gdb -iex_如何使用IEX Cloud,Matplotlib和AWS在Python中创建自动更新数据可视化
gdb -iex
Python is an excellent programming language for creating data visualizations.
Python是用于创建数据可视化的优秀编程语言。
However, working with a raw programming language like Python (instead of more sophisticated software like, say, Tableau) presents some challenges. Developers creating visualizations must accept more technical complexity in exchange for vastly more input into how their visualizations look.
但是,使用像Python这样的原始编程语言(而不是像Tableau这样的更复杂的软件)来工作面临一些挑战。 创建可视化的开发人员必须接受更多的技术复杂性,以换取更多的可视化外观输入。
In this tutorial, I will teach you how to create automatically-updating Python visualizations. We'll use data from IEX Cloud and we'll also use the matplotlib library and some simple Amazon Web Services product offerings.
在本教程中,我将教您如何创建自动更新的Python可视化文件。 我们将使用来自IEX Cloud的数据,还将使用matplotlib库和一些简单的Amazon Web Services产品。
第1步:收集数据 (Step 1: Gather Your Data)
Automatically updating charts sound appealing. But before you invest the time in building them, it is important to understand whether or not you need your charts to be automatically updated.
自动更新图表听起来很吸引人。 但是在投入时间来构建它们之前,重要的是要了解是否需要自动更新图表。
To be more specific, there is no need for your visualizations to update automatically if the data they are presenting does not change over time.
更具体地说,如果可视化呈现的数据不会随着时间变化,则无需自动更新。
Writing a Python script that automatically updates a chart of Michael Jordan's annual points-per-game would be useless - his career is over, and that data set is never going to change.
编写一个Python脚本来自动更新迈克尔·乔丹的每场年度得分图表是没有用的-他的职业生涯已经结束,数据集永远不会改变。
The best data set candidates for auto-updating visualizations are time series data where new observations are being added on a regular basis (say, each day).
自动更新可视化效果的最佳数据集是时间序列数据,其中定期(例如每天)添加新观测值。
In this tutorial, we are going to be using stock market data from the IEX Cloud API. Specifically, we will be visualizing historical stock prices for a few of the largest banks in the US:
在本教程中,我们将使用IEX Cloud API中的股市数据。 具体来说,我们将可视化美国一些最大银行的历史股价:
- JPMorgan Chase (JPM) 摩根大通(JPM)
- Bank of America (BAC) 美国银行(BAC)
- Citigroup (C) 花旗集团(C)
- Wells Fargo (WFC) 富国银行(WFC)
- Goldman Sachs (GS) 高盛(GS)
The first thing that you'll need to do is create an IEX Cloud account and generate an API token.
您需要做的第一件事是创建一个IEX Cloud帐户并生成一个API令牌。
For obvious reasons, I'm not going to be publishing my API key in this article. Storing your own personalized API key in a variable called IEX API Key will be enough for you to follow along.
出于明显的原因,我不会在本文中发布我的API密钥。 将自己的个性化API密钥存储在名为IEX API Key的变量中就足够了。
Next, we're going to store our list of tickers in a Python list:
接下来,我们将代码列表存储在Python列表中:
tickers = [
'JPM',
'BAC',
'C',
'WFC',
'GS',
]The IEX Cloud API accepts tickers separated by commas. We need to serialize our ticker list into a separated string of tickers. Here is the code we will use to do this:
IEX Cloud API接受用逗号分隔的代码。 我们需要将股票代码列表序列化为一个单独的股票代码字符串。 这是我们将用来执行此操作的代码:
#Create an empty string called `ticker_string` that we'll add tickers and commas to
ticker_string = ''
#Loop through every element of `tickers` and add them and a comma to ticker_string
for ticker in tickers:
ticker_string += ticker
ticker_string += ','
#Drop the last comma from `ticker_string`
ticker_string = ticker_string[:-1]The next task that we need to handle is to select which endpoint of the IEX Cloud API that we need to ping.
我们需要处理的下一个任务是选择需要ping的IEX Cloud API端点。
A quick review of IEX Cloud's documentation reveals that they have a Historical Prices endpoint, which we can send an HTTP request to using the charts keyword.
快速浏览IEX Cloud文档会发现它们具有“ Historical Prices端点,我们可以使用charts关键字将HTTP请求发送至该端点。
We will also need to specify the amount of data that we're requesting (measured in years).
我们还需要指定所请求的数据量(以年为单位)。
To target this endpoint for the specified data range, I have stored the charts endpoint and the amount of time in separate variables. These endpoints are then interpolated into the serialized URL that we'll use to send our HTTP request.
为了将此端点作为指定数据范围的目标,我已将charts端点和时间量存储在单独的变量中。 然后将这些端点插入到用于发送HTTP请求的序列化URL中。
Here is the code:
这是代码:
#Create the endpoint and years strings
endpoints = 'chart'
years = '10'
#Interpolate the endpoint strings into the HTTP_request string
HTTP_request = f'https://cloud.iexapis.com/stable/stock/market/batch?symbols={ticker_string}&types={endpoints}&range={years}y&token={IEX_API_Key}'This interpolated string is important because it allows us to easily change our string's value at a later date without changing each occurrence of the string in our codebase.
此插值字符串很重要,因为它使我们可以在以后更改字符串的值,而无需更改代码库中字符串的每次出现。
Now it's time to actually make our HTTP request and store the data in a data structure on our local machine.
现在是时候实际发出我们的HTTP请求并将数据存储在本地计算机上的数据结构中了。
To do this, I am going to use the pandas library for Python. Specifically, the data will be stored in a pandas DataFrame.
为此,我将使用Python的pandas库。 具体来说,数据将存储在pandas DataFrame中 。
We will first need to import the pandas library. By convention, pandas is typically imported under the alias pd. Add the following code to the start of your script to import pandas under the desired alias:
我们首先需要导入pandas库。 按照惯例,通常以别名pd导入熊猫。 将以下代码添加到脚本的开头,以使用所需的别名导入熊猫:
import pandas as pdOnce we have imported pandas into our Python script, we can use its read_json method to store the data from IEX Cloud into a pandas DataFrame:
将熊猫导入到Python脚本后,我们可以使用其read_json方法将来自IEX Cloud的数据存储到熊猫DataFrame中:
bank_data = pd.read_json(HTTP_request)Printing this DataFrame inside of a Jupyter Notebook generates the following output:
在Jupyter Notebook内部打印此DataFrame会产生以下输出:
It is clear that this is not what we want. We will need to parse this data to generate a DataFrame that's worth plotting.
显然,这不是我们想要的。 我们将需要解析此数据以生成值得绘制的DataFrame。
To start, let's examine a specific column of bank_data - say, bank_data['JPM']:
首先,让我们检查bank_data的特定列-例如bank_data['JPM'] :
It's clear that the next parsing layer will need to be the chart endpoint:
显然,下一个解析层将需要成为chart端点:
Now we have a JSON-like data structure where each cell is a date along with various data points about JPM's stock price on that date.
现在,我们有了一个类似于JSON的数据结构,其中每个单元格都是一个日期,以及有关该日期JPM股价的各种数据点。
We can wrap this JSON-like structure in a pandas DataFrame to make it much more readable:
我们可以将此类似JSON的结构包装在pandas DataFrame中,以使其更具可读性:
This is something we can work with!
这是我们可以合作的东西!
Let's write a small loop that uses similar logic to pull out the closing price time series for each stock as a pandas Series (which is equivalent to a column of a pandas DataFrame). We will store these pandas Series in a dictionary (with the key being the ticker name) for easy access later.
让我们编写一个小循环,该循环使用类似的逻辑将每个股票的收盘价时间序列作为pandas系列 (等效于pandas DataFrame的一列)。 我们将这些熊猫系列存储在字典中(键为股票代码名称),以便以后使用。
for ticker in tickers:
series_dict.update( {ticker : pd.DataFrame(bank_data[ticker]['chart'])['close']} )Now we can create our finalized pandas DataFrame that has the date as its index and a column for the closing price of every major bank stock over the last 5 years:
现在,我们可以创建最终的pandas DataFrame,该数据以日期为索引,并以列表示过去五年中每个主要银行股票的收盘价:
series_list = []
for ticker in tickers:
series_list.append(pd.DataFrame(bank_data[ticker]['chart'])['close'])
series_list.append(pd.DataFrame(bank_data['JPM']['chart'])['date'])
column_names = tickers.copy()
column_names.append('Date')
bank_data = pd.concat(series_list, axis=1)
bank_data.columns = column_names
bank_data.set_index('Date', inplace = True)After all this is done, our bank_data DataFrame will look like this:
完成所有这些操作后,我们的bank_data DataFrame将如下所示:
Our data collection is complete. We are now ready to begin creating visualizations with this data set of stock prices for publicly-traded banks. As a quick recap, here's the script we have built so far:
我们的数据收集完成。 现在,我们准备开始使用该公开交易的银行股票价格数据集创建可视化。 快速回顾一下,这是到目前为止我们构建的脚本:
import pandas as pd
import matplotlib.pyplot as plt
IEX_API_Key = ''
tickers = [
'JPM',
'BAC',
'C',
'WFC',
'GS',
]
#Create an empty string called `ticker_string` that we'll add tickers and commas to
ticker_string = ''
#Loop through every element of `tickers` and add them and a comma to ticker_string
for ticker in tickers:
ticker_string += ticker
ticker_string += ','
#Drop the last comma from `ticker_string`
ticker_string = ticker_string[:-1]
#Create the endpoint and years strings
endpoints = 'chart'
years = '5'
#Interpolate the endpoint strings into the HTTP_request string
HTTP_request = f'https://cloud.iexapis.com/stable/stock/market/batch?symbols={ticker_string}&types={endpoints}&range={years}y&cache=true&token={IEX_API_Key}'
#Send the HTTP request to the IEX Cloud API and store the response in a pandas DataFrame
bank_data = pd.read_json(HTTP_request)
#Create an empty list that we will append pandas Series of stock price data into
series_list = []
#Loop through each of our tickers and parse a pandas Series of their closing prices over the last 5 years
for ticker in tickers:
series_list.append(pd.DataFrame(bank_data[ticker]['chart'])['close'])
#Add in a column of dates
series_list.append(pd.DataFrame(bank_data['JPM']['chart'])['date'])
#Copy the 'tickers' list from earlier in the script, and add a new element called 'Date'.
#These elements will be the column names of our pandas DataFrame later on.
column_names = tickers.copy()
column_names.append('Date')
#Concatenate the pandas Series together into a single DataFrame
bank_data = pd.concat(series_list, axis=1)
#Name the columns of the DataFrame and set the 'Date' column as the index
bank_data.columns = column_names
bank_data.set_index('Date', inplace = True)步骤2:建立您要更新的图表 (Step 2: Create the Chart You'd Like to Update)
In this tutorial, we'll be working with the matplotlib visualization library for Python.
在本教程中,我们将使用用于Python的matplotlib可视化库。
Matplotlib is a tremendously sophisticated library and people spend years mastering it to their fullest extent. Accordingly, please keep in mind that we are only scratching the surface of matplotlib's capabilities in this tutorial.
Matplotlib是一个非常复杂的库,人们花了很多年才能完全掌握它。 因此,请记住,本教程仅涉及matplotlib功能的表面。
We will start by importing the matplotlib library.
我们将从导入matplotlib库开始。
如何导入Matplotlib (How to Import Matplotlib)
By convention, data scientists generally import the pyplot library of matplotlib under the alias plt.
按照惯例,数据科学家通常以别名plt导入matplotlib的pyplot库。
Here's the full import statement:
这是完整的导入语句:
import matplotlib.pyplot as pltYou will need to include this at the beginning of any Python file that uses matplotlib to generate data visualizations.
您将需要在使用matplotlib生成数据可视化效果的任何Python文件的开头包含此内容。
There are also other arguments that you can add with your matplotlib library import to make your visualizations easier to work with.
您还可以在matplotlib库导入中添加其他参数,以使可视化更易于使用。
If you're working through this tutorial in a Jupyter Notebook, you may want to include the following statement, which will cause your visualizations to appear without needing to write a plt.show() statement:
如果您正在Jupyter Notebook中完成本教程,则可能需要包含以下语句,这将导致可视化显示而无需编写plt.show()语句:
%matplotlib inlineIf you're working in a Jupyter Notebook on a MacBook with a retina display, you can use the following statements to improve the resolution of your matplotlib visualizations in the notebook:
如果您在带视网膜显示屏的MacBook上的Jupyter笔记本中工作,则可以使用以下语句来提高笔记本中matplotlib可视化效果的分辨率:
from IPython.display import set_matplotlib_formats
set_matplotlib_formats('retina')With that out of the way, let's begin creating our first data visualizations using Python and matplotlib!
有了这一点,让我们开始使用Python和matplotlib创建第一个数据可视化!
Matplotlib格式化基础 (Matplotlib Formatting Fundamentals)
In this tutorial, you will learn how to create boxplots, scatterplots, and histograms in Python using matplotlib. I want to go through a few basics of formatting in matplotlib before we begin creating real data visualizations.
在本教程中,您将学习如何使用matplotlib在Python中创建框线图,散点图和直方图。 在开始创建实际的数据可视化之前,我想了解一下matplotlib中的一些格式化基础知识。
First, almost everything you do in matplotlib will involve invoking methods on the plt object, which is the alias that we imported matplotlib as.
首先,您在matplotlib中所做的几乎所有操作都会涉及调用plt对象上的方法,该对象是我们导入matplotlib的别名。
Second, you can add titles to matplotlib visualizations by calling plt.title() and passing in your desired title as a string.
其次,您可以通过调用plt.title()并将所需的标题作为字符串传递到matplotlib可视化中添加标题。
Third, you can add labels to your x and y axes using the plt.xlabel() and plt.ylabel() methods.
第三,您可以使用plt.xlabel()和plt.ylabel()方法向x和y轴添加标签。
Lastly, with the three methods we just discussed - plt.title(), plt.xlabel(), and plt.ylabel() - you can change the font size of the title with the fontsize argument.
最后,使用我们刚刚讨论的三种方法plt.title() , plt.xlabel()和plt.ylabel() ,您可以使用fontsize参数更改标题的字体大小。
Let's dig in to creating our first matplotlib visualizations in earnest.
让我们深入研究如何创建我们的第一个matplotlib可视化。
如何在Matplotlib中创建Boxplots (How to Create Boxplots in Matplotlib)
Boxplots are one of the most fundamental data visualizations available to data scientists.
箱线图是数据科学家可用的最基本的数据可视化之一。
Matplotlib allows us to create boxplots with the boxplot function.
Matplotlib允许我们使用boxplot函数创建盒boxplot 。
Since we will be creating boxplots along our columns (and not along our rows), we will also want to transpose our DataFrame inside the boxplot method call.
由于我们将沿着列(而不是沿着行)创建框线boxplot ,因此,我们也想将我们的DataFrame换位到boxplot方法调用内。
plt.boxplot(bank_data.transpose())This is a good start, but we need to add some styling to make this visualization easily interpretatable to an outside user.
这是一个很好的开始,但是我们需要添加一些样式,以使此可视化易于外部用户解释。
First, let's add a chart title:
首先,让我们添加一个图表标题:
plt.title('Boxplot of Bank Stock Prices (5Y Lookback)', fontsize = 20)In addition, it is useful to label the x and y axes, as mentioned previously:
另外,如前所述,标记x和y轴很有用:
plt.xlabel('Bank', fontsize = 20)
plt.ylabel('Stock Prices', fontsize = 20)We will also need to add column-specific labels to the x-axis so that it is clear which boxplot belongs to each bank.
我们还需要在x轴上添加列特定的标签,以便清楚地知道每个盒属于哪个箱线图。
The following code does the trick:
以下代码可以解决问题:
ticks = range(1, len(bank_data.columns)+1)
labels = list(bank_data.columns)
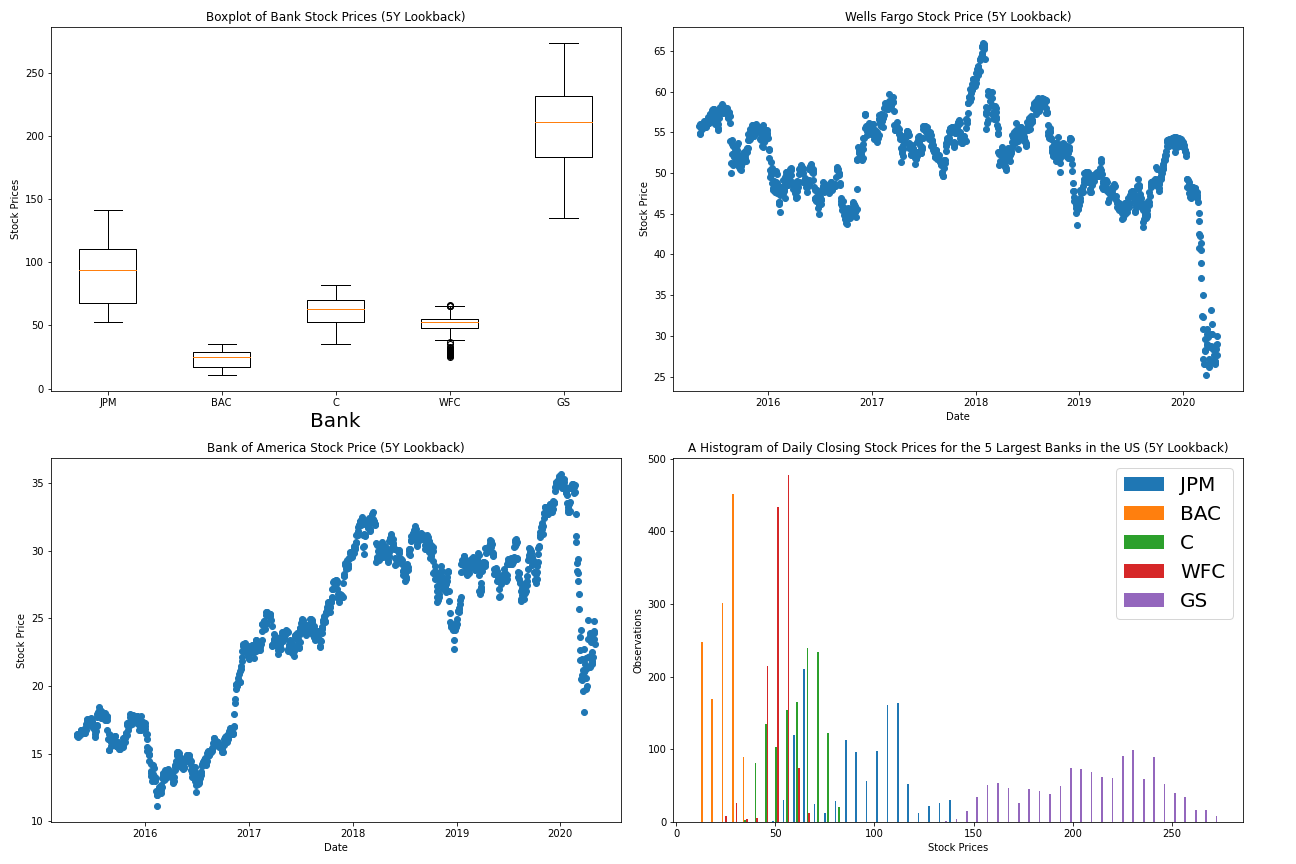
plt.xticks(ticks,labels, fontsize = 20)Just like that, we have a boxplot that presents some useful visualizations in matplotlib! It is clear that Goldman Sachs has traded at the highest price over the last 5 years while Bank of America's stock has traded the lowest. It's also interesting to note that Wells Fargo has the most outlier data points.
就像这样,我们有一个箱线图,在matplotlib中提供了一些有用的可视化效果! 显然,高盛在过去5年中的交易价格最高,而美国银行的股价却最低。 还值得注意的是,富国银行的数据点最为离群。
As a recap, here is the complete code that we used to generate our boxplots:
作为回顾,这是我们用来生成箱形图的完整代码:
########################
#Create a Python boxplot
########################
#Set the size of the matplotlib canvas
plt.figure(figsize = (18,12))
#Generate the boxplot
plt.boxplot(bank_data.transpose())
#Add titles to the chart and axes
plt.title('Boxplot of Bank Stock Prices (5Y Lookback)', fontsize = 20)
plt.xlabel('Bank', fontsize = 20)
plt.ylabel('Stock Prices', fontsize = 20)
#Add labels to each individual boxplot on the canvas
ticks = range(1, len(bank_data.columns)+1)
labels = list(bank_data.columns)
plt.xticks(ticks,labels, fontsize = 20)如何在Matplotlib中创建散点图 (How to Create Scatterplots in Matplotlib)
Scatterplots can be created in matplotlib using the plt.scatter method.
可以使用plt.scatter方法在matplotlib中创建散点图 。
The scatter method has two required arguments - an x value and a y value.
scatter方法具有两个必需的参数x值和y值。
Let's plot Wells Fargo's stock price over time using the plt.scatter() method.
让我们使用plt.scatter()方法绘制富国银行的股价随时间变化的曲线图。
The first thing we need to do is to create our x-axis variable, called dates:
我们需要做的第一件事是创建我们的x轴变量,称为dates :
dates = bank_data.index.to_series()Next, we will isolate Wells Fargo's stock prices in a separate variable:
接下来,我们将在一个单独的变量中隔离富国银行的股价:
WFC_stock_prices = bank_data['WFC']We can now plot the visualization using the plt.scatter method:
现在,我们可以使用plt.scatter方法绘制可视化plt.scatter :
plt.scatter(dates, WFC_stock_prices)Wait a minute - the x labels of this chart are impossible to read!
请稍等-此图表的x标签无法阅读!
What is the problem?
问题是什么?
Well, matplotlib is not currently recognizing that the x axis contains dates, so it isn't spacing out the labels properly.
好吧,matplotlib当前无法识别x轴包含日期,因此无法正确分隔标签。
To fix this, we need to transform every element of the dates Series into a datetime data type. The following command is the most readable way to do this:
要解决此问题,我们需要将dates系列的每个元素转换为datetime数据类型。 以下命令是最易读的方法:
dates = bank_data.index.to_series()
dates = [pd.to_datetime(d) for d in dates]After running the plt.scatter method again, you will generate the following visualization:
再次运行plt.scatter方法后,将生成以下可视化文件:
Much better!
好多了!
Our last step is to add titles to the chart and the axis. We can do this with the following statements:
我们的最后一步是向图表和轴添加标题。 我们可以使用以下语句来做到这一点:
plt.title("Wells Fargo Stock Price (5Y Lookback)", fontsize=20)
plt.ylabel("Stock Price", fontsize=20)
plt.xlabel("Date", fontsize=20)As a recap, here's the code we used to create this scatterplot:
回顾一下,这是我们用来创建散点图的代码:
########################
#Create a Python scatterplot
########################
#Set the size of the matplotlib canvas
plt.figure(figsize = (18,12))
#Create the x-axis data
dates = bank_data.index.to_series()
dates = [pd.to_datetime(d) for d in dates]
#Create the y-axis data
WFC_stock_prices = bank_data['WFC']
#Generate the scatterplot
plt.scatter(dates, WFC_stock_prices)
#Add titles to the chart and axes
plt.title("Wells Fargo Stock Price (5Y Lookback)", fontsize=20)
plt.ylabel("Stock Price", fontsize=20)
plt.xlabel("Date", fontsize=20)如何在Matplotlib中创建直方图 (How to Create Histograms in Matplotlib)
Histograms are data visualizations that allow you to see the distribution of observations within a data set.
直方图是数据可视化,可让您查看数据集中的观测值分布。
Histograms can be created in matplotlib using the plt.hist method.
可以使用plt.hist方法在matplotlib中创建直方图。
Let's create a histogram that allows us to see the distribution of different stock prices within our bank_data dataset (note that we'll need to use the transpose method within plt.hist just like we did with plt.boxplot earlier):
让我们创建一个直方图,使我们能够查看bank_data数据集中不同股票价格的分布(请注意,就像我们之前对plt.boxplot所做的一样,我们需要在plt.hist使用transpose方法):
plt.hist(bank_data.transpose())This is an interesting visualization, but we still have lots to do.
这是一个有趣的可视化,但是我们还有很多工作要做。
The first thing you probably noticed was that the different columns of the histogram have different colors. This is intentional. The colors divide the different columns within our pandas DataFrame.
您可能注意到的第一件事是直方图的不同列具有不同的颜色。 这是故意的。 颜色划分了我们的熊猫DataFrame中的不同列。
With that said, these colors are meaningless without a legend. We can add a legend to our matplotlib histogram with the following statement:
话虽如此,这些颜色没有传说就毫无意义。 我们可以使用以下语句将图例添加到matplotlib直方图中:
plt.legend(bank_data.columns,fontsize=20)You may also want to change the bin count of the histogram, which changes how many slices the dataset is divided into when goruping the observations into histogram columns.
您可能还需要更改直方图的bin count ,当将观测值放入直方图列时,它会更改数据集分为多少个切片。
As an example, here is how to change the number of bins in the histogram to 50:
例如,以下是如何将直方图中的bins数量更改为50 :
plt.hist(bank_data.transpose(), bins = 50)Lastly, we will add titles to the histogram and its axes using the same statements that we used in our other visualizations:
最后,我们将使用与其他可视化效果相同的语句向直方图及其轴添加标题:
plt.title("A Histogram of Daily Closing Stock Prices for the 5 Largest Banks in the US (5Y Lookback)", fontsize = 20)
plt.ylabel("Observations", fontsize = 20)
plt.xlabel("Stock Prices", fontsize = 20)As a recap, here is the complete code needed to generate this histogram:
回顾一下,这是生成此直方图所需的完整代码:
########################
#Create a Python histogram
########################
#Set the size of the matplotlib canvas
plt.figure(figsize = (18,12))
#Generate the histogram
plt.hist(bank_data.transpose(), bins = 50)
#Add a legend to the histogram
plt.legend(bank_data.columns,fontsize=20)
#Add titles to the chart and axes
plt.title("A Histogram of Daily Closing Stock Prices for the 5 Largest Banks in the US (5Y Lookback)", fontsize = 20)
plt.ylabel("Observations", fontsize = 20)
plt.xlabel("Stock Prices", fontsize = 20)如何在Matplotlib中创建子图 (How to Create Subplots in Matplotlib)
In matplotlib, subplots are the name that we use to refer to multiple plots that are created on the same canvas using a single Python script.
在matplotlib中, 子图是我们用来引用使用单个Python脚本在同一画布上创建的多个图的名称。
Subplots can be created with the plt.subplot command. The command takes three arguments:
可以使用plt.subplot命令创建plt.subplot 。 该命令采用三个参数:
- The number of rows in a subplot grid 子图网格中的行数
- The number of columns in a subplot grid 子图网格中的列数
- Which subplot you currently have selected 您当前选择了哪个子图
Let's create a 2x2 subplot grid that contains the following charts (in this specific order):
让我们创建一个2x2子图网格,其中包含以下图表(按此特定顺序):
- The boxplot that we created previously 我们之前创建的箱线图
- The scatterplot that we created previously 我们之前创建的散点图
A similar scatteplot that uses
BACdata instead ofWFCdata使用
BAC数据而不是WFC数据的类似脚本- The histogram that we created previously 我们之前创建的直方图
First, let's create the subplot grid:
首先,让我们创建子图网格:
plt.subplot(2,2,1)
plt.subplot(2,2,2)
plt.subplot(2,2,3)
plt.subplot(2,2,4)Now that we have a blank subplot canvas, we simply need to copy/paste the code we need for each plot after each call of the plt.subplot method.
现在我们有了一个空白的子图画布,我们只需要在每次调用plt.subplot方法之后复制/粘贴每个图所需的代码plt.subplot 。
At the end of the code block, we add the plt.tight_layout method, which fixes many common formatting issues that occur when generating matplotlib subplots.
在代码块的末尾,我们添加了plt.tight_layout方法,该方法解决了生成matplotlib子图时发生的许多常见格式设置问题。
Here is the full code:
这是完整的代码:
################################################
################################################
#Create subplots in Python
################################################
################################################
########################
#Subplot 1
########################
plt.subplot(2,2,1)
#Generate the boxplot
plt.boxplot(bank_data.transpose())
#Add titles to the chart and axes
plt.title('Boxplot of Bank Stock Prices (5Y Lookback)')
plt.xlabel('Bank', fontsize = 20)
plt.ylabel('Stock Prices')
#Add labels to each individual boxplot on the canvas
ticks = range(1, len(bank_data.columns)+1)
labels = list(bank_data.columns)
plt.xticks(ticks,labels)
########################
#Subplot 2
########################
plt.subplot(2,2,2)
#Create the x-axis data
dates = bank_data.index.to_series()
dates = [pd.to_datetime(d) for d in dates]
#Create the y-axis data
WFC_stock_prices = bank_data['WFC']
#Generate the scatterplot
plt.scatter(dates, WFC_stock_prices)
#Add titles to the chart and axes
plt.title("Wells Fargo Stock Price (5Y Lookback)")
plt.ylabel("Stock Price")
plt.xlabel("Date")
########################
#Subplot 3
########################
plt.subplot(2,2,3)
#Create the x-axis data
dates = bank_data.index.to_series()
dates = [pd.to_datetime(d) for d in dates]
#Create the y-axis data
BAC_stock_prices = bank_data['BAC']
#Generate the scatterplot
plt.scatter(dates, BAC_stock_prices)
#Add titles to the chart and axes
plt.title("Bank of America Stock Price (5Y Lookback)")
plt.ylabel("Stock Price")
plt.xlabel("Date")
########################
#Subplot 4
########################
plt.subplot(2,2,4)
#Generate the histogram
plt.hist(bank_data.transpose(), bins = 50)
#Add a legend to the histogram
plt.legend(bank_data.columns,fontsize=20)
#Add titles to the chart and axes
plt.title("A Histogram of Daily Closing Stock Prices for the 5 Largest Banks in the US (5Y Lookback)")
plt.ylabel("Observations")
plt.xlabel("Stock Prices")
plt.tight_layout()As you can see, with some basic knowledge it is relatively easy to create beautiful data visualizations using matplotlib.
如您所见,有了一些基本知识,使用matplotlib创建漂亮的数据可视化相对容易。
The last thing we need to do is save the visualization as a .png file in our current working directory. Matplotlib has excellent built-in functionality to do this. Simply add the follow statement immediately after the fourth subplot is finalized:
我们需要做的最后一件事是将可视化文件保存为当前工作目录中的.png文件。 Matplotlib具有出色的内置功能来执行此操作。 只需在完成第四个子图后立即添加以下语句:
################################################
#Save the figure to our local machine
################################################
plt.savefig('bank_data.png')Over the remainder of this tutorial, you will learn how to schedule this subplot matrix to be automatically updated on your live website every day.
在本教程的其余部分,您将学习如何安排该子图矩阵每天在您的实时网站上自动更新。
步骤3:创建一个Amazon Web Services帐户 (Step 3: Create an Amazon Web Services Account)
So far in this tutorial, we have learned how to:
到目前为止,在本教程中,我们已经学习了如何:
- Source the stock market data that we are going to visualize from the IEX Cloud API 从IEX Cloud API中获取我们将要可视化的股市数据
- Create wonderful visualizations using this data with the matplotlib library for Python 使用此数据和适用于Python的matplotlib库创建精彩的可视化
Over the remainder of this tutorial, you will learn how to automate these visualizations such that they are updated on a specific schedule.
在本教程的其余部分中,您将学习如何自动化这些可视化文件,以便按特定的时间表进行更新。
To do this, we'll be using the cloud computing capabilities of Amazon Web Services. You'll need to create an AWS account first.
为此,我们将使用Amazon Web Services的云计算功能。 您需要首先创建一个AWS账户。
Navigate to this URL and click the "Create an AWS Account" in the top-right corner:
导航到此URL ,然后单击右上角的“创建AWS账户”:
AWS' web application will guide you through the steps to create an account.
AWS的Web应用程序将指导您完成创建帐户的步骤。
Once your account has been created, we can start working with the two AWS services that we'll need for our visualizations: AWS S3 and AWS EC2.
创建您的帐户后,我们就可以使用可视化所需的两个AWS服务:AWS S3和AWS EC2。
步骤4:创建AWS S3存储桶以存储可视化内容 (Step 4: Create an AWS S3 Bucket to Store Your Visualizations)
AWS S3 stands for Simple Storage Service. It is one of the most popular cloud computing offerings available in Amazon Web Services. Developers use AWS S3 to store files and access them later through public-facing URLs.
AWS S3代表简单存储服务。 它是Amazon Web Services中最流行的云计算产品之一。 开发人员使用AWS S3存储文件,并稍后通过面向公众的URL访问它们。
To store these files, we must first create what is called an AWS S3 bucket, which is a fancy word for a folder that stores files in AWS. To do this, first navigate to the S3 dashboard within Amazon Web Services.
要存储这些文件,我们必须首先创建所谓的AWS S3 bucket ,这是在AWS中存储文件的文件夹的花哨词。 为此,请首先导航到Amazon Web Services中的S3仪表板。
On the right side of the Amazon S3 dashboard, click Create bucket, as shown below:
在Amazon S3仪表板的右侧,单击Create bucket ,如下所示:
On the next screen, AWS will ask you to select a name for your new S3 bucket. For the purpose of this tutorial, we will use the bucket name nicks-first-bucket.
在下一个屏幕上,AWS将要求您为新的S3存储桶选择一个名称。 就本教程而言,我们将使用存储桶名称nicks-first-bucket 。
Next, you will need to scroll down and set your bucket permissions. Since the files we will be uploading are designed to be publicly accessible (after all, we will be embedding them in pages on a website), then you will want to make the permissions as open as possible.
接下来,您需要向下滚动并设置存储桶权限。 由于我们将要上传的文件被设计为可公开访问(毕竟,我们将它们嵌入到网站的页面中),因此您将需要使权限尽可能开放。
Here is a specific example of what your AWS S3 permissions should look like:
这是您的AWS S3权限应显示为以下形式的特定示例:
These permissions are very lax, and for many use cases are not acceptable (though they do indeed meet the requirements of this tutorial). Because of this, AWS will require you to acknowledge the following warning before creating your AWS S3 bucket:
这些权限非常宽松,在许多用例中都是不可接受的(尽管它们确实符合本教程的要求)。 因此,AWS将要求您在创建AWS S3存储桶之前确认以下警告:
Once all of this is done, you can scroll to the bottom of the page and click Create Bucket. You are now ready to proceed!
完成所有这些操作后,您可以滚动到页面底部,然后点击Create Bucket 。 您现在可以继续了!
步骤5:修改Python脚本以将可视化文件保存到AWS S3 (Step 5: Modify the Python Script to Save Your Visualizations to AWS S3)
Our Python script in its current form is designed to create a visualization and then save that visualization to our local computer. We now need to modify our script to instead save the .png file to the AWS S3 bucket we just created (which, as a reminder, is called nicks-first-bucket).
当前形式的Python脚本旨在创建可视化,然后将该可视化保存到我们的本地计算机。 现在,我们需要修改脚本,以将.png文件保存到我们刚创建的AWS S3存储桶中(提醒一下, nicks-first-bucket称为nicks-first-bucket )。
The tool that we will use to upload our file to our AWS S3 bucket is called boto3, which is Amazon Web Services Software Development Kit (SDK) for Python.
我们用于将文件上传到AWS S3存储桶的工具称为boto3 ,它是适用于Python的Amazon Web服务软件开发套件(SDK)。
First, you'll need to install boto3 on your machine. The easiest way to do this is using the pip package manager:
首先,您需要在boto3上安装boto3 。 最简单的方法是使用pip包管理器:
pip3 install boto3Next, we need to import boto3 into our Python script. We do this by adding the following statement near the start of our script:
接下来,我们需要将boto3导入我们的Python脚本中。 为此,我们在脚本的开头附近添加了以下语句:
import boto3Given the depth and breadth of Amazon Web Services' product offerings, boto3 is an insanely complex Python library.
鉴于Amazon Web Services产品的深度和广度, boto3是一个非常复杂的Python库。
Fortunately, we only need to use some of the most basic functionality of boto3.
幸运的是,我们只需要使用boto3一些最基本的功能。
The following code block will upload our final visualization to Amazon S3.
以下代码块将最终的可视化效果上传到Amazon S3。
################################################
#Push the file to the AWS S3 bucket
################################################
s3 = boto3.resource('s3')
s3.meta.client.upload_file('bank_data.png', 'nicks-first-bucket', 'bank_data.png', ExtraArgs={'ACL':'public-read'})As you can see, the upload_file method of boto3 takes several arguments. Let's break them down, one-by-one:
如您所见, boto3的upload_file方法boto3多个参数。 让我们一一分解它们:
bank_data.pngis the name of the file on our local machine.bank_data.png是我们本地计算机上文件的名称。nicks-first-bucketis the name of the S3 bucket that we want to upload to.nicks-first-bucket是我们要上传到的S3存储桶的名称。bank_data.pngis the name that we want the file to have after it is uploaded to the AWS S3 bucket. In this case, it is the same as the first argument, but it doesn't have to be.bank_data.png是文件上传到AWS S3存储桶后我们想要的名称。 在这种情况下,它与第一个参数相同,但不必如此。ExtraArgs={'ACL':'public-read'}means that the file should be readable by the public once it is pushed to the AWS S3 bucket.ExtraArgs={'ACL':'public-read'}意味着文件一旦被推送到AWS S3存储桶,便应被公众读取。
Running this code now will result in an error. Specifically, Python will throw the following exception:
现在运行此代码将导致错误。 具体来说,Python将引发以下异常:
S3UploadFailedError: Failed to upload bank_data.png to nicks-first-bucket/bank_data.png: An error occurred (NoSuchBucket) when calling the PutObject operation: The specified bucket does not existWhy is this?
为什么是这样?
Well, it is because we have not yet configured our local machine to interact with Amazon Web Services through boto3.
好吧,这是因为我们尚未将本地计算机配置为通过boto3与Amazon Web Services进行boto3 。
To do this, we must run the aws configure command from our command line interface and add our access keys. This documentation piece from Amazon shares more information about how to configure your AWS command line interface.
为此,我们必须从命令行界面运行aws configure命令并添加访问密钥。 来自Amazon的该文档片断分享了有关如何配置AWS命令行界面的更多信息。
If you'd rather not navigate off freecodecamp.org, here are the quick steps to set up your AWS CLI.
如果您不想离开freecodecamp.org,那么这里是设置AWS CLI的快速步骤。
First, mouse over your username in the top right corner, like this:
首先,将鼠标悬停在右上角的用户名上,如下所示:
Click My Security Credentials.
单击My Security Credentials 。
On the next screen, you're going to want to click the Access keys (access key ID and secret access key drop down, then click Create New Access Key.
在下一个屏幕上,您将要单击Access keys (access key ID and secret access key下拉菜单,然后单击Create New Access Key 。
This will prompt you to download a .csv file that contains both your Access Key and your Secret Access Key. Save these in a secure location.
这将提示您下载同时包含访问密钥和秘密访问密钥的.csv文件。 将它们保存在安全的位置。
Next, trigger the Amazon Web Services command line interface by typing aws configure on your command line. This will prompt you to enter your Access Key and Secret Access Key.
接下来,通过在命令行上输入aws configure来触发Amazon Web Services命令行界面。 这将提示您输入访问密钥和秘密访问密钥。
Once this is done, your script should function as intended. Re-run the script and check to make sure that your Python visualization has been properly uploaded to AWS S3 by looking inside the bucket we created earlier:
完成此操作后,您的脚本应会按预期运行。 重新运行脚本,然后通过查看我们之前创建的存储桶,检查以确保您的Python可视化文件已正确上传到AWS S3:
The visualization has been uploaded successfully. We are now ready to embed the visualization on our website!
可视化文件已成功上传。 现在,我们准备将可视化内容嵌入我们的网站!
步骤6:将可视化内容嵌入您的网站 (Step 6: Embed the Visualization on Your Website)
Once the data visualization has been uploaded to AWS S3, you will want to embed the visualization somewhere on your website. This could be in a blog post or any other page on your site.
将数据可视化文件上传到AWS S3后,您将需要将可视化文件嵌入网站中的某个位置。 这可以在博客文章中或您网站上的任何其他页面中。
To do this, we will need to grab the URL of the image from our S3 bucket. Click the name of the image within the S3 bucket to navigate to the file-specific page for that item. It will look like this:
为此,我们需要从S3存储桶中获取图像的URL。 单击S3存储桶中的图像名称,以导航到该项目的文件特定页面。 它看起来像这样:
If you scroll to the bottom of the page, there will be a field called Object URL that looks like this:
如果滚动到页面底部,将出现一个名为Object URL的字段,如下所示:
https://nicks-first-bucket.s3.us-east-2.amazonaws.com/bank_data.pngIf you copy and paste this URL into a web browser, it will actually download the bank_data.png file that we uploaded earlier!
如果您将此URL复制并粘贴到网络浏览器中,它将实际上下载我们之前上传的bank_data.png文件!
To embed this image onto a web page, you will want to pass it into an HTML img tag as the src attribute. Here is how we would embed our bank_data.png image into a web page using HTML:
要将此图像嵌入到网页上,您需要将其作为src属性传递到HTML img标签中。 这是我们如何使用HTML将bank_data.png图像嵌入到网页中的方法:
Note: In a real image embedded on a website, it would be important to include an alt tag for accessibility purposes.
注意 :在嵌入网站的真实图像中,包含alt标签对于可访问性非常重要。
In the next section, we'll learn how to schedule our Python script to run periodically so that the data in bank_data.png is always up-to-date.
在下一节中,我们将学习如何安排Python脚本定期运行,以便bank_data.png中的数据bank_data.png是最新的。
步骤7:创建一个AWS EC2实例 (Step 7: Create an AWS EC2 Instance)
We will use AWS EC2 to schedule our Python script to run periodically.
我们将使用AWS EC2安排Python脚本定期运行。
AWS EC2 stands for Elastic Compute Cloud and, along with S3, is one of Amazon's most popular cloud computing services.
AWS EC2代表Elastic Compute Cloud,并与S3一起是Amazon最受欢迎的云计算服务之一。
It allows you to rent small units of computing power (called instances) on computers in Amazon's data centers and schedule those computers to perform jobs for you.
它使您可以在亚马逊数据中心的计算机上租用一小部分计算能力(称为实例),并安排这些计算机为您执行工作。
AWS EC2 is a fairly remarkable service because if you rent some of their smaller computers, then you actually qualify for the AWS free tier. Said differently, diligent use of the pricing within AWS EC2 will allow you to avoid paying any money whatsoever.
AWS EC2是一项相当出色的服务,因为如果您租用了一些较小的计算机,那么您实际上就有资格获得AWS免费套餐。 换句话说,在AWS EC2中勤奋地使用定价将使您避免支付任何费用。
To start, we'll need to create our first EC2 instance. To do this, navigate to the EC2 dashboard within the AWS Management Console and click Launch Instance:
首先,我们需要创建我们的第一个EC2实例。 为此,请导航到AWS管理控制台中的EC2仪表板,然后单击Launch Instance :
This will bring you to a screen that contains all of the available instance types within AWS EC2. There is an almost unbelievable number of options here. We want an instance type that qualifies as Free tier eligible - specifically, I chose the Amazon Linux 2 AMI (HVM), SSD Volume Type:
这将带您到一个包含AWS EC2内所有可用实例类型的屏幕。 这里有几乎不可思议的选项。 我们想要一个符合Free tier eligible的实例类型-具体来说,我选择了Amazon Linux 2 AMI (HVM), SSD Volume Type :
Click Select to proceed.
单击Select继续。
On the next page, AWS will ask you to select the specifications for your machine. The fields you can select include:
在下一页上,AWS将要求您选择计算机的规格。 您可以选择的字段包括:
FamilyFamilyTypeTypevCPUsvCPUsMemoryMemoryInstance Storage (GB)Instance Storage (GB)EBS-OptimizedEBS-OptimizedNetwork PerformanceNetwork PerformanceIPv6 SupportIPv6 Support
For the purpose of this tutorial, we simply want to select the single machine that is free tier eligible. It is characterized by a small green label that looks like this:
就本教程而言,我们只想选择符合免费套餐资格的单台计算机。 它的特征是带有一个小的绿色标签,如下所示:
Click Review and Launch at the bottom of the screen to proceed.
单击屏幕底部的“ Review and Launch ”以继续。
The next screen will present the details of your new instance for you to review.
下一个屏幕将显示新实例的详细信息供您查看。
Quickly review the machine's specifications, then click Launch in the bottom right-hand corner.
快速查看机器的规格,然后单击右下角的Launch 。
Clicking the Launch button will trigger a popup that asks you to Select an existing key pair or create a new key pair.
单击Launch按钮将触发一个弹出窗口,要求您Select an existing key pair or create a new key pair 。
A key pair is comprised of a public key that AWS holds and a private key that you must download and store within a .pem file.
密钥对由AWS持有的公共密钥和必须下载并存储在.pem文件中的私有密钥组成。
You must have access to that .pem file in order to access your EC2 instance (typically via SSH). You also have the option to proceed without a key pair, but this is not recommended for security reasons.
您必须有权访问该.pem文件才能访问您的EC2实例(通常通过SSH)。 您还可以选择不使用密钥对继续进行操作,但是出于安全原因, 不建议这样做。
Once this is done, your instance will launch! Congratulations on launching your first instance on one of Amazon Web Services' most important infrastructure services.
完成后,您的实例将启动! 祝贺您在Amazon Web Services最重要的基础架构服务之一上启动您的第一个实例。
Next, you will need to push your Python script into your EC2 instance.
接下来,您将需要将Python脚本推送到EC2实例中。
Here is a generic command state statement that allows you to move a file into an EC2 instance:
这是一条通用的命令状态语句,它使您可以将文件移动到EC2实例中:
scp -i path/to/.pem_file path/to/file username@host_address.amazonaws.com:/path_to_copyRun this statement with the necessary replacements to move bank_stock_data.py into the EC2 instance.
运行此语句并进行必要的替换,以将bank_stock_data.py移至EC2实例中。
You might believe that you can now run your Python script from within your EC2 instance. Unfortunately, this is not the case. Your EC2 instance does not come with the necessary Python packages.
您可能会相信,现在可以从EC2实例中运行Python脚本。 不幸的是,这种情况并非如此。 您的EC2实例未随附必需的Python软件包。
To install the packages we used, you can either export a requirements.txt file and import the proper packages using pip, or you can simply run the following:
要安装我们使用的软件包,您可以导出requirements.txt文件并使用pip导入适当的软件包,也可以简单地运行以下命令:
sudo yum install python3-pip
pip3 install pandas
pip3 install boto3We are now ready to schedule our Python script to run on a periodic basis on our EC2 instance! We explore this in the next section of our article.
现在,我们准备安排Python脚本在我们的EC2实例上定期运行! 我们将在本文的下一部分中对此进行探讨。
步骤8:计划Python脚本在AWS EC2上定期运行 (Step 8: Schedule the Python script to run periodically on AWS EC2)
The only step that remains in this tutorial is to schedule our bank_stock_data.py file to run periodically in our EC2 instance.
本教程中唯一剩下的步骤就是安排bank_stock_data.py文件在我们的EC2实例中定期运行。
We can use a command-line utility called cron to do this.
我们可以使用称为cron的命令行实用程序来执行此操作。
cron works by requiring you to specify two things:
cron工作原理是要求您指定两件事:
How frequently you want a task (called a
cron job) performed, expressed via a cron expression您想要执行任务(称为
cron job)的频率,通过cron表达式表示- What needs to be executed when the cron job is scheduled 计划cron作业时需要执行什么
First, let's start by creating a cron expression.
首先,让我们开始创建一个cron表达式。
cron expressions can seem like gibberish to an outsider. For example, here's the cron expression that means "every day at noon":
对局外人来说, cron表情似乎有些胡言乱语。 例如,这是cron表达式,表示“每天中午”:
00 12 * * *I personally make use of the crontab guru website, which is an excellent resource that allows you to see (in layman's terms) what your cron expression means.
我个人使用了crontab guru网站,这是一个很好的资源,它使您能够(以通俗的方式)了解cron表达式的含义。
Here's how you can use the crontab guru website to schedule a cron job to run every Sunday at 7am:
您可以使用以下方法使用crontab guru网站来安排cron作业,使其在每个星期日的上午7点运行:
We now have a tool (crontab guru) that we can use to generate our cron expression. We now need to instruct the cron daemon of our EC2 instance to run our bank_stock_data.py file every Sunday at 7am.
现在,我们有了一个可用来生成cron表达式的工具(crontab guru)。 现在,我们需要指示EC2实例的cron守护程序在每个星期日的上午7点运行bank_stock_data.py文件。
To do this, we will first create a new file in our EC2 instance called bank_stock_data.cron. Since I use the vim text editor, the command that I use for this is:
为此,我们将首先在EC2实例中创建一个名为bank_stock_data.cron的新文件。 由于我使用vim文本编辑器,因此我使用的命令是:
vim bank_stock_data.cronWithin this .cron file, there should be one line that looks like this: (cron expression) (statement to execute). Our cron expression is 00 7 * * 7 and our statement to execute is python3 bank_stock_data.py.
在此.cron文件中,应该有一行如下所示: (cron expression) (statement to execute) 。 我们的cron表达式是00 7 * * 7 ,要执行的语句是python3 bank_stock_data.py 。
Putting it all together, and here's what the final contents of bank_stock_data.cron should be:
放在一起,这是bank_stock_data.cron的最终内容应该是:
00 7 * * 7 python3 bank_stock_data.pyThe final step of this tutorial is to import the bank_stock_data.cron file into the crontab of our EC2 instance. The crontab is essentially a file that batches together jobs for the cron daemon to perform periodically.
本教程的最后一步是将bank_stock_data.cron文件导入到我们的EC2实例的crontab中。 crontab本质上是一个文件,它将作业批处理在一起,以便cron守护程序定期执行。
Let's first take a moment to investigate that in our crontab. The following command prints the contents of the crontab to our console:
让我们先花点时间在crontab进行调查。 以下命令将crontab的内容打印到我们的控制台:
crontab -lSince we have not added anything to our crontab and we only created our EC2 instance a few moments ago, then this statement should print nothing.
由于我们尚未向crontab中添加任何内容,并且仅在几分钟前创建了EC2实例,因此该语句不输出任何内容。
Now let's import bank_stock_data.cron into the crontab. Here is the statement to do this:
现在,将bank_stock_data.cron导入crontab 。 这是执行此操作的语句:
crontab bank_stock_data.cronNow we should be able to print the contents of our crontab and see the contents of bank_stock_data.cron.
现在,我们应该能够打印crontab的内容,并查看bank_stock_data.cron的内容。
To test this, run the following command:
要对此进行测试,请运行以下命令:
crontab -lIt should print:
它应该打印:
00 7 * * 7 python3 bank_stock_data.py最后的想法 (Final Thoughts)
In this tutorial, you learned how to create beautiful data visualizations using Python and Matplotlib that update periodically. Specifically, we discussed:
在本教程中,您学习了如何使用Python和Matplotlib创建定期更新的漂亮数据可视化。 具体来说,我们讨论了:
- How to download and parse data from IEX Cloud, one of my favorite data sources for high-quality financial data 如何从IEX Cloud下载和解析数据,这是我最喜欢的高质量财务数据来源之一
- How to format data within a pandas DataFrame 如何格式化熊猫数据框内的数据
- How to create data visualizations in Python using matplotlib 如何使用Matplotlib在Python中创建数据可视化
- How to create an account with Amazon Web Services 如何使用Amazon Web Services创建帐户
- How to upload static files to AWS S3 如何将静态文件上传到AWS S3
How to embed
.pngfiles hosted on AWS S3 in pages on a website如何将AWS S3托管的
.png文件嵌入网站的页面中- How to create an AWS EC2 instance 如何创建一个AWS EC2实例
How to schedule a Python script to run periodically using AWS EC2 using
cron如何使用
cron安排Python脚本使用AWS EC2定期运行
This article was published by Nick McCullum, who teaches people how to code on his website.
这篇文章由尼克·麦卡鲁姆(Nick McCullum)发表,他教人们如何在其网站上进行编码 。
翻译自: https://www.freecodecamp.org/news/how-to-create-auto-updating-data-visualizations-in-python-with-matplotlib-and-aws/
gdb -iex