C面试题--汇总
目录
- 一、C语言基础面试题
-
- 1. gcc编译器编译的完整流程,分别有什么作用?
- 2.什么是回调函数?
- 3.地址能否使用 printf函数中的 %u形式打印?
- 4.结构体与共用体(联合体)的区别
- 5. static、const、volatile关键字有什么作用?
-
- static:静止、静态
- const:只读
- volatile :防止编译器优化
- 6.声明变量和定义变量的区别
- 7.赋值与赋初值有什么不同?
- 8.局部变量和全局变量能否重名
- 9.如何引用一个已经定义过的外部变量
- 10.全局变量和局部变量的存储方式有什么区别?
- 10-附加:内存的分段
- 11. const 与 # define 相比有何优点?
- 12.数组与指针的区别是什么?
- 13.为什么作为函数形参的数组和指针可以互换?
- 14.形参和实参有什么区别?
- 15.指针、数组和地址之间的关系是的什么?
- 16. void指针就是空指针吗?他有什么作用?
- 17.与内存息息相关的重要概念有哪些?
- 18. #include<> 和 #include”” 有什么区别?
- 18.0 gcc附加
- 19. x=x+1 , x+=1 , x++ 哪个效率高?
- 20.为无符号类型变量赋值时,数据类型应怎样转换?
- 二、Linux基础
-
- 1. 字符设备、块设备、管道等在Linux下有个统称叫什么?
- 2.查看一个文件的类型常用的有几种方式
-
- 引申
- 3.Linux下常用的安装工具?
- 4.分别解释shell命令、shell、shell脚本
- 5.printf与scanf操作的是否是同一个文件
- 6. Linux常用的文件系统类型?如何查看文件系统类型?
- 7. windows下有没有文件系统?文件系统有何作用?
- 8.头文件和库文件一般在哪个路径下?
- 9.系统如何区别同名的文件
- 10.系统如何区别不同的进程。
- 11.查看文件有哪些命令
- 12.如修改文件的权限
- 13.什么是符号链接?
- 三、数据结构
-
- 1.数据结构主要研究的是什么?
- 2.数组和链表的区别
- 3.快速排序的算法
- 4. hash查找的算法
- 5.判断单链表是否有环
- 6.判断一个括号字符串是否匹配正确,如果括号有多种,怎么做?如(([]))正确,[[(()错误
- 四. IO进程
-
- 1.标准IO和文件IO区别?
-
- 文件IO-系统调用
- 标准IO-库函数
- 2.简述流指针?--文件指针、文件流指针
- 3.简述系统调用?
- 3.1 简述库函数
- 4.简述静态库和动态库的区别?
- 5.如何将程序执行直接运行于后台?
-
- 前台后台切换
- 6.进程的状态
- 7.什么是僵尸进程?
- 7-8.孤儿进程
- 8.简述创建子进程中的写时拷贝技术?
- 9.多线程较多进程的优势?
- 10.线程池的使用?----再看看
- 11.线程池的组成部分?
- 12.线程的同步互斥机制?
- 13.简述互斥锁的实现原理?
- 14.简述死锁的情景?
- 15.简述信号量的原理?
- 16.简述进程的通信机制?
- 17.管道的通信原理?
- 18.用户进程对信号的响应方式?
- 19.共享内存通信原理?
- 五. 网络编程
-
- 1. ISO七层网络通信结构和TCP/IP四层网络通信结构
-
- ISO七层网络模型
- TCP/IP四层网络模型
- 2. tcp通信的优缺点
- 2.3 TCP为什么要进行三次握手
- 3. udp通信的优缺点
- 4. pool与select的区别(select poll epoll的区别)
- select、poll、epoll机制的特点
- 5. io模型有哪几种
- 6. 如何实现tcp并发服务器
- 7. 网络超时检测的本质和实现方式
- 8. TCP 网络编程流程
- 9. UDP网络编程流程
- 10. UDP本地通信需要注意哪些方面
- 11. 怎么修改文件描述符的标志位--文件状态标志位
- 12. sqlite数据库的基本使用,包括增删改查
- 13. 基于UDP的聊天室如何实现数据群发
- 14. 在线词典如何实现查询单词
- 15. TCP和UDP的区别
-
- TCP与UDP区别总结:
- 16. OSI七层网络模式,每层的主要作用,主要的协议
- 17. TCP 粘包
- 18. TCP的三次握手和四次挥手分别作用,主要做什么
- 19. 如何实现并发服务器,并发服务器的实现方式有什么异同
- 20.线程和进程的区别,多线程和多进程编程的特点
- 六.C++
-
- 1. new、delete、malloc、free关系
- 2. delete与 delete []区别
- 3. C++有哪些性质(面向对象特点)
- 4. 子类析构时要调用父类的析构函数吗?
- 5. 多态,虚函数,纯虚函数
- 6. 求下面函数的返回值(微软)----特么的题呢--
- 7. 什么是“引用”?声明和使用“引用”要注意哪些问题?
- 7-8. 引用与指针的区别
- 8. 将“引用”作为 函数参数 有哪些特点?
- 9. 在什么时候需要使用“常引用”?
- 10. 将“引用”作为函数返回值类型的格式、好处和需要遵守的规则?
- 11. 结构与联合有和区别?---C基础第四题
- 12. 试写出程序结果:
- 13. 重载(overload)和重写(overried,有的书也叫做“覆盖”)的区别?
- 14. 有哪几种情况只能用intialization list(初始化列表) 而不能用assignment?
- 15. C++是不是类型安全的?
- 16. main 函数执行以前,还会执行什么代码?
- 17. 描述内存分配方式以及它们的区别?
- 18. 分别写出BOOL,int,float,指针类型的变量a 与“零”的比较语句。
- 19. 请说出const与#define 相比,有何优点?--C基础-11题
- 20. 简述数组与指针的区别?--C基础-12题
- 21. int (*s[10])(int) 表示的是什么?
- 22. 栈内存与文字常量区
- 23. 将程序跳转到指定内存地址
- 24. int id[sizeof(unsigned long)];这个对吗?为什么?
- 27. 内存的分配方式有几种?---上面 17
- 28. 基类的析构函数不是虚函数,会带来什么问题?
- 29. 全局变量和局部变量有什么区别?是怎么实现的?操作系统和编译器是怎么知道的?
- 七. ARM体系结构编程
-
- 1. 简单描述一下ARM处理器的特点,至少说出5个以上的特点。
- 2. ARM内核有多少种工作模式?请写出这些工作模式的英文缩写,有几种异常模式,有几种特权模式,cortex_a系列有几种特权模式,几种工作模式
- 3. ARM内核有多少个寄存器,简述一下
- 4. ARM通用寄存器中,有3个寄存器有特殊功能和作用,请写出它们的名字和作用。
- 5. 请描述一下CPSR寄存器中相关Bit的情况和作用。
- 6. 什么是立即数?立即数的本质是什么
- 7. 请问BL指令跳转时LR寄存器保存的是什么内容?并请简述原因
- 8. 请描述一下什么是处理器现场,如何进行保存现场?
- 9. ATPCS默认使用的是什么栈?--满减栈(ARM也是)
- 10. 什么是满栈、空栈,什么是增栈、减栈?
- 11. 请写出一条完整的ARM软件中断指令,并简要描述其作用。
- 12. 请描述一下ARM体系中异常向量表的概念。
- 13. 请写出一个ARM程序生成的bin文件映像中包含哪些内容?
- 14. 请举例说明在ARM处理器上进行一次中断处理和中断异常处理的差异。
- 15. 请简述异常中断处理发生时,是通过什么完成初始化步骤,这些初始化的具体步骤是什么?
- 16. uboot的主要作用
- 17. uboot是怎样引导启动内核的?
- 18. uboot的启动过程的重要干了什么
- 19. bootcmd和bootargs两个uboot环境变量的作用
- 20. linux内核的启动过程
- 21. uImage,zImage,vmlinux的区别
- 22. Kconfig,.config,Makefile三个文件之间的关系
- 八. 系统移植
-
- 1. Linux内核启动流程---同上 七.20
- 2. 什么是bootloader?在嵌入式系统当中bootloader的作用是什么?
- 3. 为什么汇编语言对硬件平台有依赖性而C语言却可以不依赖硬件平台?
- 4. 什么叫做交叉编译?
- 5. Linux平台下的可执行文件是什么格式?
- 6. 什么叫做反汇编?
- 7. 简述nfs服务的概念与作用?
- 8. 简述一个装有linux内核的开发板的启动过程?
- 9. 简述uboot的主要功能有哪些?
- 10. uboot如何设置环境变量?
- 11. 简述uboot中bootcmd环境变量的作用?--七.19
- 12. 简述uboot中bootargs环境变量的作用?--七.19
- 13. 简述什么叫平台相关代码什么叫平台无关代码?
- 14.如何理解linux/uboot支持各种硬件平台?
- 15. 如何配置uboot使其适合特定的开发板平台?
- 16. 如何编译uboot生成二进制文件?
- 17. 简述uboot的启动过程?
- 18. 操作系统的作用有哪些?
- 19. 如何配置linux源码使其适合特定的处理器?
- 20. 在make menuconfig界面下有些驱动可以被选成三种状态即“Y”,“N”,“M”这三种状态分别是什么含义?
- 21. 如何编译被选中为“M”选项的驱动模块?
- 22. 简述设备树的作用?
- 23. 编写设备树文件的主要依据是什么?
- 24. 简述如何将一个内核源码中已有的驱动程序编译到内核中?
- 25. 简述如何将一个自己编写的驱动程序编译到内核中?
- 26.在内核启动过程中如果控制台已经初始化我们一般采用什么方式来调试内核?
- 27. linux内核在启动过程中遇到什么情况会打印系统崩溃报告Oops?
- 28. linux内核在启动过程中遇到某些问题会打印系统崩溃报告Oops,报告中主要打印哪些内容?
- 29. 简述什么叫文件系统?什么叫根文件系统?
- 30. 开发板中为什么一般不需要安装静态库?
- 九. 驱动开发
-
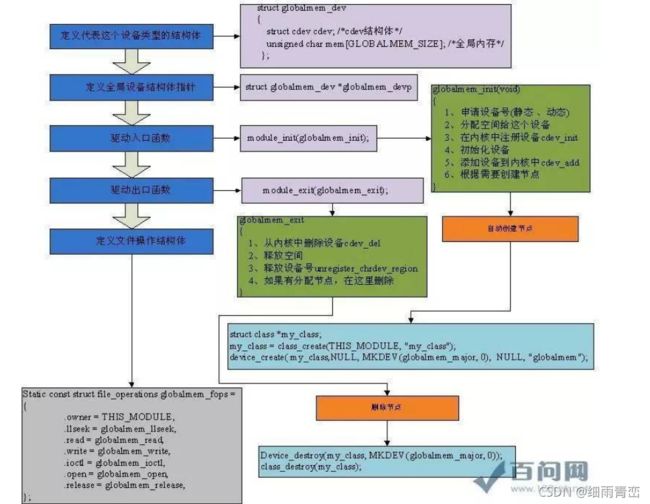
- 1. 什么是模块?
- 2. 驱动类型有几种
- 3. 字符设备驱动框架编程流程?
- 4. 什么是并发,驱动中产生竞态的原因有哪些?
- 5. 解决竞态的途径有哪些?分别有什么特点?
- 6. 驱动中IO模型有几种?
- 7. 设计linux设备模型的主要作用?
- 8. 字符设备驱动框架与linux设备模型是否矛盾?
- 9. platform架构分别分为哪个部分?他们通过什么进行匹配
- 10. 设备树与platform架构是否有矛盾?
- 11. 为什么要将中断分为上下半部?上下半部机制有哪些?
- 12. 工作队列与tasklet的区别?
- 13. 内核中内存分配函数分别有哪些?分别有什么特点?
- 14. 内核调试
-
- a.可以使用printk打印内核信息,printk的调试级别如下
- b. gdb 和 addr2line 调试内核模块
- c. 使用函数BUG_ON(),BUG()和dump_stack()调试内核
- 15. 字符设备驱动的框架
- 16. 字符设备和块设备和网络设备的区别
- 17. 并发和竞态概念,那些情况会出现竟态,解决竟态的方法,以及区别,使用场景。---上面第4题
- 18. 自旋锁和信号量的区别
- 19. 谈谈你对中断上下文,进程上下文的理解
- 20. 中断低半部主要做了什么
- 21. Platfprm平台总线驱动模型
- 22. IIC子系统驱动框架
- 23. 输入子系统驱动框架
-
- 子系统的组成
- 输入子系统的事件处理机制示意图
- 输入子系统剖析
一、C语言基础面试题
1. gcc编译器编译的完整流程,分别有什么作用?
gcc编译器编译的完整流程有四步,分别是 预处理、 编译、 汇编、 链接
预处理:处理源文件中的#ifndef、#include、#define等预处理命令,该阶段会生成一个中间文件.i
主要进行'宏定义替换','头文件展开','注释删除'等,'不会检查'语法错误
gcc -E hello.c –o #可以使用-E选项生成.i文件
##【注意】不 -o,只会在终端打印一下展开的代码,源文件不会发生改变
编译:gcc把预处理后的'结果'编译成'汇编语言'代码,输入的是.i,编译后生成汇编语言文件.s
会检查语法是否有错 , 整体编译流程:(编译步骤) 语法检查-->词法分析-->语义分析-->统计符号-->汇编(再进行)
gcc -S hello.i –o hello.s #有没有 -o 都会生成对应的 .s 文件
汇编:编译器把编译出来的'汇编语言'汇编成具体CPU上的目标代码('机器代码')。输入汇编代码文件.s,输出目标代码文件.o或.obj , 流程:(汇编步骤)->统计符号-->制作符号表
#将汇编文件生成机器码(编译成二进制文件)
gcc –c hello.s –o hello.o
#-c 表示不链接库,有没有 -o 都会生成对应的.o 文件
链接:把'多个目标代码模块'链接成一个'大的目标代码'模块。输入目标代码文件.0(与其它的目标代码文件、库文件、引导代码),汇集成一个可执行的二进制代码文件
#链接库函数,生成一个可执行文件
gcc hello.o –o hello #不 -o 会生成 a.out 可执行文件
# E S c ---> i s o
2.什么是回调函数?
回调函数就是一个通过'函数指针调用'的函数。所以当'一个函数作为参数'使用的时候,这个函数就是回调函数。
#将函数指针 最为函数的参数 的函数
int (*p)(int,int) ------ > # int my_sub(int a,int b)
一个'函数的参数'是一个'函数指针',在这个函数中'具体调用哪个'函数,'取决于'这个函数调用时,用'哪个函数给形参'的函数指针赋值
3.地址能否使用 printf函数中的 %u形式打印?
%u 是打印无符号的十进制的数字,地址是本身是无符号的16进制的,所以可以打印但是不推荐
还是%p是最标准的
4.结构体与共用体(联合体)的区别
首先结构体与共用体都是'构造类型',它们的'成员变量'都可以定义为'不同类型'的。
结构体可以同时存储多种变量类型,而共同体同一个时间只能存储和使用多个变量类型的一种,当另一时间,变量类型被改变后,原来的变量类型和值将被舍弃。
共用体的作用是同一个数据项可以使用多种格式,可以节省空间。'所有成员共享一块内存空间',每个成员的'首地址相同'
'结构体的大小'是根据每个成员变量的大小的总量确定的,而'共用体的大小'是根据最大的成员变量的大小确定的
5. static、const、volatile关键字有什么作用?
static:静止、静态
1.修饰全局变量:变量只在本模块内可见,'限定作用域',限制'变量只能在本文件'(当前.c)中使用
在定义不需要与其他文件共享的全局变量时,加上static关键字能够有效地降低程序模块之间的耦合,避免不同文件同名变量的冲突,且不会误使用。
2.修饰局部变量:变量在全局数据区分配内存空间,'延长变量的生命周期',到整个程序结束
3.修饰函数:函数的使用方式与全局变量类似,在函数的返回类型前加上static,就是静态函数,'限定作用域',限制'该函数只能在本文件'(当前.c)中使用
静态函数只能在声明它的文件中可见,其他文件不能引用该函数,不同的文件可以使用相同名字的静态函数,互不影响。
const:只读
C编译器中:被const修饰的变量是'只读变量',本质还是变量,
有人称其为常变量,和普通变量的区别在于常变量不能用于左值,其余的用法和普通常量一样。
C++编译器中:被const修饰的变量,变量名和初始值会直接放到符号表中,当使用变量名的时候会直接从符号表中读取其值。相较于C编译器,在C++编译器中const修饰的变量更像是常量。
//const 修饰谁 谁不能变----- 修饰 *p 值不能变,但是指向 可以改变
// ----- 修饰 p p的指向不能变 但是 *p的值 可以改变
const int *p; //值不能变,但是指向 可以改变
int const *p; //值不能变,但是指向 可以改变
int * const p; //p的指向不能变 但是 *p的值 可以改变
const int * const p; //p的指向不能变 但是 *p的值 可以改变
volatile :防止编译器优化
volatile关键字声明的变量,编译器对访问该变量的代码就'不再进行优化',从而可以提供对特殊地址的稳定访问。
用 volatile 声明,该关键字的作用是防止编译器直接在CPU寄存器中获取值,在内存中重新读取
6.声明变量和定义变量的区别
声明'不开辟内存空间',
定义'开辟内存空间'并且也有可能同时为其提供'初始值'。
#注意:定义引用,是开辟地址空间了的
7.赋值与赋初值有什么不同?
赋初值,也就是'初始化',只能在定义的时候操作,只能用'=',形式为
int a = 10;
赋值,是在定义后,改变变量的值,除了=还包括复合赋值语句,如+=、-=等,自加,自减也可以算赋值语句。形式为
a = 200;
#----这种**问题--应该不会有人问吧(自动屏蔽关键字)
8.局部变量和全局变量能否重名
可以,局部优先原则
在C++中,可以通过'命名空间'(匿名空间)来访问重名的全局变量,变量前面加作用域限定符 ::
但是在C语言里,好像是不能,访问全局的重名变量了
9.如何引用一个已经定义过的外部变量
1.用 extern关键字方式:声明一个变量在外部定义
2.用'引用头文件'的方式,可以在不同的C文件中声明同名的全局变量,前提是其中只能有一个C文件中对此变量赋初值,此时连接不会出错。
10.全局变量和局部变量的存储方式有什么区别?
1.'作用域'不同:全局变量的作用域为'整个程序',而局部变量的作用域为'当前函数或循环'
2.'内存存储方式'不同:全局变量存储在'全局数据区'中,局部变量存储在'栈区'
3.'生命期'不同:全局变量的生命期和主程序一样,随'程序的销毁而结束',局部变量在函数内部或循环内部,随'函数的退出'或'循环退出'就不存在了
4.'使用方式'不同:全局变量在声明后程序的'各个部分都可以'用到,但是局部变量只能在'局部使用'。(局部优先)
10-附加:内存的分段
C语言经过编译之后将内存分为以下五个区域
1.栈:由编译器进行管理,自动分配和释放,存放函数调用过程中的各种参数,局部变量,返回值及函数返回地址。操作方式类似数据结构中的栈。
2.堆:用于程序动态申请分配和释放空间。C语言中的malloc和free,C++中的new和delete均是在堆中进行的。正常情况下,程序员申请的空间在使用结束后应该释放,若程序员没有释放空间,则整个程序结束时系统自动回收。
3.全局(静态)存储区:分为DATA段和BSS段。
DATA段(全局初始化区)存放初始化的全局变量和静态变量;
BSS段(全局未初始化区)存放未初始化的全局变量和静态变量。程序运行结束时自动释放。其中,
BSS段在程序执行之前会被系统自动清零,所以未初始化全局变量和静态变量在程序执行之前已经为0。
4.文字常量区:存放常量字符串。程序结束后由系统释放。
5.程序代码区:存放程序的二进制代码。
11. const 与 # define 相比有何优点?
相同点:两者都可以用来定义常量。
不同点:
a.'处理的时期':#define是在编译的'预处理阶段'展开,而const是在'编译'、运行的时候起作用
b.#define只是'简单的字符串替换','没有类型检查'。
而const有对应的数据类型,是要进行判断的,可以避免一些低级的错误
c.就存储方式而言:define'宏定义'时'不会分配内存',#define只是进行展开,有多少地方使用,就替换多少次,它定义的宏常量在内存中有若干个备份;
const常量在定义时会在内存中分配(可以是堆中也可以是栈中),const定义的'只读变量'在程序运行过程中只有一份备份。
总结:const 与 #define 相比有何优点
a.const常量有'数据类型',而宏常量'没有数据类型',编译器可以对前者进行类型安全检查,而后者只进行字符替换,没有类型安全检查,并且在字符替换可能会产生意料不到的错误。
b.有些集成化的调试工具可以对const常量进行测试,但不能对宏常量进行测试。
12.数组与指针的区别是什么?
数组名是一个地址常量 ---> 不可以被赋值,也不可以自增自减,不能偏移
指针是变量所以可以 ++ -- ,可以偏移
对于数组而言,数组名就是一个指针,指向数组的首地址,数组的首地址 和 数组首元素的地址 和 数组名 是同一个地址
13.为什么作为函数形参的数组和指针可以互换?
C语言 形参 中'数组名''实质上'就是'指针变量'。
14.形参和实参有什么区别?
形式参数:在'定义函数'时,函数名后面括号中的变量名为'形式参数'。在函数调用之前,传递给函数的值将被复制到这些形式参数中
实际参数:在'调用函数'时,也就是真正使用一个函数时,函数名后面括号中的参数为'实际参数',函数的调用者提供给函数的参数成为实际参数
15.指针、数组和地址之间的关系是的什么?
数组是保存在一片'连续内存单元'中的,而'数组名'就是这片'连续内存单元'的'首地址',
内存单元的地址就是指针,因此数组名也是一个指针
#数组是由多个数组元素组成,元素按其数组类型的不同,所占连续内存的大小也不同。
一个'数组'的元素的首地址就是其所占连续'内存单元'的'首地址', '指针'变量'既可以指向'一个数组,'也可以指向'一个数组元素。
将'数组名'或'数组的第一个元素'的'地址'赋给指针,指针就指向了一个数组。
如果想使指针变量指向第i个元素,就可以把i元素首地址赋给它。
16. void指针就是空指针吗?他有什么作用?
void指针是一个万能指针,不是空指针
它可以表示任意一个类型的指针(malloc的返回值就是一个 void指针)
空指针一般应用于以下三种情况:
(1) 用空指针终止对递归数组结构的间接引用
(2) 用空指针作为函数调用失败时的返回值
(3) 用空指针作为警戒值
17.与内存息息相关的重要概念有哪些?
(野指针、栈(stack)、堆(heap)、静态区)
野指针:定义了一个指针变量没有进行初始化,该指针指向了一个不确定的空间,这个指针称为野指针
造成野指针的几种情况
a. 定义的指针变量没有被初始化
b. 指针的操作超过可变量的作用范围(越界)
c. 指针被释放或者删除后,没有被置为NULL,然后再次被使用
栈(stack):栈是用来保存局部变量(系统自动申请释放),栈上的内容只在函数的范围内存在,函数运行结束这些内容也会被销毁,栈的特点就是效率高,但空间大小有限
堆(heap):堆是由malloc()、calloc()、等函数或者new操作符获得的内存,由free()函数和delete()函数释放内存、堆的特点就是效率高,程序员手动申请释放,但空间大小有限
#注意:当这个程序结束,在堆区申请的空间也可以被系统释放
静态区:静态区用于保存自动全局变量和static变量,静态区的内容在整个程序中都存在,由编译器在编译的时候分配内存
18. #include<> 和 #include”” 有什么区别?
#include<> 直接在 系统的库中 去寻找需要的头文件库
#include"" 现在当前目录进行查找,如果找不到,再去系统的库里进行寻找
18.0 gcc附加
-I -I ../include #链接库(自己的库)//库的地址 #可以使用 -I 来指示非标准位置的头文件
-i
-L
-l 链接第三方库
19. x=x+1 , x+=1 , x++ 哪个效率高?
x++ 读取x的地址,然后x自增1 x++的效率最高
x+=1 读取等号右边的x的地址,计算x+1的值,将得到的值直接传给左边的x,之前已读过,故省去传值的过程
x=x+1 先读取等号右边的x的地址,计算x+1的值,然后读取等号左边的x地址,最后将等号右边的值传递给等号左边的值
# ++i 效率 比 i++ 更高
1.i++返回的是i的值,++i返回的是i+1的值;
2.i++不能用作左值, ++i 可以用作左值。
20.为无符号类型变量赋值时,数据类型应怎样转换?
隐式类型转换。所有的操作数都自动转换为无符号数。
系统会将低类型会自动转换成高类型进行计算,然后将计算的结果赋值给需要的数据类型

二、Linux基础
1. 字符设备、块设备、管道等在Linux下有个统称叫什么?
Linux 一切皆文件
2.查看一个文件的类型常用的有几种方式
ls -l
file [文件名]
stat [文件名]
引申
//普通文件类型 -
Linux中最多的一种文件类型, 包括 纯文本文件(ASCII);二进制文件(binary);数据格式的文件(data);各种压缩文件.第一个属性为 [-]
//目录文件 d
就是目录, 能用 # cd 命令进入的。第一个属性为 [d],例如 [drwxrwxrwx]
//块设备文件 b
块设备文件 : 就是存储数据以供系统存取的接口设备,简单而言就是硬盘。例如一号硬盘的代码是/dev/hda1等文件。第一个属性为 [b]
//字符设备 c
字符设备文件:即串行端口的接口设备,例如键盘、鼠标等等。第一个属性为 [c]
//套接字文件 s
这类文件通常用在网络数据连接。可以启动一个程序来监听客户端的要求,客户端就可以通过套接字来进行数据通信。第一个属性为 [s],最常在 /var/run目录中看到这种文件类型
//管道文件 p
FIFO也是一种特殊的文件类型,它主要的目的是,解决多个程序同时存取一个文件所造成的错误。FIFO是first-in-first-out(先进先出)的缩写。第一个属性为 [p]
//链接文件 l
类似Windows下面的快捷方式。第一个属性为 [l],例如 [lrwxrwxrwx] 只有软链接文件 才有l
3.Linux下常用的安装工具?
在线安装:sudo apt-get install
离线安装:sudo dpkg
安装软件 : sudo dpkg -i 软件名 (install)
查看已安装软件的版本: sudo dpkg -l 软件名
查看软件安装的路径信息 : sudo dpkg -L 软件名
卸载软件 : sudo dpkg -r 软件名 (软件的配置信息会保留)
完全卸载 : sudo dpkg -P 软件名
4.分别解释shell命令、shell、shell脚本
shell : 命令行解释器(包括sh,csh,ksh,bash,dash等不同版本的语法)
shell命令:是一种解释型语言的命令行语句
shell脚本:本质上是一个文件。 是以.sh 结尾的文件。 里面存放的是shell命令的集合。
5.printf与scanf操作的是否是同一个文件
不是
printf 操作的是标准输出流文件 #--- stdout
scanf 操作的是标准输入流文件 #--- stdin
#还有一个 标准错误输出 --- stderr
6. Linux常用的文件系统类型?如何查看文件系统类型?
Linux常用的文件系统是 ext4,ext3..
查看文件系统类型的命令(以下四个都行)
df -T
parted -l
blkid
lsblk -f
7. windows下有没有文件系统?文件系统有何作用?
有!windows文件系统包括fat16,fat32,ntfs,ntfs5.0,winfs等
作用:负责'管理和存储'文件信息的软件机构称为文件管理系统,简称文件系统。
从系统角度来看,'文件系统'是对'文件存储器空间'进行'组织和分配',负责文件存储并对存入的文件进行保护和检索的系统。
具体地说,它负责为用户建立文件,存入、读出、修改、转储文件,控制文件的存取,当用户不再使用时撤销文件等。
8.头文件和库文件一般在哪个路径下?
系统标准'头文件'位置: /usr/include
安装库的'头文件'位置: /usr/local/include/
#include系统标准'库文件'位置:/lib/usr/lib
用户'安装库'位置: /usr/local/lib
默认只搜索标准c语言库,对于系统标准库中的其他库以及安装库,需要在编译时指定库名。对于非系统
标准库还需通过-L来指定库文件位置。
a. C标准库,不需要-l 以及-L,编译时自动连接/lib/x86_64-linux-gnu/libc.so.6:gcc -o test test.c
b. 标准库中的其他库,如libmath.so:gcc -o test test.c -lm
c.安装库:如:libusb-1.0.so,gcc -o libusb-test usbtest3.0.c -lpthread -lusb-1.0
d.非系统标准库:gcc -o usbtest usbtest.c -L/home/baoli/libusb -lusb
9.系统如何区别同名的文件
文件描述符
10.系统如何区别不同的进程。
pid
11.查看文件有哪些命令
cat 由第一行开始显示文件内容 #-n 可以显示行号
tac 从最后一行开始向前显示,#可以看出 tac 是 cat 的倒着写
more 一页一页的显示文件内容
less 与 more 类似,但是比 more 更好的是,他可以往前翻页!
head 只看头几行,默认前10行
tail 只看尾巴几行,默认后10行
ls 查看目录下的文件
file 查看文件的类型
12.如修改文件的权限
chmod : 改变档案的权限, SUID, SGID, SBIT等等的特性
chmod 754 filename
#chgrp : 改变档案所属群组
#chown : 改变档案拥有者
13.什么是符号链接?
又叫软链接,
#用相对路径创建软链接时:任意文件位置发生变化的时候,链接会失效(但是链接文件依旧存在)
#用绝对路径创建的时候:链接文件可以移动到任意位置, 但是被链接文件(源文件)不能移动
三、数据结构
1.数据结构主要研究的是什么?
数据的各种逻辑结构和物理结构以及它们之间的关系(数学模型)
对各种结构定义相应的运算
设计出相应的算法
分析算法的效率
2.数组和链表的区别
(逻辑结构、内存存储、访问方式三个方面辨析)
逻辑结构:线性关系
内存存储:数组是一个连续的地址空间,链表可以是不连续的的地址空间
访问方式:数组可以通过下标直接的访问都对应的位置,链表不可以
但是数组的删除,任意位置插入,需要内存成片的移动,效率低
链表,的删除和插入更方便
顺序表:(数组)
原理:顺序表存储是将数据元素放到一块连续的内存存储空间,相邻数据元素的存放地址也相邻(逻辑
与物理统一)。
优点:
(1)空间利用率高。(局部性原理,连续存放,命中率高)
(2)存取速度高效,通过下标来直接存储。
缺点:
(1)插入和删除比较慢,比如:插入或者删除一个元素时,整个表需要遍历移动元素来重新排一次顺序。
(2)不可以增长长度,有空间限制,当需要存取的元素个数可能多于顺序表的元素个数时,会出现"溢出"问题.当元素个数远少于预先分配的空间时,空间浪费巨大。
时间性能 :查找 O(1) ,插入和删除O(n)
链表存储
原理:链表存储是在程序运行过程中动态的分配空间,只要存储器还有空间,就不会发生存储溢出问题,相邻数据元素可随意存放,但所占存储空间分两部分,一部分存放结点值(data),另一部分存放表示结点关系间的指针(struct 结构体* next)。
优点:
(1)插入和删除速度快,保留原有的物理顺序,比如:插入或者删除一个元素时,只需要改变指针指向即可。
(2)没有空间限制,存储元素的个数无上限,基本只与内存空间大小有关。
缺点:
(1)存取某个元素速度慢。
(2)占用额外的空间以存储指针(浪费空间,不连续存放,malloc开辟,空间碎片多)
(3)查找速度慢,因为查找时,需要循环链表访问,需要从开始节点一个一个节点去查找元素访问。
时间性能 :查找 O(n) ,插入和删除O(1)。
3.快速排序的算法
1.选择一个'基准'元素,通常选择第一个元素或者最后一个元素
2.通过一趟排序将(需要排序的数组)分割成独立的两部分,(左面的)其中一部分记录的元素值均比基准元素值小。(右面的)另一部分记录的元素值比基准值大。
3.此时'基准元素'在其排好序后的中间位置
4.然后递归操作,分别对这两部分用同样的方法继续进行排序,直到整个序列有序。
4. hash查找的算法
如果要从 'NUM' 个数中查找数据,
后'NUM'/0.75,求得最大质数'N',所以创建一个有'N'个元素的指针数组,然后将'NUM'个数分别对'N'取
余,
将每一个数保存在余数等于数组元素下标的链表中,然后进行查找是直接找相应的数组下标即可
#实际解释
如果要从100个数中查找数据
然后100/0.75,求得最大质数133,所以创建一个有133个元素的指针数组
然后将num个数分别对133取余,
将每一个数保存在余数等于数组元素下标的链表中,然后进行查找是直接找相应的数组下标即可
5.判断单链表是否有环
使用两个指针,同时指向同一个节点,然后一个指针一次走两步,一个指针一次走一步,然后判断这两个指针有没有指向同一个节点的时候,如果指向了同一个节点 就是有环,否则就是没有
6.判断一个括号字符串是否匹配正确,如果括号有多种,怎么做?如(([]))正确,[[(()错误
使用的是链式栈 作为基础
#一个栈,根据'右括号的'种类,判断'栈顶元素'是不是匹配,
#如果不匹配 报错返回 return,匹配 出栈
然后判断 ,如果是 ( 就进栈,如果是 ) 就出栈
判断执行完出栈函数之后的返回值,如果返回值 等于 -1 ,则是错误的
当整个括号字符串出栈 结束后,如果出栈的返回值 = 0,表示是正确的,否则是错误的
四. IO进程
1.标准IO和文件IO区别?
文件IO-系统调用
文件IO又被称作 系统调用,不涉及缓冲区,是由操作系统提供的,也就是 内核 提供API(API:函数接口)
文件IO对文件操作使用文件描述符
文件描述符:
文件的标志,是一个小的'顺序分配'的非负整数。内核用以 标识一个特定进程正在访问的文件
'进程间通信'方式中大多数也是'通过文件描述符'进行操作的
文件描述符跟文件指针类似,也是用于标识一个文件,对文件操作需要使用文件描述符
当一个程序运行时,操作系统会'自动为当前程序创建三个文件描述符'
0 标准输入文件描述符(stdin)
1 标准输出文件描述符(stdout)
2 标准错误输出文件描述符(stderr)
标准IO-库函数
标准IO就是库函数,库函数的本质还是系统调用
标准IO是在 文件IO 的基础上,封装出来的。
库函数相比系统调用,多了一个缓冲区,在执行系统调用之前,会将数据先保存在缓冲区中,只有当缓冲区刷新的时候才会执行系统调用
标准IO对文件操作使用文件指针,'fp'它是一个FILE结构体中文件指针数组的下标
#特点
标准IO的'可移植性高'
标准IO在'文件IO'的基础上'封装了一片空间名字叫做缓冲区'
FILE 结构体(文件指针) 是在'文件描述符'的基础上封装了'缓冲区'
文件指针:FILE * #又被称为文件流指针 ,流指针
2.简述流指针?–文件指针、文件流指针
FILE 结构体(文件指针) 是在'文件描述符'的基础上封装了'缓冲区
FILE指针:每个被使用的文件都在内存中开辟一个区域,用来存放文件的有关信息,这些信息是保存在一个结构体类型的变量中,该结构体类型是由系统定义的,取名为FILE。
标准I/O库的所有操作都是围绕流(stream)来进行的,在标准I/O中,流用FILE *来描述。
3.简述系统调用?
系统调用主要指的就是对'硬件'的操作流程
用户通过'应用层函数'操作'linux内核',linux'内核'再来'控制'硬件
linux内核里面封装了大量的系统调用,我们用户会通过'应用层的系统调用函数'来'调用内核的系统调用'
#不同的linux内核中的系统调用是不一样的,所以系统调用对应的程序移植性不高,一般对底层硬件操作都要通过系统调用
从执行角度讲,就是上层API接口通过引发'软中断',进入到内核空间,执行'系统调用服务'例程,通过系统调用编
号,找到对应的内核函数,将处理结果返回,中间涉及到处理器状态的切换(用户态、内核态)
3.1 简述库函数
库函数是别人为了统一不同操作系统对文件操作的函数
也就意味着主要支持C语言的系统,库函数都应该是一样的
所以库函数的移植性更高
#注意:库函数的本质还是系统调用,只不过库函数相比系统调用多了 缓冲区 ,缓冲区就是用来减少系统调用次数的
#只有当缓冲区被刷新之后才会执行系统调用

4.简述静态库和动态库的区别?
1.静态库是在链接阶段,将库和目标二进制文件合并到一起,形成一个整体,编译出可执行文件。会造
成可执行文件较大的现象,但是运行速度也就是调用函数的速度快。在软件更新时需要重新去编译成可执行
文件。静态库是以.a为后缀的。
2.动态库是在链接阶段,在目标二进制文件中创建一个库函数表单,指定链的库函数。库和可执行文件
两者相互独立所以,生成的可执行文件较小,因为需要去外部调用函数,所以速度较慢,但是更新时无需重
新编译,只需要更改库函数的实现就好了。动态库是以.so为后缀的。
5.如何将程序执行直接运行于后台?
./** &
前台后台切换
查看后台进程: jobs -l
ctrl + z : 暂停进程到保存后台
将后台暂停程序在'后台'运行起来:
bg + % 序列号(直接bg也可以)
将后台暂停进程'拿到前台运行':
fg + % 序列号(直接fg也可以,因为当前终端只有这一个可以变更修改的进程)
将程序在后台运行:./a.out + &
kill -19 pid 将进程号为pid的进程变为停止态
kill -18 pid 将进程号为pid的进程从停止态变为后台进程
6.进程的状态
睡眠态S,运行态R,停止态T,僵尸态Z,等待态D,死亡态,
+: 前台进程
<: 高优先级的进程
N: 低优先级的进程
L: 有内存分页分配并锁在内存中,多线程的
s: 会话组组长
7.什么是僵尸进程?
子进程结束,但是父进程没有结束,此时子进程的资源没有释放(回收),将此时的子进程称之为僵尸进程 #具有危害
(孩子死了,爹不给收尸,具有危害)
#处理僵尸进程的方式
方法1:'父进程结束',此时的僵尸进程就会变成孤儿进程,资源就会被init进程回收
方法2:使用'wait函数',阻塞等待子进程退出,同时可以释放僵尸进程的资源,但是wait是一个阻塞函数,父进程wait之后的代码只有当僵尸进程处理完之后才会执行
方法3:使用'waitpid函数'设置为非阻塞来处理僵尸进程但是使用非阻塞必须循环的判断子进程是否退出,如果父进程没有循环执行'waitpid函数',则无法回收资源
方法4:处理僵尸进程最好的方式是结合信号
7-8.孤儿进程
爹死了,孩子认init进程为干爹,干爹给他收尸---没有危害
8.简述创建子进程中的写时拷贝技术?
由于fork完整地拷贝了父进程的整个地址空间,因此执行速度是比较慢的。
为了提高效率
Unix系统设计者创建了vfork。vfork也创建新进程,但不产生父进程的副本。
它通过'允许父子进程可访问相同物理内存'从而伪装了对进程地址空间的真实拷贝,当'子进程需要改变内存中数据时''才拷贝父进程'。这就是著名的"写操作时拷贝"(copy-on-write)技术
9.多线程较多进程的优势?
线程通过不需要同进程一样的通信机制,线程通过共享进程的数据段完成通信,线程创建不需要复制进程的属性,创建更快
线程轮转的时候不需要切换4G的虚拟空间,所以线程更快
10.线程池的使用?----再看看
多线程技术主要解决'处理器单元内'多个线程执行的问题,它可以显著减少处理器单元的闲置时间,增加处理器单元的吞吐能力
假设一个服务器完成一项任务所需时间为:T1 创建线程时间,T2 在线程中执行任务的时间,T3销毁线程时间
如果:T1 + T3 远大于 T2,则可以采用线程池,以提高服务器性能
11.线程池的组成部分?
一个线程池包括以下四个基本组成部分:
1、线程池管理器(ThreadPool):用于创建并管理线程池,包括 创建线程池,销毁线程池,添
加新任务;
2、工作线程(PoolWorker):线程池中线程,在没有任务时处于等待状态,可以循环的执行任
务;
3、任务接口(Task):每个任务必须实现的接口,以供工作线程调度任务的执行,它主要规定了
任务的入口,任务执行完后的收尾工作,任务的执行状态等;
4、任务队列(taskQueue):用于存放没有处理的任务。提供一种缓冲机制。
12.线程的同步互斥机制?
互斥:'同一时间'只能有一个线程执行,执行'完毕后'其他线程再执行 --- 互斥锁
同步:在'互斥的基础上''有顺序'执行 --- 信号量 条件变量
13.简述互斥锁的实现原理?
'多个线程'如果要'对'同'一个共享资源进行操作'
'谁抢占到'资源,就对共享资源的操作'进行上锁'
'其他线程需要等待',当第一个线程对共享资源的'操作执行完毕后就解锁',解锁之后
'其他线程'就可以在对这个资源进行操作,
操作之前还是得'上锁'
'操作完毕后'还是得'解锁'
解锁之后其他线程又可以操作,
--以此类推--
临界资源:多个线程'共享的资源'叫做临界资源,它的改变有可能影响到其他线程的使用结果。
临界区:'操作'临界资源的'一段代码'
14.简述死锁的情景?
死锁的概念:
多线程以及多进程改善了系统资源的利用率并提高了系统的处理能力。然而,'并发执行'也带来了新的问题——--死锁。所谓死锁是指'多个线程'因'竞争资源'而造成的一种'僵局(互相等待)'',若无外力作用,这些进程都将无法向前推进
产生的原因:
1.对不可剥夺资源的竞争,才可能产生死锁(如磁带机、打印机)
2.进程推进顺序非法,请求和释放资源的顺序不当,也同样会导致死锁
15.简述信号量的原理?
信号量主要解决同步问题
信号量的本质是PV操作(P是- V是+)
信号量本质是一个计数器,对计数器有两个操作,P操作和V操作,P操作是减操作,V操作是加操作,
当信号量的值为0时,P操作将会阻塞,V操作没有影响
默认线程中的信号量PV操作执行一次只能减1或者加1
16.简述进程的通信机制?
早期的进程间通信方式:
无名管道 :只能用于'亲缘关系'的进程
有名管道 :'本地生成'套接字'文件'用于'标识内核空间'开辟的区域
信号通信 :当产生信号时,对进程有相应的处理方式---'唯一的异步通信机制'
SYSTEM V:IPC对象
消息队列 :IPC 对象,对系统所有进程可见,'保存数据',可以根据类型读取数据
共享内存 :'效率最高','实时数据'一般会使用共享内存保存
信号灯集 :'PV 操作',解决同步问题
BSD:
套接字通信 :实现'不同主机'的进程间通信
17.管道的通信原理?
管道分为无名管道跟有名管道,其原理都是'在内核中开辟一块空间',然后对这块空间进行操作,数据都存在在内存上
无名管道只能用于亲缘间进程通信,原因是在磁盘文件系统上不存在。
有名管道的出现,就是为了弥补这一缺点。有名管道在文件中属于一个特殊的文件,它确确实实存在文件系统之上,但是他的'数据存放在内存上'。
无名管道:
无名管道就是在'内核空间开辟一块区域',然后会给'进程两个文件描述符',只要多个进程可以得到这两个文件描述符,就可以对同一个管道进行操作
无名管道是一个'半双工的通信方式',意味着有'固定的读端和写端',但是无名管道不存在于磁盘空间。数据的操作也在内存。
既然无名管道给当前进程的是两个文件描述符,所以可以通过文件IO函数对其进行操作
无名管道'只能用于具有亲缘关系的进程间通信',
原因是因为无名管道既然给当前进程的是两个文件描述符,那么这两个文件描述符的创建只能在当前进程的用户空间,当fork之后产生的进程,会继承原本父进程的所有的空间,所以他能得到这两个文件描述符
管道的大小时64*1024,管道写满之后如果在进行写入的话,会阻塞等待写入。
有名管道:
有名管道创建好之后会在本地创建一个管道文件,对于当前系统中的进程都是可见的,
所以有名管道可以实现不相关进程间通信,由于创建了一个文件,所以对文件操作本质就是对内核开辟的区域操作,通过文件IO就可以操作
注意:打开有名管道时,必须读写权限同时存在。
在内核内存空间上创建管道,视管道为文件,对文件实现操作,但不能定位,管道的数据在内存上
18.用户进程对信号的响应方式?
忽略:当信号产生后对当前进程'没有任何影响'
缺省:按照当前'信号默认的方式'处理
捕捉:接收到信号后改变其函数指针执行的功能函数,执行我自己的功能--为我所用
#注意:SIGKILL、SIGSTOP 这两个信号只能以缺省(默认方式)的方式处理,不能忽略也不能捕捉
19.共享内存通信原理?
在内核空间,开辟一块物理空间,分别映射给通信的进程的虚拟地址空间上,实现多进行操作同一块区域
共享内存是一种最为高效的进程间通信方式,进程可以直接读写内存,而不需要任何数据的拷贝
为了在多个进程间交换信息,内核专门留出了一块内存区,可以由需要访问的进程将其映射到自己的私有地址空间
进程就可以直接读写这一内存区而不需要进行数据的拷贝,从而大大提高的效率。
由于多个进程共享一段内存,因此也需要依靠某种同步机制,如互斥锁和信号量等
内核预留出来了一片地址空间,专门给进程做通信使用,然后将首地址以地址映射的方式交给用户空间。共享
内存是所有进程间通讯中速度最快的。是通过地址的映射的方式做到了用户层直接操作内核层的地址上的值。
五. 网络编程
1. ISO七层网络通信结构和TCP/IP四层网络通信结构
ISO七层网络模型
应用层:面向用户的应用程序,app
表示层:数据加密、解密操作
会话层:将数据所在主机的逻辑名字和物理名字之间建立联系 (逻辑名和主机名之间的联系)
传输层:负责数据具体传输的机制(指定数据传输的方式)
网络层:如何处理如何将数据发给目的主机,路由的选择(数据分组、路由选择)
链路层:将前面所有的数据组成一个数据包,称之为一帧数据
物理层:选择数据发送的物理媒介(有线、无线)
TCP/IP四层网络模型
TCP/IP是目前为止用的'最广泛的网络体系结构'一共4层
应用层
传输层
网络层
网络接口与物理层

2. tcp通信的优缺点
TCP(即传输控制协议)概念:是一种'面向连接'的'可靠'的基于'字节流'的传输层协议,它能提供高'可
靠'性通信(即数据无误、数据无丢失、数据无失序、数据无重复到的通信)
优点:
TCP具有'回传机制',意味着如果数据发送出现问题,会重复发送
TCP提供以认可的方式显式地创建和终止连接。
TCP保证可靠的、顺序的(数据包以发送的顺序接收)以及不会重复的数据传输。
TCP处理流控制。
允许数据优先
如果数据没有传送到,则TCP套接口返回一个出错状态条件。
TCP通过保持连续并将数据块分成更小的分片来处理大数据块。—无需程序员知道
缺点:
TCP在传输数据时必须创建(并保持)一个连接。这个连接给通信进程增加了开销,让它比UDP速度要慢
2.3 TCP为什么要进行三次握手
第一次握手:'客户端'向'服务器端'发送'连接请求',TCP包头中SYN置1,自己的随机序列号seq为x。
第二次握手:当'服务器端'接收到'客户端'的连接'请求',发现SYN为1,解析获得客户端的随机序列号后。
向'客户端'发送的TCP包头中SYN置1,应答序列号ACK置1,应答序列号ack为客户端的随机序列号加一(x+1),自己的随机序列号seq为y。
第三次握手:'客户端'接收到'服务器端'的'连接请求'和'应答'后。向'服务器'发送'应答信号',应答标志位ACK置1,应答序列号为服务器的随机序列号加一(y+1)
为什么是三次?
三次握手的目的是'确保服务器'和'客户端'都具有'收发数据'的能力,
第一次握手成功说明'客户端'有'发数据'的能力,
第二次握手成功说明'服务器'有'收发数据'的能力,
第三次握手成功说明'客户端'有'接收数据'的能力,
所以三次握手的过程缺一不可,但是,如果说超过三次的握手次数,会浪费资源和时间
3. udp通信的优缺点
UDP(User Datagram Protocol)用户数据报协议,是'不可靠'的'无连接'的'数据报'协议。在数据发送前,因为不需要进行连接,所以可以进行高效率的数据传输。
优点:
1.UDP不要求保持一个连接
2.UDP没有因接收方认可收到数据包(或者当数据包没有正确抵达而自动重传)而带来的开销。(没有自动回传机制)
3.设计UDP的目的是用于短应用和控制消息
4.在一个数据包连接一个数据包的基础上,UDP要求的网络带宽比TDP更小。
缺点:
不可靠
4. pool与select的区别(select poll epoll的区别)
select:
1.select监听的'最大文件描述符的个数'是 1024 个
2.select监听的'表会被清空',所以需要'反复'将用户空间的表'拷贝'到内核空间,'效率'比较'低'。
3.select从'休眠状态被唤醒'之后,'需要遍历'所有的文件描述符,找到准备好的文件描述符,这个过程效率比较低。
poll:
1.poll监听的文件描述符'没有个数限制'
2.poll表'没有被清空','不需要'反复拷贝,'效率高'
3.poll从'休眠状态被唤醒'之后,'需要遍历'所有的文件描述符,找到准备好的文件描述符,这个过程效率比较低。
epoll:(#本世纪最好用的IO多路复用机制)
1.epoll监听的文件描述符'没有个数限制'
2.epoll'表没有被清空',不需要反复拷贝,效率高
3.epoll从'休眠状态被唤醒'之后,'不需要遍历'文件描述符能直接拿到准备好的文件描述符。
select、poll、epoll机制的特点
select,poll,epoll都是'IO多路复用'的机制。
I/O多路复用就通过一种机制,可以'监视'多个文件描述符
一旦'某个描述符就绪'(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作。
但select,poll,epoll本质上都是'同步I/O',
因为他们都需要在'读写事件就绪后'自己负责进行读写,也就是说这个'读写'过程是'阻塞'的,
而异步I/O则无需自己负责进行读写,异步I/O的实现会负责把数据从'内核'拷贝到'用户空间'---copy to /copy from 。
5. io模型有哪几种
阻塞I/O: 最常用、最简单、效率最低
非阻塞I/O: 可防止进程阻塞在I/O操作上,需要轮询
I/O 多路复用: 允许同时对多个I/O进行控制(用一个阻塞函数,阻塞所有阻塞函数)
信号驱动I/O: 一种异步通信模型(好像也是学过的唯一的一个异步IO)
6. 如何实现tcp并发服务器
tcp本身不是并发服务器的原因在于有两个读阻塞函数,
'accept'负责连接,产生对应的文件描述符,
'recv'负责接收数据,
所以可以使用父子进程或者多线程实现tcp并发服务器,也可以使用select实现多进程、多线程、select、poll、epoll
7. 网络超时检测的本质和实现方式
'超时检测':介于 阻塞 和 非阻塞 之间,设置一定的时间,
在时间到达'之内'如果没有数据则'一直阻塞'
如果时间'到了'还'没有数据',则变成'非阻塞'
#阻塞: 以读函数为例,如果缓冲区中有数据,则正常读取,如果没有数据,则'一直阻塞等待'
#非阻塞: 以读函数为例,如果缓冲区中有数据,则正常读取,如果没有数据,则'函数立即返回'
实现方式:
方法1:使用'setsockopt'实现网络超时检测 #设置套接字选项
方法2:使用'select'实现网络超时检测 #select的最后一个参数
方法3:使用'alarm闹钟'实现网络超时检测 #使用闹钟
#-------alarm原理---------------------------------------------------
alarm函数设置时间后,代码继续运行,当设定的时间到后,会产生SIGALRM信号(闹钟信号)这个信号默认
对当前进程的处理方式是结束进程
如果将信号的处理方式改为自定义,当执行完信号处理函数之后,代码会接着之前的继续运行,这是异步通信
机制默认的属性,我们将这个属性称之为'自重启属性'
'为了实现超时检测,我们只需要关闭这个自重启属性即可==> 执行完信号处理函数之后,代码会从头运行'
关闭自重启属性之后代码运行顺序:
当使用alarm设定的时间到达后,产生SIGALRM信号,执行信号处理函数
当信号处理函数执行完毕后,不会继续执行的正在执行的函数,而是错误返回,代码继续运行
#使用sigaction函数设置信号的属性
8. TCP 网络编程流程

#服务端:
创建套接字 socket()
将服务器网络信息结构体填充 sockaddr_in ===> 【man 7 ip ---> sockaddr_in
将套接字与服务器网络信息结构体绑定 bind()
将套接字设置为被动监听状态 listen()
阻塞等待客户端的连接 accept()
进行通信 read()/write() 或 recv()/send() 或 recvfrom()/sendto()
关闭文件描述符 close()
#客户端:
创建套接字 socket()
填充服务器网络信息结构体 sockaddr_in
客户端给服务器发送连接请求 connect()
进行通信 read()/write() 或 recv()/send() 或 recvfrom()/sendto()
关闭文件描述符 close()
9. UDP网络编程流程
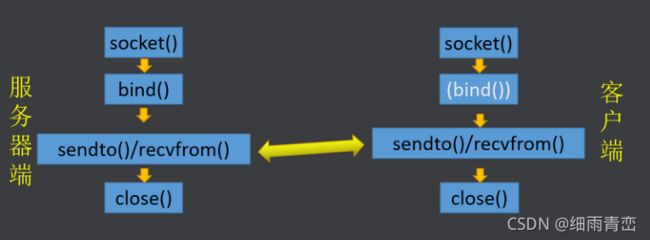
服务端:
创建套接字 socket()
填充服务器网络信息结构体 sockaddr_in
将套接字与服务器的网络信息结构体绑定 bind()
进行通信 recvfrom()/sendto()
客户端:
创建套接字 socket()
填充服务器网络信息结构体 sockaddr_in
进行通信 recvfrom()/sendto()
10. UDP本地通信需要注意哪些方面
客户端程序:
需要bind绑定'自己的本地信息结构体',也就是需要指定自己的套接字文件,
如果不这么做,服务器无法识别收到的数据来自于谁,客户端也无法接收到服务器发送的数据
11. 怎么修改文件描述符的标志位–文件状态标志位
可以通过'fcntl函数'修改文件描述符的标志位,一般执行读改写三步
int fcntl(int fd, int cmd, ... /* arg */ );
12. sqlite数据库的基本使用,包括增删改查
创建数据库:
create table 表名(成员名 成员类型,成员名 成员类型,...);
在充当主键的成员的后面加 primary key ,在创建的时候,声明这个成员是主键,不能有重复的
增加:也就是插入
insert into 表名 values('数据');//示例如下
insert into sta values(1000,'admin','123456','12345678901');
删除:
delete from 表名 where 条件;//依据后面的条件 删除 对应这个表中符合条件的 行
示例:
delete from stu where id=1002;
修改:
update 表名 set 需要被修改的值 where 条件;
示例:
update sta set name='qxy',passwd='12345' where id=1000;
查询:
select 需要查找的成员名 from 表名 where 条件;
示例:
在sta表中 查询id为1001 的 手机号
select phone from sta where id=1001;
13. 基于UDP的聊天室如何实现数据群发
在客户端连接到服务器的时候,定义一个链表(因为不确定客户端的个数,所以用链表)保存客户端bind绑定的信息,,然后群发的时候,服务器遍历整个链表,向每个客户端发送消息
14. 在线词典如何实现查询单词
服务端会通过fopen函数,打开本地的词典
由于 每个单词跟它的释义是在同一行,中间是用空格分开的,所以用fgets来读取一行,
然后使用strtok函数,用" "空格当分隔符,对这一行的数据进行裁剪,现在截取出来的就是每行的单词,
然后使用strtok函数,对截取完的字符串,再次进行提取,用'\n'作为分隔符,得到的就是释义
使用strcmp函数,对比,客户端传过来的单词,跟截取出来的单词
如果相同,把它的释义返回给客户端
15. TCP和UDP的区别
TCP与UDP基本区别
1.TCP基于面向连接与UDP是无连接
2.TCP要求系统资源较多,UDP较少;
3.UDP程序结构较简单
4.流模式(TCP)与数据报模式(UDP);
5.TCP保证数据正确性,UDP可能丢包
6.TCP保证数据顺序,UDP不保证
UDP应用场景:
1.面向数据报方式
2.网络数据大多为短消息
3.拥有大量Client
4.对数据安全性无特殊要求
5.网络负担非常重,但对响应速度要求高
具体编程时的区别
1.socket()的参数不同 ---套接字类型不同--TCP(SOCK_STREAM),UDP(SOCK_DGRAM)
2.UDP Server不需要调用listen和accept ---UDP是无连接的,所以客户端也不需要connect
3.UDP收发数据用sendto/recvfrom函数 ---TCP是面向连接的,直接使用send、from
4.TCP:地址信息在connect/accept时确定 ---三次握手也是
5.UDP:在sendto/recvfrom函数中每次均 需指定地址信息
6.UDP:shutdown函数无效
TCP与UDP区别总结:
1、TCP'面向连接'
UDP是'无连接'的,即发送数据之前不需要建立连接
2、TCP提供'可靠'的服务。也就是说,通过TCP连接传送的数据,无差错,不丢失,不重复,且按序到达
UDP尽最大努力交付,即'不'保证'可靠'交付
3、TCP面向'字节流',实际上是TCP把数据看成一连串无结构的字节流
UDP是面向'报文'(数据报)的UDP'没有拥塞控制',
因此网络出现'拥塞''不会'使源主机的'发送速率降低'(对实时应用很有用,如IP电话,实时视频会议等)
4、每一条TCP连接只能是'点到点'的
UDP支持'一对一,一对多,多对一和多对多'的交互通信
5、TCP首部开销20字节 UDP的首部开销小,只有8个字节
6、TCP的逻辑通信信道是'全双工'的'可靠'信道(在不可靠的信道上建立了一个稳定的连接),UDP则是'不可靠'信道
16. OSI七层网络模式,每层的主要作用,主要的协议
应用层:为特定应用程序提供数据传输服务。( TFTP,HTTP,SNMP,FTP,SMTP,DNS,Telnet)
表示层:对上层信息进行变换,保证一个主机应用层信息被另一个主机的应用程序理解,表示层的数据转换包括数据的加密、压缩、格式转换。
会话层:管理主机之间的会话进程,即负责建立、管理、终止。
传输层:提供端对端的接口。( TCP,UDP)
网络层:为数据包选择路由。(IP,ICMP,ARP,RARP)
数据链路层:传输有地址的帧,错误检测功能( SLIP,CSLIP,PPP,ARP,RARP,MTU)
物理层:以二进制数据形式在物理媒体上传输数据。 ISO2110,IEEE802,IEEE802.2
17. TCP 粘包
TCP粘包 -- TCP内部实现有一个 Nagle算法
会将 一段时间内 要发送的所有的数据报 整合在一起,作为 一个数据包 发送给对方
对方在接收数据时,recv的第三个参数表示每次接收数据的最大值
由于发送过来的数据是一个整体,所以无法区分每一个部分的数据
就会导致小于第三个参数设置值的多个数据粘连在一起接收到且无法区分
如何处理:
方法1:设置延时,保证不同类型的数据包不与之前的数据一起发送
方法2:在发送数据之前加头部信息,比如要发送数据的大小,然后将头部信息和要发送的数据保存在一个结
构体中,只要保证每次发送的数据大小一致,就不会出现这个问题
18. TCP的三次握手和四次挥手分别作用,主要做什么
三次握手:
目的:确定'服务器'和'客户端'两方'都有收发数据'的能力,
第一次握手说明'客户端'有'发数据'的能力
第二次握手说明'服务器端'有'收发数据'的能力
第三次握手说明'客户端'有'收数据'能力
所以三次握手这一过程缺一不可。
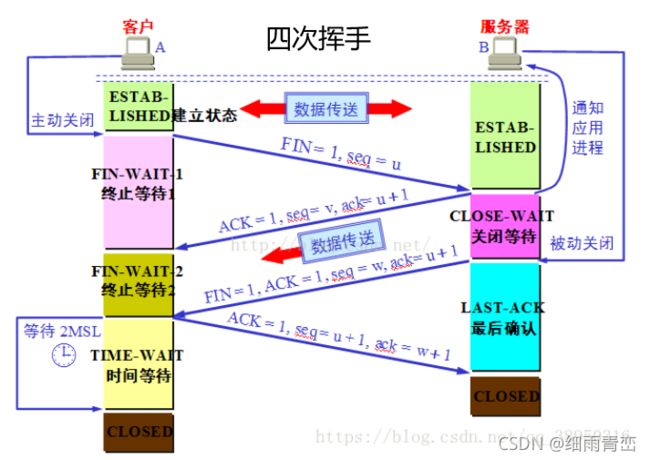
四次挥手
TCP协议是一种'面向连接'的、'可靠'的、基于'字节流'的传输层通信协议。
TCP是'全双工'模式,
这就意味着,
当 Client 发出FIN报文段时,只是表示 Client 已经'没有数据要发送'了,Client 告诉 Server,它的数据已经全部发送完毕了;但是,这个时候 Client 还是'可以接受'来自 Server 的数据;
当Server '返回ACK报文'段时,表示它已经知道 Client 没有数据发送了,但是 Server 还是'可以发送数据'到 Client 的;
当 Server 也发送了FIN报文段时,这个时候就表示 Server 也'没有数据要发送'了,就会告诉 Client ,我也没有数据要发送了,之后彼此就会愉快的中断这次TCP连接。

19. 如何实现并发服务器,并发服务器的实现方式有什么异同
实现主要分三种方式:多进程并发服务器,多线程并发服务器,I/O复用并发服务器
20.线程和进程的区别,多线程和多进程编程的特点
进程是'资源管理'的最小单位,线程是'程序执行'的最小单位。
每个'线程''享有'其所属附属'进程的所有资源'(打开的文件,内存页面,信号标识,动态分配的内存等)
线程更小,花费更少的CPU资源
(操作系统设计上,进程演化出线程,是为了更好的支持多处理器)
==》
当线程所属进程退出的时,他所产生的线程都会被强制退出
进程:
进程是程序的'一次执行过程',是一个'动态概念',是程序在执行过程中'分配'和'管理资源'的'基本单位',
'每一个进程'都有一个'自己的地址空间',
进程至少有5种基本状态,它们是:初始态,执行态,等待状态,就绪状态,终止状态。
线程:
线程是'系统调度'和'基本单位',它可'与同属'一个进程的'其他的线程''共享进程'所拥有的'全部资源'。
联系:
'线程'是'进程'的一部分,一个线程只能属于一个进程,而一个进程可以有多个线程,但至少有一个线程(主控线程)。
区别:
'资源使用'的角度出发。(所谓的资源就是计算机里的中央处理器,内存,文件,网络等等)
根本区别:'进程'是操作系统'资源分配'的'基本单位',而'线程'是'任务调度和执行'的'基本单位'
开销方面:每个'进程'都有'独立'的代码和数据'空间'(程序上下文),程序之间的切换会有较大的开销;
'线程'可以看做'轻量级的进程',同一类'线程共享'代码和数据'空间',
每个线程都有自己独立的运行栈和程序计数器(PC),线程之间切换的开销小。
所处环境:在操作系统中能'同时运行多个进程'(程序);而在同一个进程(程序)中有多个线程同时执行
(通过CPU调度,在每个时间片中只有一个线程执行)(上下文切换,时间片轮转)
内存分配方面:系统在运行的时候会为每个'进程'分配不同的'内存'空间;而对线程而言,除了CPU外,系统'不会为'线程'分配内存'(线程所使用的资源来自其所属进程的资源),线程组之间只能共享资源。
包含关系:没有'线程'的'进程'可以看做是'单线程'的,
如果一个'进程'内有'多个线程',则执行过程不是一条线的,而是'多条线(线程)共同'完成的;
线程是进程的一部分,所以线程也被称为轻权进程或者轻量级进程。
六.C++
1. new、delete、malloc、free关系
1.new分配空间的'同时可以初始化', malloc分配空间时'不可以直接初始化'
2.new如果不初始化会'自动用0初始化', malloc分配完就是'随机值',需
要'memset'或者'bzero'清0
3.mallco/free 是'库函数',new/delete 是C++的'关键字'
4.new分配空间时可以根据类型'自动计算空间大小',而malloc需要'手动计算传参'
5.new '返回的就是'相应类型的指针,而malloc需要'强制类型转换'---返回的是
(void *)
6.new会调用'构造函数',malloc不会
7.delete会调用'析构函数',free不会
2. delete与 delete []区别
//方括号里 可以写空间的大小 也可以不写,不写就是 申请了多少 就被释放多少
delete只会调用'一次''析构函数',而delete[]会调用'每一个成员'的'析构'函数。
在More Effective C++中有更为详细的解释:“当delete操作符用于数组时,它为每个数组元素调用析构函数,然后调用operator delete来释放内存。”delete与new配套,delete []与new []配套
这就说明:对于内建简单数据类型,delete和delete[]功能是相同的。对于自定义的复杂数据类型,
delete和delete[]不能互用。delete[]删除一个数组,delete删除一个指针。
简单来说,
用new分配的内存用delete删除;
用new[]分配的内存用delete[]删除。
delete[]会调用数组元素的析构函数。内部数据类型没有析构函数,所以问题不大。如果你在用delete时没用括号,delete就会认为指向的是单个对象,否则,它就会认为指向的是一个数组。
3. C++有哪些性质(面向对象特点)
面向对象的三大特征 : 封装 继承 多态 -----// 如果有四:加一个 抽象
4. 子类析构时要调用父类的析构函数吗?
'析构函数'调用的次序是先'派生类'的析构后'基类的析构',
也就是说在'基类'的的'析构调用'的时候,派生类的信息已经全部销毁了。
'定义'一个对象时先调用'基类的构造'函数、然后'调用派生类'的'构造'函数;
析构的时候'恰好相反':先调用'派生类的析构'函数、然后'调用基类的析构'函数。
5. 多态,虚函数,纯虚函数
多态:通过 父类的'指针或引用'指向 子类的对象,可以访问'子类中重写的父类中的方法'。
实现多态的必要条件:
1.继承 //---需要子类
2.父类指针或引用指向子类对象 //---需要一个指针或引用
3.虚函数 //---汇聚子类中 只有一份 公共基类的 成员
4.函数重写 //---修改原来的函数
//-----------------------------------------------------------
虚函数:以关键字 virtual 开头的成员函数。 '声明'或'定义函数'前加上 virtual
允许'在派生类'中对'基类的虚函数''重新定义'。
//-----------------------------------------------------------
纯虚函数:是一种在基类中只有声明,没有定义的函数
纯虚函数的作用:在'基类'中'为其'派生类'保留一个函数'的名字,以便'派生类''根据需要'对它进行'定义'。作为接口而存在
'纯虚函数''不具备函数'的功能,一般'不能直接被调用'。
从'基类继承'来的'纯虚函数',在'派生类'中'仍是虚函数'。
//----------------------------------------------------------
如果'一个类中'至少'有一个纯虚函数',那么这个类被称为'抽象类'(abstract class)。
'抽象类'中不仅包括'纯虚函数',也可包括'虚函数'。
抽象类'必须用作'派生其他类的'基类'
包含'纯虚函数的类' 叫做 '抽象类'
抽象类'不允许'实例化对象,否则'报错'
子类中'必须重写抽象类的纯虚函数',否则'报错'
抽象类虽然不能实例化对象,但可以通过抽象类的'指针或引用'指向子类的对象来'实现多
态'的特性
6. 求下面函数的返回值(微软)----特么的题呢–
int func(x)
{
int countx = 0;
while(x)
{
countx ++;
x = x&(x-1);
}
return countx;
}
假定x = 9999。 答案:8
思路:将x转化为2进制,看含有的1的个数。
& : 0 与 任何数 & 都等于 0 1 与 任何数 & 都等于 任何数
由于每次都是 x 跟 x-1 进行 & 运算,所以每次,都会弄没一个 1 ,所以只要看x的最开始的二进制有几个1 ,然后就会执行几次
9999先转换成二进制数,0010 0111 0000 1111 一共8 个,8次
测试代码如下:
#include 7. 什么是“引用”?声明和使用“引用”要注意哪些问题?
引用就是某个目标变量的"别名"(alias),对应用的操作与对变量直接操作效果完全相同。
声明一个'引用'的时候,切记要对其进行'初始化'。
引用声明完毕后,'相当于''目标变量名'有'两个名称',即该目标'原名称'和'引用名',不能再把该引用名作为其他变量名的别名。
声明一个引用,'不是'新定义了一个变量,它只表示该'引用名'是目标变量名的一个'别名',它本身不是一种数据类型,因此引用本身不占存储单元,系统也不给引用分配存储单元。不能建立数组的引用。
7-8. 引用与指针的区别
1. 引用必须'初始化' ,指针可以'不初始化'
2. '引用不可以改变指向' ,指针可以
3. '不存在指向NULL的引用', 指针可以指向NULL
4. '指针'在使用前需要'检查合法性' ,引用不需要
8. 将“引用”作为 函数参数 有哪些特点?
1.传递'引用'给函数 与 传递'指针'的'效果'是一样的。
这时,被调函数的'形参'就成为原来主调函数中的'实参变量'或'对象的'一个'别名'来使用,
所以在被调函数中对'形参变量的操作'就是对其'相应的目标对象'(在主调函数中)的操作。
2.使用'引用'传递函数的参数,在内存中并没有产生实参的副本,它是'直接对实参操作';
而使用'一般变量'传递函数的参数,当发生函数调用时,需要给'形参分配存储单元',形参变量是实参变量的副本;
如果传递的是'对象',还将'调用拷贝构造'函数。因此,当参数传递的数据较大时,用'引用'比用一般'变量'传递参数的'效率和所占空间'都好。
3.使用'指针'作为函数的'参数'虽然也能达到与使用引用的效果,
但是,在被调函数中同样要给'形参分配存储单元',且需要重复使用"*指针变量名"的形式进行运算,这很容易产生错误且程序的阅读性较差;
另一方面,在主调函数的调用点处,必须用变量的地址作为实参。而引用更容易使用,更清晰。
9. 在什么时候需要使用“常引用”?
如果既要利用'引用'提高程序的'效率',又要'保护'传递给函数的'数据不'在函数中'被改变',就'应使用'常引用。
//有些场景下,函数中 不想修改 形参的值,可以使用 常引用
常引用声明方式:const 类型标识符 &引用名=目标变量名;
int a ;
const int &ra=a;
ra=1; //错误
a=1; //正确
10. 将“引用”作为函数返回值类型的格式、好处和需要遵守的规则?
格式:类型标识符 &函数名(形参列表及类型说明)
{
//函数体
}
好处:在'内存'中'不产生'被返回值的'副本';
(注意:正是因为这点原因,所以'返回一个局部变量的引用是不可取'的。因为随着该局部变量生存期的结束,相应的引用也会失效,产生runtime error!)
注意事项:
1. '不能返回局部变量的引用'。这条可以参照Effective C++[1]的Item 31。
主要原因是'局部变量'会在'函数返回'后'被销毁',因此被返回的'引用'就成为了"无所指"的引用,程序会进入未知状态。
2. '不能返回函数内部new分配的内存的引用'。这条可以参照Effective C++[1]的Item 31。
虽然不存在局部变量的被动销毁问题,可对于这种情况(返回函数内部new分配内存的引用),又面临其它尴尬局面。
例如,被函数返回的'引用'只是作为一个'临时变量'出现,而没有被赋予一个实际的变量,那么这个引用所指向的空间(由new分配)就'无法释放',造成memory leak(内存泄漏)。
3. '可以返回类成员的引用',但最好是'const'。这条原则可以参照Effective C++[1]的Item 30。
主要原因是当'对象的属性'是与某种业务规则(business rule)相关联的时候,其赋值 常常与 某些其它属性或者对象的状态有关,因此有必要将赋值操作封装在一个业务规则当中。
如果其它对象可以获得该属性的'非常量引用(或指针)',那么对该属性的单纯赋值就会破坏业务规则的完整性。
4. '流操作符重载返回值'声明为"引用"的作用:
流操作符<<(打印)和>>(提取),这两个操作符常常希望被连续使用,
例如:cout << "hello" << endl;
因此这两个操作符的'返回值'应该是一个仍然支持这两个操作符的流引用。
可选的其它方案包括:返回一个流对象和返回一个流对象指针。
但是对于返回一个'流对象',程序必须重新(拷贝)构造一个新的流对象,也就是说,连续的两个<<操作符实际上是针对不同对象的!这无法让人接受。
对于返回一个'流指针'则不能连续使用<<操作符。
因此,返回一个'流对象引用'是唯一选择。这个唯一选择很关键,它说明了'引用的重要性'以及'无可替代'性。---- '返回的自身的引用'
赋值操作符=。这个操作符象流操作符一样,是可以连续使用的,
例如:x = j = 10;或者(x=10)=100;
赋值操作符的返回值必须是一个左值,以便可以被继续赋值。因此引用成了这个操作符的惟一返回值选择。
#include
int &put(int n);
int vals[10];
int error=-1;
void main()
{
put(0)=10; //以put(0)函数值作为左值,等价于vals[0]=10;
put(9)=20; //以put(9)函数值作为左值,等价于vals[9]=20;
cout<=0 && n<=9 ) return vals[n];
else { cout<<"subscript error"; return error; }
}
5. 在另外的一些操作符中,却千万不能返回引用:
+-*/ 四则运算符。它们不能返回引用,Effective C++[1]的Item23详细的讨论了这个问题。
主要原因是这四个操作符没有side effect,因此,它们必须构造一个对象作为返回值,
可选的方案包括:返回一个对象、返回一个局部变量的引用,返回一个new分配的对象的引用、返回一个静态对象引用。
根据前面提到的引用作为返回值的三个规则,2、3两个方案都被否决了。
静态对象的引用又因为((a+b) == (c+d))会永远为true而导致错误。
所以可选的只剩下返回一个对象了。
11. 结构与联合有和区别?—C基础第四题
12. 试写出程序结果:
int a=4;
int &f(int x)
{
a=a+x;
return a;
}
int main(void)
{
int t=5;
cout<13. 重载(overload)和重写(overried,有的书也叫做“覆盖”)的区别?
从定义上来说:
重载:是指允许存在多个同名函数,而这些函数的参数表不同(或许参数个数不同,或许参数类型不
同,或许两者都不同)。
重写:是指子类重新定义父类虚函数的方法。
从实现原理上来说:
重载:编译器根据函数不同的参数表,对同名函数的名称做修饰,然后这些同名函数就成了不同的函数
(至少对于编译器来说是这样的)。如,有两个同名函数:function func(p:integer):integer;和
function func(p:string):integer;。那么编译器做过修饰后的函数名称可能是这样的:int_func、
str_func。对于这两个函数的调用,在编译器间就已经确定了,是静态的。也就是说,它们的地址在编
译期就绑定了(早绑定),因此,重载和多态无关!
重写:和多态真正相关。当子类重新定义了父类的虚函数后,父类指针根据赋给它的不同的子类指针,
动态的调用属于子类的该函数,这样的函数调用在编译期间是无法确定的(调用的子类的虚函数的地址
无法给出)。因此,这样的函数地址是在运行期绑定的(晚绑定)。
14. 有哪几种情况只能用intialization list(初始化列表) 而不能用assignment?
必须使用初始化表的场景
1. '成员变量名字'和'构造函数形参名字'冲突时;---也可以用this解决
2.类中包含' const '成员变量时 //因为 const 只能在初始化的时候赋值
3.类中包含' 引用' 成员变量 //引用 只能先指向 再操作
4.类中包含'成员子对象'(类中包含其他类对象时)时
//必须使用初始化表调用子对象的构造函数 完成对成员子对象的初始化
//构造函数 才有初始化 表
15. C++是不是类型安全的?
不是。两个不同类型的指针之间可以强制转换(用reinterpret cast)。C#是类型安全的
16. main 函数执行以前,还会执行什么代码?
全局对象的构造函数会在main 函数之前执行。
17. 描述内存分配方式以及它们的区别?
1) 从静态存储区域分配。内存在程序编译的时候就已经分配好,这块内存在程序的整个运行期间都存在。例如全局变量,static 变量。
2) 在栈上创建。在执行函数时,函数内局部变量的存储单元都可以在栈上创建,函数执行结束时这些存储单元自动被释放。栈内存分配运算内置于处理器的指令集。
3) 从堆上分配,亦称动态内存分配。程序在运行的时候用malloc 或new 申请任意多少的内存,程序员自己负责在何时用free 或delete 释放内存。动态内存的生存期由程序员决定,使用非常灵活,但问题也最多。
18. 分别写出BOOL,int,float,指针类型的变量a 与“零”的比较语句。
BOOL : if ( !a ) or if(a)
int : if ( a == 0)
float : const EXPRESSION EXP = 0.000001
if ( a < EXP && a >-EXP)
pointer : if ( a != NULL) or if(a == NULL)
19. 请说出const与#define 相比,有何优点?–C基础-11题
20. 简述数组与指针的区别?–C基础-12题
21. int (*s[10])(int) 表示的是什么?
函数指针数组,每个指针指向一个int func(int param)的函数
回调函数
22. 栈内存与文字常量区
char str1[] = "abc";
char str2[] = "abc";
const char str3[] = "abc";
const char str4[] = "abc";
const char *str5 = "abc";
const char *str6 = "abc";
char *str7 = "abc";
char *str8 = "abc";
cout << ( str1 == str2 ) << endl;//0 分别指向各自的栈内存
cout << ( str3 == str4 ) << endl;//0 分别指向各自的栈内存
cout << ( str5 == str6 ) << endl;//1指向文字常量区地址相同
cout << ( str7 == str8 ) << endl;//1指向文字常量区地址相同
结果是:0 0 1 1
解答:str1,str2,str3,str4是数组变量,它们有各自的内存空间;而str5,str6,str7,str8是指针,它们指向
相同的常量区域。
23. 将程序跳转到指定内存地址
要对绝对地址0x100000赋值,我们可以用(unsigned int*)0x100000 = 1234;那么要是想让程序跳转到绝对地址是0x100000去执行,应该怎么做?
((void ()( ))0x100000 ) ( );
首先要将0x100000强制转换成函数指针,
即:(void (*)())0x100000
然后再调用它:
((void ()())0x100000)();
用typedef可以看得更直观些:
typedef void(*)() voidFuncPtr;
*((voidFuncPtr)0x100000)();
24. int id[sizeof(unsigned long)];这个对吗?为什么?
正确 这个 sizeof是编译时运算,编译时就确定了 ,可以看成和机器有关的常量。
27. 内存的分配方式有几种?—上面 17
28. 基类的析构函数不是虚函数,会带来什么问题?
#虚析构函数的作用:
用来指引delete关键字,正确回收空间。
--- 因为正常的析构函数 只能调用 父类 的析构
//基类指针指向子类对象时,如果析构函数不是虚函数
//那么只会调用 基类的析构函数,不调用子类的,所以可能会造成内存泄露
//如果基类的 析构函数是 虚函数
//则会调用 子类的析构函数,子类的析构函数 会默认 调用基类的析构函数,不会内存泄漏
29. 全局变量和局部变量有什么区别?是怎么实现的?操作系统和编译器是怎么知道的?
生命周期不同:
全局变量随主程序创建和创建,随主程序销毁而销毁;
局部变量在局部函数内部,甚至局部循环体等内部存在,退出就不存在;
使用方式不同:
通过声明后全局变量程序的各个部分都可以用到;局部变量只能在局部使用;分配在栈区。
操作系统和编译器通过'内存分配的位置'来知道的,
'全局变量'分配在'全局数据段'并且在程序开始运行的时候被加载。
'局部变量'则分配在'栈'里面 。
七. ARM体系结构编程
1. 简单描述一下ARM处理器的特点,至少说出5个以上的特点。
低功耗;
低成本,高性能,RISC结构;
体积小;
指令定长;
支持Thumb(16位)/ARM(32位)双指令集;
2. ARM内核有多少种工作模式?请写出这些工作模式的英文缩写,有几种异常模式,有几种特权模式,cortex_a系列有几种特权模式,几种工作模式
|--> 特权模式 |---> 异常模式 | --> FIQ模式(快速中断)
| | | --> IRQ模式(普通中断)
| | | --> SVC模式(特权模式)
工作 | | | --> Abort模式(中止异常模式)
模式 | | | --> Undef模式(未定义的异常模式)
| | | --> Monitor模式(安全监控模式)
| |---> 非异常模式---> System模式(User模式下的一种特权模式)
|
|--> 非特权模式 --> User模式
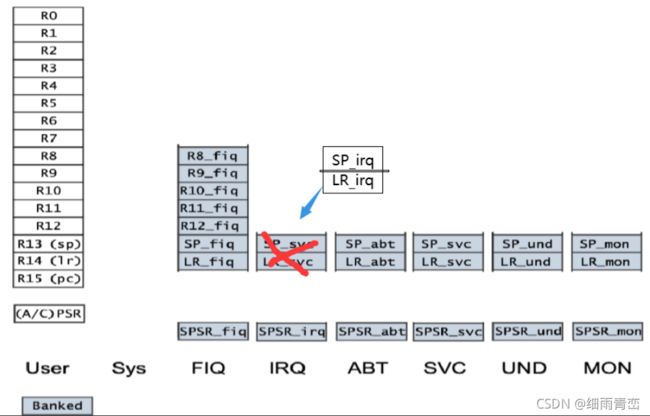
3. ARM内核有多少个寄存器,简述一下
ARM有37个寄存器,
(1)未分组寄存器:R0-R7,共8个;
(2)分组寄存器R8-R14,其中FIQ模式下有单独的一组R8-R12共5个,另外6种模式共用一组R8-R12,共5个,
(3)程序计数器PC即R15寄存器,共1个;
(4)状态寄存器CPSR,和5个备份状态寄存器SPSR,共6个
4. ARM通用寄存器中,有3个寄存器有特殊功能和作用,请写出它们的名字和作用。
R13:SP栈指针寄存器,用来保存程序'执行时的栈指针位置';
R14:LR返回链接寄存器,用来保存程序执行'BL指令'或'模式切换时'的'返回'原程序'继续执行的地址';
R15:PC程序计数器,指向'正在取指的指令的地址'
5. 请描述一下CPSR寄存器中相关Bit的情况和作用。

条件位(指令进行算术运算后的结果是否有进位,借位等),
I位(IRQ异常允许位),
F位(FIQ异常允许位),
T位(ARM/Thumb工作状态),
模式位(处理器工作模式)
N[31] : 指令的'运算结果为负数',N位被自动'置1',否则清0.
Z[30] : 指令的'运算结果为零',Z位被自动'置1',否则清0.
C[29] :
'加法':产生'进位',C位被自动'置1',否则清0.
'减法':产生'借位',C位被自动'清0',否则置1.
进位/借位:'低32位'向'高32位' 进位或者借位。
两个64位数相加,需要拆分成两个32位数进行加法运算,先算低32位,再算高32位,在进行高32位运算时需要考虑低32位是否有进位。
V[28] : '符号位'发生变化,V位被自动'置1',否则清0.
I[7] : IRQ屏蔽位
I = 0 不屏蔽IRQ中断
I = 1 屏蔽IRQ中断
F[6] : FIQ屏蔽位
F = 0 不屏蔽FIQ中断
F = 1 屏蔽FIQ中断
T[5] : 状态位
T = 0 : ARM状态 --》执行ARM指令集
T = 1 : Thumb状态 ---》执行Thumb指令集ARM指令集和Thumb指令集区别
ARM指令集: 每条指令占4个字节的空间
Thumb指令集:每条指令占2个字节的空间
#ARM指令集的功能性比Thumb指令集的功能更加完善。Thumb指令集的指令的密度要比ARM指令集高。
M[4:0] : 模式位
10000 User mode;
10001 FIQ mode;
10011 SVC mode;
10111 Abort mode;
11011 Undfined mode;
11111 System mode;
10110 Monitor mode;
10010 IRQ
#其他的保留
6. 什么是立即数?立即数的本质是什么
然后将这个数,循环 右移偶数 位,如果 可以得到 要判断的那个数,说明这个数 是一个立即数。
立即数的本质 包含在指令中的数
7. 请问BL指令跳转时LR寄存器保存的是什么内容?并请简述原因
LR中保存的是执行完'BL跳转指令的下一条指令'的地址。LR用来在'需要返回程序'时从LR中'还原程序执行的位置'继续执行。(保存现场--恢复现场)
8. 请描述一下什么是处理器现场,如何进行保存现场?
每种工作模式下都包含R0-R15,CPSR这17个寄存器,程序的执行当前状态就保存在这些寄存器中,称为处理器现场。
当发生'模式切换'时,由于其中的一些寄存器是多种模式下'共用的寄存器',为了'防止共用'处理器寄存器中的'值被破坏',所以需要'保存'原模式下的'处理器现场',
利用STM批量存储指令,把处理器现场对应的寄存器保存到栈上,待还原时再出栈恢复(模式和返回地址)。
其中保存现场的工作, 硬件完成了'CPSR模式的保存'和'PC返回地址的保存',其他寄存器的保存工作主要依靠软件压栈完成,其中'LR'因为'可能被异常处理程序中'的BL跳转指令'修改',所以一般都需要'软件压栈'再保存。
9. ATPCS默认使用的是什么栈?–满减栈(ARM也是)
10. 什么是满栈、空栈,什么是增栈、减栈?
栈的种类: (sp)
空栈:栈指针指向的栈空间没有有效的数据,
压栈时可以直接将数据压入栈空间中,
需要再次将栈指针指向一个空的空间。
满栈:栈指针指向的栈空间有有效的数据,
压栈时需要先移动栈指针指向一个空的栈空间,
在压入数据,此时栈指针指向的仍然是一个有有效数据的栈空间。
增栈:压栈时栈指针向高地址方向移动,
出栈时栈指针向低地址方向移动。
减栈:压栈时栈指针向低地址方向移动,
出栈时栈指针向高地址方向移动
11. 请写出一条完整的ARM软件中断指令,并简要描述其作用。
SWI 0x1。
SWI指令触发'软中断异常',使程序的执行流跳转到异常向量表地址0x8,0x1是软中断的中断号,
软中断处理程序可根据不同的中断号调用对应的处理子程序。一般SWI软中断都用于操作系统的系统调用。
12. 请描述一下ARM体系中异常向量表的概念。
异常向量表是从0x0地址开始,一共32个字节,包含8个表项,其中有1个保留不用,其他7个表项对应7种异常发生后的跳转位置,
这7种异常发生后分别对应到5种异常模式。每个表项里面放的一般都是一条跳转指令,
用来跳转到真正的异常处理程序入口,通过BL指令,或者LDR PC,[PC, #?] 的方式都可以实现此类跳转。
13. 请写出一个ARM程序生成的bin文件映像中包含哪些内容?
ARM生成的bin文件包含:RO,RW 两个段,注意 ZI 段一般都不在 bin 文件中占用存储空间。
14. 请举例说明在ARM处理器上进行一次中断处理和中断异常处理的差异。
中断处理相比异常处理,主要是中断需要初始化中断源和中断控制器,中断发生后在ISR中要清除相
应Pending位,而且要在进入中断处理程序一开始就清除。
15. 请简述异常中断处理发生时,是通过什么完成初始化步骤,这些初始化的具体步骤是什么?
当发生异常中断时,有ARM CORE完成一下工作,称作4大步三小步
1)拷贝CPSR到SPSR_mode
2)设置CPSR的位
修改处理器状态进入ARM态
修改处理器模式为相应的异常模式
禁止相应的中断(根据需要禁止FIQ或者IRQ)
3)保存返回地址到LR_MODE
4)设置PC位相应的异常向量
16. uboot的主要作用
uboot 属于bootloader的一种'引导程序',是用来引导启动内核的
初始化大部分的硬件,为内核运行提供基础,
给内核传递参数
uboot主要做了两个阶段的事:
第一个阶段:汇编
构建'异常向量表'
禁止'mmu'和'cache',禁止'看门狗'
硬件时钟的'初始化','内存'的'初始化'
清除'bss'段 #bss段是用来存储静态变量,全局变量的
完成uboot代码的自搬移
'初始化C代码'运行的'栈空间'
第二个阶段:C
完成'大部分硬件'的'初始化','串口'的初始化,'内存'的进一步的初始化,'电源的'初始化 等等必要'硬件的'初始化
根据命令是否进入'交互模式'还'自启动模式'
获取uboot的'环境变量',
执行'bootcmd中的命令',
最终'给内核传递参数'(bootargs)
17. uboot是怎样引导启动内核的?
uboot刚开始被放到flash中,
板子上电后,会自动把'其中的一部分代码'拷到'内存'中执行,
这部分代码负责把'剩余的uboot代码'拷到'内存'中,
然后'uboot代码'再把'kernel部分代码'也拷到'内存'中,
并且启动,内核启动后,
挂载根文件系统,执行应用程序。
18. uboot的启动过程的重要干了什么
uboot启动主要分为两个阶段,
主要在start.s文件中,第一阶段主要做的是硬件的初始化,
包括,设置'处理器模式'为'SVC模式','关闭看门狗','屏蔽中断','初始化sdram','设置栈','设置时钟',从'flash拷贝代码'到'内存','清除bss段'等,bss段是用来存储静态变量,全局变量的,
然后程序跳转到start_arm_boot函数,宣告第一阶段的结束。
第二阶段比较复杂,
做的工作主要是:
1.从flash中读出内核。
2.启动内核。
start_arm_boot的主要流程为,
设置机器id,
初始化flash,
然后进入main_loop,
等待uboot命令,
uboot要启动内核,主要经过'两个函数',
第一个是's=getenv("bootcmd")',
第二个是'run_command(s...)',
所以要启动内核,需要根据'bootcmd环境变量'的内容启动,bootcmd环境变量一般指示了从'某个flash地址'读取内核到启动的内存地址,然后启动,bootm。
uboot启动的内核为uImage,这种格式的内核是由'两部分'组成:'真正的内核'和'内核头部'组成,
'头部'中包括内核中的一些信息,比如'内核的加载地址','入口地址'。
uboot在接受到启动命令后,要做的主要是,
1,'读取'内核头部,
2,'移动'内核到合适的加载地址,
3,启动内核,执行do_bootm_linux
do_bootm_linux主要做的为,
1,设置启动参数,在特定的地址,保存启动参数,函数分别为
setup_start_tag,
setup_memory_tag,
setup_commandline_tag,
setup_end_tag,
根据名字我们就知道具体的段内存储的信息,
memory中为板子的'内存大小信息',
commandline为命令行信息,
2,跳到入口地址,启动内核
启动的函数为
the_kernel(0,bd->bi_arch_number,bd->bi_boot_param)
bd->bi_arch_number为板子的机器码,
bd->bi_boot_param为启动参数的地址
19. bootcmd和bootargs两个uboot环境变量的作用
bootcmd:<设置开发板的'自启动的环境变量'>
这个参数包含了一些命令,这些命令将在倒计时结束后,进入u-boot自启动模式后执行
setenv bootcmd tftp c2000000 uImage \; tftp c4000000 stm32mp157a-fsmp1a.dtb \; bootm c2000000 - c4000000
//-------------------------------------------------------------------------------
bootargs:这个参数设置要'传递给内核的信息',主要用来告诉'内核分区信息'和'根文件系统'所在的分区
setenv bootargs root=/dev/nfs nfsroot=192.168.1.250:/home/linux/nfs/rootfs,tcp,v4 rw console=ttySTM0,115200 init=/linuxrc ip=192.168.1.222
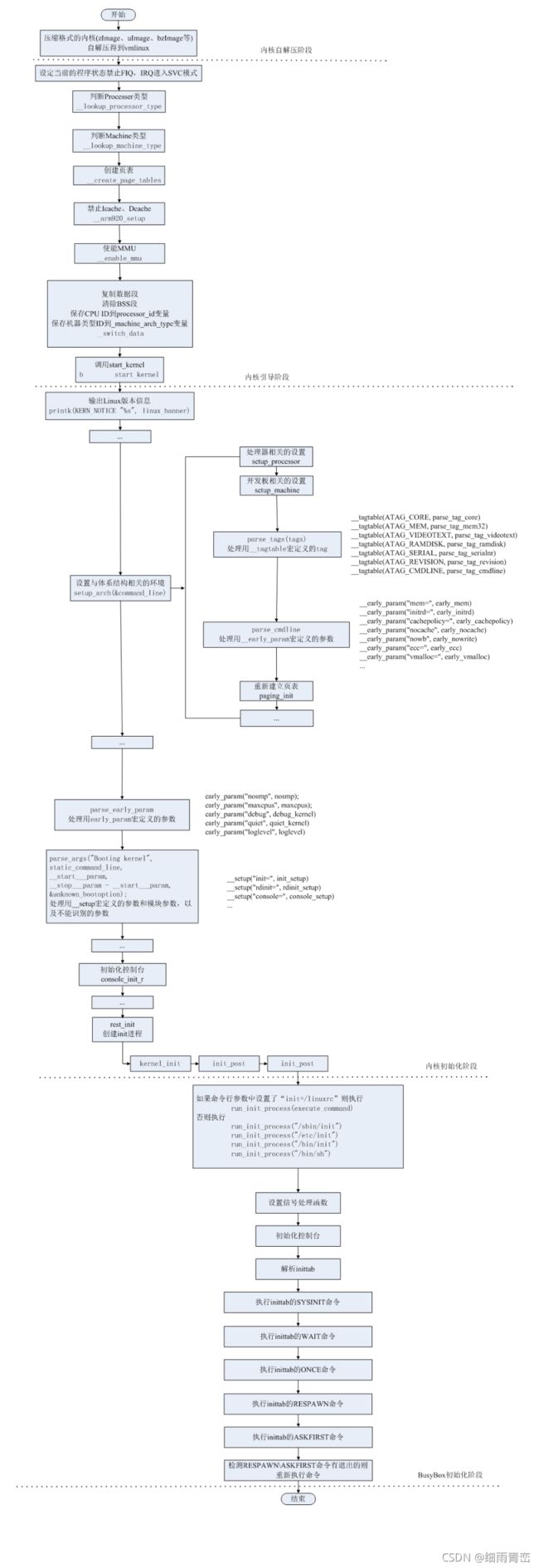
20. linux内核的启动过程
内核启动过程中主要干了那些事?
1> uboot通过'tftp命令'将'uImage下载'到内存中(下载内核)
2> 'uImage'需要完成'自解压'
3> 获取cpu的ID号,创建页表,初始化MMU,完成物理地址到虚拟地址的映射
4> '清除BSS段',bss段是用来存储静态变量,全局变量的
5> 完成绝'大多数硬件'的'初始化',进一步对硬件初始化< 内存,时钟,串口,EMMC,nfs客户端....>
5> 从'u-boot环境变量'的内存分区'获取bootargs参数','根据'bootargs'参数',决定从哪里'挂载根文件系统'。
6> '挂载'根文件系统
7> 执行根文件系统中的'1号进程','linuxrc'程序
8> 到此开发板的linux系统启动成功
21. uImage,zImage,vmlinux的区别
内核编译(make)之后会生成两个文件,
一个'Image',一个'zImage',
其中'Image'为'内核映像'文件,
而'zImage'为'内核'的一种'映像压缩文件',
'Image'大约为4M,
而'zImage'不到2M。----因为压缩了
那么uImage又是什么的?----zImage 加了个头
它是'uboot专用'的'映像'文件,它是在'zImage'之前'加上'一个长度为'64字节'的'头',
说明这个'内核的版本'、'加载位置'、'生成时间'、'大小'等信息;其'0x40'之后与'zImage没区别'。
如何生成uImage文件?
首先在uboot的/tools目录下寻找'mkimage'文件,把其copy到系统'/usr/local/bin'目录下,这样就完成制作工具。
然后在内核目录下运行'make uImage',
如果成功,便可以在'arch/arm/boot/'目录下发现'uImage'文件,其大小比zImage多'64个字节'。
其实就是一个自动跟手动的区别,
'有了'uImage'头部的描述',u-boot就知道对应Image的信息,
如果'没有头部'则需要自己'手动去添加那些参数'。
#U-boot的U是“通用”的意思。
22. Kconfig,.config,Makefile三个文件之间的关系
编译内核文件时,先要配置.config文件(make menuconfig --> 选择需要的驱动 ),
然后Makefile在编译时通过'读取.config文件'的'配置信息'来选择要编译的文件,选择驱动的加载方式。
.config文件的生成可通过 make menuconfig ARCH=arm 或 make defconfig 方式生成,
这两种方式看上去虽然不同,但是两者的原理是一样的,都是通过Kconfig文件的配置来的。
八. 系统移植
1. Linux内核启动流程—同上 七.20
1. Linux内核'自解压过程'
uboot完成系统引导以后,执行环境变量bootm中的命令;
即,将Linux内核调入内存中并调用do_bootm函数启动内核,跳转至kernel的起始位置。如果内核没有被压缩,则直接启动;如果内核被压缩过,则需要进行解压,被压缩过的kernel头部有解压程序。
压缩过的kernel入口第一个文件源码位置在/kernel/arch/arm/boot/compressed/head.S。它
将调用decompress_kernel()函数进行解压,
解压完成后,打印出信息“UncompressingLinux...done,booting the kernel”。
解压缩完成后,调用gunzip()函数(或unlz4()、或bunzip2()、或unlz())将内核放于指定位置,开始启动内核。
2. Linux内核'启动准备阶段'
由内核链接脚本/kernel/arch/arm/kernel/vmlinux.lds可知,内核入口函数为stext(/kernel/arch/arm/kernel/head.S)。
内核解压完成后,解压缩代码调用stext函数启动内核。
P.S.:内核链接脚本vmlinux.lds在内核配置过程中产生,由/kernel/arch/arm/kernel/vmlinux.lds.S文件生成。
原因是,内核链接脚本为适应不同平台,有条件编译的需求,故由一个汇编文件来完成链接脚本的制作。
(1)关闭IRQ、FIQ中断,进入SVC模式。调用setmode宏实现;
(2)校验处理器ID,检验内核是否支持该处理器;若不支持,则停止启动内核。调用__lookup_processor_type函数实现;
(3)校验机器码,检验内核是否支持该机器;若不支持,则停止启动内核。调用__lookup_machine_type函数实现;
(4)检查uboot向内核传参ATAGS格式是否正确,调用__vet_atars函数实现;
(5)建立虚拟地址映射页表。此处建立的页表为粗页表,在内核启动前期使用。Linux对内存管理有更精细的要求,随后会重新建立更精细的页表。调用__create_page_tables函数实现。
(6)跳转执行__switch_data函数,其中调用__mmap_switched完成最后的准备工作。
1)复制数据段、清除bss段,目的是构建C语言运行环境;
2)保存处理器ID号、机器码、uboot向内核传参地址;
3)b start_kernel跳转至内核初始化阶段。
3. Linux内核'初始化阶段'
此阶段从start_kernel函数开始。start_kernel函数是所有Linux平台进入系统内核初始化的入口函数。
它的主要工作是'完成剩余与硬件平台相关的初始化'工作,在进行一系列与内核相关的初始化之后,
调用'第一个用户进程init'并等待其执行。至此,整个内核启动完成。
3.1 start_kernel函数的主要工作
start_kernel函数主要完成'内核相关的初始化'工作。具体包括以下部分:
(1)内核架构 、通用配置相关初始化
(2)内存管理相关初始化
(3)进程管理相关初始化
(4)进程调度相关初始化
(5)网络子系统管理
(6)虚拟文件系统
(7)文件系统
start_kernel函数详解。
3.2 start_kernel函数流中的关键函数
(1)setup_arch(&command_line)函数'内核架构相关的初始化'函数,是非常重要的一个初始化步骤。
其中,包含了处理器相关参数的初始化、内核启动参数(tagged list)的获取和前期处理、内存子系统的早期初始化。
command_line实质是'uboot向内核''传递的命令行启动参数',即uboot中环境变量bootargs的值。
若uboot中bootargs的值为空,command_line = default_command_line,即为内核中的默认命令行参数,其值在.config文件中配置,对应CONFIG_CMDLINE配置项。
(2)setup_command_line、parse_early_param以及parse_args函数
这些函数都是在'完成命令行参数的解析、保存'。
譬如,cmdline = console=ttySAC2,115200 root=/dev/mmcblk0p2 rw init=/linuxrc rootfstype=ext3;
解析为一下四个参数:
console=ttySAC2,115200 //指定控制台的串口设备号,及其波特率
root=/dev/mmcblk0p2 rw //指定根文件系统rootfs的路径
init=/linuxrc //指定第一个用户进程init的路径
rootfstype=ext3 //指定根文件系统rootfs的类型
(3)sched_init函数初始化进程调度器,创建运行队列,设置当前任务的空线程。
(4)rest_init函数rest_init函数的主要工作如下:
1)调用kernel_thread函数启动了2个内核线程,分别是:kernel_init和kthreadd。
kernel_init线程中'调用prepare_namespace函数'挂载根文件系统rootfs;然后调用init_post函数,执行根文件系统rootfs下的第一个用户进程init。用户进程有4个备选方案,若command_line中init的路径错误,则会执行备用方案。
第一备用:/sbin/init,
第二备用:/etc/init,
第三备用:/bin/init,
第四备用:/bin/sh。
2)调用schedule函数开启内核调度系统;
3)调用cpu_idle函数,启动空闲进程idle,完成内核启动。
2. 什么是bootloader?在嵌入式系统当中bootloader的作用是什么?
Bootloader是'引导加载程序'的统称,#(Boot :引导 Loader : 加载)
是嵌入式系统上电后的第一段代码,其主要作用是将'硬件初始化'
到一个合适的状态并将'嵌入式操作系统''加载到内存中'执行。
3. 为什么汇编语言对硬件平台有依赖性而C语言却可以不依赖硬件平台?
'不同的处理器'因为'硬件的差异'其'机器码是不同'的,
'汇编语言'是将'机器码用符号'表示所以'不同的处理器''汇编语言也不同'。---解释型语言
C语言是'不能被CPU直接识别和执行'的,所以C程序需要'先被编译成机器码后'才能执行,---编译型语言--标准C库
如果我们使用的是ARM处理器那么编译的时候我们就将'C'编译成ARM的机器码,如果我们使用的是X86处理器
那么编译的时候我们就将C编译成X86的机器码,所以'C语言'可以'不区分硬件平台'。
4. 什么叫做交叉编译?
'交叉编译'就是在'一台主机'上'编辑和编译'程序,而把'编译好的程序'放到'另外一台机器'上执行。
比如嵌入式开发中我们在'电脑上编辑和编译程序',而编译好的程序'被下载到开发板'执行。
5. Linux平台下的可执行文件是什么格式?
'elf格式'的文件是linux平台下常用的'二进制格式'
6. 什么叫做反汇编?
因为'汇编语言'是用'符号来表示机器码',所以'汇编语言'和'机器码'是'一一对应'的,
所以我们可以将'汇编语言'编译成'机器码',同样如果有了'机器码'也可以'反推出汇编',
我们把通过机器码来推出汇编的过程叫做反汇编
7. 简述nfs服务的概念与作用?
NFS(Network File System)即'网络文件系统',
它允许网络中的计算机之间通过'TCP/IP网络''共享资源'。
在NFS的应用中,本地NFS的客户端应用可以透明地读写位于远端NFS服务器上的文件,就像访问本地文件一样。
8. 简述一个装有linux内核的开发板的启动过程?
一个装有linux内核的开发板上电后的
第一个程序一般是uboot,
uboot首先对'软硬件资源'进行'初始化',
然后将'固化'在存储器中的'内核'以及'相关文件'引导加载到'内存'中,
然后'内核开始运行',内核'首先'对'软硬件资源进行初始化',内核初始化完成后内核从指定位置去'挂载根文件系统'
根文件系统挂载完成后就可以运行上层的应用程序即完成了系统的启动。
9. 简述uboot的主要功能有哪些?
uboot最主要的功能有以下几点
1)'初始化一些硬件'为后续做准备
2)'引导'和'加载'内核
3)给'内核传参'
4)执行用户命令
10. uboot如何设置环境变量?
uboot中设置环境变量使用的是'setenv'命令,
比如我们想设置uboot的ipaddr环境变量为192.168.1.1就可以执行'setenv ipaddr 192.168.1.1'命令完成设置
11. 简述uboot中bootcmd环境变量的作用?–七.19
bootcmd:<设置开发板的'自启动的环境变量'>
这个参数包含了一些命令,这些命令将在倒计时结束后,进入u-boot自启动模式后执行
12. 简述uboot中bootargs环境变量的作用?–七.19
uboot除了可以引导和加载内核外还可以为内核传参,即给内核传递一些信息以便于内核的正确启动,我们可以先将这些信息(比如根文件系统位置、控制台信息等)写入到bootargs环境变量,然后uboot再将这些信息传递给内核使用。
13. 简述什么叫平台相关代码什么叫平台无关代码?
平台相关代码即和'硬件平台相关'的代码,当'硬件平台改变'后'这类代码'也'要做对应的修改'。
比如一些操作CPU、寄存器、引脚等相关代码,当硬件改变后这类代码就不再适用需要做对应的修改。
平台无关代码就是和'硬件平台无关'的代码,'不管硬件平台是否改变''这类代码都不用修改'。
平台相关: 跟硬件'平台有关代码'
arch
平台无关代码: 跟硬件'平台无关代码'
lib
include
drivers
toos
ipc
net
....
14.如何理解linux/uboot支持各种硬件平台?
一般情况下'不同的处理器'由于其'硬件的差异'其'代码是不兼容'的,
即便处理器相同外围的硬件设备不同代码也不兼容,
我们经常说linux/uboot支持各种硬件平台'并不是'其代码'真正的'能够'适用于任何平台',
而是在linux/uboot'源代码中'将其'所有支持的硬件平台'的'代码''都写了一遍',
使用的时候当前我们'使用的是什么平台'我们就'编译对应的代码'即可。
15. 如何配置uboot使其适合特定的开发板平台?
在uboot源码的顶层目录下执行'make <开发板名>_config'即可将其配置成'适合特定开发板平台'的'uboot'。
比如当前开发板的名字是origen那么我们在源码的顶层目录下执行make origen_config即可完成配置。
16. 如何编译uboot生成二进制文件?
在配置好的uboot源码的顶层目录下直接执行'make命令'即可编译uboot源码生成二进制的可执行文件。
17. 简述uboot的启动过程?
uboot主要做了两个阶段的事:
第一个阶段:汇编
构建'异常向量表'
禁止'mmu'和'cache',禁止'看门狗'
硬件时钟的'初始化','内存'的'初始化'
清除'bss'段 #bss段是用来存储静态变量,全局变量的
完成uboot代码的自搬移
'初始化C代码'运行的'栈空间'
第二个阶段:C
完成'大部分硬件'的'初始化','串口'的初始化,'内存'的进一步的初始化,'电源的'初始化 等等必要'硬件的'初始化
根据命令是否进入'交互模式'还'自启动模式'
获取uboot的'环境变量',
执行'bootcmd中的命令',
最终'给内核传递参数'(bootargs)
18. 操作系统的作用有哪些?
内存管理
文件管理
网络管理
进程管理
设备管理
#(这是Linux内核的功能)
19. 如何配置linux源码使其适合特定的处理器?
在linux源码中执行'make <处理器名>_defconfig'即可将其配置成'适合特定的处理器'的代码。
比如现在使用的处理器是exynos,那么我们在linux源码顶层目录下执行命令make exynos_defconfig即可完成配置。
20. 在make menuconfig界面下有些驱动可以被选成三种状态即“Y”,“N”,“M”这三种状态分别是什么含义?
Y--选配'到内核里',编译后的内核就包含了该驱动程序,同样内核的体积也会随之增大
N--'不会被编译'进内核,即编译后的内核也不支持该驱动
M--'模块化编译'到内核里,要将该驱动编译成模块,在编译内核的时候该驱动'不会被编译',但可以单独编译成一个驱动模块使用的时候临时加载该模块。
21. 如何编译被选中为“M”选项的驱动模块?
在linux源码的顶层目录下执行'make modules'即可将选为“M”的驱动编译成驱动模块。
insmod 可以安装这个驱动
lsmod 查看驱动
rmmod卸载驱动
22. 简述设备树的作用?
设备树(Device Tree)是种'描述硬件的数据结构',在操作系统(OS)'引导阶段'进设备'初始化'的时候,数据结构中的'硬件信息''被检测并传递'给'操作系统'。
内核中的'驱动程序''没有'开发板'硬件信息',比如'管脚的信息'、'寄存器的地址'等,所以驱动程序'不能正确的驱动'一个具体的硬件设备工作,设备树是'专门'描述开发板'硬件信息'的'文件',所以有了'设备树','驱动程序'和开发板上'具体的硬件'设备就能'建立起关系'使驱动正常工作。
23. 编写设备树文件的主要依据是什么?
设备树文件是描述开发板硬件信息的文件,
所以编写设备树的'主要依据'是根据开发板硬件的信息。
24. 简述如何将一个内核源码中已有的驱动程序编译到内核中?
首先在'make menuconfig'中'选中'我们想要的驱动,
因为内核自带的驱动程序中'没有开发板的硬件信息',
所以我们还要'按照实际的硬件信息'去'修改设备树'文件,
然后'重新编译'内核和设备树就可以将驱动编译到内核。
25. 简述如何将一个自己编写的驱动程序编译到内核中?
首先我们将自己编写的'驱动程序'放入到'内核源码'中,
然后修改对应的'Kconfig文件'使自己写的驱动能在'make menuconfig'界面中显示出来,
然后还需要修改'对应的Makefile'使驱动能'正确编译',
以上步骤完成后 编译就可以将'驱动编译进内核'。
26.在内核启动过程中如果控制台已经初始化我们一般采用什么方式来调试内核?
如果控制台已经初始化我们一般使用'printk函数'来打印我们自己的信息
27. linux内核在启动过程中遇到什么情况会打印系统崩溃报告Oops?
当linux内核在启动过程中出现以下几种问题的时候会打印'系统崩溃报告'
1)内存访问'越界' 2)使用'非法指针' 3)使用了'NULL指针' 4)使用了'不正确的指针'
28. linux内核在启动过程中遇到某些问题会打印系统崩溃报告Oops,报告中主要打印哪些内容?
报告中可以将CPU中'各个寄存器的值'、'页描述符表的位置'以及'其他信息'打印出来。
29. 简述什么叫文件系统?什么叫根文件系统?
文件系统是一种'管理和访问磁盘'的'软件机制',其'本质'是'软件',不同'文件系统'管理和访问磁盘的'机制不同'。
根文件系统是'存放运行系统'所必须的'各种工具软件'、'库文件'、'脚本'、'配置'等文件的地方
'实质'就是'一些文件'
30. 开发板中为什么一般不需要安装静态库?
库可以分为'静态库'和'动态库'
'静态库'一般是'编译程序'的时候'使用'
而'动态库'一般是'程序运行'的时候'使用'
在嵌入式开发中一般我们使用'交叉编译'的方式,即我们编辑和编译程序是在电脑下而程序编译完成后下载到开发板执行,所以'一般不会在开发板编译程序',所以开发板'一般不需要安装静态库'。
九. 驱动开发
1. 什么是模块?
Linux 内核的整体结构已经非常庞大,而其包含的组件也非常多。
这会导致两个问题,
一是生成的'内核会很大',
二是如果我们要在现有的'内核中新增或删除功能',将不得不'重新编译内核'。
Linux 提供了这样的一种机制,这种机制被称为'模块(Module)'。使得编译出的内核本身并'不需要包含所有功能',而在这些功能需要'被使用的时候',其'对应的代码'被'动态地加载到内核'中。
2. 驱动类型有几种
字符设备驱动、块设备驱动、网络设备驱动
3. 字符设备驱动框架编程流程?
模块加载部分:
1- 生成设备号
2- 注册设备号
3- 初始化字符设备对象,编写填充file_operations结构体集合
4- 添加注册字符设备
模块卸载部分:
1- 取消cdev注册
2- 取消设备号注册
4. 什么是并发,驱动中产生竞态的原因有哪些?
并发(concurrency)指的是'多个执行单元''同时、并行'被'执行',而并发的执行单元对'共享资源'(硬件资源和软件上的全局变量、静态变量等)的'访问'则很容易导致竞态(race conditions)
产生竟态的原因:当'多个进程'同时访问'同一个'驱动的'临界资源'的时候竞态就产生了。
1.对于'单核CPU'来说,如果支持'进程抢占',就会产生竞态。
2.对于'多核CPU'来说,核与核之间'本身'就会产生竞态
3.中断和进程间 会产生竞态
#(arm)中断和中断间会产生竞态 (###错误的###)
5. 解决竞态的途径有哪些?分别有什么特点?
1.顺序执行
2.互斥执行
中断屏蔽:都只能禁止和使能本CPU内的中断,因此,并不能解决SMP多CPU引发的竞态
自旋锁 :又叫忙等待锁。自旋锁期间不能有睡眠的函数存在,也不能主动放弃cpu的调度权,也不能进行耗时操作。否则容易造成死锁。
信号量 :是内核中用来保护临界资源的一种,与应用层信号量理解一致
3.互斥体
4.原子操作
6. 驱动中IO模型有几种?
(1)阻塞式IO 最简单,最常用,效率最低的io操作
(2)非阻塞式IO 需要不断的轮询。
(3)多路IO复用 解决多路输入输出的阻塞问题
(4)信号驱动IO 异步通信机制,类似于中断。
7. 设计linux设备模型的主要作用?
实现'硬件地址信息'与'软件驱动'分离 ----这特么是设备树吧
8. 字符设备驱动框架与linux设备模型是否矛盾?
字符设备驱动框架,主要为了使'应用程序'能够经过'层层调用',访问'底层硬件'。
linux设备模型实现'硬件地址信息'与'软件驱动'分离
所以二者并不矛盾。
9. platform架构分别分为哪个部分?他们通过什么进行匹配
platform运用的'分离'的思想,将'设备信息'和'设备驱动'分离,分离后借助'总线'模型 'devicebus driver'完成匹配的过程。
匹配'成功'之后执行'驱动中的probe函数',在probe中操作硬件即可
如果两者'分离'执行驱动中的'remove函数'。bus就完成匹配的工作(bus是内核实现的)。
设备,驱动,总线;
1- 按名称匹配
2- 按id_table表进行匹配
10. 设备树与platform架构是否有矛盾?
没有矛盾
'设备树'是对'设备模型'中,'硬件资源'描述部分,进行简化升级。将以前的资源'结构体',改成'设备树节点'的形式进行描述,降低了难度系数
11. 为什么要将中断分为上下半部?上下半部机制有哪些?
在中断处理函数只能做'简短不耗时'的操作,但是'有的时候'又希望在中断到来的时候'做相对耗时的操作',这样就产生了矛盾,linux内核为了解决这个矛盾引入了'中断底半部'的概念。
将这些'耗时操作'放到中断底半部完成。---但是还是不能有延时函数,因为虽然是中断底半部,但也属于中断,优先级比一般进程要高--。
#例如:当网卡中断到来的时候需要去接受网络传递过来的数据,此时就是一个耗时操作应该放到中断底半部完成。中断底半部的机制 软中断 , tasklet , 工作队列
12. 工作队列与tasklet的区别?
tasklet:
tasklet是'基于'软中断实现的,本身是通过'链表'实现的,因此'没有个数'限制。
tasklet工作在'中断上下文',它是中断的'一个部分','不能脱离'中断执行。
可以做'相对耗时'操作,但是'不能'做休眠的操作。
工作队列:
在内核启动的时候会启动一个'events'的线程这个线程默认处于'休眠'状态,在这个线程中维护一个'工作队列'。
如果想'使用工作队列'就向队列中'提交队列项',然后'唤醒events线程',让它去调用队列项中的'底半部处理函数'即可。
工作队列'可以脱离'中断执行,'没有个数限制',工作于'进程上下文'。在底半部处理函数中可以做延时,耗时,'甚至'休眠的操作。
#-------------------------------------------------------
区别:
工作队列的'使用方法'和tasklet非常'相似'
tasklet运行于'中断上下文'
工作队列运行于'进程上下文'
tasklet处理函数中'不能睡眠',而工作队列处理函数中'允许睡眠'
13. 内核中内存分配函数分别有哪些?分别有什么特点?
按页(page)分配 __get_free_pages ()
调用者指定'所需整页'的阶数作为参数之一来请求
所申请的页将会'被加入内核空间'
所分配的'物理RAM空间'是'连续'的
kmalloc
除了是'请求精确字节'的'内存'外,与按页分配相同
vmalloc
除了'物理内存不一定连续'外,与kmalloc同
14. 内核调试
a.可以使用printk打印内核信息,printk的调试级别如下
#define KERN_EMERG "0" /* system is unusable */
#define KERN_ALERT "1" /* action must be taken immediately */
#define KERN_CRIT "2" /* critical conditions */
#define KERN_ERR "3" /* error conditions */
#define KERN_WARNING "4" /* warning conditions */
#define KERN_NOTICE "5" /* normal but significant condition */
#define KERN_INFO "6" /* informational */
#define KERN_DEBUG "7" /* debug-level messages */
//打印级别的作用是用于过滤打印信息的。
<0> ------------ <7>
最大级别 最小级别
只有当'消息的级别'大于'终端的级别'的时候消息'才会'在终端上'显示'
可以通过'/proc/sys/kernel/printk' cat 这个文件来查看
cat /proc/sys/kernel/printk
4 4 1 7
终端的级别 默认消息的级别 终端的最大级别 终端的最小级别
//注意 : 修改级别的时候 只能使用 echo 重定向,不能使用 vim
b. gdb 和 addr2line 调试内核模块
大致流程如下
1.编写的makefile中的gcc加上-Wall -g选项,方便后续调试
2.加载内核模块的时候产生oops,利用dmesg 来查看 panic 内容 (例如:dmesg |tail -20)
3.查看日志内容,找到oops 发生的关键日志,(注意:出现 oops 的是从模块的基地址偏移出来的地址)
4.找到oops发生的基地址,cat /proc/modules |grep oops
5.使用 addr2line 找到 oops 位置,(addr2line -e oops.o 0x14,偏移量=偏移地址-基地址,这里的,0x14就是偏移量)
6.上面的运行结果返回的是源码某个.c文件里的行号,也就是知道了代码导致 oops 的位置是第几行
7.通过objdump 来查找oops 位置(objdump -dS --adjust-vma=0xffffffffa0358000oops.ko)
8.终端打印的结果可以看到反汇编出来的c代码,也就是知道了产生oops的内存地址对应的c代码是哪一句
c. 使用函数BUG_ON(),BUG()和dump_stack()调试内核
使用方法:
1.编写内核驱动模块的时候,在想要查看具体信息的函数中调用BUG_ON(),BUG()或者dump_stack()
2.执行sudo insmode xxx.ko后在kernle日志下可以看到调用函数的具体信息,带绝对路径的文件名和行号等
15. 字符设备驱动的框架
字符设备:提供连续的数据流,应用程序可以顺序读取,通常不支持随机存取,支持按字节/字符来读写
数据。
块设备:应用程序可以随机访问设备数据,程序可自行确定读取数据的位置。应用程序可以寻址磁盘上
的任何位置,并由此读取数据。此外,数据的读写只能以块(通常是512B)的倍数进行。与字符设备不
同,块设备并不支持基于字符的寻址。
网络设备:网络设备是特殊设备的驱动,它负责接收和发送帧数据,可能是物理帧,也可能是ip数据
包,这些特性都有网络驱动决定。它并不存在于/dev下面,所以与一般的设备不同。网络设备是一个
net_device结构,并通过register_netdev注册到系统里,最后通过ifconfig -a的命令就能看到。
16. 字符设备和块设备和网络设备的区别
字符设备:
提供连续的'数据流',应用程序可以'顺序读取',通常'不支持随机存取',支持按'字节/字符'来读写数据。
块设备:
应用程序可以'随机访问设备数据',程序可'自行确定'读取数据的'位置'。应用程序可以'寻址'磁盘上的'任何位置',并由此读取数据。
此外,数据的读写'只能以块(通常是512B)的倍数'进行。与字符设备不同,块设备并'不支持'基于字符的寻址。
网络设备:
网络设备是'特殊设备'的驱动,它负责'接收和发送'帧数据,可能是'物理帧',也可能是'ip数据包',这些特性都有网络驱动决定。
它并不存在于/dev下面(因为在写Linux内核之前网络协议就有了),所以与一般的设备不同。网络设备是一个net_device结构,并通过'register_netdev'注册到系统里,最后通过'ifconfig -a'的命令就能看到。
17. 并发和竞态概念,那些情况会出现竟态,解决竟态的方法,以及区别,使用场景。—上面第4题
并发(concurrency)是指'多个执行单元''同时、并行'的'被执行',而并发执行单元对共享资源的访问很容导致竞态(race condition)。
并发与竞态发生的条件:
对称多处理器(SMP)的多个CPU;单CPU内进程与抢占它的进程;中断与进程之间。
当'多个进程'同时访问'同一个'驱动的'临界资源'的时候竞态就产生了。
1.对于'单核CPU'来说,如果支持'进程抢占',就会产生竞态。
2.对于'多核CPU'来说,核与核之间'本身'就会产生竞态
3.中断和进程间 会产生竞态
解决并发与竞态的途径:
访问共享资源的代码区域称为'临界区域(critical section)'',解决竞态的根本途径就是对临界区的互斥访问,方法主要有中断屏蔽、原子操作、自旋锁、信号量、互斥体。
1. 中断屏蔽
单CPU避免竞态的'简单办法'就是'中断屏蔽',保证可以防止中断与进程间竞态条件的发生(所有中断被屏蔽后进程间切换的基础时钟中断也被屏蔽掉了)。
2.原子操作
原子操作是指在执行过程中不会被别的代码路径所中断,可分为整形原子操作和位原子操作。
3.自旋锁
自旋锁主要针对SMP或单CPU且内核可抢占的情况,自旋锁可以保证临界区不受别的CPU和本CPU内的抢占进程打扰。当临界区可能受到中断和底半步影响时,应该使用自旋锁的衍生操作。
自旋锁是忙等待锁,当锁不可用时,CPU会不停地循环测试而不能做其它的工作,因此自旋锁会降低系统的性能。
如果临界区域发生阻塞,可能会导致死锁,因此在自旋锁占有期间内不能调用copy_from_user(),copy_to_user(), kmalloc()等函数。
4、信号量
信号量和自旋锁不同的地方在于当进程得不到信号量时,进程会进入休眠或其它状态。
18. 自旋锁和信号量的区别
自旋锁:
当一个程序获取到自旋锁后,另外一个程序也想获取这把锁,此时后一个进程处于自旋状态(忙等,原地打
转)
1.针对'多核处理器'有效
2.自旋的时候需要'消耗cpu资源'
3.自旋锁会'导致死锁'。//---> 加锁了以后 又加一次,然后就会死锁
4.自旋锁可以工作在'中断处理函数'中
5.在自旋锁'内部不能有'延时,耗时,甚至休眠的操作。还'不能
有'copy_to_user/copy_from_user函数。
6.自旋锁在'上锁的时候'会'关闭抢占'
信号量:
信号量:当一个程序获取到信号量后,另外一个程序也想获取这个信号量,此时后一个进程处于休眠状态。
1.等待获取信号量的进程'不占用cpu资源'
2.针对'多核设计'的
3.信号量'不会产生死锁'
4.信号量保护的'临界区可以很大',里面'可以有'延时、耗时,甚至休眠的操作
5.信号量'不能用于'中断处理函数中
#------------------------------------------------------------------------
当临界区'执行时间比较小'时,采用自旋锁,否则采用信号量;
'自旋锁'绝对不能在临界区包含可能'引起阻塞的代码',信号量可以;
如果临界区的代码在'中断中'执行,应该使用'自旋锁'或'信号量的down_trylock()函数'。
19. 谈谈你对中断上下文,进程上下文的理解
进程上下文:
进程上文:
其是指进程由'用户态'切换到'内核态'是需要'保存用户态时cpu寄存器中的值','进程状态'以及'堆栈上的内容',
即保存'当前进程的进程上下文',以便'再次执行'该进程时,能够恢复切换时的状态,继续执行。
进程下文:
其是指'切换'到'内核态'后执行的程序,即进程运行在内核空间的部分。
#--------------------------------------------------------------------------------
中断上下文:
中断上文:
硬件通过'中断'触发信号,导致内核调用中断处理程序,进入'内核'空间。这个过程中,硬件的一些'变量和参数'也要传递给'内核',内核通过这些参数进行中断处理。
中断上文可以看作就是'硬件传递'过来的这些'参数'和内核需要保存的一些其他环境(主要是当前被中断的进程环境。)
中断下文:
执行在内核空间的中断服务程序。
20. 中断低半部主要做了什么
为了在中断执行'时间尽可能短'和中断处理'需完成大量工作'之间找到一个平衡点,Linux将中断处理程序分解为两个半部:顶半部(top half)和底半部(bottom half)。
顶半部完成尽可能少的比较紧急的功能,它往往只是简单地读取寄存器中的中断状态并清除中断标志后就进行“登记中断”的工作。
“登记中断”意味着将底半部处理程序挂到该设备的底半部执行队列中去。这样,顶半部执行的速度就会很快,可以服务更多的中断请求。
现在,中断处理工作的重心就落在了底半部的头上,它来完成中断事件的绝大多数任务。
底半部几乎做了中断处理程序所有的事情,而且可以被新的中断打断,这也是底半部和顶半部的最大不同,因为顶半部往往被设计成不可中断。底半部则相对来说并不是非常紧急的,而且相对比较耗时,不在硬件中断服务程序中执行。
尽管顶半部、底半部的结合能够改善系统的响应能力,但是,僵化地认为Linux设备驱动中的中断处理一定要分两个半部则是不对的。如果中断要处理的工作本身很少,则完全可以直接在顶半部全部完成。
其实上面这一段大致说明一个问题,那就是:中断要尽可能耗时比较短,尽快恢复系统正常调试,所以把中断触发、中断执行分开,也就是所说的“上半部分(中断触发)、底半部(中断执行)”,其实就是我们后面说的中断上下文。下半部分一般有tasklet、工作队列实现,触摸屏中中断实现以工作队列形式实现的
中断下半部的处理对于一个中断,如何划分出上下两部分呢?哪些处理放在上半步,哪些放在下半部?
这里有一些经验可供借鉴:
如果一个任务对时间十分敏感,将其放在上半部。
如果一个任务和硬件有关,将其放在上半部。
如果一个任务要保证不被其他中断打断,将其放在上半部。
其他所有任务,考虑放在下半部。
21. Platfprm平台总线驱动模型
相对于USB、PCI、I2C、SPI等物理总线来说,platform总线是一种'虚拟、抽象'出来的总线,实际中并不存在这样的总线。
那为什么需要platform总线呢?
其实是Linux设备驱动模型为了保持设备驱动的统一性而虚拟出来的总线。
因为对于usb设备、i2c设备、pci设备、spi设备等等,他们与cpu的通信都是直接挂在相应的总线下面与我们的cpu进行数据交互的,但是在我们的嵌入式系统当中,并不是所有的设备都能够归属于这些常见的总线,在嵌入式系统里面,SoC系统中集成的独立的外设控制器、挂接在SoC内存空间的外设却不依附与此类总线。
所以Linux驱动模型为了保持完整性,将这些设备挂在一条虚拟的总线上(platform总线),而不至于使得有些设备挂在总线上,另一些设备没有挂在总线上。
platform总线管理
(1)两个结构体platform_device和platform_driver
(2)两组接口函数(driver\base\platform.c)
// 用来注册设备驱动
int platform_driver_register(struct platform_driver *);
// 用来卸载设备驱动
void platform_driver_unregister(struct platform_driver *);
// 用来注册设备
int platform_device_register(struct platform_device *);
// 用来卸载设备
void platform_device_unregister(struct platform_device *);
不管是'先注册设备'还是'先注册设备驱动'都会进行一次'设备与设备驱动'的匹配过程,匹配成功之后就会调用'probe函数',
匹配的'原理'就是去'遍历'总线下的相应的'链表'来找到挂接在他下面的设备或者设备驱动。
(3) platform总线下的匹配函数,platform_match函数platform总线下设备与设备驱动的匹配原理就是通过名字进行匹配的,先去匹配platform_driver中的id_table表中的各个名字与platform_device->name名字是否相同,
如果相同表示匹配成功直接返回,
否则直接匹配platform_driver->nameplatform_driver->name是否相同,相同则匹配成功,否则失败。
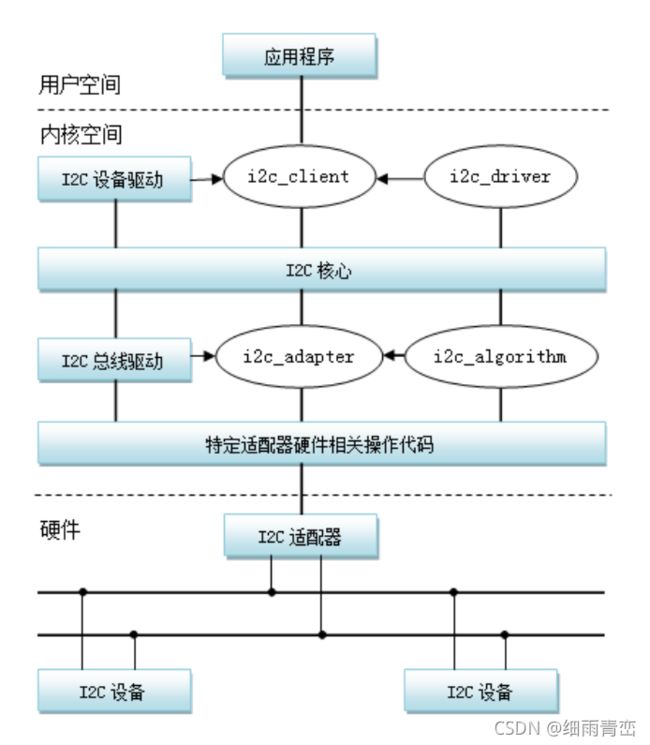
22. IIC子系统驱动框架
23. 输入子系统驱动框架
子系统的组成

输入子系统的事件处理机制示意图
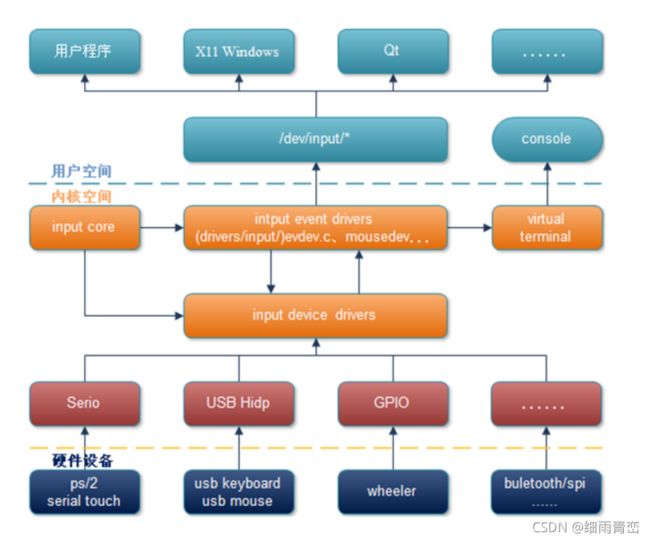
输入子系统剖析
