解析器是功能强大的工具,使用ANTLR,您可以编写可用于多种不同语言的各种解析器。
在本完整的教程中,我们将要:
- 解释基础 :解析器是什么,解析器可以用于什么
- 了解如何设置要从Javascript,Python,Java和C#中使用的ANTLR
- 讨论如何测试解析器
- 展示ANTLR中最先进,最有用的功能 :您将学到解析所有可能的语言所需的一切
- 显示大量示例
也许您已经阅读了一些过于复杂或过于局部的教程,似乎以为您已经知道如何使用解析器。 这不是那种教程。 我们只希望您知道如何编码以及如何使用文本编辑器或IDE。 而已。
在本教程的最后:
- 您将能够编写一个解析器以识别不同的格式和语言
- 您将能够创建构建词法分析器和解析器所需的所有规则
- 您将知道如何处理遇到的常见问题
- 您将了解错误,并且将知道如何通过测试语法来避免错误。
换句话说,我们将从头开始,到结束时,您将学到所有可能需要了解ANTLR的知识。

ANTLR Mega Tutorial Giant目录列表
什么是ANTLR?
ANTLR是解析器生成器,可帮助您创建解析器的工具。 解析器获取一段文本并将其转换为一个组织化的结构 ,例如抽象语法树(AST)。 您可以将AST看作是描述代码内容的故事,也可以看作是通过将各个部分放在一起而创建的逻辑表示。
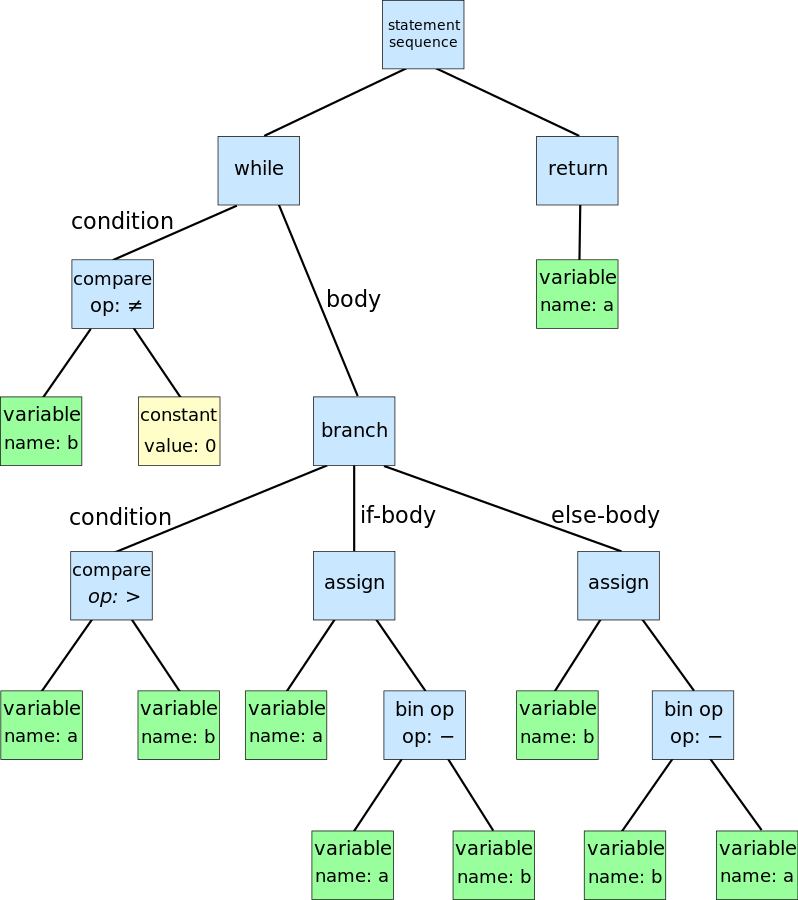
欧氏算法的AST的图形表示
获得AST所需要做的事情:
- 定义词法分析器和语法分析器
- 调用ANTLR:它将以您的目标语言(例如Java,Python,C#,Javascript)生成一个词法分析器和解析器
- 使用生成的词法分析器和解析器:调用它们并传递代码以进行识别,然后它们会返回给您AST
因此,您需要首先为要分析的事物定义一个词法分析器和解析器语法。 通常,“事物”是一种语言,但它也可以是数据格式,图表或任何以文本表示的结构。
正则表达式不够吗?
如果您是典型的程序员,您可能会问自己: 为什么我不能使用正则表达式 ? 正则表达式非常有用,例如当您想在文本字符串中查找数字时,它也有很多限制。
最明显的是缺乏递归:除非您为每个级别手动编码,否则您无法在另一个表达式中找到一个(正则)表达式。 很快就无法维持的事情。 但是更大的问题是它并不是真正可扩展的:如果您只将几个正则表达式放在一起,就将创建一个脆弱的混乱,将很难维护。
使用正则表达式不是那么容易
您是否尝试过使用正则表达式解析HTML? 这是一个可怕的想法,因为您冒着召唤克苏鲁的危险,但更重要的是, 它实际上并没有奏效 。 你不相信我吗 让我们看一下,您想要查找表的元素,因此尝试像这样的常规扩展: (.*?)
style或id类的属性。 没关系,您执行tr和td ,但是它们已满标签。
因此,您也需要消除这种情况。 而且甚至有人甚至敢使用<!—我的评论&gtl->之类的评论。 注释可以在任何地方使用,并且使用正则表达式不容易处理。 是吗?
因此,您禁止Internet使用HTML中的注释:已解决问题。
或者,您也可以使用ANTLR,对您而言似乎更简单。
ANTLR与手动编写自己的解析器
好的,您确信需要一个解析器,但是为什么要使用像ANTLR这样的解析器生成器而不是构建自己的解析器呢?
ANTLR的主要优势是生产率
如果您实际上一直在使用解析器,因为您的语言或格式在不断发展,则您需要能够保持步伐,而如果您必须处理实现a的细节,则无法做到这一点。解析器。 由于您不是为了解析而解析,因此您必须有机会专注于实现目标。 而ANTLR使得快速,整洁地执行此操作变得更加容易。
其次,定义语法后,您可以要求ANTLR生成不同语言的多个解析器。 例如,您可以使用C#获得一个解析器,而使用Javascript获得一个解析器,以在桌面应用程序和Web应用程序中解析相同的语言。
有人认为,手动编写解析器可以使其更快,并且可以产生更好的错误消息。 这有些道理,但以我的经验,ANTLR生成的解析器总是足够快。 如果确实需要,您可以调整语法并通过处理语法来提高性能和错误处理。 只要对语法感到满意,就可以这样做。
目录还是可以的
两个小注意事项:
- 在本教程的配套存储库中,您将找到所有带有测试的代码,即使我们在本文中没有看到它们
- 示例将使用不同的语言,但是知识通常适用于任何语言
设定
- 设定ANTLR
- Javascript设置
- Python设置
- Java设置
- C#设定
初学者
- 词法分析器
- 创建语法
- 设计数据格式
- Lexer规则
- 解析器规则
- 错误与调整
中级
- 用Javascript设置聊天项目
- Antlr.js
- HtmlChatListener.js
- 与听众合作
- 用语义谓词解决歧义
- 用Python继续聊天
- 与侦听器配合使用的Python方法
- 用Python测试
- 解析标记
- 词汇模式
- 解析器文法
高级
- Java中的标记项目
- 主App.java
- 使用ANTLR转换代码
- 转换代码的喜悦与痛苦
- 高级测试
- 处理表情
- 解析电子表格
- C#中的电子表格项目
- Excel注定了
- 测试一切
结束语
- 技巧和窍门
- 结论
设定
在本节中,我们准备使用ANTLR的开发环境:解析器生成器工具,每种语言的支持工具和运行时。
1.设置ANTLR
ANTLR实际上由两个主要部分组成:用于生成词法分析器和解析器的工具,以及运行它们所需的运行时。
语言工程师将只需要您使用该工具,而运行时将包含在使用您的语言的最终软件中。
无论您使用哪种语言,该工具始终是相同的:这是开发计算机上所需的Java程序。 尽管每种语言的运行时都不同,但是开发人员和用户都必须可以使用它。
该工具的唯一要求是您已经安装了至少Java 1.7 。 要安装Java程序,您需要从官方站点下载最新版本,当前版本为:
http://www.antlr.org/download/antlr-4.6-complete.jar使用说明
- 将下载的工具复制到通常放置第三方Java库的位置(例如
/usr/local/lib或C:\Program Files\Java\lib) - 将工具添加到您的
CLASSPATH。 将其添加到您的启动脚本中(例如.bash_profile) - (可选)还在您的启动脚本中添加别名,以简化ANTLR的使用
在Linux / Mac OS上执行说明
// 1.
sudo cp antlr-4.6-complete.jar /usr/local/lib/
// 2. and 3.
// add this to your .bash_profile
export CLASSPATH=".:/usr/local/lib/antlr-4.6-complete.jar:$CLASSPATH"
// simplify the use of the tool to generate lexer and parser
alias antlr4='java -Xmx500M -cp "/usr/local/lib/antlr-4.6-complete.jar:$CLASSPATH" org.antlr.v4.Tool'
// simplify the use of the tool to test the generated code
alias grun='java org.antlr.v4.gui.TestRig'在Windows上执行说明
// 1.
Go to System Properties dialog > Environment variables
-> Create or append to the CLASSPATH variable
// 2. and 3. Option A: use doskey
doskey antlr4=java org.antlr.v4.Tool $*
doskey grun =java org.antlr.v4.gui.TestRig $*
// 2. and 3. Option B: use batch files
// create antlr4.bat
java org.antlr.v4.Tool %*
// create grun.bat
java org.antlr.v4.gui.TestRig %*
// put them in the system path or any of the directories included in %path%典型工作流程
使用ANTLR时,首先要编写语法 ,即扩展名为.g4的文件,其中包含要分析的语言规则。 然后,您可以使用antlr4程序来生成程序将实际使用的文件,例如词法分析器和解析器。
antlr4 运行antlr4时可以指定几个重要选项。
首先,您可以指定目标语言,以Python或JavaScript或任何其他不同于Java的目标(默认语言)生成解析器。 其他的用于生成访问者和侦听器(不要担心,如果您不知道这些是什么,我们将在后面进行解释)。
缺省情况下,仅生成侦听器,因此要创建访问者,请使用-visitor命令行选项,如果不想生成-no-listener则使用-no-listener listener。 也有相反的选项-no-visitor和-listener ,但它们是默认值。
antlr4 -visitor 您可以使用一个名为TestRig (的小实用工具来优化语法测试TestRig (尽管,如我们所见,它通常是grun的别名)。
grun 文件名是可选的,您可以代替分析在控制台上键入的输入。
如果要使用测试工具,则即使您的程序是用另一种语言编写的,也需要生成Java解析器。 这可以通过选择与antlr4不同的选项来antlr4 。
手动测试语法初稿时,Grun非常有用。 随着它变得更加稳定,您可能希望继续进行自动化测试(我们将看到如何编写它们)。
Grun还有一些有用的选项: -tokens ,显示检测到的令牌, -gui生成AST的图像。
2. Javascript设置
您可以将语法与Javascript文件放在同一文件夹中。 包含语法的文件必须具有与语法相同的名称,该名称必须在文件顶部声明。
在下面的示例中,名称为Chat ,文件为Chat.g4 。
通过使用ANTLR4 Java程序指定正确的选项,我们可以创建相应的Javascript解析器。
antlr4 -Dlanguage=JavaScript Chat.g4请注意,该选项区分大小写,因此请注意大写的“ S”。 如果您输入有误,则会收到类似以下的消息。
error(31): ANTLR cannot generate Javascript code as of version 4.6 ANTLR可以与node.js一起使用,也可以在浏览器中使用。 对于浏览器,您需要使用webpack或require.js 。 如果您不知道如何使用两者之一,可以查阅官方文档寻求帮助或阅读网络上的antlr教程。 我们将使用node.js ,只需使用以下标准命令即可为之安装ANTLR运行时。
npm install antlr43. Python设置
有了语法后,请将其放在与Python文件相同的文件夹中。 该文件必须具有与语法相同的名称,该名称必须在文件顶部声明。 在下面的示例中,名称为Chat ,文件为Chat.g4 。
通过使用ANTLR4 Java程序指定正确的选项,我们可以简单地创建相应的Python解析器。 对于Python,您还需要注意Python的版本2或3。
antlr4 -Dlanguage=Python3 Chat.g4PyPi提供了运行时,因此您可以使用pio进行安装。
pip install antlr4-python3-runtime同样,您只需要记住指定正确的python版本。
4. Java设定
要使用ANTLR设置我们的Java项目,您可以手动执行操作。 或者您可以成为文明的人并使用Gradle或Maven。
另外,您可以在IDE中查看ANTLR插件。
4.1使用Gradle进行Java设置
这就是我通常设置Gradle项目的方式。
我使用Gradle插件调用ANTLR,也使用IDEA插件生成IntelliJ IDEA的配置。
dependencies {
antlr "org.antlr:antlr4:4.5.1"
compile "org.antlr:antlr4-runtime:4.5.1"
testCompile 'junit:junit:4.12'
}
generateGrammarSource {
maxHeapSize = "64m"
arguments += ['-package', 'me.tomassetti.mylanguage']
outputDirectory = new File("generated-src/antlr/main/me/tomassetti/mylanguage".toString())
}
compileJava.dependsOn generateGrammarSource
sourceSets {
generated {
java.srcDir 'generated-src/antlr/main/'
}
}
compileJava.source sourceSets.generated.java, sourceSets.main.java
clean{
delete "generated-src"
}
idea {
module {
sourceDirs += file("generated-src/antlr/main")
}
}我将语法放在src / main / antlr /下 ,并且gradle配置确保它们在与程序包相对应的目录中生成。 例如,如果我希望解析器位于包me.tomassetti.mylanguage中,则必须将其生成到generate-src / antlr / main / me / tomassetti / mylanguage中 。
此时,我可以简单地运行:
# Linux/Mac
./gradlew generateGrammarSource
# Windows
gradlew generateGrammarSource然后我从语法中生成了词法分析器和解析器。
然后我也可以运行:
# Linux/Mac
./gradlew idea
# Windows
gradlew idea我已经准备好要打开一个IDEA项目。
4.2使用Maven进行Java设置
首先,我们将在POM中指定需要antlr4-runtime作为依赖项。 我们还将使用Maven插件通过Maven运行ANTLR。
我们还可以指定是否使用ANTLR来生成访问者或侦听器。 为此,我们定义了几个相应的属性。
4.0.0
[..]
UTF-8
true
true
org.antlr
antlr4-runtime
4.6
[..]
[..]
org.antlr
antlr4-maven-plugin
4.6
antlr4
[..]
现在,您必须将语法的* .g4文件放在src/main/antlr4/me/tomassetti/examples/MarkupParser.
编写完语法后,您只需运行mvn package ,所有奇妙的事情就会发生:ANTLR被调用,它会生成词法分析器和解析器,并将它们与其余代码一起编译。
// use mwn to generate the package
mvn package如果您从未使用过Maven,则可以查看Java目标的官方ANTLR文档或Maven网站来入门。
使用Java开发ANTLR语法有一个明显的优势:有多个IDE的插件,这是该工具的主要开发人员实际使用的语言。 因此,它们是org.antlr.v4.gui.TestRig类的工具,可以轻松地集成到您的工作流中,如果您想轻松地可视化输入的AST,这些工具将非常有用。
5. C#设置
支持.NET Framework和Mono 3.5,但不支持.NET Core。 我们将使用Visual Studio创建我们的ANTLR项目,因为由C#目标的同一作者为Visual Studio创建了一个不错的扩展,称为ANTLR语言支持 。 您可以通过进入工具->扩展和更新来安装它。 当您构建项目时,此扩展将自动生成解析器,词法分析器和访问者/侦听器。
此外,该扩展名将允许您使用众所周知的菜单添加新项目来创建新的语法文件。 最后但并非最不重要的一点是,您可以在每个语法文件的属性中设置用于生成侦听器/访问者的选项。
另外,如果您更喜欢使用编辑器,则需要使用常规的Java工具生成所有内容。 您可以通过指示正确的语言来做到这一点。 在此示例中,语法称为“电子表格”。
antlr4 -Dlanguage=CSharp Spreadsheet.g4请注意,CSharp中的“ S”为大写。
您仍然需要项目的ANTLR4运行时,并且可以使用良好的nu'nuget安装它。
初学者
在本节中,我们为使用ANTLR奠定了基础:什么是词法分析器和解析器,在语法中定义它们的语法以及可用于创建它们的策略。 我们还将看到第一个示例,以展示如何使用所学知识。 如果您不记得ANTLR的工作原理,可以回到本节。
6.词法分析器
在研究解析器之前,我们需要首先研究词法分析器,也称为令牌化器。 它们基本上是解析器的第一个垫脚石,当然ANTLR也允许您构建它们。 词法分析器将各个字符转换为令牌 (解析器用来创建逻辑结构的原子)。
想象一下,此过程适用于自然语言,例如英语。 您正在阅读单个字符,将它们放在一起直到形成一个单词,然后将不同的单词组合成一个句子。
让我们看下面的示例,并想象我们正在尝试解析数学运算。
437 + 734词法分析器扫描文本,然后找到“ 4”,“ 3”,“ 7”,然后找到空格“”。 因此,它知道第一个字符实际上代表一个数字。 然后,它找到一个“ +”符号,因此知道它代表一个运算符,最后找到另一个数字。

它怎么知道的? 因为我们告诉它。
/*
* Parser Rules
*/
operation : NUMBER '+' NUMBER ;
/*
* Lexer Rules
*/
NUMBER : [0-9]+ ;
WHITESPACE : ' ' -> skip ;这不是一个完整的语法,但是我们已经可以看到词法分析器规则全部为大写,而解析器规则全部为小写。 从技术上讲,关于大小写的规则仅适用于其名称的第一个字符,但通常为了清楚起见,它们全都为大写或小写。
规则通常按以下顺序编写:首先是解析器规则,然后是词法分析器规则,尽管在逻辑上它们是按相反的顺序应用的。 同样重要的是要记住, 词法分析器规则是按照它们出现的顺序进行分析的 ,它们可能是不明确的。
典型的例子是标识符:在许多编程语言中,它可以是任何字母字符串,但是某些组合(例如“ class”或“ function”)被禁止,因为它们表示一个class或function 。 因此,规则的顺序通过使用第一个匹配项来解决歧义,这就是为什么首先定义标识关键字(例如类或函数)的令牌,而最后一个用于标识符的令牌的原因。
规则的基本语法很容易: 有一个名称,一个冒号,该规则的定义和一个终止分号
NUMBER的定义包含一个典型的数字范围和一个“ +”符号,表示允许一个或多个匹配项。 这些都是我认为您熟悉的非常典型的指示,否则,您可以阅读有关正则表达式的语法的更多信息。
最后,最有趣的部分是定义WHITESPACE令牌的词法分析器规则。 这很有趣,因为它显示了如何指示ANTLR忽略某些内容。 考虑一下忽略空白如何简化解析器规则:如果我们不能说忽略WHITESPACE,则必须将其包括在解析器的每个子规则之间,以便用户在所需的地方放置空格。 像这样:
operation : WHITESPACE* NUMBER WHITESPACE* '+' WHITESPACE* NUMBER;注释通常也是如此:它们可以出现在任何地方,并且我们不想在语法的每个部分中都专门处理它们,因此我们只是忽略它们(至少在解析时)。
7.创建语法
现在,我们已经了解了规则的基本语法,下面我们来看看定义语法的两种不同方法:自顶向下和自底向上。
自上而下的方法
这种方法包括从以您的语言编写的文件的一般组织开始。
文件的主要部分是什么? 他们的顺序是什么? 每个部分中包含什么?
例如,Java文件可以分为三个部分:
- 包装声明
- 进口
- 类型定义
当您已经知道要为其设计语法的语言或格式时,此方法最有效。 具有良好理论背景的人或喜欢从“大计划”入手的人可能会首选该策略。
使用这种方法时,首先要定义代表整个文件的规则。 它可能会包括其他规则,以代表主要部分。 然后,您定义这些规则,然后从最一般的抽象规则过渡到底层的实用规则。
自下而上的方法
自下而上的方法包括首先关注小元素:定义如何捕获令牌,如何定义基本表达式等等。 然后,我们移至更高级别的构造,直到定义代表整个文件的规则。
我个人更喜欢从底层开始,这些基本项目是使用词法分析器进行分析的。 然后您自然地从那里成长到结构,该结构由解析器处理。 这种方法允许只关注语法的一小部分,为此建立语法,确保其按预期工作,然后继续进行下一个工作。
这种方法模仿了我们的学习方式。 此外,从实际代码开始的好处是,在许多语言中,实际代码实际上是相当普遍的。 实际上,大多数语言都具有标识符,注释,空格等内容。显然,您可能需要进行一些调整,例如HTML中的注释在功能上与C#中的注释相同,但是具有不同的定界符。
自底向上方法的缺点在于解析器是您真正关心的东西。 不要求您构建一个词法分析器,而是要求您构建一个可以提供特定功能的解析器。 因此,如果您不了解程序的其余部分如何工作,那么从最后一部分词法分析器开始,您可能最终会进行一些重构。
8.设计数据格式
为新语言设计语法是困难的。 您必须创建一种对用户来说简单而直观的语言,同时又要明确地使语法易于管理。 它必须简洁,清晰,自然,并且不会妨碍用户。
因此,我们从有限的内容开始:一个简单的聊天程序的语法。
让我们从对目标的更好描述开始:
- 不会有段落,因此我们可以使用换行符作为消息之间的分隔符
- 我们要允许表情符号,提及和链接。 我们将不支持HTML标签
- 由于我们的聊天将针对讨厌的青少年,因此我们希望为用户提供一种简单的方法来喊叫和设置文本颜色的格式。
最终,少年们可能会大喊大叫,全是粉红色。 多么活着的时间。
9. Lexer规则
我们首先为聊天语言定义词法分析器规则。 请记住,词法分析器规则实际上位于文件的末尾。
/*
* Lexer Rules
*/
fragment A : ('A'|'a') ;
fragment S : ('S'|'s') ;
fragment Y : ('Y'|'y') ;
fragment H : ('H'|'h') ;
fragment O : ('O'|'o') ;
fragment U : ('U'|'u') ;
fragment T : ('T'|'t') ;
fragment LOWERCASE : [a-z] ;
fragment UPPERCASE : [A-Z] ;
SAYS : S A Y S ;
SHOUTS : S H O U T S;
WORD : (LOWERCASE | UPPERCASE | '_')+ ;
WHITESPACE : (' ' | '\t') ;
NEWLINE : ('\r'? '\n' | '\r')+ ;
TEXT : ~[\])]+ ;在此示例中,我们使用规则片段 :它们是词法分析器规则的可重用构建块。 您定义它们,然后在词法分析器规则中引用它们。 如果定义它们但不将它们包括在词法分析器规则中,则它们根本无效。
我们为要在关键字中使用的字母定义一个片段。 这是为什么? 因为我们要支持不区分大小写的关键字。 除了避免重复字符的情况以外,在处理浮点数时也使用它们。 为了避免重复数字,请在点/逗号之前和之后。 如下面的例子。
fragment DIGIT : [0-9] ;
NUMBER : DIGIT+ ([.,] DIGIT+)? ;TEXT令牌显示如何捕获所有内容,除了波浪号('〜')之后的字符以外。 我们不包括右方括号']',但是由于它是用于标识一组字符结尾的字符,因此必须在其前面加上反斜杠'\'来对其进行转义。
换行规则是用这种方式制定的,因为操作系统实际上指示换行的方式不同,有些包括carriage return ('\r') ,有些包括newline ('\n') ,或者二者结合。
10.解析器规则
我们继续解析器规则,这些规则是我们的程序将与之最直接交互的规则。
/*
* Parser Rules
*/
chat : line+ EOF ;
line : name command message NEWLINE;
message : (emoticon | link | color | mention | WORD | WHITESPACE)+ ;
name : WORD ;
command : (SAYS | SHOUTS) ':' WHITESPACE ;
emoticon : ':' '-'? ')'
| ':' '-'? '('
;
link : '[' TEXT ']' '(' TEXT ')' ;
color : '/' WORD '/' message '/';
mention : '@' WORD ; 第一个有趣的部分是message ,与其包含的内容有关,不如说是它所代表的结构。 我们说的是message可以是任何列出的规则中的任何顺序。 这是解决空白时无需每次重复的简单方法。 由于作为用户,我们发现空白不相关,因此我们看到类似WORD WORD mention ,但解析器实际上看到WORD WHITESPACE WORD WHITESPACE mention WHITESPACE 。
当您无法摆脱空白时,处理空白的另一种方法是更高级的:词法模式。 基本上,它允许您指定两个词法分析器部分:一个用于结构化部分,另一个用于简单文本。 这对于解析XML或HTML之类的内容很有用。 我们将在稍后展示。
很明显, 命令规则很明显,您只需要注意命令和冒号这两个选项之间不能有空格,但是之后需要一个WHITESPACE 。 表情符号规则显示了另一种表示多种选择的符号,您可以使用竖线字符“ |” 没有括号。 我们仅支持带有或不带有中间线的两个表情符号,快乐和悲伤。
就像我们已经说过的那样, 链接规则可能被认为是错误或执行不佳,实际上, TEXT捕获了除某些特殊字符之外的所有内容。 您可能只想在括号内使用WORD和WHITESPACE,或者在方括号内强制使用正确的链接格式。 另一方面,这允许用户在编写链接时犯错误,而不会使解析器抱怨。
您必须记住,解析器无法检查语义
例如,它不知道指示颜色的WORD是否实际代表有效颜色。 也就是说,它不知道使用“ dog”是错误的,但是使用“ red”是正确的。 必须通过程序的逻辑进行检查,该逻辑可以访问可用的颜色。 您必须找到在语法和您自己的代码之间划分执行力的正确平衡。
解析器应仅检查语法。 因此,经验法则是,如果有疑问,则让解析器将内容传递给程序。 然后,在程序中,检查语义并确保规则实际上具有正确的含义。
让我们看一下规则颜色:它可以包含一条消息 ,它本身也可以是消息的一部分; 这种歧义将通过使用的上下文来解决。
11.错误与调整
在尝试新语法之前,我们必须在文件开头添加一个名称。 名称必须与文件名相同,文件扩展名应为.g4 。
grammar Chat;您可以在官方文档中找到如何为您的平台安装所有内容 。 安装完所有内容后,我们创建语法,编译生成的Java代码,然后运行测试工具。
// lines preceded by $ are commands
// > are input to the tool
// - are output from the tool
$ antlr4 Chat.g4
$ javac Chat*.java
// grun is the testing tool, Chat is the name of the grammar, chat the rule that we want to parse
$ grun Chat chat
> john SAYS: hello @michael this will not work
// CTRL+D on Linux, CTRL+Z on Windows
> CTRL+D/CTRL+Z
- line 1:0 mismatched input 'john SAYS: hello @michael this will not work\n' expecting WORD 好的,它不起作用。 为什么要期待WORD ? 就在那! 让我们尝试使用选项-tokens它可以识别的令牌,以找出-tokens 。
$ grun Chat chat -tokens
> john SAYS: hello @michael this will not work
- [@0,0:44='john SAYS: hello @michael this will not work\n',,1:0]
- [@1,45:44='',,2:0] 因此,它只能看到TEXT令牌。 但是我们把它放在语法的末尾,会发生什么? 问题在于它总是尝试匹配最大可能的令牌。 所有这些文本都是有效的TEXT令牌。 我们如何解决这个问题? 有很多方法,第一种当然是摆脱该令牌。 但是目前,我们将看到第二个最简单的方法。
[..]
link : TEXT TEXT ;
[..]
TEXT : ('['|'(') ~[\])]+ (']'|')');我们更改了有问题的令牌,使其包含前面的括号或方括号。 请注意,这并不完全相同,因为它允许两个系列的括号或方括号。 但这是第一步,毕竟我们正在这里学习。
让我们检查一下是否可行:
$ grun Chat chat -tokens
> john SAYS: hello @michael this will not work
- [@0,0:3='john',,1:0]
- [@1,4:4=' ',,1:4]
- [@2,5:8='SAYS',,1:5]
- [@3,9:9=':',<':'>,1:9]
- [@4,10:10=' ',,1:10]
- [@5,11:15='hello',,1:11]
- [@6,16:16=' ',,1:16]
- [@7,17:17='@',<'@'>,1:17]
- [@8,18:24='michael',,1:18]
- [@9,25:25=' ',,1:25]
- [@10,26:29='this',,1:26]
- [@11,30:30=' ',,1:30]
- [@12,31:34='will',,1:31]
- [@13,35:35=' ',,1:35]
- [@14,36:38='not',,1:36]
- [@15,39:39=' ',,1:39]
- [@16,40:43='work',,1:40]
- [@17,44:44='\n',,1:44]
- [@18,45:44='',,2:0] 使用-gui选项,我们还可以拥有一个很好的,更易于理解的图形表示。
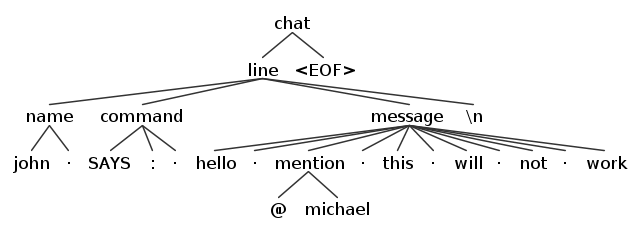
空中的点表示空白。
这行得通,但不是很聪明,不错或没有组织。 但是不用担心,稍后我们将看到更好的方法。 该解决方案的一个积极方面是,它可以显示另一个技巧。
TEXT : ('['|'(') .*? (']'|')');这是令牌TEXT的等效表示形式:“。” 匹配任何字符,“ *”表示可以随时重复前面的匹配,“?” 表示先前的比赛是非贪婪的。 也就是说,前一个子规则匹配除其后的所有内容,从而允许匹配右括号或方括号。
中级
在本节中,我们将了解如何在程序中使用ANTLR,需要使用的库和函数,如何测试解析器等。 我们了解什么是监听器以及如何使用监听器。 通过查看更高级的概念(例如语义谓词),我们还基于对基础知识的了解。 尽管我们的项目主要使用Javascript和Python,但该概念通常适用于每种语言。 当您需要记住如何组织项目时,可以回到本节。
12.使用Java脚本设置聊天项目
在前面的部分中,我们逐段地介绍了如何为聊天程序构建语法。 现在,让我们复制刚在Javascript文件的同一文件夹中创建的语法。
grammar Chat;
/*
* Parser Rules
*/
chat : line+ EOF ;
line : name command message NEWLINE ;
message : (emoticon | link | color | mention | WORD | WHITESPACE)+ ;
name : WORD WHITESPACE;
command : (SAYS | SHOUTS) ':' WHITESPACE ;
emoticon : ':' '-'? ')'
| ':' '-'? '('
;
link : TEXT TEXT ;
color : '/' WORD '/' message '/';
mention : '@' WORD ;
/*
* Lexer Rules
*/
fragment A : ('A'|'a') ;
fragment S : ('S'|'s') ;
fragment Y : ('Y'|'y') ;
fragment H : ('H'|'h') ;
fragment O : ('O'|'o') ;
fragment U : ('U'|'u') ;
fragment T : ('T'|'t') ;
fragment LOWERCASE : [a-z] ;
fragment UPPERCASE : [A-Z] ;
SAYS : S A Y S ;
SHOUTS : S H O U T S ;
WORD : (LOWERCASE | UPPERCASE | '_')+ ;
WHITESPACE : (' ' | '\t')+ ;
NEWLINE : ('\r'? '\n' | '\r')+ ;
TEXT : ('['|'(') ~[\])]+ (']'|')');通过使用ANTLR4 Java程序指定正确的选项,我们可以创建相应的Javascript解析器。
antlr4 -Dlanguage=JavaScript Chat.g4 现在,您将在文件夹中找到一些新文件,它们的名称如ChatLexer.js, ChatParser.js以及* .tokens文件,这些文件都不包含我们感兴趣的任何东西,除非您想了解ANTLR的内部工作原理。
您要查看的文件是ChatListener.js ,您不会对其进行任何修改,但是它包含我们将使用自己的侦听器覆盖的方法和函数。 我们不会对其进行修改,因为每次重新生成语法时,更改都会被覆盖。
查看它,您可以看到几个输入/退出函数,每个解析器规则都有一对。 当遇到与规则匹配的一段代码时,将调用这些函数。 这是侦听器的默认实现,它使您可以在派生的侦听器上仅覆盖所需的功能,而其余部分保持不变。
var antlr4 = require('antlr4/index');
// This class defines a complete listener for a parse tree produced by ChatParser.
function ChatListener() {
antlr4.tree.ParseTreeListener.call(this);
return this;
}
ChatListener.prototype = Object.create(antlr4.tree.ParseTreeListener.prototype);
ChatListener.prototype.constructor = ChatListener;
// Enter a parse tree produced by ChatParser#chat.
ChatListener.prototype.enterChat = function(ctx) {
};
// Exit a parse tree produced by ChatParser#chat.
ChatListener.prototype.exitChat = function(ctx) {
};
[..] 创建Listener的替代方法是创建一个Visitor 。 主要区别在于,您既无法控制侦听器的流程,也无法从其功能返回任何内容,而您既可以使用访问者来完成这两个操作。 因此,如果您需要控制AST节点的输入方式或从其中几个节点收集信息,则可能需要使用访客。 例如,这对于代码生成很有用,在代码生成中,创建新源代码所需的一些信息散布在许多部分。 听者和访客都使用深度优先搜索。
深度优先搜索意味着当一个节点将被访问时,其子节点将被访问,如果一个子节点具有自己的子节点,则在继续第一个节点的其他子节点之前,将对其进行访问。 下图将使您更容易理解该概念。

因此,对于侦听器,在与该节点的第一次相遇时将触发enter事件,并且在退出所有子节点之后将触发出口。 在下图中,您可以看到在侦听器遇到线路节点时将触发哪些功能的示例(为简单起见,仅显示与线路相关的功能)。

对于标准的访问者,其行为将是相似的,当然,对于每个单个节点都只会触发单个访问事件。 在下图中,您可以看到访问者遇到线路节点时将触发哪些功能的示例(为简单起见,仅显示与线路相关的功能)。
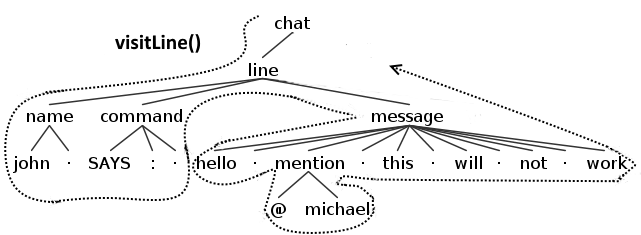
请记住, 这对于访问者的默认实现是正确的 , 这是通过返回每个函数中每个节点的子代来完成的 。 如果您忽略了访问者的方法,则有责任使访问者继续旅行或在此停留。
13. Antlr.js
终于到了看典型的ANTLR程序外观的时候了。
const http = require('http');
const antlr4 = require('antlr4/index');
const ChatLexer = require('./ChatLexer');
const ChatParser = require('./ChatParser');
const HtmlChatListener = require('./HtmlChatListener').HtmlChatListener;
http.createServer((req, res) => {
res.writeHead(200, {
'Content-Type': 'text/html',
});
res.write('');
var input = "john SHOUTS: hello @michael /pink/this will work/ :-) \n";
var chars = new antlr4.InputStream(input);
var lexer = new ChatLexer.ChatLexer(chars);
var tokens = new antlr4.CommonTokenStream(lexer);
var parser = new ChatParser.ChatParser(tokens);
parser.buildParseTrees = true;
var tree = parser.chat();
var htmlChat = new HtmlChatListener(res);
antlr4.tree.ParseTreeWalker.DEFAULT.walk(htmlChat, tree);
res.write('');
res.end();
}).listen(1337); 在主文件的开头,我们导入(使用require )必要的库和文件, antlr4 (运行时)和生成的解析器,以及稍后将要看到的侦听器。
为简单起见,我们从字符串中获取输入,而在实际情况下,它将来自编辑器。
第16-19行显示了每个ANTLR程序的基础:您从输入创建字符流,将其提供给词法分析器,然后将其转换为令牌,然后由解析器对其进行解释。
花一点时间思考一下是很有用的:词法分析器处理输入的字符,准确地说是输入的副本,而解析器处理解析器生成的标记。 词法分析器无法直接处理输入,解析器甚至看不到字符 。
记住这一点很重要,以防您需要执行一些高级操作(如操纵输入)。 在这种情况下,输入是字符串,但当然可以是任何内容流。
第20行是多余的,因为该选项已经默认为true,但是在以后的运行时版本中可能会更改,因此最好指定它。
然后,在第21行,将树的根节点设置为聊天规则。 您要调用解析器,指定一个通常是第一条规则的规则。 但是,实际上您可以直接调用任何规则,例如color 。
通常,一旦从解析器中获取AST,我们就想使用侦听器或访问者来处理它。 在这种情况下,我们指定一个侦听器。 我们特定的侦听器采用一个参数:响应对象。 我们希望使用它在响应中放入一些文本以发送给用户。 设置好听众之后,我们最终与听众一起走到树上。
14. HtmlChatListener.js
我们继续看聊天项目的听众。
const antlr4 = require('antlr4/index');
const ChatLexer = require('./ChatLexer');
const ChatParser = require('./ChatParser');
var ChatListener = require('./ChatListener').ChatListener;
HtmlChatListener = function(res) {
this.Res = res;
ChatListener.call(this); // inherit default listener
return this;
};
// inherit default listener
HtmlChatListener.prototype = Object.create(ChatListener.prototype);
HtmlChatListener.prototype.constructor = HtmlChatListener;
// override default listener behavior
HtmlChatListener.prototype.enterName = function(ctx) {
this.Res.write("");
};
HtmlChatListener.prototype.exitName = function(ctx) {
this.Res.write(ctx.WORD().getText());
this.Res.write(" ");
};
HtmlChatListener.prototype.exitEmoticon = function(ctx) {
var emoticon = ctx.getText();
if(emoticon == ':-)' || emoticon == ':)')
{
this.Res.write("??");
}
if(emoticon == ':-(' || emoticon == ':(')
{
this.Res.write("??");
}
};
HtmlChatListener.prototype.enterCommand = function(ctx) {
if(ctx.SAYS() != null)
this.Res.write(ctx.SAYS().getText() + ':' + '');
if(ctx.SHOUTS() != null)
this.Res.write(ctx.SHOUTS().getText() + ':' + '
');
};
HtmlChatListener.prototype.exitLine = function(ctx) {
this.Res.write("
");
};
exports.HtmlChatListener = HtmlChatListener;After the requires function calls we make our HtmlChatListener to extend ChatListener. The interesting stuff starts at line 17.
The ctx argument is an instance of a specific class context for the node that we are entering/exiting. So for enterName is NameContext , for exitEmoticon is EmoticonContext , etc. This specific context will have the proper elements for the rule, that would make possible to easily access the respective tokens and subrules. For example, NameContext will contain fields like WORD() and WHITESPACE(); CommandContext will contain fields like WHITESPACE() , SAYS() and SHOUTS().
These functions,
enter*andexit*,are called by the walker everytime the corresponding nodes are entered or exited while it's traversing the AST that represents the program newline. A listener allows you to execute some code, but it's important to remember that you can't stop the execution of the walker and the execution of the functions .
On line 18, we start by printing a strong tag because we want the name to be bold, then on exitName we take the text from the token WORD and close the tag. Note that we ignore the WHITESPACE token, nothing says that we have to show everything. In this case we could have done everything either on the enter or exit function.
On the function exitEmoticon we simply transform the emoticon text in an emoji character. We get the text of the whole rule because there are no tokens defined for this parser rule. On enterCommand , instead there could be any of two tokens SAYS or SHOUTS , so we check which one is defined. And then we alter the following text, by transforming in uppercase, if it's a SHOUT. Note that we close the p tag at the exit of the line rule, because the command, semantically speaking, alter all the text of the message.
All we have to do now is launching node, with nodejs antlr.js , and point our browser at its address, usually at http://localhost:1337/ and we will be greeted with the following image.

So all is good, we just have to add all the different listeners to handle the rest of the language. Let's start with color and message .
15. Working with a Listener
We have seen how to start defining a listener. Now let's get serious on see how to evolve in a complete, robust listener. Let's start by adding support for color and checking the results of our hard work.
HtmlChatListener.prototype.enterColor = function(ctx) {
var color = ctx.WORD().getText();
this.Res.write('');
};
HtmlChatListener.prototype.exitColor = function(ctx) {
this.Res.write("");
};
HtmlChatListener.prototype.exitMessage = function(ctx) {
this.Res.write(ctx.getText());
};
exports.HtmlChatListener = HtmlChatListener;
Except that it doesn't work. Or maybe it works too much: we are writing some part of message twice (“this will work”): first when we check the specific nodes, children of message , and then at the end.
Luckily with Javascript we can dynamically alter objects, so we can take advantage of this fact to change the *Context object themselves.
HtmlChatListener.prototype.exitColor = function(ctx) {
ctx.text += ctx.message().text;
ctx.text += '';
};
HtmlChatListener.prototype.exitEmoticon = function(ctx) {
var emoticon = ctx.getText();
if(emoticon == ':-)' || emoticon == ':)')
{
ctx.text = "??";
}
if(emoticon == ':-(' || emoticon == ':(')
{
ctx.text = "??";
}
};
HtmlChatListener.prototype.exitMessage = function(ctx) {
var text = '';
for (var index = 0; index < ctx.children.length; index++ ) {
if(ctx.children[index].text != null)
text += ctx.children[index].text;
else
text += ctx.children[index].getText();
}
if(ctx.parentCtx instanceof ChatParser.ChatParser.LineContext == false)
{
ctx.text = text;
}
else
{
this.Res.write(text);
this.Res.write("");
}
}; Only the modified parts are shown in the snippet above. We add a text field to every node that transforms its text, and then at the exit of every message we print the text if it's the primary message, the one that is directly child of the line rule. If it's a message, that is also a child of color, we add the text field to the node we are exiting and let color print it. We check this on line 30, where we look at the parent node to see if it's an instance of the object LineContext . This is also further evidence of how each ctx argument corresponds to the proper type.
Between lines 23 and 27 we can see another field of every node of the generated tree: children , which obviously it contains the children node. You can observe that if a field text exists we add it to the proper variable, otherwise we use the usual function to get the text of the node.
16. Solving Ambiguities with Semantic Predicates
So far we have seen how to build a parser for a chat language in Javascript. Let's continue working on this grammar but switch to python. Remember that all code is available in the repository . Before that, we have to solve an annoying problem: the TEXT token. The solution we have is terrible, and furthermore, if we tried to get the text of the token we would have to trim the edges, parentheses or square brackets. 所以,我们能做些什么?
We can use a particular feature of ANTLR called semantic predicates. As the name implies they are expressions that produce a boolean value. They selectively enable or disable the following rule and thus permit to solve ambiguities. Another reason that they could be used is to support different version of the same language, for instance a version with a new construct or an old without it.
Technically they are part of the larger group of actions , that allows to embed arbitrary code into the grammar. The downside is that the grammar is no more language independent , since the code in the action must be valid for the target language. For this reason, usually it's considered a good idea to only use semantic predicates, when they can't be avoided, and leave most of the code to the visitor/listener.
link : '[' TEXT ']' '(' TEXT ')';
TEXT : {self._input.LA(-1) == ord('[') or self._input.LA(-1) == ord('(')}? ~[\])]+ ; We restored link to its original formulation, but we added a semantic predicate to the TEXT token, written inside curly brackets and followed by a question mark. We use self._input.LA(-1) to check the character before the current one, if this character is a square bracket or the open parenthesis, we activate the TEXT token. It's important to repeat that this must be valid code in our target language, it's going to end up in the generated Lexer or Parser, in our case in ChatLexer.py.
This matters not just for the syntax itself, but also because different targets might have different fields or methods, for instance LA returns an int in python, so we have to convert the char to a int .
Let's look at the equivalent form in other languages.
// C#. Notice that is .La and not .LA
TEXT : {_input.La(-1) == '[' || _input.La(-1) == '('}? ~[\])]+ ;
// Java
TEXT : {_input.LA(-1) == '[' || _input.LA(-1) == '('}? ~[\])]+ ;
// Javascript
TEXT : {this._input.LA(-1) == '[' || this._input.LA(-1) == '('}? ~[\])]+ ; If you want to test for the preceding token, you can use the _input.LT(-1,) but you can only do that for parser rules. For example, if you want to enable the mention rule only if preceded by a WHITESPACE token.
// C#
mention: {_input.Lt(-1).Type == WHITESPACE}? '@' WORD ;
// Java
mention: {_input.LT(1).getType() == WHITESPACE}? '@' WORD ;
// Python
mention: {self._input.LT(-1).text == ' '}? '@' WORD ;
// Javascript
mention: {this._input.LT(1).text == ' '}? '@' WORD ;17. Continuing the Chat in Python
Before seeing the Python example, we must modify our grammar and put the TEXT token before the WORD one. Otherwise ANTLR might assign the incorrect token, in cases where the characters between parentheses or brackets are all valid for WORD , for instance if it where [this](link) .
Using ANTLR in python is not more difficult than with any other platform, you just need to pay attention to the version of Python, 2 or 3.
antlr4 -Dlanguage=Python3 Chat.g4 就是这样。 So when you have run the command, inside the directory of your python project, there will be a newly generated parser and a lexer. You may find interesting to look at ChatLexer.py and in particular the function TEXT_sempred (sempred stands for sem antic pred icate).
def TEXT_sempred(self, localctx:RuleContext, predIndex:int):
if predIndex == 0:
return self._input.LA(-1) == ord('[') or self._input.LA(-1) == ord('(')You can see our predicate right in the code. This also means that you have to check that the correct libraries, for the functions used in the predicate, are available to the lexer.
18. The Python Way of Working with a Listener
The main file of a Python project is very similar to a Javascript one, mutatis mutandis of course. That is to say we have to adapt libraries and functions to the proper version for a different language.
import sys
from antlr4 import *
from ChatLexer import ChatLexer
from ChatParser import ChatParser
from HtmlChatListener import HtmlChatListener
def main(argv):
input = FileStream(argv[1])
lexer = ChatLexer(input)
stream = CommonTokenStream(lexer)
parser = ChatParser(stream)
tree = parser.chat()
output = open("output.html","w")
htmlChat = HtmlChatListener(output)
walker = ParseTreeWalker()
walker.walk(htmlChat, tree)
output.close()
if __name__ == '__main__':
main(sys.argv)We have also changed the input and output to become files, this avoid the need to launch a server in Python or the problem of using characters that are not supported in the terminal.
import sys
from antlr4 import *
from ChatParser import ChatParser
from ChatListener import ChatListener
class HtmlChatListener(ChatListener) :
def __init__(self, output):
self.output = output
self.output.write('')
def enterName(self, ctx:ChatParser.NameContext) :
self.output.write("")
def exitName(self, ctx:ChatParser.NameContext) :
self.output.write(ctx.WORD().getText())
self.output.write(" ")
def enterColor(self, ctx:ChatParser.ColorContext) :
color = ctx.WORD().getText()
ctx.text = ''
def exitColor(self, ctx:ChatParser.ColorContext):
ctx.text += ctx.message().text
ctx.text += ''
def exitEmoticon(self, ctx:ChatParser.EmoticonContext) :
emoticon = ctx.getText()
if emoticon == ':-)' or emoticon == ':)' :
ctx.text = "??"
if emoticon == ':-(' or emoticon == ':(' :
ctx.text = "??"
def enterLink(self, ctx:ChatParser.LinkContext):
ctx.text = '%s' % (ctx.TEXT()[1], (ctx.TEXT()[0]))
def exitMessage(self, ctx:ChatParser.MessageContext):
text = ''
for child in ctx.children:
if hasattr(child, 'text'):
text += child.text
else:
text += child.getText()
if isinstance(ctx.parentCtx, ChatParser.LineContext) is False:
ctx.text = text
else:
self.output.write(text)
self.output.write("")
def enterCommand(self, ctx:ChatParser.CommandContext):
if ctx.SAYS() is not None :
self.output.write(ctx.SAYS().getText() + ':' + '')
if ctx.SHOUTS() is not None :
self.output.write(ctx.SHOUTS().getText() + ':' + '
')
def exitChat(self, ctx:ChatParser.ChatContext):
self.output.write("")
Apart from lines 35-36, where we introduce support for links, there is nothing new. Though you might notice that Python syntax is cleaner and, while having dynamic typing, it is not loosely typed as Javascript. The different types of *Context objects are explicitly written out. If only Python tools were as easy to use as the language itself. But of course we cannot just fly over python like this, so we also introduce testing.
19. Testing with Python
While Visual Studio Code have a very nice extension for Python, that also supports unit testing, we are going to use the command line for the sake of compatibility.
python3 -m unittest discover -s . -p ChatTests.py That's how you run the tests, but before that we have to write them. Actually, even before that, we have to write an ErrorListener to manage errors that we could find. While we could simply read the text outputted by the default error listener, there is an advantage in using our own implementation, namely that we can control more easily what happens.
import sys
from antlr4 import *
from ChatParser import ChatParser
from ChatListener import ChatListener
from antlr4.error.ErrorListener import *
import io
class ChatErrorListener(ErrorListener):
def __init__(self, output):
self.output = output
self._symbol = ''
def syntaxError(self, recognizer, offendingSymbol, line, column, msg, e):
self.output.write(msg)
self._symbol = offendingSymbol.text
@property
def symbol(self):
return self._symbol Our class derives from ErrorListener and we simply have to implement syntaxError . Although we also add a property symbol to easily check which symbol might have caused an error.
from antlr4 import *
from ChatLexer import ChatLexer
from ChatParser import ChatParser
from HtmlChatListener import HtmlChatListener
from ChatErrorListener import ChatErrorListener
import unittest
import io
class TestChatParser(unittest.TestCase):
def setup(self, text):
lexer = ChatLexer(InputStream(text))
stream = CommonTokenStream(lexer)
parser = ChatParser(stream)
self.output = io.StringIO()
self.error = io.StringIO()
parser.removeErrorListeners()
errorListener = ChatErrorListener(self.error)
parser.addErrorListener(errorListener)
self.errorListener = errorListener
return parser
def test_valid_name(self):
parser = self.setup("John ")
tree = parser.name()
htmlChat = HtmlChatListener(self.output)
walker = ParseTreeWalker()
walker.walk(htmlChat, tree)
# let's check that there aren't any symbols in errorListener
self.assertEqual(len(self.errorListener.symbol), 0)
def test_invalid_name(self):
parser = self.setup("Joh-")
tree = parser.name()
htmlChat = HtmlChatListener(self.output)
walker = ParseTreeWalker()
walker.walk(htmlChat, tree)
# let's check the symbol in errorListener
self.assertEqual(self.errorListener.symbol, '-')
if __name__ == '__main__':
unittest.main() The setup method is used to ensure that everything is properly set; on lines 19-21 we setup also our ChatErrorListener , but first we remove the default one, otherwise it would still output errors on the standard output. We are listening to errors in the parser, but we could also catch errors generated by the lexer. It depends on what you want to test. You may want to check both.
The two proper test methods checks for a valid and an invalid name. The checks are linked to the property symbol , that we have previously defined, if it's empty everything is fine, otherwise it contains the symbol that created the error. Notice that on line 28, there is a space at the end of the string, because we have defined the rule name to end with a WHITESPACE token.
20. Parsing Markup
ANTLR can parse many things, including binary data, in that case tokens are made up of non printable characters. But a more common problem is parsing markup languages such as XML or HTML. Markup is also a useful format to adopt for your own creations, because it allows to mix unstructured text content with structured annotations. They fundamentally represent a form of smart document, containing both text and structured data. The technical term that describe them is island languages . This type is not restricted to include only markup, and sometimes it's a matter of perspective.
For example, you may have to build a parser that ignores preprocessor directives. In that case, you have to find a way to distinguish proper code from directives, which obeys different rules.
In any case, the problem for parsing such languages is that there is a lot of text that we don't actually have to parse, but we cannot ignore or discard, because the text contain useful information for the user and it is a structural part of the document. The solution is lexical modes , a way to parse structured content inside a larger sea of free text.
21. Lexical Modes
We are going to see how to use lexical modes, by starting with a new grammar.
lexer grammar MarkupLexer;
OPEN : '[' -> pushMode(BBCODE) ;
TEXT : ~('[')+ ;
// Parsing content inside tags
mode BBCODE;
CLOSE : ']' -> popMode ;
SLASH : '/' ;
EQUALS : '=' ;
STRING : '"' .*? '"' ;
ID : LETTERS+ ;
WS : [ \t\r\n] -> skip ;
fragment LETTERS : [a-zA-Z] ; Looking at the first line you could notice a difference: we are defining a lexer grammar , instead of the usual (combined) grammar . You simply can't define a lexical mode together with a parser grammar . You can use lexical modes only in a lexer grammar, not in a combined grammar. The rest is not suprising, as you can see, we are defining a sort of BBCode markup, with tags delimited by square brackets.
On lines 3, 7 and 9 you will find basically all that you need to know about lexical modes. You define one or more tokens that can delimit the different modes and activate them.
The default mode is already implicitly defined, if you need to define yours you simply use mode followed by a name. Other than for markup languages, lexical modes are typically used to deal with string interpolation. When a string literal can contain more than simple text, but things like arbitrary expressions.
When we used a combined grammar we could define tokens implicitly: when in a parser rule we used a string like '=' that is what we did. Now that we are using separate lexer and parser grammars we cannot do that. That means that every single token has to be defined explicitly. So we have definitions like SLASH or EQUALS which typically could be just be directly used in a parser rule. The concept is simple: in the lexer grammar we need to define all tokens, because they cannot be defined later in the parser grammar.
22. Parser Grammars
We look at the other side of a lexer grammar, so to speak.
parser grammar MarkupParser;
options { tokenVocab=MarkupLexer; }
file : element* ;
attribute : ID '=' STRING ;
content : TEXT ;
element : (content | tag) ;
tag : '[' ID attribute? ']' element* '[' '/' ID ']' ; On the first line we define a parser grammar . Since the tokens we need are defined in the lexer grammar, we need to use an option to say to ANTLR where it can find them. This is not necessary in combined grammars, since the tokens are defined in the same file.
There are many other options available, in the documentation .
There is almost nothing else to add, except that we define a content rule so that we can manage more easily the text that we find later in the program.
I just want to say that, as you can see, we don't need to explicitly use the tokens everytime (es. SLASH), but instead we can use the corresponding text (es. '/').
ANTLR will automatically transform the text in the corresponding token, but this can happen only if they are already defined. In short, it is as if we had written:
tag : OPEN ID attribute? CLOSE element* OPEN SLASH ID CLOSE ;But we could not have used the implicit way, if we hadn't already explicitly defined them in the lexer grammar. Another way to look at this is: when we define a combined grammar ANTLR defines for use all the tokens, that we have not explicitly defined ourselves. When we need to use a separate lexer and a parser grammar, we have to define explicitly every token ourselves. Once we have done that, we can use them in every way we want.
Before moving to actual Java code, let's see the AST for a sample input.
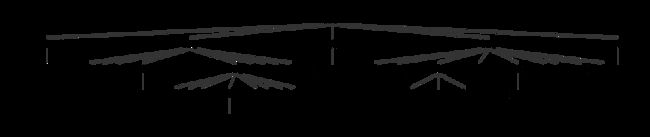
You can easily notice that the element rule is sort of transparent: where you would expect to find it there is always going to be a tag or content . So why did we define it? There are two advantages: avoid repetition in our grammar and simplify managing the results of the parsing. We avoid repetition because if we did not have the element rule we should repeat (content|tag) everywhere it is used. What if one day we add a new type of element? In addition to that it simplify the processing of the AST because it makes both the node represent tag and content extend a comment ancestor.
高级
In this section we deepen our understanding of ANTLR. We will look at more complex examples and situations we may have to handle in our parsing adventures. We will learn how to perform more adavanced testing, to catch more bugs and ensure a better quality for our code. We will see what a visitor is and how to use it. Finally, we will see how to deal with expressions and the complexity they bring.
You can come back to this section when you need to deal with complex parsing problems.
23. The Markup Project in Java
You can follow the instructions in Java Setup or just copy the antlr-java folder of the companion repository. Once the file pom.xml is properly configured, this is how you build and execute the application.
// use mwn to generate the package
mvn package
// every time you need to execute the application
java -cp target/markup-example-1.0-jar-with-dependencies.jar me.tomassetti.examples.MarkupParser.AppAs you can see, it isn't any different from any typical Maven project, although it's indeed more complicated that a typical Javascript or Python project. Of course, if you use an IDE you don't need to do anything different from your typical workflow.
24. The Main App.java
We are going to see how to write a typical ANTLR application in Java.
package me.tomassetti.examples.MarkupParser;
import org.antlr.v4.runtime.*;
import org.antlr.v4.runtime.tree.*;
public class App
{
public static void main( String[] args )
{
ANTLRInputStream inputStream = new ANTLRInputStream(
"I would like to [b][i]emphasize[/i][/b] this and [u]underline [b]that[/b][/u] ." +
"Let's not forget to quote: [quote author=\"John\"]You're wrong![/quote]");
MarkupLexer markupLexer = new MarkupLexer(inputStream);
CommonTokenStream commonTokenStream = new CommonTokenStream(markupLexer);
MarkupParser markupParser = new MarkupParser(commonTokenStream);
MarkupParser.FileContext fileContext = markupParser.file();
MarkupVisitor visitor = new MarkupVisitor();
visitor.visit(fileContext);
}
}At this point the main java file should not come as a surprise, the only new development is the visitor. Of course, there are the obvious little differences in the names of the ANTLR classes and such. This time we are building a visitor, whose main advantage is the chance to control the flow of the program. While we are still dealing with text, we don't want to display it, we want to transform it from pseudo-BBCode to pseudo-Markdown.
25. Transforming Code with ANTLR
The first issue to deal with our translation from pseudo-BBCode to pseudo-Markdown is a design decision. Our two languages are different and frankly neither of the two original one is that well designed.
BBCode was created as a safety precaution, to make possible to disallow the use of HTML but giove some of its power to users. Markdown was created to be an easy to read and write format, that could be translated into HTML. So they both mimic HTML, and you can actually use HTML in a Markdown document. Let's start to look into how messy would be a real conversion.
package me.tomassetti.examples.MarkupParser;
import org.antlr.v4.runtime.*;
import org.antlr.v4.runtime.misc.*;
import org.antlr.v4.runtime.tree.*;
public class MarkupVisitor extends MarkupParserBaseVisitor
{
@Override
public String visitFile(MarkupParser.FileContext context)
{
visitChildren(context);
System.out.println("");
return null;
}
@Override
public String visitContent(MarkupParser.ContentContext context)
{
System.out.print(context.TEXT().getText());
return visitChildren(context);
}
}The first version of our visitor prints all the text and ignore all the tags.
You can see how to control the flow, either by calling visitChildren , or any other visit* function, and deciding what to return. We just need to override the methods that we want to change. Otherwise, the default implementation would just do like visitContent , on line 23, it will visit the children nodes and allows the visitor to continue. Just like for a listener, the argument is the proper context type. If you want to stop the visitor just return null as on line 15.
26. Joy and Pain of Transforming Code
Transforming code, even at a very simple level, comes with some complications. Let's start easy with some basic visitor methods.
@Override
public String visitContent(MarkupParser.ContentContext context)
{
return context.getText();
}
@Override
public String visitElement(MarkupParser.ElementContext context)
{
if(context.parent instanceof MarkupParser.FileContext)
{
if(context.content() != null)
System.out.print(visitContent(context.content()));
if(context.tag() != null)
System.out.print(visitTag(context.tag()));
}
return null;
} Before looking at the main method, let's look at the supporting ones. Foremost we have changed visitContent by making it return its text instead of printing it. Second, we have overridden the visitElement so that it prints the text of its child, but only if it's a top element, and not inside a tag . In both cases, it achieve this by calling the proper visit* method. It knows which one to call because it checks if it actually has a tag or content node.
@Override
public String visitTag(MarkupParser.TagContext context)
{
String text = "";
String startDelimiter = "", endDelimiter = "";
String id = context.ID(0).getText();
switch(id)
{
case "b":
startDelimiter = endDelimiter = "**";
break;
case "u":
startDelimiter = endDelimiter = "*";
break;
case "quote":
String attribute = context.attribute().STRING().getText();
attribute = attribute.substring(1,attribute.length()-1);
startDelimiter = System.lineSeparator() + "> ";
endDelimiter = System.lineSeparator() + "> " + System.lineSeparator() + "> – "
+ attribute + System.lineSeparator();
break;
}
text += startDelimiter;
for (MarkupParser.ElementContext node: context.element())
{
if(node.tag() != null)
text += visitTag(node.tag());
if(node.content() != null)
text += visitContent(node.content());
}
text += endDelimiter;
return text;
} VisitTag contains more code than every other method, because it can also contain other elements, including other tags that have to be managed themselves, and thus they cannot be simply printed. We save the content of the ID on line 5, of course we don't need to check that the corresponding end tag matches, because the parser will ensure that, as long as the input is well formed.
The first complication starts with at lines 14-15: as it often happens when transforming a language in a different one, there isn't a perfect correspondence between the two. While BBCode tries to be a smarter and safer replacement for HTML, Markdown want to accomplish the same objective of HTML, to create a structured document. So BBCode has an underline tag, while Markdown does not.
So we have to make a decision
Do we want to discard the information, or directly print HTML, or something else? We choose something else and instead convert the underline to an italic. That might seem completely arbitrary, and indeed there is an element of choice in this decision. But the conversion forces us to lose some information, and both are used for emphasis, so we choose the closer thing in the new language.
The following case, on lines 18-22, force us to make another choice. We can't maintain the information about the author of the quote in a structured way, so we choose to print the information in a way that will make sense to a human reader.
On lines 28-34 we do our “magic”: we visit the children and gather their text, then we close with the endDelimiter . Finally we return the text that we have created.
That's how the visitor works
- every top element visit each child
- if it's a content node, it directly returns the text
- if it's a tag , it setups the correct delimiters and then it checks its children. It repeats step 2 for each children and then it returns the gathered text
- it prints the returned text
It's obviously a simple example, but it show how you can have great freedom in managing the visitor once you have launched it. Together with the patterns that we have seen at the beginning of this section you can see all of the options: to return null to stop the visit, to return children to continue, to return something to perform an action ordered at an higher level of the tree.
27. Advanced Testing
The use of lexical modes permit to handle the parsing of island languages, but it complicates testing.
We are not going to show MarkupErrorListener.java because w edid not changed it; if you need you can see it on the repository.
You can run the tests by using the following command.
mvn testNow we are going to look at the tests code. We are skipping the setup part, because that also is obvious, we just copy the process seen on the main file, but we simply add our error listener to intercept the errors.
// private variables inside the class AppTest
private MarkupErrorListener errorListener;
private MarkupLexer markupLexer;
public void testText()
{
MarkupParser parser = setup("anything in here");
MarkupParser.ContentContext context = parser.content();
assertEquals("",this.errorListener.getSymbol());
}
public void testInvalidText()
{
MarkupParser parser = setup("[anything in here");
MarkupParser.ContentContext context = parser.content();
assertEquals("[",this.errorListener.getSymbol());
}
public void testWrongMode()
{
MarkupParser parser = setup("author=\"john\"");
MarkupParser.AttributeContext context = parser.attribute();
TokenStream ts = parser.getTokenStream();
assertEquals(MarkupLexer.DEFAULT_MODE, markupLexer._mode);
assertEquals(MarkupLexer.TEXT,ts.get(0).getType());
assertEquals("author=\"john\"",this.errorListener.getSymbol());
}
public void testAttribute()
{
MarkupParser parser = setup("author=\"john\"");
// we have to manually push the correct mode
this.markupLexer.pushMode(MarkupLexer.BBCODE);
MarkupParser.AttributeContext context = parser.attribute();
TokenStream ts = parser.getTokenStream();
assertEquals(MarkupLexer.ID,ts.get(0).getType());
assertEquals(MarkupLexer.EQUALS,ts.get(1).getType());
assertEquals(MarkupLexer.STRING,ts.get(2).getType());
assertEquals("",this.errorListener.getSymbol());
}
public void testInvalidAttribute()
{
MarkupParser parser = setup("author=/\"john\"");
// we have to manually push the correct mode
this.markupLexer.pushMode(MarkupLexer.BBCODE);
MarkupParser.AttributeContext context = parser.attribute();
assertEquals("/",this.errorListener.getSymbol());
}The first two methods are exactly as before, we simply check that there are no errors, or that there is the correct one because the input itself is erroneous. On lines 30-32 things start to get interesting: the issue is that by testing the rules one by one we don't give the chance to the parser to switch automatically to the correct mode. So it remains always on the DEFAULT_MODE, which in our case makes everything looks like TEXT . This obviously makes the correct parsing of an attribute impossible.
The same lines shows also how you can check the current mode that you are in, and the exact type of the tokens that are found by the parser, which we use to confirm that indeed all is wrong in this case.
While we could use a string of text to trigger the correct mode, each time, that would make testing intertwined with several pieces of code, which is a no-no. So the solution is seen on line 39: we trigger the correct mode manually. Once you have done that, you can see that our attribute is recognized correctly.
28. Dealing with Expressions
So far we have written simple parser rules, now we are going to see one of the most challenging parts in analyzing a real (programming) language: expressions. While rules for statements are usually larger they are quite simple to deal with: you just need to write a rule that encapsulate the structure with the all the different optional parts. For instance a for statement can include all other kind of statements, but we can simply include them with something like statement*. An expression, instead, can be combined in many different ways.
An expression usually contains other expressions. For example the typical binary expression is composed by an expression on the left, an operator in the middle and another expression on the right. This can lead to ambiguities. Think, for example, at the expression 5 + 3 * 2 , for ANTLR this expression is ambiguous because there are two ways to parse it. It could either parse it as 5 + (3 * 2) or (5 +3) * 2.
Until this moment we have avoided the problem simply because markup constructs surround the object on which they are applied. So there is not ambiguity in choosing which one to apply first: it's the most external. Imagine if this expression was written as:
5
3
2
That would make obvious to ANTLR how to parse it.
These types of rules are called left-recursive rules. You might say: just parse whatever comes first. The problem with that is semantic: the addition comes first, but we know that multiplications have a precedence over additions. Traditionally the way to solve this problem was to create a complex cascade of specific expressions like this:
expression : addition;
addition : multiplication ('+' multiplication)* ;
multiplication : atom ('*' atom)* ;
atom : NUMBER ;This way ANTLR would have known to search first for a number, then for multiplications and finally for additions. This is cumbersome and also counterintuitive, because the last expression is the first to be actually recognized. Luckily ANTLR4 can create a similar structure automatically, so we can use a much more natural syntax .
expression : expression '*' expression
| expression '+' expression
| NUMBER
;In practice ANTLR consider the order in which we defined the alternatives to decide the precedence. By writing the rule in this way we are telling to ANTLR that the multiplication has precedence on the addition.
29. Parsing Spreadsheets
Now we are prepared to create our last application, in C#. We are going to build the parser of an Excel-like application. In practice, we want to manage the expressions you write in the cells of a spreadsheet.
grammar Spreadsheet;
expression : '(' expression ')' #parenthesisExp
| expression (ASTERISK|SLASH) expression #mulDivExp
| expression (PLUS|MINUS) expression #addSubExp
| expression '^' expression #powerExp
| NAME '(' expression ')' #functionExp
| NUMBER #numericAtomExp
| ID #idAtomExp
;
fragment LETTER : [a-zA-Z] ;
fragment DIGIT : [0-9] ;
ASTERISK : '*' ;
SLASH : '/' ;
PLUS : '+' ;
MINUS : '-' ;
ID : LETTER DIGIT ;
NAME : LETTER+ ;
NUMBER : DIGIT+ ('.' DIGIT+)? ;
WHITESPACE : ' ' -> skip; With all the knowledge you have acquired so far everything should be clear, except for possibly three things:
- why the parentheses are there,
- what's the stuff on the right,
- that thing on line 6.
The parentheses comes first because its only role is to give the user a way to override the precedence of operator, if it needs to do so. This graphical representation of the AST should make it clear.

The things on the right are labels , they are used to make ANTLR generate specific functions for the visitor or listener. So there will be a VisitFunctionExp , a VisitPowerExp , etc. This makes possible to avoid the use of a giant visitor for the expression rule.
The expression relative to exponentiation is different because there are two possible ways to act, to group them, when you meet two sequential expressions of the same type. The first one is to execute the one on the left first and then the one on the right, the second one is the inverse: this is called associativity . Usually the one that you want to use is left-associativity, which is the default option. Nonetheless exponentiation is right-associative , so we have to signal this to ANTLR.
Another way to look at this is: if there are two expressions of the same type, which one has the precedence: the left one or the right one? Again, an image is worth a thousand words.

We have also support for functions, alphanumeric variables that represents cells and real numbers.
30. The Spreadsheet Project in C#
You just need to follow the C# Setup : to install a nuget package for the runtime and an ANTLR4 extension for Visual Studio. The extension will automatically generate everything whenever you build your project: parser, listener and/or visitor.
After you have done that, you can also add grammar files just by using the usual menu Add -> New Item. Do exactly that to create a grammar called Spreadsheet.g4 and put in it the grammar we have just created. Now let's see the main Program.cs .
using System;
using Antlr4.Runtime;
namespace AntlrTutorial
{
class Program
{
static void Main(string[] args)
{
string input = "log(10 + A1 * 35 + (5.4 - 7.4))";
AntlrInputStream inputStream = new AntlrInputStream(input);
SpreadsheetLexer spreadsheetLexer = new SpreadsheetLexer(inputStream);
CommonTokenStream commonTokenStream = new CommonTokenStream(spreadsheetLexer);
SpreadsheetParser spreadsheetParser = new SpreadsheetParser(commonTokenStream);
SpreadsheetParser.ExpressionContext expressionContext = spreadsheetParser.expression();
SpreadsheetVisitor visitor = new SpreadsheetVisitor();
Console.WriteLine(visitor.Visit(expressionContext));
}
}
} There is nothing to say, apart from that, of course, you have to pay attention to yet another slight variation in the naming of things: pay attention to the casing. For instance, AntlrInputStream , in the C# program, was ANTLRInputStream in the Java program.
Also you can notice that, this time, we output on the screen the result of our visitor, instead of writing the result on a file.
31. Excel is Doomed
We are going to take a look at our visitor for the Spreadsheet project.
public class SpreadsheetVisitor : SpreadsheetBaseVisitor
{
private static DataRepository data = new DataRepository();
public override double VisitNumericAtomExp(SpreadsheetParser.NumericAtomExpContext context)
{
return double.Parse(context.NUMBER().GetText(), System.Globalization.CultureInfo.InvariantCulture);
}
public override double VisitIdAtomExp(SpreadsheetParser.IdAtomExpContext context)
{
String id = context.ID().GetText();
return data[id];
}
public override double VisitParenthesisExp(SpreadsheetParser.ParenthesisExpContext context)
{
return Visit(context.expression());
}
public override double VisitMulDivExp(SpreadsheetParser.MulDivExpContext context)
{
double left = Visit(context.expression(0));
double right = Visit(context.expression(1));
double result = 0;
if (context.ASTERISK() != null)
result = left * right;
if (context.SLASH() != null)
result = left / right;
return result;
}
[..]
public override double VisitFunctionExp(SpreadsheetParser.FunctionExpContext context)
{
String name = context.NAME().GetText();
double result = 0;
switch(name)
{
case "sqrt":
result = Math.Sqrt(Visit(context.expression()));
break;
case "log":
result = Math.Log10(Visit(context.expression()));
break;
}
return result;
}
} VisitNumeric and VisitIdAtom return the actual numbers that are represented either by the literal number or the variable. In a real scenario DataRepository would contain methods to access the data in the proper cell, but in our example is just a Dictionary with some keys and numbers. The other methods actually work in the same way: they visit/call the containing expression(s). The only difference is what they do with the results.
Some perform an operation on the result, the binary operations combine two results in the proper way and finally VisitParenthesisExp just reports the result higher on the chain. Math is simple, when it's done by a computer.
32. Testing Everything
Up until now we have only tested the parser rules, that is to say we have tested only if we have created the correct rule to parse our input. Now we are also going to test the visitor functions. This is the ideal chance because our visitor return values that we can check individually. In other occasions, for instance if your visitor prints something to the screen, you may want to rewrite the visitor to write on a stream. Then, at testing time, you can easily capture the output.
We are not going to show SpreadsheetErrorListener.cs because it's the same as the previous one we have already seen; if you need it you can see it on the repository.
To perform unit testing on Visual Studio you need to create a specific project inside the solution. You can choose different formats, we opt for the xUnit version. To run them there is an aptly named section “TEST” on the menu bar.
[Fact]
public void testExpressionPow()
{
setup("5^3^2");
PowerExpContext context = parser.expression() as PowerExpContext;
CommonTokenStream ts = (CommonTokenStream)parser.InputStream;
Assert.Equal(SpreadsheetLexer.NUMBER, ts.Get(0).Type);
Assert.Equal(SpreadsheetLexer.T__2, ts.Get(1).Type);
Assert.Equal(SpreadsheetLexer.NUMBER, ts.Get(2).Type);
Assert.Equal(SpreadsheetLexer.T__2, ts.Get(3).Type);
Assert.Equal(SpreadsheetLexer.NUMBER, ts.Get(4).Type);
}
[Fact]
public void testVisitPowerExp()
{
setup("4^3^2");
PowerExpContext context = parser.expression() as PowerExpContext;
SpreadsheetVisitor visitor = new SpreadsheetVisitor();
double result = visitor.VisitPowerExp(context);
Assert.Equal(double.Parse("262144"), result);
}
[..]
[Fact]
public void testWrongVisitFunctionExp()
{
setup("logga(100)");
FunctionExpContext context = parser.expression() as FunctionExpContext;
SpreadsheetVisitor visitor = new SpreadsheetVisitor();
double result = visitor.VisitFunctionExp(context);
CommonTokenStream ts = (CommonTokenStream)parser.InputStream;
Assert.Equal(SpreadsheetLexer.NAME, ts.Get(0).Type);
Assert.Equal(null, errorListener.Symbol);
Assert.Equal(0, result);
}
[Fact]
public void testCompleteExp()
{
setup("log(5+6*7/8)");
ExpressionContext context = parser.expression();
SpreadsheetVisitor visitor = new SpreadsheetVisitor();
double result = visitor.Visit(context);
Assert.Equal("1.01072386539177", result.ToString(System.Globalization.CultureInfo.GetCultureInfo("en-US").NumberFormat));
}The first test function is similar to the ones we have already seen; it checks that the corrects tokens are selected. On line 11 and 13 you may be surprised to see that weird token type, this happens because we didn't explicitly created one for the '^' symbol so one got automatically created for us. If you need you can see all the tokens by looking at the *.tokens file generated by ANTLR.
On line 25 we visit our test node and get the results, that we check on line 27. It's all very simple because our visitor is simple, while unit testing should always be easy and made up of small parts it really can't be easier than this.
The only thing to pay attention to it's related to the format of the number, it's not a problem here, but look at line 59, where we test the result of a whole expression. There we need to make sure that the correct format is selected, because different countries use different symbols as the decimal mark.
There are some things that depends on the cultural context
If your computer was already set to the American English Culture this wouldn't be necessary, but to guarantee the correct testing results for everybody we have to specify it. Keep that in mind if you are testing things that are culture-dependent: such as grouping of digits, temperatures, etc.
On line 44-46 you see than when we check for the wrong function the parser actually works. That's because indeed “logga” is syntactically valid as a function name, but it's not semantically correct. The function “logga” doesn't exists, so our program doesn't know what to do with it. So when we visit it we get 0 as a result. As you recall this was our choice: since we initialize the result to 0 and we don't have a default case in VisitFunctionExp. So if there no function the result remains 0. A possib alternative could be to throw an exception.
Final Remarks
In this section we see tips and tricks that never came up in our example, but can be useful in your programs. We suggest more resources you may find useful if you want to know more about ANTLR, both the practice and the theory, or you need to deal with the most complex problems.
33. Tips and Tricks
Let's see a few tricks that could be useful from time to time. These were never needed in our examples, but they have been quite useful in other scenarios.
Catchall Rule
The first one is the ANY lexer rule. This is simply a rule in the following format.
ANY : . ;This is a catchall rule that should be put at the end of your grammar. It matches any character that didn't find its place during the parsing. So creating this rule can help you during development, when your grammar has still many holes that could cause distracting error messages. It's even useful during production, when it acts as a canary in the mines. If it shows up in your program you know that something is wrong.
频道
There is also something that we haven't talked about: channels . Their use case is usually handling comments. You don't really want to check for comments inside every of your statements or expressions, so you usually throw them way with -> skip . But there are some cases where you may want to preserve them, for instance if you are translating a program in another language. When this happens you use channels . There is already one called HIDDEN that you can use, but you can declare more of them at the top of your lexer grammar.
channels { UNIQUENAME }
// and you use them this way
COMMENTS : '//' ~[\r\n]+ -> channel(UNIQUENAME) ;Rule Element Labels
There is another use of labels other than to distinguish among different cases of the same rule. They can be used to give a specific name, usually but not always of semantic value, to a common rule or parts of a rule. The format is label=rule , to be used inside another rule.
expression : left=expression (ASTERISK|SLASH) right=expression ; This way left and right would become fields in the ExpressionContext nodes. And instead of using context.expression(0) , you could refer to the same entity using context.left .
Problematic Tokens
In many real languages some symbols are reused in different ways, some of which may lead to ambiguities. A common problematic example are the angle brackets, used both for bitshift expression and to delimit parameterized types.
// bitshift expression, it assigns to x the value of y shifted by three bits
x = y >> 3;
// parameterized types, it define x as a list of dictionaries
List> x; The natural way of defining the bitshift operator token is as a single double angle brackets, '>>'. But this might lead to confusing a nested parameterized definition with the bitshift operator, for instance in the second example shown up here. While a simple way of solving the problem would be using semantic predicates, an excessive number of them would slow down the parsing phase. The solution is to avoid defining the bitshift operator token and instead using the angle brackets twice in the parser rule, so that the parser itself can choose the best candidate for every occasion.
// from this
RIGHT_SHIFT : '>>';
expression : ID RIGHT_SHIFT NUMBER;
// to this
expression : ID SHIFT SHIFT NUMBER;34. Conclusions
We have learned a lot today:
- what are a lexer and a parser
- how to create lexer and parser rules
- how to use ANTLR to generate parsers in Java, C#, Python and JavaScript
- the fundamental kinds of problems you will encounter parsing and how to solve them
- how to understand errors
- how to test your parsers
That's all you need to know to use ANTLR on your own. And I mean literally, you may want to know more, but now you have solid basis to explore on your own.
Where to look if you need more information about ANTLR:
- On this very website there is whole category dedicated to ANTLR .
- The official ANTLR website is a good starting point to know the general status of the project, the specialized development tools and related project, like StringTemplate
- The ANTLR documentation on GitHub ; especially useful are the information on targets and how to setup it on different languages .
- The ANTLR 4.6 API ; it's related to the Java version, so there might be some differences in other languages, but it's the best place where to settle your doubts about the inner workings of this tool.
- For the very interested in the science behind ANTLR4, there is an academic paper: Adaptive LL(*) Parsing: The Power of Dynamic Analysis
- The Definitive ANTLR 4 Reference , by the man itself, Terence Parr , the creator of ANTLR. The resource you need if you want to know everything about ANTLR and a good deal about parsing languages in general.
Also the book it's only place where you can find and answer to question like these:
ANTLR v4 is the result of a minor detour (twenty-five years) I took in graduate
学校。 I guess I'm going to have to change my motto slightly.Why program by hand in five days what you can spend twenty-five years of your
life automating?
We worked quite hard to build the largest tutorial on ANTLR: the mega-tutorial! A post over 13.000 words long, or more than 30 pages, to try answering all your questions about ANTLR. Missing something? Contact us and let us now, we are here to help
翻译自: https://www.javacodegeeks.com/2017/03/antlr-mega-tutorial.html