R语言构建RFM模型了解一下~~~
作者简介Introduction
杜雨,EasyCharts团队成员,R语言中文社区专栏作者,兴趣方向为:Excel商务图表,R语言数据可视化,地理信息数据可视化。
个人公众号:数据小魔方(微信ID:datamofang) ,“数据小魔方”创始人。
精彩集锦
那些年倒腾的R语言学习笔记,全都在这里了~
左手用R右手Python系列之——表格数据抓取之道
左手用R右手Python系列——循环中的错误异常规避
左手用R右手Python系列——异常捕获与容错处理
左手用R右手Python系列——任务进度管理
左手用R右手Python——CSS网页解析实战
左手用R右手Python系列17——CSS表达式与网页解析
左手用R右手Python系列之——字符串格式化进阶
R语言数据分析笔记——Cohort 存留分析
左手用R右手Python系列之——字符串格式化进阶
R语言多任务处理与并行运算包——foreach
R语言学习笔记之——数据处理神器data.table
ggplot2学习笔记——图例系统及其调整函数
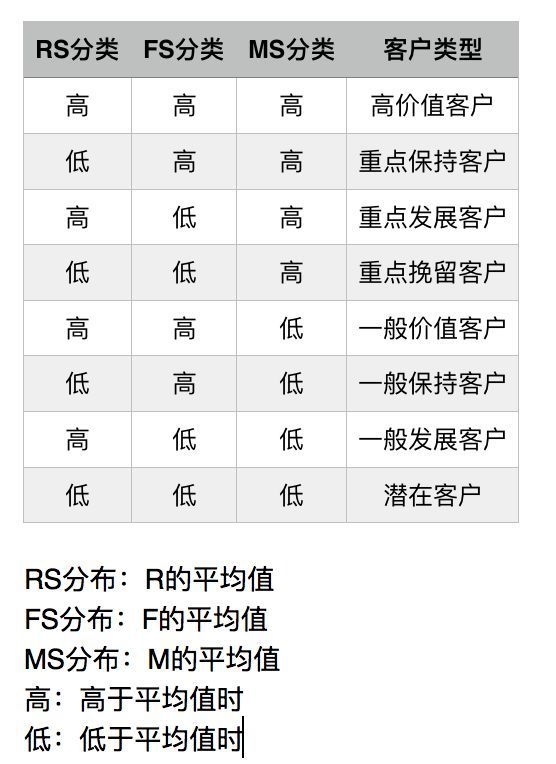
RFM模型是市场营销和CRM客户管理中经常用到的探索性分析方法,透过模型深入挖掘客户行为背后的价值规律,进而更好地利用数据价值推动业务发展和客户管理。
RFM是三种客户行为的英文缩写:
R:Recency —— 客户最近一次交易时间的间隔。R值越大,表示客户交易距今越久,反之则越近;
F:Frequency—— 客户在最近一段时间内交易的次数。F值越大,表示客户交易越频繁,反之则不够活跃;
M:Monetary —— 客户在最近一段时间内交易的金额。M值越大,表示客户价值越高,反之则越低。
一般通过对RFM三个原始指标进行分箱操作(分位数法),获得三个指标各自的若干个水平因子(需要注意因子水平大小的对应的实际意义)。
R_S:基于最近一次交易日期计算得分,距离当前日期越近,则得分越高,否则得分越低;
F_S:基于交易频率计算得分,交易频率越高,则得分越高,否则得分越低;
M_S:基于交易金额得分,交易金额越高,则得分越高,反之得分越低。
同时为了对每个客户进行综合评价,也可将以上三个得分进行加权计算(权重规则可由专家制定或者营销人员自行根据业务决定,这里统一采用100:10:1)。
RFM = 100R_S + 10F_S + 1*M_S
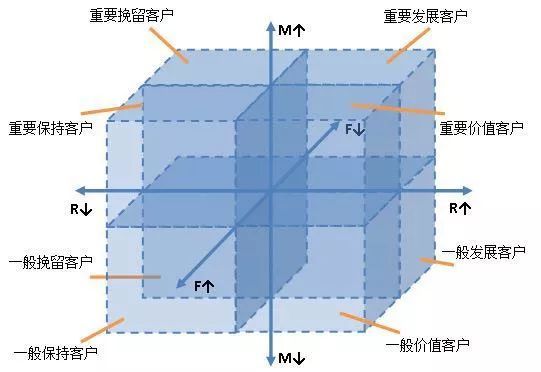
RFM核心便是构建在R、F、M三个指标得分构成的立方体组合内,形成一个非常直观的客户价值矩阵。
最终通过对R_S、F_S、M_S三指标的得分组合,形成八种客户价值类型,营销人员可以通过以上组合形成的客户类群,针对性的进行活动营销,进而提升客户价值和营收水平。
通过RFM分析识别优质客户,可以据此制定个性化沟通与营销服务,可以为营销决策提供更好地支持。
以下是利用R语言构建RFM模型的简要步骤:
1、数据准备:
## !/user/bin/env RStudio 1.1.423
## -*- coding: utf-8 -*-
## RFM Model
#* 最近一次消费(Recency)
#* 消费频率(Frenquency)
#* 消费金额(Monetary)Code Part
setwd('D:/R/File/')
library('magrittr')
library('dplyr')
library('scales')
library('ggplot2')
library("easyGgplot2")
library("Hmisc")
library('foreign')
library('lubridate')
mydata <- spss.get("trade.sav",datevars = '交易日期',reencode = 'GBK')
names(mydata) <- c('OrderID','UserID','PayDate','PayAmount')
start_time <- as.POSIXct("2017/01/01", format="%Y/%m/%d") %>% as.numeric()
end_time <- as.POSIXct("2017/12/31", format="%Y/%m/%d") %>% as.numeric()
set.seed(233333)
mydata$PayDate <- runif(nrow(mydata),start_time,end_time) %>% as.POSIXct(origin="1970-01-01") %>% as.Date()
mydata$interval <- difftime(max(mydata$PayDate),mydata$PayDate ,units="days") %>% round() %>% as.numeric()按照用户ID聚合交易频次、交易总额及首次购买时间
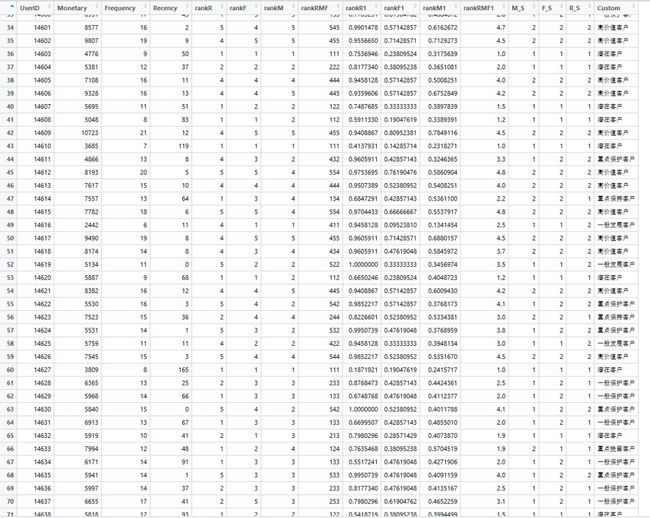
salesRFM <- mydata %>% group_by(UserID) %>% summarise(Monetary = sum(PayAmount), Frequency = n(), Recency = min(interval))2、计算得分
#分箱得分
salesRFM <- mutate( salesRFM, rankR = 6- cut(salesRFM$Recency,breaks = quantile(salesRFM$Recency, probs = seq(0, 1, 0.2),names = FALSE),include.lowest = TRUE,labels=F), rankF = cut(salesRFM$Frequency ,breaks = quantile(salesRFM$Frequency, probs = seq(0, 1, 0.2),names = FALSE),include.lowest = TRUE,labels=F), rankM = cut(salesRFM$Monetary ,breaks = quantile(salesRFM$Monetary, probs = seq(0, 1, 0.2),names = FALSE),include.lowest = TRUE,labels=F), rankRMF = 100*rankR + 10*rankF + 1*rankM)
#标准化得分(也是一种计算得分的方法)
salesRFM <- mutate(salesRFM, rankR1 = 1-rescale(salesRFM$Recency,to = c(0,1)), rankF1 = rescale(salesRFM$Frequency,to = c(0,1)), rankM1 = rescale(salesRFM$Monetary,to = c(0,1)), rankRMF1 = 0.5*rankR + 0.3*rankF + 0.2*rankM)3、客户分类:
#对RFM分类:
salesRFM <- within(salesRFM,{R_S = ifelse(rankR > mean(rankR),2,1)
F_S = ifelse(rankF > mean(rankF),2,1)
M_S = ifelse(rankM > mean(rankM),2,1)})#客户类型归类:
salesRFM <- within(salesRFM,{Custom = NA
Custom[R_S == 2 & F_S == 2 & M_S == 2] = '高价值客户'
Custom[R_S == 1 & F_S == 2 & M_S == 2] = '重点保持客户'
Custom[R_S == 2 & F_S == 1 & M_S == 2] = '重点发展客户'
Custom[R_S == 1 & F_S == 1 & M_S == 2] = '重点挽留客户'
Custom[R_S == 2 & F_S == 2 & M_S == 1] = '重点保护客户'
Custom[R_S == 1 & F_S == 2 & M_S == 1] = '一般保护客户'
Custom[R_S == 2 & F_S == 1 & M_S == 1] = '一般发展客户'
Custom[R_S == 1 & F_S == 1 & M_S == 1] = '潜在客户'
})
4、分析结果可视化:
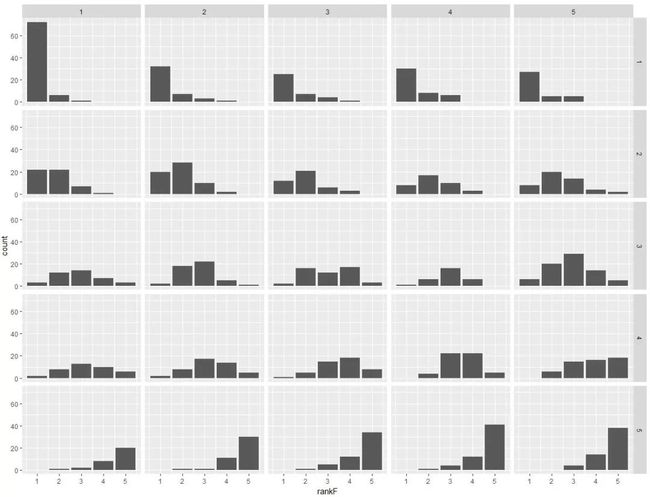
4.1 查看RFM分箱后客户分布状况:
#RFM分箱计数
ggplot(salesRFM,aes(rankF)) + geom_bar()+ facet_grid(rankM~rankR) + theme_gray()
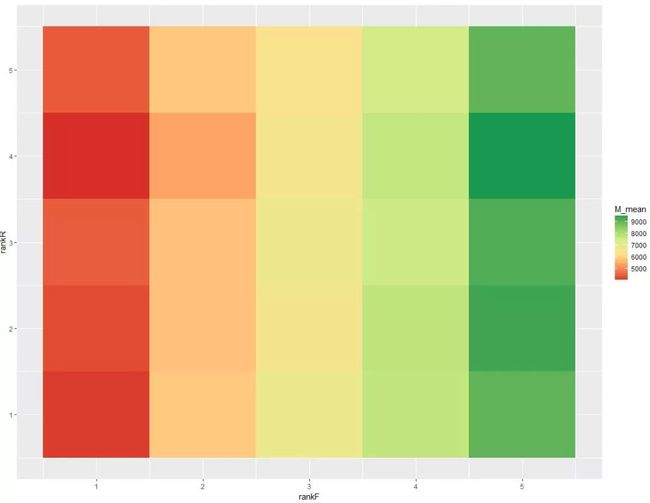
4.2 RFM热力图:
#RFM heatmap
heatmap_data <- salesRFM %>% group_by(rankF,rankR) %>% dplyr::summarize(M_mean = mean(Monetary))
ggplot(heatmap_data,aes(rankF,rankR,fill =M_mean ))+geom_tile()
+ scale_fill_distiller(palette = 'RdYlGn',direction = 1)
4.3 RFM直方图:
#RFM直方图
p1 <- ggplot(salesRFM,aes(Recency)) + geom_histogram(bins = 10,fill = '#362D4C')
p2 <- ggplot(salesRFM,aes(Frequency)) + geom_histogram(bins = 10,fill = '#362D4C')
p3 <- ggplot(salesRFM,aes(Monetary)) + geom_histogram(bins = 10,fill = '#362D4C')
ggplot2.multiplot(p1,p2,p3, cols=3)
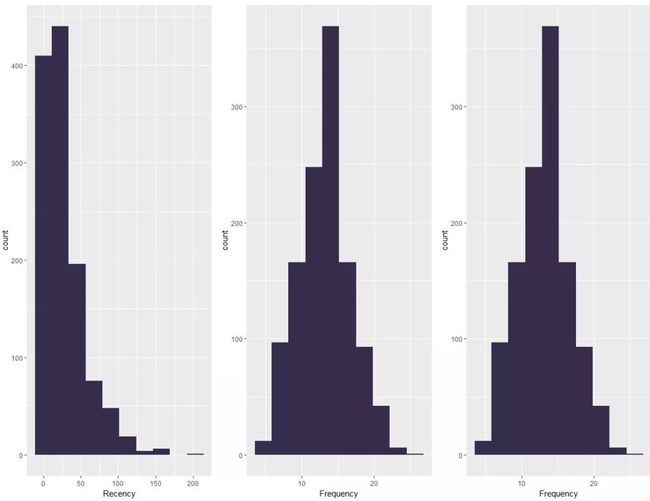
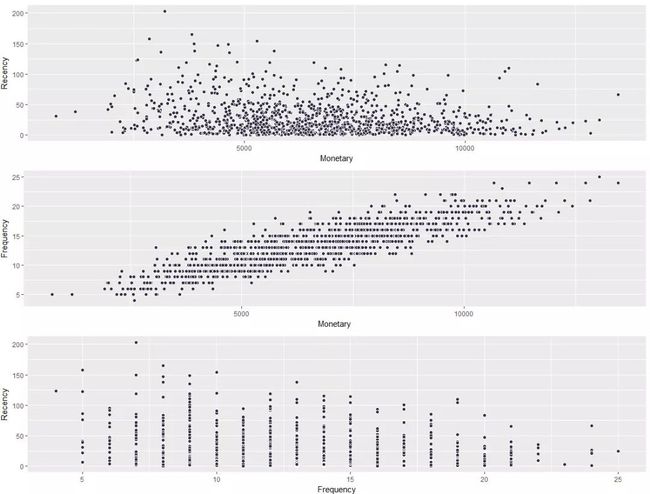
4.4 RFM两两交叉散点图:
#RFM 两两交叉散点图
p1 <- ggplot(salesRFM,aes(Monetary,Recency)) + geom_point(shape = 21,fill = '#362D4C' ,colour = 'white',size = 2)
p2 <- ggplot(salesRFM,aes(Monetary,Frequency)) + geom_point(shape = 21,fill = '#362D4C' ,colour = 'white',size = 2)
p3 <- ggplot(salesRFM,aes(Frequency,Recency)) + geom_point(shape = 21,fill = '#362D4C' ,colour = 'white',size = 2)
ggplot2.multiplot(p1,p2,p3, cols=1)
5 数据结果导出
#导出结果数据
write.csv(salesRFM,'salesRFM.csv')
Python:
1、数据准备
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import time
import numpy as np
import pandas as pd
import savReaderWriter as spss
import os
from datetime import datetime,timedeltanp.random.seed(233333)
os.chdir('D:/R/File')
pd.set_option('display.float_format', lambda x: '%.3f' % x) with spss.SavReader('trade.sav',returnHeader = True ,ioUtf8=True,rawMode = True,ioLocale='chinese') as reader: mydata = pd.DataFrame(list(reader)[1:],columns = list(reader)[0]) mydata['交易日期'] = mydata['交易日期'].map(lambda x: reader.spss2strDate(x,"%Y-%m-%d", None)) mydata.rename(columns={
'订单ID':'OrderID','客户ID':'UserID','交易日期':'PayDate','交易金额':'PayAmount'},inplace=True) start_time = int(time.mktime(time.strptime('2017/01/01', '%Y/%m/%d'))) end_time = int(time.mktime(time.strptime('2017/12/31', '%Y/%m/%d'))) mydata['PayDate'] = pd.Series(np.random.randint(start_time,end_time,len(mydata))).map(lambda x: time.strftime("%Y-%m-%d", time.localtime(x)))
mydata['interval'] = [(datetime.now() - pd.to_datetime(i,format ='%Y %m %d')).days for i in mydata['PayDate']]
mydata = mydata.astype({
'OrderID':'int64','UserID':'int64','PayAmount':'int64'})
print('---------#######-----------')
print(mydata.head())
print('---------#######-----------')
print(mydata.tail())
print('…………………………………………………………………………')
print(mydata.dtypes)
print('---------#######------------')2、得分计算:
#按照用户ID聚合交易频次、交易总额及首次购买时间
mydata.set_index('UserID', inplace=True)
salesRFM = mydata.groupby(level = 0).agg({
'PayAmount': np.sum,
'PayDate': 'count',
'interval': np.min }) # make the column names more meaningful
salesRFM.rename(columns={
'PayAmount': 'Monetary',
'PayDate': 'Frequency',
'interval':'Recency' }, inplace=True)salesRFM.head()#均值划分
salesRFM = salesRFM.assign( rankR = pd.qcut(salesRFM['Recency'], q = [0, .2, .4, .6,.8,1.] , labels = [5,4,3,2,1]), rankF = pd.qcut(salesRFM['Frequency'],q = [0, .2, .4, .6,.8,1.] , labels = [1,2,3,4,5]),rankM = pd.qcut(salesRFM['Monetary'] ,q = [0, .2, .4, .6,.8,1.] , labels = [1,2,3,4,5]))salesRFM['rankRMF'] = 100*salesRFM['rankR'] + 10*salesRFM['rankF'] + 1*salesRFM['rankM']#特征缩放——0-1标准化
from sklearn import preprocessing
min_max_scaler = preprocessing.MinMaxScaler()
salesRFM1 = min_max_scaler.fit_transform(salesRFM.loc[:,['Recency','Frequency','Monetary']].values)
salesRFM = salesRFM.assign(rankR1 = 1 - salesRFM1[:,0], rankF1 = salesRFM1[:,1], rankM1 = salesRFM1[:,2] )salesRFM['rankRFM1'] = 0.5*salesRFM['rankR1'] + 0.3*salesRFM['rankF1'] + 0.2*salesRFM['rankM1']3、客户分类:
#对RFM分类:
salesRFM = salesRFM.astype({
'rankR':'int64','rankF':'int64','rankM':'int64'})
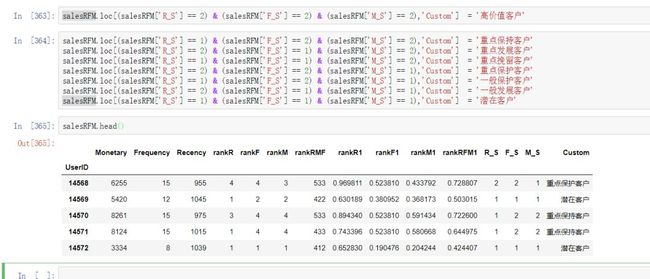
salesRFM = salesRFM.assign( R_S = salesRFM['rankR'].map(lambda x: 2 if x > salesRFM['rankR'].mean() else 1), F_S = salesRFM['rankF'].map(lambda x: 2 if x > salesRFM['rankF'].mean() else 1), M_S = salesRFM['rankM'].map(lambda x: 2 if x > salesRFM['rankM'].mean() else 1))#客户类型归类:
salesRFM['Custom'] = np.NaNsalesRFM.loc[(salesRFM['R_S'] == 2) & (salesRFM['F_S'] == 2) & (salesRFM['M_S'] == 2),'Custom'] = '高价值客户'
salesRFM.loc[(salesRFM['R_S'] == 1) & (salesRFM['F_S'] == 2) & (salesRFM['M_S'] == 2),'Custom'] = '重点保持客户'
salesRFM.loc[(salesRFM['R_S'] == 2) & (salesRFM['F_S'] == 1) & (salesRFM['M_S'] == 2),'Custom'] = '重点发展客户'
salesRFM.loc[(salesRFM['R_S'] == 1) & (salesRFM['F_S'] == 1) & (salesRFM['M_S'] == 2),'Custom'] = '重点挽留客户'
salesRFM.loc[(salesRFM['R_S'] == 2) & (salesRFM['F_S'] == 2) & (salesRFM['M_S'] == 1),'Custom'] = '重点保护客户'
salesRFM.loc[(salesRFM['R_S'] == 1) & (salesRFM['F_S'] == 2) & (salesRFM['M_S'] == 1),'Custom'] = '一般保护客户'
salesRFM.loc[(salesRFM['R_S'] == 2) & (salesRFM['F_S'] == 1) & (salesRFM['M_S'] == 1),'Custom'] = '一般发展客户'
salesRFM.loc[(salesRFM['R_S'] == 1) & (salesRFM['F_S'] == 1) & (salesRFM['M_S'] == 1),'Custom'] = '潜在客户'
RFM模型仅仅是一个前期的探索性分析,可以利用RFM模型输出的指标结果还可以进行其他分类以及降维模型的构建,深入探索客户数据价值,挖掘潜在营销点。
数据文件及code可以点击下面的GitHub链接获取:
https://github.com/ljtyduyu/DataWarehouse/tree/master/Model
如果你想要深入的去学ggplot2,但是又苦于平时学习、工作太忙木有时间研究浩如烟海的源文档,那也没关系,本小编最近花了不少功夫,把我自己学习ggplot2过程中的一些心得体会、学习经验、仿入坑指南精心整理,现已成功上线了R语言ggplot2可视化的视频课程,由天善智能独家发行,希望这门课程可以给你的R语言数据可视化学习带来更加丰富的体验。
相关课程推荐
体系全面,最具调性!R语言可视化&商务图表实战课程:


点击“阅读原文”开启新姿势