知物由学 | 告别挑花眼,AI算法如何筛选低质量图片?
知物由学 | 告别挑花眼,AI算法如何筛选低质量图片?
随着手机相机的升级,随手拿出手机拍照已经成为很多人不经意的日常,手机相册、电脑硬盘中存储的照片数量或许早已悄然过万。各类社交平台上,每一秒都有数不胜数的图片被上传和分享。
那么,如何才能轻松筛除手机相册中低质量的照片?如何才能从社交平台上的海量数据中挑选出高质量的图片用于首页展示和推荐?如何才能预先过滤低质量的图片以提高后续内容审核模型的效率……在面对这些难题时,图像质量评估算法体现出了极大的应用价值。
背景介绍
图像质量是一个宽泛的概念,在不同场景下、不同人的眼中,存在着不同的评价角度和评价标准。在摄影论坛上,专业设备拍摄的高清大片比比皆是,普通手机拍摄的照片略显逊色。
但在社交平台上,大多数图片都是用户上传的日常照片,那么手机拍摄的照片只要准确对焦、没有运动模糊,其图像质量通常已属前列。甚至有时图像失真也不一定是坏事。
例如对图1中的X光图像,人们希望它能够清晰地展现人体组织中的各种细节,因此难以容忍任何噪声,但在图2中,背景的拖影反而展现出了图像主体的高速运行,让图片更具动感。只要图像具有清晰的主体,人们对模糊背景的容忍度就很高。
由此可见,图像质量评估并没有普适的标准和统一的方法,往往需要根据不同的场景选用不同的方案。
 图1. X光图像
图1. X光图像
 图2. 高速运动的赛车照片
图2. 高速运动的赛车照片
当下,随着移动设备的普及和社交平台的流行,网络用户拍摄、上传、转载的图片数量呈爆炸式增长,监控和筛选图片数据重复且枯燥,借助于更高效的图像质量评估方法方为明智之举。
与此同时,这一应用场景也对图像质量评估方法提出了新的要求:受到用户的设备和审美水平的影响,线上图像的质量参差不齐。失真类型复杂多样且不可预测,这要求质量评估模型具备更加稳健的评估能力。
图像的失真类型
人类视觉系统对于图像质量的感知常常被笼统地称为图像清晰度。图像的清晰度受到很多因素的影响,包括失焦、相对运动(即物体运动和相机抖动)、不完善的成像系统(如镜头、相机感光模块性能较差)、图像后处理技术(如压缩和去噪)等。这些因素导致的图像失真,都会不同程度地影响图像质量。由于网络图像通常都会经过拍摄设备、网络传输、显示设备这三个节点,在这些节点上所产生的图像失真类型多样,且程度不一,使得网络图像的失真不同于特定小场景中较为单一的图像失真情况。其中,各种失真类型往往混杂交叠着出现,变化多样,对构建图像质量评估算法提出了更高的要求。
图像质量评估的三类方法
图像质量评估(Image Quality Assessment,IQA)是指通过对图像相关特性的分析,来评估图像的视觉失真程度。根据是否具有参考图像,图像质量评估可以分为全参考图像质量评估(Full Reference-IQA,FR-IQA)、半参考图像质量评估(Reduced Reference-IQA, RR-IQA)以及无参考图像质量评估(No Reference-IQA, NR-IQA),NR-IQA也称为盲参考图像质量评估(Blind IQA, BIQA)。全参考图像质量评估有原始图像作为参考,通过对比失真图像和原始图像的信息量或者某些维度的特征相似度来评估失真程度,难度较小。目前,很多成熟的方法和指标已被广泛使用,例如均方误差(MSE)、峰值信噪比(PSNR)、结构相似性(SSIM)等。FR-IQA常用于评估编解码算法性能、图像增强算法性能等场景,这些场景中天然地存在原始图像可作为参考。
 图3. 在FR-IQA的应用场景中(a)为参考图像, (b)-(f)为失真图像[1].
图3. 在FR-IQA的应用场景中(a)为参考图像, (b)-(f)为失真图像[1].
半参考图像质量评估以原始图像的部分信息,或从原始图像中提取的特征作为参考,难度介于全参考和无参考图像质量评估之间。
现实中最常见的场景是,没有参考图像也没有任何相关的信息,此时只能进行无参考图像质量评估。由于没有任何参考信息,无参考图像质量评估的难度最大。其核心在于,如何只依赖图像本身的信息构建一个合理的评估指标,使其尽可能贴近人类视觉对图像质量的感知。在网络图像的质量评估场景中,不存在参考图像,需要的正是无参考图像质量评估算法。
数据瓶颈
图像质量评估领域的数据集主要分为人工数据集和自然数据集。人工数据集是根据少量的真实图像,模拟生成一种或多种不同类型、不同程度的失真来构成失真图像数据集,常见的有TID2008、TID2013、LIVE、LIVEMD,其中TID2013规模最大,但也仅有来自25张参考图像的共3000张失真图像。人工数据集不仅规模小,更大的问题还在于失真类型过于单一,例如LIVEMD中虽然对每张参考图像叠加了两种不同的失真类型,但这与现实中的失真图像相比还是太单一了。自然失真图像的形成涉及许多复杂的因素,许多复杂的失真情况是难以通过人工模拟生成的,因此一些包含自然失真图像的数据集逐渐出现,例如LIVEC、WaterLoo Exploration、KonIQ-10k等。借助互联网众包项目,自然失真图像数据集规模正在逐渐扩大,但事实上扩充数据集的成本极高。图像质量评估算法的数据集构建不同于其他任务,由于图像质量概念存在主观性,为了得到较为客观的评分标签,每一张图像需要多人对其质量打分,最后取平均值(称为“平均主观意见得分”, MOS)作为标签。这导致标注成本比一般视觉任务高许多倍(通常是几十倍甚至上百倍)。小规模的数据集能够满足早期的传统图像质量评估算法,但对于依赖数据驱动的深度学习算法而言,则显得捉襟见肘。随着各个视觉任务对深度学习的广泛应用,数据集规模和昂贵的标注成本已经成为制约图像质量评估算法发展的瓶颈
无参考图像质量评估算法
传统的无参考图像质量评估算法通过对失真图像的一些特性来给出评估结果,不需要训练数据,但需要对失真图像的各种特性进行深入的研究,例如边缘的扩散、平滑效果、高频成分的减少或相位相干性的损失等各种模糊特性。由于不同的失真类型在图像上体现出不同的特点,最初的方法需要提前知道失真类型才能针对性地进行质量评估。例如一些方法通过对失真图像计算梯度图来表征图像的模糊失真,随后提取梯度图中与模糊失真相关的能量特征用于图像质量的预测。这类方法本质上是人工捕捉图像信息中与失真相关的规律,因此十分依赖图像数据的分布。当图像的失真类型未知,或同时存在多种不同的失真时,这类方法就很难利用某种特殊的特征来完成图像质量的评估。
**自然场景统计方法(Natural Scene Statistic, NSS)假设自然图像共享某一些特定的统计特征,当图像失真时,这些统计特征就会发生改变,这样就能够摆脱对先验失真信息的依赖。**例如自然图像的离散余弦变换系数分布呈现出脉冲状,这会直接导致熵值的差异,于是 BWS[2]采用Weibull模型来近似自然场景统计规则中的脉冲形状现象以及尖峰和重尾现象,从中提取特征并使用SVR来对图像质量进行评价;TCLT[3]进一步采用多通道融合的图像特征来模拟人类视觉系统的层次性和三色性特征,并采用K近邻模型来进行质量预测等。
虽然NSS方法在性能上获得了很大提升,但是手工特征在表征复杂的图像结构和失真信息时仍然能力有限。和计算机视觉领域的其他任务一样,图像质量评估领域特征提取方法的发展也经历了从手工特征到深度特征的过程。一般而言,深度学习特征相比手工设计的特征存在很大的优越性,但在图像质量评估领域,数据集的标注成本比其他图像任务高很多倍,导致数据集规模通常都很小,训练深度卷积网络存在过拟合问题。
因此,**一类基于深度学习的算法直接利用图像分类任务在大规模数据集上预训练得到的网络,来提取图像特征,再利用这些特征进行后处理来得到最终的评估结果。**BLNDER[4]考虑到了不同网络层对图像质量相关特征的敏感程度不同,从预训练好的VGG网络中提取多个网络层的特征表示来分别训练SVR并预测每层特征的质量评分,最后取各层得分的平均值作为输入图像最终的质量评分(如图4所示)。
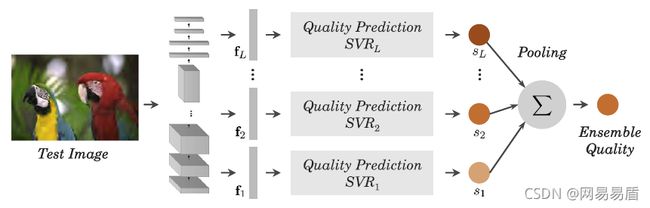 图4. BLNDER从预训练网络的多个层提取特征
图4. BLNDER从预训练网络的多个层提取特征
由于分类任务与质量评估任务之间的差异始终存在,如何扩大图像质量评估数据集实现深度网络端到端的有效训练,依然是一个需要探索的方向。一种扩充方式是将原图像分割成多个图像块,每个图像块采用原图的标签作为标签,例如CNN[5]、DIQaM[6]等。这类方法的问题在于,虽然数据规模增加了,但标签的准确性难以保证,因为图像块的质量与整体图像的质量并不总是一致的,正如图2中只包含背景区域的图像块和只包含主体区域的图像块,显然具有不同的质量评分。
因此DIQA[7]、BIECON[8]等方法结合了已有的全参考方法,在参考图像存在的情况下为图像块生成新的标签,当然这就引入了参考图像的限制。
**另一种扩充数据集的方法是从整体图像入手。**RankIQA [9]通过人工生成不同程度的失真图像来扩充数据集,虽然没有确定的质量得分标签,但可以根据失真程度对图像进行排序,从中抽取两张图像质量相对高低已知的图像构成图像对,来训练一个双生网络,最后取单路网络在小规模数据集上进行微调(如图5所示)。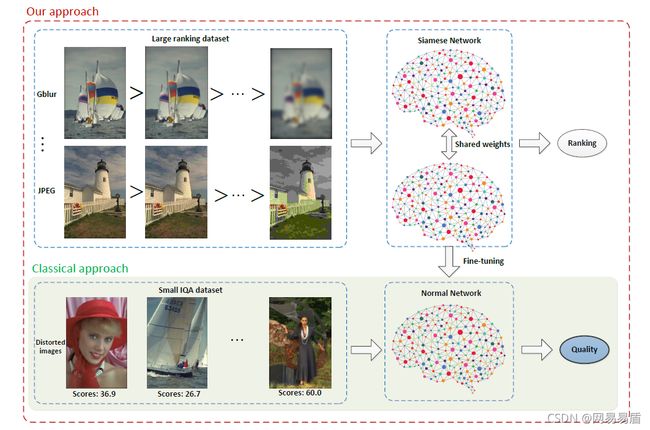 图5. RankIQ算法流程示意图
图5. RankIQ算法流程示意图
HIQA则借助GAN来扩充参考图像,让无参考图像评估跨越了没有原始图像作参照的鸿沟,如图6所示。通过GAN生成失真图像的参考图像,并与失真图像计算差值图,作为质量回归网络的输入来预测失真图像的质量,极大地提升了无参考图像质量评估模型的性能。
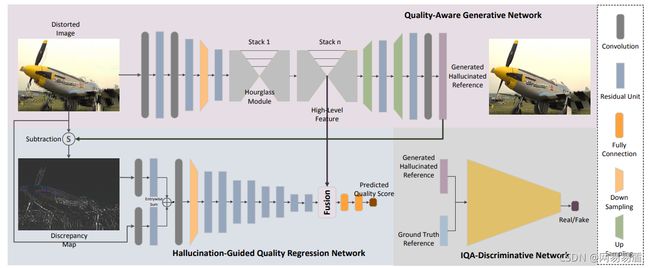 图6. HIQA算法流程示意图
图6. HIQA算法流程示意图
半监督训练方法
面对失真情况复杂且海量的互联网图像数据,为保证模型的鲁棒性,要求训练数据具有更丰富多样的失真类型。虽然RankIQA等方法通过人工模拟生成失真图像扩大了数据集规模,但难以充分模拟现实场景下的多样性。为了在不增加标注成本的前提下扩充训练集,我们引入了半监督的训练方法。
这类方法在图像分类任务上通过利用大量无标签数据获得了显著的性能提升,主要步骤包括:
(1)在小规模有标签数据集上训练获得初步的教师模型;
(2)用教师模型为大规模的无标签数据集生成伪标签;
(3)筛选某个置信度范围内的无标签数据作为新的训练集,筛选的目的是,在保证伪标签相对可靠的同时,该数据对模型而言又具有一定的学习难度;
(4)用新的无标签数据集训练学生模型;
(5)在有标签数据集上对学生模型进行微调。这类方法在图像分类任务上取得了很大的提升,但应用到图像质量评估任务上,存在三个主要问题,对此我们主要的解决方案如下:

借助现有无监督预训练参数和传统算法的模型融合结果获得初步的图像质量评估能力,进一步采用半监督训练方法扩充数据集,可以完全规避图像质量评估数据集有标签数据集规模太小的瓶颈,从而更好地发挥DNN模型在图像任务上的优势。
对大量真实网络数据的应用,显著扩大了模型训练数据的多样性,能够有效促进模型评分贴近人类主观感知。与在小规模数据集上直接训练模型得到的结果进行对比,经过半监督方法优化后的模型在包括但不限于以下几种类型的数据上具有显著的优势:
- 背景模糊但语义主体清晰的图像,优化后的模型评分更高,更符合人类重点关注语义主体清晰度的特点:
 优化前:0.78
优化前:0.78
优化后:0.94
 优化前:0.73
优化前:0.73
优化后:0.90
- 图像大片区域梯度变化较小时,传统算法和优化前的DNN模型均倾向于给出较低的评分,但优化后更符合人类感知特点:
 优化前:0.60
优化前:0.60
优化后:0.93
 优化前:0.75
优化前:0.75
优化后:0.99
- 图像存在明显的压缩损失等失真,但由于本身纹理信息丰富等原因,优化前的DNN模型均评分偏高,但优化后的模型评分更准确:
 优化前:0.59
优化前:0.59
优化后:0.10
 优化前:0.47
优化前:0.47
优化后:0.09
此外,在解决上述三个关键问题后,更多在图像分类任务获得成功的半监督方法也可以进一步引入到图像质量评估任务上进行更多的尝试和探索。
后记
在互联网图像质量评估场景下,稳健的图像质量评估模型可用于自动挑选质量较高的图片,配合美观度评估等模型可以进一步拓展算法的应用场景:
一是,手机相册中质量较低、较不美观的照片可以通过算法自动筛选和删除;
二是,社交平台可以通过上述算法挑选出高质量的图片用于首页推荐和展示,也可以对用户上传图片的质量进行及时检测和提醒;
三是,在内容审核环节为其他算法模型的输入数据提供前置质量检测功能。
半监督训练策略通过拓展训练数据规模,提高了模型的数据上限,让模型面对海量且多样的互联网数据时,依然稳定可靠。
【参考文献】
[1] Zhang, Lin, et al. “FSIM: A feature similarity indexfor image quality assessment.” IEEE transactions on ImageProcessing 20.8 (2011): 2378-2386.
[2] X. Yang, F. Li, W. Zhang, and L. He, ``Blind imagequality assessment of natural scenes based on entropy differences in the DCTdomain,’’ Entropy, vol. 20, no. 12, pp. 885_906, 2018.
[3] Q. Wu, H. Li, F. Meng, K. N. Ngan, B. Luo, C. Huang,and B. Zeng, ``Blind image quality assessment based on multichannel featurefusion and label transfer,’’ IEEE Trans. Circuits Syst. Video Technol.,vol. 26, no. 3, pp. 425_440, Mar. 2016.
[4] F. Gao, J. Yu, S. Zhu, Q. Huang, and Q. Tian, ``Blindimage quality prediction by exploiting multi-level deep representations,’’ PatternRecognit., vol. 81, pp. 432_442, Sep. 2018.
[5] L. Kang, P. Ye, Y. Li, and D. Doermann, ``Convolutionalneural networks for no-reference image quality assessment,’’ in Proc. IEEEConf. CVPR, Jun. 2014, pp. 1733_1740.
[6] S. Bosse, D. Maniry, K. R. Müller, T. Wiegand, and W.Samek, ``Deep neural networks for no-reference and full-reference image qualityassessment,’’ IEEE Trans. Image Process., vol. 27, no. 1, pp. 206_219,Jan. 2018.
[7] J. Kim, A.-D. Nguyen, and S. Lee, ``Deep CNN-basedblind image quality predictor,’’ IEEE Trans. Neural Netw. Learn. Syst.,vol. 30, no. 1, pp. 11_24, Jan. 2019.
[8] J. Kim and S. Lee, ``Fully deep blind image qualitypredictor,’’ IEEE J. Sel. Topics Signal Process., vol. 11, no. 1, pp.206_220, Feb. 2017.
[9] X. Liu, J. van de Weijer, and A. D. Bagdanov,``RankIQA: Learning from rankings for no-reference image quality assessment,’'in Proc. IEEE Conf. ICCV, Jun. 2017, pp. 1040_1049.
[10] K.-Y. Lin and G. Wang, ``Hallucinated-IQA:No-reference image quality assessment via adversarial learning,’’ in Proc.IEEE Conf. CVPR, Aug. 2018, pp. 732_741.