送书 | 跟我一起学《流畅的Python》
本文引自图灵新书《流畅的Python》的第一章——Python数据模型。本书由奋战在Python开发一线近20年的Luciano Ramalho执笔,Victor Stinner、Alex Martelli等Python大咖担纲技术审稿人,从语言设计层面剖析编程细节,兼顾Python 3和Python 2,告诉你Python中不亲自动手实践就无法理解的语言陷阱成因和解决之道,教你写出风格地道的Python代码。
参与方式:喜欢这本书,请在评论区留言,和大家分享你在学习Python过程中的一些经验和心得,根据评论质量和评论点赞数,前五名同学可获得本书。
书籍信息
作者:Luciano Ramalho
译者:安道 吴珂
-
PSF研究员、知名PyCon演讲者心血之作
-
Python核心开发人员担纲技术审校
-
全面深入,对Python语言关键特性剖析到位
-
大量详尽代码示例,并附有主题相关高质量参考文献和视频链接
-
兼顾Python 3和Python 2
本书致力于帮助Python开发人员挖掘这门语言及相关程序库的优秀特性,写出简洁、流畅、易读、易维护的代码。特别是深入探讨了针对数据库处理时生成器的具体应用、特性描述符(ORM的关键),以及Python式的对象:协议与接口、抽象基类及多重继承。
第 1 章 Python数据模型
Guido 对语言设计美学的深入理解让人震惊。我认识不少很不错的编程语言设计者, 他们设计出来的东西确实很精彩,但是从来都不会有用户。Guido 知道如何在理论上做出一定妥协,设计出来的语言让使用者觉得如沐春风,这真是不可多得。1
——Jim HuguninJython 的作者,AspectJ 的作者之一,.NET DLR 架构师
Python 最好的品质之一是一致性。当你使用Python 工作一会儿后,就会开始理解Python 语言,并能正确猜测出对你来说全新的语言特征。
然而,如果你带着来自其他面向对象语言的经验进入Python 的世界,会对len(colle-citon) 而不是collection.len() 写法觉得不适。当你进一步理解这种不适感背后的原因之后,会发现这个原因,和它所代表的庞大的设计思想,是形成我们通常说的“Python 风格”(Pythonic)的关键。这种设计思想完全体现在Python 的数据模型上,而数据模型所描述的API,为使用最地道的语言特性来构建你自己的对象提供了工具。
数据模型其实是对Python 框架的描述,它规范了这门语言自身构建模块的接口,这些模块包括但不限于序列、迭代器、函数、类和上下文管理器。
注1:摘自“Story of Jython”(http://hugunin.net/story_of_jython.html),这是Jython Essentials(Samuele Pedroni 和Noel Rappin 著,O’Reilly 出版社,2002 年)一书的序。
不管在哪种框架下写程序,都会花费大量时间去实现那些会被框架本身调用的方法,Python 也不例外。Python 解释器碰到特殊的句法时,会使用特殊方法去激活一些基本的对象操作,这些特殊方法的名字以两个下划线开头,以两个下划线结尾(例如__getitem__)。比如obj[key] 的背后就是__getitem__ 方法,为了能求得my_collection[key] 的值,解释器实际上会调用my_collection.__getitem__(key)。
这些特殊方法名能让你自己的对象实现和支持以下的语言构架,并与之交互:
-
迭代
-
集合类
-
属性访问
-
运算符重载
-
函数和方法的调用
-
对象的创建和销毁
-
字符串表示形式和格式化
-
管理上下文(即with 块)
magic 和dunder
魔术方法(magicmethod)是特殊方法的昵称。有些Python开发者在提到__getitem__这个特殊方法的时候,会用诸如“下划线-下划线- getitem”2 这种说法,但是显然这种说法会引起歧义,因为像__x 这种命名在Python 里还有其他含义,3 但是如果完整地说出“下划线-下划线- getitem -下划线- 下划线”,又会很麻烦。于是我跟着Steve Holden,一位技术书作者和老师, 学会了“双下- getitem”(dunder-getitem)这种说法。于是乎,特殊方法也叫双下方法(dundermethod)。4
注2:即under-under-getitme 的直译。——译者注
注3:详见9.7 节。
注4: 我是从SteveHolden 那里第一次听说dunder这个说法的。根据维基百科的解释,MarkJohnson 和TimeHochberg 是最早在书写中开始使用这个词的人(https://en.wikipedia.org/wiki/Reserved_word#Reserved_ranges)。那是2002年9月26日,他们两人在邮件列表里回复“__( 双下划线)怎么念?”这个问题时提到了dunder,最先回复的是Johnson(https://mail.python.org/pipermail/python-list/2002-September/112991.html), 11 分钟后Hochberg 也回复了(https://mail.python.org/pipermail/python-list/2002-September/114716.html)
1.1 一摞Python风格的纸牌
接下来我会用一个非常简单的例子来展示如何实现__getitme__和__len__ 这两个特殊方法,通过这个例子我们也能见识到特殊方法的强大。
示例1-1里的代码建立了一个纸牌类。
示例1-1 一摞有序的纸牌
import collections
Card = collections.namedtuple('Card',['rank', 'suit'])
class FrenchDeck:
ranks = [str(n) for n inrange(2, 11)] + list('JQKA')
suits = 'spades diamonds clubshearts'.split()
def __init__(self):
self._cards = [Card(rank, suit)for suit in self.suits
for rank in self.ranks]
def __len__(self):
return len(self._cards)
def __getitem__(self,position):
return self._cards[position]
首先,我们用collections.namedtuple 构建了一个简单的类来表示一张纸牌。自Python2.6开始,namedtuple 就加入到Python 里,用以构建只有少数属性但是没有方法的对象,比如数据库条目。如下面这个控制台会话所示,利用namedtuple,我们可以很轻松地得到一个纸牌对象:
>>> beer_card =Card('7', 'diamonds')
>>> beer_card
Card(rank='7', suit='diamonds')
当然,我们这个例子主要还是关注FrenchDeck 这个类,它既短小又精悍。首先,它跟任何标准Python 集合类型一样,可以用len() 函数来查看一叠牌有多少张:
>>> deck =FrenchDeck()
>>> len(deck)
52
从一叠牌中抽取特定的一张纸牌,比如说第一张或最后一张,是很容易的:deck[0] 或deck[-1]。这都是由__getitem__方法提供的:
>>> deck[0]
Card(rank='2', suit='spades')
>>> deck[-1]
Card(rank='A', suit='hearts')
我们需要单独写一个方法用来随机抽取一张纸牌吗?没必要,Python 已经内置了从一个序列中随机选出一个元素的函数random.choice,我们直接把它用在这一摞纸牌实例上就好:
>>> from random importchoice
>>> choice(deck)
Card(rank='3', suit='hearts')
>>> choice(deck)
Card(rank='K', suit='spades')
>>> choice(deck)
Card(rank='2', suit='clubs')
现在已经可以体会到通过实现特殊方法来利用Python 数据模型的两个好处。
-
作为你的类的用户,他们不必去记住标准操作的各式名称(“怎么得到元素的总数?是.size() 还是.length() 还是别的什么?”)。
-
可以更加方便地利用Python的标准库,比如random.choice 函数,从而不用重新发明轮子。
而且好戏还在后面。
因为__getitem__ 方法把[] 操作交给了self._cards 列表,所以我们的deck 类自动支持切片(slicing)操作。下面列出了查看一摞牌最上面3 张和只看牌面是A 的牌的操作。其中第二种操作的具体方法是,先抽出索引是12 的那张牌,然后每隔13 张牌拿1 张:
>>>deck[:3]
[Card(rank='2',suit='spades'), Card(rank='3', suit='spades'),
Card(rank='4',suit='spades')]
>>>deck[12::13]
[Card(rank='A',suit='spades'), Card(rank='A', suit='diamonds'),
Card(rank='A',suit='clubs'), Card(rank='A', suit='hearts')]
另外,仅仅实现了__getitem__方法,这一摞牌就变成可迭代的了:
>>>for card in deck: # doctest: +ELLIPSIS
...print(card)
Card(rank='2',suit='spades')
Card(rank='3',suit='spades')
Card(rank='4',suit='spades')
...
反向迭代也没关系:
>>>for card in reversed(deck): # doctest: +ELLIPSIS
...print(card)
Card(rank='A',suit='hearts')
Card(rank='K',suit='hearts')
Card(rank='Q',suit='hearts')
...
doctest 中的省略
为了尽可能保证书中的Python控制台会话内容的正确性,这些内容都是直接从doctest里摘录的。在测试中,如果可能的输出过长的话,那么过长的内容就会被如上面例子的最后一行的省略号(...)所替代。此时就需要#doctest: +ELLIPSIS 这个指令来保证doctest 能够通过。要是你自己照着书中例子在控制台中敲代码,可以略过这一指令。
迭代通常是隐式的,譬如说一个集合类型没有实现__contains__方法,那么in 运算符就会按顺序做一次迭代搜索。于是,in 运算符可以用在我们的FrenchDeck 类上,因为它是可迭代的:
>>>Card('Q', 'hearts') in deck
True
>>>Card('7', 'beasts') in deck
False
那么排序呢?我们按照常规,用点数来判定扑克牌的大小,2 最小、A 最大;同时还要加上对花色的判定,黑桃最大、红桃次之、方块再次、梅花最小。下面就是按照这个规则来给扑克牌排序的函数,梅花2的大小是0,黑桃A 是51:
suit_values = dict(spades=3, hearts=2, diamonds=1, clubs=0)
defspades_high(card):
rank_value= FrenchDeck.ranks.index(card.rank)
return rank_value * len(suit_values) + suit_values[card.suit]
有了spades_high 函数,就能对这摞牌进行升序排序了:
>>>for card in sorted(deck, key=spades_high): # doctest: +ELLIPSIS
...print(card)
Card(rank='2',suit='clubs')
Card(rank='2',suit='diamonds')
Card(rank='2',suit='hearts')
...(46 cards ommitted)
Card(rank='A',suit='diamonds')
Card(rank='A',suit='hearts')
Card(rank='A', suit='spades')
虽然FrenchDeck隐式地继承了object 类,5 但功能却不是继承而来的。我们通过数据模型和一些合成来实现这些功能。通过实现__len__ 和__getitem__这两个特殊方法,FrenchDeck就跟一个Python 自有的序列数据类型一样,可以体现出Python的核心语言特性(例如迭代和切片)。同时这个类还可以用于标准库中诸如random.choice、reversed和sorted 这些函数。另外,对合成的运用使得__len__ 和__getitem__的具体实现可以代理给self._cards 这个Python列表(即list 对象)。
如何洗牌
按照目前的设计,FrenchDeck是不能洗牌的,因为这摞牌是不可变的(immu-table):卡牌和它们的位置都是固定的,除非我们破坏这个类的封装性,直接对_cards 进行操作。第11 章会讲到,其实只需要一行代码来实现__setitem__ 方法,洗牌功能就不是问题了。
注5:在Python 2 中,对object 的继承需要显式地写为FrenchDeck(object);而在Python 3 中,这个继承关系是默认的。
1.2 如何使用特殊方法
首先明确一点,特殊方法的存在是为了被Python解释器调用的,你自己并不需要调用它们。也就是说没有my_object.__len__()这种写法,而应该使用len(my_object)。在执行len(my_object)的时候,如果my_object是一个自定义类的对象,那么Python会自己去调用其中由你实现的__len__ 方法。
然而如果是Python内置的类型,比如列表(list)、字符串(str)、字节序列(bytearray) 等,那么CPython会抄个近路,__len__ 实际上会直接返回PyVarObject里的ob_size 属性。PyVarObject是表示内存中长度可变的内置对象的C 语言结构体。直接读取这个值比调用一个方法要快很多。
很多时候,特殊方法的调用是隐式的,比如for i inx: 这个语句,背后其实用的是iter(x),而这个函数的背后则是x.__iter__()方法。当然前提是这个方法在x 中被实现了。
通常你的代码无需直接使用特殊方法。除非有大量的元编程存在,直接调用特殊方法的频率应该远远低于你去实现它们的次数。唯一的例外可能是__init__方法,你的代码里可能经常会用到它,目的是在你自己的子类的__init__方法中调用超类的构造器。
通过内置的函数(例如len、iter、str,等等)来使用特殊方法是最好的选择。这些内置函数不仅会调用特殊方法,通常还提供额外的好处,而且对于内置的类来说,它们的速度更快。14.12节中有详细的例子。
不要自己想当然地随意添加特殊方法,比如__foo__ 之类的,因为虽然现在这个名字没有被Python内部使用,以后就不一定了。
1.2.1 模拟数值类型
利用特殊方法,可以让自定义对象通过加号“+”(或是别的运算符)进行运算。第13章对此有详细的介绍,现在只是借用这个例子来展示特殊方法的使用。
我们来实现一个二维向量(vector)类,这里的向量就是欧几里得几何中常用的概念,常在数学和物理中使用的那个(见图1-1)。
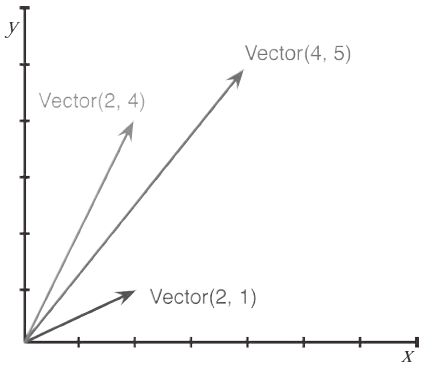
图1-1:一个二维向量加法的例子,Vector(2,4) + Vextor(2,1) =Vector(4,5)
Python 内置的complex 类可以用来表示二维向量,但我们这个自定义的类可以扩展到n 维向量,详见第14 章。
为了给这个类设计API,我们先写个模拟的控制台会话来做doctest。下面这一段代码就是图1-1 所示的向量加法:
>>> v1 = Vector(2, 4)
>>> v2 = Vector(2, 1)
>>> v1 + v2
Vector(4, 5)
注意其中的+ 运算符所得到的结果也是一个向量,而且结果能被控制台友好地打印出来。
abs 是一个内置函数,如果输入是整数或者浮点数,它返回的是输入值的绝对值;如果输入是复数(complexnumber),那么返回这个复数的模。为了保持一致性,我们的API在碰到abs 函数的时候,也应该返回该向量的模:
>>> v = Vector(3, 4)
>>> abs(v)
5.0
我们还可以利用* 运算符来实现向量的标量乘法(即向量与数的乘法,得到的结果向量的方向与原向量一致6,模变大):
>>> v * 3
Vector(9, 12)
>>> abs(v * 3)
15.0
示例1-2 包含了一个Vector 类的实现,上面提到的操作在代码里是用这些特殊方法实现的:__repr__、__abs__、__add__ 和 __mul__。
示例1-2 一个简单的二维向量类
from math import hypot
class Vector:
def __init__(self, x=0, y=0):
self.x = x
self.y = y
def __repr__(self):
return 'Vector(%r, %r)' % (self.x, self.y)
def __abs__(self):
return hypot(self.x, self.y)
def __bool__(self):
return bool(abs(self))
def __add__(self, other):
x = self.x + other.x
y = self.y + other.y
return Vector(x, y)
def __mul__(self, scalar):
return Vector(self.x * scalar, self.y * scalar)
注6:如果向量与负数相乘,得到的结果向量的方向与原向量相反。——编者注
虽然代码里有6 个特殊方法,但这些方法(除了__init__)并不会在这个类自身的代码中使用。即便其他程序要使用这个类的这些方法,也不会直接调用它们,就像我们在上面的控制台对话中看到的。上文也提到过,一般只有Python的解释器会频繁地直接调用这些方法。接下来看看每个特殊方法的实现。
1.2.2 字符串表示形式
Python 有一个内置的函数叫repr,它能把一个对象用字符串的形式表达出来以便辨认,这就是“字符串表示形式”。repr 就是通过__repr__ 这个特殊方法来得到一个对象的字符串表示形式的。如果没有实现__repr__,当我们在控制台里打印一个向量的实例时,得到的字符串可能会是
交互式控制台和调试程序(debugger)用repr 函数来获取字符串表示形式;在老的使用% 符号的字符串格式中,这个函数返回的结果用来代替%r 所代表的对象;同样,str.format函数所用到的新式字符串格式化语法(https://docs.python.org/2/library/string.html#format-string-syntax)也是利用了repr,才把!r 字段变成字符串。
% 和str.format这两种格式化字符串的手段在本书中都会使用。其实整个Python社区都在同时使用这两种方法。个人来讲,我越来越喜欢str.format了,但是Python 程序员更喜欢简单的%。因此,这两种形式并存的情况还会持续下去。
在__repr__的实现中,我们用到了%r 来获取对象各个属性的标准字符串表示形式——这是个好习惯,它暗示了一个关键:Vector(1, 2) 和Vector('1','2') 是不一样的,后者在我们的定义中会报错,因为向量对象的构造函数只接受数值,不接受字符串7。
__repr__ 所返回的字符串应该准确、无歧义,并且尽可能表达出如何用代码创建出这个被打印的对象。因此这里使用了类似调用对象构造器的表达形式(比如Vector(3,4) 就是个例子)。
__repr__ 和__str__ 的区别在于,后者是在str() 函数被使用,或是在用print 函数打印一个对象的时候才被调用的,并且它返回的字符串对终端用户更友好。
如果你只想实现这两个特殊方法中的一个,__repr__是更好的选择,因为如果一个对象没有__str__ 函数,而Python 又需要调用它的时候,解释器会用__repr__作为替代。
“Difference between __str__ and__repr__ in Python”
http://stackoverflow.com/questions/1436703/difference-between-str-and-repr-in-python
是StackOverflow 上的一个问题,Python程序员AlexMartelli 和MartijnPieters 的回答很精彩。
注7:实际上,Vector 的构造函数接受字符串。而且,对于使用字符串构造的Vector,这6 个特殊方法中,只有__abs__ 和__bool__会报错。此外,1.2.4 节定义的__bool__ 不会报错。——编者注
1.2.3 算术运算符
通过__add__ 和__mul__,示例1-2 为向量类带来了+ 和* 这两个算术运算符。值得注意的是,这两个方法的返回值都是新创建的向量对象,被操作的两个向量(self 或other)还是原封不动,代码里只是读取了它们的值而已。中缀运算符的基本原则就是不改变操作对象,而是产出一个新的值。第13章会谈到更多这方面的问题。
示例1-2只实现了数字做乘数、向量做被乘数的运算,乘法的交换律则被忽略了。在第13章里,我们将利用__rmul__解决这个问题。
1.2.4 自定义的布尔值
尽管Python里有bool 类型,但实际上任何对象都可以用于需要布尔值的上下文中(比如if 或while 语句,或者and、or 和not 运算符)。为了判定一个值x 为真还是为假,Python 会调用bool(x),这个函数只能返回True 或者False。
默认情况下,我们自己定义的类的实例总被认为是真的,除非这个类对__bool__或者__ len__函数有自己的实现。bool(x) 的背后是调用x.__bool__()的结果;如果不存在__bool__ 方法,那么bool(x) 会尝试调用x.__len__()。若返回0,则bool 会返回False;否则返回True。
我们对__bool__的实现很简单,如果一个向量的模是0,那么就返回False,其他情况则返回True。因为__bool__函数的返回类型应该是布尔型,所以我们通过bool(abs(self))把模值变成了布尔值。
在Python标准库的文档中,有一节叫作“Built-in Types”(https://docs.python.org/3/library/stdtypes.html#truth),其中规定了真值检验的标准。通过实现__bool__,你定义的对象就可以与这个标准保持一致。
如果想让Vector.__bool__ 更高效,可以采用这种实现:
def __bool__(self):
return bool(self.x or self.y)
它不那么易读,却能省掉从abs 到__abs__ 到平方再到平方根这些中间步骤。通过bool 把返回类型显式转换为布尔值是为了符合__bool__对返回值的规定,因为or 运算符可能会返回x 或者y 本身的值:若x 的值等价于真,则or 返回x 的值;否则返回y 的值。
1.3 特殊方法一览
Python 语言参考手册中的“DataModel”
https://docs.python.org/3/reference/datamodel.html
一章列出了83个特殊方法的名字,其中47个用于实现算术运算、位运算和比较操作。
表1-1和表1-2 列出了这些方法的概况。
这些表并没有完全按照官方文档分组。
表1-1:跟运算符无关的特殊方法

表1-2:跟运算符相关的特殊方法

当交换两个操作数的位置时,就会调用反向运算符(b * a 而不是a * b)。增量赋值运算符则是一种把中缀运算符变成赋值运算的捷径(a = a * b 就变成了a *= b)。第13 章会对这两者作出详细解释。
1.4 为什么len不是普通方法
我在2013年问核心开发者RaymondHettinger 这个问题时,他用“Python 之禅”(https://www.python.org/doc/humor/#the-zen-of-python)里的原话回答了我:“实用胜于纯粹。”在1.2 节里我提到过,如果x 是一个内置类型的实例,那么len(x) 的速度会非常快。背后的原因是CPython会直接从一个C 结构体里读取对象的长度,完全不会调用任何方法。获取一个集合中元素的数量是一个很常见的操作,在str、list、memoryview等类型上,这个操作必须高效。
换句话说,len 之所以不是一个普通方法,是为了让Python自带的数据结构可以走后门, abs 也是同理。但是多亏了它是特殊方法,我们也可以把len 用于自定义数据类型。这种处理方式在保持内置类型的效率和保证语言的一致性之间找到了一个平衡点,也印证了“Python 之禅”中的另外一句话:“不能让特例特殊到开始破坏既定规则。”
如果把abs 和len 都看作一元运算符的话,你也许更能接受它们——虽然看起来像面向对象语言中的函数,但实际上又不是函数。有一门叫作ABC 的语言是Python 的直系祖先,它内置了一个# 运算符,当你写出#s 的时候, 它的作用跟len 一样。如果写成x#s 这样的中缀运算符的话,那么它的作用是计算s 中x 出现的次数。在Python里对应的写法是s.count(x)。注意这里的s 是一个序列类型。
1.5 本章小结
通过实现特殊方法,自定义数据类型可以表现得跟内置类型一样,从而让我们写出更具表达力的代码——或者说,更具Python 风格的代码。
Python 对象的一个基本要求就是它得有合理的字符串表示形式,我们可以通过__repr__和__str__ 来满足这个要求。前者方便我们调试和记录日志,后者则是给终端用户看的。这就是数据模型中存在特殊方法__repr__和__str__ 的原因。
对序列数据类型的模拟是特殊方法用得最多的地方,这一点在FrenchDeck类的示例中有所展现。在第2 章中,我们会着重介绍序列数据类型,然后在第10章中,我们会把Vector 类扩展成一个多维的数据类型,通过这个练习你将有机会实现自定义的序列。
Python 通过运算符重载这一模式提供了丰富的数值类型,除了内置的那些之外,还有decimal.Decimal和fractions.Fraction。这些数据类型都支持中缀算术运算符。在第13章中,我们还会通过对Vector 类的扩展来学习如何实现这些运算符,当然还会提到如何让运算符满足交换律和增强赋值。
Python 数据模型的特殊方法还有很多,本书会涵盖其中的绝大部分,探讨如何使用和实现它们。
1.6 延伸阅读
对本章内容和本书主题来说,Python语言参考手册里的“Data Model”一章(https://docs.python.org/3/reference/datamodel.html)是最符合规范的知识来源。
Alex Martelli 的《Python 技术手册(第2 版)》对数据模型的讲解很精彩。我写这本书的时候,《Python技术手册》的最新版本是2006年出版的,书里用的还是Python2.5,但是Python关于数据模型的概念并没有太大的变化,而书中Martelli对属性访问机制的描述, 应该是除了CPython中的C 源码之外在这方面最权威的解释。Martelli还是StackOverflow 上的高产贡献者,在他名下差不多有5000条答案,你也可以去他的StackOverflow 主页(http://stackoverflow.com/users/95810/alex-martelli)上看看。
David Beazley 著有两本基于Python 3 的书,其中对数据模型进行了详尽的介绍。一本是《Python参考手册(第4 版)》8,另一本是与BrianK. Jones 合著的《PythonCookbook(第3 版)中文版》。
由GregorKiczales、Jimdes Rivieres 和DanielG. Bobrow 合著的TheArt of the Metaobject Protocol( 又称AMOP,MIT出版社,1991年) 一书解释了元对象协议(metaobject protocol,MOP)的概念,而Python数据模型便是对这一概念的一种阐释。
注8:该书已由人民邮电出版社出版,书号:978-7-115-24259-4。——编者注
杂谈
数据模型还是对象模型
Python文档里总是用“Python 数据模型”这种说法,而大多数作者提到这个概念的时候会说“Python对象模型”。Alex Martelli 的《Python 技术手册(第2 版)》和David Beazley 的《Python 参考手册(第4 版)》是这个领域中最好的两本书,但是他们也总说“Python 对象模型”。维基百科中对象模型的第一个定义(http://en.wikipedia.org/wiki/Object_model)是:计算机编程语言中对象的属性。这正好是“Python数据模型”所要描述的概念。我在本书中一直都会用“数据模型”这个词,首先是因为在Python 文档里对这个词有偏爱,另外一个原因是Python 语言参考手册中与这里讨论的内容最相关的一章的标题就是“数据模型”(https://docs.python.org/3/reference/datamodel. html)。
魔术方法
在Ruby 中也有类似“特殊方法”的概念,但是Ruby 社区称之为“魔术方法”,而实际上Python 社区里也有不少人用的是后者。而我恰恰认为“特殊方法”是“魔术方法”的对立面。Python 和Ruby 都利用了这个概念来提供丰富的元对象协议,这不是魔术,而是让语言的用户和核心开发者拥有并使用同样的工具。考虑一下JavaScript,情况就正好反过来了。JavaScript 中的对象有不透明的魔术般的特性,而你无法在自定义的对象中模拟这些行为。比如在JavaScript 1.8.5 中,用户的自定义对象不能有只读属性,然而不少JavaScript 的内置对象却可以有。因此在JavaScript 中,只读属性是“魔术”般的存在,对于普通的JavaScript 用户而言,它就像超能力一样。2009 年推出的ECMAScript 5.1 才让用户可以定义只读属性。JavaScript 中跟元对象协议有关的部分一直在进化,但由于历史原因,这方面它还是赶不上Python 和Ruby。
元对象
The Art of the Metaobject Protocal (AMOP)是我最喜欢的计算机图书的标题。客观来说,元对象协议这个词对我们学习Python 数据模型是有帮助的。元对象所指的是那些对建构语言本身来讲很重要的对象,以此为前提,协议也可以看作接口。也就是说,元对象协议是对象模型的同义词,它们的意思都是构建核心语言的API。
一套丰富的元对象协议能让我们对语言进行扩展,让它支持新的编程范式。AMOP 的第一作者Gregor Kiczales 后来成为面向方面编程的先驱,他写出了一个Java 扩展叫AspectJ,用来实现他对面向方面编程的理念。其实在Python 这样的动态语言里,更容易实现面向方面编程。现在已经有几个Python 框架在做这件事情了,其中最重要的是zope.interface(http://docs.zope.org/zope.interface/)。第11 章的延伸阅读里会谈到它(完)。
我们此前已经给大家送了不少Python学习书籍,比如此前很受大家欢迎的《Python编程:从入门到实践》,但仅仅阅读书籍距离成为一名Python高手还是有一段距离的,尤其是无监督的自学环境下。
为了帮助大家更快更高效地学习Python,CSDN学院特推出年度大课《从零基础到Python全栈工程师的成长之路》, 直播+录播,配备班主任和助教, 设置闯关制来监督学习效果,帮你在成为Python高手之路上更进一步。

☞ 点击阅读原文,查看详细课程信息