mysql和jdbc(韩)
mysql和jdbc(韩)
Mysql
mysql数据库的安装和配置
SQLyog的安装和使用
快速注释 :ctrl + shift + c
取消注释:ctrl + shift + r
数据库 表的本质仍然是文件
数据库三层结构
- 所谓安装Mysql数据库,就是在主机安装一个数据库管理系统(DBMS),这个管理程序可以管理多个数据库
- 一个数据中可以创建多个表,已保存数据
- 数据库管理系统、数据库、表的关系如图所示
端口是什么:
一个程序的身份证号,具有唯一性
sql、DB、DBMS分别是什么,它们之间有什么关系?
DB:
DataBase(数据库,数据库实际上在硬盘上以文件的形式存在)
DBMS:
DataBase Management System(数据库管理系统,常见的有:MySQL,Oracle,DB2,Sybase,SqlServer…)
SQL:
结构化查询语言,是一门标准通用的语言,标准的sql适合于所有的数据产品。
SQL属于高级语言,只要能看懂英语单词的,写出来的sql语句,可以读懂什么意思
SQL语句在执行的时候,实际上内部也会先进行编译,然后再执行sql
DBMS负责执行sql语句,通过执行sql语句来操作DB当中的数据
DBMS-(执行)-> SQL -(操作)->DB
什么是表?
表:table
表:table是数据库的基本组成单元,所有的数据都以表格的形式组织,目的是可读性强
一个表包括行和列:
行:被称为数据/记录(data)
列:被称为字段(column)
每一个字段应该包含那些属性?
字段名,数据类型,相关的约束
SQL语句的分类
学习MySQL主要还是学习通用的SQL语句,那么SQL语句也包括增删改查,SQL语句应该怎么分类呢?
DQL(数据查询语言):查询语句,凡是select语句都是DQL
DML(数据操作语言):insert,delete,update,对表中的数据进行增删改
DDL(数据定义语言):create,drop,alter,对表结构的增删改
TCL(事务控制语言):commit提交事务,rollback回滚事务
DCL(数据控制语言):grant授权,revoke撤销权限等
创建数据库
- CHARACTER SET:指定数据库采用的字符集,如果不指定字符集,默认utf8
- COLLATE:指定数据库字符集的效对规则(常用的utf8_bin(区分大小写)、utf8_general_ci(不区分大小写:默认))
- 创建数据库不用指定 存储引擎 ,创建表时才需要
//使用指令创建数据库
create database hsp_db01;
//删除数据库
drop database hsp_db01;
//创建一个使用utf8字符集的hsp_db02数据库
create database hsp_db02 character set utf8;
//创建要给使用utf8字符集,并带效对规则的hsp_db03数据库
create database hsp_db03 character set utf8 collate utf8_general_ci;
查看、删除数据库
//查看有哪些数据库
show databases;
//显示数据库创建语句
show create database 数据库名;
//删除数据库语句(一定要慎用)
drop database [if exists] 数据库名;
说明:在创建数据库,表的时候,为了规避关键字,可以使用反引号解决,反引号是 左上角 和 波浪线 一起的哪个
create database `create`;
#查看数据库有哪些表,需要注意的是,该指令需要进入数据库后才有效
SHOW TABLES;
备份和恢复数据库
//备份数据库(注意:在DOS执行)命令行
mysqldump -u 用户名 -p -B 数据库1 数据库2 数据库n > 文件名.sql
//恢复数据库(注意:进入Mysql命令行在执行)
Source 文件名.sql
//备份数据库中的表
mysqldump -u 用户名 -p 数据库 表1 表2 表n > 文件名.sql
//备份数据库中的表
//首先要进入要恢复的数据库
use test
//然后再执行
Source 文件名.sql
创建表
create table table_name(
field1 datatype,
field2 datatype,
field3 datatype
)character set 字符集 collate 校对规则 engine 引擎
field:指定列名 datatype:指定列类型(字段类型)
character set:如不指定则为所在数据库字符集
collate:如不指定则为所在数据库校对规则
engine:引擎
创建外键语法:foreign key(本表字段名) references 主表名(主表字段名),写在字段最后面
常见的数据类型

其中经常使用的是
- int(四个字节)
- double(双精度,8个字节)
- decimal[M,D](大小不确定)
- 可以支持更加精确的小数位,M 是小数位数(精度)的总数,D 是小数点(标度)后面的位数
- 如果 D 是 0 ,则没有小数点,M 最大是65位,D最大是30位,如果D被省略,默认是0 ,如果M被省略,默认是10
- 建议:如果希望小数的精度高,推荐使用decimal
- char(0-255)(255字符)
- varchar(0-65535)(2^16-1)(65535表示的字节,不是字符,具体的大小会根据字符集改变)
- utf8编码最大字符数21844(65535-3)/3
- gbk编码最大字符数32766
- char(4)//这里的 4 表示 字符数,不管中文还是字母都是 4 个,表示定长,也就是说,即使你插入"aa",没有四个字符,也会占用分配的4个字符的空间
- varchar(4)//这里 4 表示字符数 ,不管字母还是中文都以定义好的表的编码来存放数据,表示变长,就是说,如果你插入了"aa",实际占用空间大小并不是4个字符,而是按照实际占用空间来分配(varchar 本身还需要占用1-3个字节来记录存放内容长度)(实际数据大小+ (1-3)个字节)
- 这里的 4 表示 最大的字符数
- 如果数据是定长的,推荐使用char,比如 手机号等等
- 如果说一个字段的长度是不确定的,推荐使用varchar
- text(0-65535)(2^16-1)
- datetime(年月日时分秒)
- timestamp(时间戳),如果想要让该列自动的更新时间,再创建表的时候需要在 timestamp 后面加上 not null default current_timestamp on update current_timestamp
指定数据类型是 无符号的 :
create table t1(
id tinyint unsigned
);
//载数据类型后面加上一个 unsigned 表示无符号的数据,不加表示有符号的数据
CREATE TABLE `emp`(
id INT,
`name` VARCHAR(10),
sex CHAR(1),
brithday DATE,
entry_date DATE,
job VARCHAR(20),
salary FLOAT,
`resume` TEXT
)CHARACTER SET utf8 COLLATE utf8_bin ENGINE INNODB;
#utf8_general_ci
INSERT INTO `emp` VALUES(100,'小妖怪','男','2020-11-23','2020-11-23 11:11:11','巡山',3000,'大王叫我来巡山');
#使用枚举,来定义性别,这个是有效的
sex enum('男','女')) not null,
#设置某列自增长,从1开始自动的增加,存数据该列的内容可以填 null,也可以不填
create table t(
id int primary key auto_increment
)
#自增长需要配合(primary key 或者 unique 使用)
#自增长默认从1开始,也可以通过如下命令修改
alter table 表名 auto_increment = 新的开始值;
#如果你添加数据时,给自增长字段指定的有值,则以指定的值为准,如果制定了自增长,一般来说,就按照自增长的规则来添加数据
删除和修改表
使用 ALTER TABLE 语句追加,修改,删除列的语法
#添加列,after 表示在哪个列后面
alter table tablename add 列名 datatype default ecpr after 列名;
ALTER TABLE emp ADD image VARCHAR(32) NOT NULL DEFAULT '' AFTER RESUME;
#修改列
alter table tablename modify 列名 datarype default expr;
ALTER TABLE emp MODIFY job VARCHAR(64) NOT NULL DEFAULT '';
#删除列
alter table tablename drop column 列名;
ALTER TABLE employee DROP COLUMN sex;
#查看表的结构,可以查看表所有的列
desc 表名;
#修改表名
rename table 原表名 to 新表名;
RENAME TABLE emp TO employee;
#修改字符集
alter table 表名 character set 字符集;
ALTER TABLE employee CHARACTER SET utf8;
#修改列名,不能只写到 修改后列名 那里,后面的 数据类型 也要写,至于后面的不为空,默认,可写可不写
alter table employee change 原列名 修改后列名 varchar(64) not null default '';
ALTER TABLE employee CHANGE `name` emp_name VARCHAR(64) NOT NULL DEFAULT '';
CRUD
insert 表中插入数据
insert into 表名(列名1,列名2,列名3...) values(数据1,数据2,数据3...)
细节说明
-
插入的数应与字段的数据类型相同
insert into emp(id,name,price) values('30','小米手机',2000); #虽然说这里的 30 用单引号了,但是mysql 的底层会尝试将该字符串 转换为 数字,如果可以转换,则该语句 没有问题,可以正常存储 -
数据的长度应在列的规定范围内
-
在values中列出的数据位置必须与被假如的列的排列位置像对应
-
字符和日期型数据 应包含在 单引号 中
-
列可以插入空值,前提是该字段允许为空
-
如果是给表中的所有字段添加数据,可以不写前面的字段名称
-
默认值的使用,当不给某个字段值时,如果有默认值就会添加,否则报错
-
insert into 表名(列名1,列名2,列名3…) values(数据1,数据2,数据3…),(数据1,数据2,数据3…),(数据1,数据2,数据3…) 这个形式可以依次添加多条记录
update修改表中数据
update tablename set 字段名1=值1,字段名2=值2 where []
#如果where条件没有写的话,会修改表中所有的值
使用细节
- update 语句可以用新值更新原有表行中的各列
- set 子句指示要修改那些列和要给与那些值
- where 子句指定应更新那些行,如没有where子句,则更新所有的行
- 如果需要修改多个字段,可以通过 set 字段1 = 值1,字段2=值2…
delete删除表中数据
delete from tablename where [];
使用细节
- 如果没有写where 条件语句,会将表中所有数据删除
- delete 语句不能删除某一列的值
- 使用 delete 语句仅删除记录,不删除表本身,如要删除表,使用drop table 语句
select查询表中数据
简单的查询语句:(DQL)
语法格式:
select [distinct] 字段名1,字段名2... from 表名;
- distinct 表示不显示重复的数据
- *号表示查询所有列
提示:
任何一条sql语句以“;”结尾。
sql语句不区分大小写。
select ENAME from emp;
给查询结果的列重命名?
select ename,sal * 12 as yearsal from emp;
别名当中有中文?
select ename,sal*12 as ‘年薪’ from emp;
注意:标准sql语句中要求字符串使用单引号括起来,虽然mysql支持双引号,尽量别用
起别名的时候,as关键字可以省略,使用空格
查询全部字段?
select * from emp;实际开发中不建议使用*效率太低。
可以使用表达式对查询的列进行计算
select name ,(chinese + english + math) as count from student;
单表查询
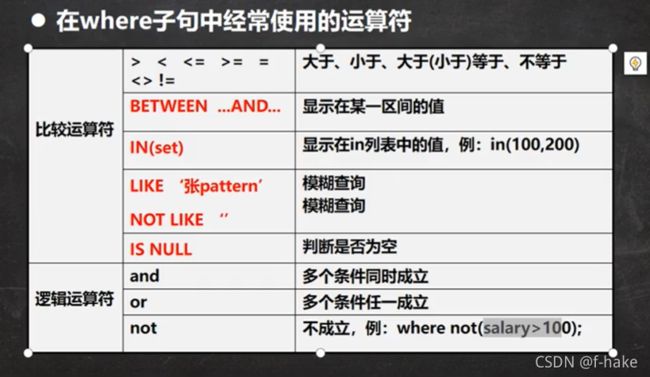
条件查询
语法格式:
select 字段,字段…from 表名 where 条件;
执行顺序:先from,然后where,最后select
查询工资等于5000的员工姓名?
select ename from emp where sal = 5000;
找出工资不等于3000
select ename,sal from emp where sal <>3000;
select ename,sal from emp where sal !=3000;
找出工资再1000和3000之间的工资,包括1000,3000
select ename,sal from enp where sal>=1000 and sal<=3000;
select ename,sal from emp where sal between 1000 and 3000;[1000,3000]必须左小右大
空不是一个值,不能用等号衡量,必须使用is null或者is not null
select ename,sal,comm from emp where comm is null;
找出那些人没有津贴?
select ename,sal,comm from emp where comm is null or comm = 0;
or表示或者
and和or联合起来用:找出薪资大于1000的并且部门编号是20或者是30部门的员工
select ename,sal,deptno from emp where sal >=100 and (deptno = 20 or deptno = 30);
注意:当运算符的优先级不确定的时候加小括号
in等同于or:找出工作岗位是MANAGER和SALESMAN的员工?
select ename,job from emp where job = ‘SALESMAN’ or job = ‘MANAGER’;
select ename,job from emp where job in(‘MANAGER’,‘SALESMAN’);
select ename,job from emp where sal in(1000,5000’);找出工资是1000或者5000的,不是表示一段区间
not in:不在这个值的
not between…and
模糊查询like?
找出名字当中含有o的?(必须掌握两个特殊的符号,一个是%,一个是_,%代表任意多个字符,__代表任意1个字符)
select ename from emp where ename like ‘%o%’;
找出第二个字母是A的
select ename from emp where ename like ‘_A%’;
找出名字中有下划线的
select ename from emp where ename like ‘%\_%’;\具有转义作用
排序
按照工资升序排
select ename,sal from emp order by sal;默认升序,asc表示升序,desc表示降序
select ename,sal from emp order by sal asc;
select ename,sal from emp order by sal desc;
按照工资的降序排列,当工资相同的时候再按照名字的升序排列
select ename,sal from emp order by sal desc , ename asc;中间用逗号隔开,多个字段同时排序,越靠前的起的主导作用越大
找出工作岗位是SALESMAN的员工,并且要求按照薪资的降序排列
select ename,job,sal from emp where job = ‘SALESMAN’ order by sal desc;
from–>where–>select–>order by
分组函数
count 计数
- count(*) 统计有多少行记录
- count(列名) 统计该列下,不为空的行记录
sum 求和,只对 数值 有效
avg 平均值,只对 数值 有效
max 最大值,只对 数值 有效
min 最小值,只对 数值 有效
所有的分组函数都是对“某一组”数据进行操作的
找出工资总和
select sum(sal) from emp;
找出总人数
select count(主键) from emp;
分组函数一共五个,又称:多行处理函数,特点,输入多行,输出一行
分组函数自动忽略null;
所有数据库都是这样规定的,只要有null参与运算,结果都是null
ifnull() 空处理函数
ifnull(可能为NULL的数据,被当作什么处理)
找出高于平均工资的员工
select ename from emp where sal > (select avg(sal) from emp);
分组函数不能直接直接出现在where子句中,因为group by是在where执行之后才会执行的,而(分组函数)又是在group by之后执行的,没有分组哪来的分组函数。
count(*)记录总数
count(某个具体的字段)记录不为空的总数
group by:按照某个字段或者某些字段进行分组
having:having是对分组之后的数据进行再次的过滤
案例:找出某个工作岗位的最高工资
select job,max(sal) from emp group by job;
当出现group by时,select后面只能出现分组函数和分组的字段
注意分组函数一般都会和group by 联合使用,这也是为什么它被称为分组函数的原因
并且任何一个分组函数(count,sum,man,min,avg)都是在group by 执行完毕之后才会执行的
当一条语句中没有group by的话,整张表的数据会自成一组
执行顺序
//执行顺序
select 5
...
from 1
...
where 2
...
group by 3
...
having 4
...
order by 6
...
limit 7
找出每个部门不同工作岗位的最高薪资
SELECT deptno,job,MAX(sal) FROM emp GROUP BY deptno , job ORDER BY deptno;
先分部门,在分岗位
找出每个部门的最高薪资,要求显示薪资大于2500的数据
SELECT deptno,MAX(sal) FROM emp GROUP BY deptno HAVING MAX(sal) > 2500 ORDER BY deptno;这种方式效率较低
SELECT deptno,MAX(sal) FROM emp WHERE sal > 2500 GROUP BY deptno ORDER BY deptno;先过滤再分组
找出每个部门的平均薪资,要求显示薪资大于2000的数据
SELECT deptno,AVG(sal) FROM emp GROUP BY deptno HAVING AVG(sal) > 2000 ORDER BY deptno;
select
...
from
...
where
...
group by
...
having
...
order by
...
limit
...
顺序不能改
关于查询结果集的去重
select distinct job from emp;
distinct只能出现在所有字段的最前面
字符串相关函数
| charset(str) | 返回字串字符集 |
|---|---|
| concat(string [,…]) | 连接字串 |
| instr(string,substrnig) | 返回substring在string中出现的位置,没有返回0 |
| ucase(string) | 转换成大写 |
| lcase(string) | 转换成小写 |
| left(string,length) | 从string中的左边起取length个字符 |
| length(string) | 返回string的长度 |
| replace(str,search_str,replace_str) | 在str中用replace_str替换search_str |
| strcmp(string1,string2) | 逐字符比较两字串大小 |
| substring(str,position,[length]) | 从str的position开始[从1开始计算],取length个字符 |
| ltrim(string) rtrim(string) trim | 去除前端空格或后端空格或者全部前后空格 |
#连接字符串,concat(ename,' 工作是 ',job)当作一列输出
select concat(ename,' 工作是 ',job) from emp;
#查看字符串出现的位置
select instr('hsp','p') from dual;
#将字符串都转换为大写
select ucase(ename) from emp;
#将字符串都转换为小写
select lcase(ename) from emp;
#从字符串左边起取length个字符
select left(ename,2) from emp;
#从字符串右边起取length个字符
select right(ename,2) from emp;
#返回字符串长度(按照字节返回)
select length(ename) from emp;
#将字符串都转换为大写
select ucase(ename) from emp;
#字符串替换,用smith替换mark
select replace(ename,'smith','mark') from emp;
#从字符串第一个位置开始取length个字符
select substring(ename,1,2) from emp;
#去除空格
select ltrim(' hsp') from dual;
#以首字母小写的方式显示所有员工表的姓名
SELECT REPLACE(`name`,LCASE(LEFT(`name`,1)),LEFT(`name`,1) FROM emp;
SELECT CONCAT(LCASE(LEFT(`name`,1),SUBSTRING(`name`,2)) FROM emp;
数学相关函数
| abs(num) | 绝对值 |
|---|---|
| bin(decimal_number) | 十进制换二进制 |
| ceiling(number) | 向上取整,得到比num2大的最小整数 |
| conv(number,from_base,to_base) | 进制转换 |
| floor(number) | 向下取整,得到比num小的最大整数 |
| format(number,decimal_places) | 保留小数位数 |
| hex(decimalNumber) | 转十六进制 |
| least(number1,numer2,[…]) | 求最小值 |
| mod(numerator,denominator) | 求余 |
| rand([seed]) | rand([seed])其范围为0= |
rand()返回一个随机浮点值 v ,范围在0 到 1 之间(即,其范围为0=< v =< 1.0)。若以指定一个整数N,则它被用作种子值,用来产生重复序列
#取绝对值
select abs(-10) from dual;
#十进制转二进制
select bin(10) from dual;
#向上取整,取最小的整数
select ceiling(1.1) from dual;
#向下取整,取最大的整数
select floor(1.1) from dual;
#进制的转换,将十进制表示的 5 转为二进制
select conv(5,10,2) from dual;
#保留小数(四舍五入)
select format(80.15465,2) from dual;
#取最小值
select least(1.1,2,1) from dual;
#求余
select mod(10,3) from dual;
#取随机数(0,1.0),每次运行都是不一样的结果
select rand() from dual;
#取随机数(0,1.0),每次运行都是一样的结果,这里的3不是固定,想填什么都行
select rand(3) from dual;
时间日期相关函数
部分可以当作值,传入数据库
| current_date() | 当前日期 |
|---|---|
| current_time() | 当前时间 |
| current_timestamp() | 当前时间戳 |
| date(datetime) | 返回 datetime的日期部分 |
| date_add(date1,interval d_value d_type) | 在date1中加上日期或时间 |
| date_sub(date1,interval d_value d_type) | 在date1中减去一个时间 |
| datediff(date1,date2) | 两个日期差(结果是天) |
| timediff(date1,date2) | 两个时间差(多少小时多少分钟多少秒) |
| now() | 当前时间 |
| year|month|date(datetime) from_unixtime() | 年月日 |
补充:
last_day(‘2021-11-2’),查询该月的最后一天的日期
#当前日期
select current_date() from dual;
#当前时间
select current_time() from dual;
#当前时间戳
select current_timestamp() from dual;
#eg:
insert into mes values(1,'北京新闻',current_timestamp);
#查询在十分钟内发布的新闻( 10 表示 value minute 表示type)
select * from mes where date_add(send_time,interval 10 minute) >= new();
select * from mes where date_sub(now(),interval 10 minute) <= new();
#两个时间差多少天
select datediff('2020-11-11','2019-11-23') from dual;
#两个时间差
select timediff('2020-11-11 12:15:23','2019-11-23 9:56:47') from dual;
#获取年月日
select year(now()) from dual;
select month(now()) from dual;
select day(now()) from dual;
#unix_timestamp() 返回70年1月1号 到现在的秒数
select unix_timestamp() from dual;
#from_unixtime() 可以把一个unix_timestamp秒数,转成指定格式的日期
#意义:在开发中,可以存放一个整数,然后表示时间,通过from_unixtime转换为时间
select from_unixtime(1618483484,'%Y-%m-%d %H:%i:%s') from dual;
interval 后面可以是 year,minute,second,hour,day等
datediff(date1,date2)得到的天数可以是负数
加密和系统函数
| user() | 查询用户 |
|---|---|
| database() | 数据库名称 |
| md5(str) | 为字符串算出一个MD5 32的字符串(密码加密) |
| password(str) | 从原文密码str计算并返回庙貌字符串,通过用于对mysql数据库的用户密码加密 |
#查看当前登录用户,以及登录IP
select user() from dual;
#查看当前数据名称
select database() from dual;
#加密,解密
insert into mes values(md5('hsp'));
select md5('hsp') from dual;
select password('hsp') from dual;
md5和password是两种不同的加密算法
流程控制函数
判断是否为 null 要使用 is null ,判断不为空 使用 is not
先看两个需求:
- 查询emp表,如果comm是null,则显示0.0
- 如果emp表的job是 clerk 则显示职员,如果是 manager 则显示经理,如果是salesman 则显示销售人员,其它正常显示
| if(expr1,expr2,expr3) | 如果expr1为true,则返回expr2否则返回expr3 |
|---|---|
| ifnull(expr1,expr2) | 如果expr1不为空,则返回expr1,否则返回expr2 |
| select case when expr1 then expr2 when expr3 then expr4 else expr5 end;类似一个多分支 | 如果expr1 为true,则返回expr2,如果expr3为true,则返回expr4,否则返回expr5 |
#
select if(true,'北京','上海') from dual;
select if(false,'北京','上海') from dual;
#
select ifnull(null,'hsp') from dual;
select ifnull('jack','hsp') from dual;
#
select if(comm is null,0.0,comm) from emp;
select ifnull(comm,0.0) from emp;
select ename,(select case when job = 'clerk' then '职员' when job = 'manager' then '经理' when job = 'salesman' then '销售人员' else job end) from emp;
特别说明:在mysql中,日期类型是可以直接比较的,但是需要注意日期的格式
select * from emp where hiredate > '1992-1-1';
多表查询
多表查询是指基于两个和两个以上的表查询,在实际开发中,查询单个表可能不能满足你的需求
select ename, sal, emp.deptno ,dname from emp,dept where emp.deptno = dept.deptno;
注意:多表查询的条件不能少于 表的个数-1 ,否则会出现笛卡尔集现象
在实际开发中,一般一个业务都会对应多张表
需要注意的是:在实际开发中,我们使用最多的还是多表连接,即(from emp,dept)这种方式
连接方式
- 内连接:等值连接、非等值连接、自连接
- 外连接:左外连接(左连接)、右外连接(右连接
在表的连接查询方面存在一种现象被称为:笛卡尔积现象
笛卡尔集现象:当两张表进行连接查询时,没有进行任何条件限制,最终的查询结果条数是两张表记录条数的乘积
表的别名
select e.name , d.dname from emp e , dept d;
表的别名有什么好处?
- 第一:执行效率高
- 第二:可读性好
怎么避免笛卡尔集现象,加上条件过滤
思考:避免了笛卡尔集现象,会减少记录的匹配次数吗?
不会,匹配次数还是一样多,只不过显示的是有效记录
案例:找出每一个员工的部门名称,要求显示员工名和部门名
SELECT e.ename , d.dname FROM emp e,dept d WHERE e.deptno = d.deptno;过时了不用了
内连接
内连接之等值连接:最大特点是:条件是等量关系
案例:找出每一个员工的部门名称,要求显示员工名和部门名
SELECT e.ename , d.dname FROM emp e,dept d WHERE e.deptno = d.deptno;92版过时了不用了
SELECT e.ename , d.dname FROM emp e join dept d on e.deptno = d.deptno;99版
SELECT e.ename , d.dname FROM emp e inner join dept d on e.deptno = d.deptno;99版,inner可以省略,表示内连接
内连接之非等值连接:最大的特点:连接条件中的关系是非等值关系
找出每个员工的工资等级,要求显示员工名、工资、工资等级
SELECT e.ename , e.sal , s.grade FROM emp e JOIN salgrade s ON e.sal BETWEEN s.losal AND s.hisal
**内连接之自连接:**最大的特点是:一张表当作两张表,自己连接自己,相同的表要取别名
找出每个员工的上级领导,要求显示员工名和对应的领导名(最大的领导不会查询出来)
SELECT e.ename ‘员工名’,s.ename ‘领导名’ FROM emp e JOIN emp s ON e.mge = s.empno;
外连接
什么是外连接,和内连接有什么区别?
内连接:假设表a和表b进行连接,使用内连接的话,凡是A表和B表能够匹配上的记录查询出来,这就是内连接。AB两张表没有主次之分,两张表是平等的。
外连接:假设表A和表B进行连接,使用外联接的话,AB两表中有一个主表有一个副表,主要查询主表中的数据,捎带着查询副表中的数据,当副表上的数据没有和主表上的数据匹配上,副表自动模拟出NULL与之匹配。
外连接的分类:
- 左外连接(左连接):左边那张表是主表,右边那张表是副表
- 右外连接(右连接):右边那张表是主表,左边那张表是副表
案例:找出每个员工的上级领导(所有员工必须查询出来)
SELECT e.ename ‘员工名’,s.ename ‘领导名’ FROM emp e LEFT OUTER JOIN emp s ON e.mge = s.empno;(左连接)(14条记录)outer可以省略
SELECT e.ename ‘员工名’,s.ename ‘领导名’ FROM emp s RIGHT JOIN emp e ON e.mge = s.empno;(右连接)(14条记录)
外连接最重要的特点是:主表的数据无条件的全部查询出来
案例:找出那个部门没有员工
SELECT d.dname , e.ename FROM dept d LEFT JOIN emp e ON d.deptno = e.deptno WHERE e.ename IS NULL;
三张表怎么查询
A join B jion C on : 表示A表先和B表进行连接,然后结果集在和C表连接(也可以说表示A表先和B表进行连接,A表在和C表连接)
案例:找出每一个员工的部门名称和工资等级
SELECT e.ename , d.dname , s.grade FROM emp e JOIN dept d ON e.deptno = d.deptno JOIN salgrade s ON e.sal BETWEEN s.losal AND s.hisal;
案例:展出没有给员工的部门名称和工资等级以及上级领导
SELECT e.ename , d.dname , s.grade , e1.ename FROM emp e JOIN dept d ON e.deptno = d.deptno JOIN salgrade s ON e.sal BETWEEN s.losal AND s.hisal LEFT JOIN emp e1 ON e.mge = e1.empno;
子查询
什么是子查询,子查询可以出现在那个地方
-
单行子查询:是指只返回一行数据的子查询语句
-
多行子查询:是指返回多行数据的子查询,使用关键字 in
SELECT ename,job,sal,deptno FROM emp WHERE job IN(SELECT DISTINCT job FROM emp WHERE deptno = 10) AND deptno != 10;
在多行子查询中使用all操作符
请思考:如何显示工资比部门30的所有员工的工资搞得员工的姓名、工资和部门号(取最大值)
select ename,sal,deptno from emp where sal > all(select sal from emp where deptno = 30);
在多行子查询中使用any操作符
请思考:如何显示工资比部门30的其中一个员工的工资高的员工的姓名、工资和部门号(取最小值)
select ename,sal,deptno from emp where sal > any(select sal from emp where deptno = 30);
子查询当作临时表使用
select语句当中嵌套select语句,被嵌套的select语句是子查询
子查询可以出现在哪里?
- select…(select)
- from…(select)
- where…(select)
案例:找出每个部门平均薪水的薪资等级
第一步:找出部门平均薪水
SELECT deptno , AVG(sal) FROM emp GROUP BY deptno;
第二步:把刚才查询出来的结果集当作一张临时表使用
SELECT d.de,d.av,s.grade FROM (SELECT deptno de, AVG(sal) av FROM emp GROUP BY deptno) d JOIN salgrade s ON d.av BETWEEN s.losal AND s.hisal;
多列子查询
多列子查询则是指查询返回多个列数据的子查询语句
请思考:查询与smith的部门和岗位完全相同的所有雇员(并且不包含ford本人)
SELECT ename
FROM emp ,(SELECT job,deptno FROM emp WHERE ename = 'ford') s
WHERE emp.job =s.job AND emp.deptno = s.deptno AND emp.ename != 'ford';
select * from emp where (deptno,job) = (select deptno,job from emp where ename = 'smith') and ename != 'smith';
练习
- 查找每个部门工资高于本部门平均工资的人的资料
#每个部门的平均工资
select avg(sal),deptno from emp group by deptno;
#
select * from emp,(select avg(sal) a,deptno from emp group by deptno) s where emp.sal > s.a and emp.deptno = s.deptno;
- 查找每个部门工资最高人的全部信息
SELECT MAX(sal) msal,deptno FROM emp GROUP BY deptno;
SELECT * FROM emp ,(SELECT MAX(sal) msal,deptno FROM emp GROUP BY deptno) s WHERE emp.sal = s.msal AND emp.deptno = s.deptno;
- 查询每个部门的信息(包括:部门名,编号,地址)和人员数量,
SELECT COUNT(1),deptno FROM emp GROUP BY deptno;
SELECT * FROM dept,(SELECT COUNT(1),deptno FROM emp GROUP BY deptno) a WHERE dept.deptno = a.deptno;
特别提醒:
- 临时表 取 别名
- 表名.*,表示将该表的所右列都显示出来
表的复制和删除
在开发中,有时为了对某个sql语句进行效率测试,我们需要海量数据时,可以使用此法为表创建海量数据
#先把emp表的记录复制到my_table
insert into my_table(id,`name`,sal,job,deptno) select empno,ename,sal,job,deptno from emp;
#自我复制
insert into my_table select * from my_table;
如果删除一张表中重复的记录
#1.先创建一个临时表,该表的结构和要删除表的结构是一样的
create table my_tmp like emp;
#这个语句是把emp表的结构(列),复制到my_table02中
#2.把emp的记录通过distinct 关键字处理后,把记录 复制到 my_tmp
insert into my_tmp select distinct * from emp;
#3.清楚掉 emp 中记录
delete * from emp
#4.把my_tmp表的记录复制到emp中
insert into emp select * from my_tmp;
#5.drop掉临时表
drop table my_tmp;
合并查询
有时在实际开发中,为了合并多个select语句的结果,可以使用集合操作符号 union,union all
union all:该操作符用于取得两个结果集的并集,当使用该操作符时,不会取消重复行
select ename,sal,job,from emp where sal > 2500 union all select ename,sal,job,from emp where job = 'manager';
union:该操作符用于取得两个结果集的并集,当使用该操作符时,会取消重复行
select ename,sal,job,from emp where sal > 2500 union select ename,sal,job,from emp where job = 'manager';
还可以将两张不相干的表的数据拼接在一起
select ename from emp
union
select dname from dept;
这样做显示的列名,只能是第一个结果集的列名,两个查询结果的列的数量必须是一样的
limit(重点中的重点,以后分页查询全靠它了),limit是Mysql中特有的,不通用,去结果集中的部分数据
limit startIndex,length
startIndex:表示起始的位置
length:表示取几个数据
limit是最后执行的
MySQL常见的约束:
-
非空约束:not null
-
唯一约束:unique
-
主键约束:primary key(简称PK)
-
外键约束:foreign key(简称FK)
-
检查:check
主键:primary key
用于唯一的标识表行的数据,当定义主键约束后,该列不能重复
注意细节
-
primary key不能重复而且不能为null
-
一张表最多只能有一个主键,但可以是符合主键
-
主键的指定方式有两种
-
直接在字段后指定:字段名 primary key
create table t( id int primary key, `name` varchar(32), email varchar(32) ); -
在表定义最后写 primary key(列名);
create table t( id int, `name` varchar(32), email varcahr(32), primary key(id,`name`) ); -
使用 desc 表名,查看表结构可以到primary key的情况
-
在实际开发中,每个表往往都会设计一个主键
not null(非空)
如果在列上定义了not null,那么当插入数据时,必须为列提供数据
#字段名 字段类型 not null
create table q(
id int not null
)
unique(唯一)
当定义了唯一约束后,该列值是不能重复的
#字段名 字段类型 unique
create table m(
id int unique not null
)
细节
- 如果没有指定not null,则unique字段可以有多个null
- 一张表可以有多个unique字段
外键:foreign key
用于定义主表和从表之间的关系:外键约束要定义在从表上,主表则必须具有主键约束或是 unique 约束,当定义外键约束后,要求外键列数据必须在主表的主键列存在或是为null
create table my_stu(
id int primary key,
`name` varchar(32) not null default '',
class_id int,
foreign key (class_id) references my_class(id)
);
外键的顺序要求
- 删除数据的时候,先删除子表,在删除父表
- 添加数据的时候,先添加父表,在添加子表
- 创建表的时候,先创建父表,在创建子表
- 删除表的时候,先删除子表,在删除父表
- 外键指向的表的字段,要求是primary key 或者是 unique
- 表的类型是innodb,这样的表才支持外键
- 外键字段的类型要和主键字段的类型一致(长度可以不一样)
- 外键字段的值,必须在主键字段中出现过,或者为null(前提是外键字段允许为null)
- 一旦建立主外键的关系,数据不能随意删除了
check
用于强制行数据必须满足的条件,假定在sal列上定义了check约束,并要求sal列值在1000-2000之间如果不在1000-2000之间就会提示出错
提示:oracle和sql server均支持check,但是mysql5.7目前还不支持check,只做语法校验,但不会生效
在mysql中实现check的功能,一般是在程序中控制,或者通过触发器完成
基本语法:列名 类型 check(check条件)
create table t(
id int primary key,
`name` varchar(32) not null default '',
sex varchar(5) check(sex in(man,woman)),
sal double check(sal>1000 and sal<2000)
);
事务(transaction)
什么是事务,是一个完整的业务逻辑单元,不可再分
比如:银行账户转账,从a账户向b账户转账10000,需要执行两条update语句
update t_act set balance = balance - 10000 where actno = “act-001”;
update t_act set balance = balance + 10000 where actno = “act-002”;
以上两条语句必须同时成功,或者同时失败,不允许出现一条成功,另一条失败
要想保证以上两条DML语句同时成功或者失败,那么就需要使用数据库的事务机制
只有增删改需要事务,其它的不需要事务(DML语句)
假设所有的业务都能使用一条DML语句搞定,还需要事务机制吗?
不需要事务
但是实际情况不是这样的,通常一个业务需要多条DML语句共同联合完成
mysql事务默认情况下是自动提交的(什么是自动提交,只要执行一条任意DML语句则提交一次)
事务和锁
当执行事务操作时(dml语句),mysql会在表上加上锁,防止其它用户该表的数据,这对用户来说是非常重要的
mysql数据库控制台事务的几个重要操作
#开始一个事务
start transaction
#保存点名,设置保存点
savepoint
#保存点名,回退事务
rollback to
#回退全部事务
rollback
#提交事务,所有的操作生效,不能回退
commit
演示
#创建测试表
CREATE TABLE t1(
id INT ,
`name` VARCHAR(32)
);
#开始事务
START TRANSACTION;
#设置保存点
SAVEPOINT a;
#指定dml操作
INSERT INTO t1 VALUES(1,'hsp');
SELECT * FROM t1;
#设置保存点
SAVEPOINT b;
#指定dml操作
INSERT INTO t1 VALUES(4,'edu');
SELECT * FROM t1;
#回退到b
ROLLBACK TO b;
SELECT * FROM t1;
#回退到a
ROLLBACK TO a;
SELECT * FROM t1;
#如果这样,表示回退到开始
ROLLBACK;
#提交事务,所有操作都生效,不能再回退,保存点也会清除
COMMIT;
回退事务:再介绍回退事务前,先介绍一下保存点(savepoint),保存带你是事务中的点,用于取消部分事务,当结束事务时,会自动的删除该事务所定义的所有保存点,当执行回退事务时,通过指定保存点可以回到指定的点, 如果回退到更加前面的保存点,不能再回退到更加后面的保存点
提交事务:使用commit语句可以提交事务,当执行了commit语句后,会确认事务的变化,结果事务,删除保存点,释放锁,数据生效,当使用commit语句结束事务后,其他会话(其他连接)将可以查看到事务变化后的新数据
事务细节讨论
- 如果不开始事务,默认情况下,dml操作时自动提交的,不能回滚
- 如果开始一个事务,你没有创建保存点,你可以执行rollback,默认就是回退到你事务开始的状态
- 你也可以在这个事务中(还没有提交时),创建多个保存点,比如:savepoint aaa; 执行dml, savepoint bbb;
- 你可以在事务没有提交前,先择回退到哪个保存点
- Mysql的事务机制需要innodb的存储引擎下可以使用,myisam不好使
- 开始一个事务有两种方式: start transaction , set autocommit = off;
事务的隔离级别
事务隔离级别介绍
- 多个连接开启各自事务操作数据库中数据时,数据库系统要负责隔离操作,以保证个连接在获取数据时的准确性
- 如果不考虑隔离性,可能会引发如下问题:脏读,不可重复读,幻读
脏读:当一个事务读取另一个事务尚未提交的修改(dml)时,产生脏读
不可重复读:同一查询在同一事务中多次进行,由于其他提交事务所作的修改或删除,每次返回不同的结果集,此时发生不可重复读
幻读:同一查询在同一事务中多次进行,由于其它提交事务所做的插入操作,每次返回不同的结果集,此时发生幻读
事务隔离级别:定义了事务与事务之间的隔离程度
| Mysql隔离级别 | 脏读 | 不可重复读 | 幻读 | 加锁读 |
|---|---|---|---|---|
| 读未提交(Read uncommitted) | √ | √ | √ | 不加锁 |
| 读已提交(Read committed) | x | √ | √ | 不加锁 |
| 可重复读(Repeatable read) | x | x | x | 不加锁 |
| 可串行化(Serializable) | x | x | x | 加锁 |
说明:√可能出现,x不会出现
#查看当前会话隔离级别
selete @@tx_isolation;
#8版本
select @@transaction_isolation;
#查看系统当前隔离级别
select @@global.transaction_isolation;
#默认的隔离级别(可重复读)
REPEATABLE-READ
#设置当前会话隔离级别,read uncommitted 表示隔离级别,前面的都是固定的语法
set session transaction isolation level read uncommitted;
#设置系统当前隔离级别
set global transabtion isolation level (级别);
隔离级别是和事务相关的,离开事务就不要谈隔离界别
可以通过开启两个命令行窗口来进行测试
mysql默认的事务隔离级别是 repeatable read ,一般情况下,没有特殊要求,没有必要修改(因为该级别可以满足绝大部分项目需求)
设置默认的隔离级别
在my.ini文件中,加入下面这句话
transaction-isolation = [隔离级别]
事务的acid特性
- 原子性(atomicity):原子性是指事务是一个不可分割的工作单位,食物中的操作要么都发生,要么都不发生
- 一致性(consistency):事务必须使数据库从一个一致性状态变换到另外一个一致性状态
- 隔离性(isolation):事务的隔离性十多个用户并发访问数据时,数据库为每一个用户开启的事务,不能被其它事务的操作数据所干扰,多个并发事务之间要相互隔离
- 持久性(durability):持久性是指一个事务一旦被提交,他对数据库中数据的改变就是永久性的,接下来即使数据库发生故障也不应该对其有任何影像
索引
说起提高数据库性能,索引是最物美价廉的东西了,不用加内存,不用改程序,不用调sql,查询速度就可能提高百千倍
一个表有八百万条数据,在没有创建索引时的大小是524m,创建索引后的大小是655m(索引本身也会占用空间);原本没有创建索引前查询一条数据需要4.5秒,创建索引之后0.003秒,时间提高太多
#empno_index 索引名称
#on emp (empno) 表示在emp表的empno列创建索引
create index empno_index on emp (empno);
创建索引后,只对创建了索引的列有效
索引的原理
当我们没有创建索引时,一个查询语句会进行全表扫描(即使前面已经找到数据,还是会往下扫描,判断下面部分有没有这个符合条件的数据),索引查询速度很慢
使用索引为什么会快?形成一个索引的数据结构,比如二叉树等等
索引的代价
- 磁盘占用
- 对(update delete insert)语句的效率有一定的影像
在实际开发中,select占用的比例大概有90%,所以说索引的利还是大于弊
索引的类型
- 主键索引,主键自动的为主索引(primary key),即主键自动就是一个索引
- 唯一索引(unique),即有unique约束的也是自动为索引
- 普通索引(index),优点:允许索引有允许重复
- 全文索引(fulltext)(适用于MyISAM),一般开发,不使用mysql自带的全文索引,而是使用:全文搜索 Solr 和 ElasticSearch (ES)
添加索引
添加唯一索引
#id_index 索引名称
#on t12 (id) 哪个表,哪个字段添加索引
create unique index id_index on t12 (id);
添加普通索引
#方式一
create index id_index on t12 (id);
#方式二
alter table t12 add index id_index (id);
添加主键索引
alter table t12 add primary key (id);
如何在唯一索引和普通索引中选择:如果某列的值,是不会重复的,则优先考虑使用 unique ,否则使用普通索引
删除索引
#删除所引
#id_index 索引名称
#t12 表名
drop index id_index on t12;
#查询表中有哪些索引
show index from t12;
#删除主键索引的方式
alter table t12 drop primary key;
修改索引,先删除,在添加新的索引
查询索引
show index from t;
show indexes from t;
show keys from t;
创建索引的规则
-
较频繁的作为查询条件字段应该创建索引
select * from emp where empno = 1; -
唯一性太差的字段不适合单独创建索引,即使频繁作为查询条件(比如说:10万数据,有五万是 男的 这样的索引就没有意义了)
select * from emp where sex = '男'; -
更新非常频繁的字段不适合创建索引(登录次数)
select * from emp where logincount = 1 -
不会出现在where子句中字段不该创建索引(即:不会是查询条件的)
视图
看一个需求
emp表的列信息很多,有些信息是个人重要信息(比如:sal,comm,mgr,hiredate),如果我们希望某个用户只能查询到emp表的(empno,ename,job,deptno)信息,有什么办法?–> 视图
什么是视图
视图是一个虚拟表,其内容由查询定义,同真实的表一样,视图包含列,其数据来自对应的真实表(基表)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2dhOt0U7-1630487044484)(D:\知识点截图\多用户即时通讯系统\mysql_视图和基表的关系.png)]
视图的基本使用
#创建视图
create view 视图名 as select 语句
#更新视图
alter view 视图名 as select 语句
#查看创建视图的指令
show create view 视图名
#删除视图
drop view 视图名1,视图名2
练习:创建一个视图emp_view01,只能查询emp表的(empno,ename,job,deptno)信息
CREATE VIEW emp_view01 AS SELECT empno,ename,job,deptno FROM emp;
查看视图结构
DESC emp_view01;
视图细节讨论:
- 创建视图后,到数据库中看,对应视图只有一个视图结构文件(形式:视图名.frm)
- 视图的数据变换会影响到基表,基表的数据变换也会影像到视图(insert update delete)
- 视图中可以再次使用视图
视图的最佳实践
- 安全。一些数据表有着重要的信息,有些字段是保密的,不能让用户直接看到,这时就可以创建一个视图,在着张视图中只保留一部分字段,这样,用户就可以查询自己需要的字段,不能查看保密的字段
- 性能。关系数据库的数据常常会分表存储,使用外键建立这个表的之间关系,这时数据库查询通过会用到连接(join),这样做不但麻烦,效率相对也比较第,如果建立一个视图,将相关的表和字段组合在一起,就可以避免使用 join 来查询数据
- 灵活。如果系统中有一张旧的表,这张表由于设计的问题,即将被废弃,然而,很多应用都是基于这张表,不易修改,这时就可以建立一张视图,视图中的数据直接映射到新建的表,这样,就可以少做很多改动,也到了升级数据表的目的。
练习:针对emp,dept和salgrade三张表,创建一个视图emp_view03,可以显示雇员编号,雇员名,雇员部分名称和薪水级别
CREATE VIEW emp_view04 AS SELECT empno,ename,deptno,grade FROM
(SELECT empno,ename,dept.deptno,sal a FROM emp,dept
WHERE emp.deptno = dept.deptno ) b , salgrade s WHERE b.a BETWEEN s.losal AND s.hisal;
也可以不同上面这样,直接 from emp,dept,salgrade where ...
三大范式:
第一范式:要有主键,一个字段不能存储多个信息
第二范式:所有非主键字段完全依赖主键,尽量不要有联合主键,不能有部分依赖关系
- 多对多,三张表,关系表两个外键
第三范式:所有非主键字段全部依赖主键,不能有传递依赖
- 一对多,两张表,多的表加外键
在实际开发中,以满足客户的需求为主,有的时候会拿冗余换执行速度
JDBC编程六步:
- 第一步:注册驱动,告诉java程序,要连接的是哪个数据库
- 第二步:获取连接,表示JVM的进程和数据库之间的进程之间的通道打开了
- 第三步:获取数据库操作对象,专门执行sql语句的对象
- 第四步:执行SQL语句(DQL,DML)
- 第五步:处理查询结果集(只有第四步是执行select的时候,才有这第五步处理查询结果集)
- 第六步:释放资源(使用完后一定要关闭资源)
mysql表类型和存储引擎
基本介绍
- mysql的表类型有存储引擎(storage engines)决定,主要包括myisam,innodb,memory等
- mysql数据表主要支持六种类型:CSV,Memory,ARCHIVE,MRG_MYISAM,MYISAM,Innodb
- 这六种又分为两类,一类是”事务安全型“,比如:innodb ,其余都属于第二类,称为”非事务安全型“
显示当前数据库支持的存储引擎
show engines;
细节说明:
- MyISAM不支持事务,也不支持外键,但其访问数据快,对事物完整性没有要求
- Innodb存储引擎提供了具有提交、回滚和崩溃恢复能力的事务安全,但是比起MyISAM存储引擎,Innodb写的处理效率差一些并且会占用更多的磁盘空间以保留数据和索引
- MEMORY存储引擎使用内存中的内容来创建表,每个MEMORY表实际对应一个磁盘空间。MEMORY类型的表访问非常的快,因为它的数据是放在内存中的,并且默认是使用HASH索引,但是一旦服务关闭,表中的数据就会丢失掉,表的结构还在
如何选择表的存储引擎
- 如果你的应用不需要事务,处理的只是基本的CRUD操作,那么MyISAM是不二选择,速度快
- 如果需要支持事务,选择Innodb
- Mymory存储引擎就是将数据存储在内存中,由于没有磁盘I/O的等待,速度极快,但由于是内存存储引擎,所做的任何修改在服务器重启后都将消失(经典用法:用户的在线状态)
修改存储引擎
alter table 表名 engine = 存储引擎;
Mysql管理
mysql中的用户,都存储在系统数据库mysql中user表中
其中user表的重要字段说明
- host:允许登录的 位置 ,localhost表示该用户只允许本机登录,也可以指定ip地址,比如:192.168.1.100
- user:用户名
- authentication_string:密码,是通过mysql的password()函数加密之后的密码
当我们做项目开发时,可以根据不同的开发人员,赋给他相应的mysql操作权限,所以mysql数据库管理人员(root),根据需要创建不同的用户,然后赋给相应的权限,供人员使用
创建用户
#创建用户,同时指定密码
create user '用户名'@'允许登录位置' identified by '密码';
create user 'hsp'@'localhost' indentified by '123456';
删除用户
drop user '用户名' @ '允许登录位置';
drop user 'hsp'@'localhost';
不同的数据库用户,登录到dbms后,根据相应的权限,可以操作的数据库和数据对象(表,视图,触发器)都不一样
用户修改密码
#修改自己密码
set passdword = password('密码');
#修改他人密码(需要由修改用户密码权限)
set password for '用户名'@'登录位置' = password('密码');
给用户授权
基本语法
grant 权限列表 on 库.对象名 to '用户名'@'登录位置' [identified by '密码']
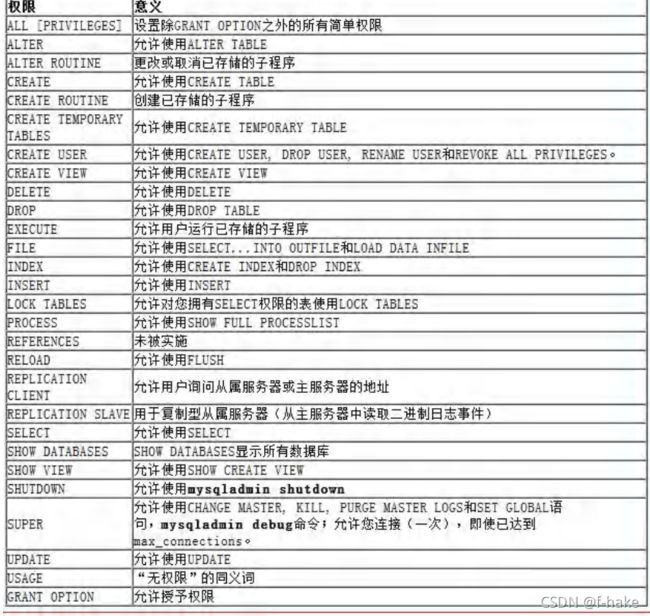
说明
- 权限列表,多个权限用逗号分开
- grant seleact on …
- grant seleact,delete,create on …
- grant all [privaileges] on … 赋予该用户在该对象上的所有权限
- 特别说明(下面的是写在 库.对象名 的位置)
- 库.*:表示某个数据库中所有数据对象(表,视图,存储过程等)
- 星.星(星表示:*):代表本系统中的所有数据库的所有兑现昂(表,视图,存储过程)
- identified by 可以省略,也可以写出
- 如果用户存在,就是修改该用户的密码,(授权的同时修改用户密码)
- 如果该用户不存在吗,就是创建该用户,(授权的同时创建用户)
回收用户授权
基本语法
revoke 权限列表 on 库.对象名 from '用户名'@'登录位置';
权限生效指令
如果权限没有生效,可以执行下面命令
flush privileges;
练习
#创建要给用户(你的名字,拼音),密码 123,并且只可以从本地登录,不让远程登录
create user 'cyg'@'localhost' identified by '123';
#创建库和表 testdb 下的 news 表,要求:使用root用户创建
create database testdb;
create table news(
id int,
content varchar(32)
)
#给用户分配查看news表和添加数据的权限
grant select,insert on testdb.news to 'cyg'@'localhost';
#测试看看用户是否只有着几个权限
update news set content = '北京新闻' where id = 100;失败
#修改密码为 abc ,要求:使用root 用户完成
set password for 'cyg'@'localhost' = password('abc');
#回收权限
revoke select on testdb.news from 'cyg'@'localhost';
#重新登录
#使用root 用户删除你的用户
drop user 'cyg'@'localhost';
用户管理的细节:
-
在创建用户的时候,如果不指定 Host ,则为%,%表示所有IP都有连接权限
create user jack;等价于 create user 'jack'@'%'; -
也可以这样指定 ,表示xxx用户在192.168.1.*的IP都可以登录mysql
create user 'xxx'@'192.168.1.%' -
在删除用户的时候,如果host不是%,需要明确指定 ‘用户名’@‘host值’
drop user jack;等价于 drop user 'jack'@'%';
练习
-
显示所有雇员名及其年收入(sal*12+comm),并指定别名
select ename,(sal*12+ifnull(comm,0)) from emp; -
显示部门10和30中工资超过1500的雇员名及工资
select ename,sal from emp where sal > 1500 and deptno in(10,30); -
显示在1991年2月1日到1991年5月1日之间雇用的雇员名,岗位及雇佣日期,并以雇佣日期进行排序
SELECT ename,job,hiredate FROM emp WHERE hiredate<'1991-05-01' AND hiredate>'1991-02-01' ORDER BY hiredate; -
找出奖金大于薪水的员工
select * from emp where ifnull(comm,0)>sal; -
找出各月倒数第三天受雇的所有员工
select * from emp where datediff(last_day(hiredate),hiredate) < 3; -
找出入职时间超过12年
select * from emp where date_add(hiredate, interval 12 year) < now(); -
列出至少有一个员工的所有部门
SELECT deptno ,COUNT(1) FROM emp GROUP BY deptno having COUNT(1) > 0; -
列出受雇日期晚于其直接上级的所有员工
SELECT e.ename FROM emp e ,emp m WHERE e.mgr = m.empno AND e.hiredate > m.hiredate -
列出部门名称和这些部门的员工信息,同时列出那些没有员工的部门
SELECT dname,emp.* FROM dept LEFT JOIN emp ON emp.deptno = dept.deptno -
列出薪金高于在部门30工作的所有员工的薪金的员工姓名和薪金
SELECT ename,sal FROM emp WHERE sal > (SELECT MAX(sal) FROM emp WHERE deptno =30) AND deptno !=30; -
列出在每个部门工作的员工数量、平均工资和平均服务期限
SELECT deptno,COUNT(1),AVG(sal),FORMAT(AVG(DATEDIFF(NOW(),hiredate) / 365),2) '平均服务年限' FROM emp GROUP BY deptno; -
列出各种工作的最低工资
select min(sal) from emp group by job;
大练习
设学校环境如下:一个系有若干个专业,每个专业一年只招一个班,每个班有若干个学生。先要建立关于系、班级、学生的数据库,关系模式为:
- 班class(班号:classid,专业名:subject,系名:deptname,入学年份:enrolltime,人数:num)
- 学生student(学号:studentid,姓名:name,年龄:age,班号:classid)
- 系department(系号:departmentid,系名:deptname)
CREATE TABLE department(
departmentid VARCHAR(3) PRIMARY KEY NOT NULL,
deptname VARCHAR(32) UNIQUE NOT NULL DEFAULT ''
);
CREATE TABLE class(
classid VARCHAR(32) PRIMARY KEY NOT NULL,
`subject` VARCHAR(32),
deptname VARCHAR(32),
enrolltime VARCHAR(4),
num INT,
FOREIGN KEY (deptname) REFERENCES department(deptname)
);
CREATE TABLE student(
studentid VARCHAR(4) PRIMARY KEY NOT NULL,
`name` VARCHAR(32) NOT NULL DEFAULT '',
age INT,
classid VARCHAR(32) NOT NULL ,
FOREIGN KEY (classid) REFERENCES class(classid)
);
要求:
- 每个表的主外键
- department是唯一约束
- 学生姓名不能为空
- 使用sql语句完成
插入如下数据:
department(
001,数学;
002,计算机;
003,化学;
004,中文;
005,经济;
)
class(
101,软件,计算机,1995,20;
102,微电子,计算机,1996,30;
111,无机化学,化学,1995,29;
112,高分子化学,化学,1996,25;
121,统计数学,数学,1995,20;
131,现代语言,中文,1996,20;
141,国际贸易,经济,1997,30;
142,国际金融,经济,1996,14;
)
student(
8101,张三,18,101;
8102,钱四,16,121;
8103,王玲,17,131;
8105,李飞,19,102;
8109,赵四,18,141;
8110,李可,20,142;
8201,张飞,18,111;
8302,周瑜,16,112;
8203,王亮,17,111;
8305,董庆,19,102;
8409,赵龙,18,101;
8510,李丽,20,142;
)
INSERT INTO department VALUES('001','数学');
INSERT INTO department VALUES('002','计算机');
INSERT INTO department VALUES('003','化学');
INSERT INTO department VALUES('004','中文');
INSERT INTO department VALUES('005','经济');
INSERT INTO class VALUES('101','软件','计算机','1995',20);
INSERT INTO class VALUES('102','微电子','计算机','1996',30);
INSERT INTO class VALUES('111','无机化学','化学','1995',29);
INSERT INTO class VALUES('112','高分子化学','化学','1996',25);
INSERT INTO class VALUES('121','统计数学','数学','1995',20);
INSERT INTO class VALUES('131','现代语言','中文','1996',20);
INSERT INTO class VALUES('141','国际贸易','经济','1997',30);
INSERT INTO class VALUES('142','国际金融','经济','1996',14);
INSERT INTO student VALUES('8101','张三',18,'101');
INSERT INTO student VALUES('8102','钱四',16,'121');
INSERT INTO student VALUES('8103','王玲',17,'131');
INSERT INTO student VALUES('8105','李飞',19,'102');
INSERT INTO student VALUES('8109','赵四',18,'141');
INSERT INTO student VALUES('8110','李可',20,'142');
INSERT INTO student VALUES('8201','张飞',18,'111');
INSERT INTO student VALUES('8302','周瑜',16,'112');
INSERT INTO student VALUES('8203','王亮',17,'111');
INSERT INTO student VALUES('8305','董庆',19,'102');
INSERT INTO student VALUES('8409','赵龙',18,'101');
INSERT INTO student VALUES('8510','李丽',20,'142');
完成如下功能:
-
找出所有姓李的学生
SELECT * FROM student WHERE `name` LIKE '李%' -
列出所有开设超过1个专业的系的名字
SELECT deptname FROM class GROUP BY deptname HAVING COUNT(1)>1; -
列出人数大于等于30的系的编号和名字
SELECT t.* , `sum` FROM department tt, (SELECT SUM(num) `sum` ,deptname d FROM class GROUP BY deptname) t WHERE tt.deptname = t.d -
学校新增了一个物理系,编号为006
INSERT INTO department VALUES('006','物理系') -
学生张三退学,请更新相关的表
start transaction; update class set num = (num -1) where classid = (select classid from student where `name` = '张三'); delete from student where `name` = '张三'; commit;
JDBC
基本介绍
- JDBC为访问不同的数据提供了统一的接口,为使用者屏蔽了细节问题
- java程序员使用JDBC,可以连接任何提供了JDBC驱动程序的数据库系统,从而完成对数据库的各种操作
- JDBC的基本原理(重要)
连接 url 的格式
jdbc:mysql://localhost:3306/school?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
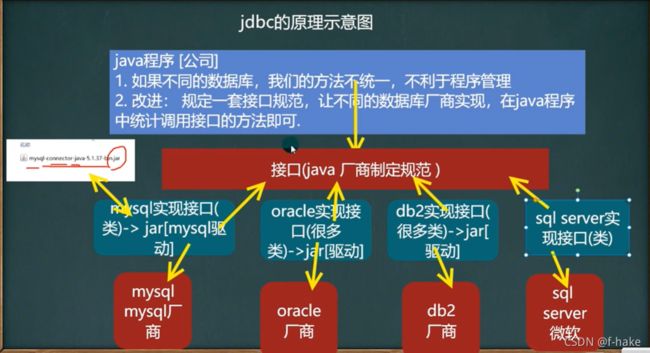
说明:JDBC是java提供一套用于数据库操作的接口API,java程序员只需要面向这套接口编程即可,不同的数据库厂商,需要针对这套接口,提供不同实现,相关类和接口在java.sql和javax.sql包中
自己测试代码
/**
* 我们规定的jdbc接口
* @author cyg
* @create 2021-08-30 19:18
*/
public interface JdbcInterface {
//连接
public Object getConnection();
//crud
public void crud();
//结束
public void close();
}
public class MysqlJdbcImple implements JdbcInterface{
@Override
public Object getConnection() {
System.out.println("得到 mysql 的连接");
return null;
}
@Override
public void crud() {
System.out.println("完成 mysql 的增删改查");
}
@Override
public void close() {
System.out.println("断开 mysql 的连接");
}
}
public class OracleJdbcImple implements JdbcInterface{
@Override
public Object getConnection() {
System.out.println("完成对 oracle 的连接");
return null;
}
@Override
public void crud() {
System.out.println("完成对 oracle 的增删改查");
}
@Override
public void close() {
System.out.println("完成对 oracle 的关闭");
}
}
public class TestJdbc {
public static void main(String[] args) {
//完成对mysql的操作
JdbcInterface jdbcImple1 = new MysqlJdbcImple();
//使用接口来调用实现类(动态绑定机制)
jdbcImple1.getConnection();
jdbcImple1.crud();
jdbcImple1.close();
JdbcInterface jdbcImple2 = new OracleJdbcImple();
jdbcImple2.getConnection();
jdbcImple2.crud();
jdbcImple2.close();
}
}
JDBC程序编写步骤
- 注册驱动-加载 Driver 类
- 获取连接-得到 Connection
- 执行增删改查-发送SQL给mysql执行
- 释放资源-关闭相关连接
由于版本的问题,和老韩说的不一样了
获取数据库连接5种方式
方式一:会直接使用 com.mysql.cj.jdbc.Driver(),属于静态加载,灵活性差,依赖性强,退出方式二
Driver driver = new com.mysql.cj.jdbc.Driver();
String url = "jdbc:mysql://localhost:3306/school?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true");
Properties properties = new Properties();
properties.setProperty("user","root");
properties.setProperty("password","cyg520zsw");
Connection conn = driver.connect(url,properties);
System.out.println(conn);
方式二:
Class clazz = Class.forName("com.mysql.cj.jdbc.Driver");
Driver driver = (Driver) clazz.newInstance();
String url = "jdbc:mysql://localhost:3306/school?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true";
Properties properties = new Properties();
properties.setProperty("user","root");
properties.setProperty("password","cyg520zsw");
Connection conn = driver.connect(url,properties);
System.out.println(conn);
方式三:
public void conn03() throws ClassNotFoundException, IllegalAccessException, InstantiationException, SQLException {
//使用反射加载Driver
Class clazz = Class.forName("com.mysql.cj.jdbc.Driver");
Driver driver = (Driver)clazz.newInstance();
//创建url和user和password
//jdbc:mysql://localhost:3306/school?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai
String url = "jdbc:mysql://localhost:3306/school?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true";
String user = "root";
String password = "cyg520zsw";
//注册driver驱动,不过现在的版本不用显示注册了
//DriverManager.registerDriver(driver);
//得到连接
Connection connection = DriverManager.getConnection(url, user, password);
System.out.println(connection);
}
方式四:
public void conn04() throws ClassNotFoundException, IllegalAccessException, InstantiationException, SQLException {
Class<?> clazz = Class.forName("com.mysql.cj.jdbc.Driver");
/*
* static {
try {
DriverManager.registerDriver(new Driver());
} catch (SQLException var1) {
throw new RuntimeException("Can't register driver!");
}
}
* */
Driver driver = (Driver)clazz.newInstance();
String url = "jdbc:mysql://localhost:3306/school?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true";
String user = "root";
String password = "cyg520zsw";
Connection connection = DriverManager.getConnection(url, user, password);
System.out.println(connection);
}
方式五:
public void conn05() throws IOException, ClassNotFoundException, IllegalAccessException, InstantiationException, SQLException {
Properties properties = new Properties();
properties.load(new FileInputStream("src/mysql.properties"));
String user = properties.getProperty("user");
Object password = properties.get("password");
String driver = properties.getProperty("driver");
String url = properties.getProperty("url");
Class.forName(driver);//aClass没有用到,可以不用写结果
//Driver dri = (Driver)aClass.newInstance();//没有用到,可以不写
Connection connection = DriverManager.getConnection(url, user, (String) password);
System.out.println(connection);
}
老韩提示:
- mysql驱动5.1.6之后可以无需Class.forName(“com.mysql.cj.jdbc.Driver”)
- 从jdk1.5以后使用了jdbc4,不在需要显示调用Class.forName()注册驱动而是自动调用驱动jar包下META-INF]\services\java.sql.Driver文本中的类名称去注册
- 建议还是写上 Class.forName(“com.mysql.cj.jdbc.Driver”),更加明确
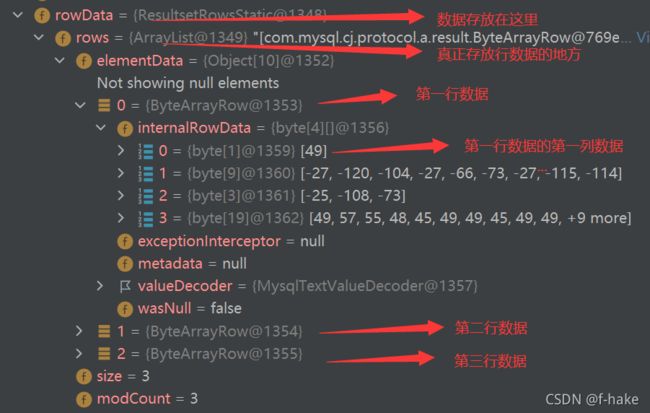
ResultSet结果集
基本介绍
- 表示数据库结果集的数据表,通过通过执行查询数据库的语句生成
- ResultSet对下昂报纸一个光标指向当前的数据行,最初,光标位于第一行之前
- next方法将光标移动到下一行,并且由于在ResultSet对象中没有更多行时返回false,因此可以在while循环中使用循环来遍历结果集
public class ResultSet_ {
public static void main(String[] args) throws IOException, ClassNotFoundException, SQLException {
Properties properties = new Properties();
properties.load(new FileInputStream("src/mysql.properties"));
String user = properties.getProperty("user");
String password = properties.getProperty("password");
String driver = properties.getProperty("driver");
String url = properties.getProperty("url");
//注册驱动
Class.forName(driver);
//得到连接
Connection connection = DriverManager.getConnection(url, user, password);
//得到statement,存在SQL注入问题
Statement statement = connection.createStatement();
//组织sql
String sql = "select id,name,sex,borndate from actor";
//执行sql,该语句返回单个ResultSet对象
/*
*
* */
ResultSet resultSet = statement.executeQuery(sql);
//使用while循环取出数据
while (resultSet.next()) {
//让光标向后移动,如果没有更多行,则返回false
int id = resultSet.getInt(1);//得到第一列数据
String name = resultSet.getString(2);//得到第二列数据
String sex = resultSet.getString(3);//得到第三列数据
Date date = resultSet.getDate(4);//得到第四列数据
System.out.println(id+"\t"+name+"\t"+sex+"\t"+date);
}
//关闭连接
resultSet.close();
statement.close();
connection.close();
}
}
Statement(存在SQL注入问题)
基本介绍
- Statement对象 用于执行静态SQL语句并返回其生成的结果的对象
- 在连接建立后,需要对数据库进行访问,执行 命令或是SQL语句,可以通过下面三种中的一个来执行:Statement(存在SQL注入问题),PreparedStatement(预处理),CallableStatement(存储过程)
- Statement对象执行SQL语句,存在SQL注入风险
- SQL注入是利用某些系统没有对用户输入的数据进行充分的检查,而在用户输入数据中注入非法的SQL语句段或命令,恶意攻击数据库
- 要防范SQL注入,只要用PreparedStatement(从Statement扩展而来)取代Statement就可以了
PreparedStatement(预处理)
- PreparedStatement执行的SQL语句中参数用问号(?)来表示,调用PreparedStatement对象的 setXXX()方法来设置这些参数.setXXX()方法有两个参数,第一个参数是要设置的SQL语句中的参数索引(从1开始),第二个是设置SQL语句中的参数的值
- 调用executeUpdate():执行更新,包括:增,删,改
- 调用executeQuery():返回 ResultSet对象
预处理的好处:
- 不再使用+拼接sql语句,减少语法错误
- 有效的解决了sql注入问题
- 大大减少了编译次数,效率较高
public class PreparedStatement_ {
public static void main(String[] args) throws IOException, ClassNotFoundException, SQLException {
Scanner scanner = new Scanner(System.in);
System.out.print("请输入查询者id:");
int id = scanner.nextInt();
System.out.print("请输入查询者姓名:");
String name = scanner.next();
/*System.out.print("请输入姓名:");
String name = scanner.next();
System.out.print("请输入性别:");
String sex = scanner.next();
System.out.print("请输入出生日期:");
String borndate = scanner.next();
System.out.print("请输入电话:");
String phone = scanner.next();*/
Properties properties = new Properties();
properties.load(new FileInputStream("src/mysql.properties"));
String user = properties.getProperty("user");
String password = properties.getProperty("password");
String driver = properties.getProperty("driver");
String url = properties.getProperty("url");
//注册驱动
Class.forName(driver);
//得到连接
Connection connection = DriverManager.getConnection(url, user, password);
//组织sql,其中的?就相当于占位符
String sql = "select id,name,sex,borndate from actor where id = ? and name = ?";
//String sql = "insert into actor values(null,?,?,?,?)";
//得到PreparedStatement,由于需要实参sql,所以需要先定义sql语句
//preparedStatement对象是实现了PreparedStatement接口的实现类的对象
PreparedStatement preparedStatement = connection.prepareStatement(sql);
//给?号赋值
preparedStatement.setInt(1,id);
preparedStatement.setString(2,name);
/*preparedStatement.setString(1,name);
preparedStatement.setString(2,sex);
preparedStatement.setString(3,borndate);
preparedStatement.setString(4,phone);*/
//执行sql,该语句返回单个ResultSet对象
//executeQuery,查询语句专用
//executeUpdate,dml语句专用
//这里不用传入sql,因为前面已经关联了,并且sql中也没有给定值,
ResultSet resultSet = preparedStatement.executeQuery();
/*if (resultSet.next()){
System.out.println("查询成功");
}else{
System.out.println("查询失败");
}*/
/*int result = preparedStatement.executeUpdate();
if (result == 1){
System.out.println("插入成功");
}else{
System.out.println("插入失败");
}*/
//使用while循环取出数据
while (resultSet.next()) {
//让光标向后移动,如果没有更多行,则返回false
int id1 = resultSet.getInt(1);//得到第一列数据
String name1 = resultSet.getString(2);//得到第二列数据
String sex = resultSet.getString(3);//得到第三列数据
Date date = resultSet.getDate(4);//得到第四列数据
System.out.println(id1+"\t"+name1+"\t"+sex+"\t"+date);
}
//关闭连接
//resultSet.close();
preparedStatement.close();
connection.close();
}
}
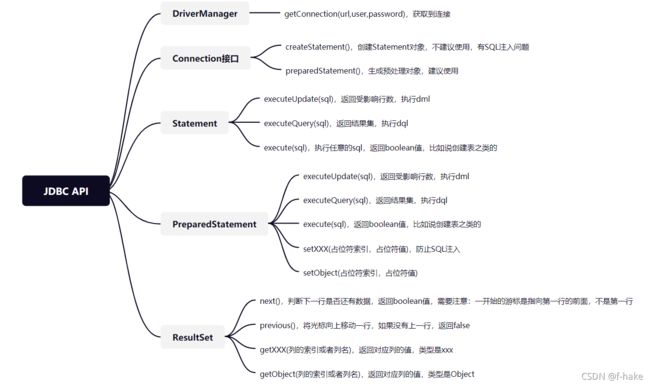
封装JDBCUtils
在jdbc操作中,获取连接和释放资源是经常用到的,可以将其封装为JDBC连接的工具类JDBCUtils
/**
* jdbc的工具类,完成mysql的连接的关闭
* @author cyg
* @create 2021-08-31 15:17
*/
public class JDBCUtils {
//定义相关的属性(4个),因为只需要一份,因此,我们做出static
private static String user ; //用户名
private static String password ; //密码
private static String url ; //url
private static String driver ; //驱动名
//在static代码块中,初始
static{
try {
Properties properties = new Properties();
properties.load(new FileInputStream("src/mysql.properties"));
user = properties.getProperty("user");
password = properties.getProperty("password");
url = properties.getProperty("url");
driver = properties.getProperty("driver");
} catch (IOException e) {
//在实际开发中,我们可以这样处理
//1.将编译异常转换为运行异常
//2.这时 调用者 可以选择捕获异常,也可以选择默认处理异常,比较方便
throw new RuntimeException(e);
}
}
//编写方法,连接数据库,返回Connection
public static Connection getConnection(){
Connection connection = null;
try {
Class.forName(driver);
connection = DriverManager.getConnection(url, user, password);
} catch (ClassNotFoundException | SQLException e) {
//将编译异常转换为运行异常
throw new RuntimeException(e);
}
return connection;
}
//编写方法,关闭资源
/*
* 可能需要关闭的资源
* 1.ResultSet
* 2.Statement 或者 PreparedStatement
* 因为Statement 是 PreparedStatement 的父类,所以用Statement接收参数
* 3.Connection
* 4.如果需要关闭资源就传入,否则传入null就行,也可以使用重载
* */
public static void close(ResultSet set, Statement statement,Connection connection){
try {
if (set != null) {
set.close();
}
if (statement != null) {
statement.close();
}
if (connection != null) {
connection.close();
}
} catch (SQLException e) {
//将编译异常转换为运行异常
throw new RuntimeException(e);
}
}
}
练习
public class JDBCUtils_use {
public static void main(String[] args) {
}
@Test
public void testDML(){
//Update,insert,delete
Connection connection = null;
//class com.mysql.cj.jdbc.ConnectionImpl
System.out.println(connection.getClass());
PreparedStatement preparedStatement = null;
try {
String sql = "insert into actor values(null,?,?,?,?)";
connection = JDBCUtils.getConnection();
preparedStatement = connection.prepareStatement(sql);
preparedStatement.setString(1,"milan");
preparedStatement.setString(2,"女");
preparedStatement.setString(3,"1989-12-03");
preparedStatement.setString(4,"456");
int i = preparedStatement.executeUpdate();
if (i == 1){
System.out.println("插入成功");
}else{
System.out.println("插入失败");
}
} catch (SQLException e) {
e.printStackTrace();
}finally {
JDBCUtils.close(null,preparedStatement,connection);
}
}
@Test
public void testDQL(){
Connection connection = null;
PreparedStatement preparedStatement = null;
ResultSet resultSet = null;
try {
String sql = "select * from actor where name = ?";
connection = JDBCUtils.getConnection();
preparedStatement = connection.prepareStatement(sql);
preparedStatement.setString(1,"milan");
resultSet = preparedStatement.executeQuery();
/*if (resultSet.next()){
System.out.println("查询成功");
}else{
System.out.println("查询失败");
}*/
//上面执行完之后已经在第一行,在执行一次就是查看第二行数据,所以有上面这里就不会执行
while (resultSet.next()){
int id = resultSet.getInt("id");
String name = resultSet.getString("name");
String sex = resultSet.getString("sex");
Date borndate = resultSet.getDate("borndate");
String phone = resultSet.getString("phone");
System.out.println(id+"\t"+name+"\t"+sex+"\t"+borndate+"\t"+phone);
}
} catch (SQLException e) {
e.printStackTrace();
}finally {
JDBCUtils.close(resultSet,preparedStatement,connection);
}
}
}
事务
基本介绍
- JDBC程序中当一个Connection对象创建成功时,默认情况下是自动提交事务,每次执行一个SQL语句时,如果执行成功,就会向数据库自动提交,而不能回滚
- JDBC程序中为了让多个SQL语句作为一个整体执行,需要使用事务
- 调用Connection的 setAutoCommit(false)可以取消自动提交事务
- 在所有的SQL语句都成功之后,调用 commit()方法提交事务
- 在其中某个操作失败或出现异常时,调用rollback()方法回滚事务
public class Transaction_ {
public static void main(String[] args) {
}
@Test
//不使用事务,操作转账的业务,在默认情况下,Connection对象是自动提交的
public void noTransaction(){
Connection connection = null;
PreparedStatement preparedStatement = null;
PreparedStatement preparedStatement1 = null;
try {
String sql = "UPDATE account set balance = balance - 100 where name = ?";
String sql1 = "UPDATE account set balance = balance + 100 where name = ?";
connection = JDBCUtils.getConnection();
//第一条sql
preparedStatement = connection.prepareStatement(sql);
preparedStatement.setString(1,"马云");
int i = preparedStatement.executeUpdate();
if (i == 1){
System.out.println("减少成功");
}else{
System.out.println("减少失败");
}
int a = 1/0;//抛出异常 ,出现异常,只减不增
//第二条sql
preparedStatement1 = connection.prepareStatement(sql1);
preparedStatement1.setString(1,"马化腾");
int i1 = preparedStatement1.executeUpdate();
if (i1 == 1){
System.out.println("增加成功");
}else{
System.out.println("增加失败");
}
} catch (SQLException e) {
e.printStackTrace();
}finally {
JDBCUtils.close(null,preparedStatement,connection);
JDBCUtils.close(null,preparedStatement1,null);
}
}
@Test
//使用事务,操作转账的业务
public void useTransaction(){
Connection connection = null;
PreparedStatement preparedStatement = null;
PreparedStatement preparedStatement1 = null;
try {
String sql = "UPDATE account set balance = balance - 100 where name = ?";
String sql1 = "UPDATE account set balance = balance + 100 where name = ?";
connection = JDBCUtils.getConnection();
//将connection设置为不自动提交
connection.setAutoCommit(false);
//第一条sql
preparedStatement = connection.prepareStatement(sql);
preparedStatement.setString(1,"马云");
int i = preparedStatement.executeUpdate();
if (i == 1){
System.out.println("减少成功");
}else{
System.out.println("减少失败");
}
//int a = 1/0;//抛出异常 ,出现异常,只减不增
//第二条sql
preparedStatement1 = connection.prepareStatement(sql1);
preparedStatement1.setString(1,"马化腾");
int i1 = preparedStatement1.executeUpdate();
if (i1 == 1){
System.out.println("增加成功");
}else{
System.out.println("增加失败");
}
//这里提交事务
connection.commit();
} catch (Exception e) {
//这里需要对异常进行方法,不然没有捕获到 算术异常
//这里我们有机会进行回滚,即撤销执行的sql
System.out.println("sql执行,遇到问题,回滚到初始状态");
try {
connection.rollback();//默认回滚到开始状态
} catch (SQLException throwables) {
throwables.printStackTrace();
}
e.printStackTrace();
}finally {
JDBCUtils.close(null,preparedStatement,connection);
JDBCUtils.close(null,preparedStatement1,null);
}
}
}
批处理
基本介绍
- 当需要成批插入或者更新记录时,可以采用java的批量更新机制,这一机制允许多条语句一次性提交给数据库批量处理,通过情况下比单独提交处理更有效率
- JDBC的批量处理语句包括下面方法
- addBatch():添加需要批量处理的SQL语句或参数
- executeBatch():执行批量处理语句
- clearBath():清空批处理包的语句
- JDBC连接Mysql时,如果要使用批处理功能,请在 url 中加入参数 (rewriteBatchedStatements=true)
- 批处理往往和PreparedStatement一起搭配使用,既可以减少编译次数,又减少运行次数,效率大大提高
- 需要关闭自动提交事务功能 connection.setAutoCommit(false),批处理才会生效
public class Batch_ {
public static void main(String[] args) {
}
@Test
//传统方法,添加5000条数据
public void noBatch(){
PreparedStatement preparedStatement =null;
Connection connection = null;
try {
connection = JDBCUtils.getConnection();
String sql = "insert into account values(null,?,?)";
preparedStatement = connection.prepareStatement(sql);
System.out.println("开始执行");
long l1 = System.currentTimeMillis();
for (int j = 0; j < 5000; j++) {
preparedStatement.setString(1,"张飞" +j);
preparedStatement.setDouble(2,9000 + j);
int result = preparedStatement.executeUpdate();
}
long l2 = System.currentTimeMillis();
System.out.println(l2 - l1);
} catch (Exception e) {
e.printStackTrace();
}finally {
JDBCUtils.close(null,preparedStatement,connection);
}
}
@Test
//使用batch,添加5000条数据,需要关闭自动提交事务才能真正执行批处理操作
public void useBatch(){
PreparedStatement preparedStatement =null;
Connection connection = null;
try {
connection = JDBCUtils.getConnection();
connection.setAutoCommit(false);
String sql = "insert into account values (null,?,?)";
preparedStatement = connection.prepareStatement(sql);
System.out.println("开始执行");
long l1 = System.currentTimeMillis();
for (int j = 0; j < 5000; j++) {
preparedStatement.setString(1,"张飞" +j);
preparedStatement.setDouble(2,9000 + j);
int result = preparedStatement.executeUpdate();
//将 sql 语句加入到批处理包中
preparedStatement.addBatch();
//当有一千条记录时,在批量执行
if ((j+1) % 1000 == 0){
preparedStatement.executeBatch();
//清空一下
preparedStatement.clearBatch();
}
}
connection.commit();
long l2 = System.currentTimeMillis();
System.out.println(l2 - l1);
} catch (Exception e) {
try {
connection.rollback();
} catch (SQLException throwables) {
throwables.printStackTrace();
}
e.printStackTrace();
}finally {
JDBCUtils.close(null,preparedStatement,connection);
}
}
}
//1.创建 ArrayList - elementData => Object[]
//2.elementData =>Object[] 就会存放我们预处理的sql语句
//3.当elementData满后,就按照1.5扩容
//4.当添加到指定的值后,就executeBatch
//5.批量处理会减少我们发送sql语句的网络开销,而且较少编译次数,因此效率提高
底层数据是存储在 batchedArgs(ArrayList数组) 里面的 elementData 里面,1.5倍扩容数组容量
数据库连接池
传统获取Connection问题分析
- 传统的JDBC数据库连接使用DriverManager来获取,每次向数据库建立连接的时候都要讲 Connection 加载到内存中,再验证IP地址,用户名和密码(0.05s~1s时间)。需要数据库连接的时候就向数据库要求一个,频繁的进行数据库连接操作将占用很多的系统资源,容易造成服务器崩溃
- 每一次数据库连接,使用完后都得断开,如果程序出现异常而未能关闭,讲导致数据库内存泄漏,最终将导致重启数据库
- 传统获取连接得方式,不能控制创建得连接数量,如连接过多,也可能导师内存泄漏,Mysql崩溃
- 解决传统开发中的数据库连接问题,可以采用数据库连接池技术
数据库连接池的基本介绍
- 预先在缓冲池中放入一定数量的连接,当需要建立数据库连接时,只需从”缓冲池“中取出一个,使用完毕之后再放回去
- 数据库连接池负责分配,管理和释放数据库连接,它允许应用程序重复使用一个现有的数据库连接,而不是重新建立一个
- 当应用程序向连接池请求的连接数超过最大连接数量时,这些请求将被加入到等待队列中
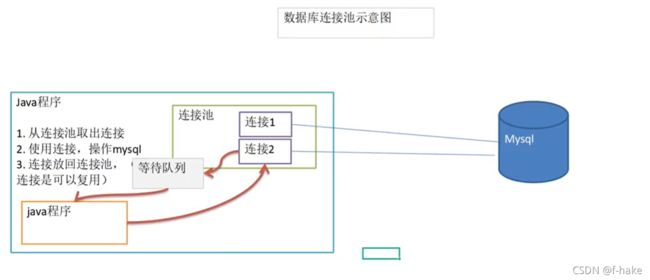
数据库连接池种类
- JDBC的数据库连接池使用java.sql.DataSource 来表示,DataSource 只是一个接口,该接口通常由第三方提供实现[提供.jar包]
- C3P0 数据库连接池,速度相对较慢,稳定性不错
- DBCP数据库连接池,速度相对 C3P0较快,但不稳定
- Proxool数据库连接池,有监控连接池状态的功能,稳定性较C3P0差一点
- BoneCP数据库连接池,速度快
- **Druid(德鲁伊)**是阿里提供的数据库连接池,集DBCP,C3P0,Proxool优点于一身的数据库连接池
C3P0数据库连接池
需要先把jar包放到libs文件夹中,然后添加到项目中
public class C3P0_ {
@Test
//方式一:相关参数,在程序中指定
public void testC3P0_01(){
//1.创建一个数据源对象
ComboPooledDataSource comboPooledDataSource = new ComboPooledDataSource();
//2.通过配置文件mysql.properties获取相关信息
Properties properties = new Properties();
try {
properties.load(new FileInputStream("src/mysql.properties"));
String user = properties.getProperty("user");
String password = properties.getProperty("password");
String driver = properties.getProperty("driver");
String url = properties.getProperty("url");
//给数据源 comboPooledDataSource 设置相关的参数
//注意:连接管理是由 comboPoolDataSource 来管理
comboPooledDataSource.setDriverClass(driver);
comboPooledDataSource.setJdbcUrl(url);
comboPooledDataSource.setUser(user);
comboPooledDataSource.setPassword(password);
//设置初始化连接数,具体的数量根据项目来调整
comboPooledDataSource.setInitialPoolSize(10);
//设置最大连接数
comboPooledDataSource.setMaxPoolSize(50);
long l = System.currentTimeMillis();
for (int i = 0; i < 5000; i++) {
Connection connection = comboPooledDataSource.getConnection();
connection.close();
}
//这个方法就是从 DataSource 接口实现
/*Connection connection = comboPooledDataSource.getConnection();
System.out.println("连接ok");
connection.close();*/
long l1 = System.currentTimeMillis();
System.out.println(l1 - l);
} catch (Exception e) {
throw new RuntimeException(e);
}
}
@Test
//第二种方式,使用配置文件模板来完成
//1.将c3p0 提供的 c3p0-config.xml 拷贝到 src 下
//2.该文件指定了连接数据库和连接池的相关参数
public void testC3P0_02(){
try {
ComboPooledDataSource cygMysql = new ComboPooledDataSource("cygMysql");
long l = System.currentTimeMillis();
for (int i = 0; i < 5000; i++) {
Connection connection = cygMysql.getConnection();
connection.close();
}
/*ComboPooledDataSource cygMysql = new ComboPooledDataSource("cygMysql");
Connection connection = cygMysql.getConnection();
System.out.println("连接成功~");
connection.close();*/
long l1 = System.currentTimeMillis();
System.out.println(l1 - l);
} catch (SQLException e) {
e.printStackTrace();
}
}
}
Druid(德鲁伊)数据库连接池
- 先将Druid德鲁伊的jar包复制到libs包下,然后添加到项目中
- 将Druid的配置文件拷贝到src下
public class Druid_ {
@Test
public void testDruid(){
//1.加入druid jar包
//2.加入配置文件 druid.properties , 将该文件拷贝到项目的src目录下
try {
//3.创建 Properties 对象,读取配置文件
Properties properties = new Properties();
properties.load(new FileInputStream("src/druid.properties"));
//4.创建一个指定参数的数据库连接池
DataSource dataSource = DruidDataSourceFactory.createDataSource(properties);
long l = System.currentTimeMillis();
for (int i = 0; i < 5000; i++) {
//5.得到连接
Connection connection = dataSource.getConnection();
//System.out.println("连接成功");
connection.close();
}
long l1 = System.currentTimeMillis();
System.out.println(l1 - l);
/*//5.得到连接
Connection connection = dataSource.getConnection();
System.out.println("连接成功");
connection.close();*/
} catch (Exception e) {
throw new RuntimeException(e);
}
}
}
测试
public class JDBCUtilsByDruid_user {
public static void main(String[] args) {
Connection connection = null;
PreparedStatement preparedStatement = null;
ResultSet resultSet = null;
try {
String sql = "select * from actor where name = ?";
connection = JDBCUtilsByDruid.getConnection();
//class com.alibaba.druid.pool.DruidPooledConnection
System.out.println(connection.getClass());
preparedStatement = connection.prepareStatement(sql);
preparedStatement.setString(1,"milan");
resultSet = preparedStatement.executeQuery();
/*if (resultSet.next()){
System.out.println("查询成功");
}else{
System.out.println("查询失败");
}*/
//上面执行完之后已经在第一行,在执行一次就是查看第二行数据,所以有上面这里就不会执行
while (resultSet.next()){
int id = resultSet.getInt("id");
String name = resultSet.getString("name");
String sex = resultSet.getString("sex");
Date borndate = resultSet.getDate("borndate");
String phone = resultSet.getString("phone");
System.out.println(id+"\t"+name+"\t"+sex+"\t"+borndate+"\t"+phone);
}
} catch (SQLException e) {
e.printStackTrace();
}finally {
JDBCUtilsByDruid.close(resultSet,preparedStatement,connection);
}
}
}
Apache-DBUtils
先分析一个问题
- 关闭connection后,resultSet结果集无法使用
- resultSet不利于数据的管理
- 示意图
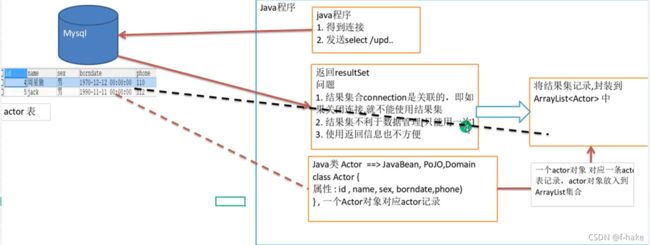
使用土方法来解决ResultSet = 封装 => ArrayList
public ArrayList<Actor> testApacheDBUtils(){
Connection connection = null;
PreparedStatement preparedStatement = null;
ResultSet resultSet = null;
ArrayList<Actor> arrayList = new ArrayList<>();
try {
String sql = "select * from actor where name = ?";
connection = JDBCUtilsByDruid.getConnection();
//class com.alibaba.druid.pool.DruidPooledConnection
System.out.println(connection.getClass());
preparedStatement = connection.prepareStatement(sql);
preparedStatement.setString(1,"milan");
resultSet = preparedStatement.executeQuery();
//上面执行完之后已经在第一行,在执行一次就是查看第二行数据,所以有上面这里就不会执行
while (resultSet.next()){
int id = resultSet.getInt("id");
String name = resultSet.getString("name");
String sex = resultSet.getString("sex");
Date borndate = resultSet.getDate("borndate");
String phone = resultSet.getString("phone");
//System.out.println(id+"\t"+name+"\t"+sex+"\t"+borndate+"\t"+phone);
//将得到的 resultSet 的记录,封装到 Actor 对象,放入到 arrayList 集合中
arrayList.add(new Actor(id,name,sex,borndate,phone));
}
System.out.println("arrayList集合:" + arrayList);
} catch (SQLException e) {
e.printStackTrace();
}finally {
JDBCUtilsByDruid.close(resultSet,preparedStatement,connection);
}
//因为ArrayList和Connection没有任何关联,所以该集合可以复用
return arrayList;
}
基本介绍
- commons-dbutils是Apache组织提供的一个开源JDBC工具类库,它是对JDBC的封装,使用dbutils能极大简化jdbc编码的工作量
DbUtils类的介绍
- QureyRunner类,该类封装了SQL的执行,是线程安全的,可以实现增、删、改、查、批处理
- RusultSetHandler接口:改接口用于处理java.sql.ResultSet,将数据按要求转换为另一种形式

应用实例
使用DBUtils+数据库连接池(druid)方法,完成对表actor的 crud 操作
/**
* 使用(Apache)DBUtils+数据库连接池(druid)方法,完成对表actor的 crud 操作
* @author cyg
* @create 2021-09-01 9:50
*/
public class DBUtils_user {
@Test
//返回结果是多行的形式
public void testQueryMany() throws SQLException {
//1.得到 connection
Connection connection = JDBCUtilsByDruid.getConnection();
//2.使用 DBUtils 类和接口,先引入 DBUtils 相关的jar文件,加入到本项目中
//3.创建一个QueryRunner
QueryRunner queryRunner = new QueryRunner();
//queryRunner就可以执行相关的方法,返回ArrayList 结果集
String sql = "select id,name,sex,phone from actor where id >= ?";
//query就是执行一个sql语句,得到ResultSet并封装到ArrayList集合中,返回集合
//connection:连接
//sql:sql语句
//new BeanListHandler<>(Actor.class):将ResultSet -> Actor对象 -> 封装到ArrayList
//Actor.class:底层需要使用反射机制去调用Actor,所以Actor需要无参构造
// 1 :就是传给sql语句的值,可以传入多个(可变形参)
//query底层已经将Result关闭了,所以释放资源时,不用在关闭ResultSet了
//query底层会创建并关闭PreparedStatement,所以释放资源时,不用在关闭PreparedStatement
//这里出现问题,无法将查询出来 borndate 赋值给 Actor 中的 borndate属性(Date类型)
//查询之后好像是因为新旧版本对于Date的识别问题
List<Actor> list =
queryRunner.query(connection, sql, new BeanListHandler<>(Actor.class),1);
System.out.println("输出集合的信息");
for (Actor actor : list) {
System.out.println(actor);
}
/*
* public T query(Connection conn, String sql, ResultSetHandler rsh, Object... params) throws SQLException {
PreparedStatement stmt = null;
ResultSet rs = null;
Object result = null;
try {
stmt = this.prepareStatement(conn, sql);
this.fillStatement(stmt, params);
rs = this.wrap(stmt.executeQuery());
result = rsh.handle(rs);
} catch (SQLException var33) {
this.rethrow(var33, sql, params);
} finally {
try {
this.close(rs);
} finally {
this.close((Statement)stmt);
}
}
return result;
}
*
* */
JDBCUtilsByDruid.close(null,null,connection);
}
@Test
//返回结果是单行记录
public void testQuerySingle() throws SQLException {
//1.得到 connection
Connection connection = JDBCUtilsByDruid.getConnection();
//2.使用 DBUtils 类和接口,先引入 DBUtils 相关的jar文件,加入到本项目中
//3.创建一个QueryRunner
QueryRunner queryRunner = new QueryRunner();
//queryRunner就可以执行相关的方法,返回单个对象
String sql = "select id,name,sex,phone from actor where id = ?";
//因为我们返回的是单个记录<-->单个对象,使用的Handler 是 BeanHandler
Actor actor = queryRunner.query(connection, sql, new BeanHandler<>(Actor.class), 4);
System.out.println(actor);
JDBCUtilsByDruid.close(null,null,connection);
}
@Test
//返回结果是单行单列的情况(object)
public void testQueryScalar() throws SQLException {
//1.得到 connection
Connection connection = JDBCUtilsByDruid.getConnection();
//2.使用 DBUtils 类和接口,先引入 DBUtils 相关的jar文件,加入到本项目中
//3.创建一个QueryRunner
QueryRunner queryRunner = new QueryRunner();
//queryRunner就可以执行相关的方法,返回单个对象
String sql = "select name from actor where id = ?";
//因为我们返回的是一个数据,使用的Handler 是 ScalarHandler
Object Object = queryRunner.query(connection, sql, new ScalarHandler(), 4);
System.out.println(Object);
JDBCUtilsByDruid.close(null,null,connection);
}
@Test
//演示DML操作,增加,删除,修改
public void testDML() throws SQLException {
Connection connection = JDBCUtilsByDruid.getConnection();
QueryRunner queryRunner = new QueryRunner();
String sql = "insert into actor values(null,?,?,?,?)";
int affectedRow = queryRunner.update(connection, sql, "cyg","男","1996-09-21","1870");
if (affectedRow == 1) {
System.out.println("新增成功");
}else{
System.out.println("操作失败");
}
JDBCUtilsByDruid.close(null,null,connection);
}
}
表和javaBean的类型映射关系
int----Integer
char,varchar-----String
DateTime-------Date/String
需要注意:在高版本中,DateTime-----Date已经不匹配了
Dao和增删改查通过方法-BasicDao
先分析一个问题
apache-dbutils+druid简化了jdbc开发,但还有不足
- SQL语句是固定的,不能通过参数传入,通用性不好,需要进行改进,更方便执行 增删改查
- 对于select操作,如果有返回值,返回类型不能固定,需要使用泛型
- 将来的表很多,业务需求复杂,不可能只靠一个Java类完成
- 引出----> BasicDao 画出示意图,看看在实际开发,应该如何处理
基本说明:
- DAO:data access object数据访问对象
- 这样的通用类,称为 BasicDao ,是专门和数据库交互的,即完成对数据库(表)的crud操作
- 在BasicDao 的基础上,实现一张表 对应一个Dao,更好的完成功能,比如 Customer表–Customer.java类(javaBean)–CustomerDao.java
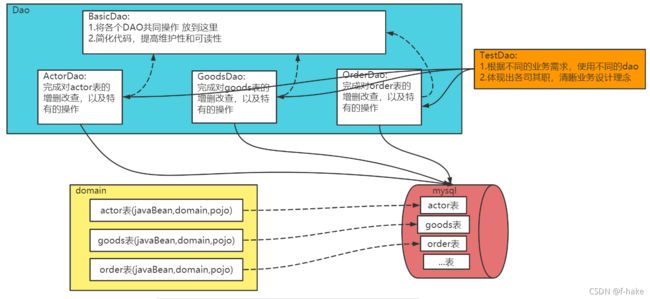
/**
* 基于Druid数据库连接池的工具类
* @author cyg
* @create 2021-09-01 9:37
*/
@SuppressWarnings("all")
public class JDBCUtilsByDruid {
private static DataSource dataSource;
//在静态代码块,完成dataSource的初始化
static{
try {
Properties properties = new Properties();
properties.load(new FileInputStream("src/druid.properties"));
dataSource = DruidDataSourceFactory.createDataSource(properties);
} catch (Exception e) {
throw new RuntimeException(e);
}
}
public static Connection getConnection(){
Connection connection = null;
try {
connection = dataSource.getConnection();
} catch (SQLException e) {
throw new RuntimeException(e);
}
return connection;
}
//这里的close并不是真正的关闭,而是将 connection 引用连接断开放回到 连接池当中
public static void close(ResultSet resultSet, Statement statement,Connection connection){
try {
if (resultSet != null) {
resultSet.close();
}
if (statement != null) {
statement.close();
}
if (connection != null) {
connection.close();
}
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
}
/**
* Actor对象和 actor 表的记录对应
* @author cyg
* @create 2021-09-01 10:17
*/
public class Actor {
private Integer id;
private String name;
private String sex;
private Date borndate;
private String phone;
public Actor() {
//一定要给一个无参构造器(反射需要)
}
public Actor(Integer id, String name, String sex, Date borndate, String phone) {
this.id = id;
this.name = name;
this.sex = sex;
this.borndate = borndate;
this.phone = phone;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
}
public Date getBorndate() {
return borndate;
}
public void setBorndate(Date borndate) {
this.borndate = borndate;
}
public String getPhone() {
return phone;
}
public void setPhone(String phone) {
this.phone = phone;
}
@Override
public String toString() {
return "Actor{" +
"id=" + id +
", name='" + name + '\'' +
", sex='" + sex + '\'' +
", borndate=" + borndate +
", phone='" + phone + '\'' +
'}';
}
}
/**
* 开发BasicDao,是其它DAO的父类
* @author cyg
* @create 2021-09-01 15:42
*/
@SuppressWarnings("all")
public class BasicDao<T> {
//泛型指定具体类型
private QueryRunner qr = new QueryRunner();
//开发通用的dml方法,针对任意的表
public int update(String sql , Object... parameters){
Connection connection = null;
try {
connection = JDBCUtilsByDruid.getConnection();
int accessedRow = qr.update(connection, sql, parameters);
return accessedRow;
} catch (SQLException e) {
throw new RuntimeException(e);
}finally {
JDBCUtilsByDruid.close(null,null,connection);
}
}
//返回多个对象(多行数据),针对任意的表
//clazz 表示传入一个类的Class对象
public List<T> queryMulti(String sql , Class<T> clazz, Object... parameters){
Connection connection = null;
List<T> list = new ArrayList<>();
try {
connection = JDBCUtilsByDruid.getConnection();
list = qr.query(connection, sql, new BeanListHandler<T>(clazz), parameters);
return list;
} catch (SQLException e) {
throw new RuntimeException(e);
}finally {
JDBCUtilsByDruid.close(null,null,connection);
}
}
//返回单个对象(一行数据),针对任意的表
public T querySingle(String sql , Class<T> clazz, Object... parameters){
Connection connection = null;
try {
connection = JDBCUtilsByDruid.getConnection();
T t = qr.query(connection, sql, new BeanHandler<T>(clazz), parameters);
return t;
} catch (SQLException e) {
throw new RuntimeException(e);
}finally {
JDBCUtilsByDruid.close(null,null,connection);
}
}
//返回单个数据,针对任意的表
public Object queryScalar(String sql, Object... parameters){
Connection connection = null;
try {
connection = JDBCUtilsByDruid.getConnection();
Object o = qr.query(connection, sql, new ScalarHandler(), parameters);
return o;
} catch (SQLException e) {
throw new RuntimeException(e);
}finally {
JDBCUtilsByDruid.close(null,null,connection);
}
}
}
/**
* @author cyg
* @create 2021-09-01 16:08
*/
public class ActorDao extends BasicDao<Actor>{
//就有Basic的方法
//根据业务需求,可以编写特有的方法
}
/**
* @author cyg
* @create 2021-09-01 16:09
*/
public class TestDao {
public static void main(String[] args) {
//测试ActorDao对actor表的crud操作
ActorDao actorDao = new ActorDao();
//查询多行记录 where id >= ?
/*String sql = "select id,name,sex,phone from actor";
List actors = actorDao.queryMulti(sql, Actor.class);
for (Actor actor : actors) {
System.out.println(actor);
}*/
//查询单行记录
/*String sql = "select id,name,sex,phone from actor where id = ?";
Actor actor = actorDao.querySingle(sql, Actor.class, 2);
System.out.println(actor);*/
//查询单个数据
/*String sql = "select count(1) from actor";
Object o = actorDao.queryScalar(sql);
System.out.println(o);*/
//增加数据
/*String sql = "insert into actor values(null,?,?,?,?)";
int result = actorDao.update(sql, "zsw", "女", "1996-6-13", "157");
System.out.println(result);*/
//修改数据
/*String sql = "Update actor set name = ? where id = ?";
int result = actorDao.update(sql, "haha", 1);
System.out.println(result);*/
//删除数据
String sql = "delete from actor where id = ?";
int result = actorDao.update(sql, 7);
System.out.println(result);
}
}
/**
* @author cyg
* @create 2021-09-01 16:08
*/
public class ActorDao extends BasicDao<Actor>{
//就有Basic的方法
//根据业务需求,可以编写特有的方法
}
/**
* @author cyg
* @create 2021-09-01 16:09
*/
public class TestDao {
public static void main(String[] args) {
//测试ActorDao对actor表的crud操作
ActorDao actorDao = new ActorDao();
//查询多行记录 where id >= ?
/*String sql = "select id,name,sex,phone from actor";
List actors = actorDao.queryMulti(sql, Actor.class);
for (Actor actor : actors) {
System.out.println(actor);
}*/
//查询单行记录
/*String sql = "select id,name,sex,phone from actor where id = ?";
Actor actor = actorDao.querySingle(sql, Actor.class, 2);
System.out.println(actor);*/
//查询单个数据
/*String sql = "select count(1) from actor";
Object o = actorDao.queryScalar(sql);
System.out.println(o);*/
//增加数据
/*String sql = "insert into actor values(null,?,?,?,?)";
int result = actorDao.update(sql, "zsw", "女", "1996-6-13", "157");
System.out.println(result);*/
//修改数据
/*String sql = "Update actor set name = ? where id = ?";
int result = actorDao.update(sql, "haha", 1);
System.out.println(result);*/
//删除数据
String sql = "delete from actor where id = ?";
int result = actorDao.update(sql, 7);
System.out.println(result);
}
}