
概述
freeswitch的核心源代码是基于apr库开发的,在不同的系统上有很好的移植性。
哈希表在开发中应用的非常广泛,主要场景是对查询效率要求较高的逻辑,是典型的空间换时间的数据结构实现。
大多数的底层库有各自的哈希表实现方法,那么apr库中对于哈希表究竟是如何实现的呢,其中有什么优点和缺点?
下面我们对apr库的哈希表实现做一个介绍。
环境
centos:CentOS release 7.0 (Final)或以上版本
freeswitch:v1.8.7
GCC:4.8.5
哈希表数据结构
apr库的哈希表源代码文件在libs/apr目录下。
libs\apr\include\apr_hash.h
libs\apr\tables\apr_hash.c
哈希表结构体定义在apr_hash.c中。
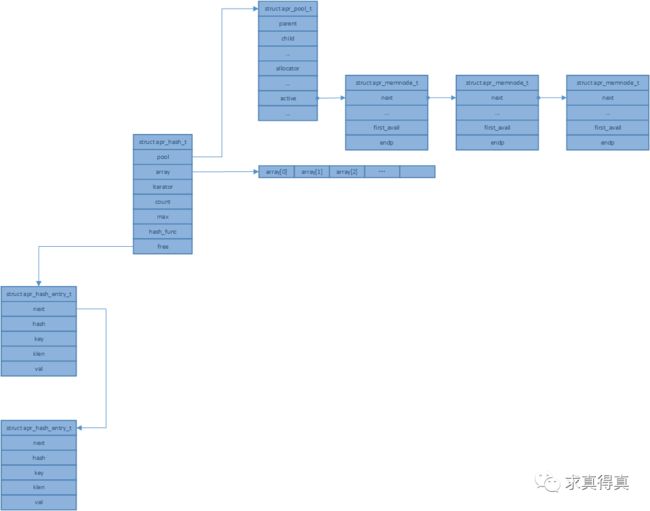
struct apr_hash_entry_t {
apr_hash_entry_t *next;
unsigned int hash;
const void *key;
apr_ssize_t klen;
const void *val;
};
struct apr_hash_index_t {
apr_hash_t *ht;
apr_hash_entry_t *this, *next;
unsigned int index;
};
struct apr_hash_t {
apr_pool_t *pool;
apr_hash_entry_t **array;
apr_hash_index_t iterator; /* For apr_hash_first(NULL, ...) */
unsigned int count, max;
apr_hashfunc_t hash_func;
apr_hash_entry_t *free; /* List of recycled entries */
};

常用函数
查看源代码头文件libs\apr\include\apr_hash.h。
apr_hashfunc_default //默认hash函数
apr_hash_make //创建hash表
apr_hash_make_custom //创建hash表,自定义hash函数
apr_hash_copy //复制hash表
apr_hash_set //hash表插入一个新的键值对
apr_hash_get //hash表查找key对应的value
apr_hash_first //hash表遍历,第一个节点
apr_hash_next //hash表遍历,下一个节点
apr_hash_this //hash表遍历,获取当前节点内容
apr_hash_count //hash表键值对计数
apr_hash_clear //清空所有键值对
apr_hash_overlay //合并俩个hash表
apr_hash_merge //合并俩个hash表,自定义冲突处理函数
apr_hashfunc_default默认哈希函数
apr库哈希表默认的哈希函数使用times33哈希算法,times33算法很简单,就是不断的乘33。
对于字符串类型的key,times33算法很好用,计算很快,hash结果分布均匀。
核心代码如下:
if (*klen == APR_HASH_KEY_STRING) {
for (p = key; *p; p++) {
hash = hash * 33 + *p;
}
*klen = p - key;
}
else {
for (p = key, i = *klen; i; i--, p++) {
hash = hash * 33 + *p;
}
}
apr_hash_make创建
apr库哈希表的创建函数。
1, 从内存池分配apr_hash_t大小的内存。
2, 字段初始化,包括内存池指针赋值,free指针设置为NULL,count设置为0,max为INITIAL_MAX(15), array指针数组内存分配,hash函数使用apr_hashfunc_default。

apr_hash_set插入
apr库哈希表,插入键值对。
1, 查找。根据key计算hash值,并在hash值对应的array[hash & ht->max]下查找key,key已存在则返回当前entry。key不存在,优先从free链表中获取entry,否则新建entry并返回。
2, 检查获取到的entry。如果传入的val值为空,则将该entry删除并加入free链表。传入的val值正常,则替换entry中的val字段。
3, 检查count计数超过max时,扩展哈希表。
4, 扩展哈希表时,创建new_array数组,new_max大小为(max * 2 + 1)。遍历array,赋值到new_array并切换array数组。

apr_hash_get查找
apr哈希表查找的逻辑:
根据key计算hash值,并在hash值对应的array[hash & ht->max]下查找key,key存在则返回当前entry中的val值。key不存在则返回NULL。
apr_hash_clear清空
apr哈希表清空的逻辑:
遍历hash表,把所有的entry节点中的val设置为NULL。
所以,apr_hash_clear之后,hash表并没有清空,只是把所有的entry节点的val置空,并将entry放入了free链表。
总结
apr库的哈希表对于大部分场景已经足够使用了。但是有一些特殊的场景要考虑到出问题的可能。
apr库哈希表不是线程安全的。
apr库哈希表没有对冲突做进一步处理,在array[i]下的entry链表长度超过某个阈值时,通过某些方法降低冲突,比如扩容、修改hash算法、entry使用红黑树代替链表等等。
空空如常
求真得真