⑦SparkSQL初案例
先看看最基础的sparkSQL,创建简单RDD然后过滤
val sparkConf: SparkConf = new SparkConf().setAppName("BookCarCard")
.setMaster("local[2]") //生产不要这段
val spark: SparkSession = SparkSession.builder().config(sparkConf)
.getOrCreate()
val df = spark.createDataFrame(Seq(("a", 1), ("a", 2), ("b", 2),
("b", 3), ("c", 1))).toDF("id", "num")
df.filter("num>2").show()学习SparkSQL看个案例,准备好的数据如下
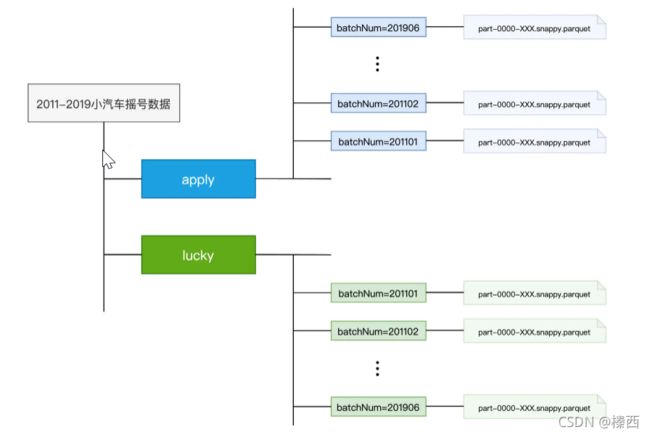
可以看到,根目录下有 apply 和 lucky 两个子目录,apply 目录的内容是 2011-2019 年各个批次参与摇号的申请号码,而 lucky 目录包含的是各个批次中签的申请号码。为了叙述方便,我们把参与过摇号的人叫“申请者”,把中签的人叫“中签者”。apply 和 lucky 的下一级子目录是各个摇号批次,而摇号批次目录下包含的是 Parquet 格式的数据文件。
数据探索
不过,先别忙着直接上手数据分析。在此之前,先要对数据模式(Data Schema)有最基本的认知,也就是源数据都有哪些字段,这些字段的类型和含义分别是什么,这一步就是我们常说的数据探索。数据探索的思路是这样的:首先,使用 SparkSession 的 read API 读取源数据、创建 DataFrame。然后,通过调用 DataFrame 的 show 方法,我们就可以轻松获取源数据的样本数据,从而完成数据的初步探索,代码如下所示。
import org.apache.spark.sql.DataFrame
val rootPath: String = _
// 申请者数据
val hdfs_path_apply: String = s"${rootPath}/apply"
// spark是spark-shell中默认的SparkSession实例
// 通过read API读取源文件
val applyNumbersDF: DataFrame = spark.read.parquet(hdfs_path_apply)
// 数据打印
applyNumbersDF.show
// 中签者数据
val hdfs_path_lucky: String = s"${rootPath}/lucky"
// 通过read API读取源文件
val luckyDogsDF: DataFrame = spark.read.parquet(hdfs_path_lucky)
// 数据打印
luckyDogsDF.show在windows环境下,不能直接spark.read,先看SparkSession
什么是 SparkSession
Apache Spark 2.0 引入了 SparkSession,其为用户提供了一个统一的切入点来使用 Spark 的各项功能,并且允许用户通过它调用 DataFrame 和 Dataset 相关 API来编写 Spark 程序。最重要的是,它减少了用户需要了解的一些概念,使得我们可以很容易地与 Spark 交互。在 2.0 版本之前,与 Spark 交互之前必须先创建 SparkConf 和 SparkContext。然而在 Spark 2.0 中,我们可以通过 SparkSession 来实现同样的功能,而不需要显式地创建 SparkConf, SparkContext 以及 SQLContext,因为这些对象已经封装在SparkSession 中。
package org.example.spark
import org.apache.spark.sql.{DataFrame, SparkSession}
import org.apache.spark.{SparkConf}
object SparkSQL1 {
def main(args: Array[String]): Unit = {
val hdfs_path_apply: String = "D:\\testCode\\apply"
// 申请者数据
// spark是spark-shell中默认的SparkSession实例
//设置spark的配置文件信息
val sparkConf: SparkConf = new SparkConf().setAppName("BookCarCard")
.setMaster("local[2]")
val spark: SparkSession = SparkSession.builder().config(sparkConf)
.getOrCreate()
val applyNumbersDF: DataFrame = spark.read.parquet(hdfs_path_apply)
// 数据打印
applyNumbersDF.show
// 中签者数据
val hdfs_path_lucky: String = "D:\\testCode\\luckey"
// 通过read API读取源文件
val luckyDogsDF: DataFrame = spark.read.parquet(hdfs_path_lucky)
// 数据打印
luckyDogsDF.show
}
}另外,SparkSession,可以把它理解为是 SparkContext 的进阶版,是 Spark(2.0 版本以后)新一代的开发入口。SparkContext 通过 textFile API 把源数据转换为 RDD,而 SparkSession 通过 read API 把源数据转换为 DataFrame。而 DataFrame,你可以把它看作是一种特殊的 RDD。RDD 我们已经很熟悉了,现在就把 DataFrame 跟 RDD 做个对比,让你先对 DataFrame 有个感性认识。
先从功能分析,与 RDD 一样,DataFrame 也用来封装分布式数据集,它也有数据分区的概念,也是通过算子来实现不同 DataFrame 之间的转换,只不过 DataFrame 采用了一套与 RDD 算子不同的独立算子集。
再者,在数据内容方面,与 RDD 不同,DataFrame 是一种带 Schema 的分布式数据集,因此,你可以简单地把 DataFrame 看作是数据库中的一张二维表。
最后,DataFrame 背后的计算引擎是 Spark SQL,而 RDD 的计算引擎是 Spark Core,这一点至关重要。不过,关于计算引擎之间的差异,我们留到以后再去展开。好啦,言归正传。简单了解了 SparkSession 与 DataFrame 的概念之后,我们继续来看数据探索。
把上述代码丢进 spark-shell 之后,分别在 applyNumbersDF 和 luckyDogsDF 这两个 DataFrame 之上调用 show 函数,我们就可以得到样本数据。可以看到,“这两张表”的 Schema 是一样的,它们都包含两个字段,一个是 String 类型的 carNum,另一个是类型为 Int 的 batchNum。
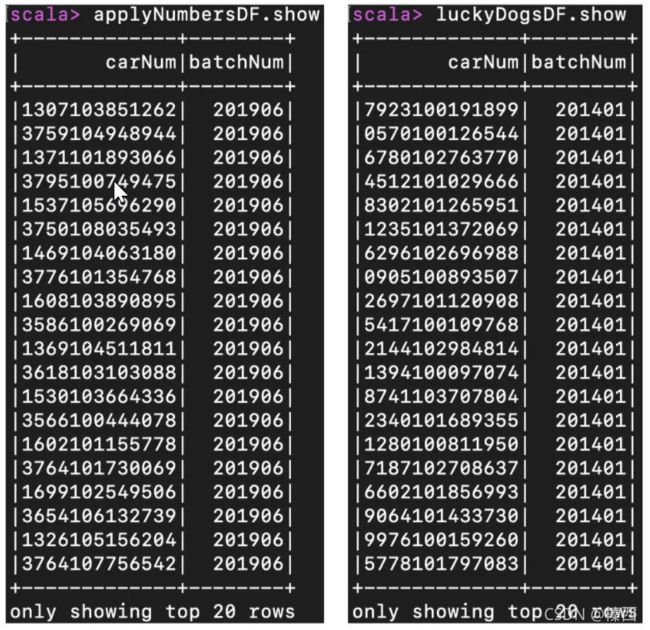
其中,carNum 的含义是申请号码、或是中签号码,而 batchNum 则代表摇号批次,比如 201906 表示 2019 年的最后一批摇号,201401 表示 2014 年的第一次摇号。好啦,进行到这里,初步的数据探索工作就告一段落了
业务需求实现
完成初步的数据探索之后,我们就可以结合数据特点(比如两张表的 Schema 完全一致,但数据内容的范畴不同),来实现最开始的业务需求:计算中签率与倍率之间的量化关系。首先,既然是要量化中签率与倍率之间的关系,我们只需要关注那些中签者(lucky 目录下的数据)的倍率变化就好了。而倍率的计算,要依赖 apply 目录下的摇号数据。因此,要做到仅关注中签者的倍率,我们就必须要使用数据关联这个在数据分析领域中最常见的操作。此外,由于倍率制度自 2016 年才开始推出,所以我们只需要访问 2016 年以后的数据即可。基于以上这些分析,我们先把数据过滤与数据关联的代码写出来,如下所示。
// 过滤2016年以后的中签数据,且仅抽取中签号码carNum字段
val filteredLuckyDogs: DataFrame = luckyDogsDF.filter
(col("batchNum") >= "201601").select("carNum")
// 摇号数据与中签数据做内关联,Join Key为中签号码carNum
val jointDF: DataFrame = applyNumbersDF.join
(filteredLuckyDogs, Seq("carNum"), "inner")在上面的代码中,我们使用 filter 算子对 luckyDogsDF 做过滤,然后使用 select 算子提取 carNum 字段。紧接着,我们在 applyNumbersDF 之上调用 join 算子,从而完成两个 DataFrame 的数据关联。
join 算子有 3 个参数,你可以对照前面代码的第 5 行来理解,这里第一个参数用于指定需要关联的 DataFrame,第二个参数代表 Join Key,也就是依据哪些字段做关联,而第三个参数指定的是关联形式,比如 inner 表示内关联,left 表示左关联,等等。
做完数据关联之后,接下来,我们再来说一说,倍率应该怎么统计。对于倍率这个数值,官方的实现略显粗暴,如果去观察 apply 目录下 2016 年以后各个批次的文件,你就会发现,所谓的倍率,实际上就是申请号码的副本数量。比如说,我的倍率是 8,那么在各个批次的摇号文件中,我的申请号码就会出现 8 次。是不是很粗暴?因此,要统计某个申请号码的倍率,我们只需要统计它在批次文件中出现的次数就可以达到目的。按照批次、申请号码做统计计数,是不是有种熟悉的感觉?没错,这不就是我们之前学过的 Word Count 吗?它本质上其实就是一个分组计数的过程。不过,这一次,咱们不再使用 reduceByKey 这个 RDD 算子了,而是使用 DataFrame 的那套算子来实现,我们先来看代码。
val multipliers: DataFrame = jointDF.groupBy
(col("batchNum"),col("carNum")).agg(count(lit(1)).alias("multiplier"))分组计数
对照代码我给你分析下思路,我们先是用 groupBy 算子来按照摇号批次和申请号码做分组,然后通过 agg 和 count 算子把(batchNum,carNum)出现的次数,作为 carNum 在摇号批次 batchNum 中的倍率,并使用 alias 算子把倍率重命名为“multiplier”。这么说可能有点绕,我们可以通过在 multipliers 之上调用 show 函数,来直观地观察这一步的计算结果。为了方便说明,我用表格的形式来进行示意。