面试整理
转载自:https://blog.csdn.net/qian2213762498/article/details/80480888
项目经历
作为面试官如何 判断一个面试者的机器学习水平
0 机器学习的原理 参考
就比如说性别分类吧,机器学习通过训练数据的特征(比如人的身高体重)和数据的输出变量(如人的性别)来训练一个分类或者回归模型,用这个模型来预测新的数据。
梯度下降和线性回归!!!前者是优化方法(用于nn中后向传播的参数更新)后者是分类方法,用于前向传播得到输出值
0 回归和分类的区别 参考
回归常用来预测一个连续值比如说预测今天我被lamda录取的概率,分类常用来预测一个离散值比如说贴标签。
0 什么是线性回归
在我看来,线性回归相当于一种拟合,他们是构造函数模型来拟合样本数据,在拟合的过程中 他会考虑样本的方差和偏差 。
0 什么是逻辑回归
逻辑回归有点像像线性回归,不过他们俩有区别:
1逻辑回归是非线性的
2 逻辑回归相当于对线性回归的值域压缩到01之间
0 为什么需要激活函数 这里写链接内容
激活函数可以使输出值与输入值变得非线性(不使用激活函数的话深度神经网络实际上和多层感知机就没区别了,全是线性组合)这里写链接内容,可微且单调(当优化方法是基于梯度的时候这个性质就是必须的),同时激活函数还能控制输出值范围,使得基于梯度的优化方法变得更稳定
0 sigmoid 和softmax区别 这里写链接内容
sigmoid将一个一维实值映射到01区间中的一个实值(tanh是-1 1 区间)
softmax将一个k维实值向量映射到01区间的另一个实值向量
0 讲一下逻辑回归(sigmoid)的定义函数(损失函数,梯度下降)参考 参考2必看ng
0 详细讲一下softmax的定义函数(损失函数,雅可比矩阵)
0 你在两篇论文中扮演的角色
第一篇论文是第四作者,那时我刚进入实验室,只参与了一些数据预处理和论文修订工作,并没有参与核心模型设计。
第二篇论文是第三作者,这一阶段我和组内一位博士生(论文的第一作者,第二作者为导师)一起合作研究,由他指导大方向,我来负责实验复现,代码编写。论文中的创新点(多级注意力机制)是我们一起讨论得出的。可以说第二篇论文我是全程参与的。
实际上multi-level attention那篇之前三月试投了coling,但是很多细节都没打磨好(比如一些使用不同语料的对比实验)。coling三个审稿人的意见分别是(2,3,4)(满分是5分),很遗憾最终还是没能用回复改变2分那位审稿人的意见,但是我觉得过程才是重要的,这段经历也让我觉得我更适合科研而不是工作,同时我也发现了平台的重要性,大工的nlp实力确实不强,如果我确定走学术路线,必须去争取进入一个更高层次的平台。
0 什么是凸优化(最优化) 参考 参考2 参考3
凸优化的使用条件: 1 目标函数是凸函数(也就是任意两点连线上的值大于对应自变量处的函数值) 2
变量所属集合是凸集合(也就是任意两个元素连线上的点也在集合中)
凸优化问题中局部最优解就等于全局最优解,凸优化应用到机器学习领域主要是用来调整和更新参数
1. CNN部分
1.1 一般训练模型的数据集分为哪几种
一般训练模型分三个数据集,训练集用来训练模型,更新权重。验证集用来评估模型的性能,看有没有欠拟合或者过拟合。测试集是我们最后要预测的数据集,一般来说是没有标签的。
1.2 对深度学习的理解(CNN卷积,池化)
那我就讲讲我对CNN和RNN的理解吧,首先CNN他有两个最重要的操作:卷积和池化参考
cnn卷积相当于一种压缩信息的实值映射,在图像处理中,他是利用像素点和周围像素的信息与卷积核做内积,用求和后的新值表示这个窗口区域的特征值;在自然语言处理中,是用一个单词和他的线性上下文组成的窗口与卷积核内积然后求和,最终得到一个句子的特征向量。
cnn池化相当于在卷积的基础上进一步压缩信息,使得特征向量更小,更易于处理,常用的有平均池化和最大池化,就是用窗口内的最大值或者平均值代替整个窗口。
1.2.1cnn的局部感知和参数共享
cnn的局部感知是指滤波器根据窗口进行卷积
cnn的参数共享是指窗口权重不变
1.2.2cnn的优点和局限性(和lstm相比,为什么第二篇不用cnn)
优点: 卷积窗口可以实现同时用过去和未来的信息判断当前的信息
局限性: 首先,cnn的卷积窗口不可能太大而且他还是固定的,这样的话在文本的长距离依赖关系中明显不如lstm
2.3 讲讲最熟悉的算法
简单的梯度下降梯度更新
手写Logistic回归
2.5 线性回归对于数据的假设是怎样的 参考
1就是因变量y是多个自变量x之间的线性组合。
2 数据样本点之间独立同分布(也就是随机变量服从同一分布且相互独立)
3 样本点没有测量误差(实际上这是不可能实现的,但是实际中会假设满足这个条件来降低模型复杂度)
2.6 说说你的论文 并行多池化CNN 生物医学事件触发词的识别吧
这篇论文是第四作者,当时刚加入实验室,所以只是做了一些数据预处理和跑跑实验的工作,但是我对论文的模型还是有了解的。
首先论文做的触发词识别是事件抽取的一个子任务,生物医学事件呢主要由触发词和要素组成的,触发词一般是动词或者动名词,他是触发这个事件的词,比如说“蛋白质降低了血液流动性”那这里降低就是一个生物医学事件的触发词,这个事件波及的对象,也就是血液这个词就是要素,要素也可以看成是触发词和实体之间的一种复杂关系。
我们提出的触发词识别的模型的主要特点一个是并行,一个是多池化。
1 首先在输入层,我们用Gdep和Word2vecf得到了基于依存关系的词向量,然后用这个词向量拼接距离向量来表示一个单词,这里的距离向量呢代表了这个单词到句子中的触发词的距离,你像刚才的降低他的距离就是0因为他是触发词。
2 然后在卷积层,我们用了不同大小的卷积窗口来获得句子的特征向量,不同窗口的卷积是并行的。
3 在池化层呢我们把特征向量一分为二,,分的原则是触发词前的特征表示和触发词后的特征表示,然后对这个一分为二的特征向量分别进行池化,相当于一个特征向量得到两个池化值。这里不同窗口得到的特征向量也是并行多池化处理的,最后的结果会被连接在一起送入softmax分类器。
为什么多池化?
因为一个句子里可能有多个生物医学事件,如果仅仅对整个句子求max值,显然会丢失信息,而触发词作为事件的触发因素,以他作分界是合理的
使用的什么优化方法?
adadelta,好处是不用设置学习率,自适应学习
2. LSTM部分
–看过的论文
Attention-Based Bidirectional Long Short-Term Memory Networks for
Relation Classification
2.1 BLSTM是怎么实现的
2.2 去60%的负例是怎么实现的,有什么用
2.3 对深度学习的理解(RNN LSTM) 必看参考 lstm
Rnn呢实际上相当于一种较深层次的神经网络,他是对神经网络展开多个step,每个step会共享同一个神经网络模块,正是由于这种显著的序列性质,rnn在处理自然语言问题的时候有很大的优势。但是,她也有一个明显的缺点:一旦序列过长,可能会引发梯度消失的问题,也就是说(画图)反向传播过程中链式法则的连乘操作会导致梯度越来越小。为了解决这个问题,才有了LSTM,lstm呢有个显著的特征,就是他引入了cell状态和门这两个概念,cell状态由两部分组成:一个是过去的信息,一个是当前的信息,两个信息相加得到cell当前时刻的状态。由于是相加的形式,cell仅仅通过遗忘门决定记忆多少过去的信息,从而解决了长期依赖的问题,同时各个门的输出实际上都是上一时刻cell状态的复合函数,这样反向求导的时候,连乘的没一项变成了连加,就缓解了梯度的消失,当然了,lstm是不能完全解决梯度小时问题的,因为他只是将每一步的求导变成求和,但是链式法则的连乘依然是存在的。
在lstm的基础上也出现了一些变体,比如我们论文中用到的双向lstm,他呢就是对一个句子正向和反向各自处理一遍,这样的话相当于正向过程中利用了过去的也就是前文中的信息,而反向过程中则可以利用未来的也就是后文中的信息来决断当前的信息。
2.4 梯度下降法是什么(lamda詹德川)
2.5 牛顿迭代是什么(lamda詹德川)
2.6 说一下神经网络的优缺点(复旦)
就拿我接触过的lstm吧,它本质上是一种RNN,有很多变种,RNN优缺点,LSTM的改进等等
2.7 实习干了什么,怎么做的,以及复述了一个用于关系抽取的网络模型(对论文项目进行讲解)
使用BLSTM做的模型(注意那个图)
对数据的处理
画网络模型图,从输入层到输出层,隐层,dropout ,用的什么优化函数
2.8 LSTM之父
Jürgen Schmidhuber 尤尔根 施密德胡波
2.9 Attention之父
Attention机制最早是在视觉图像领域提出来的,应该是在九几年思想就提出来了,但是真正火起来应该算是google mind团队的这篇论文《Recurrent Models of Visual Attention》[14],他们在RNN模型上使用了attention机制来进行图像分类。随后,Bahdanau等人在论文《Neural Machine Translation by Jointly Learning to Align and Translate》 [1]中,使用类似attention的机制在机器翻译任务上将翻译和对齐同时进行,他们的工作算是是第一个提出attention机制应用到NLP领域中。
https://blog.csdn.net/yimingsilence/article/details/79208092
https://blog.csdn.net/sparkexpert/article/details/72785304
2.9.1 说说你理解的attention 必看 必看2
attention看起来很高端,实际上他的思想非常简洁,它主要是受到人脑的注意力模型的启发,因为人在观察眼前的事物的时候,只会聚焦到一小部分画面而对其他部分选择性忽视,就比如说摄影吧,为什么单反拍出来的照片比手机拍的更抓人眼球?就是因为单反虚化好,这里虚化就相当于刻意模糊掉画面里次要内容和背景,突出主体(比如说睡觉的小猫咪啊什么的),这就是一种现实中的attention,那么注意力机制应用到文本领域,其实相当于一种文本聚焦模型,基本思想是对文本分配不同的注意力,使得不同的内容对整个文本的贡献各不相同,句子的主干单词会被分配更多的注意力。比如说我们在第二篇论文中使用的一种多级注意力机制,
、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、
attention是受到人脑注意力模型的启发,可以看作是一种资源分配模型,在某个特定时刻,人的注意力总是集中在画面中的某个焦点部分,而对其他部分视而不见。attention应用到文本领域有一个很大的好处,就是他可以针对长文本选择性地关注那些比较重要的单词,比如说“我特别想进入lamda深造”,那么加了注意力机制的神经网络在理解这句话的时候就可能会对“我lamda深造”三个词增加权重,这样的话就相当于抽取了一个句子的主干信息。
最基本的attention是应用在机器翻译的Encoder-Decoder模型,没有引入attention的模型中句子里每个单词对于翻译目标单词的贡献都是一样的,引入attention之后,会更多地关注对句子含义贡献大的单词。
2.10 手写一下你用的attention公式
Attention-Based Bidirectional Long Short-Term Memory Networks for
Relation Classification(这篇论文的注释版再看一遍)
先是tanh激活隐层状态
然后softmax获得att矩阵
然后隐层输出与att矩阵点乘
最后结果tanh激活
配套https://blog.csdn.net/appleml/article/details/78043041
2.11 你论文的motivation是什么
篇章中不仅句内单词有联系,句子之间也是有联系的
2.12 实验细节
如果测试集的正确率比训练集高很多,可能会出现哪些问题参考
1 训练集上过拟合
可以考虑:1.1 人工减少特征维度
1.2 dropout 保持输入输出神经元不变,在前向和后向传播过程中随机删除一些隐藏单元,达到正则化的效果(原因是:减少的隐层单元实际上增加了网络的稀疏性,从而减少了不同特征之间的关联性,因为过拟合他其实根本原因就是特征维度太多了,有些特征之间就会存在很多特定的关联性)
1.3 正则化; 保留所有的特征,通过降低参数θ的值,来影响模型
1.3 引入随机噪音来避免过拟合
2 训练集样本不均匀 比如负例过多,考虑去负例,保持10:1
如果训练集的正确率一直上不去,可能会出现哪些问题 参考
1 训练集欠拟合,特征维度过少,导致拟合的函数无法满足训练集,误差较大。
考虑增加特征维度来解决。
怎么实现的
训练集测试集是如何组成的
损失函数用的什么
用的语料包括那些
2.12.1 说说你的multi-level attention based BLSTM nn for event extraction
这篇论文我是第三作者,我和组里的一位博士生(也就是一作)一起做出的这篇论文,我的主要工作呢是模型搭建和多级注意力的实现。首先,生物医学事件抽取呢分了三个子任务,分别是触发词识别,要素识别和后处理构成事件,这三个过程是串行的,也就是先找出触发词,再找出要素,最后就用触发词和要素构成事件。
我们在触发词识别和要素识别中用了同样的神经网络模型,我们这个模型最主要额特点是 双词向量机制和多级注意力机制:
首先,在输入层,我们使用了两套词向量作为cell的两个输入,其中一套是基于依存关系训练得到的词向量,另一套是随机初始化后跟随网络训练更新,前一个可以看作包含普遍特征信息,后一个可以看作包含了task-specific的信息。
然后在网络层,我们使用了双向lstm,正向的话可以更好地利用过去的信息,反向的话可以更好地利用未来的信息。
然后对于隐层输出,我们使用了多级注意力机制,首先word-level att是对句子里的每个单词分配注意力,然后求得句子的特征向量,之后sentence-level att再对不同的句子向量分配注意力,新的句子表示最后被送到softmax分类器中进行分类。
2.13 遇到过什么问题,怎么解决的?
刚开始准备使用attention的时候,尝试了很多中方法,比如说,曾经尝试过一种固定的attention,就是只给句子中的触发词和要素各分配0.5的权重,其他部分权重为0,也试过以触发词为中心,按照正态分布给上下文分配attention,他们效果都不太理想,最后还是选定了self-attention,他相当于一个可学的随机向量,可以跟随网络训练而自己调整权重
2.14 论文最自豪的点(你这个是以句子为单位的,那你这个第二级注意力是怎么个attention法)
多级注意力机制,,我们这个第二级注意力机制呢,主要是为了同一个batch里(要素候选都是并行处理的嘛),区分出哪些可能是
3.相关
3.1对人工智能的看法 (南大)
虽然人工智能现在是weak
AI,但是在很多领域的应用都已经获得了非常好的经济和社会效益,比如医疗诊断,自动驾驶等等。也许在十年前,我们根本无法想象会有一台叫AlphaGo的机器能在围棋这样一个象征人类智慧的项目中击败最顶尖的人类的,这一切,都要感谢人工智能。因此,我认为人工智能是真正的未来。当然,现阶段AI还远未达到强人工智能的水平,因此,我们现在要做的就是捉紧时间研究人工智能,掌握人工智能,就好比那些在手刨地时代掌握了农具的人一样,将会获得巨大的竞争优势。
3.2machine learning现阶段的问题 (上交)
我从来没有想过这个问题,也承认自己自学的时候有点儿死,没有站在整个领域的角度去看过,只重视一些算法
3.3你最近看了什么论文?发表在什么期刊上?作者是谁?(上交)
3.4 统计某市的下水井盖个数(北大软微,类似的还有估算出租车数量) 参考
一般雨水管道检查井是30m一个,污水井间距大一点。了解城市规模与路网密度的关系,知道了城市的大概面积,可以算出道路的长度,然后可以推算出井盖的总数。
3.5 机器学习了解多少,看过什么(lamda吴建鑫)(优点,局限性)
目前我做的都是深度学习方向的研究,没有怎么系统地看教学视频,都是遇到什么问题解决什么问题这样在实践中学习,比如早期接触神经网络,对xx感觉没掌握要领,就看了西瓜书以及一些blog。。。。。(这里xx可以是贝叶斯或者什么机器学习算法的推导,然后老师可能会顺着这个问你怎么推导贝叶斯,你就能顺着往坑里跳了,记得一定精心准备几个西瓜书的推导
3.6 了不了解本人是做什么研究的(lamda吴建鑫)
导师主页一定要看
3.7 看成绩单,问如何进行文献检索(南大)
选修课也很重要啊,先看看自己选过哪些再重点复习相关的。参考
如果知道文章标题啊,DOI啊(Digital Object Unique
Identifier,即数字对象唯一标识符,通俗一点来讲,DOI就是一篇文献的身份证),作者名和期卷号啊直接上谷歌学术搜就行,如果刚入门的话,早期得先搜一下关键词,然后从结果里找一些引用高的文献读一下(当然越近越好,老古董读起来不太容易理解),如果对某篇文献感兴趣,接着搜一下那篇论文的通讯作者,一般来说都会是个大牛。实际上读完这几篇高引用论文之后,很有可能会发现他们的参考文献中有很多重叠的,那些论文也是必读的。实际上如果仅仅为了入门了解的话,还有个简单方法,搜一下相关综述,可以说非常全的介绍了,我早起就是看的review(笑)。后期深入之后,肯定要跟踪前沿动态,这时候就搜一下之前找到的那些大牛近几年的publication,或则干脆直接关注他们的谷歌学术账户,跟踪他们的进展
3.8 大学什么科目学的比较好(哈工大)
想想挖坑
3.8 做过的项目涉及到的算法有什么(哈工大),写过哪些大的程序设计项目?
课程设计算吗,课程设计的话写过小型编译器,我主要负责的是递归下降语法分析
美赛用过主成分分析和BP神经网络等,实验用过lstm
3.9 逻辑回归和线性回归的区别是什么(软件所)
参考
我认为逻辑回归有点像是对线性回归做了一个值域压缩,将y 的阈值从y∈(+∞,−∞)压缩到(0,1),也就是说两个问题本质上都是一致的,就是模型的拟合(匹配)。 但是分类问题的y值(也称为label), 更离散化一些. 而且, 同一个y值可能对应着一大批的x, 这些x是具有一定范围的。
3.10 有没有联系过其他老师?
联系过复旦的邱锡鹏老师,当时邱老师让我读他的一篇论文,让我做review,那篇论文是关于多任务学习的,那我就讲讲我做review的思路吧,我一般读论文,先是看摘要,然后通读一遍论文,因为我之前没接触过这个东西,所以从他的参考文献中又多读了几篇引用的论文,发现他这个模型实际上是在他自己前几篇论文的基础上做的进一步改进,我就综合他的这几篇论文中提出的模型的演化历史写了review。
3.11 你认为他的论文的主要创新点是什么(也可以说你最近读过什么论文,顺势回答这篇,注意了解一下GAN)
GAN+lstm内部结构微调
3.12 如果实现一个功能有两种方法,第一种是不一定能做出来,比较陌生,需要占用挺多时间的方法,第二种是比较熟悉,但是只能实现所有功能的百分之八十,那你会选择哪种方法?
3.12
一个舞会,头上有白帽子和黑帽子,而且所有人中至少有一顶黑帽子。每个人都能看见除自己之外的所有帽子颜色。如果有人发现自己的帽子是黑的,就在关灯的时候鼓掌。第一次,大家互相看其他人帽子颜色。关灯之后没人鼓掌。第二次,关灯之后还是没人鼓掌。第三次关灯的时候响起了掌声。问场上有多少顶黑帽子?
第一次没有人鼓掌,说明至少两顶帽子,否则只有一定的话那个人看到的其他人都是白帽子,那他自己肯定就知道了自己是黑的。
第二次没人鼓掌,说明至少有三顶帽子,这时候已经知道至少两顶了,假设真的只有两顶的话,每个黑人看到的都应该是一定黑猫,他们肯定就知道自己和另外一个人是黑人
第三次鼓掌 说明就是三顶帽子,也就是每个黑人看到的都是两顶黑帽子
4 美赛
4.1 美赛用了什么
pca主成分分析,pca的原理
bp神经网络 ,bp神经网络的原理
专业课
1. C/C++
1.1 请用英语说一下面向对象和面向过程的区别 参考(南大)
“面向过程”是一种是事件为中心的编程思想。就是分析出解决问题所需的步骤,然后用函数把这写步骤实现,并按顺序调用。
”面向对象“是以“对象”为中心的编程思想。
简单的举个例子(面试中注意举例):汽车发动、汽车到站。汽车启动是一个事件,汽车到站是另一个事件,面向过程编程的过程中我们关心的是事件,而不是汽车本身。针对上述两个事件,形成两个函数,之后依次调用。对于面向对象来说,我们关心的是汽车这类对象,两个事件只是这类对象所具有的行为。而且对于这两个行为的顺序没有强制要求。
面向过程的思维方式是分析综合,面向对象的思维方式是构造。
“Process-oriented” is an event-centric programming idea. Is to analyze the steps required to solve the problem, and then use the function to achieve this write step, and call in order.
“Object-oriented” is an object-centered programming idea.
A simple example: cars start, cars arrive. The car startup is an event, and the car arrival is another event. In the course of process-oriented programming, we care about the event, not the car itself. For the above two events, two functions are formed and then called one after another. For object orientation, we are concerned with objects such as cars. Two events are just the behavior of such objects. And there is no requirement for the order of these two behaviors.
The process-oriented way of thinking is analysis and synthesis, and the object-oriented way of thinking is construction.
1.2 malloc函数申请一个二维数组(CUHK)参考1 参考2
-
//一维数组
-
char * p=(
char *)
malloc(
sizeof(
char)*列数);
-
free(p);
-
//二维数组 使用二级指针
-
char **p;
-
p =(
char**)
malloc(行数*
sizeof(
char*));
-
for(
int i=
0;i<列数;i++)
-
{
-
p[i]=(
char *)
malloc(列数*
sizeof(
char));
-
}
-
for(
int i=
0;i<列数;i++)
free(p[i]);
-
free(p);
-
//二维数组 使用指向数组的指针
-
char (*p)[行数]=(
char(*)[行数])
malloc(
sizeof(
char)*行数*列数);
-
free(p);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
1.3给你一个数组,设计一个既高效又公平的方法随机打乱这个数组(此题和洗牌算法的思想一致)
为了保证公平,每个数只能被选中和移动一次,那么我可以每次随机选一个数移动到最后的位置,然后递归移动前n-1个数
1.4各类变量的内存分配 参考
char 1 字节 short 2字节 int 4字节 long 4字节 long long 8字节float 4字节 double 8字节
内存分配顺序:首先将全局变量和静态本地变量分配在静态存储区,然后将声明的局部变量分配在栈区作用域结束后系统自动收回,最后将动态申请的空间分配在堆区,由程序员手动释放。
1.4.1 全局,静态,局部的区别
全局和局部的区别主要在生存周期和作用域
静态主要是相对自动变量而言,他俩的主要区别是存储位置和初始化,前者存在静态存储区且只初始化一次
1.5 多态和继承 参考
继承:新类从已有类那里得到已有的特性,比如说交通工具这个类中有属性速度,那么汽车这个新类就可以从交通工具中继承这个属性
多态:一个接口,多种方法,在子类中重写父类的虚函数,当用父类指针调用这个虚函数的时候实际上调用的是重写后的函数
2. 数据结构与常用算法
2.1 用O(n)复杂度找到一组数中出现次数最多的数字和这组数的中位数 (CUHK)参考1
设数A出现次数超过一半。每次删除两个不同的数,在剩余的数中,数A出现的次数仍超过一半。通过重复这个过程,求出最后的结果(复杂度呢??)
2.1.2 找出一个数组中出现次数超过一半的数(北大软微) 参考
基本思路见链接
2.2“栈”的实现(用数组和链表怎么实现)(上科大)参考
先谈谈栈的最重要特点:先入后出,其次他包含两种必要操作:入栈顶和栈顶出栈
数组实现的思想很简单。利用一个变量count来记录栈顶下标,通过改变栈下标值来模拟出入栈。
链表实现依靠表头指针作为栈顶指针,采用头插法插入和删除操作。
2.3矩阵相乘的时间复杂度 (上科大)参考
如果用朴素的算法,mxn的矩阵和nxk的矩阵相乘的运算量是O(mnk),原因是,计算结果是一个m*k矩阵,这说明至少需要进行m*k次运算,而每次运算还要进行n次的求和运算(左边的每一行*右边的每一列)
当然,如果用并行计算的话,比如python里的tensor.dot函数替代for循环,时间复杂度会大大降低
2.4什么是NP难问题(浙大)
2.5 逆波兰(南大)
2.6 快排复杂度是多少,并且黑板上手写证明。(lamda俞杨,其他的排序复杂度也要会)参考
快排可以看作一种递归树他的的时间复杂度是O(nlogn),证明主要从以下三点
1
当递归树趋于平衡时也就是快排的最好情况,复杂度与树高有关,经过子问题划分为复杂度相等的两个子序列,由不等式推断可得O(nlogn)
2
当递归树极端不平衡(如原有数据就是正序或者逆序的),每次划分后只得到一个序列(另一个序列为空),由不等式推断得O(n^2)
3
平均情况下设枢轴的关键字应该在第k的位置(1≤k≤n),那么(具体见算法笔记里夹得纸)

2.7 简述如何“快速选到第n个数”(快速选择,复杂度为O(n))(lamda俞杨)参考
当数据量少,可以直接装进数组的话,可以采用类似快排的思想,每一步都是把大于某值的数放在一边,小于某值的放在另一边,如果大数区间容量大于n,就在大数区间继续划分直到大数区间容量为n,否则在小数区间划分,直到小数区间的大数区容量为n-k;时间复杂度为O(n)
类似的还有快速选到最大的n个数//快速选到中位数(也就是第n/2大的数)
当数据量太多不能用数组存储,就建一个小顶堆,新元素比堆顶大就插入,当插入次数为n堆顶就是所求。建堆O(m),插入O(logm),假设一共m个数,则O(m+n*logm)
2.7 解释一下什么是时间复杂度(南大)参考
时间复杂度实际上以一种度量,并不是真正意义上的算法运行时间,相当于给你一把尺子去量一下这个算法的耗时他主要是为了描述,时间复杂度的关注点是算法中基本操作的重复次数,根据这个次数来估计算法耗时。同时为了简化问题,时间复杂度只考虑了最高项的阶数,因为问题规模足够大时其他项的贡献可以忽略。
2.8 B树是什么?主要作用是什么? (哈工大)
B树是一种平衡的多叉树,它最初启发于二叉查找树,因为二叉查找树呢有个缺点,就是数据一多,他的深度就比较高,而你每查找一次节点就相当于访问一次磁盘,这样的话就会降低速度,B树的根本思想就是在一个节点上存更多的索引信息,也就是改二叉为多叉,减少查找时的io操作.
3. 操作系统(重要)
3.1什么是虚拟内存(上科大)
3.2 操作系统线程跟进程的区别 (lamda) 参考
1 线程可以看作是一个轻量级的进程,两者的主要区别是:线程是CPU调度和分派的基本单位,而进程是系统资源分配的基本单位。
2 引入线程的目的是为了提高系统的并发性,这是因为,同一进程内的不同线程切换不会引起进程切换,从而避免系统调用,减少了系统开销。
3 进程和线程的关系有个很好的例子:比如把咱们面试过程看成一个进程,那么老师要做的是提出问题,我要做的是听问题,思考问题,如果仅仅有进程,那么这三件事必须一件件完成,也就是老师在提出问题时,我不能同时进行思考,线程就是为了解决这个问题,进程中的每个事件分配一个线程,这些线程可以并发执行,从而提高。
4. 数据库
4.1几个范式是什么(浙大) 参考
1NF: 字段是最小的的单元不可再分
2NF:满足1NF,表中的字段必须完全依赖于全部主键而非部分主键 (一般我们都会做到)
3NF:满足2NF,非主键外的所有字段必须互不依赖
4NF:满足3NF,消除表中的多值依赖
4.2 关系模式和关系
你可以理解为数据表。“关系模式”和“关系”的区别,类似于面向对象程序设计中”类“与”对象“的区别。”关系“是”关系模式“的一个实例,你可以把”关系”理解为一张带数据的表,而“关系模式”是这张数据表的表结构
4.3数据库增删改查
5. 计算机网络
6. 计算机组成原理
7. 编译原理
7.1 做过什么大型的代码项目?
写过小型编译器,我主要做词法分析和递归下降语法分析
7.1.1 递归下降语法分析和lr分析的区别
8.软件工程
8.1 软件错误怎么找啊 参考
软件错误有好多种,而且在整个软件开发周期中可能会扩散,不过一般来说边界值是最容易出错的,其次还可以通过追踪一条数据的完整流程来判断错误,还不行那就随机测试了(笑,靠天吃饭
8.2 软件测试的内容 参考
软件测试主要有两点:一个是验证verification,一个是确认validation
验证的话就是说你软件是不是正确地实现了这个功能,也就是do it right
确认的话就是说你软件实现的这个功能是不是正确的,也就是do the right thing
8.3软件包括那些
软件的话不仅仅包括程序,还应该有相应的文档
简单点说就是 程序+文档
9 开放性问题
9.1 证明一个有m个元素的数列a(全是整数),让你证明存在i<=j使得(ai+….+aj) mod m = 0.
反证法,假设不存在,那么任意一个数mod m都不等于零,ai mod m 只能有m-1种可能(也就是ai只能有m-1种可能),ai +ai-1 mod m也不会等于零,则ai-1 只能由m-2种(因为ai有m-1种而ai-1 mod m也不能等于0相当于又减少了一种) 依次类推,a1只能有零种,矛盾
数学课
1. 线性代数(重要)
1.0 什么是行列式 参考
行列式是一个函数,它可以将方阵(注意只有方阵才有行列式)映射到一个实值,他等于矩阵特征值的乘积,也就是说,他的大小可以衡量矩阵变换后空间扩大或者缩小的情况。比如:如果行列式为0那么说明空间至少沿着某一维完全收缩了,使其失去了所有体积,行列式为1则说明矩阵变换没有改变空间体积
1.0.1 矩阵转置 矩阵的逆
以对角线为轴的镜像,手面朝向自己表示原矩阵,先翻过手背,再逆时针旋转90°得到矩阵转置
方阵A和方阵A的逆
1.0.2矩阵乘积和点乘
矩阵乘法A*B是A(m*n)的行向量与B(n*m)的列向量的每一项对应相乘后求和,A的列数必须和B的行数保持一致
点乘可以用矩阵乘法表示 A点乘B = AT*B
1.0.3 正交矩阵
矩阵的转置和矩阵的乘积=单位阵,那么这个矩阵就是正交矩阵,他的列向量组一定是标准正交向量组
1.1 特征值、特征向量的求法、意义(上科大) 参考
物理意义:首先,矩阵可以看作是一种线性变换也可以看做一种空间图像,那么矩阵乘法就可以看作是一种图像在方向和长度上的变换,我们说某个矩阵的特征向量可以看做一种特征图像,这种特殊图像经过这个矩阵所定义的运动变换之后得到的新图像相比原来的特征图像只发生了伸缩变化而没有发生旋转变换,伸缩的比例呢就是他的特征值。
求法:通过一个等式来求特征值 |兰姆达E - A|=0 求出特征值之后通过等式 兰姆达x = A x求出对应的特征向量x
1.1.2 特征分解 参考
矩阵分解为由其特征值和特征向量表示的矩阵之积的方法
如果矩阵的特征值全都不同,那么他的所有特征向量都是线性无关且正交的,那么矩阵A就可以被对角化,这个过程就是特征分解 A=VΛV−1 其中 V=[x1,x2,⋯,xn]V=[x1,x2,⋯,xn] , Λ=Diag(λ1,λ2,⋯,λn)Λ=Diag(λ1,λ2,⋯,λn) 。
PCA的本质就是协方差矩阵的对角化nono 奇异值分解
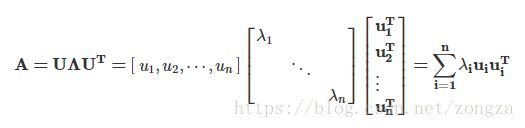
1.1.3 什么是矩阵的对角化
按照我的理解,矩阵对角化实际上就是一个特征分解的过程,如果一个方阵的特征值全都不相同,那么这个方阵就能相似于由特征值组成的对角矩阵,他们之间的相似变换矩阵p和p-1就是由特征向量组成的
1.1.4 什么是奇异值分解? 参考 详细
奇异值分解有点像特征分解的推广版本,因为特征分解只是针对方阵的嘛,非方阵想进行矩阵分解的话就可以通过奇异值代替
1.2 矩阵的秩(上科大) 参考
物理意义: 之前说过了,矩阵可以看做是一种图像也可以看作是一种线性变换,那么按照我的理解,一个矩阵的秩相当于别的图像经过这个矩阵定义的线性变换后得到的图像的空间维度
1 比如说变换矩阵【【0,0】【0,0】】无论什么样的图像,进过这种变换之后都被压缩成一个点,所以这个矩阵的秩就是0
2 再比如说变换矩阵【【1,-1】【1,-1】】他的两个列向量是在一条直线上的,因此无论什么图像,经过变换后都会被压缩成一条直线,那么这个矩阵的秩就是1
3 再比如变换矩阵【【1,-1】【1,1】【1,2】】他的两个列向量在三维空间中确定了一个平面,其它图像经过这种变换后的图像一定属于这个平面,因此他的秩是2
1.3 什么是线性相关(lamda)什么是线性表示 参考1 参考2
线性相关是判断一组向量是否可以通过适当的线性组合表示成一个零向量. 线性组合中至少有一个非零因子
线性表示是判断一组向量是否可以通过适当的线性组合表示另外一个向量. 线性组合中可以全是零
OR
线性相关是判断一组向量中任意一个向量都不能表示成其他向量的线性组合
1.4 什么是正则化
正则的本质是对要优化的参数进行约束,在机器学习中这个参数就是一种特征,通过限制这个特征的数量级来避免过拟合。
2. 高等数学
2.0 零点存在定理
函数在a-b的闭区间连续 ,且f(a)*f(b)<0那么开区间(a,b)之间一定存在零点 ξ
2.0 函数连续的定义
函数连续有三个条件,一个是在该点有定义,一个是在该点有极限,并且这个极限的值等于该点的函数值
2.1 你说你数学比较好,那说一下函数零点怎么求
当时只说了个二分法,其实牛顿迭代,遗传算法(这个没看懂)都可以啊
牛顿迭代:他的原理是用泰勒公式的一阶展开这条直线近似模拟曲线,然后不断地迭代更新这条直线,一直更新到用于模拟的那条直线的根收敛于实际曲线的根 参考 参考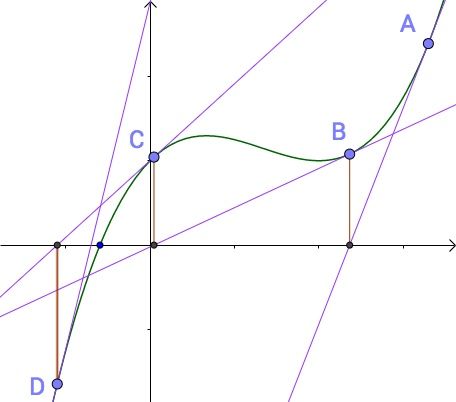
遗传算法:没看懂
2.1.2 函数极值点怎么求(也就是导数为0的点,也就是最优化问题)
求函数极值可以看作是求导数为0的点,因此可以用牛顿二阶迭代来求零点,他原理是利用泰勒公式的二阶展开,求展开后的零点,然后不断地更新迭代。一般来说牛顿法比梯度下降更快,因为后者是一阶收敛,前者二阶收敛,二阶相当于考虑了梯度的梯度,也就是说,牛顿法在判断那个方向梯度最大的同时还会考虑走了这个方向之后梯度是否会变得更大,因此更好地利用了全局信息,所以相对更快 参考1 参考
参考
梯度下降:每次选梯度反方向走一步(也就是下降最快的方向),这个方法有个缺点就是,步长如果太长,可能会在最优值附近徘徊,步长太小,前进就太慢 参考
梯度下降:梯度下降就是上面的推导,要留意,在梯度下降中,对于θ的更新,所有的样本都有贡献,也就是参与调整θ.其计算得到的是一个标准梯度。因而理论上来说一次更新的幅度是比较大的。如果样本不多的情况下,当然是这样收敛的速度会更快啦~
随机梯度下降:可以看到多了随机两个字,随机也就是说用样本中的一个例子来近似所有的样本,来调整θ,因而随机梯度下降是会带来一定的问题,因为计算得到的并不是准确的一个梯度,容易陷入到局部最优解中
批量梯度下降:其实批量的梯度下降就是一种折中的方法,他用了一些小样本来近似全部的,其本质就是随机指定一个例子替代样本不太准,那我用个30个50个样本那比随机的要准不少了吧,而且批量的话还是非常可以反映样本的一个分布情况的。
2.1.3手写logistics回归和梯度下降公式
2.1.4为什么优化时选择梯度方向,梯度方向为什么是变化最快的方向?
因为梯度方向下降最快,为什么最快呢,因为你把函数进行泰勒展开,f(x0+dx) =f(x0)+f ‘ (x0)dx +。。。,那么f(x0+dx)-f(x0)约等于f ‘ (x0)dx 当dx=f ‘ (x0)时两者差值最大,类似的多元函数中的dx就是他的梯度
2.2 什么是导数,什么是微分,什么是积分 参考
导数就是函数在这一点变化率
微分是函数导数乘以自变量的增量,他是因变量的增量的线性主部,▲y=dy+o(▲x)
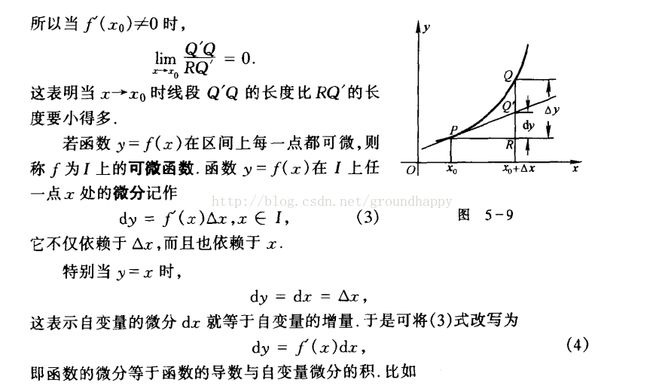
导数和微分的区别。
当自变量x发生一个极小的偏移deta x 后 变化了相对于原y值的一个增量deta y
导数指的是 deta y/ deta x的值,表示的是斜率
微分指的是 deta y的线性主部 参看图5-9
积分
定积分是某种特殊合式的极限
不定积分是某个函数f(x)的原函数的集合
2.3什么是链式法则
链式法则是用来求复合函数的导数,也就是偏导数的。比如说y是x的函数 z是y的函数那么dz/dx =dz/dy * dy/dx
再比如 u v是x y的函数,f是u v的函数,那么df/dx=df/du*du/dx + df/dv*dv/dx
3. 概率论(重要) 机器学习中的概率论1 2
3.1 什么是大数定律(LAMDA)先通俗讲再举例
大数定律通俗一点来讲,就是样本数量很大的时候,样本均值和数学期望充分接近,也就是说当我们大量重复某一相同的实验的时候,其最后的实验结果可能会稳定在某一数值附近。就像抛硬币一样,当我们不断地抛,抛个上千次,甚至上万次,我们会发现,正面或者反面向上的次数都会接近一半,也就是这上万次的样本均值会越来越接近50%这个真实均值,随机事件的频率近似于它的概率。
3.1.2什么是中心极限定理 参考
中心极限定理是说当样本数量无穷大的时候,样本均值的分布呈现正态分布(边说边比划正态曲线)
大数定律和中心极限定理的区别:
前者更关注的是样本均值,后者关注的是样本均值的分布,比如说掷色子吧,假设一轮掷色子n次,重复了m轮,当n足够大,大数定律指出这n次的均值等于随机变量的数学期望,而中心极限定理指出这m轮的均值分布符合围绕数学期望的正态分布
3.2 全概率公式与贝叶斯公式 参考
全概率是用原因推结果,贝叶斯是用结果推原因
++++++++++++++++++++++++++++++++++++++++
全概率:P(A)=P(B1)P(A|B1)+P(B2)P(A|B2)+P(B3)P(A|B3)+⋯
把Bi看作是事件A发生的一种“可能途径”,P(A|B1)则是通过这种途径得到A的可能性,而途径的选择是随机的,因此可以把P(A)看作不同途径概率的和
村庄 小偷
+++++++++++++++++++++++++++++++++++++++++
贝叶斯 利用贝叶斯定理,我们可以通过条件概率P(Y|X)P(Y|X)计算出P(X|Y)P(X|Y),从某种意义上说,就是“交换”条件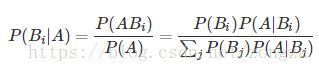
这里贝叶斯可以看作求某种途径占所有途径的比例
+++++++++++++++++++++++++++++++++++++++++
贝叶斯用在机器学习中:
比如性别分类,在身高体重等因素已知的情况下判断男性或者女性,这里假设身高体重都是正态分布,这样就可以根据u和σ2求出来某一性别下他的身高=xx的概率大小也就是条件概率继而求出P(性别|身高,体重)
P(性别|身高,体重)=p(身高|性别) * p(体重|性别) / ∑ P(身高,体重|性别) 分母是常数
3.2.2 链式法则
P(X1,X2,…,Xn)=P(X1)P(X2|X1)…P(Xn|X1,X2,…,Xn−1)…………
链式法则通常用于计算多个随机变量的联合概率,特别是在变量之间相互为(条件)独立时会非常有用。注意,在使用链式法则时,我们可以选择展开随机变量的顺序;选择正确的顺序通常可以让概率的计算变得更加简单。
3.2.3 什么是概率分布
概率分布是描述一个随机变量的不同取值范围及其概率的函数,函数中有一些参数可以调整这一分布的范围和取值概率,有了这个函数,就可以计算n次实验后某事件发生的概率。
3.2.4 连续和离散分布
离散分布:随机变量只在一些有限的位置取值,例如抛硬币,他的期望可以通过直接累积相加得到也就是ΣxP(x)
连续分布:随机变量的取值是连续且无穷的,例如01之间任取一个数,他的期望可以通过积分求得也就是∫xP(x)dx
3.2.5说一下正态分布
正态分布又称高斯分布,他是连续型随机变量的分布,它主要由两个参数u和σ^2,也就是期望和方差,遵从正态分布的随机变量满足这样一个规律:取值离u越近的概率越大,同时σ描述了分布的胖瘦,他越大,曲线越矮胖,越小,曲线越高瘦。
3.2.6 说一下t分布
t分布主要针对正态分布且方差未知的总体,如果你的样本很少而你还相求均值的时候就得用t分布
3.3 方差相关(lamda吴建鑫)
0 概念
概率论中方差用来度量随机变量和其数学期望(即均值)之间的偏离程度。统计中的方差(样本方差)是每个样本值与全体样本值的平均数之差的平方值的平均数
1 方差的计算方法,他会提前写好一个方差表达式问你对不对,如果不对的话请写出正确的表达式;
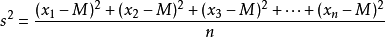
注意点1 实际上n应为n-1
注意点2 M和u的区别,前者是所有样本xi的均值后者是随机变量X的数学期望,前者分母n-1后者n
2 方差中n-1的含义参考
是为了保证计算出来的方差没有偏差。实际上将Xi-X拔扩展为Xi-u+(u-X拔)之后可得到除以n所得到的方差始终小于真正的方差,偏差的大小是1/n *真实方差的平方,为了去掉这个偏差才最终变为n-1
3 如果写一个程序计算方差,那么计算一次内存访问几次
这里就不考虑缺页了,假设数据全都在一页中且页已经调入内存
首先求样本均值需要一个for循环n次
其次计算方差也需要一个for循环求差值,差值的平方,差值的平方的和
所以一共2n次。
3.3.2 协方差与相关系数
它可以用来度量两个随机变量的相关性
Cov(X,Y)=E((X−E(X))(Y−E(Y)))
3.3.3 独立和不相关 方差与相关系数
相关描述的是随机变量之间线性相关而方差或者说独立性描述的是值相关,所以随机变量之间独立则一定不相关但是不相关不一定独立(不如可能存在非线性函数使得两个随机变量能满足该函数提供的映射)
3.4极大似然估计与机器学习随机梯度下降算法
3.10 什么是事件的独立性
某一事件发生的概率完全不受到其他事件的影响,用公式表示就是P(A,B)=P(A)*P(B)
3.11设么是随机变量
随机变量并不是一个真的变量,它更像是将样本空间的结果映射到真值的函数,让我们可以将事件空间的形式概念抽象出来
3.12 什么是数学期望
随机变量的均值(不同于样本均值),大数定律指出如果样本足够的话,样本均值才会无限接近期望
3.13 什么是马尔科夫链?参考
马尔可夫链描述了随机变量的一个状态序列,在这个状态序列里未来信息只与当前信息有关,而与过去的信息无关。他有两个很重要的假设:
1 t+1时刻的状态的概率分布只与t时刻有关
2 t到t+1的状态转移与t值无关
一个马尔可夫模型可以看作是状态空间(也就是所有可能状态)+状态转移矩阵(也就是一个条件概率分布)+ 初始概率分布(就是初始化状态)
3.4有一苹果,两个人抛硬币来决定谁吃这个苹果,先抛到正面者吃。问先抛这吃到苹果的概率是多少?
第一次抛硬币后两人的先后顺序就确定了,假设A先于B,那么A只能在1357.。。等奇数次抛硬币,现在我们吧问题分成两个部分,实际上第三次以后赢和第一次以后赢他面临的处境一样,他在第一次赢的概率是1/2,在第三次以后赢的概率是1/2*1/2*p,所以有p=1/2+1/4*p,解出来的p就是先抛赢的概率
当然也可以用等比数列求,第一次+第三次+。。。。加到最后0
3.5一副扑克牌54张,现分成3等份每份18张,问大小王出现在同一份中的概率是多少?
先求总的分配方案:M=(C54取18)(C36取18)(C18取18)种分法
再求大小王在一份的分配方案:N=(C3取1)(C52取16)(C36取18)*(C18取18)种
3.6一条长度为l的线段,随机在其上选2个点,将线段分为3段,问这3个子段能组成一个三角形的概率是多少?
运用线性规划的思想,假设l被分成x,y-x,l-y的三个线段,期中y>x,l>y,利用三角形两边之和大于第三边可以得到三个方程组,画图求解
3.7你有两个罐子以及50个红色弹球和50个蓝色弹球,随机选出一个罐子然后从里面随机选出一个弹球,怎么给出红色弹球最大的选中机会?在你的计划里,得到红球的几率是多少?
在一个罐子中抽到红球的最大概率是1,也就是罐子里全都是红球,而另一个罐子里是剩余红球和全部的篮球,能得到当罐子一的红球越少,罐子二中的红球所占的比例就越大,抽中的概率也就越大,所以最好的分配方案是一个罐子有一个红球,另一个罐子有49红50蓝,这样总概率是1/2*1+1/2*(49/99)
3.8给你一个骰子,你扔到几,机器将会给你相应的金钱。比如,你扔到6,机器会返回你6块钱,你扔到1,机器会返回你1块钱。请问,你愿意最多花多少钱玩一次?
就是求一下数学期望,因为假设你玩无穷次,根据大数定律,实际上你的收益就是随机变量的数学期望,他等于1*1/6+2*1/6+…=3.5,你不能花比这更多的钱,否则会赔本
3.9有一对夫妇,先后生了两个孩子,其中一个孩子是女孩,问另一个孩子是男孩的概率是多大?
答案是2/3.两个孩子的性别有以下四种可能:(男男)(男女)(女男)(女女),其中一个是女孩,就排除了(男男),还剩三种情况。其中另一个是男孩的占了两种,2/3. 之所以答案不是1/2是因为女孩到底是第一个生的还是第二个生的是不确定的。
X是随机变量,X在[0,1]之间,E[X]=u,1>c,请证明P(X < cu)<=(1-u)/(1-cu)
缺少
两个正太分布相加是不是正太分布
4. 离散数学
4.1全序,偏序
偏序只对部分元素成立关系R,全序对集合中任意两个元素都有关系R。
例如:
集合的包含关系就是半序,也就是偏序,因为两个集合可以互不包含;
而实数中的大小关系是全序,两个实数必有一个大于等于另一个;
又如:复数中的大小就是半序,虚数不能比较大小。
英语
1英文是让我介绍最喜欢的歌曲(南大)
2 英文介绍自己的家乡(浙大)
3 英语自我介绍(lamda詹德川)
4 英语介绍做过的项目(lamda詹德川)
5 英语介绍一下梯度下降法是什么,什么是特征值,特征值的含义,牛顿迭代是什么(lamda詹德川)
面经
LAMDA
1 东北大学学姐:给一篇文章,一分钟的时间看Abstract,然后讲述文章的大意 链接
把俞扬老师给的论文讲一遍,PPT展示
面试的人有大概10个左右,除了俞扬老师,其他都是他实验室的学生
俞扬老师没怎么问问题,就问了一个“ε-greedy”算法中ε取值的问题
他的学生,按照简历中的问题提问,看我自学了斯坦福机器学习的课程,就问了一些情况,然后问我现在在学校实验室从事什么工作,有哪些成果了。
*LAMDA的面试不是说问题都回答出来的就好了。个人觉得,首先通过论文讲解看你的理解能力,能够理解到什么程度。然后之后的面试提问是了解你目前的学术背景。面试只是能否被录取的冰山一角,其实你的简历,你的学术经历,你的成绩,你的思维方式,你的态度等等都是考核内容。反正就把真实的自己展示出来就好,录取了说明你适合这个实验室,没有被录取只能说明你不合适,而不是不够优秀,带着这样坦然的心态表现自己一定能被录取到一个最适合你的地方!
面试的步骤
-
英文能力:有很多种类型,有英文介绍的,也有翻译论文的(英译中),我抽到的是论文翻译。没有上下文,只有一句话,表面意思能看懂,但是翻译超奇怪,然后我就说,这个我翻译不好。
-
专业知识:因为我是机器学习方向的,所以问了一个“大数定理”,然而早就全忘记,我说老师我没学过,现在想想老师心里一定是懵逼的……然后问了一个“有监督学习”的问题,给了一个医院化验的背景,问我如何用神经网络求解,训练集怎么设置,最后结果怎么分析。这个答得还是可以,毕竟还是学过一些。最后问了一下对“人工智能”的看法,其实之前从来没有想过这个问题,但是面试前去和一个老师交流了一下,正好那个老师提出了他对AI的看法,于是我就套用咯,我说现在人工智能是weak AI,balabala……
-
科研经历:问了一下在学校里做了什么工作了。
面试的气氛相当融洽,说说笑笑。最后面试得了一个“优秀学生奖”。但是没有被预录取,因为机试得了0分……
2 东北大学学长
3 某学长
6月9日
6点到南京南,3号线转2号线到了定的宾馆,爸妈都去了,然后吃了个饭就回房间准备去了,这天看到夜里一点,准备了很多关于自我介绍和项目经历的表述,还头痛万一有三个老师要我去面试怎么办(笑)
6月10日 早上下暴雨,鞋子都湿透了到了计算机系楼,先进了左边的软件楼 发现只有五层,然后又下去问,才知道要走另外一边(笑)
八点五十在921集合,gw老师简单地说了两句,大概流程是:
上午分三个组,每组三个老师依次考察每一位学生,只是考察一些基础方面的问题,比如会问些概率论和线代的知识,什么线性相关,矩阵的秩,还问了简单的排序复杂度之类的东西,总之就是考察专业背景嘛
除此之外就是自我介绍,然后贴着简历问,建议就是找到自己的特长点吧,要有发散性思维,如果问你一个开放问题自己要能有想到一个说服力强的解的能力。
下午就是去自己填报的导师志愿那里面试啦,只有一个老师给了我机会,报的话三个志愿要确定好顺序,(第一志愿可以不填周大牛,据说没填他的也有机会收到他的面试通知)可以节约一个第一志愿,反正基本都是第一志愿的老师会给你机会,剩下两个志愿基本没用(笑
下午的面试就是根老师相关的了,我因为之前和老师在WX上聊过,所以就走了个过场,大致聊聊lamda招生情况,自己对于科研的看法,自己的读博意愿,就结束了。
总的来说lamda的老师都很和蔼可亲,只要自己硬实力到了就不会被淘汰吧,我自己觉得几项硬实力的顺序这样的
超级含金量比赛(acm之类的,我不知道应该是什么牌比较厉害,反正去面试的时候听说有金牌)
成绩(985往上,弱校得专业第一吧,强校前几名?)和国奖类的奖学金 英语(6级500来分就够了吧)
相关背景的项目经历和论文什么的(老师也都明白本科捣鼓不出什么厉害玩意。。) 各种水比赛,校级的就别写了,实在拿不出手(笑)
(仅仅是我个人的排名,不代表任何一位老师的看法,可能越缺什么就越觉得什么厉害吧。。)
whu学姐
lamda
上午是集体面试,下午是单独面试(填的志愿上录了你的那位老师)。
集体面试有三位老师,一般围绕简历上的项目展开问、了解的机器学习算法展开问、一些数学问题。面我的三位老师有两位是不认识的,剩下一位甚是年轻活泼,出了实验室才意识到是吴建鑫老师,和他的影响因子比起来真是让人惊讶(对他好感max嘤)。了解到的问题有:
自我介绍(我是用的英文,结果导致老师们对我印象比较深…?)
贝叶斯公式(我说了最基本的公式P(A|B)=P(A)P(B|A)P(B)^(-1),接下来的对话连老师的问题都没有听懂……还说我竟然会用分式形式写他们都没见过…)
方差的计算公式(两种),分别访问内存几次 岭回归(我在动机说明里提到的,然而根本没有详细了解过啊摔!直接说不记得了,答出英文名字ridge
regression挽尊。。)
在美赛中得的奖(英文),听了半天才听懂问的award,答meritorious(幸亏无聊的时候还百度了下这个单词的发音)
矩阵对角化、凸优化、逻辑回归、求函数的零点的方法(二分法、牛顿迭代、坐标下降(上升)法……)
下午的面试,每个老师好像只会面五个人左右,基本不会再问专业性问题,聊聊天……和西北大学的同学谈了西安的城市问题、中国国情、大学生活、人生规划blah……
后来听说lamda的筛人很玄学,不要在简历里装逼过度……本来以为面试会很轻松,结果面试前的心脏跳得飞起,紧张到不行。多面试壮壮胆果然是很有必要的。
6/256东大学长
LAMDA面试
第一次来南京就下起了暴雨,早上来学校的时候路上都快被淹了。今天见到了好多学校的大佬,见到了周老师,面了两场试。
趁着还没忘,记录一下面试的过程吧。
lamda单独招生,四五月份就开始报名了。今年是和夏令营分开的,但是过了lamda的面试,还需要拿到南大招生办的面试才可以进这个实验室。最开始报名的时候要求填报三位老师志愿(填上服从调剂,我当时忘写了)。你能否来面试都看这三位老师有没有兴趣面试你。
今年第一批面试的人不多,三十多个,差不多每个老师面试3-5人。如果志愿中的多个老师对你感兴趣,你就能有多次面试资格了。来了以后发现各种牛人报周志华老师,但是最后选了九个给了面试资格,是其他老师的2倍。
这次面试分上午和下午。上午的面试有三个老师,基本就是自我介绍加上随便问点简历上的问题,时间不长,也就十来分钟吧,感觉这个面试只是让同学们熟悉熟悉,找找面试感觉。下午的面试就是报的老师单独面了。好像其他有老师会带着他的研究生一块面试学生。下午的面试才重要,如果老师要你了,只要以后的机试没太大问题,基本就能进lamda了。面试完之后大家如果觉得不够满意,可以在所有面试结束后进去再跟老师聊聊或者换个老师霸面(这需要挺大的勇气的,所以报三个老师志愿的时候最好了解一下他们的研究方向,根据自己的水平报志愿),我想找其他老师聊的时候很多办公室已经锁门了所以有点晚了。
下面是面试的问题:
上午面试:先自我介绍,然后问,你说你数学比较好,那说一下函数零点怎么求吧。当时只说了个二分法,其实牛顿迭代,遗传算法都可以啊,唉当时没想起来。然后另一个老师问了逻辑回归的函数表达式和如何用梯度下降法优化。十来分钟,所以上午的不是很重要。
下午面试:我报了M.Li老师,面了我一个小时。
首先自我介绍,然后问我美赛数学建模的论文,然后五分钟读一篇英文论文让我描述论文的大概意思(是关于他的研究方向的,大概是用神经网络定位编程中的逻辑错误),我没大看懂,硬着头皮说了几句,后来就又问了软件错误如何找到啊软件测试的内容啊什么的,都是关于他研究方向的。但是我回答的一般,不过看他也比较满意。还问了大学碰到的印象比较深的问题,是如何解决的。之后问了个问题:如果实现一个功能有两种方法,第一种是不一定能做出来,比较陌生,需要占用挺多时间的方法,第二种是比较熟悉,但是只能实现所有功能的百分之八十,那你会选择哪种方法? 后来问了我一个逻辑题:一个舞会,头上有白帽子和黑帽子,而且所有人中至少有一顶黑帽子。每个人都能看见除自己之外的所有帽子颜色。如果有人发现自己的帽子是黑的,就在关灯的时候鼓掌。第一次,大家互相看其他人帽子颜色。关灯之后没人鼓掌。第二次,关灯之后还是没人鼓掌。第三次关灯的时候响起了掌声。问场上有多少顶黑帽子。这个问题我分析了一下说了三顶,又跟老师说明了思考过程。最后问我很多同学有清北情节,如果给你offer你还会参加其他学校夏令营吗?我说我还想报名清华北大的面试。然后他问如果被清华北大录取了你会选择这里吗?我当时就如实说了我的想法,如果清华北大稍微差一点的学院录取我,我也想选择清北。说完之后面试就结束了。
上交
2东北大学学姐:上交
面试一共氛围3个环节:
第一环节:中文介绍自己
第二环节:英文陈述研究兴趣
第三环节:问问题
中文自我介绍很快,1分钟左右,然后我就开始英文陈述了,但是!还没等我说完呢,大boss就打断我,用极其流利的英语(瞬间觉得自己的英语优势没有了)问我“你认为machine learning现阶段的问题是什么?”从来没有想过,回答不上来,很诚实地说“我从来没有想过这个问题,也承认自己自学的时候有点儿死,没有站在整个领域的角度去看过,只重视一些算法”。然后boss又问我,觉得自己的motivation是什么,在团队中有什么优势,我就胡乱说了一通,他还让我举例子,我支支吾吾举不出例子来,他就打断我说”算了算了,下一个问题吧“(当时就想,嗯,完蛋了)。还问我报清华没,如果清华和交大都招你,你去哪儿。我说我来交大,他说不可能,我说我是南方人,更加偏爱上海这座城市。然后旁边的年轻老师听我一直在强调自己看了一些papers(真是自己给自己挖坑),就问我,你最近看了什么论文?发表在什么期刊上?作者是谁?这……我说我并没有注意过发在什么期刊上,然后转移话题说,我刚看了谷歌deepmind实验室发表的强化学习的论文,关于DQN的,感觉很有趣。(多亏南京大学俞扬老师面试的时候让我们看了deepmind的论文,那次真的查了很多资料来弄懂)然后面试就结束了。
浙大
3 东北大学学姐 浙大
面试的流程如下:
-
读两份英文论文,然后进去之后用英语回答老师关于论文的问题;
-
用英语回答一些开放性问题,我被要求介绍自己的家乡。
-
用中文回答专业问题。第一个问题就把我难倒了……让我说说什么是NP难问题,我真不知道……乱说一通,然后老师给我举了例子,让我解决一下这个NP难问题,当时脑子里想的是,NP难,那应该很难吧,能解决吗?!就在那里乱讲,老师无语:行了,下一个问题……第二个问题是关于机器学习了,让我说了一下代价敏感的分类(这个主要是和他的医学图像分类任务相关的一个问题,我的需要关注实体识别和触发词识别),我还是不会,但是也不能什么都不说啊,于是在勉强回答后,紧接着开始陈述自己对机器学习的理解,讲自己对这个方向满满的热情,自己做的一些学习和研究,感觉自己讲的头头是道 :) 第三个问题是数据库的,让我说一下几个范式……没复习,忘光了,只能勉强凭借记忆回答,还算说出了几个来。
所以说面试真的没有太考察你的专业知识,考查的是你思维的方式,说话的方式,随机应变的能力,你的研究兴趣,对研究方向的热情,还有你的自信!有什么专业知识学不到呢?但是这一些软实力却不是容得到的
中科院
参考链接
东北大学软件学姐->上交学硕
东北大学软件学长->清软专硕
?->清华学长
985->南大学长
东大->lamda詹德川
whu学姐->北叉
东大软件6/256->清软
13级东大6/259学长