Hadoop+Hdfs+Hbase+Kafka+Zookeeper集群搭建
摘要:
本文详细介绍了基于centos7的Hadoop集群的搭建过程,给出了Hadoop的基础知识和项目搭建的流程,搭建了一个master结点和两个slave结点的Hadoop集群,在master和slave服务器上配置HDFS(hadoop分布式文件系统) ,HBase(集群数据库),zookeeper(集群维护服务),以及 kafka(消息队列),同时详细给出搭建过程和测试结果,并对搭建过程遇到的bug进行详细的记录
文章目录
-
- 摘要:
- 1 关于Hadoop
-
- 1.1 Hadoop是什么
- 1.2 Hadoop能做什么
- 1.3 怎么使用Hadoop
- 2 项目准备
-
- 2.1 Linux centos环境准备
- 2.2安装 java 环境(三台机器都要安装)
- 2.3 修改三台主机 hostname
- 2.4 配置集群机器之间的免密登录
- 3 安装 hadoop
-
- 3.1 解压 hadoop 压缩包
- 3.2 配置环境变量
- 3.3 修改配置文件
- 3.4 拷贝文件
- 3.5 创建临时文件目录
- 3.6 格式化 hdfs 文件系统
- 3.7 启动hadoop
- 4 测试Hadoop
-
- 4.1 web 页面测试
- 4.2 hdfs 功能测试
- 4.3 mapreduce 功能测试
- 5 安装配置Zookeeper集群
-
- 5.1 修改配置文件zoo.cfg
- 5.2 新建并编辑myid文件
- 6 安装配置HBase集群
-
- 6.1 修改配置文件
- 6.2分发并同步安装包
- 6.3 启动hbase
- 7 安装配置kafka集群
-
- 7.1 修改配置文件
- 7.2 分发并同步安装包
- 7.3 slave1和slave2上更改broker id
- 7.4 启动kafka
- 8 启动集群
- 9 测试kafka
- 10 测试Hbase
- 11 遇到的bug
-
- 11.1 启动hdfs时,datanodes报错
- 11.2 启动hdfs时,datanode无法正常启动
- 11.3 yarn无法正常启动 (resourceManager/nodeManager)
- 11.4 webHDFS出错
1 关于Hadoop
1.1 Hadoop是什么
Hadoop是由java语言编写的,在分布式服务器集群上存储海量数据并运行分布式分析应用的开源框架,其核心部件是HDFS与MapReduce。
HDFS是一个分布式文件系统:引入存放文件元数据信息的服务器Namenode和实际存放数据的服务器Datanode,对数据进行分布式储存和读取。
MapReduce是一个分布式计算框架:MapReduce的核心思想是把计算任务分配给集群内的服务器里执行。通过对计算任务的拆分(Map计算/Reduce计算)再根据任务调度器(JobTracker)对任务进行分布式计算。
1.2 Hadoop能做什么
大数据存储:分布式存储
日志处理:擅长日志分析
ETL:数据抽取到oracle、mysql、DB2、mongdb及主流数据库
机器学习: 比如Apache Mahout项目
搜索引擎:Hadoop + lucene实现
数据挖掘:目前比较流行的广告推荐,个性化广告推荐
Hadoop是专为离线和大规模数据分析而设计的,并不适合那种对几个记录随机读写的在线事务处理模式。
1.3 怎么使用Hadoop
-
Hadoop集群的搭建
无论是在windows上装几台虚拟机玩Hadoop,还是真实的服务器来玩,说简单点就是把Hadoop的安装包放在每一台服务器上,改改配置,启动就完成了Hadoop集群的搭建。 -
上传文件到Hadoop集群,实现文件存储
Hadoop集群搭建好以后,可以通过web页面查看集群的情况,还可以通过Hadoop命令来上传文件到hdfs集群,通过Hadoop命令在hdfs集群上建立目录,通过Hadoop命令删除集群上的文件等等。 -
编写map/reduce程序,完成计算任务
通过集成开发工具(例如eclipse)导入Hadoop相关的jar包,编写map/reduce程序,将程序打成jar包扔在集群上执行,运行后出计算结果。
2 项目准备
2.1 Linux centos环境准备
- 三台centos 7机器,本例中使用 vmware 创建三台虚拟机作为替代
- 准备好 jdk 8(不要使用jdk8以上的版本,会出n多bug) 和 hadoop-3.1.3 安装包

- 准备三台虚拟机配置静态ip点这里
创建虚拟机,并且将网络适配器选用 NAT模式,并且配置为静态 ip, 机器静态ip配置参考 静态ip设置 分别将三台机器的ip 设置为 [192.168.19.200,192.168.19.201,192.168.19.202]
2.2安装 java 环境(三台机器都要安装)
由于 hadoop 框架的启动是依赖 java 环境,因此需要准备 jdk 环境,本例中使用的 jdk8 在/home/min/tar目录下进行演示,使用 jdk-8u202-linux-x64.tar.gz 解压jdk ,然后使用 mv jdk1.8.0_201 jdk8 将目录改名
- 配置 jdk 环境变量
使用命令 vi /etc/profile 将如下代码添加到文件末尾,JAVA_HOME 变量设置为自己的目录
export JAVA_HOME=/home/min/tar/jdk8
export CLASSPATH=.$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$JAVA_HOME/bin:$PATH
配置好以后使用 source /etc/profile 重新加载配置文件,使用 java -version 测试jdk 配置是否成功
2.3 修改三台主机 hostname
本例中Linux操作系统为为 centos 7,使用自带的 hostnamectl 修改hostname
//192.168.19.200 上执行
hostnamectl set-hostname master
//192.168.19.201 上执行
hostnamectl set-hostname slave1
//192.168.19.202 上执行
hostnamectl set-hostname slave2
- 修改 host文件
使用 vi /etc/hosts 编辑该文件,在文件最后追加主机与ip的对应关系 最后重启机器,将这些配置生效
192.168.19.200 master
192.168.19.201 slave1
192.168.19.202 slave2
2.4 配置集群机器之间的免密登录
hadoop 集群是通过主节点的 rpc 调用来对整个集群进行统一的操作管理,如果不配置免密登录,在每次启动集群时需要输入每个从节点的机器密码,免密登录很好的解决此问题
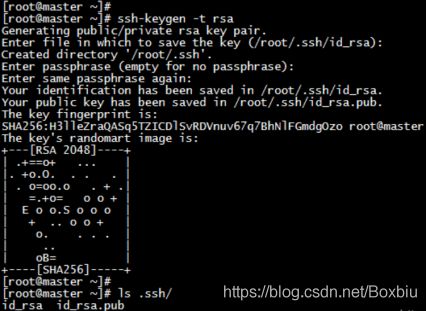
- 分别在三台机器上生成 ssh 链接的私钥和公钥(一直回车,直到结束),在用户的家目录下生成一个隐藏文件 .ssh
ssh-keygen -t rsa
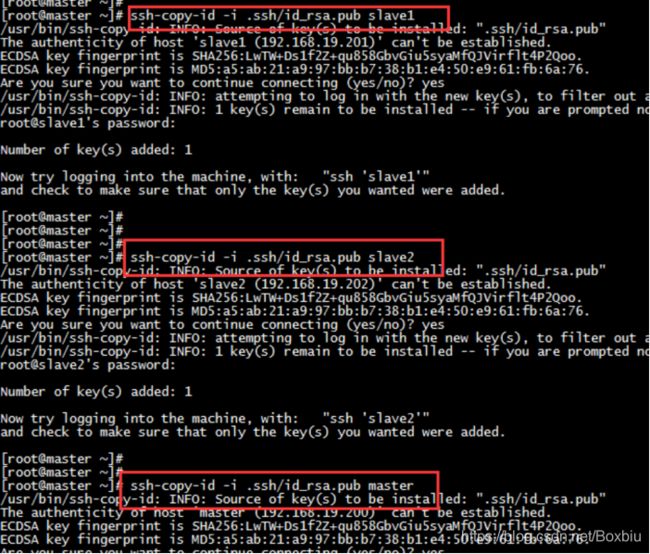
2. 将本机的公钥拷贝到其余两台机器和本机,以 master 机器为例
ssh-copy-id -i .ssh/id_rsa.pub slave1
ssh-copy-id -i .ssh/id_rsa.pub slave2
ssh-copy-id -i .ssh/id_rsa.pub master
-
将三台机器公钥都拷贝完成后,会在 ~/.ssh 文件下生成 authorized_keys,known_hosts 两个文件,存放的是一些免密登录的信息
-
关闭防火墙
关闭防火墙,并且设置开机不启动
systemctl stop firewalld.service
systemctl disable firewalld.service
3 安装 hadoop
3.1 解压 hadoop 压缩包
使用命令 tar -zxvf hadoop-3.1.3.tar.gz 解压 hadoop 压缩包
3.2 配置环境变量
在三台机器上都配置 HADOOP_HOME ,vi /etc/profile 添加图中内容,保存后,使用 source /etc/profile 使配置文件生效
export JAVA_HOME=/home/min/tar/jdk-11.0.4
export CLASSPATH=. J A V A H O M E / l i b / d t . j a r : JAVA_HOME/lib/dt.jar: JAVAHOME/lib/dt.jar:JAVA_HOME/lib/tools.jar
export HADOOP_HOME=/home/min/tar/hadoop-3.1.3
export PATH=JAVA_HOME/bin: P A T H : PATH: PATH:HADOOP_HOME/bin
3.3 修改配置文件
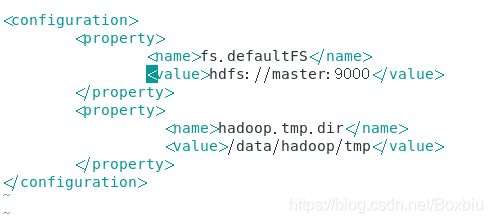
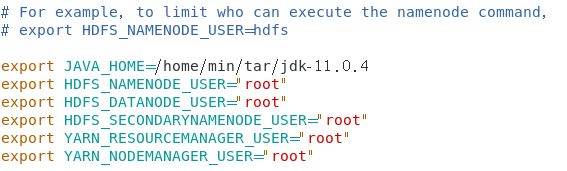
修改Hadoop目录下的 etc/hadoop文件夹中的core-site.xml,hadoop-env.sh,hdfs-site.xml,mapred-site.xml,yarn-site.xml,workers。先修改 master 节点上的配置文件,然后通过远程复制到 slave1 与 slave2
- 修改core-site.xml
- 修改 hadoop-env.sh
- 修改hdfs-site.xml
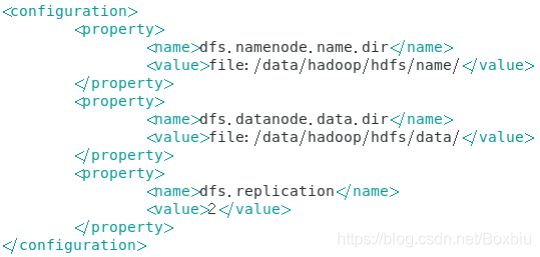
- 修改mapred-site.xml

- 修改workers

- 修改yarn-site.xml
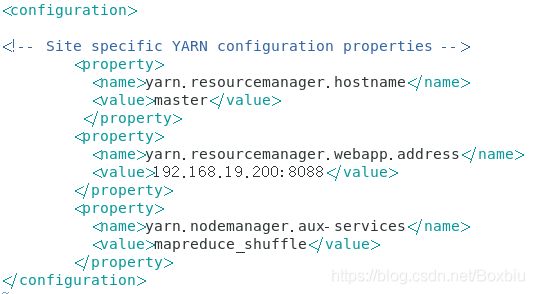
3.4 拷贝文件
将 hadoop 目录从 master 拷贝到 slave1 与 slave2,由于之前配置了免密登录,所以不需要输入密码即可完成拷贝
scp -qr /home/min/tar/hadoop-3.1.3 slave1:/home/min/tar
scp -qr /home/min/tar/hadoop-3.1.3 slave2:/home/min/tar
3.5 创建临时文件目录
创建临时文件目录 (三台机器都需创建), 创建的目录对应于 第六步 hdfs-site.xml 中配置的目录
mkdir -p /data/hadoop/hdfs/data
mkdir -p /data/hadoop/hdfs/name
3.6 格式化 hdfs 文件系统
在master结点上的hadoop的安装目录下的 bin 目录下执行以下命令
./hdfs namenode -format
注意:
如果需要重新格式化NameNode,需要先将原来NameNode和DataNode下的文件全部删除,不然会报错,NameNode和DataNode所在目录是在core-site.xml中hadoop.tmp.dir、dfs.namenode.name.dir、dfs.datanode.data.dir属性配置的。
因为每次格式化,默认是创建一个集群ID,并写入NameNode和DataNode的VERSION文件中(VERSION文件所在目录为hdfs/name/current 和 hdfs/data/current),重新格式化时,默认会生成一个新的集群ID,如果不删除原来的目录,会导致namenode中的VERSION文件中是新的集群ID,而DataNode中是旧的集群ID,不一致时会报错。
3.7 启动hadoop
主节点上在hadoop目录下执行:
./sbin/start-all.sh
- 主节点上jps进程如下:
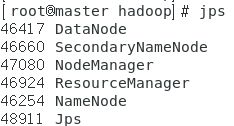
- 每个子节点上的jps进程如下:

如果这样表示hadoop集群配置成功
4 测试Hadoop
4.1 web 页面测试
以下几个web页面是否可以正常打开(注意关闭防火墙)
http://192.168.19.200:8088/cluster hadoop 集群信息
http://192.168.19.200:9870/dfshealth.html#tab-overview hdfs 地址
http://192.168.19.200:9864/datanode.html dataNode 地址
http://192.168.19.200:8042/node nodeManager 地址
http://192.168.19.200:9868/status.html secondaryNameNode
4.2 hdfs 功能测试
- 提前打开web界面查看 hdfs 文件系统,目前根目录下没有任何文件
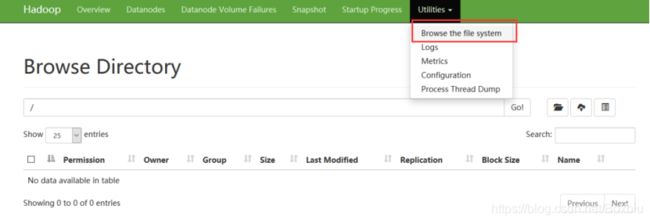
- 使用命令 hdfs dfs -put start-dfs.sh / 将sbin文件夹中的 start-dfs.sh 文件上传到 hdfs 文件系统的根目录下
- 重新打开web界面查看 hdfs 文件系统文件是否上传成功

4.3 mapreduce 功能测试
- /home/min 目录下创建一个文件 wordtest 文件内容如下,下面我们用自带的库函数 统计各个单词出现的次数
Good morning, everyone. Thank you for taking your time. It’s really my honor to have this opportunity to take part in this interview. Now, I would like to introduce myself briefly.
- 将该文件上传到 hdfs 文件系统上(因为 mapreduce 功能是在 hdfs 基础之上)【使用的是另一种 hdfs 上传文件的命令】
hadoop fs -put wordtest /wordtest

- 执行 mapreduce 后生成结果文件
hadoop jar /home/min/hadoop-3.1.3/share/hadoop/mapreduce
/hadoop-mapreduce-examples-3.1.3.jar wordcount /wordtest /result

- 查看统计结果
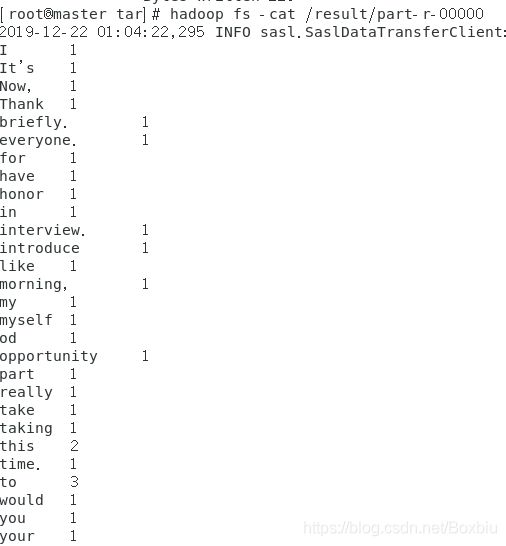
5 安装配置Zookeeper集群
解压zookeeper安装包,并重命名为zookeeper,然后进行以下操作。
5.1 修改配置文件zoo.cfg
进入~/zookeeper/conf目录,拷贝zoo_sample.cfg文件为zoo.cfg
cp zoo_sample.cfg zoo.cfg
对zoo.cfg进行编辑,内容如下:
dataDir=/home/min/tar/zookeeper/data
server.1=192.168.19.200:2888:3888
server.2=192.168.19.201:2888:3888
server.3=192.168.19.202:2888:3888
5.2 新建并编辑myid文件
在dataDir目录下新建myid文件,输入一个数字(master为1,slave1为2,slave2为3),比如master主机上的操作如下:
mkdir /home/min/tar/zookeeper/data
echo "1" > /home/min/tar/zookeeper/data/myid
同样,也可以使用scp命令进行远程复制,只不过要修改每个节点上myid文件中的数字
scp -qr /home/min/tar/zookeeper slave1:/home/min/tar
scp -qr /home/min/tar/zookeeper slave2:/home/min/tar
注意事项:
如果启动报类似异常:QuorumCnxManager@384] – Cannot open channel to 2 at election address slave-02/192.168.0.178:3888 是可以忽略的,因为该服务启动时会尝试连接所有节点,而其他节点尚未启动。通过后面部分可以看到,集群在选出一个Leader后,最后稳定 了。其他结点可能也出现类似问题,属于正常。
6 安装配置HBase集群
将hbase安装包进行解压,并重命名为hbase,然后进入habase的bin目录进行如下配置。
6.1 修改配置文件
- 配置hbase-env.sh
export JAVA_HOME=/home/min/tar/jdk-11.0.4
export HBASE_CLASSPATH=/home/min/tar/hadoop-3.1.3/etc/hadoop/
export HBASE_MANAGES_ZK=false
- 配置hbase-site.xml
hbase.rootdir
hdfs://master:9000/hbase
hbase.master
master
hbase.cluster.distributed
true
hbase.zookeeper.property.clientPort
2181
hbase.zookeeper.quorum
master,slave1,slave2
zookeeper.session.timeout
60000000
dfs.support.append
true
- 配置regionservers
在 regionservers 文件中添加slave列表:
master
slave1
slave2
6.2分发并同步安装包
将整个hbase安装目录都远程拷贝到所有slave服务器:
scp -qr /home/min/tar/hbase slave1:/home/min/tar
scp -qr /home/min/tar/hbase slave2:/home/min/tar
6.3 启动hbase
./hbase/bin/start-hbase.sh

7 安装配置kafka集群
将kafka安装包进行解压,并重命名为kafka,对config目录下的server.properties添加配置
7.1 修改配置文件
- 添加broker.id
broker.id=01
host.name=master
- 添加zookeeper节点地址和端口
zookeeper.connect=master:2181,slave1:2181,slave2:2181
7.2 分发并同步安装包
scp -qr /home/min/tar/kafka slave1:/home/min/tar
7.3 slave1和slave2上更改broker id
将broker id改为02和03
7.4 启动kafka
由于没有配置环境,需要再kafka目录下启动
./bin/kafka-server-start.sh -daemon config/server.properties

8 启动集群
-
启动ZooKeeper
zookeeper/bin/zkServer.sh start -
启动hadoop
./hadoop-3.1.3/sbin/start-all.sh -
启动hbase
./hbase/bin/start-hbase.sh -
启动kafka
./bin/kafka-server-start.sh -daemon config/server.properties -
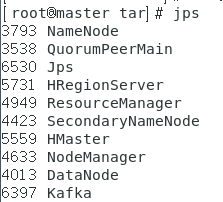
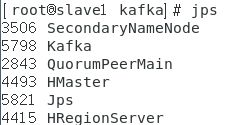
启动后,master上进程和slave进程列表
Mater
Slave
9 测试kafka
- 在master上创建topic-test
./bin/kafka-topics.sh --create --zookeeper master:2181,slave1:2181,slave2:2181 --replication-factor 3 --partitions 3 --topic test
Created topic "test".
- 在master,slave1,2上查看已创建的topic列表
./bin/kafka-topics.sh --list --zookeeper localhost:2181

3. 在master上启动生产者
./bin/kafka-console-producer.sh --broker-list master:9092,slave1:9092,slave2:9092 --topic test

4. 在其他节点上启动控制台消费者
./bin/kafka-console-consumer.sh --bootstrap-server master:9092,slave1:9092,slave2:9092 --from-beginning --topic test
![]()
10 测试Hbase
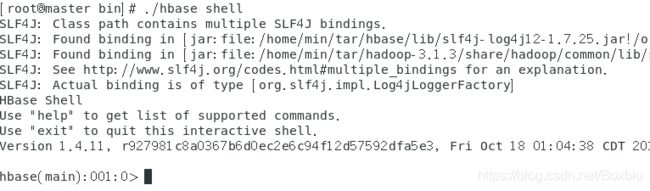
这个测试是通过HBase Shell 命令来完成一个 HBase 表的创建、插入、查找、删除操作。
-
进入shell模式
-
创建test1表
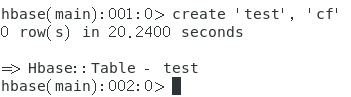
-
显示表

-
插入数据

-
查看数据

-
获取数据

-
删除表
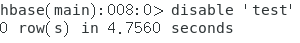
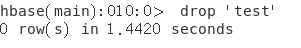
11 遇到的bug
11.1 启动hdfs时,datanodes报错
Starting datanodes
ERROR: Refusing to run as root: root account is not found. Aborting.
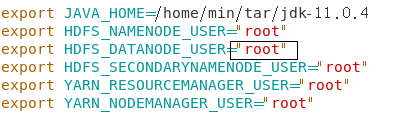
解决办法:
在hadoop/etc/hadoop/hadoop-env.sh中的配置文件中的root多打了个空格,更正即可
11.2 启动hdfs时,datanode无法正常启动
当我们多次格式化文件系统(hadoop namenode -format)时,会出现DataNode无法启动。
多次启动中发现有NameNode节点,并没有DataNode节点
如图所示:
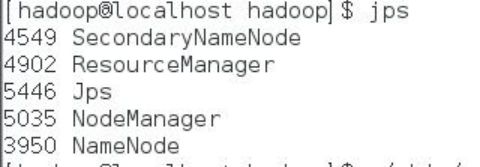
经查看相关日志发现问题所在:
datanode的clusterID 和 namenode的clusterID 不匹配。
当我们执行文件系统格式化时,会在namenode数据文件夹(即配置文件中dfs.name.dir在本地系统的路径)中保存一个current/VERSION文件,记录namespaceID,标志了所有格式化的namenode版本。如果我们频繁的格式化namenode,那么datanode中保存(即dfs.data.dir在本地系统的路径)的current/VERSION文件只是你地第一次格式化时保存的namenode的ID,因此就会造成namenode和datanode之间的ID不一致。
解决办法:
删除DataNode的所有资料及将集群中每个datanode节点的/dfs/data/current中的VERSION删除,然后重新执行hadoop namenode -format进行格式化,重启集群,错误消失。
出现该问题的原因:
在第一次格式化dfs后,启动并使用了hadoop,后来又重新执行了格式化命令(hdfs namenode -format),这时namenode的clusterID会重新生成,而datanode的clusterID 保持不变。
11.3 yarn无法正常启动 (resourceManager/nodeManager)
./sbin/start-yarn.sh
jps上找不到 resourceManager 和 nodeManger的进程, 查询日志发现是jdk版本问题
解决办法: 从jdk9以后 java9默认禁用访问许多javax. * API。更换jdk8即可
11.4 webHDFS出错
如下图,提示"Failed to retrieve data from /webhdfs/v1/?op=LISTSTATUS:Server Error“,也无法透过Web界面上传文件
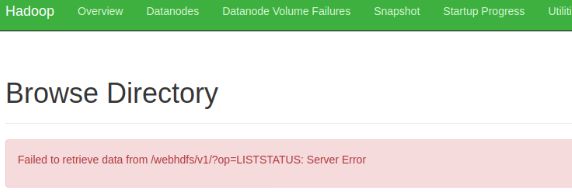
经过一番查找之后(可找Hadoop的Log日志)确认是Jdk的版本问题,更换jdk版本为 jdk8
这件事得到一个教训,软件并不是版本越高越好