Hive简介
定义
Facebook为了解决海量日志数据的分析而开发了hive,后来开源给了Apache基金会组织。 hive是一种用SQL语句来协助读写、管理存储在HDFS上的大数据集的数据仓库软件。
hive特点
▪ hive 最大的特点是通过类 SQL 来分析大数据,而避免了写 mapreduce Java 程序来分析数据,这样使得分析数据更容易。
▪数据是存储在HDFS上的,hive本身并不提供数据的存储功能
▪hive是将数据映射成数据库和一张张的表,库和表的元数据信息一般存在关系型数据库上(比如MySQL)。
▪数据存储方面:他能够存储很大的数据集,并且对数据完整性、格式要求并不严格。
▪数据处理方面:不适用于实时计算和响应,使用于离线分析。
hive基本语法
hive中的语句有点类似于mysql语句,主要分为DDL,DML,DQL,在此笔者就不做详细介绍了,略微指出一点hive表分为内部表、外部表、分区表和分桶表,大数据培训感兴趣的读者可以查阅相关资料。
Hive原理
hive架构图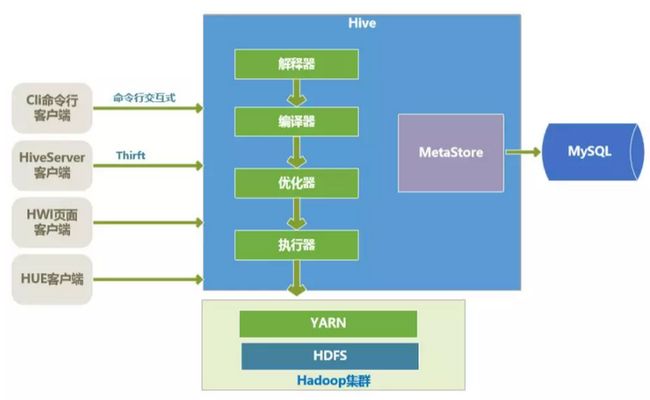
hive内核
hive 的内核是驱动引擎,驱动引擎由四部分组成,这四部分分别是:
▪解释器:解释器的作用是将hiveSQL语句转换为语法树(AST)。
▪编译器:编译器是将语法树编译为逻辑执行计划。
▪优化器:优化器是对逻辑执行计划进行优化。
▪执行器:执行器是调用底层的运行框架执行逻辑执行计划。
hive底层存储
hive的数据是存储在HDFS上,hive中的库和表可以看做是对HDFS上数据做的一个映射,所以hive必须运行在一个hadoop集群上。
hive程序执行过程
hive执行器是将最终要执行的mapreduce程序放到YARN上以一系列job的方式去执行。
hive元数据存储
hive的元数据是一般是存储在MySQL这种关系型数据库上的,hive与MySQL之间通过 MetaStore服务交互。
表2 hive元数据相关信息

hive客户端
hive有很多种客户端,下边简单列举了几个:
▪ cli命令行客户端:采用交互窗口,用hive命令行和hive进行通信。
▪ hiveServer2客户端:用Thrift协议进行通信,Thrift是不同语言之间的转换器,是连接不同语言程序间的协议,通过JDBC或者ODBC去访问hive(这个是目前hive官网推荐使用的连接方式)。
▪ HWI客户端:hive自带的客户端,但是比较粗糙,一般不用。
▪ HUE客户端:通过Web页面来和hive进行交互,使用比较,一般在CDH中进行集成。
Hive调优
hadoop就像吞吐量巨大的轮船,启动开销大,如果每次只做小数量的输入输出,利用率将会很低。所以用好hadoop的首要任务是增大每次任务所搭载的数据量。hive优化时,把hive Sql当做mapreduce 程序来读,而不是当做SQL来读。hive优化这要从三个层面进行,分别是基于mapreduce优化、hive架构层优化和hiveQL层优化。
基于mapreduce优化
合理设置map数
上面的mapreduce执行过程部分介绍了,在执行map函数之前会先将HDFS上文件进行分片,得到的分片做为map函数的输入,所以map数量取决于map的输入分片(inputsplit),一个输入分片对应于一个map task,输入分片由三个参数决定,如表3:
表3 输入分片决定参数
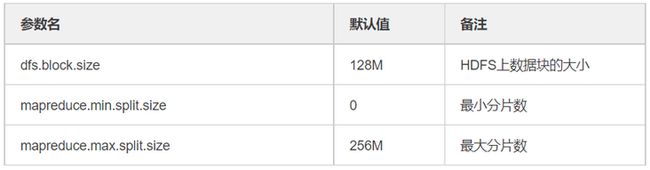
公式:分片大小=max(mapreduce.min.split.size,min(dfs.block.size, mapreduce.max.split.size)),默认情况下分片大小和dfs.block.size是一致的,即一个HDFS数据块对应一个输入分片,对应一个map task。这时候一个map task中只处理一台机器上的一个数据块,不需要将数据跨网络传输,提高了数据处理速度。
合理设置reduce数
决定 reduce 数量的相关参数如表4:
表4 reduce数决定参数
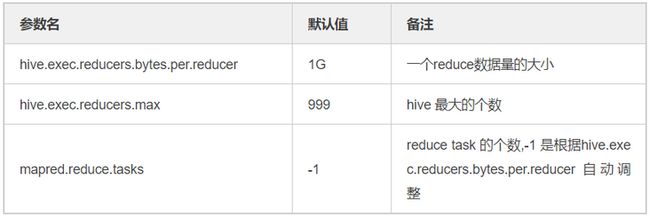
所以可以用set mapred.reduce.tasks手动调整reduce task个数。
hive架构层优化
不执行mapreduce
hive从HDFS读取数据,有两种方式:启用mapreduce读取、直接抓取。
set hive.fetch.task.conversion=more
hive.fetch.task.conversion参数设置成more,可以在 select、where 、limit 时启用直接抓取方式,能明显提升查询速度。
本地执行mapreduce
hive在集群上查询时,默认是在集群上N台机器上运行,需要多个机器进行协调运行,这个方式很好地解决了大数据量的查询问题。但是当hive查询处理的数据量比较小时,其实没有必要启动分布式模式去执行,因为以分布式方式执行就涉及到跨网络传输、多节点协调等,并且消耗资源。这个时间可以只使用本地模式来执行mapreduce job,只在一台机器上执行,速度会很快。
JVM重用
因为hive语句最终要转换为一系列的mapreduce job的,而每一个mapreduce job是由一系列的map task和Reduce task组成的,默认情况下,mapreduce中一个map task或者一个Reduce task就会启动一个JVM进程,一个task执行完毕后,JVM进程就退出。这样如果任务花费时间很短,又要多次启动JVM的情况下,JVM的启动时间会变成一个比较大的消耗,这个时候,就可以通过重用JVM来解决。
set mapred.job.reuse.jvm.num.tasks=5
这个设置就是制定一个jvm进程在运行多次任务之后再退出,这样一来,节约了很多的 JVM的启动时间。
并行化
一个hive sql语句可能会转为多个mapreduce job,每一个job就是一个stage,这些 job 顺序执行,这个在hue的运行日志中也可以看到。但是有时候这些任务之间并不是是相互依赖的,如果集群资源允许的话,可以让多个并不相互依赖stage并发执行,这样就节约了时间,提高了执行速度,但是如果集群资源匮乏时,启用并行化反倒是会导致各个job相互抢占资源而导致整体执行性能的下降。
启用并行化:
set hive.exec.parallel=true
hiveQL层优化
利用分区表优化
分区表是在某一个或者某几个维度上对数据进行分类存储,一个分区对应于一个目录。在这中的存储方式,当查询时,如果筛选条件里有分区字段,那么hive只需要遍历对应分区目录下的文件即可,不用全局遍历数据,使得处理的数据量大大减少,提高查询效率。
当一个hive表的查询大多数情况下,会根据某一个字段进行筛选时,那么非常适合创建为分区表。
利用桶表优化
桶表的概念在本教程第一步有详细介绍,就是指定桶的个数后,存储数据时,根据某一个字段进行哈希后,确定存储再哪个桶里,这样做的目的和分区表类似,也是使得筛选时不用全局遍历所有的数据,只需要遍历所在桶就可以了。
hive.optimize.bucketmapJOIN=true;
hive.input.format=org.apache.hadoop.hive.ql.io.bucketizedhiveInputFormat;
hive.optimize.bucketmapjoin=true;
hive.optimize.bucketmapjoin.sortedmerge=true;
join优化
▪ 优先过滤后再join,最大限度地减少参与join的数据量。
▪ 小表join大表原则
应该遵守小表join大表原则,原因是join操作的reduce阶段,位于join左边的表内容会被加载进内存,将条目少的表放在左边,可以有效减少发生内存溢出的几率。join中执行顺序是从做到右生成job,应该保证连续查询中的表的大小从左到右是依次增加的。
▪ join on条件相同的放入一个job
hive中,当多个表进行join时,如果join on的条件相同,那么他们会合并为一个
mapreduce job,所以利用这个特性,可以将相同的join on的放入一个job来节省执行时间。
select pt.page_id,count(t.url) PV
from rpt_page_type pt join ( select url_page_id,url from trackinfo where ds='2016-10-11' ) t on pt.page_id=t.url_page_id join ( select page_id from rpt_page_kpi_new where ds='2016-10-11' ) r on t.url_page_id=r.page_id group by pt.page_id;
▪ 启用mapjoin
mapjoin是将join双方比较小的表直接分发到各个map进程的内存中,在map进程中进行join操作,这样就省掉了reduce步骤,提高了速度。
▪ 桶表mapjoin
当两个分桶表join时,如果join on的是分桶字段,小表的分桶数时大表的倍数时,可以启用map join来提高效率。启用桶表mapjoin要启用hive.optimize.bucketmapjoin参数。
▪ Group By数据倾斜优化
Group By很容易导致数据倾斜问题,因为实际业务中,通常是数据集中在某些点上,这也符合常见的2/8原则,这样会造成对数据分组后,某一些分组上数据量非常大,而其他的分组上数据量很小,而在mapreduce程序中,同一个分组的数据会分配到同一个reduce操作上去,导致某一些reduce压力很大,其他的reduce压力很小,这就是数据倾斜,整个job 执行时间取决于那个执行最慢的那个reduce。
解决这个问题的方法是配置一个参数:set hive.groupby.skewindata=true。
当选项设定为true,生成的查询计划会有两个MR job。第一个MR job 中,map的输出结果会随机分布到Reduce中,每个Reduce做部分聚合操作,并输出结果,这样处理的结果是相同的Group By Key有可能被分发到不同的Reduce中,从而达到负载均衡的目的;第二个MR job再根据预处理的数据结果按照Group By Key分布到Reduce中(这个过程可以保证相同的GroupBy Key被分布到同一个Reduce中),最后完成最终的聚合操作。
▪ Order By 优化
因为order by只能是在一个reduce进程中进行的,所以如果对一个大数据集进行order by,会导致一个reduce进程中处理的数据相当大,造成查询执行超级缓慢。
▪ 一次读取多次插入
▪ Join字段显示类型转换
▪ 使用orc、parquet等列式存储格式
原创作者:bling ss