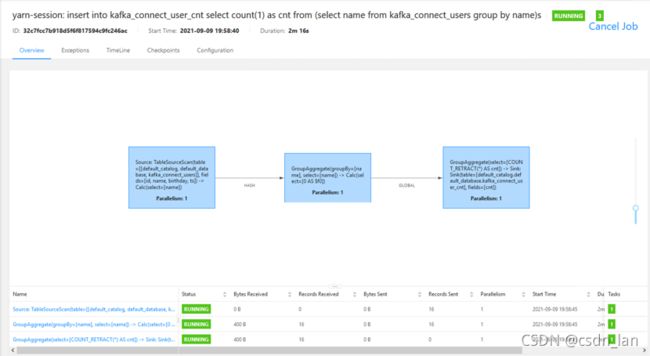
insert into kafka_connect_user_cnt select count(1) as cnt from (select name from kafka_connect_users group by name)s
4. 任务启动并验证数据准确性:
1) flink sql同步任务启动:
2) 新增数据至mysql-source:

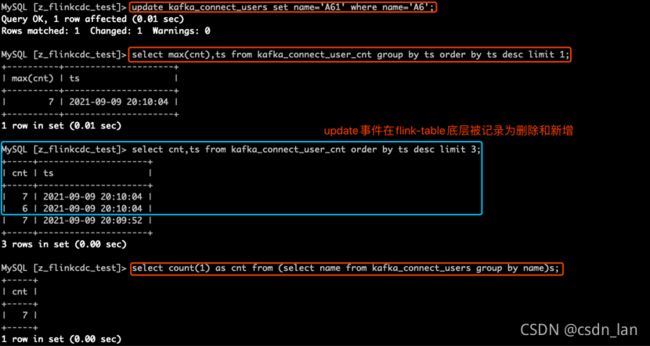
3) 更改数据:
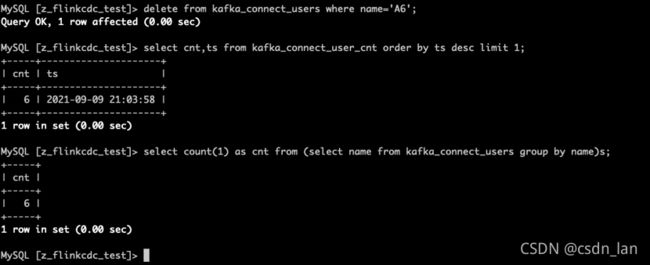
4) 删除数据:
使用SuperSet对sink-mysql中结果数据进行可视化:
可视化部分同《flinkcdc实时大屏实践》,不再赘述
附件:
1. debezium-connector-mysql-1.2.0.Final-plugin.tar.gz
2. flink-connector-jdbc_2.11-1.12.0.jar
3. mysql-connector-java-8.0.16.jar
4. flink-sql-connector-kafka_2.11-1.12.3.jar
5. 下载链接:
链接: 百度网盘 请输入提取码
密码: 3w9s