Kafka生产者-概念速览|配置参数|序列化|分区——《Kafka权威指南》笔记
文章目录
-
- Kafka生产者——向Kafka写入数据
-
- 生产者概览
-
- 消息发送过程
- 创建 Kafka 生产者
- 生产者的配置
-
- 顺序保证
- 序列化器
-
- 自定义序列化器
- 使用 Avro 序列化
- 分区
-
- 自定义分区器Demo
Kafka生产者——向Kafka写入数据
除了内置的客户端外,Kafka还提供了二进制连接协议,也就是说,我们直接向Kafka网络端口发送适当的字节序列,就可以从Kafka读取消息或往Kafka写入消息。因此还有好多语言实现的Kafka客户端,比如C++,Python,Go,不仅限于Java。
生产者概览
一个应用程序在很多情况下需要向Kafka写入消息:记录用户活动、保存日志信息、记录只能家电信息、与其他应用程序进行异步通信、缓冲即将写入数据库的数据,等等。
消息发送过程
尽管生产者API使用起来很简单,但消息的发送过程还是挺复杂的。
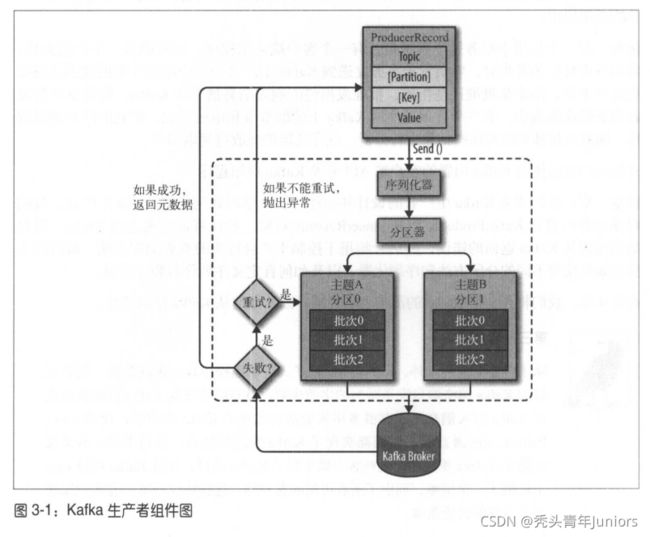
1)我们首先创建一个 ProducerRecord 对象开始,ProducerRecord 对象需要包含目标主题和要发送的内容,还可以指定键和分区。
2)在发送 PR 时,生产者需要先把键值对象序列化成字节数组,这样才能在网络上传输。
3)接下来,数据被传给分区器。如果 PR 中已经指定了分区,那么分区器就不会再做任何事情了,直接把指定的分区返回。如果没有,分区器则会根据 PR 中的键来选择一个分区。
4)紧接着,这条记录就会添加到一个记录批次里,这个批次的所有消息都会被发送到相同的主题和分区里。
5)之后,有一个独立的线程将这些记录批次发送给相应的broker上。
6)服务器在收到这些消息时会返回一个响应,如果消息发送成功写入Kafka中,就会返回一个 RecordMetaData 对象,它包含着主题和分区信息,以及记录在分区里的偏移量。
创建 Kafka 生产者
想要写入Kafka,首先要创建一个生产者对象,并设置一些属性。Kafka生产者有3个必选属性。
bootstrap.servers
该属性指定 broker 的地址清单,地址格式为:host:port。建议提供两个broker信息,其中一个宕机,生产者仍然能够连接到集群上。
key.serializer
broker希望接收到的消息的键值都是字节数组,不过生产者需要将键值所包装的Java对象转成字节数组。Kafka客户端默认提供 ByteArraySerializer、StringSerializer 和 IntegerSerializer 的序列化器。
value.serializer
如果键是整数类型而值是字符串,那么需要使用不同的序列化器。
Properties kafkaProps = new Properties();
kafkaProps.put("bootstrap.servers","hadoop102:9092,hadoop103:9092");
kafkaProps.put("key.serializer","org.apache.kafka.common.serialization.StringSerializer");
kafkaProps.put("value.serializer","org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String,String> producer = new KafkaProducer<String, String>(kafkaProps);
此时实例化生产者后,接下来就可以发送开始发送消息了。
发送消息有以下3种方式。
- 发送并忘记(fire-and-forget)
- 我们把消息发送给服务器,但并不关心它是否到达。
- 同步发送
- 我们使用send()方法发送消息,它会返回一个 Future 对象,调用 get() 方法进行等待,就可以知道消息是否发送成功了。
- 异步发送
- 我们调用 send() 发送,并指定一个回调函数,服务器在返回响应时会调用该函数。
//发送并忘记
producer.send(record);
//同步发送
try {
RecordMetadata metadata = producer.send(record).get();
Long offset = metadata.offset();
} catch (Exception e) {
e.printStackTrace();
}
//异步发送
producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
if (e != null){
e.printStackTrace();
}
}
});
生产者的配置
- acks
- acks参数表明了必须多少个副本收到了消息,生产者才会认为消息写入成功的。这个参数对于消息丢失的可能性有着重要影响。
- 设置 acks = 0 的话,生产者在成功写入消息之前不会等待任何服务器响应。但如果当中出现了消息丢失,生产者也无从得知,好处就是最大速度发送消息,从而达到很高的吞吐量。
- 设置 acks = 1 的话,只要集群首领节点收到消息,生产者就会收到一个来自服务器的成功响应。但如果消息无法到达首领节点(leader节点崩溃,新的leader没有被选举出来),生产者就会收到错误响应并重发。不过一个没有收到消息的新leader,消息还是会丢失。
- 设置 acks = all 的话**,只有当所有参与复制的节点全部收到消息时**,生产者才会收到一个来自服务器的成功响应。这种模式是最安全的,不过延迟比acks=1会更高。
- acks参数表明了必须多少个副本收到了消息,生产者才会认为消息写入成功的。这个参数对于消息丢失的可能性有着重要影响。
- buffer.memory
- 用来设置生产者内存缓冲区大小,生产者用它缓冲要发送到服务器的消息。如果应用程序发送消息的速度超过发送服务器的速度,就会导致生产者空间不足。这个时候,send()方法调用要么阻塞,要么抛出异常,取决于如何设置 block.on.buffer.full 参数
- compression.type
- 默认情况下,消息发送时不会被压缩。该参数可以设置为 snappy,gzip,它指定了消息被发送给broker之前使用哪种压缩算法进行压缩。
- snappy压缩算法 是由Google发明,它占用较少的CPU,能够提供更好的性能和可观的压缩比,用于考虑性能和网络带宽。
- gzip压缩算法 一般会占用较多CPU,但会提供更高的压缩比,因此如果网络带宽有限,可以使用该算法。
- 使用压缩可以降低网络传输和存储开销,而这往往是向 Kafka 发送消息的瓶颈所在。
- 默认情况下,消息发送时不会被压缩。该参数可以设置为 snappy,gzip,它指定了消息被发送给broker之前使用哪种压缩算法进行压缩。
- retries
- 因为生产者向服务器发送消息可能收到的时临时性的错误(比如分区找不到leader)。在这种情况下,reties参数决定着生产者可以重发消息的次数,默认每次重试次数等待100ms,不过可以通过 retry.backoff.ms 参数来改变这个时间间隔。
- 我们可以先测试以下恢复一个崩溃节点需要多少时间。
- 因为生产者向服务器发送消息可能收到的时临时性的错误(比如分区找不到leader)。在这种情况下,reties参数决定着生产者可以重发消息的次数,默认每次重试次数等待100ms,不过可以通过 retry.backoff.ms 参数来改变这个时间间隔。
- batch.size
- 该参数指定了一个批次可以使用的内存大小,按照字节计算。当批次被填满,批次中所有的信息会被发送出去。当然也不一定填满会发送(还要考虑linger.ms参数),过大会占用内存,过小会频繁发送消息,增加开销。
- linger.ms
- 该参数指定了生产者在发送批次之前等待更多消息加入批次的时间。KafkaProducer会在批次填满或者linger.ms达到上限时,就把批次发送出去。
- 如果设置比0大的数,虽然会增加延迟,但会提升吞吐量。(因为一次性发送更多的消息,每条消息开销就变小了。
- 该参数指定了生产者在发送批次之前等待更多消息加入批次的时间。KafkaProducer会在批次填满或者linger.ms达到上限时,就把批次发送出去。
- max.in.flight.requests.per.connection
- 该参数指定了生产者在收到服务器响应之前可以发送多少个消息。它的值越高,占用的内存就会越高,不过会提升吞吐量。
- timeout.ms、request.timeout.ms、meta.fetch.timeout.ms
- req.ms 指定了生产者在发送消息时等待服务器返回响应的时间
- meta.ms 指定了生产者获取元数据时服务器返回响应的时间
- time.ms 指定了broker等待同步副本返回消息确认的时间,与acks的配置向匹配——如果指定时间里没有收到同步副本的确认,那么broker就会返回一个错误。
- max.request.size
- 用于控制生产者发送的请求大小,能发送单个消息的最大值。另外,broker对可接收的消息最大值也有自己的限制 message.max.bytes ,所以两边的配置最好可以匹配,避免生产者发送消息被broker拒绝。
顺序保证
Kafka 可以保证在同一个分区内的顺序是一致的。
有些场景对于顺序是非常重要的,比如银行。
因此如果 retries 参数设置成非零整数,同时把 max.in.flight.requeset.per.connection 设为比1大的数,那么如果第一个批次的消息写入失败,而第二次的消息写入成功,而broker将重新写入第一批次。那么此时两个批次的顺序就会反过来。
因此,如果某些场景要求消息是有序的,消息写入成功也是很重要的,所以不建议把 reties 设为0,但可以把 request.per.connection 设为 1,这样生产者发送第一批消息时,就不会有其他消息发送给broker。
序列化器
之前我们讲到实例化一个生产者,就必须要指定一个序列化器,虽然Kafka提供了默认的字符串序列化器,整型和字节数组序列化器,不过不足以满足大部分场景的需求,因为我们要序列化的记录类型越来越多,越来越复杂。
自定义序列化器
如果我们发送到 Kafka 的对象如果不是简单字符串和整型,那么可以使用序列化框架,如 Arvo、Thrift、Protobuf,或者使用自定义序列化器。当然使用现成的序列化框架最好。
如果我们需要发送的消息是一个Customer对象的话
/**
* @Author Juniors Lee
* @Date 2021/11/16
*/
public class Customer {
private int customID;
private String customerName;
public int getCustomID() {
return customID;
}
public void setCustomID(int customID) {
this.customID = customID;
}
public String getCustomerName() {
return customerName;
}
public void setCustomerName(String customerName) {
this.customerName = customerName;
}
}
因此我们要自定义的序列化器。
/**
* @Author Juniors Lee
* @Date 2021/11/16
*/
public class CustomerSerializer implements Serializer<Customer> {
@Override
public void configure(Map<String, ?> map, boolean b) {
//不做任何配置
}
@Override
/**
* Customer 对象被序列化成:
* 表示 customerID 的4字节整数
* 表示 customerName 长度的4字节整数
* 表示 customerName 的N个字节
*/
public byte[] serialize(String s, Customer customer) {
byte[] serializedName;
int stringSize;
if (customer == null)
return null;
else {
if (customer.getCustomerName() != null){
serializedName = customer.getCustomerName().getBytes(StandardCharsets.UTF_8);
stringSize = serializedName.length;
}else {
serializedName = new byte[0];
stringSize = 0;
}
}
ByteBuffer buffer = ByteBuffer.allocate(4 + 4 + stringSize);
buffer.putInt(customer.getCustomID());
buffer.putInt(stringSize);
buffer.put(serializedName);
return buffer.array();
}
@Override
public void close() {
//不需要关闭任何东西
}
}
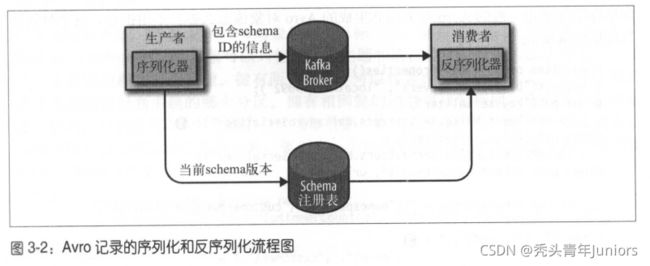
使用 Avro 序列化
Apache Avro 是一种与编程语言无关的序列化格式。Doug Cutting创建的这个给项目,目的是为了一种共享数据文件的形式。
Avro 数据是通过与语言无关的 schema 来定义的。而 schema 是通过 JSON 来描述,数据被序列化成二进制或JSON文件。
Avro 有一个很有意思的特性是,当负责写消息的应用程序使用了新 schema,负责读的应用程序可以继续处理消息而无需做出任何改动,这点很适合Kafka上使用。
分区
ProducerRecord对象包括了目标主题、键和值。Kafka的消息是一个个键值对,当然键可以为null。不过大部分的应用程序都要用到键,一是作为消息的附带信息,二是能够用来决定消息该写到主题的哪个分区,相同的键分配到相同的分区中。一个进程只会从一个主题中读取数据。
如果键值为 null,而且使用了默认的分区器,那么记录将被随机发送到主题内各个可用的分区上。分区器使用的是轮询(Round Robin)算法将消息均衡地发布在各个分区上。
当然如果键不为null,而且使用的默认分区器,那么Kafka会对键进行散列,然后根据散列值将消息映射到特定的分区上,而这样的映射,我们将用到主题所有的分区,而不仅仅是可用的分区。这也意味着,如果写入数据的分区也可能是不可用的,当然这个情况很少发生。
只有在不改变主题分区的数量的情况下,键与分区之间的映射才能保持不变,因此最好在创建主题的时候就把分区规划好。
自定义分区器Demo
/**
* @Author Juniors Lee
* @Date 2021/11/16
*/
public class BananaPartitioner implements Partitioner {
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster){
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
if ((keyBytes == null) || (!(key instanceof String)))
throw new InvalidRecordException("We expect all messages to have customer name as key")
if (((String)key).equals("Banana"))
return numPartitions; //Banana总是分配到最后一个分区
//其他记录被散列在其他分区
return (Math.abs(Utils.murmur2(keyBytes)) % (numPartitions - 1));
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> map) {
}
}