python爬虫实战之爬取中国农药网
前言:这算是和研究生老师第一次正式的进行项目,虽说开始的有点随便,但是第二战还是挺成功的!自己作为一个本科生,也很幸运可以跟着学点知识,随便帮自己学院的老师出点力。还记得第一次交接任务时是和陈瑞学长,初战《贵州农经网》,还算成功,后来由于需要分类,暂时告一段落。
这次的目标是《中国农药网》,这是一个农药行业门户网站,集信息资讯、农药信息,交易服务于一体的专业化、电子商务平台。我主要就是获取到某类农药的具体信息,如:名称,品牌,生产许可证,预防对象,农药登记号等信息
文章目录
- 1、分析目标
-
- 1.1、实现思路
- 1.2、思路解析
- 2、使用正则匹配商品信息
-
- 2.1、请求网页源码
- 2.2、分析网页
- 2.3、匹配网页信息
-
- 2.3.1、网页预处理
- 2.3.2、匹配信息测试与方法改进
-
- 2.3.2.1、普通匹配信息测试
- 2.3.2.2、替换中英文符号的重要性
- 2.3.2.3、结束标签的选择
- 2.3.2.4、模糊定位匹配
- 2.4、匹配全部信息源代码汇总
- 3、使用BS4爬取主页信息
-
- 3.1、requests请求数据
- 3.2、两次提取数据失败
- 3.3、提取数据成功
- 3.4、构造所有首页路径
- 3.5、随机模拟不同的客户端
- 4、所有源码汇总
1、分析目标
这个项目初步看起来有点棘手,但也不是很难,主要是它和很多网页不一样的是,它的商品信息介绍不规范,详细信息是由厂家自己写上去的,所有只能使用正则表达式去匹配到关键词,再获取信息。
1.1、实现思路
可以把这个网站分为子页和主页两个先分开进行,分别写好对应的代码后,再把它进行合并。这样会更方便对网页的解析学习,从而提升开发效率。
1.2、思路解析
我需要先从主页面获取到每个商品的具体链接,然后通过这个链接请求到网页源代码,再进行相关信息匹配。
首页如图示:

从这里我们可以看到它信息都是以列表的形式来显现的,并且很规范,对于这样的信息,是非常容易拿到手的。
我从这里获取到一个商品的链接后,就可以进去它的详细页面了,如图:


通过对几个页面的信息进行比较,会发现这些信息的排布并没有规律,标签也不统一,直接就是用户自己描述的,但是它们信息的关键词没有多大的变化,所有可以使用正则表达式来进行匹配到相关信息。
2、使用正则匹配商品信息
2.1、请求网页源码
这个网站没有反爬虫的措施,我直接使用requests请求网页源码,不需要做任何伪装,拿到源码并没有任何难度。
import requests
url = "http://www.agrichem.cn/u850386/2019/02/22/ny1535604683.shtml"
html = requests.get(url).text
print(html)
建议拿到网页源码后,先别忙着去提取信息,最好先检查结果一下是否包含我们需要的信息:
2.2、分析网页
为什么要分析网页?分析网页的目的就是为了选择恰当的方法拿到更准确的信息,特别是对于这种没有规则的网站,非常有必要进行详细的分析。通过Ctrl+F实现查找,有时候可以本身是存在的,但是就没有检索到结果,这时候就有必要检查一下符号是否中英文一致了,或者缺少空格之类的,建议用来查找的关键词字数不要太多!

2.3、匹配网页信息
这个地方最好的方式是选择正则表达式来匹配信息,简单的介绍一下正的用法,比如我截取的这个代码片段来提取信息:
html = """
品牌: 诺尔特成分含量: 1%-30%包装规格: 25毫升+2包助剂净重: 0.02kg毒性: 低毒剂型: 乳油农药成分: 烯草酮农药类型: 有机农药农药登记证号: PD20132201

"""
- 从上面的信息来看,我们要提取的信息都有很关键的分隔标记,比如
:和,我们要的东西正好在这里面,但是该信息中有一些信息是多余的,如
2.3.1、网页预处理
(1) 先去掉干扰标签
" "
(2) 把英文:替换为中文:
html.replace(" ","").replace(":",":")
结果如下:

2.3.2、匹配信息测试与方法改进
现在虽然文中还有\n和空格,但是已经不会影响我们匹配信息了,正则表达式的简单运用,掌握.*?就可以要到自己想要的信息了。
2.3.2.1、普通匹配信息测试
使用方法:.*?代替不需要的部分+关键标记+(.*?)需要提取的信息+关键标记,如下例所示:
找到品牌:
import re
re.findall('.*?品牌:(.*?).*?',html)#品牌
#运行结果
['诺尔特']
找到毒性:

找到图片链接:
import re
re.findall('.*?src="(.*?)".*?',html)

2.3.2.2、替换中英文符号的重要性
这样爬取信息很方便吧?但是问题来了,你有没有想过关键词的后面符号是中文状态,或者是英文状态,它不就匹配不了了吗?如:

重点: 所以在拿到这个网页源码的时候,必须先它的英文符号:替换为中文的:,统一字符,方便定位信息。
2.3.2.3、结束标签的选择
从上文来看,我们对文字信息选择的结束标签都是,替换掉我们要匹配的关键词,似乎都能完成我们所要匹配的任务,但是如果我们要匹配的信息在该段落后面呢,这样它的结束标签是
import re
html = """农药登记证号:PD20132201"""
re.findall('.*?农药登记证号:(.*?).*?',html)
#输出结果:
[]
改进方法:
re.findall('.*?农药登记证号:(.*?),html)
重点: 我们选择结束标签时必须要选择所有关键词都共同拥有的结束标记,这样无论是还是
2.3.2.4、模糊定位匹配
- 为什么还要进行模糊定位匹配呢?
主要是因为用户上传的说明千奇百怪,好在关键词不离其中,或者关键词不在末尾和ming
案例1:
如“农药登记证号:”,有些用户写成“产品登记证号”,所有就只能选择“登记证号:”作为关键词
import re
html = """**登记证号:PD20132201"""
re.findall('.*?登记证号:(.*?),html)
#运行结果:
['PD20132201']
案例2:
如“生产许可证”在有些地方又叫“产品标准号”,所以必须要考虑到,并且不能把:作为关键字符,防止它关键词在中间匹配不到信息,最后匹配到的信息,以:作为定位符切割数据。如图:

提取方式:
html = """农药生产许可证/批准文号:HNP32224-D3889"""
standard = re.findall('.*?生产许可证(.*?),html)#生产许可证号
if len(standard) ==0:
standard = re.findall('.*?产品标准号(.*?),html)#生产许可证号
if len(standard) !=0:
standard = str(standard[0]).split(':')[-1]#[-1]表示向右边截取所有数据
print(standard)
输出结果:
HNP32224-D3889
2.4、匹配全部信息源代码汇总
import requests,re,time
from lxml import etree
start = time.time()
url = "http://www.agrichem.cn/u850386/2019/02/22/ny1535604683.shtml"
html = requests.get(url).text
etrees = etree.HTML(html)
good_type = etrees.xpath('/html/body/div[3]/div[1]/a[last()-1]/text()')#投入品类型
input_name = etrees.xpath('/html/body/div[3]/div[1]/a[last()]/text()')#投入品名称
html = html.replace(" ","").replace(":",":")
brank = re.findall('.*?品牌:(.*?),html)#品牌
if len(brank) == 0:
brank = re.findall('.*?名称:(.*?),html)#品牌
standard = re.findall('.*?生产许可证(.*?),html)#生产许可证号
if len(standard) ==0:
standard = re.findall('.*?产品标准号(.*?),html)#生产许可证号
if len(standard) !=0:
standard = str(standard[0]).split(':')[-1]
prevention = re.findall('.*?防治对象:(.*?),html)#防治对象
toxicity = re.findall('.*?毒性:(.*?),html)#毒性
register = re.findall('.*?登记证号(.*?),html)#农药登记证号
if len(register) != 0:
register = str(register[0]).split(':')[-1]
print (good_type,input_name,brank,standard,prevention,toxicity,register)
end = time.time()
use_time = (end-start)/60
print ("您所获获取的信息一共使用%s分钟"%use_time)
输出结果:
['除草剂'] ['烯草酮'] ['诺尔特'] [] [] ['低毒'] PD20132201
您所获获取的信息一共使用0.14976612329483033分钟
3、使用BS4爬取主页信息
刚开始我还以为这个页面的信息很容易爬取到,因为它对源码没有反爬措施,但是,它对信息的提取就有了很大的限制,就相当于给你HTML源码,但是不让你筛选信息,否则就隐藏自己的数据,我也是第一次见这种情况,还是花了一点时间才搞定的
3.1、requests请求数据
import requests
index = "http://www.agrichem.cn/nylistpc/%E5%86%9C%E8%B5%84-%E5%86%9C%E8%8D%AF-%E6%9D%80%E8%8F%8C%E5%89%82-----1-.htm?type=&isvip=&personreal=&companyreal="
indexHtml = requests.get(index).text
print(indexHtml)
成功拿到数据:

3.2、两次提取数据失败
- 然后我就开始顺手的使用lxml来解析网页提取数据了,但是经过多次测试,居然都失败了,这里就不描述了。。。
- 我开始使用正则表达式来提取信息,先来看看源网页:

- 总之,干扰项实在是太多,先去掉这些无用的东西吧
indexHtml = indexHtml.replace("\r\n","").replace("\t","")
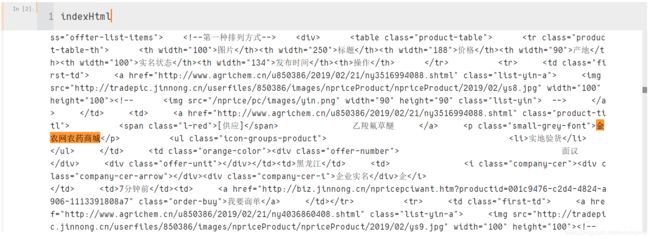
这里也是有点奇怪了,我昨天爬取时,先拿到了源码,主要是使用替换功能,它就把我需要的数据隐藏起来,今天居然可以看到数据了,继续。。。
- 用正则提取所有数据
import requests,re
index = "http://www.agrichem.cn/nylistpc/%E5%86%9C%E8%B5%84-%E5%86%9C%E8%8D%AF-%E9%99%A4%E8%8D%89%E5%89%82------.htm?type=&isvip=&personreal=&companyreal="
indexHtml = requests.get(index).text
indexHtml = indexHtml.replace("\r\n","").replace("\t","")
r = re.compile('.*class="first-td">.*?href="(.*?)".*?list-yin-a">.*?src="(.*?)".*?class="small-grey-font">(.*?)*(.*?) .*?')
name= re.findall(r,indexHtml)
print (name)
- 运行结果:
[('http://www.agrichem.cn/u850386/2019/02/21/ny4036860408.shtml', 'http://tradepic.jinnong.cn/userfiles/850386/images/npriceProduct/npriceProduct/2019/02/ys9.jpg', '金农网农药商城', '黑龙江')]
- 它居然就只拿到一条数据就不执行了!!!
3.3、提取数据成功
- 后来我把目标发放在BS4的上面,结果重要成功了!
import requests
from bs4 import BeautifulSoup
def get_html(index):
indexHtml = requests.get(index).text
remove(indexHtml)
def remove(indexHtml):
soup = BeautifulSoup(indexHtml, "html.parser")
for tr in soup.find_all('tr'):
try:
company = tr.find(attrs={
"class":"small-grey-font"}).get_text()#公司名称
good_link = tr.find_all('a')[0].get('href')#商品链接
address = tr.find_all('td')[3].get_text()#产地
good_pic = tr.find_all('img')[0].get('src')#图片路径
print (company,good_link,address,good_pic)
except:
print ("这是标题,没有找到数据")
if __name__ == '__main__':
index = "http://www.agrichem.cn/nylistpc/农资-农药-杀菌剂-----4-.htm?type=&isvip=&personreal=&companyreal="
get_html(index)
- 提取结果如下:
这是标题,没有找到数据
潍坊奥丰作物病害防治有限公司 http://www.agrichem.cn/u462913/2018/03/06/ny5758621412.shtml 山东 http://tradepic.jinnong.cn/userfiles/462913/images/npriceProduct/npriceProduct/2018/03/%E5%BE%AE%E4%BF%A1%E5%9B%BE%E7%89%87_20180207123707_%E5%89%AF%E6%9C%AC_%E5%89%AF%E6%9C%AC.jpg
潍坊奥丰作物病害防治有限公司 http://www.agrichem.cn/u462913/2018/03/19/ny2819540869.shtml 山东 http://tradepic.jinnong.cn/userfiles/462913/images/npriceProduct/npriceProduct/2018/11/C3A4BEC77F701DE5AFCC18B2831353B5.jpg
潍坊奥丰作物病害防治有限公司 http://www.agrichem.cn/u832227/2018/10/10/ny1423363037.shtml 山东 http://tradepic.jinnong.cn/userfiles/832227/images/npriceProduct/npriceProduct/2018/10/43b1OOOPICe7%20(1)_%E5%89%AF%E6%9C%AC22.jpg
河南卓美农业科技有限公司 http://www.agrichem.cn/u819902/2018/01/08/ny5108840639.shtml 河南 http://tradepic.jinnong.cn/userfiles/819902/_thumbs/images/npriceProduct/npriceProduct/2018/01/%E5%BE%AE%E4%BF%A1%E5%9B%BE%E7%89%87_20180106183557.jpg
河南卓美农业科技有限公司 http://www.agrichem.cn/u819902/2018/01/03/ny3604101956.shtml 河南 http://tradepic.jinnong.cn/userfiles/819902/_thumbs/images/npriceProduct/npriceProduct/2018/01/1-1G1141J10O48.jpg
潍坊奥丰作物病害防治有限公司 http://www.agrichem.cn/u462913/2018/03/19/ny4721304356.shtml 山东 http://tradepic.jinnong.cn/userfiles/462913/images/npriceProduct/npriceProduct/2018/11/LGICJ9%7B%25S3V%5BO9%40F)7L9%24OA_%E5%89%AF%E6%9C%AC.jpg
河南卓美农业科技有限公司 http://www.agrichem.cn/u819902/2018/01/07/ny4744431710.shtml 河南 http://tradepic.jinnong.cn/userfiles/819902/_thumbs/images/npriceProduct/npriceProduct/2018/01/%E5%BE%AE%E4%BF%A1%E5%9B%BE%E7%89%87_20180106183544.jpg
潍坊奥丰作物病害防治有限公司 http://www.agrichem.cn/u839662/2018/08/18/ny4431648810.shtml 江西 http://tradepic.jinnong.cn/userfiles/839662/images/npriceProduct/npriceProduct/2018/08/%E6%9E%9D%E5%B9%B2%E6%BA%83%E8%85%90%E7%81%B5.jpg
河南卓美农业科技有限公司 http://www.agrichem.cn/u819902/2018/01/03/ny0402204907.shtml 河南 http://tradepic.jinnong.cn/userfiles/819902/images/npriceProduct/npriceProduct/2018/01/1-1G1141J53S19.jpg
河南卓美农业科技有限公司 http://www.agrichem.cn/u819902/2018/01/03/ny4136385189.shtml 河南 http://tradepic.jinnong.cn/userfiles/819902/_thumbs/images/npriceProduct/npriceProduct/2018/01/1-1G1141JAU02.jpg
河南卓美农业科技有限公司 http://www.agrichem.cn/u819902/2018/01/03/ny2515692603.shtml 河南 http://tradepic.jinnong.cn/userfiles/819902/_thumbs/images/npriceProduct/npriceProduct/2018/01/1-1G1141K445D6.jpg
河南卓美农业科技有限公司 http://www.agrichem.cn/u819902/2018/01/03/ny4340308460.shtml 河南 http://tradepic.jinnong.cn/userfiles/819902/_thumbs/images/npriceProduct/npriceProduct/2018/01/1-1G1141K044W7.jpg
注意:
- 为什么这里要用
try:?
一方面来说,是为了防止标签或数据缺失而报错,只要的目的是跳过标题栏的数据,因为它的标签和正文的一样

它们都在tr标签之中,但是标题的内容是th,所有输出的数据为[ ],try:的目的数据跳过这些空值,当然也可以使用条件语句它判断它。
3.4、构造所有首页路径
for page in range(1,5,1):
index = "http://www.agrichem.cn/nylistpc/农资-农药-除草剂-----%s-.htm?type=&isvip=&personreal=&companyreal="%page
print ("正在爬取第%s个主页的信息"%page)
print(index)
运行结果:
正在爬取第1个主页的信息
http://www.agrichem.cn/nylistpc/农资-农药-除草剂-----1-.htm?type=&isvip=&personreal=&companyreal=
正在爬取第2个主页的信息
http://www.agrichem.cn/nylistpc/农资-农药-除草剂-----2-.htm?type=&isvip=&personreal=&companyreal=
正在爬取第3个主页的信息
http://www.agrichem.cn/nylistpc/农资-农药-除草剂-----3-.htm?type=&isvip=&personreal=&companyreal=
正在爬取第4个主页的信息
http://www.agrichem.cn/nylistpc/农资-农药-除草剂-----4-.htm?type=&isvip=&personreal=&companyreal=
3.5、随机模拟不同的客户端
如果需要使用模拟不同的客户端,可以使用fake_useragent随机生成UserAgent,但是在这里并须需要这个,可以简单的说下这个方法:
- 随机生成5个不同浏览器的UserAgent:
from fake_useragent import UserAgent
for i in range(5):
print(UserAgent().random)
生成结果:
Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/34.0.1847.116 Safari/537.36 Mozilla/5.0 (iPad; U; CPU OS 3_2 like Mac OS X; en-us) AppleWebKit/531.21.10 (KHTML, like Gecko) Version/4.0.4 Mobile/7B334b Safari/531.21.10
Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 5.2; Trident/4.0; Media Center PC 4.0; SLCC1; .NET CLR 3.0.04320)
Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/36.0.1985.67 Safari/537.36
Mozilla/5.0 (Windows NT 6.1; rv:6.0) Gecko/20100101 Firefox/19.0
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2227.1 Safari/537.36
- 随机生成5个谷歌浏览器的UserAgent:
from fake_useragent import UserAgent
for i in range(5):
print(UserAgent().chrome)
生成结果:
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1664.3 Safari/537.36
Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2226.0 Safari/537.36
Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/33.0.1750.517 Safari/537.36
Mozilla/5.0 (X11; OpenBSD i386) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/36.0.1985.125 Safari/537.36
Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/37.0.2049.0 Safari/537.36
4、所有源码汇总
import requests,re,csv,time
from lxml import etree
from bs4 import BeautifulSoup
start = time.time()
#创建CSV文件
fp = open('D:\\中国农药网.csv','a',newline='',encoding='utf-8')
writer = csv.writer(fp)
writer.writerow(('生成厂商','商品链接','投入品类型','投入品名称','品牌','生产许可证','预防对象','毒性','农药登记号','地址','图片链接')) #csv头部
def get_html(index):
indexHtml = requests.get(index).text
print ("~"*80)
soup = BeautifulSoup(indexHtml, "html.parser")
for tr in soup.find_all('tr'):
try:
company = tr.find(attrs={
"class":"small-grey-font"}).get_text()#公司名称
address = tr.find_all('td')[3].get_text()#产地
good_pic = tr.find_all('img')[0].get('src')#图片路径
good_link = tr.find_all('a')[0].get('href')#商品链接,并请求该链接
print ("-"*80)
try:
html = requests.get(good_link).text
etrees = etree.HTML(html)
good_type = etrees.xpath('/html/body/div[3]/div[1]/a[last()-1]/text()')[0]#投入品类型
input_name = etrees.xpath('/html/body/div[3]/div[1]/a[last()]/text()')[0]#投入品名称
html = html.replace(" ","").replace(":",":")
brank = re.findall('.*?品牌:(.*?),html)[0]#品牌
if len(brank) == 0:
brank = re.findall('.*?名称:(.*?),html)[0]#品牌
standard = re.findall('.*?生产许可证(.*?),html)[0]#生产许可证号
if len(standard) ==0:
standard = re.findall('.*?产品标准号(.*?),html)[0]#生产许可证号
if len(standard) !=0:
standard = str(standard).split(':')[-1]#截取:后面的所有数据
prevention = re.findall('.*?防治对象:(.*?),html)[0]#防治对象
toxicity = re.findall('.*?毒性:(.*?),html)[0]#毒性
register = re.findall('.*?登记证号(.*?),html)[0]#农药登记证号
if len(register) != 0:
register = str(register).split(':')[-1]
except:
pass
position = (company,good_link,good_type,input_name,brank,standard,prevention,toxicity,register,address,good_pic)
print (position)
writer.writerow((position))#写入数据
except:
print ("这是标题,没有找到数据")
pass
def main():
for page in range(1,8,1):
index = "http://www.agrichem.cn/nylistpc/农资-农药-除草剂-----%s-.htm?type=&isvip=&personreal=&companyreal="%page
print ("正在爬取第%s个主页的信息"%page)
get_html(index)
if __name__ == '__main__':
main()
end = time.time()
use_time = (end-start)/60
fp.close() #关闭文件
print ("您所获获取的信息一共使用%s分钟"%use_time)
编辑器运行结果截屏:

csv结果截屏:

总结:对于一个刚入门的小白来说,可能在爬某个网站的时候会遇见很多看是简单,但是很复杂的网页,反正先不要怕,试作把它细分,一步一步的来完成,多尝试用不同的库来解析网页,总会找到自己忽略掉的地方,这样才能不断的提升自己的能力!