ansible 测试_如何测试Ansible并发疯
ansible 测试
It is the translation of my speech at DevOps-40 2020-03-18:
这是我在DevOps-40 2020-03-18上 演讲的翻译:
After the second commit, each code becomes legacy. It happens because the original ideas do not meet actual requirements for the system. It is not bad or good thing. It is the nature of infrastructure & agreements between people. Refactoring should align requirements & actual state. Let me call it Infrastructure as Code refactoring.
第二次提交后,每个代码都变为旧版。 发生这种情况是因为最初的想法不符合系统的实际要求。 这不是坏事也不是好事。 这是人与人之间基础设施和协议的本质。 重构应符合需求和实际状态。 让我称之为“基础结构即代码重构”。
旧版拦截 (Legacy interception)
第1天:零患者 (Day № 1: Patient zero)
There was a project. It was a casual project, nothing special. There were operations engineers and developers. They were dealing with exactly the same task: how to provision an application. However, there was a problem: each team tried to do in a unique way. They had decided to deal with it & use Ansible as the source of the truth.
有一个项目。 这是一个休闲项目,没什么特别的。 有运营工程师和开发人员。 他们正在处理完全相同的任务:如何配置应用程序。 但是,有一个问题:每个团队都试图以一种独特的方式来做。 他们决定处理它,并使用Ansible作为真理的源头。
№89:传承 (Day № 89: Legacy arise)

Time was ticking, they were doing as much as possible, unfortunately, they got legacy. How did this happen?
时间在流逝,他们正在尽力而为,不幸的是,他们得到了遗产。 这怎么发生的?
- There were a bunch of ASAP tasks. 有很多ASAP任务。
- It was ok do not write the documentation. 可以,不要写文档。
- They didn't have enough knowledge about ansible. 他们没有关于ansible的足够知识。
- Maybe, there were some Full Stack Overflow Developers — it was ok to copy-paste a solution from the StackOverflow. 也许有一些Full Stack Overflow开发人员-可以从StackOverflow复制粘贴解决方案。
- There was lack communication. 缺乏沟通。
The reasons were well known. There was nothing special. It was a standard process. IaC was behaving like code: it was becoming outdated, it had to be maintained & actualized.
原因众所周知。 没有什么特别的。 这是一个标准过程。 IaC的行为类似于代码:它已经过时,必须维护和实现。
第109天:好的,我们有。 下一步是什么? (Day № 109: Ok, we have. What's next?)
Original idea / model of IaC became outdated & stuck. IaC did not meet business / customers / users requirements. It became hard to maintain the IaC, they were wasting time struggling with kludges. It was epiphany moment.
IaC的原始想法/模型已经过时并陷入困境。 IaC不符合业务/客户/用户要求。 维持IaC变得很困难,因为他们浪费时间与kludge斗争。 那是顿悟时刻。
重构IaC (Refactoring IaC)
№139:您真的需要IaC重构吗? (Day № 139: Do you really need IaC refactoring?)
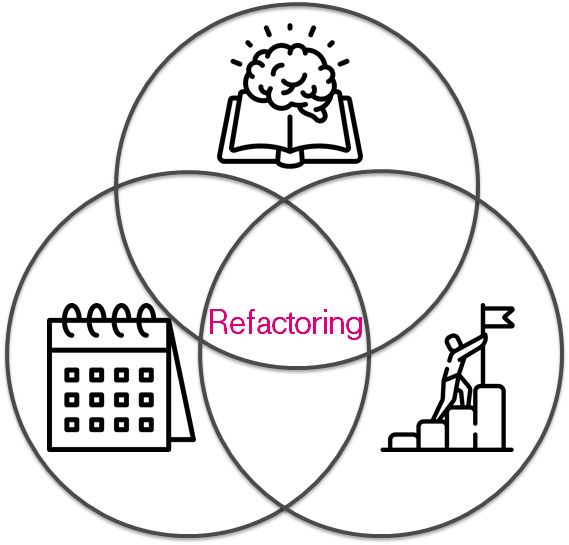
First of all before refactoring you must answer three simple questions:
首先,在重构之前,您必须回答三个简单的问题:
Do I have a reason?
我有理由吗?
Do I have enough time?
我有足够的时间吗?
Do I have enough knowledge that?
我是否有足够的知识?
If your answers are no, then refactoring might be a problem or challenge for you. You can do things worse.
如果您的答案是否定的,那么重构对您可能是一个问题或挑战。 您可以做的更糟。
In our case the project knew that our infrastructure team had a pretty good experience in the IaC refactoring (Lessons learned from testing Over 200,000 lines of Infrastructure Code), so our infrastructure team kindly agreed to help with refactoring. It was part of our daily routine to refactor the project.
在我们的案例中,该项目知道我们的基础架构团队在IaC重构方面具有相当不错的经验( 从测试超过200,000行基础架构代码中学到的经验教训 ),因此我们的基础架构团队衷心同意为重构提供帮助。 重构项目是我们日常工作的一部分。
第149天:准备进行重构 (Day № 149: Prepare to refactor)
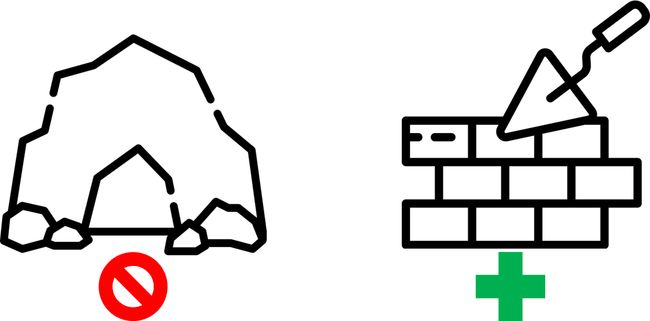
First of all, we had to determine the goal. We were talking, digging into the processes & researching how to deal with the problems. After researches we made & presented the main concept. The main idea was split infrastructure code into small parts and deal with each part separately. It allowed us to cover by tests each piece of the infrastructure and understood the functionality of that piece of infrastructure. As a result, we were able to refactor infrastructure little by little without breaking agreements.
首先,我们必须确定目标。 我们正在交谈,深入研究流程并研究如何解决问题。 经过研究,我们提出并提出了主要概念。 主要思想是将基础结构代码分成小部分,并分别处理每个部分。 它使我们能够通过测试覆盖基础结构的每个部分,并了解该基础结构的功能。 结果,我们能够在不违反协议的情况下一点一点地重构基础架构。
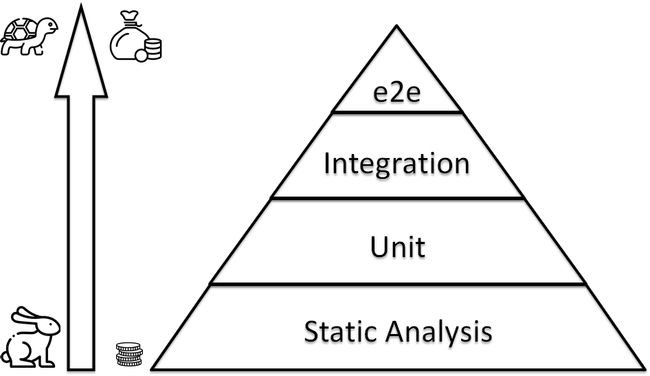
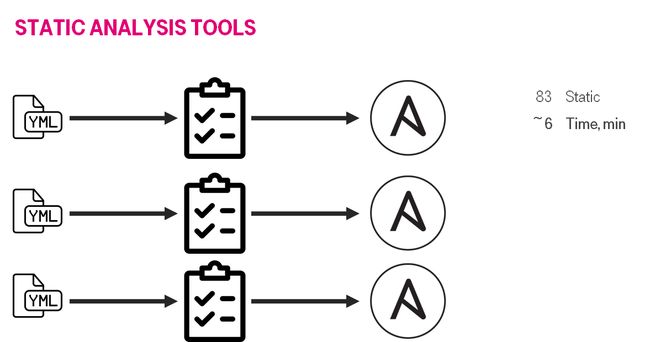
Let me mention about the IaC testing pyramid. If we are talking that Infrastructure is Code, then we should reuse practices from development for infrastructure, i.e. unit testing, pair DevOpsing, code review… etc… One of this approaches is a software testing & using testing pyramid for that. My idea is:
让我谈谈IaC测试金字塔。 如果我们说基础架构就是代码,那么我们应该重用基础架构开发中的实践,例如单元测试,配对DevOpsing,代码审查等等。其中一种方法是软件测试和为此使用测试金字塔。 我的想法是:
static — shellcheck/ansible lint
静态 — Shellcheck / Anible皮棉
unit — molecule/kitchen + testinfra/inspec for basic blocks: modules, roles, etc
单元 —分子/厨房+ testinfra / inspec基本模块:模块,角色等
integration — check whole server configuration — group of roles. again molecule/kitchen
集成 -检查整个服务器配置-角色组。 再分子/厨房
e2e(end to end) — check that group of servers work correctly as an infrastructure
e2e(端到端) —检查服务器组作为基础结构是否正常工作
如何测试Ansible? (How to test Ansible?)
Before the other part of the story let me share my attempts to Ansible before that project. It is important because I want to share the context.
在故事的另一部分之前,让我在该项目之前与Ansible分享我的尝试。 这很重要,因为我想共享上下文。
第№-997天:提供SDS (Day № -997: SDS provision)
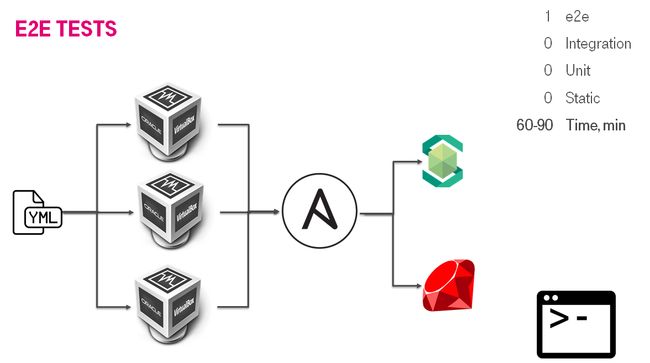
It was a couple of projects before. We were developing SDS (Software Defined Storage). That was software and hardware appliance. The appliance consisted of custom OS distributive, upscale servers, a lot of business logic. As part of SDS, we had a bunch of processes i.e. how to provision the SDS installation. For provisioning we used Ansible. To make a short story long: we had reverted IaC testing pyramid. We had an e2e test and they lasted 60-90 minutes. It was too slow. The main idea was to create the installation & emulate a user activity(i.e. mount iSCSI & write something). We created the IaC testing solution.
之前是几个项目。 我们正在开发SDS(软件定义的存储)。 那是软件和硬件设备。 该设备由自定义OS分布式高端服务器和许多业务逻辑组成。 作为SDS的一部分,我们有很多流程,即如何配置SDS安装。 对于供应,我们使用了Ansible。 长话短说:我们恢复了IaC测试金字塔。 我们进行了e2e测试,测试持续了60-90分钟。 太慢了。 主要思想是创建安装并模拟用户活动(即安装iSCSI并编写内容)。 我们创建了IaC测试解决方案。
You can read a bit more: How to test your own OS distribution.
您可以阅读更多内容: 如何测试自己的OS发行版 。
№-701:Ansible和测试厨房 (Day № -701: Ansible & test kitchen)
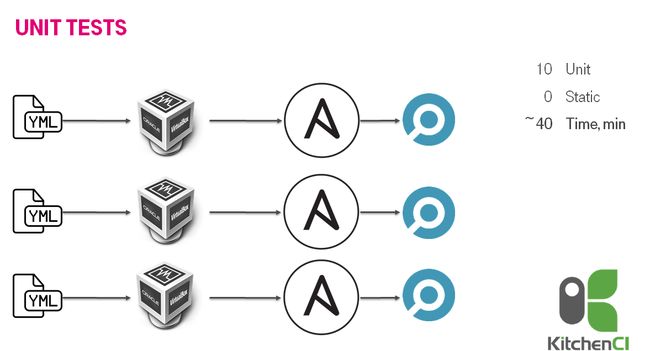
The next idea was not to reinvent the wheel & use production-ready solution, i.e. test kitchen / kitchen-ci & inspec. We decided to use it because we had enough expertise in the ruby world. We were creating VMs inside a VM. It was working more or less fine: 40 minutes for 10 roles.
下一个想法不是重新发明轮子,而是使用可用于生产的解决方案,即测试kitchen / kitchen-ci和inspec。 我们决定使用它,因为我们在Ruby领域拥有足够的专业知识。 我们正在虚拟机内部创建虚拟机。 它的运行情况差不多不错:10个角色需要40分钟。
You can read a bit more: Test me if you can. Do YML developers Dream of testing ansible?.
您可以阅读更多内容: 如果可以,请测试一下。 YML开发人员是否梦想过测试? 。
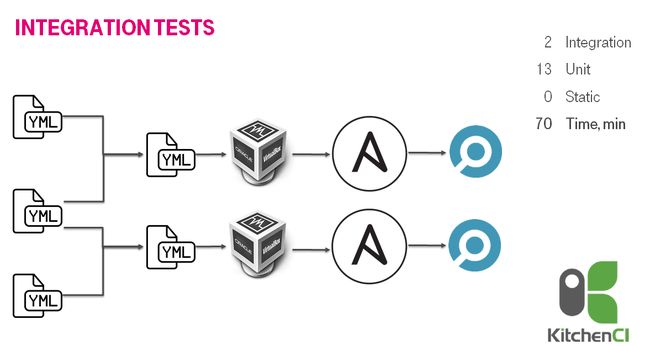
In general, it was a stable solution. However, when we increased the number of tested roles to 15(13 base roles + 2 meta roles) we faced an issue. The speed of tests felt down dramatically to 70 minutes. It was to slow. We were not able to think about XP (extreme programming) practices.
通常,这是一个稳定的解决方案。 但是,当我们将测试角色的数量增加到15(13个基本角色+ 2个元角色)时,我们遇到了一个问题。 测试速度急剧下降到70分钟。 太慢了。 我们无法考虑XP(极限编程)实践。
第-601天:Ansible和分子 (Day № -601: Ansible & molecule)

It triggered us to use molecule & docker. As a result, we had 20-25 minutes for 7 roles.
它触发了我们使用Molecular & docker 。 结果,我们有20-25分钟的时间来担任7个角色。
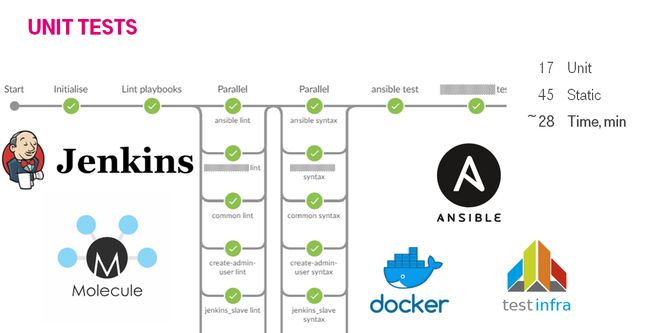
We increased the number of tested roles to 17 & linted playbooks to 45. It lasted about 28 minutes with 2 Jenkins slaves.
我们将经过测试的角色的数量增加到17个,而皮下的剧本则增加到45个。与2个Jenkins奴隶一起进行了大约28分钟。
第167天:将测试引入项目 (Day № 167: Introduce tests to the project)

It was a bad idea to test all roles from the very beginning. Because it was an immense change. We wanted to change the project little by little and avoid problems. So, we arranged the S.M.A.R.T. goal lint all roles. We were enabling linting roles/playbooks one by one. It was yak shaving: we were slowly improving the project and creating the culture.
从一开始就测试所有角色是一个坏主意。 因为这是一个巨大的变化。 我们希望一点一点地改变项目并避免出现问题。 因此,我们安排了SMART目标的所有角色。 我们正在逐一启用lint角色/剧本。 ving牛刮胡子:我们正在慢慢改进项目并创造文化。
It is not really important how to shave the yak. It might be stickers on the wardrobe, tasks in the Jira or spreadsheet in the google docs. The main idea you should track current status & understand how it is going. You should not burn out during refactoring, because it is a long boring journey.
如何剃the牛并不是很重要。 它可能是衣橱上的贴纸,Jira中的任务或Google文档中的电子表格。 您应该跟踪当前状态并了解其发展的主要思路。 在重构期间,您不应该精疲力尽,因为这是一个漫长的无聊旅程。
Refactoring is easy as pie:
重构很简单:
Eat.
吃。
Sleep.
睡觉。
Code.
码。
IaC test.
IaC测试。
Repeat
重复
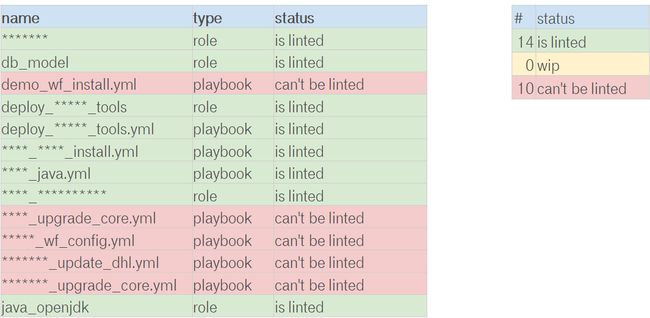
So, we with started from the linting. It was a good start point.
因此,我们从起毛开始。 这是一个很好的起点。
第181天:绿色建筑大师 (Day № 181: Green Build Master)
Linting was the very first step to the Green Build Master. I costed almost nothing, but it created good habits & processes inside the team:
Linting是迈向Green Build Master的第一步。 我几乎不花任何钱,但是它在团队内部建立了良好的习惯和流程:
- Red test is bad, you should fix it. 红色测试不好,您应该修复它。
- If you see code smell — improve it. 如果看到代码异味,请改善它。
- Code must be better after you. 您编写的代码一定更好。
第№193天:整理->单元测试 (Day № 193: Linting -> Unit tests)

We had processes how to change the master branch. The next step was to replace linting via real roles applying. We had to understand how roles were implemented and why.
我们已经有了如何更改master分支的过程。 下一步是通过实际角色申请替换棉绒。 我们必须了解角色的实施方式以及原因。
第211天:单元测试->集成测试 (Day № 211: Unit tests -> Integration tests)
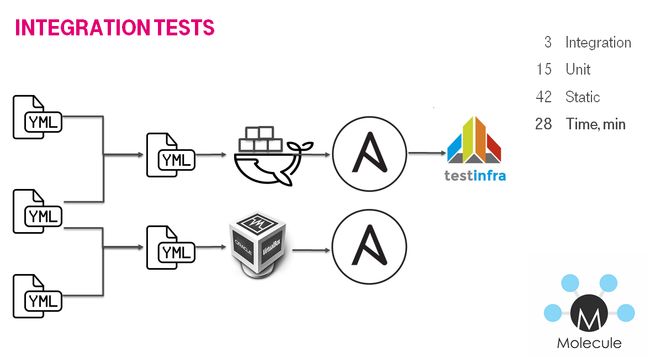
We finished with unit tests. The vas majority of roles were tested after each commit. The next step was the integration tests. We had to test the combination of simple bricks which creates the building — whole server configuration.
我们完成了单元测试。 每次提交后,对大多数角色进行了测试。 下一步是集成测试。 我们必须测试创建建筑物的简单砖块的组合-整个服务器配置。
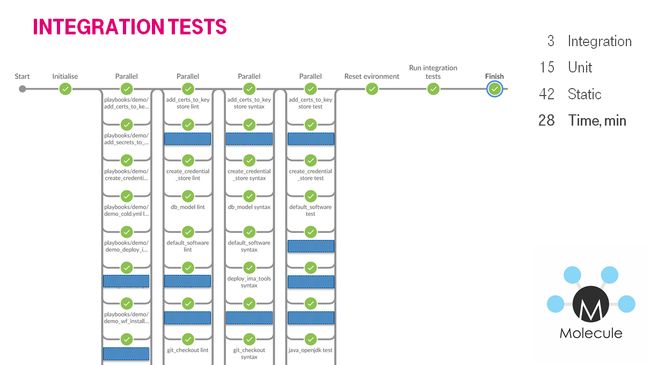
We were generating bunch of stages. The stages were executing simultaneously.
我们正在产生一堆阶段。 这些阶段是同时执行的。
Jenkins + Docker + Ansible =测试 (Jenkins + Docker + Ansible = Tests)

- Checkout repo and generate build stages. 签出回购并生成构建阶段。
- Run lint playbook stages in parallel. 并行运行皮棉剧本阶段。
- Run lint role stages in parallel. 并行运行lint角色阶段。
- Run syntax check role stages in parallel. 并行运行语法检查角色阶段。
Run test role stages in parallel.
并行运行测试角色阶段。
- Lint role. 皮棉角色。
- Check dependency on other roles. 检查对其他角色的依赖性。
- Check syntax. 检查语法。
- Create docker instance 创建Docker实例
- Run molecule/default/playbook.yml. 运行Molecular / default / playbook.yml。
- Check idempotency. 检查幂等性。
- Run integration tests 运行集成测试
- Finish 完
第271天:公交车因素 (Day№ 271: Bus Factor)
At the beginning of the project, there were a small amount of people. They were reviewers. Time was ticking and knowledge on how to write ansible roles were spread across all teams members. The interesting thing was that we were rotating reviewer on the 2 weeks basis.
在项目开始时,人数很少。 他们是审稿人。 时间在流逝,所有团队成员都散布了有关如何编写反角色的知识。 有趣的是,我们每两周轮换一次审稿人。
The review had to be simple & reviewer friendly. So, we integrated Jenkins + bitbucket + Jira for that. Unfortunately, the review is not a silver bullet. I.e. we missed bad code to the master and had flapped unstable tests.
审查必须简单且审查员友好。 因此,我们为此集成了Jenkins + bitbucket + Jira。 不幸的是,该评论不是万灵丹。 也就是说,我们错过了错误的代码给主机,并扑灭了不稳定的测试。
- get_url:
url: "{
{ actk_certs }}/{
{ item.1 }}"
dest: "{
{ actk_src_tmp }}/"
username: "{
{ actk_mvn_user }}"
password: "{
{ actk_mvn_pass }}"
with_subelements:
- "{
{ actk_cert_list }}"
- "{
{ actk_certs }}"
delegate_to: localhost
- copy:
src: "{
{ actk_src_tmp }}/{
{ item.1 }}"
dest: "{
{ actk_dst_tmp }}"
with_subelements:
- "{
{ actk_cert_list }}"
- "{
{ actk_certs }}"Fortunately, we fixed that:
幸运的是,我们修复了以下问题:
get_url:
url: "{
{ actk_certs }}/{
{ actk_item }}"
dest: "{
{ actk_src_tmp }}/{
{ actk_item }}"
username: "{
{ actk_mvn_user }}"
password: "{
{ actk_mvn_pass }}"
loop_control:
loop_var: actk_item
with_items: "{
{ actk_cert_list }}"
delegate_to: localhost
- copy:
src: "{
{ actk_src_tmp }}/{
{ actk_item }}"
dest: "{
{ actk_dst_tmp }}"
loop_control:
loop_var: actk_item
with_items: "{
{ actk_cert_list }}"第311天:加快测试速度 (Day № 311: Speed up tests)

Amount of tests was increasing, the project was growing. As a result, in the bad case out tests were executing for 60 minutes. For dealing with that we decided to remove integration tests via VMs & use the only docker. Also, we replaced testinfra via ansible verifier for unifying toolset.
测试数量在增加,项目也在增长。 结果,在最坏的情况下,测试执行了60分钟。 为了解决这个问题,我们决定通过VM删除集成测试并使用唯一的docker。 另外,我们通过ansible验证程序替换了testinfra,以统一工具集。
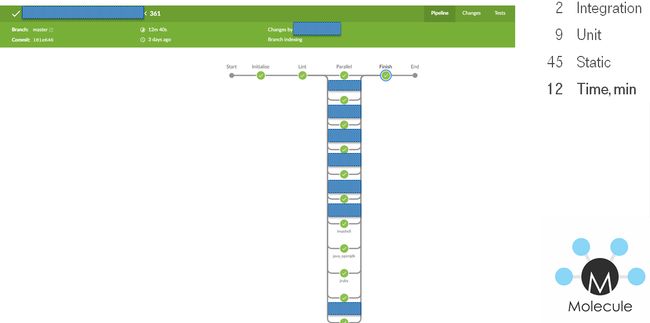
We made some changes:
我们进行了一些更改:
- Migrated to the docker. 迁移到Docker。
- Removed duplicated tests & simplified dependencies. 删除重复的测试和简化的依赖关系。
- Increased amount of Jenkins slaves. 詹金斯奴隶数量增加。
- Changed test execution order. 更改了测试执行顺序。
- Added ability lint all via a single command, it helped to lint all locally via 1 command. 通过单个命令添加了全部功能,可以通过1条命令在本地完成全部功能。
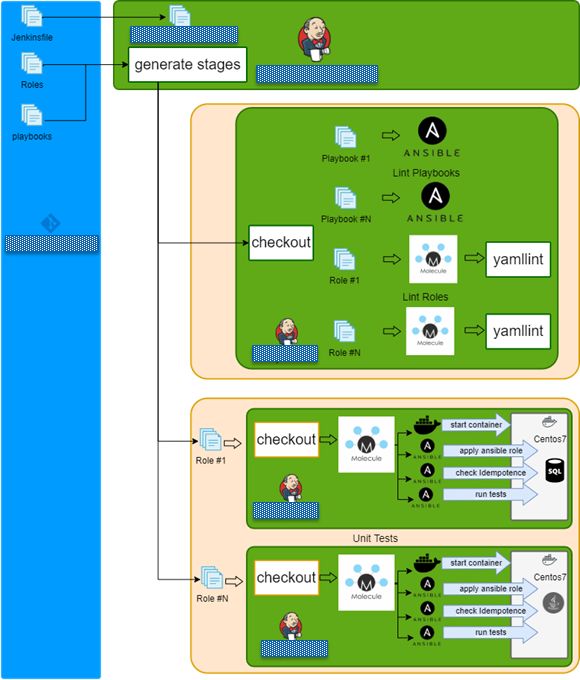
As a result, of that changes, the Jenkins pipeline also was changed
结果,Jenkins管道也发生了变化
- Generate build stages. 生成构建阶段。
- Lint all in parallel. 平行所有棉绒。
- Run test role stages in parallel. 并行运行测试角色阶段。
- Finish. 完。
得到教训 (Lessons learned)
Let me share some lessons learned
让我分享一些经验教训
避免全局变量 (Avoid global variables)
Ansible uses the global variable namespace. I know about workaround via private_role_vars, but it is not a silver bullet.
Ansible使用全局变量名称空间。 我知道通过private_role_vars解决方法,但这不是灵丹妙药。
Let us create two roles role_a & role_b
让我们创建两个角色role_a和role_b
# cat role_a/defaults/main.yml
---
msg: a
# cat role_a/tasks/main.yml
---
- debug:
msg: role_a={
{ msg }}# cat role_b/defaults/main.yml
---
msg: b
# cat role_b/tasks/main.yml
---
- set_fact:
msg: b
- debug:
msg: role_b={
{ msg }}- hosts: localhost
vars:
msg: hello
roles:
- role: role_a
- role: role_b
tasks:
- debug:
msg: play={
{msg}}
We often need some variables to be accessible globally and shared between different role. One obvious example is JAVA_HOME. Ansible has a flat namespace, and this can lead to variable names collisions. For example, two roles (say, webserver and mailserver) may use the same variable named 'port'; such a variable may be accidentally overwritten with the same value in both roles. It's better to prefix variable names in your roles either by a role name, or some short form of it.
我们通常需要一些变量可以全局访问并在不同角色之间共享。 一个明显的例子是JAVA_HOME。 Ansible具有平面名称空间,这可能导致变量名冲突。 例如,两个角色(例如,Web服务器和邮件服务器)可以使用同一个名为“端口”的变量。 在两个角色中,这样的变量可能会意外地被相同的值覆盖。 最好在角色中使用变量名或它的短形式作为变量名的前缀。
BAD: use a global variable.
BAD :使用全局变量。
# cat roles/some_role/tasks/main.yml
---
debug:
var: java_homeGOOD: In this case, it's a good idea to define such a variable in the inventory, and use a local variable in your role with a default value of the global one. This way the roles are kind of self-contained, and it's easy to see what variables the role uses just by looking into the defaults.
良好 :在这种情况下,最好在清单中定义一个这样的变量,并在您的角色中使用局部变量,其默认值为全局变量。 这样,角色便是独立的,只需查看默认值,就很容易看出角色使用了哪些变量。
# cat roles/some_role/defaults/main.yml
---
r__java_home:
"{
{ java_home | default('/path') }}"
# cat roles/some_role/tasks/main.yml
---
debug:
var: r__java_home前缀角色变量 (Prefix role variables)
It makes sense to use the role name as the prefix for a variable. it helps to understand the source inventory easier.
使用角色名称作为变量的前缀是有意义的。 它有助于更容易地了解源清单。
BAD: use a global variable.
BAD :使用全局变量。
# cat roles/some_role/defaults/main.yml
---
db_port: 5432GOOD: Prefix variable.
GOOD :前缀变量。
# cat roles/some_role/defaults/main.yml
---
some_role__db_port: 5432使用循环控制变量 (Use the loop control variable)
BAD: If you use standard item and somebody decides to loop your role you can face unpredictable issues.
不好 :如果您使用标准item ,但有人决定扮演您的角色,那么您可能会遇到不可预测的问题。
---
- hosts: localhost
tasks:
- debug:
msg: "{
{ item }}"
loop:
- item1
- item2GOOD: Override the default variable via loop_var.
好的 :通过loop_var覆盖默认变量。
---
- hosts: localhost
tasks:
- debug:
msg: "{
{ item_name }}"
loop:
- item1
- item2
loop_control:
loop_var: item_name检查输入变量 (Check input variables)
If your role requires input roles it makes sense to raise if they are not presented.
如果您的角色需要输入角色,那么如果没有显示输入角色,则有必要提高。
GOOD: Check variables.
良好 :检查变量。
- name: "Verify that required string variables are defined"
assert:
that: ahs_var is defined and ahs_var | length > 0 and ahs_var != None
fail_msg: "{
{ ahs_var }} needs to be set for the role to work "
success_msg: "Required variables {
{ ahs_var }} is defined"
loop_control:
loop_var: ahs_var
with_items:
- ahs_item1
- ahs_item2
- ahs_item3避免使用哈希字典,使用扁平结构 (Avoid hashes dictionaries, use a flat structure)
While dictionaries may seem like a good fit for your variables, you should minimize their usage due to the following:
尽管字典似乎很适合您的变量,但由于以下原因,您应尽量减少使用它们:
- It's not possible for a user to change only one element of a dictionary. 用户不可能只更改字典中的一个元素。
Dictionary elements cannot take values from other elements.
字典元素不能从其他元素获取值。
Example: A dictionary that stores some OS user:
示例:存储一些OS用户的字典:
BAD: Use hash/dictionary.
不良 :使用哈希/字典。
---
user:
name: admin
group: adminDownsides: you cannot set the default group name to the user name; if a person using your role wants to customize only the name, they must also supply the group. With regular variables, those issues are gone: Both variables can be changed independently, and the default group name matches the user name.
缺点:您不能将默认组名设置为用户名; 如果使用您的角色的人仅想自定义名称,则他们还必须提供该组。 使用常规变量,这些问题就消除了:可以独立更改两个变量,并且默认组名与用户名匹配。
GOOD: Use flatten structure & prefix variable.
好的 :使用扁平化的结构和前缀变量。
---
user_name: admin
user_group: "{
{ user_name }}"创建幂等的剧本和角色 (Create idempotent playbooks & roles)
Roles and playbooks have to be idempotent. It decreases your fear to run a role. As a resul, configuration drift is a minimum as possible.
角色和剧本必须是幂等的。 它减少了您扮演角色的恐惧。 作为结果,配置漂移是最小的。
避免使用命令外壳模块 (Avoid using command shell modules)
Imperative approach via command / shell modules is instead of declarative ansible nature.
通过命令/外壳模块的命令式方法不是声明性的本质。
通过分子测试您的角色 (Test your roles via molecule)
The molecule is pretty flexible, let me show some examples:
该分子非常灵活,让我展示一些例子:
分子多个实例 (Molecule Multiple instances)
In the molecule.yml in the platforms you can describe a bunch of instances:
在platforms的molecule.yml中,您可以描述一堆实例:
---
driver:
name: docker
platforms:
- name: postgresql-instance
hostname: postgresql-instance
image: registry.example.com/postgres10:latest
pre_build_image: true
override_command: false
network_mode: host
- name: app-instance
hostname: app-instance
pre_build_image: true
image: registry.example.com/docker_centos_ansible_tests
network_mode: hostAfter that you can use the instances in the converge.yml:
之后,您可以在converge.yml使用实例:
---
- name: Converge all
hosts: all
vars:
ansible_user: root
roles:
- role: some_role
- name: Converge db
hosts: db-instance
roles:
- role: some_db_role
- name: Converge app
hosts: app-instance
roles:
- role: some_app_roleAnsible验证程序 (Ansible verifier)
Molecule allows you to use ansible verifier instead of inspec / testinfra / serverspec. It's the default from the 3.0 version.
Molecule允许您使用ansible验证程序代替inspec / testinfra / serverspec。 这是3.0版本的默认设置。
You can check that file contains expected body:
您可以检查文件是否包含预期的正文:
---
- name: Verify
hosts: all
tasks:
- name: copy config
copy:
src: expected_standalone.conf
dest: /root/wildfly/bin/standalone.conf
mode: "0644"
owner: root
group: root
register: config_copy_result
- name: Certify that standalone.conf changed
assert:
that: not config_copy_result.changedOr you can start the service & perform a smoke test:
或者,您可以启动服务并执行烟雾测试:
---
- name: Verify
hosts: solr
tasks:
- command: /blah/solr/bin/solr start -s /solr_home -p 8983 -force
- uri:
url: http://127.0.0.1:8983/solr
method: GET
status_code: 200
register: uri_result
until: uri_result is not failed
retries: 12
delay: 10
- name: Post documents to solr
command: /blah/solr/bin/post -c master /exampledocs/books.csv将复杂的逻辑放入模块和插件 (Put complex logic into modules & plugins)
Ansible nature is a declarative approach & YAML. It is extremely hard to use standard developers patterns as is because there is no syntax sugar for that. If you want to implement complex not straight logic in a playbook usually it will be ugly. Fortunately, you can customize ansible via creating your own modules & plugins.
Ansible本质是一种声明式方法和YAML。 照原样使用标准开发人员模式非常困难,因为它没有语法糖。 如果要在剧本中实现复杂的非直截了当的逻辑,通常会很难看。 幸运的是,您可以通过创建自己的模块和插件来定制ansible。
总结技巧和窍门 (Summarize Tips & Tricks)
- Avoid global variables. 避免使用全局变量。
- Prefix role variables. 前缀角色变量。
- Use the loop control variable. 使用循环控制变量。
- Check input variables. 检查输入变量。
- Avoid hashes dictionaries, use a flat structure. 避免使用哈希字典,使用扁平结构。
- Create idempotent playbooks & roles. 创建幂等的剧本和角色。
- Avoid using command shell modules. 避免使用命令外壳模块。
- Test your roles via molecule. 通过分子测试您的角色。
- Put complex logic into modules & plugins. 将复杂的逻辑放入模块和插件中。
结论 (Conclusion)
One does not simply refactor agreements & infrastructure. It is a long interesting journey.
一个不只是重构协议和基础架构。 这是一段漫长而有趣的旅程。
链接 (Links)
Slides How to test Ansible and don't go nuts
幻灯片如何测试Ansible,不要发疯
Video How to test Ansible and don't go nuts
视频如何测试Ansible并别发狂
Lessons learned from testing Over 200,000 lines of Infrastructure Code
测试超过200,000行基础架构代码的经验教训
How to test your own OS distribution
如何测试自己的操作系统发行版
Test me if you can. Do YML developers Dream of testing ansible?
可以的话测试一下。 YML开发人员是否梦想过测试?
Ansible: Coreos to centos, 18 months long journey
Ansible:Coreos到centos,历时18个月
A list of awesome IaC testing articles, speeches & links
很棒的IaC测试文章,演讲和链接列表
cross psot
交叉点
Russion version
俄版
翻译自: https://habr.com/en/post/500226/
ansible 测试