作为基础软件皇冠上的明珠,数据库技术一直以来都是开发者关注的焦点。这关注度是如此之高,几乎自然打通了学界和产业界的隔阂,以至于关于数据库技术的每一篇重要论文面世,都可能导致一批价值数十亿美金的公司出现。
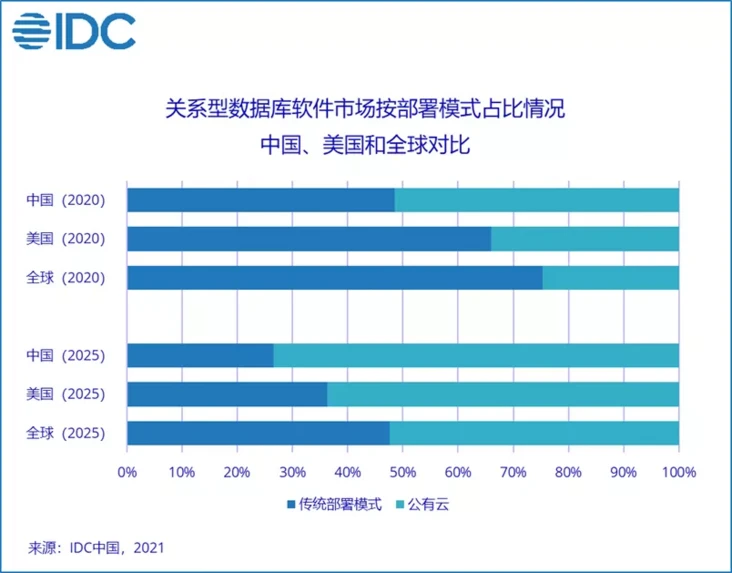
而在最近几年,纵观整个数据库产业,云数据库逐渐成为焦点中的焦点。据 Gartner, Inc 称,到 2022 年,所有数据库中有 75% 将部署或迁移到云平台,只有 5% 曾考虑返回到本地。而 IDC 认为,到 2025 年,全球超过 50% 的数据库将部署在公有云上;在中国市场,这个数据更为夸张,达到了 70% 以上。
那么问题来了,如果云数据库,或者叫云原生数据库,是确凿无疑的下一个风口。那么其当下主要的技术和发展方向是什么?我们该如何看待云原生数据库的发展趋势?亚马逊云科技在 2020 年发布的 Babelfish 或许能够带给我们一些启发。
Babelfish,一个被人低估的重磅发布
Babelfish 在 2020 年的 re:Invent 上发布,由亚马逊云科技 CEO Andy Jassy 宣布。
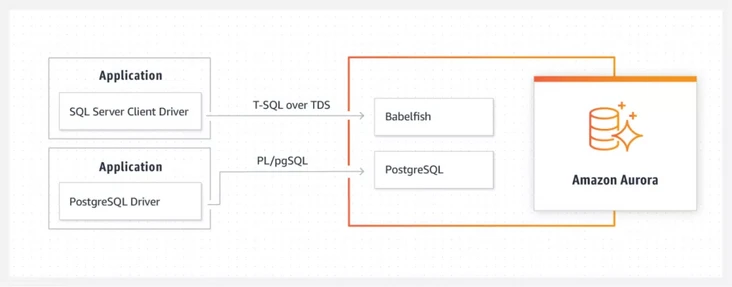
简单来说,Babelfish 是云数据库 Amazon Aurora PostgreSQL 的一个插件,它让 Aurora 能够兼容 Microsoft SQL Server 编写的应用程序。
Babelfish 刚刚发布,Youtube 上就有许多工程师制作视频表达了不理解。因为自打云数据库出现,相关迁移服务就在产业内随处可见,几乎每一家公有云企业,都能提供相关迁移服务,只不过大部分是针对 Oracle 的。有一家叫做 Enterprise DB 的美国,专门提供从 Oracle 到 PostgreSQL 的迁移服务。相关代理层、SQL 语言转换工具更是层出不穷。
事实上,亚马逊云科技自己就有相关的迁移服务,比如 Amazon Schema Convertion Tool 做架构迁移,Amazon Database Migration Service 做存储迁移。
那么,Babelfish 存在的意义是什么呢?多加一层代理增加后端处理成本吗?
实际上,只迁移架构和存储是不完整的,构建在数据库之上的应用还没有完成迁移。以 Babelfish 服务的场景来说,基于 Microsoft SQL Server 构建的应用使用 T-SQL 与数据库交互,这与 PostgreSQL 完全是两码事。如果你想将应用也同步迁移,除非把这部分重写一遍。
这也让数据库迁移成为了业内非常少见的动作,不是大家不想(毕竟谁也没法保证最初的架构选型永远正确),但成本实在是太高。
这种迁移成本,我们可以通过一套比较通用的迁移方案来感受下:
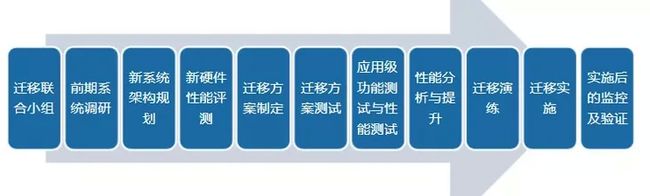
比起这种沉重的迁移,如果数据库天生兼容,是不是方便太多了?这也是 Babelfish 存在最主要的意义。
而许多人,会低估 Babelfish ,可能也是因为只看见了其商业层面的意义,而没有注意到其技术层面的难度。
Oracle 和 PostgreSQL,许多特性相同,转换尚且困难;切换到 T-SQL 和 PostgreSQL 就更加复杂了。数据库的同步转换要注意许多异常复杂的细节问题,包括查询语言的转换,存储过程的转换,静态游标的转换,触发器的转换,等等。
亚马逊云科技 的 Sébastien Stormacq 曾在发布的博客中指出,在 T-SQL 中,MONEY 类型具有四位小数精度, PostgreSQL 则只有两位小数精度,这种细微的差异可能会导致四舍五入错误,并对下游流程(例如财务报告)产生重大影响。
他说:“在这种情况下,Babelfish 会确保保留了 SQL Server 数据类型的语义和 T-SQL 功能:我们创建了一个 MONEY 数据类型,使其行为与 SQL Server 应用程序预期的一样。”
Babelfish 的方案是用 hooks(钩子)方法在 PostgreSQL 内置引擎中实现,将自己暴露为不同的数据库(否则就只能修改 PostgreSQL 许多核心区域的代码),其架构图如下:
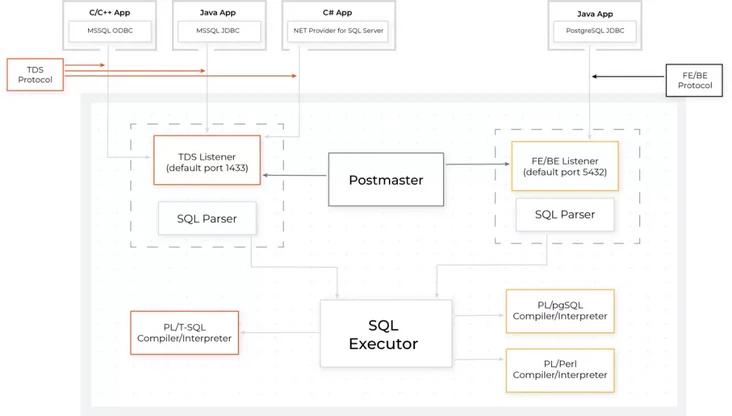
精妙之处在于,通过数据库内核部分执行器层面的扩展开发,Babelfish 实现了 T-SQL 与 pgSQL 之间的互相调用。也就是说,新写 PostgreSQL 代码可以调用之前应用写的 SQL Server 代码。对于写过存储过程的朋友们来说,这个功能已经和 Babelfish 的名字一样,带上“科幻”色彩了。即便已经使用了最硬核的实现方式, Babelfish 也没有完全实现兼容,ADD SIGNATURE 等一些功能、语法还没有实现。亚马逊官方工程师说:“SQL Server 已经发展了 30 多年,我们不希望立即支持所有功能。相反,我们专注于最常见的 T-SQL 命令并返回正确的响应或错误消息。”
这也恰恰说明了类似迁移加速器的开发难度,也证实了为什么开源路线才是最适合 Babelfish 发展的,因为开源可以让足够多的开发者参与到产品迭代中来。
同理,一个如此高难度的开发项目,也不太可能是无足轻重的。相反,它可能是亚马逊云科技 2020 年最重要的发布之一。
数据库碎片化时代,真的来了?
亚马逊在云计算领域的发布,曾多次引导了整个产业的发展方向。比如,2012 年发布的 Amazon Redshift 引导了云原生数仓的发展方向,2014 年发布的 Amazon Lambda 引导了 Serverless 的发展方向(Gartner 到 2019 年才确认 Serverless 为未来趋势),Amazon Aurora 本身也是云原生数据库的先驱产品。
如果说,Babelfish 也代表了一种方向,那么或许是,数据库碎片化的时代,真的来了。
数据库这个产品本身因为开发难度太高,长期以来都被少数几家公司把控着,其中的佼佼者 Oracle 更是以极快的速度提升着商业数据库的开发门槛。
但数据库“单极”化发展后导致的价格高、绑定风险高等问题,也让众多企业逐渐难以忍受。当下,各种类型的数据库层出不穷,关系型、键值、时序、图形……让人难以抉择。另外一个重要的现象是,大部分云原生数据库都是基于 PostgreSQL 研发而来,但后续的许多研发力量却没有投入到高性能、高可拓展性等传统技术概念本身。
数据库兼容,这一开发难度高,与性能无关的特性,却成为了亚马逊云科技的研发重点。某种意义上也说明,遍地开花的各类型数据库还将长期存在于产业内。人们习惯认为,产业的长期发展趋势是从单一走向多元,最终经过市场筛选,回归单一。但这次,“单极”时代可能真的一去不复返了。
此外,在 2020 Gartner 的魔力象限报告里,云数据库领域有数家占领导位置的企业,亚马逊、微软、Google 位居前三位。
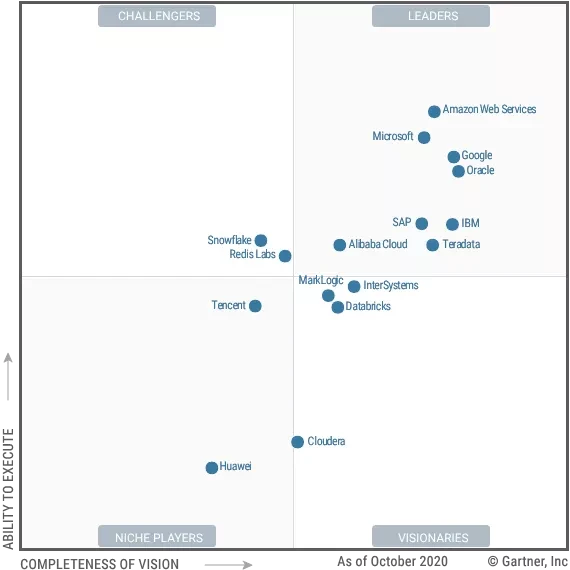
而就在 2019 年,前三名还是微软、Oracle、亚马逊。老大老三打着打着,老二没了……
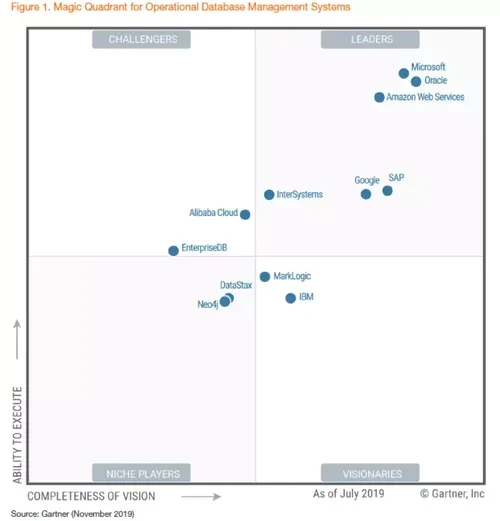
如今,有 Babelfish 加持的 Amazon Aurora ,兼容了 Microsoft SQL Server ,恐怕受伤的还是 Oracle。云数据库之间的墙壁在倒塌,而传统商业型数据库的竞争难度在进一步加大。
而乘上碎片化时代东风,发布了 Babelfish 的 Amazon ,也顺理成章的成为了云数据库市场新的领头羊。
写在最后
数据库行业远未走到终局,也不会有所谓的终局。但云原生数据库可以获得的优势并不仅限于数据库本身,比如 Amazon Aurora Serverless 提供的弹性伸缩服务,Amazon Aurora Global Database 提升了数据全球同步能力与业务连续性,Amazon DevOps Guru 将机器学习引入了应用管理。这是“合力”,将数据库在云上的体验拉伸到了全新的维度。
在云数据库领域,这种“合力”将主导接下来的市场格局。
11 月 30 日,2021 re:Invent 又将到来,Adam Selipsky 将首次以亚马逊云科技新任 CEO 的身份亮相。相信云数据库市场的趋势动向,也将随之更加清晰。
