09-使用snappy对Sentinel-1 GRDH数据进行预处理
09-使用snappy对Sentinel-1数据进行预处理
- 前言
- 准备工作
- 源数据
- snappy包重要类和其属性、方法
-
- 数据的读和写操作
- Product类的属性和方法使用简介
-
- SNAP Engine API文档查阅
- get和set方法
- snappy处理数据
-
- 方式1 使用SNAP自带的操作符处理
-
- 查阅操作符
- 查阅操作符参数
- 方式2 读入numpy数组处理
- Sentinel-1 GRDH数据预处理
-
- 单个数据集预处理演示
-
- 一些辅助函数
- 读入操作
- 裁剪操作
- 轨道校正操作
- 热噪声去除操作
- 辐射定标操作
- 斑点滤波(相干斑滤波)
- 地形校正
- 分贝化操作
- 写入数据
- 多个数据集预处理演示
- 后语
- 参考文献
前言
OK! 经过前面数篇有点冗长的博客,介绍snappy的时机终于成熟透!接下来,是时候向各位展示一下snappy的一些“奇巧淫技”了!
08篇中使用SNAP的命令行工具gpt,结合流程图文件,快速对Sentinel-1和Sentinel-2数据进行预处理,后面的几篇博文将使用snappy(SNAP的python接口包)实现相同的预处理。另外,需要说明的是snappy和gpt也有比较密切的关系,因此,先介绍了gpt工具的使用,以便辅助snappy的使用。
在我看来,snappy这个python接口是非常有用的,因为它可以读取Sentinel等卫星数据为numpy包的ndarray类(n维数组类),这样,我们可以借助python丰富、强大的开源包扩展SNAP不完善或欠缺的功能,比如结合最近几年比较火的scikit-learn库、深度学习框架tensorflow, keras, pytorch完成更高级的分类(土地利用分类等)或回归问题(定量遥感反演等)。
snappy包,目前看来还是资料还是比较少,另外,刚开始使用(不熟悉其模块和功能的话),可能会不太习惯,因为其是通过jpy(一个将python和java代码连接起来的桥梁包)将python代码转为java代码传到SNAP所带的Java虚拟机执行的,如果不注意就会将Java和python语法混乱,也是因为这个原因,snappy的doc文档很难直接获取(代码补全困难),需要查看SNAP 的Java API doc文档。
但是,一般的比较常见的操作和功能在官方的博客、论坛等是能找到其相关的参考代码的。尽管snappy还有一些缺陷,但考虑到其可以比较便捷地完成Sentinel等系列卫星的预处理,和结合丰富的python开源包,意味着我们可以更快更好做更多的事情,还是很值得研究一下的。
准备工作
请参照01篇博客利用SNAP在本地电脑配置好snappy。如果你想利用snappy来开发利用或扩展SNAP的功能,务必安装好snappy,否则,后面代码无法运行。博主这是使用的是win64 python3.6 配置的,这个目前可以绝大数开源的python包适配,比如适配深度学习框架tensorflow, pytorch等。
尽管可以编写、执行、调试python代码的IDE工具很多,但目前看来Pycharm的python代码补全功能最为强大,使用起来比较方便,建议有条件的同学可以试下,尽管pycharm也有点缺点,比如启动很慢等。(博主使用的是正版的Pycharm专业版,因为可以使用Jupyter notebook,可以交互式写代码。如果你有教育邮箱的话就可以免费激活使用Pycharm专业版IDE)。
源数据
数据源为覆盖上海市全境的6景Sentinel-1 GRDH 数据:

同一天的两景影像镶嵌刚好覆盖整个上海市范围(这里共有3景):

本篇博客涉及到的代码见百度云盘链接:
链接:https://pan.baidu.com/s/1DgH5S3i4CogzH0YqC3cVyQ
提取码:e2dj
snappy包重要类和其属性、方法
snappy包包括众多的Java类以及其属性、方法(这些来自SNAP的Java源代码),在我看来snappy包中比较重要的是数据的输入和输出(和numpy的交互),还有就是通用的GPF(Graph Processing Framework,流程处理框架)操作符(预处理和调用SNAP的封装的功能函数),这里暂时只介绍这些。
如果你比较熟悉Java代码,可以直接利用Java代码调用或扩展SNAP的功能想利用,可以参考SNAP官方的SNAP wiki博客SNAP development部分,奈何博主Java比较菜,Python相对熟悉一些,因此,博主目前只能介绍一些比较常见的snappy操作,以下内容主要参考SNAP官方的snappy 使用wiki博客。注意,某一些内容还需要修改,比如路径,下面的代码才可以运行。
SNAP的Java源码使用到了Java版的GDAL库,比较多的类和函数设计和GDAL库有点类似,有的GDAL库基础的同学理解起来会容易一些。Java中基本上许多东西都是设计成类的,
因此,从snappy中往往导入的是类,然后再导入其属性或方法。此外,虽然snappy封装了较多的类,但是,还有一些Java类只能通过jpy包(Python-Java桥梁包)的gettype()函数才能创建(即jpy.gettype(), 该函数需要传入一个Java类名字符串, 见后文方式1 使用SNAP自带的操作符处理)。
以下的内容如果有面向对象的程序设计知识,可能会容易理解很多。
数据的读和写操作
from snappy import ProductIO
# 读入产品数据集,MER_FRS_L1B_SUBSET.dim为(snappy自带的测试数据集,在snappy的安装路径下)数据集的路径,
# 这里是相对路径,你可能需要修改为你的绝对路径或相对路径
# 返回值p是一个snappy.Product类对象
p = ProductIO.readProduct(r'E:\Anaconda\Anaconda3\envs\py36\Lib\site-packages\snappy\testdata\MER_FRS_L1B_SUBSET.dim')
# 写入数据,需要传入一个snappy.Product对象,''为你的输出文件名路径
# ''为保存的数据格式,可以是SNAP的标准数据格式'BEAM-DIMAP'(默认值),
# 或者常见的'GeoTiff'格式等,如果有写入的格式参数的话,保存的文件名可以没有不带后缀.dim、.tif等
# ProductIO.writeProduct(p, '', '') # 写入产品数据集
# snappy的测试数据大小很小,我直接保存在当前路径下了, 保存为test_write1.tif
ProductIO.writeProduct(p, 'test_write1', 'GeoTiff') # 写入产品数据集
上述代码通过snappy的ProductIO类(Product类的输入和输出模块类)的readProduct和writeProduct方法。
- readProduct方法 :从磁盘读入一个产品数据,该函数输入的参数要读取的数据集路径(可以是绝对路径或相对路径)或者File对象,是返回的是一个snappy.Product类对象(产品类对象,可以理解为一个数据集对象)。
可以参考后文的单个数据集预处理演示读入操作部分的代码。
- writeProduct方法:向磁盘写入一个产品数据,三个输入参数分别是product类对象,保存的文件名绝对路径或相对路径或者Java的File类对象,写入格式的格式字符串说明,实际上该函数还有其它的参数,如进度条参数,默认是Null,不显示进度条。
可以参考后文所写的单个数据集预处理演示写入数据部分的代码。
如果你要查看snappy.ProductIO类的接口,你需要查阅SNAP本来的Java API, 主要有两个,基本我们只需要查阅第一个 SNAP Engine API文档就可以,另一个文档主要是SNAP GUI 界面API文档。
SNAP Engine API Documentation
SNAP Desktop API Documentation
比如我要查阅ProductIO类的源代码定义,只需要到SNAP Engine API Documentation网页上查找ProductIO类即可(左下方侧框是SNAP Engine 定义所有类,默认是按字母升序排序的,不是很难查找):

更详细的readProduct和writeProduct方法的参数介绍:

Product类的属性和方法使用简介
snappy.Product可能我们使用snappy时最常用的类,其封装大量方法和函数,很难一一详述,所有这些方法和属性,可以通过SNAP Engine API文档找到, 以该类为例,展示API文档的查阅使用,学会使用API文档,才能在更好地使用其源代码,从而,创造出更方便和强大的用法。该开始看到一大堆的英文API文档可能会比较苦恼,但是如果静下心来细看,其实是不难理解。
尽管有些类定义的属性和方法众多,但是在绝大数的情况下,我们可能用不到,往往是需要用到时才查阅该类的方法使用。当然,如果你能以开发者的角度理解该类的定义,他为什么这样设计,怎样才能使用户更便捷是使用该API,你就能思考得更深入,理解得更透切。实际上,对于开源库包而言,源代码的可读性比效率性更重要,因此,流行的开源包绝大数是比较容易学和利用的。SNAP的开发者团队也是很看中这点。因此,就常规应用而言,我们不必为某些庞大的类对象感到恐慌。例外的话,SNAP开发者团队会在SNAP官方论坛解答疑问,如果不懂的话,可以到那里去询问一下。
SNAP Engine API文档查阅
Product类的定义:

再往下是属性总结:

再往下为该类构造函数和方法:

前面只是一些简洁的总结,要往后翻才能看到跟详细的参数说明:
父类的继承以及属性参数介绍:

构造函数的参数介绍:

该类方法的功能和参数介绍:
get和set方法
Product类(包括snappy的其它类)的方法,很大一部分方法都是以get和set开头的方法,通常表示获取某些属性或对象、设置或修改某些属性和对象。
# p是snappy.Product类对象
# getBand是该类的方法,通过传入一个波段名(字符串),获取该波段对象(snappy.Band类)
rad13 = p.getBand('radiance_13')
# 通过snappy.Band类的setName方法设置该类对象rad13的波段名
rad13.setName('just_a_test')
下面这段代码暂时不可以运行,因为target_product还没有定义,这只是举例,见后面。
# target_product是snappy.Product类对象
# 设置波段some_output_band_based_on_rad13的缺失值(NoDataValue)
# target是snappy.Band对象
target_band = target_product.getBand('some_output_band_based_on_rad13')
# 从rad13波段从获取其缺失值,并赋予到target波段(some_output_band_based_on_rad13)
target_band.setNoDataValue(rad13.getNoDataValue())
通常snappy子类方法返回值是整数或字符串对象(例如:这里的p.getSceneRasterWidth()返回的是整数,p.getName()返回的是字符串),这是python可以直接解释和识别的。
# p是snappy.Product类对象
# 获取该产品数据的名字,返回的name是字符串
name = p.getName()
width = p.getSceneRasterWidth()
band_names = p.getBandNames()
但是有时一些snappy子类的函数返回是一个Java对象,这通常python不能识别(例如上面p.getBandNames()返回的就是一个java对象,python不能直接识该对象)
p.getBandNames()
#>>>[Ljava.lang.String;(objectRef=0x00000000391DEAE8)
这时可以使用python大的list函数将其转化list对象,其
bands = list(p.getBandNames())
bands
#>>> ['radiance_1', 'radiance_2', 'radiance_3', 'radiance_4', 'radiance_5', 'radiance_6', 'radiance_7',
#'radiance_8', 'radiance_9', 'radiance_10', 'radiance_11', 'radiance_12', 'just_a_test', 'radiance_14', 'radiance_15', 'l1_flags', 'detector_index']
type(bands)
#>>> 如果类属性方法返回的是Java字符串(Java String),如p.getAutoGrouping()方法的返回值
p.getAutoGrouping()
#>>> org.esa.snap.core.datamodel.Product$AutoGrouping(objectRef=0x00000000391DEAC8)
这时,可以通过python的str()函数将其转换为python的字符串类对象。
autogrouping = str(p.getAutoGrouping())
autogrouping
#>>> 'Oa*_reflectance:Oa*_reflectance_err:A865:ADG:CHL:IWV:KD490:PAR:T865:TSM:atmospheric_temperature_profile:lambda0:FWHM:solar_flux'
type(autogrouping)
#>>> snappy处理数据
方式1 使用SNAP自带的操作符处理
如果可以直接使用SNAP Engine Operators(SNAP GUI界面中的操作)实现的操作,通过snappy.GPF类的 createProduct()方法可以调用该操作。这和使用SNAP的命令行gpt工具调用的操作是一样的。后面主要使用该种处理方式对Sentinel-1数据进行预处理。
GPF.createProduct()方法:
- 第一个的参数是gpt工具对应的操作符字符串(流程图文件.xml文件
节点的字符串); - 第二个参数是一个Java的HashMap对象(相当于Python的字典对象),通过该HashMap对象传入gpt工具对应的操作符的参数名及其值(流程图文件中也可以看到该参数键值对,SNAP GUI 界面也可以看到操作符对应的参数);
- 第三个参数是要处理的Product类对象。
- 其返回值也是一个Product类对象。
注意,向一个操作符传入一个空的HashMap类对象,使用的是该操作符的默认参数值。这意味着,当你也可以通过HashMap类对象只修改部分的参数,其它不修改部分将使用默认参数。此外, 使用默认参数值要必须传入一个空的HashMap类对象,而不可以将其省略。
查阅操作符
或许你想知道,SNAP中有哪些可以直接条用的操作符,SNAP GUI界面的菜单栏选项,或许可以给予你提示,但是可以借助SNAP的命令行工具gpt查询更全面,可以打开命令行窗口,输入gpt -h
gpt -h
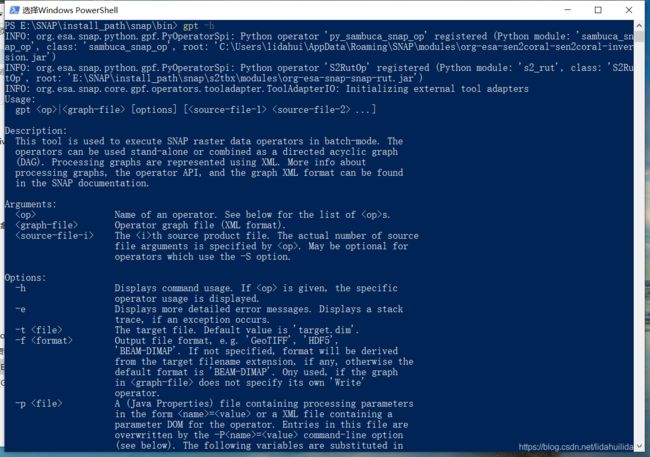
往下拉,可以找到‘Operators’字眼:
然后,你就可以看到很多的操作符名字以及其功能描述:

查阅操作符参数
以从重采样操作(‘Resample’)为例,查阅该操作其相关的参数:
- 1.使用SNAP的命令行工具gpt查询:
打开命令行窗口,对于查询Resample操作而言,输入以下代码即可:
gpt Resample -h

这个查询结果比较好,因为其指出其参数值的类,注意,向HashMap传入实际的参数名没有前面-P(-PXXXX是gpt工具的-P参数设置方法),比如,命令行中使用-Pdownsampling参数,向HashMap对象传入参数名是downsampling。
- 2.使用SNAP的GUI界面查询
在SNAP的操作界面找到操作的菜单按钮,在打开的该操作菜单的GUI界面上,选择
File–>Display Parameters:

显示的参数选项(这里的参数显示不是很全,因为没有添加数据集):

- 3.流程图文件.xml中也可以看到该操作操作名及其参数:

在我看来,第一种方式较好些,因为可以看到输入参数的类型,这样,可以避免向HashMap对象传入错误的参数值,尽管有一些麻烦。
#导入相关类
from snappy import ProductIO
from snappy import GPF
from snappy import Hashmap
from snappy import ProgressMonitor
from snappy import jpy
# 向Hashmap对象,传入参数键值对
parameters = Hashmap()
parameters.put('targetResolution', '10')
parameters.put('referenceBand', 'B4')
# 调用GPF(流程图处理框架)定义的操作
operator_name = 'Resample'
target_product = GPF.createProduct(operator_name, parameters, p)
# 通过ProductIO类对象写入数据
# 通过ProductIO类的writeProduct方法写入
# 这是单线程的写入方式,写入大影像时速度会比较慢
write_format = 'BEAM-DIMAP' # 以BEAM-DIMAP格式写入
# ProductIO.writeProduct(target_product , <'your/out/directory'>, write_format)
ProductIO.writeProduct(target_product ,'./test_write2', write_format)
# 另一种写入方式,通过GPF操作符写入,这种方式使用GPF操作符调用
# 默认使用多线程计算,因此效率很高,推荐使用这种方式,特别是在数据量大的时候
WriteOp = jpy.get_type('org.esa.snap.core.gpf.common.WriteOp')
# 以GeoTiff-BigTiff格式写入,这是一种存储大影像的.tif格式
writeOp = WriteOp(target_product, File('./test_write3.tif'), 'GeoTIFF-BigTIFF')
writeOp.writeProduct(ProgressMonitor.NULL)
# 上面writeOp部分代码和下面的方式是一样的,
# 多数的格式写入器不支持在写入数据更新数据更新数据(除了默认的'BEAM-DIMAP'格式)
# 这时可以将incrementtal参数设置为False
incremental = False
# GPF.writeproduct(target_product, File('your/out/directory'), write_format, incremental, pm)
GPF.writeProduct(target_product , File('./test_write4'), write_format, incremental, ProgressMonitor.NULL)
# 官方的教程多了这个代码,但似乎在Jupyter Notebook上不起作用
# 下述代码是在写入时加入一个进度条显示
def createProgressMonitor():
PWPM = jpy.get_type('com.bc.ceres.core.PrintWriterProgressMonitor')
JavaSystem = jpy.get_type('java.lang.System')
monitor = PWPM(JavaSystem.out)
return monitor
pm = createProgressMonitor()
GPF.writeProduct(target_product , File('./just_test2'), write_format, incremental, pm)
方式2 读入numpy数组处理
SNAP自带的操作不能满足你的计算需求时或者你打算实现自己的计算的情况下,Band类对象的readPixels()和writePixels()方法(这两个方法继承自AbstractBand类)可以获取计算所需栅格值、保存结果(和numpy数组交互)。如果你想以SNAP中的定义的写入器写入数据,建议在计算开始之前在脚本中完全设置好Product类target_product类的相关属性。在下面的例子中,p仍然是前面所提到的Product类对象(是数据源)。
通过SNAP Engine API可以查到AbstractBand类的readPixels()和writePixels()方法,如下:
参数x, y栅格左上角像素坐标值(x, y,整型,其中x表示第几列,y表示第几行, 从0开始计算,而不是1);w为读入栅格范围的宽度(列数,整型); h为读入栅格范围的高度(行数, 整型); double[] , float[], int[] pixels为要读入或写入的numpy一维float64, float32, int32数组; pm是可选参数(ProgressMonitor类),用于读入或写入展示进度条;
有两点需要需要强调, 再强调的,w,h分别指宽度和高度,而不是右下角的像素坐标值;传入的numpy数组必须是一维数组,且元素总数和二维栅格包含的总像元数相同(相当将二维数组展开为一维数组)。这两点很容易出错!

通过这两个方法实现和numpy数组的交互,从而可以和众多的python第三方包交互,例如scipy,scikit-learn等,从而大大扩其功能。该函数用法见下文代码的第6,7部分。
# 1.导入相关库和类
import snappy
from snappy import ProductUtils
import numpy as np
p = ProductIO.readProduct(r'E:\Anaconda\Anaconda3\envs\py36\Lib\site-packages\snappy\testdata\MER_FRS_L1B_SUBSET.dim')
# 这里的p的是前文的Product类对象
# 获取该Product类对象的栅格集宽度大小
width = p.getSceneRasterWidth()
# 获取该Product类对象的栅格集高度大小
height = p.getSceneRasterHeight()
# 创建一个空的Product类对象,'My target product'指其Product类对象名字
# 'The type of my target product'指该Product类对象的产品类型字符串
# width 栅格数据集的宽度
# height 栅格数据集的高度
#target_product = snappy.Product('My target product', 'The type of my target product', width, height)
target_product = snappy.Product('target_product', 'temp_type', width, height)
# 2. 可选的操作:从Product类对象复制元数据到target_product
ProductUtils.copyMetadata(p, target_product)
# 可选也可以设置target_product特定描述,如下
target_product.setDescription('Product containing very valuable output bands')
# 3.设置Product类的写入器
# 使用write_format格式字符串定义 (这里如 'BEAM-DIMAP'):
target_product.setProductWriter(ProductIO.getProductWriter(write_format))
# 4.向新建的Product类对象添加Band类对象
# Now, you could copy bands form the source product if you are interested in writing them to the target product as well. Check out ProductUtils.copyBand() regarding this task.
# 在计算之前需要创建为新建的Product类对象创建一个空的波段对象
# 新的波段名
band_name = 'new_band'
# 栅格值类型为snappy.ProductData.TYPE_FLOAT32
target_band = target_product.addBand(band_name, snappy.ProductData.TYPE_FLOAT32)
# 对刚创建的band对进行更多的属性设置
# 从Product类对象p的'source_band_name'波段获取该波段的缺失值
nodata_value = p.getBand('radiance_13').getNoDataValue()
# 设置Band类对象target_band的缺失值以及波长值(nm)
target_band.setNoDataValue(nodata_value)
target_band.setNoDataValueUsed(True)
target_band.setSpectralWavelength(425.0)
# 你还可以对其它的波段属性进行设置,有一些属性的设置对得到你所期望的波段非常关键
# 5.写入文件头
# 刚刚添加到target_product的所有结构和元信息仍然在内存中。因此,我们必须在写入数据之前先
# 写入它的头。writeHeader()的唯一参数是数据集的绝对路径,不带文件扩展名。此路径的最后一个
# 字符串是写入时的目标产品名称。
# 最后输出的数据文件名为test_write3.dim
target_product.writeHeader('test_write3')
# 6. 从源产品数据集中导入波段source_band_name的数据
sourceband = p.getBand('source_band_name')
# 创建一个一维数组,其大小和读入栅格范围的二维数组展开后得到的
# 一维数组大小一致,用于存储数据
r1 = np.zeros(width * height, dtype=np.float32)
print('Reading...')
rad13.readPixels(0, 0, width, height, r1)
# 7. 向新建的波段写入数据
print("Writing...")
target_band.writePixels(0, 0, width, height, r1)
target_product.closeIO()
print("Done.")
上述代码很有代表性,涉及到数据读入和写入,以及和numpy库的交互,建议多看看几遍,后面可能经常用到相似的代码片段。
Sentinel-1 GRDH数据预处理
利用SNAP对Sentinel-1 GRDH数据进行预处理的详细步骤及解释请看07篇博客,利用SNAP的命令行对其进行预处理请看08篇博客。
单个数据集预处理演示
预处理流程和之前博客中展示的是一样的,如下:

为了避免代码过长,这里将按预处理的步骤将其分隔开来。刚开始部分是一些辅助函数,比如查看某个处理操作的参数、数据可视化的函数。(博主是用jupyter notebook 写的代码, 每个步骤是分开,但是,如果你想封装为函数以便批量处理,也是非常容易的)。注意,我不会讲解太多python的基础知识,下面的代码,除了snappy外,都是比较常见的python自带包或第三方开源包,并且博主加了必要的注释,应该是可以理解的。
一些辅助函数
以下是导入的相关包和定义的辅助函数代码:
# -*- coding: utf-8 -*-
# Author: 超级禾欠水
# 导入相关库
import matplotlib.image as mpimg # 可视化
import matplotlib.pyplot as plt # 可视化
from zipfile import ZipFile # 压缩文件类
import os # 访问文件
from glob import iglob # 访问文件
import pandas as pd # 数据分析和操作常用库
import numpy as np # 科学计算库
import subprocess # 调用系统进程
import snappy # SNAP的python接口包
import math # 基本的数学函数包
# 修改pandas列的字符宽度,因为Sentinel数据文件名很长
pd.options.display.max_colwidth = 80
# 可视化函数
def output_view(product:snappy.Product, band_names:list,
stretch_percent:float=0.02)->None:
"""
:param product: snappy GPF product对象,输入的Sentinel-1产品数据集类对象
:param band_names: 要可视化的波段名
:param stretch_percent: 直方图拉伸的百分比,默认为2%(0.02)拉伸
:return: None
"""
band_count = len(band_names) # 波段数
band_data_list = [] # 保存波段数据的列表
vmins = [] # 保存波段数据拉伸的下边界值列表
vmaxs = [] # 保存波段数据拉伸的上边界值列表
for band_name in band_names:
band = product.getBand(band_name)
w = band.getRasterWidth()
h = band.getRasterHeight()
band_data = np.zeros(w * h, np.float32)
band.readPixels(0, 0, w, h, band_data)
band_data = band_data.reshape((h, w))
band_data_list.append(band_data)
# 求取该波段数据拉伸的上下下边界值列表
vmin, vmax = np.percentile(band_data, (100 * stretch_percent / 2, 100 - 100 * stretch_percent / 2 ))
vmins.append(vmin)
vmaxs.append(vmax)
rows = math.ceil(band_count / 3)
# 每行最多放3个图
fig, axes = plt.subplots(rows, 3, figsize=(15, rows * 5))
for i, ax in enumerate(axes):
if i > band_count - 1:
ax.set_axis_off()
break
ax.imshow(band_data_list[i], cmap='gray', vmin=vmins[i], vmax=vmaxs[i])
ax.set_title(band_names[0])
# 查看SNAP某个操作的函数
def print_operator_help(operator_name:str)->None:
"""
:param operator_name: SNAP中的操作名,可以通过命令行工具gpt -h
:return: None
"""
print(subprocess.Popen(['gpt', operator_name, '-h'], stdout=subprocess.PIPE,
universal_newlines=True).communicate()[0])
# 查看影像快视图,以了解其覆盖范围
def look_S1_zip_quick_look(S1_zip_file_name:str)->None:
"""
:param S1_zip_file_name: Sentinel数据压缩文件名
:return: None
"""
with ZipFile(S1_zip_file_name, 'r') as qck_look:
qck_look_img = qck_look.open(name[0] + '.SAFE/preview/quick-look.png')
img = mpimg.imread(qck_look_img)
plt.figure(figsize=(15, 15))
plt.title('Quicklook visualition - ' + name[0] + '\n')
plt.axis('off')
plt.imshow(img)
读入操作
# 读取Sentinel-1数据
product_path = r"G:\test\S1_GRDH"
input_S1_files = sorted(list(iglob(os.path.join(product_path, '**', '*S1*.zip'), recursive=True)))
# 获取其文件名,拍摄模式,产品等级类型,极化方式,影像高度,影像宽度,波段名
name, sensing_mode, product_type, polarization, height, width, band_names = ([] for _ in range(7))
for i in input_S1_files:
sensing_mode.append(i.split('_')[3])
product_type.append(i.split('_')[4])
polarization.append(i.split('_')[-6])
# Read with snappy
s1_read = snappy.ProductIO.readProduct(i)
name.append(s1_read.getName())
height.append(s1_read.getSceneRasterHeight())
width.append(s1_read.getSceneRasterWidth())
band_names.append(s1_read.getBandNames())
# 保存到一个pandas的数据框中
df_s1_read = pd.DataFrame({
'name':name, 'Sensing Mode':sensing_mode, 'Product Type':'Product Type',
'Polarization': polarization, 'Height':height,
'Width':width, 'Band Name':band_names})
print(df_s1_read)
结果:

查看快视图:
# 查看第一个数据集的快视图
look_S1_zip_quick_look(input_S1_files[0])
结果:
(与你手动打开解压后的压缩文件查看到的快示图应该是一样的)

裁剪操作
为了减少数据量,这里使用裁剪操作(这样,即使小内存的电脑也能较好较快地得到结果)。
查看该操作的参数:
# 裁剪操作
# 查看裁剪操作的参数
print_operator_help('Subset')
结果:

执行该操作:
# 裁剪,这里使用像素坐标来裁剪
# (x, y)为左上角的点,x对应列, y对应行,
# width为要裁剪的宽度范围(width个列,含左上角所在的第一列)
# height为要裁剪的高度范围(height个列,含左上角的第一行)
# 这个区域属于张家港和南通市
x, y, width, height = 2000, 2000, 5000, 5000
# 裁剪操作的参数- snappy
# 通过Java的HashMap类对象parameters设置参数,相当于python的字典类对象
parameters = snappy.HashMap()
# 复制元数据
parameters.put('copyMetadata', True)
# 设置裁剪区域参数
parameters.put('region', '%s, %s, %s, %s' %(x, y, width, height))
# 执行裁剪操作
subset = snappy.GPF.createProduct('Subset', parameters, s1_read)
subset:snappy.Product
# 打印该数据集的波段名
print('band_names:', list(subset.getBandNames()))
# 查看裁剪后的振幅图(2%拉伸)
output_band_names = ['Amplitude_VV', 'Amplitude_VH']
output_view(subset, output_band_names)

轨道校正操作
查看该操作的参数:
# 轨道校正操作
# 查看轨道校正操作的参数
print_operator_help('Apply-Orbit-File')
结果:

执行该操作:
# 轨道校正操作 - snappy
parameters = snappy.HashMap()
parameters.put('Apply-Orbit-File', True)
# 执行轨道校正操作
apply_orbit = snappy.GPF.createProduct('Apply-Orbit-File', parameters, subset)
这里没有可视化该结果。
热噪声去除操作
查看该操作的参数:
# 热噪声去除操作
# 查看热噪声去除操作的参数
print_operator_help('ThermalNoiseRemoval')
结果:

执行该操作:
# 热噪声去除操作 - snappy
parameters = snappy.HashMap()
parameters.put('removeThermalNoise', True)
# 执行热噪声去除操作
thermal_noise = snappy.GPF.createProduct('ThermalNoiseRemoval', parameters, apply_orbit)
print('band_names:', list(thermal_noise.getBandNames()))
# 查看热噪声去除操作的强度图(2%拉伸)
output_band_names = ['Intensity_VV', 'Intensity_VH']
output_view(thermal_noise, output_band_names)

辐射定标操作
查看该操作的参数:
# 辐射定标操作
# 查看辐射定标操作的参数
print_operator_help('Calibration')
结果:

执行该操作:
# 辐射定标操作 - snappy
# 设置参数部分
parameters = snappy.HashMap()
# 以标准后向散射系数sigma0的方式定标
parameters.put('outputSigmaBand', True)
parameters.put('sourceBands', 'Intensity_VH,Intensity_VV')
parameters.put('selectedPolarisations', 'VH,VV')
# 没有分贝化
parameters.put('outputImageScaleInDb', False)
calibrated = snappy.GPF.createProduct("Calibration", parameters, thermal_noise)
print('band_names:', list(calibrated .getBandNames()))
# 查看辐射定标后的影像
output_band_names = ['Sigma0_VV', 'Sigma0_VH']
output_view(calibrated, output_band_names)
结果:

斑点滤波(相干斑滤波)
查看该操作的参数:
# 斑点滤波操作
# 查看斑点滤波操作参数
print_operator_help('Speckle-Filter')
结果:

执行该操作:
# 斑点滤波操作 - snappy
parameters = snappy.HashMap()
# 使用改进型Lee滤波器滤波
parameters.put('filter', 'Refined Lee')
parameters.put('filterSizeX', 5)
parameters.put('filterSizeY', 5)
speckle = snappy.GPF.createProduct('Speckle-Filter', parameters, calibrated)
print('band_names:', list(speckle .getBandNames()))
# 查看斑点滤波的影像
output_band_names = ['Sigma0_VV', 'Sigma0_VH']
output_view(speckle, output_band_names)
结果:

地形校正
地形校正时,使用了和当地Sentinel-2相同的UTM 51/WGS84坐标系(注意,每个区域的UTM投影带号可能不同,你可能需要修改为自身研究区的UTM投影坐标),并且去掉了没有DEM数据的掩膜功能(对于靠海和水域地区,需要去掉这个,否则,该部分会被爱掩膜掉)。
查看该操作的参数:
# 地形校正操作
# 查看地形校正操作的参数
print_operator_help('Terrain-Correction')
结果:

地形校正等类似操作需要获取投影参数WKT文本表示(这是一大段的坐标系描述字符串,如果如果自己一个一个字符地输入是很痛苦的事情,并且很容易出错,好在,有两种方式可以获取有效所需坐标系的WKT表示):
- 1.在SNAP GUI 地形校正界面中选择好投影后,便可以在查看该操作的参数中,找到相应的参数值:

找到

- 2.使用Spatial Reference官网查询对应坐标系的OGC WKT文本
经过博主的测试,OGC WKT文本表示,SNAP是可以识别的,大概是因为SNAP是开源软件,所以对开源的东西(OGC)支持比较好,比例QGIS、OTB等表示:


(但是,实际上该文本和SNAP产生的WKT文本还是有点细微的出入的(尽管相对别的表示最为接近),另外,ESRI WKT文本似乎在SNAP的支持上有点问题,最好,使用OGC WKT,如果需要和别的GIS/RS软件打交道的话)

执行该操作:
# 设置投影(wkt形式)
# 这里使用UTM投影(WGS84椭球体下)
proj = """PROJCS["WGS 84 / UTM zone 51N",
GEOGCS["WGS 84",
DATUM["WGS_1984",
SPHEROID["WGS 84",6378137,298.257223563,
AUTHORITY["EPSG","7030"]],
AUTHORITY["EPSG","6326"]],
PRIMEM["Greenwich",0,
AUTHORITY["EPSG","8901"]],
UNIT["degree",0.01745329251994328,
AUTHORITY["EPSG","9122"]],
AUTHORITY["EPSG","4326"]],
UNIT["metre",1,
AUTHORITY["EPSG","9001"]],
PROJECTION["Transverse_Mercator"],
PARAMETER["latitude_of_origin",0],
PARAMETER["central_meridian",123],
PARAMETER["scale_factor",0.9996],
PARAMETER["false_easting",500000],
PARAMETER["false_northing",0],
AUTHORITY["EPSG","32651"],
AXIS["Easting",EAST],
AXIS["Northing",NORTH]]"""
# 地形校正操作 - snappy
parameters = snappy.HashMap()
# 使用‘SRTM 3Sec’DEM
parameters.put('demName', 'SRTM 3Sec')
parameters.put('imgResamplingMethod', 'BILINEAR_INTERPOLATION')
# 设置分辨率
parameters.put('pixelSpacingInMeter', 10.0)
parameters.put('mapProjection', proj)
# 对于海域无高程部分不使用掩膜
parameters.put('nodataValueAtSea', False) # do not mask areas without elevation
parameters.put('saveSelectedSourceBand', True)
terrain_correction = snappy.GPF.createProduct('Terrain-Correction', parameters, speckle)
print('band_names:', list(terrain_correction.getBandNames()))
# 查看地形校正后的影像
output_band_names = ['Sigma0_VV', 'Sigma0_VH']
output_view(terrain_correction, output_band_names)
结果:

分贝化操作
查看该操作的参数:
# 分贝化(DB化)操作
# 查看地形校正操作的参数
print_operator_help('LinearToFromdB')
结果:

执行该操作:
# 分贝化操作 - snappy
parameters = snappy.HashMap()
db= snappy.GPF.createProduct('LinearToFromdB', parameters, terrain_correction)
print('band_names:', list(db.getBandNames()))
# 查看分贝化后的影像
output_band_names = ['Sigma0_VH_db', 'Sigma0_VV_db']
output_view(db, output_band_names)
结果:

写入数据
这里保存为geotiff格式。
执行该操作:
# 保存的文件名
outpath_name = r'G:\test\S1_GRDH\results\snappy_test_S1_GRDH_Sub_Orb_Thm_Cal_Spk_TC_dB.tif'
#不支持更新数据
incremental = False
# 写入操作 - snappy
# 以Geotiff格式写入
snappy.GPF.writeProduct(db, snappy.File(outpath_name), 'GeoTIFF', incremental, snappy.ProgressMonitor.NULL)
print('Product successfully saved in:', outpath_name)
结果:

在SNAP中打开验证该结果看看:
后来,我重新运行了整个流程,大约耗时约6分钟,速度还可以的(尽管去掉一些查看参数或可视化之类的辅助函数可以更快一些),虽然在小数据集和使用gpt工具运行的时间差不多,但是,在大数据集中,gpt+流程图文件执行效率更高。
多个数据集预处理演示
SNAP中内存释放问题,似乎还没有解决,尽管官方很早就该问题的修复提上的日程。尽管可以将上述的单个数据的代码,编写为一个函数,从而,在批处理是反复调用,但是,如果数据量大的话,可能很快就因为内存不能及时释放导致操作失败。这里,使用的是SNAP 官方论坛Temporary fix for snappy memory issues的解决方案,实际上,08篇博客也是用了该方法,也是就通过调用python的subprocess模块以命令行“杀死进程”的方式强制释放内存,这样,就不用担心内存不能及时释放导致处理失败的问题!
(由于处理的两景Sentinel SAR影像数据量较大,8G运行内存处理起来可能有些吃力,16G以上运行内存应该是无压力的)
下面代码使用的预处理流程,如下图所示:

现将下述代码预处理代码保存为preprocess_S1.py(也是是别的python脚本文件,只要和别的python脚本文件混淆就可以):
(抱歉,很长的一段代码,但是,其逻辑是不难理解的)。
# -*- coding: utf-8 -*-
# Author: 超级禾欠水
import datetime
import time
from snappy import ProductIO
from snappy import HashMap
from snappy import GPF
from snappy import jpy
from snappy import File
from snappy import ProgressMonitor
import sys
import os
def read_s1_zip_file(file_name):
print('\tReading Sentinel-1 zip file...')
# 执行读入操作
output = ProductIO.readProduct(file_name)
return output
def do_apply_orbit_file(product):
print('\tApply orbit file...')
# 轨道校正操作 - snappy
parameters = HashMap()
parameters.put('Apply-Orbit-File', True)
# 执行轨道校正操作
output = GPF.createProduct('Apply-Orbit-File', parameters, product)
return output
def do_thermal_noise_removal(product):
# 热噪声去除操作 - snappy
parameters = HashMap()
parameters.put('removeThermalNoise', True)
# 执行热噪声去除操作
output = GPF.createProduct('ThermalNoiseRemoval', parameters, product)
return output
def do_calibration(product):
print('\tCalibration...')
parameters = HashMap()
# 以标准后向散射系数sigma0的方式定标
parameters.put('outputSigmaBand', True)
parameters.put('productBands', 'Intensity_VH,Intensity_VV')
parameters.put('selectedPolarisations', 'VH,VV')
# 没有分贝化
parameters.put('outputImageScaleInDb', False)
output = GPF.createProduct("Calibration", parameters, product)
return output
def do_speckle_filtering(product):
print('\tSpeckle filtering...')
parameters = HashMap()
# 使用Refine Lee滤波器。默认是Lee Sigma
parameters.put('filter','Refined Lee')
output = GPF.createProduct('Speckle-Filter', parameters, product)
return output
def do_terrain_correction(product, proj):
print('\tTerrain correction...')
parameters = HashMap()
parameters.put('demName', 'SRTM 3Sec')
parameters.put('imgResamplingMethod', 'BILINEAR_INTERPOLATION')
parameters.put('mapProjection', proj) # 如果你需要使用UTM/WGS84投影,可以注释该行代码,默认是WGS84地理坐标系
parameters.put('saveProjectedLocalIncidenceAngle', False)
parameters.put('saveSelectedproductBand', True)
parameters.put('nodataValueAtSea', False)
# 分辨率为10m
parameters.put('pixelSpacingInMeter', 10.0)
output = GPF.createProduct('Terrain-Correction', parameters, product)
return output
def do_line_to_db(product):#将线性单位转为分贝值
print('\tLining_to_db...')
# 使用默认参数值,即选择所有通道
parameters = HashMap()
output = GPF.createProduct('LinearToFromdB',parameters,product)
return output
# 使用wkt坐标范围裁剪
def do_subset(product, wkt):
print('\tSubsetting...')
parameters = HashMap()
parameters.put('geoRegion', wkt)
output = GPF.createProduct('Subset', parameters, product)
return output
# 使用像素坐标裁剪
def do_subset(product, x, y, width, height):
parameters = HashMap()
# 复制元数据
parameters.put('copyMetadata', True)
# 设置裁剪区域参数
parameters.put('region', '%s, %s, %s, %s' % (x, y, width, height))
# 执行裁剪操作
output = GPF.createProduct('Subset', parameters, product)
return output
def do_SliceAssembly(product_list):
# 使用默认参数值,即选择所有通道
# 创建一个product类数组
products = jpy.array('org.esa.snap.core.datamodel.Product', len(product_list))
for count in range(len(product_list)):
products[count] = product_list[count]
parameters = HashMap()
output = GPF.createProduct('SliceAssembly', parameters, products)
return output
def write_to_file(product, file_path, format='BEAM-MAP'):
print("Writing...")
# 不支持更新数据
incremental = False
# 写入操作 - snappy
# 以format格式写入
GPF.writeProduct(product, File(file_path), format, incremental, ProgressMonitor.NULL)
def pre_process(path, files, outpath):
# 上海市UTM投影
proj = '''
PROJCS["UTM Zone 51 / World Geodetic System 1984",
GEOGCS["World Geodetic System 1984",
DATUM["World Geodetic System 1984",
SPHEROID["WGS 84", 6378137.0, 298.257223563, AUTHORITY["EPSG","7030"]],
AUTHORITY["EPSG","6326"]],
PRIMEM["Greenwich", 0.0, AUTHORITY["EPSG","8901"]],
UNIT["degree", 0.017453292519943295],
AXIS["Geodetic longitude", EAST],
AXIS["Geodetic latitude", NORTH]],
PROJECTION["Transverse_Mercator"],PARAMETER["central_meridian", 123.0],
PARAMETER["latitude_of_origin", 0.0],PARAMETER["scale_factor", 0.9996],
PARAMETER["false_easting", 500000.0],PARAMETER["false_northing", 0.0],
UNIT["m", 1.0],AXIS["Easting", EAST],AXIS["Northing", NORTH]]
''' # 不同的区域,通常需要修改带号(UTM Zone 51)和中央经度123.0的值(即PARAMETER["central_meridian", 123.0])
# # 使用WGS84地理坐标系对应的prj
# proj = '''
# GEOGCS["WGS 84",
# DATUM["WGS_1984",
# SPHEROID["WGS 84", 6378137, 298.257223563, AUTHORITY["EPSG", "7030"]],
# AUTHORITY["EPSG", "6326"]],
# PRIMEM["Greenwich", 0, AUTHORITY["EPSG", "8901"]],
# UNIT["degree", 0.0174532925199433, AUTHORITY["EPSG", "9122"]],
# AUTHORITY["EPSG", "4326"]]
files = files.split(';')
basename = os.path.basename(files[0])
# 获取时间和日期
date = basename.split('_')[4].split('T')[0]
# 循环开始时间
loopstarttime = str(datetime.datetime.now())
print('Start time:', loopstarttime)
start_time = time.time()
## 开始预处理:
# 镶嵌
product_list = []
for index in range(len(files)):
sentinel_1 = read_s1_zip_file(files[index])
# 热噪声去除
thermalremoved = do_thermal_noise_removal(sentinel_1)
applyorbit = do_apply_orbit_file(thermalremoved)
# 辐射定标
calibrated = do_calibration(applyorbit)
product_list.append(calibrated)
# 镶嵌
assembly = do_SliceAssembly(product_list)
del thermalremoved, applyorbit, calibrated
# 斑点滤波
filtered = do_speckle_filtering(assembly)
# 地形校正
terrain_corrected = do_terrain_correction(filtered, proj)
del filtered
# 分贝化
line_to_db = do_line_to_db(terrain_corrected )
del terrain_corrected
# 写入数据
print("Writing...")
final_path = outpath + '\\' + 'Shanghai_S1_GRDH_' + date + '.tif'
write_to_file(line_to_db, final_path, format='GeoTIFF-BigTIFF')
del line_to_db
print('Done.')
print("--- %s seconds ---" % (time.time() - start_time))
path = sys.argv[1]
files = sys.argv[2]
outpath = sys.argv[3]
pre_process(path, files, outpath)
上述的镶嵌部分的代码,需要多说一下的:
def do_SliceAssembly(product_list):
# 使用默认参数值,即选择所有通道
# 创建一个product类数组
products = jpy.array('org.esa.snap.core.datamodel.Product', len(product_list))
for count in range(len(product_list)):
products[count] = product_list[count]
parameters = HashMap()
output = GPF.createProduct('SliceAssembly', parameters, products)
return output
因为镶嵌使用两个以上的数据集,这里通过使用Product类数组实现向SliceAssembly操作传递多个数据集的。
主程序,这里保存为snappy_batch_process_S1_GRDH.py:
# -*- coding: utf-8 -*-
# Author: 超级禾欠水
# 导入相关库
import subprocess
import os, gc
import time
import glob
# python.exe文件所在路径,如果有多个版本的python,请注意对应的路径
python_exe_path = r'E:\Anaconda\Anaconda3\envs\py36\python.exe'
# 要执行的python脚本文件
py_file_path = r'C:\Users\lidahui\Desktop\My_file\snappy_project\preprocess_S1.py'
# 批处理Sentinel-1 GRDH 数据所在路径(压缩文件即可)
in_path = r'G:\test\S1_GRDH' ###########
# 存放处理后数据的路径
out_path= r'G:\test\S1_GRDH\snappy_batch_results' ######
if not os.path.exists(out_path):
os.makedirs(out_path)
# 获取该输入路径的Sentinel-1 GRDH原始数据压缩文件.zip
zip_files = sorted(glob.glob(os.path.join(in_path, '*.zip')))
# 同一天两景中的某景构成的part1列表
part1_files = zip_files[::2]
# 同一天两景中的另一景构成的part2列表
part2_files = zip_files[1::2]
for file_ndex in range(len(part1_files)):
gc.enable()
gc.collect()
files = [part1_files[file_ndex],part2_files[file_ndex]]
basename = os.path.basename(files[0])
# 获取时间和日期
date = basename.split('_')[4].split('T')[0]
print("PreProcessing %s's data..."%(date))
files = ';'.join(files)
pipeline_out = subprocess.check_output([python_exe_path, py_file_path, in_path, files, out_path],
stderr=subprocess.STDOUT)
print("The Preprocession of %s's data finishes!"%(date))
# # 睡眠30s,以等待释放内存
print("Sleeping...")
time.sleep(30)
执行代码(可以直接运行snappy_batch_process_S1_GRDH.py,当然在命令行窗口页也可以运行):
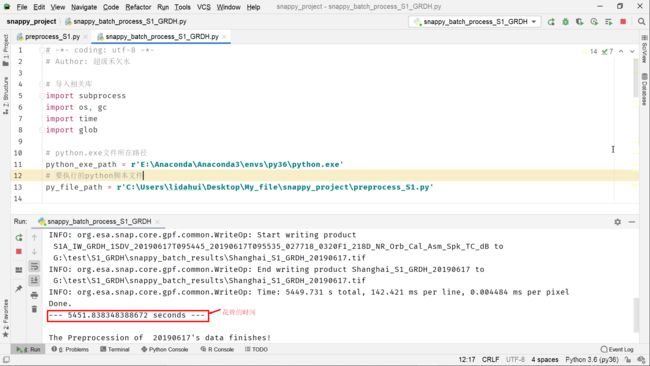
处理一天的镶嵌数据耗费了1个半小时左右的时间,相交使用gpt和流程图效率要低一些(gpt + 流程图文件,约为半小时)。但是,预处理,并非snappy的优势所在,重要的是其可以和Python第三方库结合起来,从而大大扩展相应的可能应用。(无论gpt工具还是snappy,抑或是SNAP GUI界面也好,其实,耗费的时间,只要花费在写操作上,因此,使用固态硬盘的话,写入速度跟快,相应地处理时间会明显减少!博主这里使用的是机械硬盘,因此,耗费的时间还是较多的。当然,耗费的时间也会和写入的影像格式有关,默认的SNAP 影像格式为BEAM-DIMAP格式(这里使用了GeoTiff-BigTiff格式),该格式相较别的格式写入速度会快一些)
结果:
后语
抱歉,拖了很久才开始介绍snappy的使用。不过,前面数篇博客对于编写snappy相关的代码是很有帮助的。本篇博客代码遵循从简单到复杂,循循渐进的思路。仔细地看这篇博客的话,代码的一些片段是比较经典的,并且一些代码还是有点深度的,新手者可能需要琢磨一下才行。但愿,你能有所收获。
尽管使用snappy来做预处理,需要写较长的代码,比不上使用gpt+流程图文件方式来得简单一些,但是,使用snappy可以更精致地控制各项流程参数(Java源代码级别的调用),并且snappy还支持一些使用gpt工具很难实现的操作,比如一些控制点操作,变化分析等等。
尽管到目前为此,仍然只是介绍了Sentinel卫星的预处理,但是,后面,将会展示利用snappy和python的第三方开源包结合起来实现一些Sentinel卫星影像数据分析和应用的强大功能。如果是处理SAR卫星,python还有另一个python包(pyroSAR)可用,该包的开发者也是属于SNAP开发者团队,实现了一些SNAP的SAR处理功能,感兴趣的话,也可以学一下该包,SNAP论坛上有该包的开发者在答疑,也有相关的讨论。
最后,老话了!如果你对欧空局开源软件处理软件SNAP及其snappy开发处理感兴趣,可以加入博主创建的欧空局SNAP处理交流群:665903216(这个群已满人),欧空SNAP处理交流群(二):1102493346。
参考文献
[1] SNAP 官方wiki博客snappy的使用https://senbox.atlassian.net/wiki/spaces/SNAP/pages/19300362/How+to+use+the+SNAP+API+from+Python
[2] SNAP Engine API文档
http://step.esa.int/docs/v6.0/apidoc/engine/
[3] https://github.com/wajuqi/Sentinel-1-preprocessing-using-Snappy
[4] SNAP 官方论坛Temporary fix for snappy memory issues帖子
https://forum.step.esa.int/t/temporary-fix-for-snappy-memory-issues/9772
[5] SNAP 官方论坛Multi-Threading and Performance of snappy / jpy帖子
https://forum.step.esa.int/t/multi-threading-and-performance-of-snappy-jpy/7754