Tesseract-OCR5.0软件安装和语言包安装(Windows系统)
原文链接:http://www.juzicode.com/image-tesseract-ocr5-install-on-windows
Tesseract是一款优秀的开源OCR软件,目前由Google维护改进,已发展到5.0版本,从4.0版本起增加了基于LSTM神经网络的识别引擎。今天聊聊怎么安装Tesseract命令行软件和语言包,正确配置Tesseract是制作自定义字体和使用其Python接口pytesseract的基础。
1、下载软件安装包
首先下载安装包,进入tesseract的github文档页(https://tesseract-ocr.github.io/tessdoc),找到5.0.0.x目录下的Binaries目录:
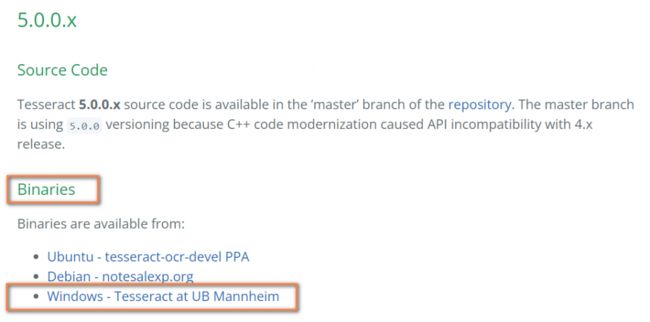
Binaries目录下包含多种操作系统的二进制安装包,以windows系统为例,进入“Windows – Tesseract at UB Mannheim”(https://github.com/UB-Mannheim/tesseract/wiki)下载安装包,这是一个第三方制作的安装包,当前(2021.11)最新版本为5.0.0:

你也可以进入第三方的官网Index of /tesseract找到各种历史版本下载。
2、下载语言包
下一步下载语言包,进入tesseract的github文档页(https://tesseract-ocr.github.io/tessdoc),找到5.0.0.x目录下的Traineddata Files目录:

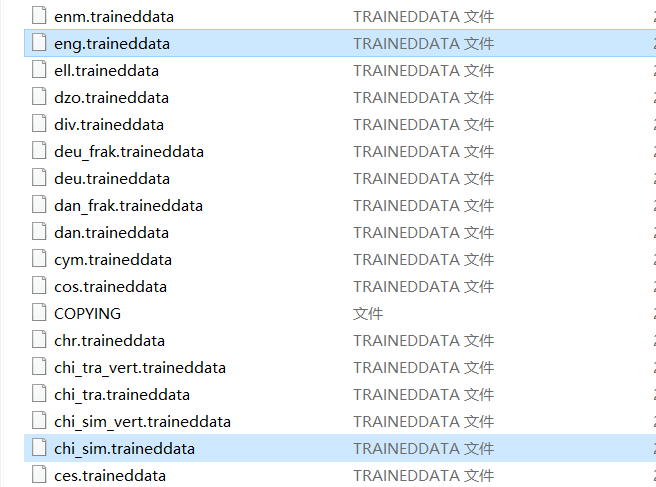
该目录下有tessdata,tessdata_best,tessdata_fast等5种语言包,其中tessdata是检测速度和准确度居中的语言包,后缀best对应最慢和最准确的语言包,后缀fast对应最快和准确度较差的语言包,这里我们选择tessdata。进入到tessdata语言包的github仓后,可以用git命令拉到本地,或者网页版下载到本地后解压,就可以看到很多以语言简称为文件名、traineddata为后缀的文件,其中eng.traineddata和chi_sim.traineddata一般足够应对中文和英文场景:
3、安装软件
双击下载的安装包(tesseract-ocr-w64-setup-v5.0.0-rc1.20211030.exe),一路Next:

直到提示安装完成。
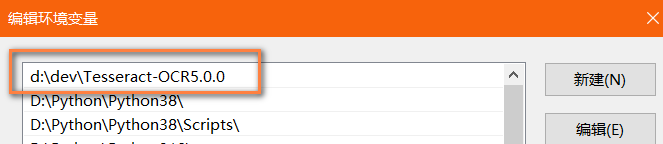
接下来需要手动配置系统环境变量,在windows系统环境变量PATH中添加刚才的安装路径,比如桔子菌的安装路径为D:\dev\Tesseract-OCR5.0.0:
接下来重新打开一个新的命令行,输入”tesseract.exe -v”验证软件的安装是否正确:
E:\juzicode>tesseract.exe -v
tesseract v5.0.0-rc1.20211030
leptonica-1.78.0
libgif 5.1.4 : libjpeg 8d (libjpeg-turbo 1.5.3) : libpng 1.6.34 : libtiff 4.0.9 : zlib 1.2.11 : libwebp 0.6.1 : libopenjp2 2.3.0在打印信息中可以看到对应的版本号v5.0.0-rc1.20211030以及各种依赖库文件的版本号,表示安装成功。
4、安装语言包
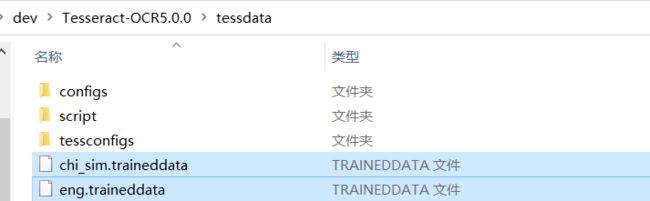
接下来安装语言包,在上一个步骤下载的语言包中找到需要的traineddata文件,比如表示英文和中文简体的eng.traineddata和chi_sim.traineddata,复制到软件安装目录的tessdata路径下,这里桔子菌的语言包目录是:D:\dev\Tesseract-OCR5.0.0\tessdata。
再次进入到系统环境变量,添加一个名称为“TESSDATA_PREFIX”的系统变量,输入语言包所在的路径:

设置完成后打开一个新的命令行输入“tesseract.exe –list-langs”可以检查语言包是否完成安装:
E:\juzicode\tess>tesseract.exe --list-langs
List of available languages (3):
chi_sim
eng
osd桔子菌前面拷贝了eng.traineddata和chi_sim.traineddata 2个文件到tessdata目录下,输入“tesseract.exe –list-langs”执行后看到了chi_chm和eng 2种语言,说明对应的语言类型安装成功。
5、测试、识别
接下来就是使用tesseract识别文字验证安装情况。
通过“tesseract –help”可以打印出大部分的命令,其中识别图片的命令如下形式:
tesseract.exe imagename|imagelist|stdin outputbase|stdout [options…] [configfile…]这里第1个参数是imagename|imagelist|stdin,可以是单个图片文件名称、多个图片文件组成的清单或者标准输入stdin,第2个参数是outputbase|stdout,可以是输出文件名称或者标准输出stdout,options选项可以配置语言种类、设置识别引擎、分页模式等,configfile一般用的比较少。
我们先来看一个简单的例子,要解析的文件名称为test.png,要识别的图片如下图:

下面这个例子解析单个文件test.png(第1个参数),在标准输出(命令行界面)打印解析结果(第2个参数为stdout),用-l参数带chi_sim表示使用简体中文语言:
E:\juzicode\tess>tesseract.exe test.png stdout -l chi_sim
juzicode.com
微 信 公 众 号 : 桔 子 code
这 是 一 个 测 试 例 子也可以将stdout改为其他的字符串(第2个参数改为输出文件名称,不用带txt后缀),这样会将识别的结果写入到以该字符串命名的txt文件中:
E:\juzicode\tess>tesseract.exe test.png result -l chi_sim在当前目录下就会生成一个result.txt的文件,文件内容就是识别出来的文字内容。
可以将多个文件名单独成行写入到一个txt文件中构成一个imagelist,第1个参数就可以输入该文件名称,从而实现一次识别多个文件。需要注意的是图片文件名称需要单独成行,否则会认为一行中多个文件名称组成的字符串是一个文件,从而导致出现找不到文件的错误:Error in fopenReadStream: file not found。下面这个例子中todo.txt中保存了同目录下的2个图片文件名称:test.png,test2.png,将原来的第1个参数改为“todo.txt”执行解析命令:
E:\juzicode\tess>tesseract.exe todo.txt stdout -l chi_sim
Page 0 : test.png
juzicode.com
微 信 公 众 号 : 桔 子 code
这 是 一 个 测 试 例 子
Page 1 : test2.png
这 是 第 2 个 测 试 例 子输出内容包含了图片文件名称和对应的识别结果。
下面的例子是从pdf文件中截取的一个片段,文件名为bookseg.png:

E:\juzicode\tess>tesseract bookseg.png stdout -l chi_sim
引 言
数 字 图 像 处 理 方 法 的 重 要 性 源 于 两 个 主 要 应 用 领 域 : 改 善 图 示 信 息 以 便 人 们 解 释 ; 为 存 储 、 传
输 和 表 示 而 对 图 像 数 据 进 行 处 理 , 以 便 于 机 器 自 动 理 解 。 本 章 有 几 个 主 要 目 的 : (1) 定 义 我 们 称 之 为
图 像 处 理 领 域 的 范 围 ; (2) 从 历 史 观 点 回 顾 图 像 处 理 的 起 源 ; (3) 通 过 考 察 一 些 主 要 的 应 用 领 域 , 给 出
图 像 处 理 技 术 状 况 的 概 念 ; (4) 筒 要 讨 论 数 字 图 像 处 理 中 所 用 的 主 要 方 法 ; (5) 概 述 通 用 目 的 的 典 型 图
像 处 理 系 统 的 组 成 ; (6) 列 出 公 开 发 表 的 数 字 图 像 处 理 领 域 的 一 些 图 书 和 文 献 。从识别的结果看,对于这种清晰度较高的图片识别效果还是非常完美的。
小结:注意tesseract的安装包含2个部分,一个是软件本身的安装,安装完成后需要配置PATH系统变量,一个是语言包的安装,语言包拷贝完成后需要配置TESSDATA_PREFIX系统变量。
notes:
1.安装软件后如果没有配置PATH路径会提示:’tesseract’ 不是内部或外部命令,也不是可运行的程序或批处理文件。
2.如果语言包没有安装,或者没有正确设置TESSDATA_PREFIX,将会提示Failed loading language错误:
Error opening data file d:\dev\Tesseract-OCR5.0.0\tessdata\eng.traineddata
Please make sure the TESSDATA_PREFIX environment variable is set to your “tessdata” directory.
Failed loading language ‘eng’
Tesseract couldn’t load any languages!
Could not initialize tesseract.
推荐阅读:
有了这个方法群聊斗图你就不会输了
只需几行代码生成22种风格各异的彩色图
你别耍我,0.1+0.2居然不等于0.3?
如何实现一个“万能”的调试打印函数
有了这款神器,什么吃灰文件都统统现形
一行代码深度定制你的专属二维码(amzqr)
桔子菌和超市老板田大爷的一次角色互换经历
改造getpass,强迫症患者再也不用担心少输字符了
来看看怎么用OpenCV解构Twitter大牛的视觉错觉图