day 49 hbase 安装
文章目录
- 一、HBase
-
- 1、Master
- 2、RegionServer
- 3、Region
- 二、hbase 安装
-
- hbase 重置
- 三、hbase shell
- 总结
I know, i know
地球另一端有你陪我
一、HBase
HBase – Hadoop Database
是一个高可靠性、高性能、面向列、可伸缩、实时读写的分布式数据库
利用 Hadoop HDFS 作为其文件存储系统
利用 Hadoop MapReduce 来处理 HBase 中的海量数据
利用Zookeeper作为其分布式协同服务
主要用来存储非结构化和半结构化的松散数据(列存 NoSQL 数据库)
1、Master
为 Region server 分配 region
( region 类似hadoop 中的 block,hbase 中的存储单位,存储于 hdfs 中,文件格式是 Hfile)
负责 Region server 的负载均衡
(某一个 server 负载过多 region 时,会进行再分配)
发现失效的 Region server 并重新分配其上的 region
管理用户对 table 的增删改操作
(指的是表结构(列簇等)的增删改)
2、RegionServer
维护 region,处理对这些 region 的 IO 请求
(读写操作)
负责切分在运行过程中变得过大的 region
(一个 region 过大时,会自动进行切分。也能建表时预设值,进行自动切分)
3、Region
HBase 自动把表水平划分成多个区域(region),每个 region 保存一个表里某段连续的数据;
这些数据按照字典升序排列(类比 windows 的文件名升序)
每个表一开始只有一个 region,随着数据不断插入表,region 不断增大,
当增大到一个阀值的时候,region就会等分会两个新的 region(裂变);
当 table 中的行不断增多,就会有越来越多的 region,这样一张完整的表被保存在多个Regionserver 上
二、hbase 安装
依赖于 hadoop 和 zookeeper
因此需要先开启 hadoop 和 zookeeper
start-all.sh
// 三台启动zookeeper
zkServer.sh start
zkServer.sh status
1 上传解压文件
tar -xvf hbase-1.4.6-bin.tar.gz -C /usr/local/soft/
2 修改hbase-env.sh文件
增加java配置
vim conf/hbase-env.sh
export JAVA_HOME=/usr/local/soft/jdk1.8.0_171
关闭默认zk配置(我们已经提前配置 zk,将自带的关闭)
export HBASE_MANAGES_ZK=false
3 修改 hbase-site.xml 文件
vim conf/hbase-site.xml
//标签内添加
<property>
<name>hbase.rootdir</name>
<value>hdfs://master:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>node1,node2,master</value>
</property>
4 修改 regionservers 文件(regionservers 节点的指定)
vim conf/regionservers
node1
node2
5 同步到所有节点
(注意此处并不是单引号)
scp -r hbase-1.4.6/ node1:`pwd`
scp -r hbase-1.4.6/ node2:`pwd`
6 添加环境变量
vim /etc/profile
7 启动 hbase 集群,只需要在 master 上
start-hbase.sh
8 验证网址
http://master:16010
打开 base 命令行
hbase shell
hbase日志文件所在的目录
/usr/local/soft/hbase-1.4.6/logs
关闭集群的命令
stop-hbase.sh
hbase 重置
关闭进程
stop-hbase.sh
删除数据(hdfs)
hdfs dfs -rmr /hbase
删除元数据(zk)
zkCli.sh
rmr /hbase
重新启动hbase
start-hbase.sh
时间同步
yum install ntp -y
三、hbase shell
name space 命名空间,可以理解为类似文件夹的存储结构
hbase 中存在命名空间,但是相对弱化,大部分表都存在默认命名空间中(default)
hbase 自带一个名为 hbase 的命名空间,其中一个表 meta 比较关键,存放所有表的信息
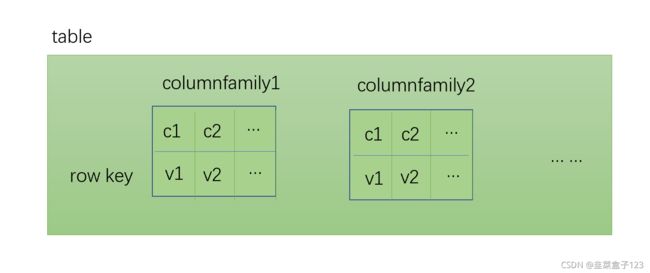
1 创建用户表
create 'table','cf1','cf2'
create 'table',{NAME=>'cf1',VERSION=>'3'},'cf2'
create 'pokemon','cf1','cf2'
2 展示当前用户表
list
3 查看表信息
describe 'pokemon'
4 删除、增加列簇
alter 'table', 'delete'=>'cf2'
alter 'table', NAME=>'cf2'
5 插入数据
每个 value 需要单独插入,没写入一个 value 会生成一条记录
这一条记录叫做单元格(cell)
put 'table','rowkey','cf1:c1','v1'
put 'pokemon','001','cf1:name','ralts'
put 'pokemon','001','cf2:level','8'
6 查询记录
get 'pokemon','001'
get 'pokemon','001','cf1:name'
7 查询所有记录
scan 'pokemon'
/ 查询前两条
scan 'pokemon', {
LIMIT => 2}
/ 查询,起止之间,左闭右开
scan 'pokemon', {STARTROW => '001', ENDROW => '002'}
8 统计表记录
INTERVAL设置多少行显示一次及对应的rowkey,默认1000;
CACHE每次去取的缓存区大小,默认是10,调整该参数可提高查询速度
count 'pokemon',{
INTERVAL => intervalNum, CACHE => cacheNum}
9 删除
实际上数据依然存在,只是更改了标记,变为不可用
/ 删除单元格
delete 'pokemon', '001', 'cf1:name'
/ 指定rowkey删除
deleteall 'pokemon','001'
/ 清空表数据,会清空所有的预分区
truncate 'pokemon'
10 启用、禁用表
hbase 中表有两种状态,分别是启用和禁用
想要删除表,需要先禁用
/ 禁用表
disable 'pokemon'
/ 启用表
enable 'pokemon'
/ 查询表是否存在
exists 'pokemon'
/ 删除表
drop 'pokemon'
总结
元数据:
描述数据的数据
hive:
数据存放于 hdfs
元数据存放于 sql
hbase:
数据存放于 region server(实际上还是hdfs)
元数据存放于 zookeeper
查询本机添加的路径
echo $JAVA_HOME
hbase 中, backspace 和 del 键想效果相同
想要向前删除,需要 ctrl + backspace
hbase 建表时,严格区分大小写