猿辅导公司的数据中台部门为猿辅导、斑马、猿编程、小猿搜题、猿题库、南瓜科学等各个业务线的产品、运营、研发提供标准化的数据集(OneData)和统一数据服务(OneService)。OLAP平台作为数据中台的一个核心部分,为各个业务线提供统一标准化的、可复用的、高可靠的数据服务,支持各个业务线人员进行快速灵活的查询和分析,是连接前台和后台的桥梁。
我们引入了性能强悍的新一代MPP数据库:StarRocks,来构建OLAP平台。基于StarRocks,我们统一了实时数据分析和离线数据分析。当前StarRocks有3个集群,每天百万级有效查询请求,p99延迟1s,用于广告投放渠道转化、用户成单和续报、直播质量监控等多个数据场景,支持各业务线进行更加快速灵活的查询和分析,全面提升数据分析能力。
“ 作者:申阳,
猿辅导数据中台,大数据研发工程师 ”
平台选型的业务背景
业务特点和需求
猿辅导作为互联网教育行业赛道中的领先品牌,每日有海量数据生成,为实现科技助力教育,十分重视数据在公司发展中发挥的作用,需要不断解决在数据建设上遇到的诸多挑战。
在互联网教育数据体系中,不仅仅要关注用户活跃、订单收入,也很看重渠道推广转换率和用户续报率。这些指标存在不同的维度和不同的计算口径,以及多样化的业务系统接入模式,给我们OneService的底层设计带来了挑战。另一方面,数据时效性需求逐渐增强,离线T+1的数据已经越来越无法满足驱动业务的需求,数据逐步实时化也成为不可逆转的行业发展趋势。
在这样的背景下,我们的OLAP平台需要同时支持实时和离线数据写入,以支持不同时效的查询需求;需要支持复杂、多样的数据查询逻辑,以满足各种不同的业务场景的数据分析需求;需要能够进行快速的在线扩展,以支持业务快速发展带来的数据规模增长。
对OLAP引擎的需求
总结起来,我们对于OLAP的需求大概包括以下几点:
- 数据查询延迟在秒级/毫秒级;
- 同时高效支持大宽表和多表join查询,以支持复杂查询场景;
- 需要支持高并发查询场景;
- 同时支持流式数据和批式数据摄入,支持实时/离线数据ETL任务;
- 支持标准化SQL,大幅度降低用户使用成本;
- 具有高效的精准去重能力;
- 较好的在线扩展能力,较低的运维管理成本。
技术选型和优劣势对比
OLAP(On-line Analytical Processing,联机分析处理)是在基于数据仓库多维模型的基础上实现的面向分析的各类操作的集合,强调数据分析性能和SQL执行时间。
在当今,各类OLAP数据引擎可谓百花齐放,可以分为MOLAP ( Multi-dimensional OLAP )、ROLAP ( Relational OLAP ) 和HOLAP ( Hybrid OLAP ) 三类。
MOLAP引擎的代表包括:Druid,Kylin等,本质是通过空间和预计算换在线查询时间。在数据写入时生成预聚合数据,这样查询的时候命中的就是预聚合的数据而非明细数据,从而大幅提高查询效率,在一些固定查询模式的场景中,这种效率提升可谓非常明显。但是他的缺点也来自于这种预聚合模型,因为它极大的限制了数据模型的灵活性,比如在数据维度变化时的数据重建成本非常高,而且明细数据也丢失了。
ROLAP引擎的代表包括:Presto,Impala,GreenPlum,Clickhouse等,和MOLAP的区别在于,ROLAP在收到查询请求时,会先把query解析成查询计划,执行查询算子,在原始数据基础上进行诸如sum、groupby等各种各类计算,查询灵活,可扩展性好,往往使用MPP架构通过扩大并发来提升计算效率。这种模型的引擎优点是灵活性好,但是对于一个大查询/复杂查询它的性能是不稳定的,同时可能造成冗余的重复计算,消耗更多资源。
HOLAP引擎是MOLAP和ROLAP的融合体,对于聚合数据的查询请求,使用类似于MOLAP的预计算数据模型。对于明细数据和没有预聚合的数据场景下使用ROLAP的计算方式,比拼资源和算力,这样即使没有明确的场景要求下,也可以实现最优化的查询性能,适应性更好。这方面做的比较好的系统主要有StarRocks。
在团队的小伙伴们一系列调研和论证之后,首先排除了无法提供低延迟查询性能的引擎,比如Presto等,其次我们同时需要兼顾复杂业务场景支持能力,易用性和生产运维成本最低化,因此在这些维度上对比了Druid、ClickHouse、Kylin和StarRocks。

StarRocks作为一个MPP架构的HOLAP引擎,保证了数据模型的灵活性和查询性能,Rollup和物化视图功能使用了MOLAP引擎的预计算思想,在一些场景上通过空间换时间的方式极大地提高数据查询效率。最终我们选择StarRocks,一方面是因为StarRocks查询性能强悍,同时兼容MySQL协议极大降低了用户的使用门槛;另一方面它可以在高并发和高吞吐的不同场景下都表现出较好的适用性,和数据中台流批一体的OneService发展思路不谋而合。
应用场景
我们基于StarRocks构建了实时和离线统一的OLAP平台,交互查询和BI报表应用在数据中台的应用层发挥了巨大作用,为各个业务线的主管/产品运营同学的运营策略、广告投放策略等提供了可靠支持。
基于StarRocks,我们构建的全新数据架构如下:
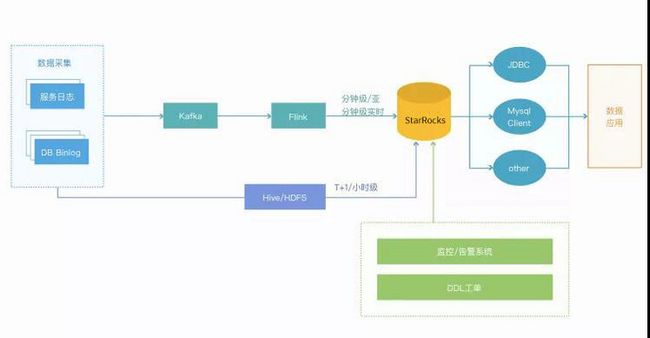
下面简单介绍几个典型的应用场景:
实时直播质量监控
我们使用StarRocks在直播质量分析相关系统中提供支持。这部分是直播引擎的研发同事十分关心的一些指标,直接关系到直播上课中的服务质量,一般是分钟级/亚分钟级的时效性要求。场景包括:网络质量、宏观丢包率、高峰时段可用率、音视频可用率等。

离线数据交互查询和BI报表
在数据架构升级前,离线T+1数据最终落地到MySQL上进行交互式查询和BI报表展示,查询的Query多是单表查询,维度组合较为灵活。但是随着业务增长和数据规模扩大,MySQL的查询性能逐渐遇到瓶颈,无法支持一些多维度数据的查询场景,同时运维成本也越来越重。
在架构升级过程中,我们引入了StarRocks计算引擎作为BI数据的落地层。由于StarRocks兼容MySQL协议,数据应用层可以通过JDBC直接连接,因此在迁移过程中几乎没有成本,而数据摄入和查询效率得到了几倍到几百倍的提升,为各个业务线的主管/产品运营同学提供了可靠的决策支持。
准实时用户成单和续报数据
我们在订单/续报等核心数据场景中,T+1的离线数据已经无法为业务提供最有力的决策支撑,越来越多需要当天数据的场景和报表需求。这里的主要挑战是:
- 跨团队合作、跨源、跨库的数据场景。
- 数据有时效性要求,查询响应要快。
- 对线上业务没有侵入性,屏蔽影响。
我们的解决方法是,导入Hive历史存量数据+订阅binlog增量数据通过flinkSQL实时灌进StarRocks中,同时针对不用的业务需求场景做表结构设计和查询优化。
实时推广投放策略
对于广告投放类的效果数据,我们会需要分钟级或更高的时效性要求,因为数据的变化可能直接影响到投放效果的评估和投放策略的变化。
我们同样用flinkSQL订阅业务DB的binlog,最终落地到StarRocks,作为BI报表和业务系统的统一数据产出口径。
实践心得
集群监控
目前我们关注的核心集群监控指标包括:
- FE节点失联
- BE节点失联
- BE磁盘坏盘
- BE CPU平均使用率过高
- FE Master的内存水位过高
基于Query级别的监控主要有:
- 大查询告警,例如ScanBytes、ScanRows
- 超过2分钟的慢查询告警
- 用户连接数过多
- 用“select 1”查询探活整体服务的可用性
打通生态
在早期使用时,StarRocks当时和其他大数据开源生态的适配能力还有不足,因此我们做了一些改造性工作。
Flink Connector
我们目前实时的摄入任务大部分都是通过Flink来实现。我们基于Stream Load实现了flink connector,线上使用性能良好,数据批次的时效性一般控制在分钟/半分钟级别。
离线数据摄入
对于离线数据的摄入,基本是T+1的时效,在凌晨调度中完成。
我们主要是使用Stream Load和Broker Load两种方式,我们在仓库ETL调度框架中对于两种Load分别进行了封装,区别是:
- 数据量不大/需要加工计算的,先落地本地磁盘文件,然后通过Stream Load导入StarRocks
- 数据量较大的,先写入Hive临时表,然后Broker Load导入StarRocks
Presto StarRocks Catalog
我们使用Presto查询StarRocks的时候主要是针对于一些需要跨源查询的场景,比如StarRocks中的实时同步数据与Hive中的历史数据通过一定条件join并最终产出小时级的数据报表。
这里遇到的问题是Presto原生的MySQL Catalog无法读取StarRocks元数据,主要原因是information_schema中元数据的类型和Presto数据类型需要适配,我们最终通过重新实现的Presto StarRocks Catalog来解决。
StarRocks审计平台
另外我们也打造了StarRocks DDL工单审计平台,帮助用户能够更好的建立正确的表结构。
审计平台会监控大查询和慢查询,这些对集群性能影响较大的查询,通过告警机器人的方式通知到用户,督促大家去做查询的优化。
基于审计日志数据治理
之前常见遇到的一个问题是:BE CPU被吃光了/磁盘IO打满
不同的case都可能导致这个现象:
- 某一个大查询scan数据量太多、耗时较长直接吃掉所有io
- 表buckets过多导致scan所有盘
- 大查询频繁提交等
这类问题排查起来较为困难,除了手动杀掉查询,好像没什么好的处理办法。另一方面大量的导入操作(compaction)是否也会造成cpu和io的压力。
目前的解决方案就是通过审计日志和BE服务日志来监控查询和写入,对于有问题的请求及时处理避免对集群性能影响的进一步扩大。
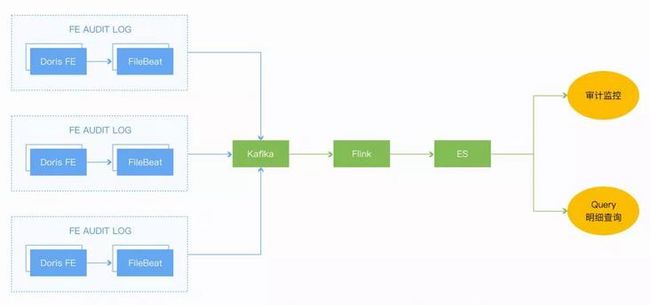
我们通过filebeat采集了fe.audit.log日志,并最终导入到ES中,基于ES做query的分析和监控。
目前监控主要是:大查询和慢查询,这些对集群性能影响较大的查询,通过告警机器人的方式通知到用户,督促大家去做查询的优化。并实现了大查询/慢查询的告警,监控和明细分析。
未来展望和规划
应用场景
后续我们计划基于StarRocks做更多的场景实践探索:
- 基于Bitmap的多维分析/BI自助工具
- 通用事件分析平台(支持明细+聚合)
运维建设
在组件运维层面的工作包括:自动化运维,建设回归测试框架、自动化集群扩缩容脚本、自动化集群升级脚本等,降低人工操作成本。
平台推广
在数据中台的平台化建设中也少不StarRocks的参与,包括:
- 技术分享,最佳实践和用户培训;
- 统一元数据平台,打通不同引擎的DDL、权限/租户管理等功能;
- 用户自助BI工具,屏蔽引擎细节,用户简单操作的可视化报表平台。
总结
通过引入StarRocks计算引擎,我们实现了流式数据、批式数据融合的一站式数据存储和查询引擎,对外提供语义一致和易用的数据服务。可以说StarRocks为猿辅导数据中台的标准化数据集(OneData)和统一数据平台服务(OneService)能力奠定了一个稳固的基础,支持各业务线进行更加快速灵活的查询和分析,全面提升数据分析能力,也为未来的数据平台化建设提供了更多可能性。
最后,十分感谢StarRocks鼎石科技团队专业的支持服务,希望我们能一起把StarRocks建设得更好。