Go语言入门分享
简介: Go语言出自Ken Thompson、Rob Pike和Robert Griesemer之手,起源于2007年,并在2009年正式对外发布。Go的主要目标是“兼具Python等动态语言的开发速度和C/C++等编译型语言的性能与安全性”,旨在不损失应用程序性能的情况下降低代码的复杂性,具有“部署简单、并发性好、语言设计良好、执行性能好”等优势。

作者 | 赋行
来源 | 阿里技术公众号
前言
曾经我是一名以Java语言为主的开发者,做过JavaWeb相关的开发,后来转Android,还是离不开Java,直到转去做大前端了,其实也就是一直在用JS写业务。如今由于个人发展原因,来到阿里云,由于项目需要就撸起了Go语言;多年编程经验告诉我,语言只是工具罢了,重要的还是其思想与逻辑,所以只需学学语法就好了,于是我便三天入门Go,期间主要用Java和JS来类比,语法变化之大,差点让我从入门到放弃了!其实,还真不是学习语法就好了呢,其中包含了很多Go的设计理念。正所谓好记性不如敲烂键盘,学过的东西,还是要沉淀沉淀,也可以分享出来一起探讨,更有助于成长,于是我就简单记录了一下我的Go语言入门学习笔记。
一 简介
Go语言出自Ken Thompson、Rob Pike和Robert Griesemer之手,起源于2007年,并在2009年正式对外发布,其实都是Google的,设计Go语言的初衷都是为了满足Google的需求。Go的主要目标是“兼具Python等动态语言的开发速度和C/C++等编译型语言的性能与安全性”,旨在不损失应用程序性能的情况下降低代码的复杂性,具有“部署简单、并发性好、语言设计良好、执行性能好”等优势。最主要还是为了并发而生,并发是基于goroutine的,goroutine类似于线程,但并非线程,可以将goroutine理解为一种虚拟线程。Go语言运行时会参与调度goroutine,并将goroutine合理地分配到每个CPU中,最大限度地使用CPU性能。
二 环境
我们玩Java的时候需要下载JDK,类似于此,用Go开发也需要下载Go,里面提供各种develop-kit、library以及编译器。在官网下载mac版本pkg后直接安装,最后用 go version 命令验证版本:

然后就是设置这两个环境变量,mac系统是在 .bash_profile 文件里面:
export GOROOT=/usr/local/go
export GOPATH=$HOME/go- GOROOT:表示的是Go语言编译、工具、标准库等的安装路径,其实就相当于配置JAVA_HOME那样。
- GOPATH:这个和Java有点不一样,Java里并不需要设置这个变量,这个表示Go的工作目录,是全局的,当执行Go命令的时候会依赖这个目录,相当于一个全局的workspace。一般还会把$GOPATH/bin设置到PATH目录,这样编译过的代码就可以直接执行了。
1 纯文本开发
编写代码,可以保存在任意地方,例如新建一个helloworld目录,创建hello.go文件:
package main
import "fmt"
func main() {
fmt.Println("hello, world")
}然后执行 go build hello.go 就可以编译出hello文件,在./hello就可以执行了;或者直接 go run hello.go 合二为一去执行。执行这个命令并不需要设置环境变量就可以了。看起来和c差不多,但是和Java不一样,运行的时候不需要虚拟机。早期的GO工程也是使用Makefile来编译,后来有了强大的命令 go build、go run,可以直接识别目录还是文件。

2 GoLand
自动import,超爽的体验!不用按command + /了!
运行项目需要设置build config,和Android、Java的都差不多,例如创建一个hello-goland项目:
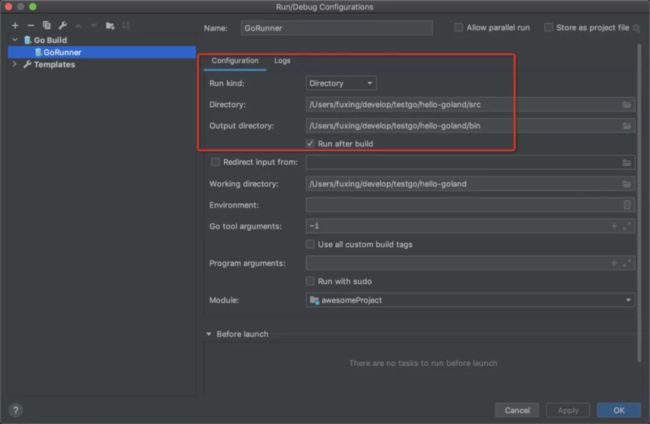
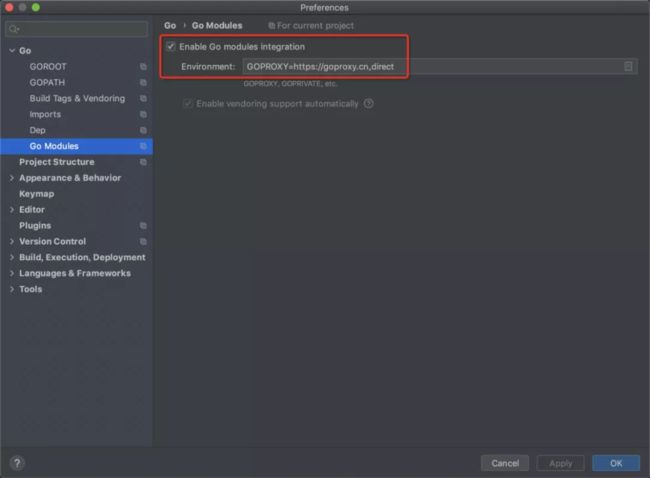
导入go module项目的时候需要勾选这项,否则无法像maven/gradle那样sync下载依赖:
3 VSCODE
直接搜索Go插件,第一个最多安装量的就是了,我还没用过所以不太清楚如何。
三 工程结构
在设置GOPATH环境变量的时候,这个目录里面又分了三个子目录bin、pkg、src,分别用于存放可执行文件、包文件和源码文件。当我们执行Go命令的时候,如果我们指定的不是当前目录的文件或者绝对路径的目录的话,就会去GOPATH目录的去找。这样在GOPATH目录创建了xxx的目录后,就可以在任意地方执行 go build xx 命令来构建或者运行了。
pkg目录应该是在执行 go install 后生成的包文件,包括.a这样的文件,相当于一个归档。
├── bin
│ ├── air
│ ├── govendor
│ ├── swag
│ └── wire
├── pkg
│ ├── darwin_amd64
│ ├── mod
│ └── sumdb
└── src
├── calc
├── gin-blog
├── github.com
├── golang.org
├── google.golang.org
├── gopkg.in
└── simplemath这样对于我们具体项目来说并不好,没有Workspace的概念来隔离每个项目了,所以我觉得这个GOPATH目录放的应该是公用的项目,例如开源依赖的。我们在开发过程中,也会下载很多的依赖,这些依赖都下载到这个目录,和我们的项目文件混在一起了。
另外,通过IDE可以设置project的GOPATH,相当于在执行的时候给GOPATH增加了一个目录变量,也就是说,我们创建一个项目,然后里面也有bin、src、pkg这三个目录,和GOPATH一样的,本质上,IDE在运行的时候其实就是设置了一下GOPATH:
GOPATH=/Users/fuxing/develop/testgo/calc-outside:/Users/fuxing/develop/go #gosetup
Go语言在寻找变量、函数、类属性及方法的时候,会先查看GOPATH这个系统环境变量,然后根据该变量配置的路径列表依次去对应路径下的src目录下根据包名查找对应的目录,如果对应目录存在,则再到该目录下查找对应的变量、函数、类属性和方法。
其实官方提供了Go Modules的方法更好解决。
1 Go Modules
从Go 1.11版本开始,官方提供了Go Modules管理项目和依赖,从1.13版本开始,更是默认开启了对Go Modules的支持,使用Go Modules的好处是显而易见的 —— 不需要再依赖GOPATH,你可以在任何位置创建Go项目,并且在国内,可以通过 GOPROXY 配置镜像源加速依赖包的下载。也就是说,创建一个项目就是一个mod,基本上目前Go开源项目都是这样做的。其实就是类似于Maven和Gradle。
// 创建mod项目,也是可以用IDE来new一个mod项目的:
go mod init calc-mod
// 一般开源在github上面的项目名字是这样的;和maven、gradle不一样的是,开发完成根本不需要发布到仓库!只要提交代码后打tag就可以了
go mod init github.com/fuxing-repo/fuxing-module-name
// 创建一个模块:执行这个命令主要是多了一个go.mod文件,里面就一行内容:
module calc-mod
// import以后,执行下载依赖命令,不需要编辑go.mod文件。依赖会下载到GOPATH/pkg/mod目录
go list用GoLand来打开不同的项目,显示依赖的外部库是不一样的,如果是用GOPATH创建的项目,需要用命令下载依赖包到GOPATH:
go get -u github.com/fuxing-repo/fuxing-module-name


四 语法
1 包:Package 和 Import
Java里面的包名一般是很长的,和文件夹名称对应,作用就是命名空间,引入的时候需要写长长的一串,也可以用通配符:

Go里面一般的包名是当前的文件夹名称,同一个项目里面,可以存在同样的包名,如果同时都需要引用同样包名的时候,就可以用alias区分,类似于JS那样。一般import的是一个包,不像Java那样import具体的类。同一个包内,不同文件,但是里面的东西是可以使用的,不需要import。这有点类似于C的include吧。如果多行的话,用括号换行包起来。


Go语言中,无论是变量、函数还是类属性及方法,它们的可见性都是与包相关联的,而不是类似Java那样,类属性和方法的可见性封装在对应的类中,然后通过 private、protected 和 public 这些关键字来描述其可见性,Go语言没有这些关键字,和变量和函数一样,对应Go语言的自定义类来说,属性和方法的可见性根据其首字母大小写来决定,如果属性名或方法名首字母大写,则可以在其他包中直接访问这些属性和方法,否则只能在包内访问,所以Go语言中的可见性都是包一级的,而不是类一级的。
在Java里面,只有静态,或者对象就可以使用点运算符,而且是极其常用的操作,而在Go里面,还可以用一个包名来点,这就是结合了import来使用,可以点出一个函数调用,也可以点出一个结构体,一个接口。另外区别于C,不管是指针地址,还是对象引用,都是用点运算符,不需要考虑用点还是箭头了!

入口的package必须是main,否则可以编译成功,但是跑不起来:
Compiled binary cannot be executed.
原因就是找不到入口函数,跟C和Java一样吧,也需要main函数。
2 变量
- 用 var 关键字修饰(类似于JS),有多个变量的时候用括号 () 包起来,默认是有初始化值的,和Java一样。
- 如果初始化的时候就赋值了那可以不需要 var 来修饰,和Java不同的是变量类型在变量后面而不是前面,不过需要 := 符号。
- 最大的变化就是类型在变量后面!
- 语句可以省略分号 ;
var v1 int = 10 // 方式一,常规的初始化操作
var v2 = 10 // 方式二,此时变量类型会被编译器自动推导出来
v3 := 10 // 方式三,可以省略 var,编译器可以自动推导出v3的类型
//java
private HashMap mBlockInfo; 多重赋值
i, j = j, i可以实现变量交换,有点像JS的对象析构,但是其实不一样。有了这个能力,函数是可以返回多个值了!
匿名变量
用 _ 来表示,作用就是可以避免创建定义一些无意义的变量,还有就是不会分配内存。
指针变量
和C语言一样的,回想一下交换值的例子即可,到底传值和传址作为参数的区别是啥。
Go语言之所以引入指针类型,主要基于两点考虑,一个是为程序员提供操作变量对应内存数据结构的能力;另一个是为了提高程序的性能(指针可以直接指向某个变量值的内存地址,可以极大节省内存空间,操作效率也更高),这在系统编程、操作系统或者网络应用中是不容忽视的因素。
指针在Go语言中有两个使用场景:类型指针和数组切片。
作为类型指针时,允许对这个指针类型的数据进行修改指向其它内存地址,传递数据时如果使用指针则无须拷贝数据从而节省内存空间,此外和C语言中的指针不同,Go语言中的类型指针不能进行偏移和运算,因此更为安全。
变量类型
Go语言内置对以下这些基本数据类型的支持:
- 布尔类型:bool
- 整型:int8、byte、int16、int、uint、uintptr 等
- 浮点类型:float32、float64
- 复数类型:complex64、complex128
- 字符串:string
- 字符类型:rune,本质上是uint32
- 错误类型:error
此外,Go语言也支持以下这些复合类型:
- 指针(pointer)
- 数组(array)
- 切片(slice)
- 字典(map)
- 通道(chan)
- 结构体(struct)
- 接口(interface)
还有const常量,iota这个预定义常量用来定义枚举。可以被认为是一个可被编译器修改的常量,在每一个const关键字出现时被重置为0,然后在下一个const出现之前,每出现一次iota,其所代表的数字会自动增1。
const (
Sunday = iota
Monday
Tuesday
Wednesday
Thursday
Friday
Saturday
numberOfDays
)类型强转
v1 := 99.99
v2 := int(v1) // v2 = 99
v1 := []byte{'h', 'e', 'l', 'l', 'o'}
v2 := string(v1) // v2 = hello
//字符相关的转化一般用strconv包
v1 := "100"
v2, err := strconv.Atoi(v1) // 将字符串转化为整型,v2 = 100
v3 := 100
v4 := strconv.Itoa(v3) // 将整型转化为字符串, v4 = "100"
//结构体类型转换
//类型断言
//x.(T) 其实就是判断 T 是否实现了 x 接口,如果实现了,就把 x 接口类型具体化为 T 类型;
claims, ok := tokenClaims.Claims.(*jwt.StandardClaims)数组与切片
//定义数组
var a [8]byte // 长度为8的数组,每个元素为一个字节
var b [3][3]int // 二维数组(9宫格)
var c [3][3][3]float64 // 三维数组(立体的9宫格)
var d = [3]int{1, 2, 3} // 声明时初始化
var e = new([3]string) // 通过 new 初始化
var f = make([]string, 3) // 通过 make初始化
//初始化
a := [5]int{1,2,3,4,5}
b := [...]int{1, 2, 3}
//切片
b := []int{} //数组切片slice就是一个可变长数组
c := a[1:3] // 有点类似于subString,或者js.slice
d := make([]int, 5) //make相当于,new、alloc,用来分配内存
//数组的长度
length := len(a)
//添加一个元素
b = append(b, 4)字典
其实就是Java里的map,使用上语法有很多不同。
var testMap map[string]int
testMap = map[string]int{
"one": 1,
"two": 2,
"three": 3,
}
//还可以这样初始化:
var testMap = make(map[string]int) //map[string]int{}
testMap["one"] = 1
testMap["two"] = 2
testMap["three"] = 3make和new
// The make built-in function allocates and initializes an object of type
// slice, map, or chan (only). Like new, the first argument is a type, not a
// value. Unlike new, make's return type is the same as the type of its
// argument, not a pointer to it. The specification of the result depends on
// the type:
// Slice: The size specifies the length. The capacity of the slice is
// equal to its length. A second integer argument may be provided to
// specify a different capacity; it must be no smaller than the
// length. For example, make([]int, 0, 10) allocates an underlying array
// of size 10 and returns a slice of length 0 and capacity 10 that is
// backed by this underlying array.
// Map: An empty map is allocated with enough space to hold the
// specified number of elements. The size may be omitted, in which case
// a small starting size is allocated.
// Channel: The channel's buffer is initialized with the specified
// buffer capacity. If zero, or the size is omitted, the channel is
// unbuffered.
func make(t Type, size ...IntegerType) Type
// The new built-in function allocates memory. The first argument is a type,
// not a value, and the value returned is a pointer to a newly
// allocated zero value of that type.
func new(Type) *Type区别就是返回值和参数不同,一个是值,一个是指针,slice、chan、map只能用make,本身就是指针。其他make、new都行。
神奇的nil
Java里面用null比较舒服,直接就判空了,除了在string类型的时候,还要判断字符为 "",但是Go里面的string要判断为空就简单一点,不能判断nil,只能判断 ""。然而Go里面的nil却和null不一样,其实是和JS里面 ==、=== 很像。
nil也是有类型的。
func Foo() error {
var err *os.PathError = nil
// …
return err //实际返回的是[nil, *os.PathError]
//return nil //正确的方式是直接return nil 实际返回的是[nil, nil]
}
func main() {
err := Foo()
fmt.Println(err) //
fmt.Println(err == nil) // false
fmt.Println(err == (*os.PathError)(nil)) //true
} 根对象:Object
在Java里面,如果不用多态,没有接口,父类,超类的话,就用Object作为根对象,在Go里面,如果函数参数不知道用什么类型,通常会用 interface{},这是个空接口,表示任意类型,因为不是弱类型语言,没有any类型,也不是强面向对象语言,没有Object,所以就有这个空接口的出现。

3 语句
比较大的一个特点就是能不用括号的地方都不用了。
控制流程
if语句的判断条件都没有了括号包起来,还可以前置写变量初始化语句,类似于for循环,左花括号 { 必须与 if 或者 else 处于同一行。

switch语句变得更强大了,有这些变化:
- switch关键字后面可以不跟变量,这样case后面就必须跟条件表达式,其实本质上就是美化了if-else-if。
- 如果switch后面跟变量,case也变得强大了,可以出现多个结果选项,通过逗号分隔。
- swtich后面还可以跟一个函数。
- 不需要用break来明确退出一个case,如果要穿透执行一层,可以用 fallthrough 关键字。
score := 100
switch score {
case 90, 100:
fmt.Println("Grade: A")
case 80:
fmt.Println("Grade: B")
case 70:
fmt.Println("Grade: C")
case 60:
case 65:
fmt.Println("Grade: D")
default:
fmt.Println("Grade: F")
}
s := "hello"
switch {
case s == "hello":
fmt.Println("hello")
fallthrough
case s == "xxxx":
fmt.Println("xxxx")
case s != "world":
fmt.Println("world")
}
//output:hello xxxx循环流程
去掉了 while、repeat 这些关键字了,只保留了 for 这个关键字,其实用起来差不多。break , continue 这些关键字还是有的。
//通用的用法
for i := 1; i <= 5; i++ {
fmt.Println(i)
}
//类似于while的用法
a := 1
for a <= 5 {
fmt.Println(a)
a ++
}
//死循环
for {
// do something
}
for ;; {
// do something
}
//类似java for-each的用法
listArray := [...]string{"xiaobi", "xiaoda", "xiaoji"}
for index, item := range listArray {
fmt.Printf("hello, %d, %s\n", index, item)
}
//java
for (String item : someList) {
System.out.println(item);
}跳转流程
Go很神奇的保留了一直被放弃的goto语句,记得是Basic、Pascal那些语言才会有,不知道为啥。
i := 1
flag:
for i <= 10 {
if i%2 == 1 {
i++
goto flag
}
fmt.Println(i)
i++
}defer流程有点像Java里面的finally,保证了一定能执行,我感觉底层也是goto的实现吧。在后面跟一个函数的调用,就能实现将这个xxx函数的调用延迟到当前函数执行完后再执行。
这是压栈的变量快照实现。
func printName(name string) {
fmt.Println(name)
}
func main() {
name := "go"
defer printName(name) // output: go
name = "python"
defer printName(name) // output: python
name = "java"
printName(name) // output: java
}
//output:
java
python
go
//defer后于return执行
var name string = "go"
func myfunc() string {
defer func() {
name = "python"
}()
fmt.Printf("myfunc 函数里的name:%s\n", name)
return name
}
func main() {
myname := myfunc()
fmt.Printf("main 函数里的name: %s\n", name)
fmt.Println("main 函数里的myname: ", myname)
}
//output:
myfunc 函数里的name:go
main 函数里的name: python
main 函数里的myname: go4 函数
- 关键字是 func,Java则完全没有 function 关键字,而是用 public、void 等等这样的关键字,JS也可以用箭头函数来去掉 function 关键字了。
- 函数的花括号强制要求在首行的末尾。
- 可以返回多个值!返回值的类型定义在参数后面了,而不是一开始定义函数就需要写上,跟定义变量一样,参数的类型定义也是一样在后面的,如果相同则保留最右边的类型,其他省略。
- 可以显式声明了返回值就可以了,必须每个返回值都显式,就可以省略 return 变量。
//一个返回值
func GetEventHandleMsg(code int) string {
msg, ok := EventHandleMsgMaps[code]
if ok {
return msg
}
return ""
}
//多个返回值
func GetEventHandleMsg(code int) (string, error) {
msg, ok := EventHandleMsgMaps[code]
if ok {
return msg, nil
}
return "", nil
}
//不显式return变量值
func GetEventHandleMsg(code int) (msg string, e error) {
var ok bool
msg, ok = EventHandleMsgMaps[code]
if ok {
//do something
return
}
return
}匿名函数和闭包
在Java里面的实现一般是内部类、匿名对象,不能通过方法传递函数作为参数,只能传一个对象,实现接口。
Go则和JS一样方便,可以传递函数,定义匿名函数。
//传递匿名函数
func main() {
i := 10
add := func (a, b int) {
fmt.Printf("Variable i from main func: %d\n", i)
fmt.Printf("The sum of %d and %d is: %d\n", a, b, a+b)
}
callback(1, add);
}
func callback(x int, f func(int, int)) {
f(x, 2)
}
//return 匿名函数
func main() {
f := addfunc(1)
fmt.Println(f(2))
}
func addfunc(a int) func(b int) int {
return func(b int) int {
return a + b
}
}不定参数
和Java类似,不同的是在调用是也需要用 ... 来标识。
//定义
func SkipHandler(c *gin.Context, skippers ...SkipperFunc) bool {
for _, skipper := range skippers {
if skipper(c) {
return true
}
}
return false
}
//调用
middlewares.SkipHandler(c, skippers...)五 面向对象
在C语言里面经常会有用到别名的用法,可以用 type 类起一个别名,很常用,特别是在看源码的时候经常出现:
type Integer int
1 类
没有 class 的定义,Go里面的类是用结构体来定义的。
type Student struct {
id uint
name string
male bool
score float64
}
//没有构造函数,但是可以用函数来创建实例对象,并且可以指定字段初始化,类似于Java里面的静态工厂方法
func NewStudent(id uint, name string, male bool, score float64) *Student {
return &Student{id, name, male, score}
}
func NewStudent2(id uint, name string, male bool, score float64) Student {
return Student{id, name, male, score}
}2 成员方法
定义类的成员函数方法比较隐式,方向是反的,不是声明这个类有哪些成员方法,而是声明这个函数是属于哪个类的。声明语法就是在 func 关键字之后,函数名之前,注意不要把Java的返回值定义给混淆了!
//这种声明方式和C++一样的,这个就是不是普通函数了,而是成员函数。
//注意到的是,两个方法一个声明的是地址,一个声明的是结构体,两个都能直接通过点操作。
func (s Student) GetName() string {
return s.name
}
func (s *Student) SetName(name string) {
s.name = name
}
//使用
func main() {
//a是指针类型
a := NewStudent(1, "aa", false, 45)
a.SetName("aaa")
fmt.Printf("a name:%s\n", a.GetName())
b := NewStudent2(2, "bb", false, 55)
b.SetName("bbb")
fmt.Printf("b name:%s\n", b.GetName())
}
//如果SetName方法和GetName方法归属于Student,而不是*Student的话,那么修改名字就会不成功
//本质上,声明成员函数,就是在非函数参数的地方来传递对象、指针、或者说是引用,也就是变相传递this指针
//所以才会出现修改名字不成功的case3 继承
没有 extend 关键字,也就没有了继承,只能通过组合的方式来实现。组合就解决了多继承问题,而且多继承的顺序不同,内存结构也不同。
type Animal struct {
name string
}
func (a Animal) FavorFood() string {
return "FavorFood..."
}
func (a Animal) Call() string {
return "Voice..."
}
type Dog struct {
Animal
}
func (d Dog) Call() string {
return "汪汪汪"
}
//第二种方式,在初始化就需要指定地址,其他都没变化
type Dog2 struct {
*Animal
}
func test() {
d1 := Dog{}
d1.name = "mydog"
d2 := Dog2{}
d2.name = "mydog2"
//结构体是值类型,如果传入值变量的话,实际上传入的是结构体值的副本,对内存耗费更大,
//所以传入指针性能更好
a := Animal{"ddog"}
d3 := Dog{a}
d4 := Dog2{&a}
}这种语法并不是像Java里面的组合,使用成员变量,而是直接引用Animal并没有定义变量名称(当然也是可以的,不过没必要了),然后就可以访问Animal中的所有属性和方法(如果两个类不在同一个包中,只能访问父类中首字母大写的公共属性和方法),还可以实现方法重写。
4 接口
Java的接口是侵入式的,指的是实现类必须明确声明自己实现了某个接口。带来的问题就是,如果接口改了,实现类都必须改,所以以前总是会有一个抽象类在中间。
//定义接口:
type Phone interface {
call()
}
//实现接口:
type IPhone struct {
name string
}
func (phone IPhone) call() {
fmt.Println("Iphone calling.")
}Go的接口是非侵入式的,因为类与接口的实现关系不是通过显式声明,而是系统根据两者的方法集合进行判断。一个类必须实现接口所有的方法才算是实现了这个接口。接口之间的继承和类的继承一样,通过组合实现,多态的实现逻辑是一样的,如果接口A的方法列表是接口B的方法列表的子集,那么接口B可以赋值给接口A。
六 并发编程
目前并发编程方面还没学习多少,就简单从网上摘了这一个经典的生产者消费者模型例子来初步感受一下,后续深入学习过后再进行分享。

// 数据生产者
func producer(header string, channel chan<- string) {
// 无限循环, 不停地生产数据
for {
// 将随机数和字符串格式化为字符串发送给通道
channel <- fmt.Sprintf("%s: %v", header, rand.Int31())
// 等待1秒
time.Sleep(time.Second)
}
}
// 数据消费者
func customer(channel <-chan string) {
// 不停地获取数据
for {
// 从通道中取出数据, 此处会阻塞直到信道中返回数据
message := <-channel
// 打印数据
fmt.Println(message)
}
}
func main() {
// 创建一个字符串类型的通道
channel := make(chan string)
// 创建producer()函数的并发goroutine
go producer("cat", channel)
go producer("dog", channel)
// 数据消费函数
customer(channel)
}
//output:
dog: 1298498081
cat: 2019727887
cat: 1427131847
dog: 939984059
dog: 1474941318
cat: 911902081
cat: 140954425
dog: 336122540七 总结
这只是一个简单入门,其实Go还有很多很多东西我没有去涉及的,例如context、try-catch、并发相关(如锁等)、Web开发相关的、数据库相关的。以此贴开始,后续继续学习Go语言分享。
原文链接
本文为阿里云原创内容,未经允许不得转载。