Python数据分析|pandas入门必看!(《利用Python进行数据分析》)
pandas数据结构介绍
Series
Series为一维数组型对象,是一个长度固定且有序的字典,可以将索引值和数据值按位置配对。
import pandas as pd
obj=pd.Series([4,7,-5,3])
obj.index#获取索引
obj.values#获取值
obj2=pd.Series([4,7,-5,3],index=["d",'b','a','c'])#设置索引集以及数据集
obj2
obj2[['c','a']]#用索引标签取出数据
obj2[obj2>0]
obj2*2
'b' in obj2#返回布尔值
sdata={
"ohio":35000,'texas':71000,'oregon':16000,'utah':5000}#将字典导入到series中
obj3=pd.Series(sdata)
obj3
#按照字典的键调整顺序
states=['california','ohio','oregon','texas']#引用索引调整了数据的顺序
obj4=pd.Series(sdata,index=states)
obj4
#isnull和notnull检查缺失数据
pd.isnull(obj4)
pd.notnull(obj4)
#对数据进行命名,相当于标题
obj4.name='population'
obj4.index.name="states"
DataFrame
表示矩阵的数据表,包含已排序的列集合,每一列可以是不同的值类型。
构建dataframe
import pandas as pd
from pandas import Series,DataFrame
data={
"hello":[1,2,3,4,5],
"my":[6,7,8,9,10],
"world":[11,12,13,14,15]}
frame=pd.DataFrame(data)
frame.head()#展现头五行
columns对列进行操作
import pandas as pd
from pandas import Series,DataFrame
data={
"hello":[1,2,3,4,5],
"my":[6,7,8,9,10],
"world":[11,12,13,14,15]}
frame=pd.DataFrame(data)
frame
#指定列的顺序,将数据按照指定顺序排列
pd.DataFrame(data,columns=["my","hello","world"])
#若传入的列不在字典中,将会在结果中出现缺失值
frame2=pd.DataFrame(data,columns=["my","hello","world","hhhh"],index=['one','two','three','four','five'])
frame2.columns
frame2['hello']#直接引用hello所在列的数据
#将空的列进行赋值
frame2['hhhh']=np.arange(6)
frame2
loc对行进行操作
#通过位置或特殊属性loc进行选取
frame2.loc['three']
#将空的列进行赋值,赋值时须注意值得长度与dataframe的铲毒相匹配
frame2['debt']=np.arange(6.)
#选择性将行赋值
val=pd.Series([-1.2,-1.5,-1.7],index=['two','four','five'])
frame2['hhhh']=val
frame2
字典套用
#若被赋值的列不存在,则生成一个新列
frame2['eastern']=frame2.world==11
#删除某列
del frame2['my']
frame2
#包含字典的嵌套字典
pop={
'nevada':{
2001:2.4,2002:2.9},'onio':{
2000:1.5,2001:1.7,2002:3.6}}
frame3=pd.DataFrame(pop)
frame3
#设置显示索引,字典不会被排序
pd.DataFrame(pop,index=[2001,2002,2003])
#包含series的字典构造DataFrame
pdata={
'onio':frame3['onio'][:-1],'nevada':frame3['nevada'][:2]}#注意切片左闭右开呀
pd.DataFrame(pdata)
基本功能
reindex重建索引
reindex()函数重新建索引,括号内为索引值;
obj=pd.Series([4.5,7.2,-5.3,3.6],index=['d','b','a','c'])
obj
#重建索引
obj2=obj.reindex(["a",'b','c','d','e'])
obj2
#重新插值或填值
obj3=pd.Series(['blue','purple','yellow'],index=[0,2,4])
obj3
method选参数插值
#reindex可以改变行索引、列索引
frame=pd.DataFrame(np.arange(9).reshape((3,3)),index=['a','c','d'],columns=['onio','texas','california'])
frame
frame2=frame.reindex(['a','b','c','d'])
frame2
states=['texas','utah','california']
frame2=frame2.reindex(columns=states)#将改后的表赋给frame2,修改索引不是在原基础上改的
##等价于
frame2.loc[['a','b','c','d'],states]#取对应索引下的行列值,此句是定位而不是调索引名
drop删除条目
obj=pd.Series(np.arange(5.),index=['a','b','c','d','e'])
obj
new_obj=obj.drop('c')#去掉索引为c的元素
obj.drop(['d','c'])
obj.drop('c',inplace=True)
#inplace=true不创建新的对象,直接对原始对象进行修改;对数据进行修改,创建并返回新的对象承载其修改结果。
索引、选择与过滤
用数组切片处理数据
obj=pd.Series(np.arange(4.),index=['a','b','c','d'])
obj
obj[[1,3]]#只导出来两个数据及其对应的索引
obj[obj<2]#只导出来符合条件的数据及其对应的索引
#series的切片是闭区间
obj['b':'c']
#通过切片将数值series中的元素赋值
obj['b':'c']=5
obj
obj[:2]#前两行啊
obj[obj<=5]=0
obj
loc和iloc选择数据
对dataframe用轴标签(loc)或者整数标签(iloc)已numpy的语法从中选择数组的行和列的自己
obj=pd.Series(np.arange(4.),index=['a','b','c','d'])
obj
obj[[1,3]]#只导出来两个数据及其对应的索引
obj[obj<2]#只导出来符合条件的数据及其对应的索引
#series的切片是闭区间
obj['b':'c']
#通过切片将数值series中的元素赋值
obj['b':'c']=5
obj
obj[:2]#前两行啊
obj[obj<=5]=0
obj
data=pd.DataFrame(np.arange(16).reshape((4,4)),index=['m','n','v','p'],columns=["a",'b','c','d'])
data
#loc绝对引用索引,切片需要严格按照行名和列名来处理,不可以统一使用数字
data.loc[:'v','b']
#iloc可以用数字代替切片器‘索引名‘
data.iloc[2,[3,0,1]]
data.iloc[2]
data.iloc[:3,:3]
算数和数据对齐
df1=pd.DataFrame(np.arange(9.).reshape((3,3)),columns=list('bcd'),index=['ohio','texas','colorado'])
df1
df2=pd.DataFrame(np.arange(12.).reshape((4,3)),columns=list('bde'),index=['utah','ohio','texas','oregon'])
df2
df1+df2#保留并集行和列,未交叠部分相加为nan
#创建字典dataframe,字典名作为列名,对相同列名的数据进行计算
df1=pd.DataFrame({
'a':[1,2]})
df1
df2=pd.DataFrame({
'b':[3,4]})
df2
df1+df2#等价于df1.add(df2)
使用fill_value=?填充值的算数方法
来看上述的这个代码的例子,如df1缺失相关列或行,用fill_value=0对其进行填充,再做计算
df1=pd.DataFrame(np.arange(9.).reshape((3,3)),columns=list('bcd'),index=['ohio','texas','colorado'])
df2=pd.DataFrame(np.arange(12.).reshape((4,3)),columns=list('bde'),index=['utah','ohio','texas','oregon'])
df1.add(df2,fill_value=0)
#重建时可以令两个列/行相等
df1.reindex(columns=df2.columns,fill_value=0)
算数方法
| 方法 | 描述 |
|---|---|
| add,radd | df1+df2,df2+df1 |
| sub,rsub | df1-df2,df2-df1 |
| div,rdiv | df1/df2,df2/df1 |
| floordiv,rfloordiv | df1//df2,df2//df1 |
| mul,rmul | df1df2,df2df1 |
| pow,rpow | 幂次方 |
dataframe与series的计算
简单来说,用一个表格与某数组进行相加减,即在表格中寻找与数组元素相匹配的元素进行计算
frame=pd.DataFrame(np.arange(12.).reshape((4,3)),columns=list('bde'))
frame
series=frame.iloc[2]
frame+series#按照series的索引,对应将frame的列分别加series
series3=frame['d']
frame.add(series3,axis='index')#按照d列对应的行,与frame中的元素相加
apply函数实现映射
我们在函数中实现对Series不同属性之间的计算,返回一个结果,apply函数 会自动遍历每一行DataFrame的数据,最后将所有结果组合成一个Series数据结构并返回.
DataFrame.apply(func, axis=0, broadcast=False, raw=False, reduce=None, args=(), **kwds)
frame=pd.DataFrame(np.random.randn(4,3),columns=list("bde"),index=['utah',"ohio",'texas','oregon'])
frame
f=lambda x:x.max()-x.min()
frame.apply(f)#按列求函数值
frame.apply(f,axis='columns')#按照行来求函数值
applymap()函数可对dataframe中的每个函数进行统一操作
format=lambda x:'%.2f'%x
frame.applymap(format)#将frame中的每个元素统一化为两个浮点数的标准格式
sort排序和rank排名
对dataframe排序
按照索引的名称进行升序或者降序排列
#对dataframe按照索引顺序排列
frame=pd.DataFrame(np.arange(8).reshape((2,4)),index=['three','one'],columns=['d','a','b','c'])
frame
frame.sort_index()#默认是升序
frame.sort_index(axis=1,ascending=False)#沿水平方向,按照索引降序排列
#对dataframe中的值排序,需要设置参数,判断根据哪一列或哪一行的值排序
frame.sort_values(by=['d','a'],ascending=False)
对series进行排序
#对值进行排序
obj=pd.Series([4,7,-3,2],index=['a','b','c','d'])
obj.sort_values()#默认升序
obj2=pd.Series([4,np.nan,7,np.nan,-3,2],index=['a','b','c','d',"e",'f'])
obj2.sort_values()#nan值默认排序至series的尾部
排名
平均排名
obj=pd.Series([7,-5,7,4,2,0,4])
obj
obj.rank()#根据值的升序进行排名
上述对应 排名为[6.5, 1., 6.5, 4.5, 3. , 2. , 4.5],也就是将同排名进行同组平均分配,计算排名值
按序排名
obj=pd.Series([7,-5,7,4,2,0,4])
obj
obj.rank(method='first')
上述对应排名为[6., 1., 7., 4., 3., 2., 5.],也就是按照值升序依次排名,对于同名次数据,出现顺序决定其排名先后
平级排名
按照值降序对其进行排名,首先设定ascending=false
obj=pd.Series([7,-5,7,4,2,0,4])
obj
obj.rank(ascending=False,method='max')
其对应排名为[2., 7., 2., 4., 5., 6., 4.],对于同样大的数值,按照同一层排名来处理,此处的method参数可以换为其他值
| method | 描述 |
|---|---|
| average | 在组中分配平均排名 |
| min | 对整个组使用最小排名 |
| max | 对整个组使用最大排名 |
| first | 按照值在数据中出现的次序分配排名 |
| dense | 在与min相同,组件排名总增加1,不是一个组中的相等元素的数量 |
以上述数据为例,不同的参数执行结果为
obj.rank(ascending=False,method='dense').values
#[1., 5., 1., 2., 3., 4., 2.]同组并列,不同组加一,应该比较常用
obj.rank(ascending=False,method='min').values
#[1., 7., 1., 3., 5., 6., 3.]同组并列,不同组跳过上一组元素数量
obj.rank(ascending=False,method='max').values
#[2., 7., 2., 4., 5., 6., 4.]按照最大值排列
obj.rank(ascending=False,method='first').values
#[1., 7., 2., 3., 5., 6., 4.]同组值不判断同排名,按照顺序排列
描述性统计
描述性统计指标就那些,代入各个指标的函数就可,其中需要解释几个参数
- axis:轴的方向,axis=1横向,axis=0列向
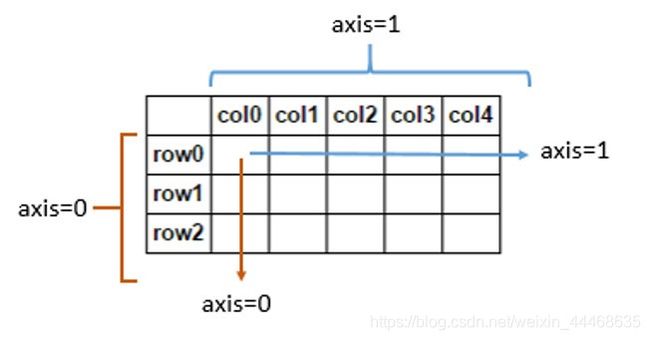
- skipna:排除缺失值,一版默认为自动排除缺失值,为true,有些情况下不得忽略缺失值,则任何计算都显示为nan,此时为false
- level:如果轴是多层索引的,改参数可以缩减分组层级
相关描述性指标代码如下:
df=pd.DataFrame([[1.4,np.nan],[7.1,-4.5],[np.nan,np.nan],[0.75,-1.3]],index=['a','b','c','d'],columns=['one','two'])
df
df.sum(axis=1)#按行求和,自动忽略nan值
df.sum(axis=1,skipna=False)#按行求和,不忽略nan值
df.idxmax()#最大值索引
df.idxmin()#最小索引
df.cumsum()#累计求和
df.median()#中位数
df.prod()#所有值的积
df.kurt()#样本峰度的值
df.pct_change()#计算百分比
df.describe().applymap(lambda x:'%.2f'%x)#describe自动生成描述性统计函数,后面限制了元素的数字格式
obj=pd.Series(['a','a','c','d']*4)
obj.describe()#字符型数组的描述性指标
相关性和协方差
ps一个函数,obj.is_unique判断一组数据是否都是唯一值
导入一个表格为price
returns=price.pct_change()#先求百分比
returns['a'].corr(returns['b'])#求两个列之间的相关系数
returns.corr()#返回数据的相关性矩阵
returns.cov()#返回数据的协方差矩阵
returns.corrwith(return.a)#返回每一列与a列的相关系数
唯一值、计数和成员属性
obj=pd.Series(['c','a','d','a','b','b','c','c'])
uniques=obj.unique()
uniques#返回数组中的唯一值
pd.value_counts(obj.values,sort=False)#返回每个值的个数,默认为降序,也可以用sort来设置分层排序
mask=obj.isin(['c','d'])#判断某个元素是否在数组中
obj[mask]#将mask传入,只显示在数组中的这部分
#依据unique-vals中的元素,在to_match查找对应元素,并返回与前者相同的索引名
to_match=pd.Series(['c','a','b','b','c','a'])
unique_vals=pd.Series(['c','b','a'])
pd.Index(unique_vals).get_indexer(to_match)
#返回data中唯一值在每个列中的个数
data=pd.DataFrame({
'qu1':[1,3,4,3,4],'qu2':[2,3,1,2,3],'qu3':[1,5,2,4,4]})
result=data.apply(pd.value_counts).fillna(0)#返回data中唯一值在每个列中的个数