机器视觉
从 Google 的无人驾驶汽车到可以识别假钞的自动售卖机,机器视觉一直都是一个应用广 泛且具有深远的影响和雄伟的愿景的领域。
我们将重点介绍机器视觉的一个分支:文字识别,介绍如何用一些 Python库来识别和使用在线图片中的文字。
我们可以很轻松的阅读图片里的文字,但是机器阅读这些图片就会非常困难,利用这种人类用户可以正常读取但是大多数机器人都没法读取的图片,验证码 (CAPTCHA)就出现了。验证码读取的难易程度也大不相同,有些验证码比其他的更加难读。
将图像翻译成文字一般被称为光学文字识别(Optical Character Recognition, OCR)。可以实现OCR的底层库并不多,目前很多库都是使用共同的几个底层 OCR 库,或者是在上面 进行定制。
ORC库概述
在读取和处理图像、图像相关的机器学习以及创建图像等任务中,Python 一直都是非常出色的语言。虽然有很多库可以进行图像处理,但在这里我们只重点介绍:Tesseract
Tesseract
Tesseract 是一个 OCR 库,目前由 Google 赞助(Google 也是一家以 OCR 和机器学习技术闻名于世的公司)。Tesseract 是目前公认最优秀、最精确的开源 OCR 系统。 除了极高的精确度,Tesseract 也具有很高的灵活性。它可以通过训练识别出任何字体,也可以识别出任何 Unicode 字符。
安装Tesseract
Windows 系统
下载可执行安装文件https://code.google.com/p/tesseract-ocr/downloads/list安装。
Linux 系统
可以通过 apt-get 安装:
$sudo apt-get install tesseract-ocr
Mac OS X系统
用 Homebrew(http://brew.sh/)等第三方库可以很方便地安装 brew install tesseract
要使用 Tesseract 的功能,比如后面的示例中训练程序识别字母,要先在系统中设置一 个新的环境变量 $TESSDATA_PREFIX,让 Tesseract 知道训练的数据文件存储在哪里,然后搞一份tessdata数据文件,放到Tesseract目录下。
-
在大多数 Linux 系统和 Mac OS X 系统上,你可以这么设置:
$export TESSDATA_PREFIX=/usr/local/share/Tesseract -
在 Windows 系统上也类似,你可以通过下面这行命令设置环境变量:
#setx TESSDATA_PREFIX C:\Program Files\Tesseract OCR\Tesseract
安装pytesseract
Tesseract 是一个 Python 的命令行工具,不是通过 import 语句导入的库。安装之后,要用 tesseract 命令在 Python 的外面运行,但我们可以通过 pip 安装支持Python 版本的 Tesseract库:
pip install pytesseract
处理给规范的文字
你要处理的大多数文字都是比较干净、格式规范的。格式规范的文字通常可以满足一些需求,不过究竟什么是“格式混乱”,什么算“格式规范”,确实因人而异。 通常,格式规范的文字具有以下特点:
- 使用一个标准字体(不包含手写体、草书,或者十分“花哨的”字体) • 虽然被复印或拍照,字体还是很清晰,没有多余的痕迹或污点
- 排列整齐,没有歪歪斜斜的字
- 没有超出图片范围,也没有残缺不全,或紧紧贴在图片的边缘
文字的一些格式问题在图片预处理时可以进行解决。例如,可以把图片转换成灰度图,调 整亮度和对比度,还可以根据需要进行裁剪和旋转(详情请关注图像与信号处理),但是,这些做法在进行更具扩展性的 训练时会遇到一些限制。
格式规范文字的理想示例
通过下面的命令运行 Tesseract,读取文件并把结果写到一个文本文件中: `tesseract test.jpg text
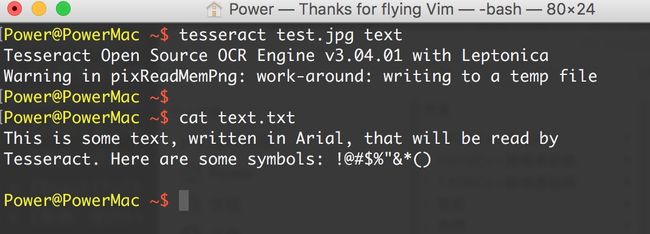
cat text.txt 即可显示结果。
识别结果很准确,不过符号^和*分别被表示成了双引号和单引号。大体上可以让你很舒服地阅读。
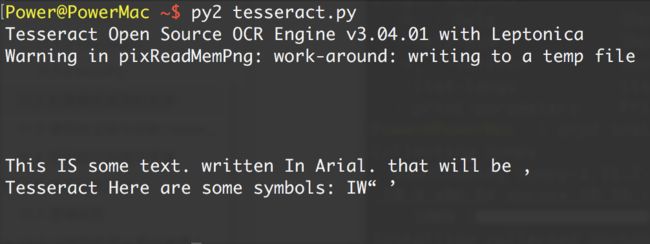
通过Python代码实现
import pytesseract
from PIL import Image
image = Image.open('test.jpg')
text = pytesseract.image_to_string(image)
print text
运行结果:
This is some text, written in Arial, that will be read by Tesseract. Here are some symbols: !@#$%"&*()
对图片进行阈值过滤和降噪处理(了解即可)
很多时候我们在网上会看到这样的图片:

Tesseract 不能完整处理这个图片,主要是因为图片背景色是渐变的,最终结果是这样:
随着背景色从左到右不断加深,文字变得越来越难以识别,Tesseract 识别出的 每一行的最后几个字符都是错的。
遇到这类问题,可以先用 Python 脚本对图片进行清理。利用 Pillow 库,我们可以创建一个 阈值过滤器来去掉渐变的背景色,只把文字留下来,从而让图片更加清晰,便于 Tesseract 读取:
from PIL import Image
import subprocess
def cleanFile(filePath, newFilePath):
image = Image.open(filePath)
# 对图片进行阈值过滤,然后保存
image = image.point(lambda x: 0 if x<143 else 255)
image.save(newFilePath)
# 调用系统的tesseract命令对图片进行OCR识别
subprocess.call(["tesseract", newFilePath, "output"])
# 打开文件读取结果
file = open("output.txt", 'r')
print(file.read())
file.close()
cleanFile("text2.jpg", "text2clean.png")
通过一个阈值对前面的“模糊”图片进行过滤的结果

除了一些标点符号不太清晰或丢失了,大部分文字都被读出来了。Tesseract 给出了最好的 结果:
从网站图片中抓取文字
用 Tesseract 读取硬盘里图片上的文字,可能不怎么令人兴奋,但当我们把它和网络爬虫组合使用时,就能成为一个强大的工具。
网站上的图片可能并不是故意把文字做得很花哨 (就像餐馆菜单的 JPG 图片上的艺术字),但它们上面的文字对网络爬虫来说就是隐藏起来 了,举个例子:
-
虽然亚马逊的 robots.txt 文件允许抓取网站的产品页面,但是图书的预览页通常不让网络机 器人采集。
-
图书的预览页是通过用户触发 Ajax 脚本进行加载的,预览图片隐藏在 div 节点 下面;其实,普通的访问者会觉得它们看起来更像是一个 Flash 动画,而不是一个图片文 件。当然,即使我们能获得图片,要把它们读成文字也没那么简单。
-
下面的程序就解决了这个问题:首先导航到托尔斯泰的《战争与和平》的大字号印刷版 1, 打开阅读器,收集图片的 URL 链接,然后下载图片,识别图片,最后打印每个图片的文 字。因为这个程序很复杂,利用了前面几章的多个程序片段,所以我增加了一些注释以让 每段代码的目的更加清晰:
import time
from urllib.request import urlretrieve
import subprocess
from selenium import webdriver
#创建新的Selenium driver
driver = webdriver.PhantomJS()
# 用Selenium试试Firefox浏览器:
# driver = webdriver.Firefox()
driver.get("http://www.amazon.com/War-Peace-Leo-Nikolayevich-Tolstoy/dp/1427030200")
# 单击图书预览按钮 driver.find_element_by_id("sitbLogoImg").click() imageList = set()
# 等待页面加载完成
time.sleep(5)
# 当向右箭头可以点击时,开始翻页
while "pointer" in driver.find_element_by_id("sitbReaderRightPageTurner").get_attribute("style"):
driver.find_element_by_id("sitbReaderRightPageTurner").click()
time.sleep(2)
# 获取已加载的新页面(一次可以加载多个页面,但是重复的页面不能加载到集合中)
pages = driver.find_elements_by_xpath("//div[@class='pageImage']/div/img")
for page in pages:
image = page.get_attribute("src")
imageList.add(image)
driver.quit()
# 用Tesseract处理我们收集的图片URL链接 for image in sorted(imageList):
# 保存图片
urlretrieve(image, "page.jpg")
p = subprocess.Popen(["tesseract", "page.jpg", "page"], stdout=subprocess.PIPE,stderr=subprocess.PIPE)
f = open("page.txt", "r")
p.wait() print(f.read())
和我们前面使用 Tesseract 读取的效果一样,这个程序也会完美地打印书中很多长长的段 落,第六页的预览如下所示:
6
"A word of friendly advice, mon
cher. Be off as soon as you can,
that's all I have to tell you. Happy
he who has ears to hear. Good-by,
my dear fellow. Oh, by the by!" he
shouted through the doorway after
Pierre, "is it true that the countess
has fallen into the clutches of the
holy fathers of the Society of je-
sus?"
Pierre did not answer and left Ros-
topchin's room more sullen and an-
gry than he had ever before shown
himself.
但是,当文字出现在彩色封面上时,结果就不那么完美了:
WEI' nrrd Peace
Len Nlkelayevldu Iolfluy
Readmg shmdd be ax
wlnvame asnossxble Wenfler
an mm m our cram: Llhvary
- Leo Tmsloy was a Russian rwovelwst
I and moval phflmopher med lur
A ms Ideas 01 nonviolenx reswslance m 5 We range 0, "and"
如果想把文字加工成普通人可以看懂的 效果,还需要花很多时间去处理。
下一节将介绍另一种方法来解决文字混乱的问题,尤其是当你愿意花一点儿时间训练 Tesseract 的时候。
通过给 Tesseract 提供大量已知的文字与图片映射集,经过训练 Tesseract 就可以“学会”识别同一种字体,而且可以达到极高的精确率和准确率,甚至可以忽略图 片中文字的背景色和相对位置等问题。
尝试对知乎网验证码进行处理:
许多流行的内容管理系统即使加了验证码模块,其众所周知的注册页面也经常会遭到网络 机器人的垃圾注册。
那么,这些网络机器人究,竟是怎么做的呢?既然我们已经,可以成功地识别出保存在电脑上 的验证码了,那么如何才能实现一个全能的网络机器人呢?
大多数网站生成的验证码图片都具有以下属性。
- 它们是服务器端的程序动态生成的图片。验证码图片的 src 属性可能和普通图片不太一 样,比如
- 图片的答案存储在服务器端的数据库里。
- 很多验证码都有时间限制,如果你太长时间没解决就会失效。
- 常用的处理方法就是,首先把验证码图片下载到硬盘里,清理干净,然后用 Tesseract 处理 图片,最后返回符合网站要求的识别结果。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import requests
import time
import pytesseract
from PIL import Image
from bs4 import BeautifulSoup
def captcha(data):
with open('captcha.jpg','wb') as fp:
fp.write(data)
time.sleep(1)
image = Image.open("captcha.jpg")
text = pytesseract.image_to_string(image)
print "机器识别后的验证码为:" + text
command = raw_input("请输入Y表示同意使用,按其他键自行重新输入:")
if (command == "Y" or command == "y"):
return text
else:
return raw_input('输入验证码:')
def zhihuLogin(username,password):
# 构建一个保存Cookie值的session对象
sessiona = requests.Session()
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:47.0) Gecko/20100101 Firefox/47.0'}
# 先获取页面信息,找到需要POST的数据(并且已记录当前页面的Cookie)
html = sessiona.get('https://www.zhihu.com/#signin', headers=headers).content
# 找到 name 属性值为 _xsrf 的input标签,取出value里的值
_xsrf = BeautifulSoup(html ,'lxml').find('input', attrs={'name':'_xsrf'}).get('value')
# 取出验证码,r后面的值是Unix时间戳,time.time()
captcha_url = 'https://www.zhihu.com/captcha.gif?r=%d&type=login' % (time.time() * 1000)
response = sessiona.get(captcha_url, headers = headers)
data = {
"_xsrf":_xsrf,
"email":username,
"password":password,
"remember_me":True,
"captcha": captcha(response.content)
}
response = sessiona.post('https://www.zhihu.com/login/email', data = data, headers=headers)
print response.text
response = sessiona.get('https://www.zhihu.com/people/maozhaojun/activities', headers=headers)
print response.text
if __name__ == "__main__":
#username = raw_input("username")
#password = raw_input("password")
zhihuLogin('[email protected]','ALAxxxxIME')
值得注意的是,有两种异常情况会导致这个程序运行失败。第一种情况是,如果 Tesseract 从验证码图片中识别的结果不是四个字符(因为训练样本中验证码的所有有效答案都必须 是四个字符),结果不会被提交,程序失败。第二种情况是虽然识别的结果是四个字符, 被提交到了表单,但是服务器对结果不认可,程序仍然失败。
在实际运行过程中,第一种 情况发生的可能性大约为 50%,发生时程序不会向表单提交,程序直接结束并提示验证码 识别错误。第二种异常情况发生的概率约为 20%,四个字符都对的概率约是 30%(每个字 母的识别正确率大约是 80%,如果是五个字符都识别,正确的总概率是 32.8%)。
训练Tesseract
大多数其他的验证码都是比较简单的。例如,流行的 PHP 内容管理系统 Drupal 有一个著 名的验证码模块(https://www.drupal.org/project/captcha),可以生成不同难度的验证码。

那么与其他验证码相比,究竟是什么让这个验证码更容易被人类和机器读懂呢?
- 字母没有相互叠加在一起,在水平方向上也没有彼此交叉。也就是说,可以在每一个字 母外面画一个方框,而不会重叠在一起。
- 图片没有背景色、线条或其他对 OCR 程序产生干扰的噪点。
- 虽然不能因一个图片下定论,但是这个验证码用的字体种类很少,而且用的是 sans-serif 字体(像“4”和“M”)和一种手写形式的字体(像“m”“C”和“3”)。
- 白色背景色与深色字母之间的对比度很高。
这个验证码只做了一点点改变,就让 OCR 程序很难识别。
- 字母和数据都使用了,这会增加待搜索字符的数量。
- 字母随机的倾斜程度会迷惑 OCR 软件,但是人类还是很容易识别的。
- 那个比较陌生的手写字体很有挑战性,在“C”和“3”里面还有额外的线条。另外这 个非常小的小写“m”,计算机需要进行额外的训练才能识别。 用下面的代码运行 Tesseract 识别图片:
tesseract captchaExample.png output
我们得到的结果 output.txt 是: 4N\,,,C<3
训练Tesseract
要训练 Tesseract 识别一种文字,无论是晦涩难懂的字体还是验证码,你都需要向 Tesseract 提供每个字符不同形式的样本。
做这个枯燥的工作可能要花好几个小时的时间,你可能更想用这点儿时间找个好看的视频 或电影看看。首先要把大量的验证码样本下载到一个文件夹里。
下载的样本数量由验证码 的复杂程度决定;我在训练集里一共放了 100 个样本(一共 500 个字符,平均每个字符 8 个样本;a~z 大小写字母加 0~9 数字,一共 62 个字符),应该足够训练的了。
提示:建议使用验证码的真实结果给每个样本文件命名(即4MmC3.jpg)。 这样可以帮你 一次性对大量的文件进行快速检查——你可以先把图片调成缩略图模式,然后通过文件名 对比不同的图片。这样在后面的步骤中进行训练效果的检查也会很方便。
第二步是准确地告诉 Tesseract 一张图片中的每个字符是什么,以及每个字符的具体位置。 这里需要创建一些矩形定位文件(box file),一个验证码图片生成一个矩形定位文件。一 个图片的矩形定位文件如下所示:
4 15 26 33 55 0
M 38 13 67 45 0
m 79 15 101 26 0
C 111 33 136 60 0
3 147 17 176 45 0
第一列符号是图片中的每个字符,后面的 4 个数字分别是包围这个字符的最小矩形的坐标 (图片左下角是原点 (0,0),4 个数字分别对应每个字符的左下角 x 坐标、左下角 y 坐标、右上角 x 坐标和右上角 y 坐标),最后一个数字“0”表示图片样本的编号。
显然,手工创建这些图片矩形定位文件很无聊,不过有一些工具可以帮你完成。我很喜欢 在线工具 Tesseract OCR Chopper(http://pp19dd.com/tesseract-ocr-chopper/),因为它不需要 安装,也没有其他依赖,只要有浏览器就可以运行,而且用法很简单:上传图片,如果要 增加新矩形就单击“add”按钮,还可以根据需要调整矩形的尺寸,最后把新生成的矩形 定位文件复制到一个新文件里就可以了。
矩形定位文件必须保存在一个 .box 后缀的文本文件中。和图片文件一样,文本文件也是用 验证码的实际结果命名(例如,4MmC3.box)。另外,这样便于检查 .box 文件的内容和文件的名称,而且按文件名对目录中的文件排序之后,就可以让 .box 文件与对应的图片文件 的实际结果进行对比。
你还需要创建大约 100 个 .box 文件来保证你有足够的训练数据。因为 Tesseract 会忽略那 些不能读取的文件,所以建议你尽量多做一些矩形定位文件,以保证训练足够充分。如果 你觉得训练的 OCR 结果没有达到你的目标,或者 Tesseract 识别某些字符时总是出错,多 创建一些训练数据然后重新训练将是一个不错的改进方法。
创建完满载 .box 文件和图片文件的数据文件夹之后,在做进一步分析之前最好备份一下这 个文件夹。虽然在数据上运行训练程序不太可能删除任何数据,但是创建 .box 文件用了你 好几个小时的时间,来之不易,稳妥一点儿总没错。此外,能够抓取一个满是编译数据的 混乱目录,然后再尝试一次,总是好的。
前面的内容只是对 Tesseract 库强大的字体训练和识别能力的一个简略概述。如果你对 Tesseract 的其他训练方法感兴趣,甚至打算建立自己的验证码训练文件库,或者想和全世 界的 Tesseract 爱好者分享自己对一种新字体的识别成果,推荐阅读 Tesseract 的文档:https://github.com/tesseract-ocr/tesseract/wiki,加油!