【推荐系统论文精读系列】(十二)--Neural Factorization Machines for Sparse Predictive Analytics
文章目录
- 一、摘要
- 二、介绍
- 三、特征交互建模
-
- 3.1 因子分解机
- 3.1.1 FM表达能力的限制
- 3.2 深度神经网络
- 3.2.1 DNN优化难点
- 四、Neural Factorization Machines
-
- 4.1 NFM模型
-
- 4.1.1 Embedding layer
- 4.1.2 Bi-Interaction-layer
- 4.1.3 Hidden Layers
- 4.1.4 Prediction Layer
- 4.2 学习
-
- 4.2.1 Dropout
- 4.2.2 Batch Normalization
- Preferences
论文名称:Neural Factorization Machines for Sparse Predictive Analytics
原文地址:NFM
⚡本系列历史文章⚡
【推荐系统论文精读系列】(一)–Amazon.com Recommendations
【推荐系统论文精读系列】(二)–Factorization Machines
【推荐系统论文精读系列】(三)–Matrix Factorization Techniques For Recommender Systems
【推荐系统论文精读系列】(四)–Practical Lessons from Predicting Clicks on Ads at Facebook
【推荐系统论文精读系列】(五)–Neural Collaborative Filtering
【推荐系统论文精读系列】(六)–Field-aware Factorization Machines for CTR Prediction
【推荐系统论文精读系列】(七)–AutoRec Autoencoders Meet Collaborative Filtering
【推荐系统论文精读系列】(八)–Deep Crossing:Web-Scale Modeling without Manually Crafted Combinatorial Features
【推荐系统论文精读系列】(九)–Product-based Neural Networks for User Response Prediction
【推荐系统论文精读系列】(十)–Wide&Deep Learning for Recommender Systems
【推荐系统论文精读系列】(十一)–DeepFM A Factorization-Machine based Neural Network for CTR Prediction
【推荐系统论文精读系列】(十二)–Neural Factorization Machines for Sparse Predictive Analytics
一、摘要
现在很多基于网站应用的预测任务都需要对类别进行建模,例如用户的ID、性别和职业等。为了使用通常的机器学习预测算法,需要将这些类别变量通过one-hot将其转化成二值特征,这就会导致合成的特征向量是高度稀疏的。为了有效学习这些稀疏数据,关键就是要解释不同特征之间的影响。
FMs是一个有效的方式去使用二阶特征交互。可是,FMs的特征交互只是以线性的方式,不能够充分的捕捉到非线性和复杂的真实数据中的内在结构。然而DNN最近已经被广泛用于学习非线性特征交互在工业界,例如Google提出的Wide&Deep和微软提出的DeepCross,但是DNN存在一个问题就是如果网络太深是难以训练的。
本篇论文,我们提出了一个新型网络结构NFM用于在稀疏情况下进行预测。NFM结合了FM捕捉二阶特征的线性能力和DNN对高阶特征建模的能力。概念上讲,NFM计算起来是更加的贵相比FM,因为FM可以被看成是NFM的一个特例没有隐层。
二、介绍
预测性分析是非常重要的技术在信息检索、数据挖掘任务中,从推荐系统到在线广告推送、视觉分析和事物检测。通常情况下,一个预测性的任务通常是找到一个映射函数,将预测变量映射到一些目标值,例如实值目标用于回归,分类标签作为分类。不同于音频和图片,网站应用大多数都是离散的分类特征。为了构建一个预测性的模型对于这些分类变量,一个通常的解决办法就是将其转化称二值特征通过使用one-hot编码,在这之后,就可以使用常用的机器学习算法,比如逻辑回归或者支持向量机等。
根据分类预测变量的可能值,生成的特征向量可以是高维但稀疏的。为了用这样的稀疏数据建立有效的ML模型,考虑特征之间的相互作用至关重要。工业界和学术界的许多成功解决方案在很大程度上依赖于手工制作组合特征,通过组合多个预测变量(也称为预测变量)构建新特征。众所周知,顶尖的数据科学家通常精通组合特征,而组合特征在他们获胜的方法中起着关键作用。但是,这些功能的强大成本很高,因为设计有效的功能需要大量的工程工作和有用的领域知识。因此,这些解决方案很难推广到新的问题或领域。
另一个解决方案不是手动增加特征向量,而是设计一个ML模型来自动从原始数据中学习特征交互。一种流行的方法是因子分解机(FMs),它将特征嵌入到潜在空间中,并通过特征嵌入向量的内积对特征之间的交互进行建模。虽然FM在许多预测任务中产生了巨大的潜力,但我们认为其性能可能受到其线性以及成对(二阶)特征交互建模的限制。具体来说,对于具有复杂和非线性底层结构的真实世界数据,FM可能不够表达。虽然已经提出了高FMs,但它们仍然属于线性模型家族,并且声称难以估计。此外,已知它们仅比FM有微小的改进,我们怀疑其原因可能是由于以线性方式对高阶相互作用进行建模。
在这项工作中,我们提出了一种新的稀疏数据预测模型,称为神经因子分解机(NFMs),它通过模拟高阶和非线性特征交互来增强FMs。通过在神经网络建模中设计一种新的操作-BI-product,我们首次将FM纳入神经网络框架。通过在双交互层之上叠加非线性层,我们能够加深浅层线性FM,有效地模拟高阶和非线性特征交互,以提高FM的表现力。与传统的深度学习方法不同,传统的深度学习方法只是将嵌入向量拼接在低层,我们使用双向交互池对信息量更大的特征交互进行编码,极大地促进了神经网络层学习到更有意义的信息。我们在两个用于上下文感知预测和个性化标签推荐的公共基准上进行了大量实验。由于只有一个隐藏层,我们的NFM显著优于FM,提高了73%。与最先进的深度学习方法相比,我们的1层NFM显示出一致的改进,结构更简单,模型参数更少。
这项工作的主要贡献总结如下。
(1) 据我们所知,我们是第一个在神经网络建模中引入双向交互池操作的人,并为FM提供了一个新的神经网络视图。
(2) 基于这一新观点,我们开发了一种新的NFM模型,在神经网络框架下加深FM,用于学习高阶和非线性特征交互。
(3) 我们在两个实际任务上进行了大量实验,以研究双向交互池和NFM模型,证明了NFM的有效性,以及在稀疏环境下使用神经网络进行预测的巨大前景。
三、特征交互建模
由于组合特征空间很大,传统的解决方案通常依赖于手动特征工程或特征选择技术(如GBDT)来选择重要的特征交互。这种解决方案的一个限制是,它们不能推广到训练数据中未出现的组合特征。近年来,基于嵌入的方法变得越来越流行,它们试图从原始数据中学习特征交互。通过将高维稀疏特征嵌入低维潜在空间,该模型可以推广到不可见的特征组合。无论领域如何,我们都可以将这些方法分为两类:
1)基于因式分解机的线性模型
2)基于神经网络的非线性模型
在接下来的内容中,我们将简要回顾这两种具有代表性的技术。
3.1 因子分解机
因子分解机最初是为协作推荐而提出的。给定实值特征向量,FM通过通过因子化交互参数对每对特征之间的所有交互进行建模来估计目标:
y ^ F M ( x ) = w 0 + ∑ i = 1 n w i x i + ∑ i = 1 n ∑ j = i + 1 n v i T v j ∗ x i x j \hat {y}_{FM}(x)=w_0+\sum_{i=1}^nw_ix_i+\sum_{i=1}^n\sum_{j=i+1}^nv_i^Tv_j*x_ix_j y^FM(x)=w0+i=1∑nwixi+i=1∑nj=i+1∑nviTvj∗xixj
FM的一个主要功能来源于其通用性,与仅对两个实体的关系建模的矩阵分解(MF)不同,FM是一个通用的预测器,用于监督学习的任何实值特征向量。显然,它使用特征之间的二阶因式分解相互作用增强了线性/逻辑回归(LR)。通过指定输入特征,Rendle表明FM可以模拟许多特定的因子分解模型,如标准MF、并行因子分析和SVD++,由于这种通用性,FM被认为是稀疏数据预测最有效的嵌入方法之一。它已经成功地应用于许多预测任务,从在线广告,微博检索,到关系提取。
3.1.1 FM表达能力的限制
尽管有效,我们指出FM仍然属于(多元)线性模型族。不幸的是,现实世界数据的底层结构通常是高度非线性的,无法用线性模型精确近似。因此,FM可能在建模具有复杂内在结构和规律的真实数据时存在表示能力不足的问题。
在方法学方面,已经开发出许多FM变体。例如,Hong建议COFM从多视图数据中学习;Oentaryo通过设计分层正则化器将特征的先验知识编码为FM;Lin提出了场感知FM,它学习一个特征的多个嵌入向量,以区分其与不同场特征的交互作用。最近,肖提出了注意FM,利用注意网络来了解每个特征交互的重要性。然而,这些变体都是FM的线性扩展,只模拟二阶特征交互。因此,它们在建模真实世界数据时可能会遇到同样的表达性问题。
在这项工作中,我们通过赋予FM非线性建模的能力来改进FM的表达能力。其思想是对潜在空间进行非线性变换二阶特征的相互作用;同时,可以捕获高阶特征交互。
3.2 深度神经网络
近五年来,深度神经网络(deep neural networks,DNNs)取得了巨大的成功,被广泛应用于语音识别、计算机视觉和自然语言处理等领域。然而,DNN的使用在IR和DM社区中并不普遍。在我们看来,我们认为一个原因可能是IR和DM任务的大多数数据都是自然稀疏的,例如用户行为、文档/查询以及从分类变量转换而来的各种特征。尽管DNN显示出从密集数据中学习模式的强大能力,但对稀疏数据使用DNN的审查较少,如何在稀疏设置下使用DNN有效学习特征交互尚不清楚。
直到最近,一些工作才开始探索,用于稀疏预测分析的某些场景的DNN。提出了一个神经协同过滤(NCF)框架来学习用户和项目之间的交互。后来,NCF框架被扩展为属性感知CF的属性交互模型。然而,他们的方法仅适用于学习两个实体之间的交互,不直接支持监督学习的一般设置。Zhang开发了一种FM支持的神经网络(FNN),它使用FM学习的特征嵌入来初始化DNN。Cheng提出了Wide&Deep,其中深度部分是一个多层感知器(MLP),用于连接特征嵌入向量以学习特征交互。Shan提出了用于ads预测的DeepCross,它通过用最先进的残差网络取代MLP,与Wide&Deep共享一个类似的框架。
3.2.1 DNN优化难点
提到这些基于神经网络的方法的共同结构,将多层叠加在嵌入向量的串联之上以学习特征交互。期望多层能够以隐式方式学习任意阶数的组合特征。然而,我们发现这种体系结构的一个关键弱点是,简单地将特征嵌入向量串联在一起,在低层次上携带的关于特征交互的信息太少。他最近的工作提供了一个经验证据,这表明简单地将用户和项目嵌入向量连接起来会导致协作过滤的效果非常差。要解决这一问题,必须依靠以下深层次来学习有意义的交互功能。虽然有人声称多个非线性层能够很好地学习特征交互,但由于梯度消失/爆炸、过度拟合、退化等臭名昭著的问题,这种深层架构在实践中很难优化。
在这项工作中,我们提出了一种用于稀疏数据预测的神经网络新范式。我们提出了一种新的双向交互操作来模拟二阶特征交互,而不是串联特征嵌入向量。这将在低层中产生更多的信息表示,极大地帮助后续非线性层学习高阶交互。
四、Neural Factorization Machines
我们首先提出了NFM模型,该模型结合了FMs和神经网络的优点,用于稀疏数据建模。然后,我们讨论了学习过程,以及如何在神经网络中使用一些有用的技术-Dropout和批量标准化-用于NFM。
4.1 NFM模型
和因子分解机一样,NFM是一个通用的学习器能够用于任何实值特征向量,给定 x ∈ R d x\in R^d x∈Rd 作为输入向量,NFM评估标签:
y ^ N F M ( x ) = w 0 + ∑ i = 1 n w i x i + f ( x ) \hat {y}_{NFM}(x)=w_0+\sum_{i=1}^nw_ix_i+f(x) y^NFM(x)=w0+i=1∑nwixi+f(x)
第一项和第二项是FM中的线性部分,它对数据的全局偏置和特征权重进行建模,第三项 f ( x ) f(x) f(x) 是NFM部分的核心,它是一个多层前馈神经网络。
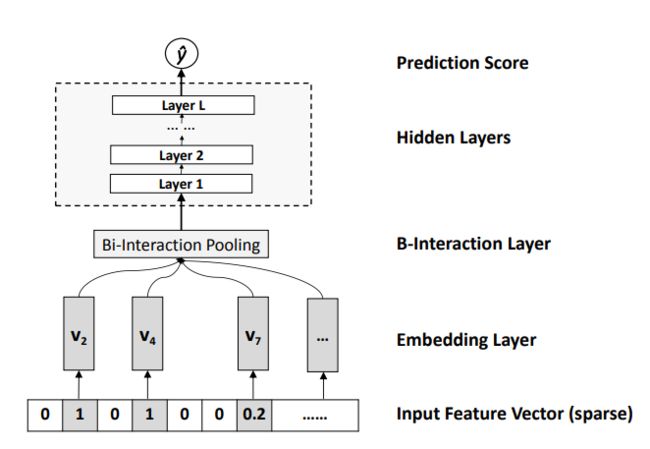
4.1.1 Embedding layer
嵌入层是完全连接的,将每个特征映射到一个稠密向量。正式地说,让 v i ∈ R k v_i\in R^k vi∈Rk 为第i个特征的embedding向量,,我们就会获得一个embedding集合, V x = { x 1 v 1 , . . . , x n v n } V_x=\{x_1v_1,...,x_nv_n\} Vx={ x1v1,...,xnvn} 去表示输入向量 x x x 。
4.1.2 Bi-Interaction-layer
我们然后将Embedding结合喂进Bi-Interaction-layer,这是一个池化操作将一个Embedding向量集合转化为一个向量:
f B I ( V x ) = ∑ i = 1 n ∑ j = i + 1 n x i v i ∗ x j v j f_{BI}(V_x)=\sum_{i=1}^n\sum_{j=i+1}^nx_iv_i*x_jv_j fBI(Vx)=i=1∑nj=i+1∑nxivi∗xjvj
显然,BI池化层的输出是一个k维向量,它编码嵌入空间中特征之间的二阶交互。
4.1.3 Hidden Layers
在BI池化层之上是一堆全连接层,这些层能够学习功能之间的高级交互。正式地说,全连接层的定义如下:
z 1 = σ 1 ( W 1 f B I ( V x ) + b 1 ) z 2 = σ 2 ( W 2 z 1 + b 2 ) . . . z L = σ L ( W L z L − 1 + b L ) z_1=\sigma_1(W_1f_{BI}(V_x)+b_1)\\ z_2=\sigma_2(W_2z_1+b_2)\\ ...\\ z_L=\sigma_L(W_Lz_{L-1}+b_L) z1=σ1(W1fBI(Vx)+b1)z2=σ2(W2z1+b2)...zL=σL(WLzL−1+bL)
我们允许模型以非线性方式学习高阶特征交互。这有利于现有的高阶交互学习方法,如高阶FM和指数机器,它们仅支持以线性方式学习高阶交互。至于全连接层的结构(每层的大小),可以自由选择塔型、常数和钻石型等结构。
4.1.4 Prediction Layer
最后,将最后一个隐藏层的输出向量转换为最终预测分数:
f ( x ) = h T z L f(x)=h^Tz_L f(x)=hTzL
其中向量表示预测层的神经元权重。
综上所述,我们给出了NFM预测模型的公式如下:
y ^ N F M ( x ) = w 0 + ∑ i = 1 n w i x i + h T σ L ( W L ( . . . σ 1 ( W 1 f B I ( V x ) + b 1 ) ) + b L ) \hat {y}_{NFM}(x)=w_0+\sum_{i=1}^nw_ix_i+h^T\sigma_L(W_L(...\sigma_1(W_1f_{BI}(V_x)+b_1))+b_L) y^NFM(x)=w0+i=1∑nwixi+hTσL(WL(...σ1(W1fBI(Vx)+b1))+bL)
4.2 学习
NFM可以应用于各种预测任务,包括回归、分类和排序。要估计NFM的模型参数,我们需要指定一个目标函数进行优化。对于回归,常用的目标函数是平方损失:
L r e g = ∑ ( y ^ − y ( x ) ) 2 L_{reg}=\sum(\hat {y}-y(x))^2 Lreg=∑(y^−y(x))2
正则化项是可选的,此处省略,因为我们发现神经网络建模中的一些技术(如dropout)可以很好地防止NFM过度拟合。对于分类任务,我们可以优化铰链损失或对数损失.对于排名任务,我们可以优化两两个性化排名损失或对比最大边际损失。在这项工作中,我们关注回归任务并优化方程的平方损失。排名/分类任务的优化也可以用同样的方法进行。
随机梯度下降(SGD)是优化神经网络模型的通用解算器。它迭代更新参数直至收敛。每次随机选择一个训练实例,朝负梯度方向更新每个模型参数:
θ = θ − η ∗ 2 ( y ^ − y ( x ) ) d y ^ ( x ) d θ \theta=\theta-\eta*2(\hat{y}-y(x))\frac{d\hat{y}(x)}{d\theta} θ=θ−η∗2(y^−y(x))dθdy^(x)
其中, θ \theta θ 是一个可训练的模型参数, η \eta η 是控制梯度下降步长的学习率。由于NFM是一个多层神经网络模型,可以使用链式规则导出每个模型参数的梯度。这里我们只给出BI池化层的微分,因为其他层都是标准操作在神经网络建模中得到了广泛应用,并在TensorFlow和Keras等ML工具包中得到了广泛应用。
因此,对于端到端的神经方法,在插入双交互池层后,仍然可以端到端地学习它们。为了利用现代计算平台的矢量化和并行加速,mini-batch SGD在实践中得到了更广泛的应用,它对一批训练实例进行采样,并基于ba更新模型参数tch.在我们的实现中,我们使用mini-batch Adagrad作为优化器,而不是vanilla SGD。它的主要优点是学习速率可以在训练阶段自适应,这减轻了选择适当学习速率的痛苦,并导致比vanilla SGD更快的收敛。
4.2.1 Dropout
虽然神经网络模型具有很强的表示能力,但它们也容易过度拟合训练数据。Dropout是神经网络的一种正则化技术,用于防止过度拟合。其思想是随机丢弃神经元(及其连接)也就是说,在每次参数更新中,只有对预测有贡献的部分模型参数将被更新。通过这个过程,它可以防止神经元对训练数据的复杂共同适应。需要注意的是,在测试阶段,必须禁用Dropout,并且整个网络用于估算。因此,Dropout也可以被视为使用较小的神经网络进行模型平均。
4.2.2 Batch Normalization
训练多层神经网络的一个困难是由于协方差偏移。这意味着在训练过程中,随着前一层参数的变化,每一层输入的分布都会发生变化。因此,后一层在更新其参数时需要适应这些变化(通常是噪声),这会对训练产生不利影响。为了解决这一问题,Ioffe和Szegdy提出了(BN),它将层输入标准化为每个训练小批量的零平均单位方差高斯分布。已经证明,BN在多个计算机视觉任务中具有更快的收敛速度和更好的性能。
B N ( x i ) = γ ∗ ( x i − μ B σ B ) + β BN(x_i)=\gamma*(\frac{x_i-\mu_B}{\sigma_B})+\beta BN(xi)=γ∗(σBxi−μB)+β
μ B = 1 ∣ B ∣ ∑ i ∈ B x i \mu_B=\frac{1}{|B|}\sum_{i\in B}x_i μB=∣B∣1∑i∈Bxi 意为每个小批量数据的均值, σ B 2 = 1 ∣ B ∣ ∑ i ∈ B ( x i − μ B ) 2 \sigma_B^2=\frac{1}{|B|}\sum_{i\in B}(x_i-\mu_B)^2 σB2=∣B∣1∑i∈B(xi−μB)2 意为每个小批次数据的方差, γ \gamma γ 和 β \beta β 是可训练参数(向量),用于缩放和移动归一化值以恢复网络的表示能力。请注意,在测试中,还需要应用BN,其中和是根据整个训练数据估计的。
Preferences
[1] L. Baltrunas, K. Church, A. Karatzoglou, and N. Oliver. Frappe: Understanding the usage and perception of mobile app recommendations in-the-wild. CoRR, abs/1505.03014, 2015.
[2] I. Bayer, X. He, B. Kanagal, and S. Rendle. A generic coordinate descent framework for learning from implicit feedback. In WWW, 2017.
[3] M. Blondel, A. Fujino, N. Ueda, and M. Ishihata. Higher-order factorization machines. In NIPS, 2016.
[4] M. Blondel, M. Ishihata, A. Fujino, and N. Ueda. Polynomial networks and factorization machines: New insights and ecient training algorithms. In ICML, 2016.
[5] D. Cao, X. He, L. Nie, X. Wei, X. Hu, S. Wu, and T.-S. Chua. Cross-platform app recommendation by jointly modeling ratings and texts. ACM TOIS, 2017.
[6] J. Chen, B. Sun, H. Li, H. Lu, and X.-S. Hua. Deep ctr prediction in display advertising. In MM, 2016.
[7] J. Chen, H. Zhang, X. He, L. Nie, W. Liu, and T.-S. Chua. AŠentive collaborative €ltering: Multimedia recommendation with feature- and item-level aŠention. In SIGIR, 2017.
[8] T. Chen, X. He, and M.-Y. Kan. Context-aware image tweets modelling and recommendation. In MM, 2016.
[9] H.-T. Cheng, L. Koc, J. Harmsen, T. Shaked, T. Chandra, H. Aradhye, G. Anderson, G. Corrado, W. Chai, M. Ispir, R. Anil, Z. Haque, L. Hong, V. Jain, X. Liu, and H. Shah. Wide & deep learning for recommender systems. In DLRS, 2016.
[10] J. Duchi, E. Hazan, and Y. Singer. Adaptive subgradient methods for online learning and stochastic optimization. Journal of Machine Learning Research, 2011.
[11] D. Erhan, Y. Bengio, A. Courville, P.-A. Manzagol, P. Vincent, and S. Bengio. Why does unsupervised pre-training help deep learning? Journal of Machine Learning Research, 2010.
[12] M. Genzel and G. Kutyniok. A mathematical framework for feature selection from real-world data with non-linear observations. arXiv preprint arXiv:1608.08852, 2016. [13] F. M. Harper and J. A. Konstan. Œe movielens datasets: History and context. ACM Transactions on Interactive Intelligent Systems, 2015.
[14] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In CVPR, 2016.
[15] X. He, M. Gao, M.-Y. Kan, Y. Liu, and K. Sugiyama. Predicting the popularity of web 2.0 items based on user comments. In SIGIR, 2014.
[16] X. He, L. Liao, H. Zhang, L. Nie, X. Hu, and T.-S. Chua. Neural collaborative €ltering. In WWW, 2017.
[17] X. He, H. Zhang, M.-Y. Kan, and T.-S. Chua. Fast matrix factorization for online recommendation with implicit feedback. In SIGIR, 2016.
[18] L. Hong, A. S. Doumith, and B. D. Davison. Co-factorization machines: Modeling user interests and predicting individual decisions in twiŠer. In WSDM, 2013.
[19] R. Hong, Y. Yang, M. Wang, and X.-S. Hua. Learning visual semantic relationships for ecient visual retrieval. IEEE Transactions on Big Data, 2015.
[20] S. Io‚e and C. Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shi‰. In ICML, 2015.
[21] Y. Juan, Y. Zhuang, W.-S. Chin, and C.-J. Lin. Field-aware factorization machines for ctr prediction. In RecSys, 2016.
[22] Y. Koren. Factorization meets the neighborhood: A multifaceted collaborative €ltering model. In KDD, 2008.
[23] A. Novikov, M. Tro€mov, and I. Oseledets. Exponential machines. In ICLR Workshop, 2017.
[24] R. J. Oentaryo, E.-P. Lim, J.-W. Low, D. Lo, and M. Finegold. Predicting response in mobile advertising with hierarchical importance-aware factorization machine. In WSDM, 2014.
[25] F. Petroni, L. Del Corro, and R. Gemulla. Core: Context-aware open relation extraction with factorization machines. In EMNLP, 2015.
[26] R. Qiang, F. Liang, and J. Yang. Exploiting ranking factorization machines for microblog retrieval. In CIKM, 2013.
[27] S. Rendle. Factorization machines. In ICDM, 2010.
[28] S. Rendle. Factorization machines with libfm. ACM Transactions on Intelligent Systems and Technology, 2012.
[29] S. Rendle, C. Freudenthaler, Z. Gantner, and L. Schmidt-Œieme. Bpr: Bayesian personalized ranking from implicit feedback. In UAI, 2009.
[30] S. Rendle, Z. Gantner, C. Freudenthaler, and L. Schmidt-Œieme. Fast contextaware recommendations with factorization machines. In SIGIR, 2011.
[31] Y. Shan, T. R. Hoens, J. Jiao, H. Wang, D. Yu, and J. Mao. Deep crossing: Web-scale modeling without manually cra‰ed combinatorial features. In KDD, 2016.
[32] F. Shen, Y. Mu, Y. Yang, W. Liu, L. Liu, J. Song, and H. T. Shen. Classi€cation by retrieval: Binarizing data and classi€er. In SIGIR, 2017.
[33] N. Srivastava, G. E. Hinton, A. Krizhevsky, I. Sutskever, and R. Salakhutdinov. Dropout: a simple way to prevent neural networks from over€Šing. Journal of Machine Learning Research, 2014.
[34] M. Wang, W. Fu, S. Hao, D. Tao, and X. Wu. Scalable semi-supervised learning by ecient anchor graph regularization. IEEE Transaction on Knowledge and Data Engineering, 2016.
[35] M. Wang, X. Liu, and X. Wu. Visual classi€cation by l1-hypergraph modeling. IEEE Transaction on Knowledge and Data Engineering, 2015.
[36] P. Wang, J. Guo, Y. Lan, J. Xu, S. Wan, and X. Cheng. Learning hierarchical representation model for nextbasket recommendation. In SIGIR, 2015.
[37] X. Wang, X. He, L. Nie, and T.-S. Chua. Item silk road: Recommending items from information domains to social users. In SIGIR, 2017.
[38] J. Xiao, H. Ye, X. He, H. Zhang, F. Wu, and T.-S. Chua. AŠentional factorization machines: Learning the weight of feature interactions via aŠention networks. In IJCAI, 2017.
[39] C. Xiong, J. Callan, and T.-Y. Liu. Learning to aŠend and to rank with word-entity duets. In SIGIR, 2017.
[40] C. Zhang, G. Zhou, Q. Yuan, H. Zhuang, Y. Zheng, L. Kaplan, S. Wang, and J. Han. Geoburst: Real-time local event detection in geo-tagged tweet streams. In SIGIR, 2016. [41] H. Zhang, F. Shen, W. Liu, X. He, H. Luan, and T.-S. Chua. Discrete collaborative €ltering. In SIGIR, 2016.
[42] H. Zhang, M. Wang, R. Hong, and T.-S. Chua. Play and rewind: Optimizing binary representations of videos by self-supervised temporal hashing. In MM, 2016.
[43] H. Zhang, Z.-J. Zha, Y. Yang, S. Yan, Y. Gao, and T.-S. Chua. AŠribute-augmented semantic hierarchy: Towards bridging semantic gap and intention gap in image retrieval. In MM, 2013.
[44] W. Zhang, T. Du, and J. Wang. Deep learning over multi-€eld categorical data. In ECIR, 2016.