Backbone 之 FPN:特征金字塔 (Pytorch实现及代码解析)
背景:
为了增强语义性,传统的物体检测模型通常只在深度卷积网络的最后一个特征图上进行后续操作,而这一层对应的下采样率(图像缩小的倍数)通常又比较大,如16、32,造成小物体在特征图上的有效信息较少,小物体的检测性能会急剧下降,这个问题也被称为多尺度问题。 解决多尺度问题的关键在于如何提取多尺度的特征。传统的方法有图像金字塔(Image Pyramid),主要思路是将输入图片做成多个尺度,不同尺度的图像生成不同尺度的特征,这种方法简单而有效,大量使用在了COCO等竞赛上,但缺点是非常耗时,计算量也很大。 从前面几大主干网络的内容可以知道,卷积神经网络不同层的大小与语义信息不同,本身就类似一个金字塔结构。2017年的FPN(Feature Pyramid Network)方法融合了不同层的特征,较好地改善了多尺度检测问题。
FPN网络结构:
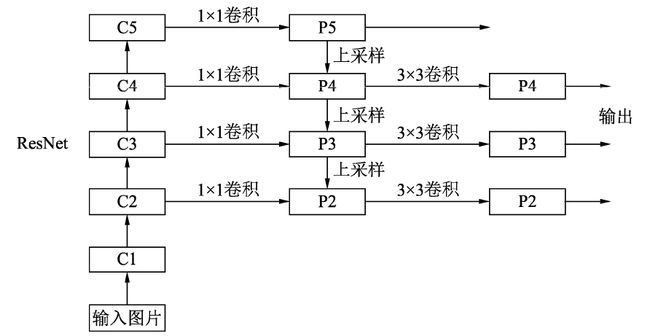
FPN的总体架构如上图所示,主要包含自下而上网络、自上而下网络、横向连接与卷积融合4个部分。
自下而上:
最左侧为普通的卷积网络,默认使用ResNet结构,用作提取语义信息。C1代表了ResNet的前几个卷积与池化层,而C2至C5分别为不同的ResNet卷积组,这些卷积组包含了多个Bottleneck结构,组内的特征图大小相同,组间大小递减。
自上而下:
首先对C5进行1×1卷积降低通道数得到P5,然后依次进行上采样得到P4、P3和P2,目的是得到与C4、C3与C2长宽相同的特征,以方便下一步进行逐元素相加。这里采用2倍最邻近上采样,即直接对临近元素进行复制,而非线性插值。
横向连接(Lateral Connection):
目的是为了将上采样后的高语义特征与浅层的定位细节特征进行融合。高语义特征经过上采样后,其长宽与对应的浅层特征相同,而通道数固定为256,因此需要对底层特征C2至C4进行11卷积使得其通道数变为256,然后两者进行逐元素相加得到P4、P3与P2。由于C1的特征图尺寸较大且语义信息不足,因此没有把C1放到横向连接中。
卷积融合:
在得到相加后的特征后,利用3×3卷积对生成的P2至P4再进行融合,目的是消除上采样过程带来的重叠效应,以生成最终的特征图。
如何选择特征图:
对于实际的物体检测算法,需要在特征图上进行RoI(Region of Interests,感兴趣区域)提取,而FPN有4个输出的特征图,选择哪一个特征图上面的特征也是个问题。FPN给出的解决方法是,对于不同大小的RoI,使用不同的特征图,大尺度的RoI在深层的特征图上进行提取,如P5,小尺度的RoI在浅层的特征图上进行提取,如P2。
FPN将深层的语义信息传到底层,来补充浅层的语义信息,从而获得了高分辨率、强语义的特征,在小物体检测、实例分割等领域有着非常不俗的表现。
具体代码:
import torch.nn as nn
import torch.nn.functional as F
import math
##先定义ResNet基本类,或者可以说ResNet的基本砖块
class Bottleneck(nn.Module):
expansion = 4 ##通道倍增数
def __init__(self, in_planes, planes, stride=1, downsample=None):
super(Bottleneck, self).__init__()
self.bottleneck = nn.Sequential(
nn.Conv2d(in_planes, planes, 1, bias=False),
nn.BatchNorm2d(planes),
nn.ReLU(inplace=True),
nn.Conv2d(planes, planes, 3, stride, 1, bias=False),
nn.BatchNorm2d(planes),
nn.ReLU(inplace=True),
nn.Conv2d(planes, self.expansion * planes, 1, bias=False),
nn.BatchNorm2d(self.expansion * planes),
)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
def forward(self, x):
identity = x
out = self.bottleneck(x)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
##FPN类
class FPN(nn.Module):
def __init__(self, layers):
super(FPN, self).__init__()
self.inplanes = 64
###下面四句代码代表处理输入的C1模块--对应博客中的图
self.conv1 = nn.Conv2d(3, 64, 7, 2, 3, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(3, 2, 1)
###搭建自下而上的C2,C3,C4,C5
self.layer1 = self._make_layer(64, layers[0])
self.layer2 = self._make_layer(128, layers[1], 2)
self.layer3 = self._make_layer(256, layers[2], 2)
self.layer4 = self._make_layer(512, layers[3], 2)
###定义toplayer层,对C5减少通道数,得到P5
self.toplayer = nn.Conv2d(2048, 256, 1, 1, 0)
###代表3*3的卷积融合,目的是消除上采样过程带来的重叠效应,以生成最终的特征图。
self.smooth1 = nn.Conv2d(256, 256, 3, 1, 1)
self.smooth2 = nn.Conv2d(256, 256, 3, 1, 1)
self.smooth3 = nn.Conv2d(256, 256, 3, 1, 1)
###横向连接,保证通道数目相同
self.latlayer1 = nn.Conv2d(1024, 256, 1, 1, 0)
self.latlayer2 = nn.Conv2d( 512, 256, 1, 1, 0)
self.latlayer3 = nn.Conv2d( 256, 256, 1, 1, 0)
##作用:构建C2-C5砖块,注意stride为1和2的区别:得到C2没有经历下采样
def _make_layer(self, planes, blocks, stride=1):
downsample = None
if stride != 1 or self.inplanes != Bottleneck.expansion * planes:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, Bottleneck.expansion * planes, 1, stride, bias=False),
nn.BatchNorm2d(Bottleneck.expansion * planes)
)
###初始化需要一个list,代表左侧网络ResNet每一个阶段的Bottleneck的数量
layers = []
layers.append(Bottleneck(self.inplanes, planes, stride, downsample))
self.inplanes = planes * Bottleneck.expansion
for i in range(1, blocks):
layers.append(Bottleneck(self.inplanes, planes))
return nn.Sequential(*layers)
###自上而下的上采样模块
def _upsample_add(self, x, y):
_,_,H,W = y.shape
return F.upsample(x, size=(H,W), mode='bilinear') + y
def forward(self, x):
###自下而上
c1 = self.maxpool(self.relu(self.bn1(self.conv1(x))))
c2 = self.layer1(c1)
c3 = self.layer2(c2)
c4 = self.layer3(c3)
c5 = self.layer4(c4)
###自上而下
p5 = self.toplayer(c5)
p4 = self._upsample_add(p5, self.latlayer1(c4))
p3 = self._upsample_add(p4, self.latlayer2(c3))
p2 = self._upsample_add(p3, self.latlayer3(c2))
###卷积融合,平滑处理
p4 = self.smooth1(p4)
p3 = self.smooth2(p3)
p2 = self.smooth3(p2)
return p2, p3, p4, p5
点个赞再走呗!!
