深度学习入门-基于python的理论与实现-卷积神经网络
目录
- 1 前言
-
- 1.1 整体结构
- 1.2卷积层
-
- 1.2.1 全连接层出现的问题
- 1.2.2 卷积运算
- 1.2.3 填充
- 1.2.4 步幅
- 1.2.5 三维数据的卷积运算
- 1.2.6 结合方块思考
- 1.2.7 批处理
- 1.3 池化层
- 1.4 卷积层和池化层的实现
-
- 1.4.1 四维数组
- 1.4.2 基于im2col的展开
- 1.4.3 卷积层的实现
- 1.4.4池化层的实现
- 1.5 CNN 的实现
- 1.6 CNN的可视化
-
- 1.6.1 第一层权重的可视化
- 1.6.2 基于分层结构的信息提取
- 1.7 具有代表性的CNN
-
- 1.7.1 LetNet
- 1.7.2 AlexNet
- 小结
1 前言
卷积神经网络的缩写是CNN,CNN被用于人工智能各个方面,如图像识别,语音识别,几乎基于深度学习的的方法都是以CNN为基础的,本章介绍CNN的结构以及代码实现。
1.1 整体结构
CNN中的整体结构中增加了卷积层和池化层,在之前的神经网络结构中,我们知道有隐藏层Affiine和激活成RELU。还有softmax进行分类输出最终的结果
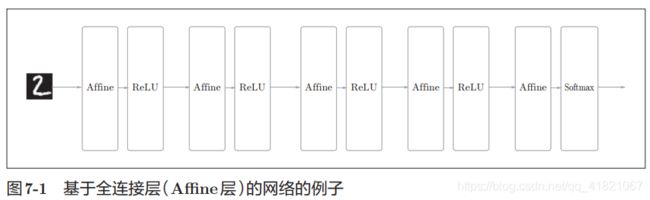
现在CNN中只是将之前的Affine层替换成了卷积层Convolution,把激活层替换成了池化层。
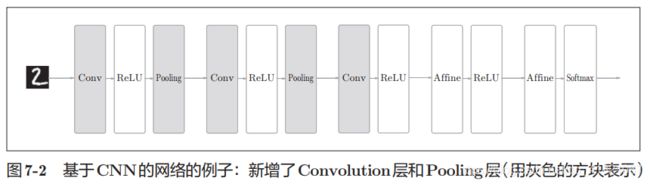
1.2卷积层
CNN中会出现很多新术语,并且其中传递的数据都是多维度的数据,
1.2.1 全连接层出现的问题
在之前的全连接神经网络中我们是基于Affiine层的,这种神经网络忽略了数据的形状,每一层都与上一层连接,如果一个数据是多维度的话在这种神经网络中会被变换成一列,无法利用与形状有关的信息,比如空间上相邻的像素有相似的值,RBG 的各个通道之间的关系。CNN解决了这一问题,可以输入输出多维数据,我们把输入/输出的数据叫做输入/输出特征图。
1.2.2 卷积运算
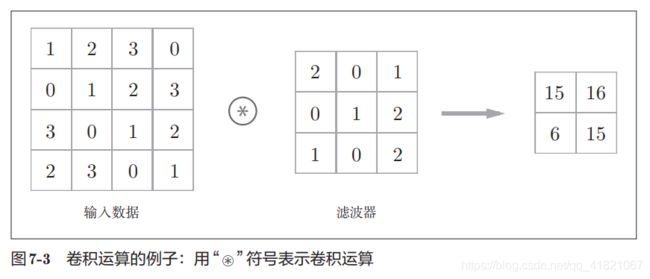
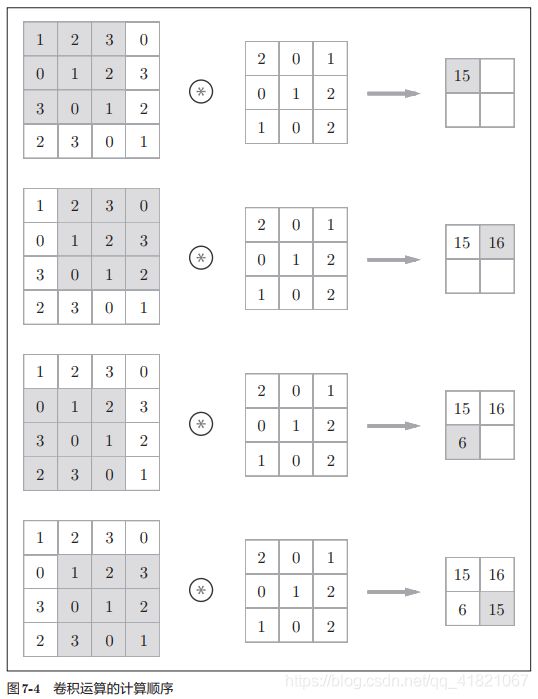
在卷积运算过程中要加入滤波器,在这里滤波器的维度是22 ,卷积神经网络的维度是33,通过在卷积神经网络上移动,然后与滤波器相同位置上的数值相乘后相加,这样就可以得到一个2*2维度的输出结果。
如下图所示

1.2.3 填充
我们在卷积神经网络的计算中经常要用到填充,可以在周围填充1、2、3像素的0,比如在44的卷积神经网络中填充1像素的0就变成了66维度,用33的滤波器就可以生成44 维度的输出特征值
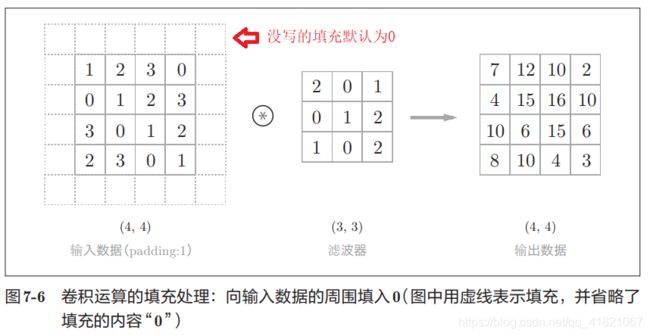
那为什么要使用填充呢?我们知道44的输入与33 的滤波器相乘之后会产生2*2的输出结果比输入来说经过卷积运算之后空间变小了,为了避免这样的情况就会使用填充,确保输出空间结构和输入空间结构一样,然后再传递给下一层神经网络。
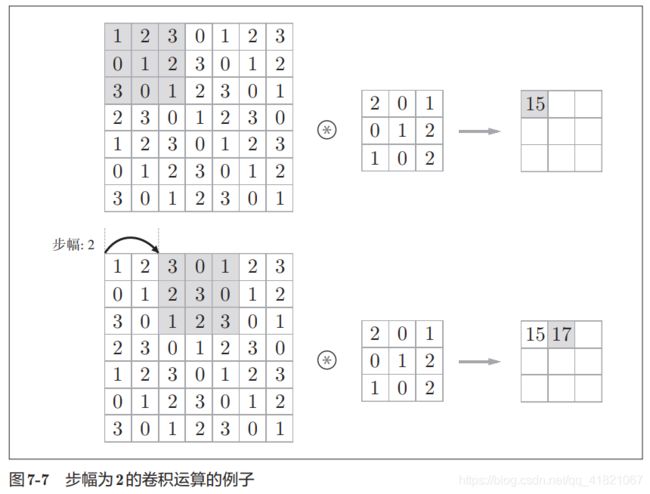
1.2.4 步幅
步幅就是将输入数据应用到滤波器的幅度,如果中间间隔一个就是步幅为2,如下图

1.2.5 三维数据的卷积运算

需要注意的是,输入的通道数(多少个二维矩阵)要和滤波器的通道数相同,如上图所示,滤波器的通道数和输入的通道数都为3。
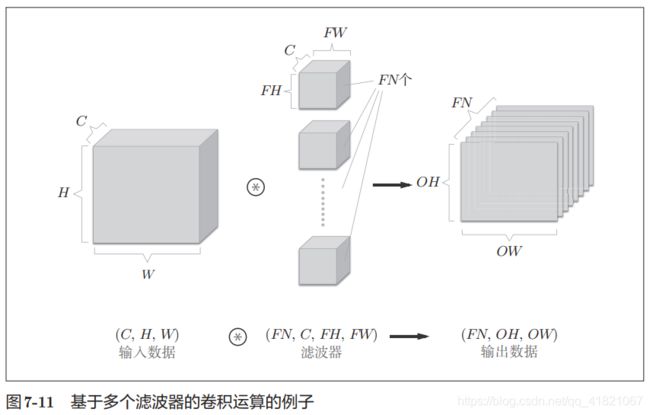
1.2.6 结合方块思考
将数据和滤波器结合长方体的方块来考虑,3维数据的卷积

上面最后输出的是一个特征图,如果要输出多个特征图,也就是说要在通道上进行多个卷积运,那么我们就需要多个滤波器了,如下图所示:

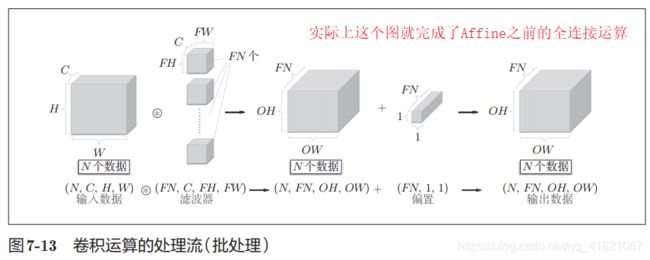
1.2.7 批处理
上面都是基于一个输入块的,如果有多个输入块的化,怎么处理呢
1.3 池化层
池化是缩小高、长方向上的空间的运算。他能把激活函数的输出规模缩小,如下图所示:
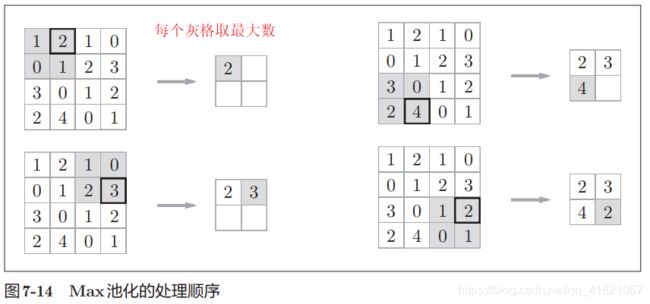
上面的图中选择的是最大数,实际上还有avg等各种取法
池化层
1、没有要学习的参数
是从目标区域中取最大值或者平均值
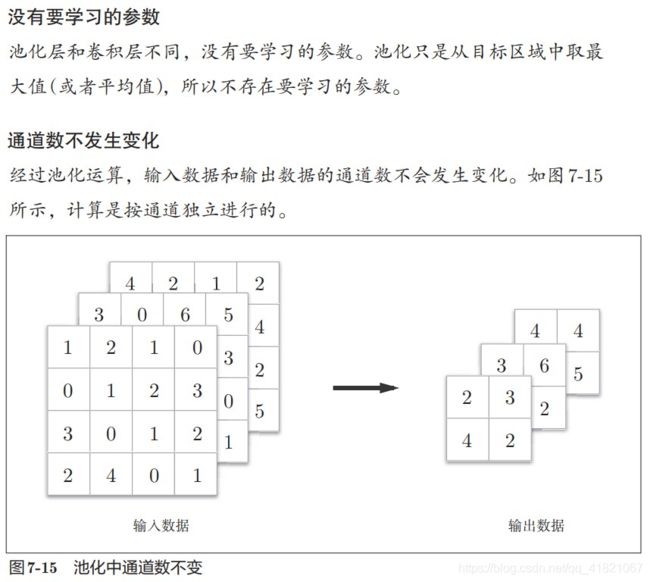
2、通道数不发生变化
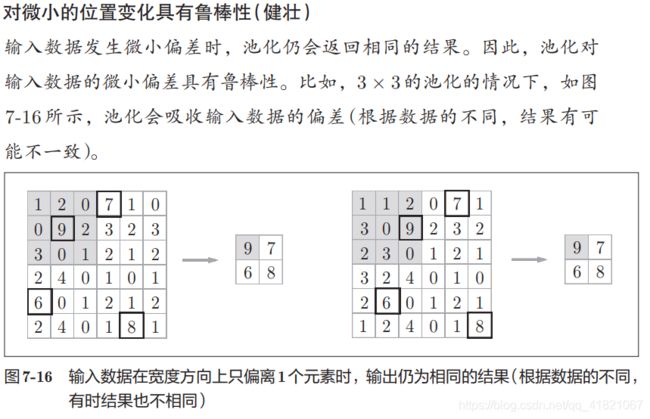
3、对微小的位置变化具有鲁棒性
当输入数据发生微小的偏差的时候,池化层仍然会返回相同的结果
1.4 卷积层和池化层的实现
1.4.1 四维数组
我们在前面提到过进行批量处理的时候需要多一个数量的参数,对于一个三维图形就要多加一维。
1.4.2 基于im2col的展开
如果老老实实进行卷积运算,那么就需要把输入的3/4维数据展开,这样要多个for循环,需要注意的是Numpy在for循环计算速度比较慢,所以我们使用im2col函数实现。



1.4.3 卷积层的实现

import sys,os
sys.path.append(os.pardir)
from common.util import im2col
x1=np.random.rand(1,3,3,7)
#x1为输入数据,由(数据量,通道,高,长)组成
col1=im2col(x1,5,5,stride=1,pad=0)#第一个5是滤波器的高,第二个5是滤波器的长,stride是步幅,pad是充
print(col1.shape) #(9,75)
x2=np.random.rand(10,3,7,7)
col2=im2col(x2,5,5,stride=1,pad=0)
print(col2.shape)#(90,75)
#卷积层实现类
class Convolution:
def __init__(self,w,b,strde=1,pad=0):
self.w=w
self.b=b
self.stride=stride
self.pad=pad
def forward(self,x):
FN,C,FH,FW=self.W.shape
N,C,H,W=x.shape #输出大小计算
out_h=int(1+(H+2*self.pad-FH)/self.stride)
out_w=int(1+(w+2*self.pad-FW)/self.stride)
col=im2col(x,FH,FW,self.stride,self.pad)
col_w=self.w.reshape(FN,-1).T#滤波器的展开,FN,-1指的是FN行,自动控制有多少列
out=np.dot(col,col_w)+self.b
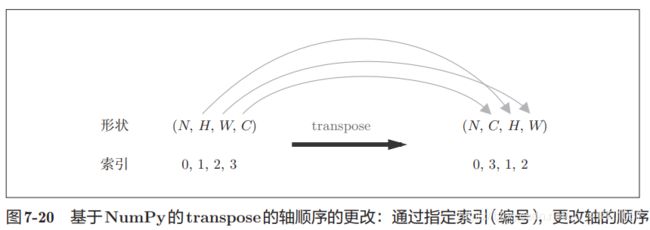
out=out.reshape(N,out_h,out_w,-1).transpose(0,3,1,2)#可以调度维度上数据的位置
return out
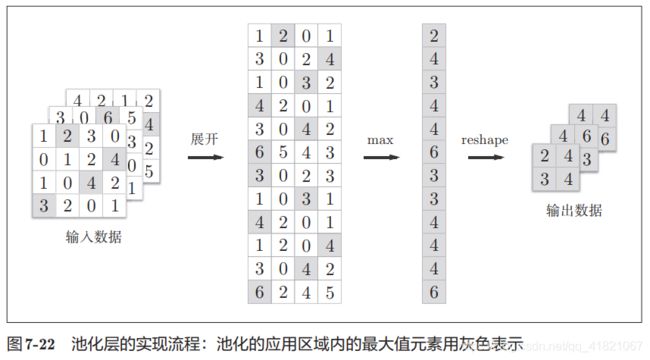
1.4.4池化层的实现
池化层可以单独按通道展开

展开后取最大值,取值之后用reshape函数来进行重构维度
#池化层的实现类
class pooling:
def __init__(self,pool_h,pool_w,stride=1,pad=0):
self.pool_h=pool_h
self.pool_w=pool_w
self.stride=stride
self.pad=pad
def forward(self,x):
N,C,H,W=x.shape
out_h=int(1+(H-self.pool_h)/self.stride)
out_w=int(1+(W-self.pool_w)/self.pool_w)
#展开(1)
col=im2col(x,self,pool_h,self.pool_w,self.stride,self,pad)
col=col.reshape(-1,self.pool_h*self.pool_w)
#最大值
out=np.max(col,axis=1)
#转换(3)
out=out.reshape(N,out_h,out_w,C).transpose(0,3,1,2)
return out
如上实现池化层需要三步:
1.展开输入数据
2求各行的最大值
3转换为合适的输出大小
1.5 CNN 的实现
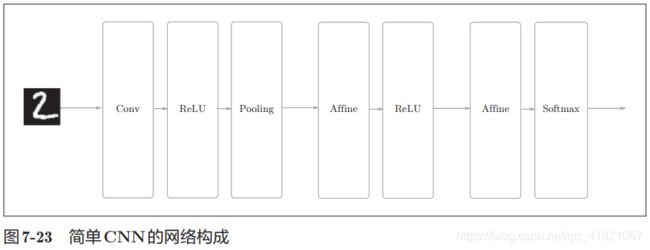
初始化参数

实现类代码
# coding: utf-8
import sys, os
sys.path.append(os.pardir) # 为了导入父目录的文件而进行的设定
import pickle
import numpy as np
from collections import OrderedDict
from common.layers import *
from common.gradient import numerical_gradient
class SimpleConvNet:
"""简单的ConvNet
conv - relu - pool - affine - relu - affine - softmax
Parameters
----------
input_size : 输入大小(MNIST的情况下为784)
hidden_size_list : 隐藏层的神经元数量的列表(e.g. [100, 100, 100])
output_size : 输出大小(MNIST的情况下为10)
activation : 'relu' or 'sigmoid'
weight_init_std : 指定权重的标准差(e.g. 0.01)
指定'relu'或'he'的情况下设定“He的初始值”
指定'sigmoid'或'xavier'的情况下设定“Xavier的初始值”
"""
def __init__(self, input_dim=(1, 28, 28),
conv_param={'filter_num':30, 'filter_size':5, 'pad':0, 'stride':1},
hidden_size=100, output_size=10, weight_init_std=0.01):
filter_num = conv_param['filter_num']
filter_size = conv_param['filter_size']
filter_pad = conv_param['pad']
filter_stride = conv_param['stride']
input_size = input_dim[1]
conv_output_size = (input_size - filter_size + 2*filter_pad) / filter_stride + 1
pool_output_size = int(filter_num * (conv_output_size/2) * (conv_output_size/2))
# 初始化权重
self.params = {}
self.params['W1'] = weight_init_std * \
np.random.randn(filter_num, input_dim[0], filter_size, filter_size)
self.params['b1'] = np.zeros(filter_num)
self.params['W2'] = weight_init_std * \
np.random.randn(pool_output_size, hidden_size)
self.params['b2'] = np.zeros(hidden_size)
self.params['W3'] = weight_init_std * \
np.random.randn(hidden_size, output_size)
self.params['b3'] = np.zeros(output_size)
# 生成层
self.layers = OrderedDict()
self.layers['Conv1'] = Convolution(self.params['W1'], self.params['b1'],
conv_param['stride'], conv_param['pad'])
self.layers['Relu1'] = Relu()
self.layers['Pool1'] = Pooling(pool_h=2, pool_w=2, stride=2)
self.layers['Affine1'] = Affine(self.params['W2'], self.params['b2'])
self.layers['Relu2'] = Relu()
self.layers['Affine2'] = Affine(self.params['W3'], self.params['b3'])
self.last_layer = SoftmaxWithLoss()
def predict(self, x):
for layer in self.layers.values():
x = layer.forward(x)
return x
def loss(self, x, t):
"""求损失函数
参数x是输入数据、t是教师标签
"""
y = self.predict(x)
return self.last_layer.forward(y, t)
def accuracy(self, x, t, batch_size=100):
if t.ndim != 1 : t = np.argmax(t, axis=1)
acc = 0.0
for i in range(int(x.shape[0] / batch_size)):
tx = x[i*batch_size:(i+1)*batch_size]
tt = t[i*batch_size:(i+1)*batch_size]
y = self.predict(tx)
y = np.argmax(y, axis=1)
acc += np.sum(y == tt)
return acc / x.shape[0]
def numerical_gradient(self, x, t):
"""求梯度(数值微分)
Parameters
----------
x : 输入数据
t : 教师标签
Returns
-------
具有各层的梯度的字典变量
grads['W1']、grads['W2']、...是各层的权重
grads['b1']、grads['b2']、...是各层的偏置
"""
loss_w = lambda w: self.loss(x, t)
grads = {}
for idx in (1, 2, 3):
grads['W' + str(idx)] = numerical_gradient(loss_w, self.params['W' + str(idx)])
grads['b' + str(idx)] = numerical_gradient(loss_w, self.params['b' + str(idx)])
return grads
def gradient(self, x, t):
"""求梯度(误差反向传播法)
Parameters
----------
x : 输入数据
t : 教师标签
Returns
-------
具有各层的梯度的字典变量
grads['W1']、grads['W2']、...是各层的权重
grads['b1']、grads['b2']、...是各层的偏置
"""
# forward
self.loss(x, t)
# backward
dout = 1
dout = self.last_layer.backward(dout)
layers = list(self.layers.values())
layers.reverse()
for layer in layers:
dout = layer.backward(dout)
# 设定
grads = {}
grads['W1'], grads['b1'] = self.layers['Conv1'].dW, self.layers['Conv1'].db
grads['W2'], grads['b2'] = self.layers['Affine1'].dW, self.layers['Affine1'].db
grads['W3'], grads['b3'] = self.layers['Affine2'].dW, self.layers['Affine2'].db
return grads
def save_params(self, file_name="params.pkl"):
params = {}
for key, val in self.params.items():
params[key] = val
with open(file_name, 'wb') as f:
pickle.dump(params, f)
def load_params(self, file_name="params.pkl"):
with open(file_name, 'rb') as f:
params = pickle.load(f)
for key, val in params.items():
self.params[key] = val
for i, key in enumerate(['Conv1', 'Affine1', 'Affine2']):
self.layers[key].W = self.params['W' + str(i+1)]
self.layers[key].b = self.params['b' + str(i+1)]
1.6 CNN的可视化
1.6.1 第一层权重的可视化
我们使用卷积滤波器的形状是(30,1,5,5),即30个大小为5*5通道为1 的滤波器济宁学习
代码实现如下
# coding: utf-8
import numpy as np
import matplotlib.pyplot as plt
from simple_convnet import SimpleConvNet
def filter_show(filters, nx=8, margin=3, scale=10):
"""
c.f. https://gist.github.com/aidiary/07d530d5e08011832b12#file-draw_weight-py
"""
FN, C, FH, FW = filters.shape
ny = int(np.ceil(FN / nx))
fig = plt.figure()
fig.subplots_adjust(left=0, right=1, bottom=0, top=1, hspace=0.05, wspace=0.05)
for i in range(FN):
ax = fig.add_subplot(ny, nx, i+1, xticks=[], yticks=[])
ax.imshow(filters[i, 0], cmap=plt.cm.gray_r, interpolation='nearest')
plt.show()
network = SimpleConvNet()
# 随机进行初始化后的权重
filter_show(network.params['W1'])
# 学习后的权重
network.load_params("params.pkl")
filter_show(network.params['W1'])
第一层学习后的滤波器图像(权重参数图像)

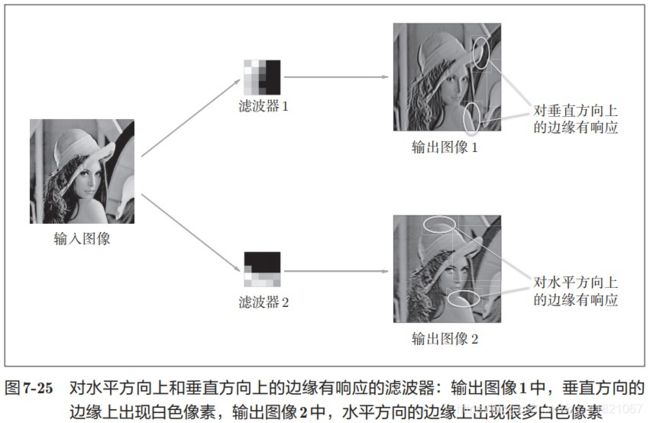
可以看到滤波器学习图像的边缘部分,从而传递给下一次学习
1.6.2 基于分层结构的信息提取
上面的结果是基于第一层的卷积层得到的,第一层的卷积层中提取了边缘或者斑块信息,那么堆叠了多层的CNN中,各层中又会提取到什么信息?根据深度学习的研究,随着层次的加深,提取的信息(也就是反映神经元)也越来越抽象,
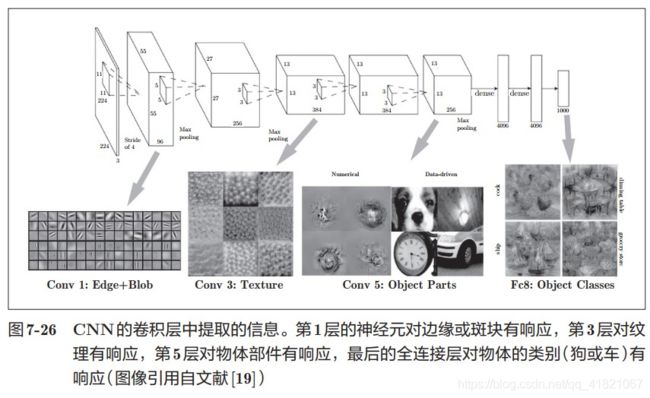
上图是具有8层CNN的AlexNet
1.7 具有代表性的CNN
关于CNN,我们已经提出了各种神经网络结构,具有代表性的是1998年提出的letNet,和2012年被提出的AlexNet
1.7.1 LetNet
这是进行手写数字识别的网络,它具有连续的卷积层和池化层,

1.7.2 AlexNet
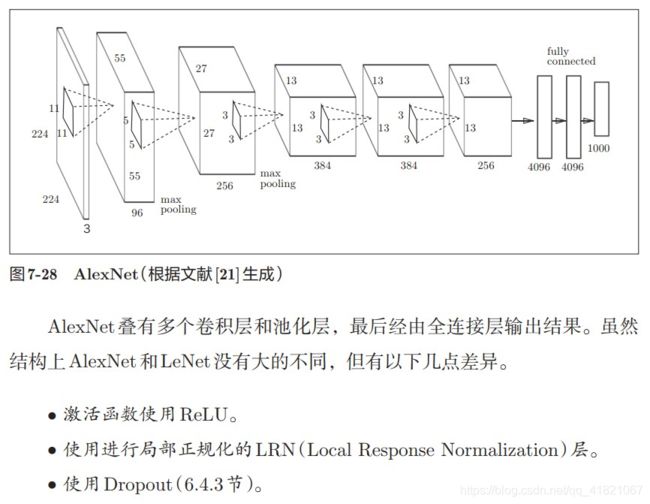
小结
letNet和AlexNet 没有什么太大的不同,但是,围绕的环境和计算机技术有了很大的进步,擅长大规模并行计算的GPU得到了很大的普及,高速进行大量的运算已经得到了可能,大数据和GPU为深度学习提供了动力。