Flink快速上手
前面讲Hadoop的时候已经说了大数据的整个生态就是围绕存储采集、存储、计算进行的,今天要说的就是“计算”,目前分离线计算和实时计算,这两大块分别诞生了像Spark和Flink两大Super Star框架,这两大框架的初衷Spark定位于离线计算,Flink定位于实时计算,但随着业务的发展,也是为了市场的占有,二者分别开始蚕食对方的领域,各自在自身的体系架构中融入了实时和离线计算,大有一统江湖之意。
1.Flink的安装和配置
去官网下载Flink安装包,放到虚拟机的某个目录下。
flink下载
用下面的命令解压:
tar -zxvf apache-flink-1.9.3.tar.gz修改配置,打开 /conf/flink-conf.yaml
jobmanager.rpc.address: localhost
rest.port: 8081根据自身情况修改这两个属性,第一个是jobmanager的地址,可以改成你的实际IP地址,第二个是Flink的Web客户端的端口号,如果默认的8081没有用,那就不用改,如果被占用,就改成其他的。
设置环境变量,打开 /etc/profile,增加:
export FLINK_HOME=/usr/local/flink-1.9.0/
export PATH=$PATH:$FLINK_HOME/bin用 source命令让环境变量生效。
进入flink安装目录的bin目录,输入下面的命令启动flink:
./start-cluster.sh在你的电脑的浏览器中敲下面的地址就可以访问Flink Web UI
http://192.136.11.100:8081/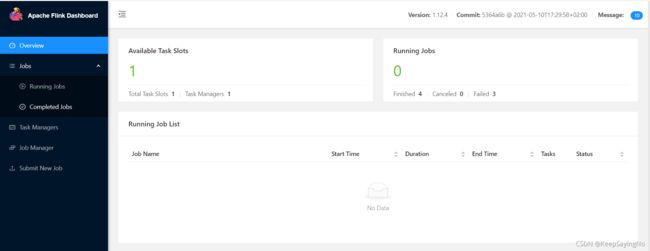
2.任务提交
flink的安装目录下的/examples目录下提供了丰富的例子,首先以经典WordCount为例,在flink的根目录下执行下面的命令:
./bin/flink run ./examples/streaming/WordCount.jar虚拟机会打印下面的信息:
Executing WordCount example with default input data set.
Use --input to specify file input.
Printing result to stdout. Use --output to specify output path.
Job has been submitted with JobID 94bbcabbc2e6a0cf6c534b3ad47d1fec
Program execution finished
Job with JobID 94bbcabbc2e6a0cf6c534b3ad47d1fec has finished.
Job Runtime: 288 ms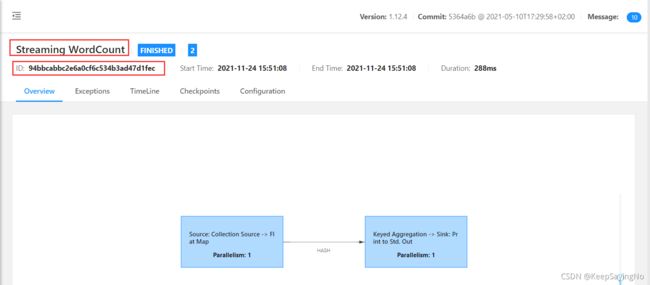
虚拟机上控制台输出的信息,JobID和在Web客户端上看到的 JobID是一致的,关于Job的名称是哪里来的后面的分析源码会讲到。这里有同学会问刚才执行任务的结果哪里可以看到,在日志里面可以看到,执行下面的命令查看结果:
tail -200f flink-root-taskexecutor-0-cdh100.out在上面的执行任务后,控制台输出的信息有这两句值得重视:
Use --input to specify file input.
Printing result to stdout. Use --output to specify output path.这两句话的意思是在执行任务的时候可以指定参数实现对指定目录的文件进行单词统计,然后输出到指定目录的输出文件。随便在哪个目录下新建一个txt文件,然后里面输入一些英文句子。执行下面的命令:
./bin/flink run ./examples/streaming/WordCount.jar --input /home/data.txt --output /home/out.txt最后可以在/home/out.txt看到结果
3.源码分析
ackage org.apache.flink.streaming.examples.wordcount;
import java.util.Iterator;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.utils.MultipleParameterTool;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.examples.wordcount.util.WordCountData;
import org.apache.flink.util.Preconditions;
public class WordCount {
public WordCount() {
}
public static void main(String[] args) throws Exception {
MultipleParameterTool params = MultipleParameterTool.fromArgs(args);
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.getConfig().setGlobalJobParameters(params);
DataStream text = null;
// 判断有没有带input参数,如果带了,就到这个指定目录下取文件,否则就用jar包带
// 的一个WordCountData类里面的常量字符串里面的数据
if (params.has("input")) {
Iterator var4 = params.getMultiParameterRequired("input").iterator();
while(var4.hasNext()) {
String input = (String)var4.next();
if (text == null) {
text = env.readTextFile(input);
} else {
text = ((DataStream)text).union(new DataStream[]{env.readTextFile(input)});
}
}
Preconditions.checkNotNull(text, "Input DataStream should not be null.");
} else {
System.out.println("Executing WordCount example with default input data set.");
System.out.println("Use --input to specify file input.");
text = env.fromElements(WordCountData.WORDS);
}
DataStream> counts = ((DataStream)text).flatMap(new org.apache.flink.streaming.examples.wordcount.WordCount.Tokenizer()).keyBy((value) -> {
return (String)value.f0;
}).sum(1);
// 判断有没有带output参数,如果带了,就将结果输出到该文件中
// 否则就将结果在日志中打印
if (params.has("output")) {
counts.writeAsText(params.get("output"));
} else {
System.out.println("Printing result to stdout. Use --output to specify output path.");
counts.print();
}
// 开始执行任务,这个方法的入参就是job的名字,这也是为什么在客户端上显示的
// 名字是Streaming WordCount
env.execute("Streaming WordCount");
}
} 4.体验实时计算
前面讲的flink的用法都是基于已有数据的统计,这和spark的统计大相径庭,flink最强大的就是实时统计,因此再讲一个例子,也是/examples文件下的,执行下面的命令,启动Job:
./bin/flink run ./examples/streaming/SocketWindowWordCount.jar --port 6666 这时会看到该Job一直处于在线状态:

用net-tools启动一个端口用来发送信息:
nc -l 6666 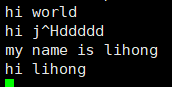
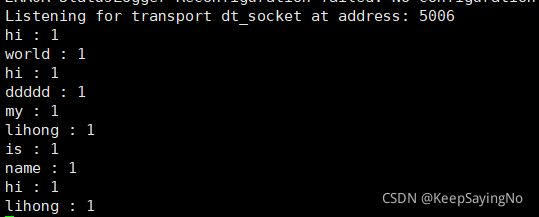
上述功能的实现源码:
package org.apache.flink.streaming.examples.socket;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.examples.socket.SocketWindowWordCount.1;
import org.apache.flink.streaming.examples.socket.SocketWindowWordCount.2;
public class SocketWindowWordCount {
public SocketWindowWordCount() {
}
public static void main(String[] args) throws Exception {
String hostname;
int port;
try {
ParameterTool params = ParameterTool.fromArgs(args);
hostname = params.has("hostname") ? params.get("hostname") : "localhost";
port = params.getInt("port");
} catch (Exception var6) {
System.err.println("No port specified. Please run 'SocketWindowWordCount --hostname --port ', where hostname (localhost by default) and port is the address of the text server");
System.err.println("To start a simple text server, run 'netcat -l ' and type the input text into the command line");
return;
}
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream text = env.socketTextStream(hostname, port, "\n");
DataStream windowCounts = text.flatMap(new 2()).keyBy((value) -> {
return value.word;
}).window(TumblingProcessingTimeWindows.of(Time.seconds(5L))).reduce(new 1());
windowCounts.print().setParallelism(1);
env.execute("Socket Window WordCount");
}
} 5.总结
本文首先了讲了如何安装和配置Flink,通过图文的方式能让读者在实操中遇到问题能迅速解决问题。进而通过两个Flink自带的例子教大家怎么样提交任务。欢迎大家在学习过程中遇到问题和我交流,可以留言,我会及时回复。