题目背景
红太阳幼儿园的小朋友们开始分糖果啦!
CSP考完了,祝愿大家都取得理想的成绩~
大家最喜欢的蒟蒻君为大家奉上CSPJ2021题解,大家有哪里不会的可以参考一下 (请AKer们忽略a)
由于时间原因更得确实太晚了请大家原谅

红太阳幼儿园有 n n n 个小朋友,你是其中之一。保证 n ≥ 2 n \ge 2 n≥2。
有一天你在幼儿园的后花园里发现无穷多颗糖果,你打算拿一些糖果回去分给幼儿园的小朋友们。
由于你只是个平平无奇的幼儿园小朋友,所以你的体力有限,至多只能拿 R R R 块糖回去。
但是拿的太少不够分的,所以你至少要拿 L L L 块糖回去。保证 n ≤ L ≤ R n \le L \le R n≤L≤R。
也就是说,如果你拿了 k k k 块糖,那么你需要保证 L ≤ k ≤ R L \le k \le R L≤k≤R。
如果你拿了 k k k 块糖,你将把这 k k k 块糖放到篮子里,并要求大家按照如下方案分糖果:只要篮子里有不少于 n n n 块糖果,幼儿园的所有 n n n 个小朋友(包括你自己)都从篮子中拿走恰好一块糖,直到篮子里的糖数量少于 n n n 块。此时篮子里剩余的糖果均归你所有——这些糖果是作为你搬糖果的奖励。
作为幼儿园高质量小朋友,你希望让作为你搬糖果的奖励的糖果数量(而不是你最后获得的总糖果数量!)尽可能多;因此你需要写一个程序,依次输入 n , L , R n, L, R n,L,R,并输出出你最多能获得多少作为你搬糖果的奖励的糖果数量。
输入一行,包含三个正整数 n , L , R n, L, R n,L,R,分别表示小朋友的个数、糖果数量的下界和上界。
输出一行一个整数,表示你最多能获得的作为你搬糖果的奖励的糖果数量。
7 16 23610 14 188见附件中的 candy/candy3.in。见附件中的 candy/candy3.ans。篮子里现在糖果数 20 ≥ n = 7 20 \ge n = 7 20≥n=7,因此所有小朋友获得一块糖;
篮子里现在糖果数变成 13 ≥ n = 7 13 \ge n = 7 13≥n=7,因此所有小朋友获得一块糖;
篮子里现在糖果数变成 KaTeX parse error: Expected 'EOF', got '&' at position 3: 6 &̲lt; n = 7,因此这 6 6 6 块糖是作为你搬糖果的奖励。
容易发现,你获得的作为你搬糖果的奖励的糖果数量不可能超过 6 6 6 块(不然,篮子里的糖果数量最后仍然不少于 n n n,需要继续每个小朋友拿一块),因此答案是 6 6 6。
容易发现,当你拿的糖数量 k k k 满足 14 = L ≤ k ≤ R = 18 14 = L \le k \le R = 18 14=L≤k≤R=18 时,所有小朋友获得一块糖后,剩下的 k − 10 k - 10 k−10 块糖总是作为你搬糖果的奖励的糖果数量,因此拿 k = 18 k = 18 k=18 块是最优解,答案是 8 8 8。
| 测试点 | n ≤ n \le n≤ | R ≤ R \le R≤ | R − L ≤ R - L \le R−L≤ |
|---|---|---|---|
| 1 1 1 | 2 2 2 | 5 5 5 | 5 5 5 |
| 2 2 2 | 5 5 5 | 10 10 10 | 10 10 10 |
| 3 3 3 | 10 3 {10}^3 103 | 10 3 {10}^3 103 | 10 3 {10}^3 103 |
| 4 4 4 | 10 5 {10}^5 105 | 10 5 {10}^5 105 | 10 5 {10}^5 105 |
| 5 5 5 | 10 3 {10}^3 103 | 10 9 {10}^9 109 | 0 0 0 |
| 6 6 6 | 10 3 {10}^3 103 | 10 9 {10}^9 109 | 10 3 {10}^3 103 |
| 7 7 7 | 10 5 {10}^5 105 | 10 9 {10}^9 109 | 10 5 {10}^5 105 |
| 8 8 8 | 10 9 {10}^9 109 | 10 9 {10}^9 109 | 10 9 {10}^9 109 |
| 9 9 9 | 10 9 {10}^9 109 | 10 9 {10}^9 109 | 10 9 {10}^9 109 |
| 10 10 10 | 10 9 {10}^9 109 | 10 9 {10}^9 109 | 10 9 {10}^9 109 |
对于所有数据,保证 2 ≤ n ≤ L ≤ R ≤ 10 9 2 \le n \le L \le R \le {10}^9 2≤n≤L≤R≤109。
这道题作为普及T1还是很凉心滴…
求 max l ≤ x ≤ r x ( m o d n ) \displaystyle \max\limits_{l≤x≤r}x\pmod n l≤x≤rmaxx(modn),或者说是求l≤x≤r时,x%n的最大值。
首先任意一个数mod n,结果最大也就是n - 1了。
那什么时候答案是n - 1呢?有一下两种情况:
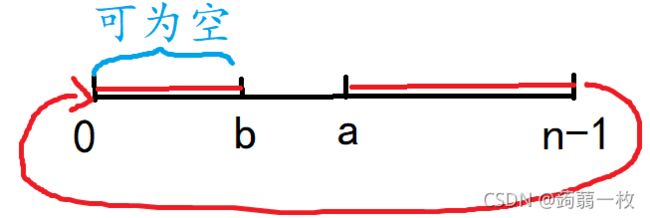
若不符合以上条件,即r - l + 1 < n且l % n <= r % n,答案为r % n。
我真是个高质量幼儿园小朋友啊
#include 
假设比较两个元素的时间为 O ( 1 ) \mathcal O(1) O(1),则插入排序可以以 O ( n 2 ) \mathcal O(n^2) O(n2) 的时间复杂度完成长度为 n n n 的数组的排序。不妨假设这 n n n 个数字分别存储在 a 1 , a 2 , … , a n a_1, a_2, \ldots, a_n a1,a2,…,an 之中,则如下伪代码给出了插入排序算法的一种最简单的实现方式:
这下面是 C/C++ 的示范代码
for (int i = 1; i <= n; i++)
for (int j = i; j >= 2; j--)
if (a[j] < a[j-1]) {
int t = a[j-1];
a[j-1] = a[j];
a[j] = t;
}
这下面是 Pascal 的示范代码
for i:=1 to n do
for j:=i downto 2 do
if a[j]为了帮助小 Z 更好的理解插入排序,小 Z 的老师 H 老师留下了这么一道家庭作业:
H 老师给了一个长度为 n n n 的数组 a a a,数组下标从 1 1 1 开始,并且数组中的所有元素均为非负整数。小 Z 需要支持在数组 a a a 上的 Q Q Q 次操作,操作共两种,参数分别如下:
1 x v 1~x~v 1 x v:这是第一种操作,会将 a a a 的第 x x x 个元素,也就是 a x a_x ax 的值,修改为 v v v。保证 1 ≤ x ≤ n 1 \le x \le n 1≤x≤n, 1 ≤ v ≤ 1 0 9 1 \le v \le 10^9 1≤v≤109。注意这种操作会改变数组的元素,修改得到的数组会被保留,也会影响后续的操作。
2 x 2~x 2 x:这是第二种操作,假设 H 老师按照上面的伪代码对 a a a 数组进行排序,你需要告诉 H 老师原来 a a a 的第 x x x 个元素,也就是 a x a_x ax,在排序后的新数组所处的位置。保证 1 ≤ x ≤ n 1 \le x \le n 1≤x≤n。注意这种操作不会改变数组的元素,排序后的数组不会被保留,也不会影响后续的操作。
H 老师不喜欢过多的修改,所以他保证类型 1 1 1 的操作次数不超过 5000 5000 5000。
小 Z 没有学过计算机竞赛,因此小 Z 并不会做这道题。他找到了你来帮助他解决这个问题。
第一行,包含两个正整数 n , Q n, Q n,Q,表示数组长度和操作次数。
第二行,包含 n n n 个空格分隔的非负整数,其中第 i i i 个非负整数表示 a i a_i ai。
接下来 Q Q Q 行,每行 2 ∼ 3 2 \sim 3 2∼3 个正整数,表示一次操作,操作格式见【题目描述】。
对于每一次类型为 2 2 2 的询问,输出一行一个正整数表示答案。
3 4 3 2 1
2 3
1 3 2
2 2
2 3
1
1
2
在修改操作之前,假设 H 老师进行了一次插入排序,则原序列的三个元素在排序结束后所处的位置分别是 3 , 2 , 1 3, 2, 1 3,2,1。
在修改操作之前,假设 H 老师进行了一次插入排序,则原序列的三个l元素在排序结束后所处的位置分别是 3 , 1 , 2 3, 1, 2 3,1,2。
注意虽然此时 a 2 = a 3 a_2 = a_3 a2=a3,但是我们不能将其视为相同的元素。
见附件中的 sort/sort2.in 与 sort/sort2.ans。
该测试点数据范围同测试点 1 ∼ 2 1 \sim 2 1∼2。
见附件中的 sort/sort3.in 与 sort/sort3.ans。
该测试点数据范围同测试点 3 ∼ 7 3 \sim 7 3∼7。
见附件中的 sort/sort4.in 与 sort/sort4.ans。
该测试点数据范围同测试点 12 ∼ 14 12 \sim 14 12∼14。
对于所有测试数据,满足 1 ≤ n ≤ 8000 1 \le n \le 8000 1≤n≤8000, 1 ≤ Q ≤ 2 × 10 5 1 \le Q \le 2 \times {10}^5 1≤Q≤2×105, 1 ≤ x ≤ n 1 \le x \le n 1≤x≤n, 1 ≤ v , a i ≤ 1 0 9 1 \le v,a_i \le 10^9 1≤v,ai≤109。
对于所有测试数据,保证在所有 Q Q Q 次操作中,至多有 5000 5000 5000 次操作属于类型一。
各测试点的附加限制及分值如下表所示。
| 测试点 | n ≤ n \le n≤ | Q ≤ Q \le Q≤ | 特殊性质 |
|---|---|---|---|
| 1 ∼ 4 1 \sim 4 1∼4 | 10 10 10 | 10 10 10 | 无 |
| 5 ∼ 9 5 \sim 9 5∼9 | 300 300 300 | 300 300 300 | 无 |
| 10 ∼ 13 10 \sim 13 10∼13 | 1500 1500 1500 | 1500 1500 1500 | 无 |
| 14 ∼ 16 14 \sim 16 14∼16 | 8000 8000 8000 | 8000 8000 8000 | 保证所有输入的 a i , v a_i,v ai,v 互不相同 |
| 17 ∼ 19 17 \sim 19 17∼19 | 8000 8000 8000 | 8000 8000 8000 | 无 |
| 20 ∼ 22 20 \sim 22 20∼22 | 8000 8000 8000 | 2 × 1 0 5 2 \times 10^5 2×105 | 保证所有输入的 a i , v a_i,v ai,v 互不相同 |
| 23 ∼ 25 23 \sim 25 23∼25 | 8000 8000 8000 | 2 × 1 0 5 2 \times 10^5 2×105 | 无 |
给出长度为n的数组与q次操作,每次操作有两种类型:
1️⃣ 将a[x]改为v。
2️⃣ 求出进行插入排序后之前的a[x]排在第几位(不改变数组中元素值)。
对于每次修改操作,直接将a[x]赋值为v;
对于每次查询操作,按照题目中给出的插入排序代码排序,求出a[x]的位置。
时间复杂度:O(qn2),O(1)修改,O(n2)查询
空间复杂度:O(n)
在36分做法的基础上手写cmp函数(若值不同,值越小越靠前;否则,输入时的下标越小越靠前,模拟插入排序),对于每次查询操作用sort代替插入排序。
时间复杂度:O(qnlogn),O(1)修改,O(nlogn)查询
空间复杂度:O(n)
其实对于每次查询操作,我们并不需要大动干戈地排一遍序,此时:
答案 = x - ∑ i = 1 x − 1 a [ i ] > a [ x ] + ∑ i = x + 1 n a [ i ] < a [ x ] \displaystyle \sum_{i=1}^{x-1} {a[i]>a[x]} +\sum_{i=x+1}^{n} {a[i]
原理想必大家都懂,就是在最开始x的基础上先向左找不合法的元素然后向左移,再向右找不合法的元素然后向右移,这样遍历一遍就能得出最终a[x]的下标了。
时间复杂度:O(qn),O(1)修改,O(n)查询。
空间复杂度:O(n)
小伙伴们可以发现,前几个方法的修改都是直接O(1),然后再查询上做文章。但是题目中说过,修改最多只有5000次,而查询最多有2 * 105次,所以正解肯定需要一个O(1)的查询。
对于每次修改操作,我们需要让数组有序并且记录下元素的下标,那么问题来了:
在一个有序的数组中插入一个数,如何让数组有序?
既然数组有序,我们可以将新插入的数分为两类:
对于1,我们将这段数排一下序就ok了。当然不要浪费前面所有数有序的特性,我们将这段数向前冒泡即可。
对于2,同理,向后冒泡。
时间复杂度:O(qn2),O(n)修改,O(1)查询。
在修改查询这类题中线段树是肥肠常用的算法啦~
幸运的是插入排序是稳定排序,但是线段树不能插入两个量(值和下标)鸭。
所以这里我们用一个权值表现这两个量:n * a[i] + i - 1。
接下来就是上模板了。
对于不会的小伙伴们蒟蒻君在这里也不细讲了 (毕竟能力时间有限),麻烦出门右转百度~
由于线段树处理1 ~ 2n,导致修改查询复杂度是常数级的。
时间复杂度:O(q),修改O(1),查询O(1)(63次)。
空间复杂度:O(n)。
#include #include #include #include 温馨提示: 若cin/cout不加去同步优化会T掉6个点,退化成76分算法。
#include 
在本问题中,计算机分为两大类:服务机(Server)和客户机(Client)。服务机负责建立连接,客户机负责加入连接。
需要进行网络连接的计算机共有 n n n 台,编号为 1 ∼ n 1 \sim n 1∼n,这些机器将按编号递增的顺序,依次发起一条建立连接或加入连接的操作。
每台机器在尝试建立或加入连接时需要提供一个地址串。服务机提供的地址串表示它尝试建立连接的地址,客户机提供的地址串表示它尝试加入连接的地址。
一个符合规范的地址串应当具有以下特征:
a.b.c.d:e 的格式,其中 a , b , c , d , e a, b, c, d, e a,b,c,d,e 均为非负整数;相应地,不符合规范的地址串可能具有以下特征:
a.b.c.d:e 格式的字符串,例如含有多于 3 3 3 个字符 . 或多于 1 1 1 个字符 : 等情况;例如,地址串 192.168.0.255:80 是符合规范的,但 192.168.0.999:80、192.168.00.1:10、192.168.0.1:088、192:168:0:1.233 均是不符合规范的。
如果服务机或客户机在发起操作时提供的地址串不符合规范,这条操作将被直接忽略。
在本问题中,我们假定凡是符合上述规范的地址串均可参与正常的连接,你无需考虑每个地址串的实际意义。
由于网络阻塞等原因,不允许两台服务机使用相同的地址串,如果此类现象发生,后一台尝试建立连接的服务机将会无法成功建立连接;除此之外,凡是提供符合规范的地址串的服务机均可成功建立连接。
如果某台提供符合规范的地址的客户机在尝试加入连接时,与先前某台已经成功建立连接的服务机提供的地址串相同,这台客户机就可以成功加入连接,并称其连接到这台服务机;如果找不到这样的服务机,则认为这台客户机无法成功加入连接。
请注意,尽管不允许两台不同的服务机使用相同的地址串,但多台客户机使用同样的地址串,以及同一台服务机同时被多台客户机连接的情况是被允许的。
你的任务很简单:在给出每台计算机的类型以及地址串之后,判断这台计算机的连接情况。
接下来 n n n 行,每行两个字符串 o p , a d \mathit{op}, \mathit{ad} op,ad,按照编号从小到大给出每台计算机的类型及地址串。
其中 o p \mathit{op} op 保证为字符串 Server 或 Client 之一, a d \mathit{ad} ad 为一个长度不超过 25 25 25 的,仅由数字、字符 . 和字符 : 组成的非空字符串。
每行的两个字符串之间用恰好一个空格分隔开,每行的末尾没有多余的空格。
如果第 i i i 台计算机为服务机,则:
OK。FAIL。ERR。如果第 i i i 台计算机为客户机,则:
FAIL。ERR。5
Server 192.168.1.1:8080
Server 192.168.1.1:8080
Client 192.168.1.1:8080
Client 192.168.1.1:80
Client 192.168.1.1:99999
OK
FAIL
1
FAIL
ERR
10
Server 192.168.1.1:80
Client 192.168.1.1:80
Client 192.168.1.1:8080
Server 192.168.1.1:80
Server 192.168.1.1:8080
Server 192.168.1.999:0
Client 192.168.1.1.8080
Client 192.168.1.1:8080
Client 192.168.1.1:80
Client 192.168.1.999:0
OK
1
FAIL
FAIL
OK
ERR
ERR
5
1
ERR
见附件中的 network/network3.in。见附件中的 network/network3.ans。见附件中的 network/network4.in。见附件中的 network/network4.ans。计算机 1 1 1 为服务机,提供符合规范的地址串 192.168.1.1:8080,成功建立连接;
计算机 2 2 2 为服务机,提供与计算机 1 1 1 相同的地址串,未能成功建立连接;
计算机 3 3 3 为客户机,提供符合规范的地址串 192.168.1.1:8080,成功加入连接,并连接到服务机 1 1 1;
计算机 4 4 4 为客户机,提供符合规范的地址串 192.168.1.1:80,找不到服务机与其连接;
计算机 5 5 5 为客户机,提供的地址串 192.168.1.1:99999 不符合规范。
| 测试点编号 | n ≤ n \le n≤ | 特殊性质 |
|---|---|---|
| 1 1 1 | 10 10 10 | 性质 1 2 3 |
| 2 ∼ 3 2 \sim 3 2∼3 | 100 100 100 | 性质 1 2 3 |
| 4 ∼ 5 4 \sim 5 4∼5 | 1000 1000 1000 | 性质 1 2 3 |
| 6 ∼ 8 6 \sim 8 6∼8 | 1000 1000 1000 | 性质 1 2 |
| 9 ∼ 11 9 \sim 11 9∼11 | 1000 1000 1000 | 性质 1 |
| 12 ∼ 13 12 \sim 13 12∼13 | 1000 1000 1000 | 性质 2 |
| 14 ∼ 15 14 \sim 15 14∼15 | 1000 1000 1000 | 性质 4 |
| 16 ∼ 17 16 \sim 17 16∼17 | 1000 1000 1000 | 性质 5 |
| 18 ∼ 20 18 \sim 20 18∼20 | 1000 1000 1000 | 无特殊性质 |
“性质 1”为:保证所有的地址串均符合规范;
“性质 2”为:保证对于任意两台不同的计算机,如果它们同为服务机或者同为客户机,则它们提供的地址串一定不同;
“性质 3”为:保证任意一台服务机的编号都小于所有的客户机;
“性质 4”为:保证所有的地址串均形如 a.b.c.d:e 的格式,其中 a , b , c , d , e a, b, c, d, e a,b,c,d,e 均为不超过 10 9 {10}^9 109 且不含有多余前导 0 0 0 的非负整数;
“性质 5”为:保证所有的地址串均形如 a.b.c.d:e 的格式,其中 a , b , c , d , e a, b, c, d, e a,b,c,d,e 均为只含有数字的非空字符串。
对于 100 % 100 \% 100% 的数据,保证 1 ≤ n ≤ 1000 1 \le n \le 1000 1≤n≤1000。
这题的名字好像图论哦
给出n台计算机的地址串,每台计算机都是服务机或者客户机。
若地址串不合法,输出"ERR",否则:
思路应该比较简单,这道题主要有两个难点:
对于第一个问题,我们直接按题目中所说的规则去模拟就好了,对于第二个问题其实我们用STL里的map就行了(蒟蒻君的方法不一定是最好用的)。
这里我们可以定义一个映射表:
(位置在代码中注释易错点1,2的地方)
注意判断3个’.‘和’:‘的顺序,即’:‘是否在’.'的前面,若没有判断就是可怜的75pts。
注意题目中说的没有前导0,不能只判断a,b,c,d,e的第一位是不是0,若a,b,c,d,e==0,判断错误,可怜的10pts。
#include 小熊的水果店里摆放着一排 n n n 个水果。每个水果只可能是苹果或桔子,从左到右依次用正整数 1 , 2 , … , n 1, 2, \ldots, n 1,2,…,n 编号。连续排在一起的同一种水果称为一个“块”。小熊要把这一排水果挑到若干个果篮里,具体方法是:每次都把每一个“块”中最左边的水果同时挑出,组成一个果篮。重复这一操作,直至水果用完。注意,每次挑完一个果篮后,“块”可能会发生变化。比如两个苹果“块”之间的唯一桔子被挑走后,两个苹果“块”就变成了一个“块”。请帮小熊计算每个果篮里包含的水果。
第一行,包含一个正整数 n n n,表示水果的数量。
第二行,包含 n n n 个空格分隔的整数,其中第 i i i 个数表示编号为 i i i 的水果的种类, 1 1 1 代表苹果, 0 0 0 代表桔子。
输出若干行。
第 i i i 行表示第 i i i 次挑出的水果组成的果篮。从小到大排序输出该果篮中所有水果的编号,每两个编号之间用一个空格分隔。
12
1 1 0 0 1 1 1 0 1 1 0 0
1 3 5 8 9 11
2 4 6 12
7
10
20
1 1 1 1 0 0 0 1 1 1 0 0 1 0 1 1 0 0 0 0
1 5 8 11 13 14 15 17
2 6 9 12 16 18
3 7 10 19
4 20
见附件中的 fruit/fruit3.in。见附件中的 fruit/fruit3.ans。这是第一组数据的样例说明。
所有水果一开始的情况是 [ 1 , 1 , 0 , 0 , 1 , 1 , 1 , 0 , 1 , 1 , 0 , 0 ] [1, 1, 0, 0, 1, 1, 1, 0, 1, 1, 0, 0] [1,1,0,0,1,1,1,0,1,1,0,0],一共有 6 6 6 个块。
在第一次挑水果组成果篮的过程中,编号为 1 , 3 , 5 , 8 , 9 , 11 1, 3, 5, 8, 9, 11 1,3,5,8,9,11 的水果被挑了出来。
之后剩下的水果是 [ 1 , 0 , 1 , 1 , 1 , 0 ] [1, 0, 1, 1, 1, 0] [1,0,1,1,1,0],一共 4 4 4 个块。
在第二次挑水果组成果篮的过程中,编号为 2 , 4 , 6 , 12 2, 4, 6, 12 2,4,6,12 的水果被挑了出来。
之后剩下的水果是 [ 1 , 1 ] [1, 1] [1,1],只有 1 1 1 个块。
在第三次挑水果组成果篮的过程中,编号为 7 7 7 的水果被挑了出来。
最后剩下的水果是 [ 1 ] [1] [1],只有 1 1 1 个块。
在第四次挑水果组成果篮的过程中,编号为 10 10 10 的水果被挑了出来。
对于 10 % 10 \% 10% 的数据, n ≤ 5 n \le 5 n≤5。
对于 30 % 30 \% 30% 的数据, n ≤ 1000 n \le 1000 n≤1000。
对于 70 % 70 \% 70% 的数据, n ≤ 50000 n \le 50000 n≤50000。
对于 100 % 100 \% 100% 的数据, 1 ≤ n ≤ 2 × 10 5 1 \le n \le 2 \times {10}^5 1≤n≤2×105。
由于数据规模较大,建议 C/C++ 选手使用 scanf 和 printf 语句输入、输出。
给出一个长度为n的数组,每一位必为0或1,连续的一段0或1被称为1个“块”,每次输出所有“块”的第一位的编号,被输出的位直接删除。
注意每轮输出后,所有的“块”都是“重新组合”的,如:
12
1 1 0 0 1 1 1 0 1 1 0 0
第一轮:

第二轮:

按照题目说的意思直接模拟,代码细节较多。
时间复杂度:O(n2)
空间复杂度:O(n)
用队列维护每一个“块”,若两个块在队列里相邻且元素相同,直接合并,代码细节还是有亿点多。
时间复杂度:O(nlogn)
空间复杂度:O(n)
看大佬的题解说这题就是个珂朵莉树模板 (可惜我太弱了根本布吉岛珂朵莉树是啥)。
时间复杂度:O(nlogn)
空间复杂度:O(n)
#include #include 这里直接照搬代码。
// Author : Luogu Canstant0x5F3759DF
#include (我打死也不会告诉你我不会弄超链接下载)
考虑到文章长度问题,蒟蒻君把附件上传到了洛谷剪切板。
⭐T1~T2点击这里⭐
⭐T3~T4点击这里⭐