【深度强化学习】Sarsa
Sarsa
正如其名,SARSA 即是使用 ( s t , a t , r t , s t + 1 , a t + 1 ) (s_t,a_t,r_t,s_{t+1},a_{t+1}) (st,at,rt,st+1,at+1) 来更新 Q π Q_\pi Qπ,也就是 State-Action-Reward-State-Action。
1 TD target
首先,我们回顾一下 discounted return \text{discounted return} discounted return:
U t = R t + γ ⋅ R t + 1 + γ 2 ⋅ R t + 2 + γ 3 ⋅ R t + 3 + γ 4 ⋅ R t + 4 + ⋯ = R t + γ ⋅ ( R t + 1 + γ ⋅ R t + 2 + γ 2 ⋅ R t + 3 + γ 3 ⋅ R t + 4 + ⋯ ) \begin{gathered} U_{t}=R_{t}+\gamma \cdot R_{t+1}+\gamma^{2} \cdot R_{t+2}+\gamma^{3} \cdot R_{t+3}+\gamma^{4} \cdot R_{t+4}+\cdots \\ \ \ \ \ \ \ =R_{t}+\gamma \cdot\left(R_{t+1}+\gamma \cdot R_{t+2}+\gamma^{2} \cdot R_{t+3}+\gamma^{3} \cdot R_{t+4}+\cdots\right) \\ \end{gathered} Ut=Rt+γ⋅Rt+1+γ2⋅Rt+2+γ3⋅Rt+3+γ4⋅Rt+4+⋯ =Rt+γ⋅(Rt+1+γ⋅Rt+2+γ2⋅Rt+3+γ3⋅Rt+4+⋯)
也就是 U t = R t + γ ⋅ U t + 1 U_t = R_t + \gamma \cdot U_{t+1} Ut=Rt+γ⋅Ut+1,该式反应了相邻两个回报之间的关系。
假设 R t R_t Rt 依赖于 ( S t , A t , S t + 1 ) (S_t,A_t,S_{t+1}) (St,At,St+1),有下式:
Q π ( s t , a t ) = E [ U t ∣ s t , a t ] = E [ R t + γ ⋅ U t + 1 ∣ s t , a t ] = E [ R t ∣ s t , a t ] + γ ⋅ E [ U t + 1 ∣ s t , a t ] = E [ R t ∣ s t , a t ] + γ ⋅ E [ Q π ( S t + 1 , A t + 1 ) ∣ s t , a t ] \begin{aligned} Q_{\pi}\left(s_{t}, a_{t}\right) &=\mathbb{E}\left[U_{t} \mid s_{t}, a_{t}\right] \\ &=\mathbb{E}\left[R_{t}+\gamma \cdot U_{t+1} \mid s_{t}, a_{t}\right] \\ &=\mathbb{E}\left[R_{t} \mid s_{t}, a_{t}\right]+\gamma\cdot\mathbb{E}\left[U_{t+1} \mid s_{t}, a_{t}\right] \\ &=\mathbb{E}\left[R_{t} \mid s_{t}, a_{t}\right]+\gamma \cdot \mathbb{E}\left[Q_{\pi}\left(S_{t+1}, A_{t+1}\right) \mid s_{t}, a_{t}\right] \end{aligned} Qπ(st,at)=E[Ut∣st,at]=E[Rt+γ⋅Ut+1∣st,at]=E[Rt∣st,at]+γ⋅E[Ut+1∣st,at]=E[Rt∣st,at]+γ⋅E[Qπ(St+1,At+1)∣st,at]
于是我们有: Q π ( s t , a t ) = E [ R t + γ ⋅ Q π ( S t + 1 , A t + 1 ) ] Q_{\pi}\left(s_{t}, a_{t}\right) =\mathbb{E}\left[R_{t}+\gamma \cdot Q_{\pi}(S_{t+1},A_{t+1})\right] Qπ(st,at)=E[Rt+γ⋅Qπ(St+1,At+1)]。这里有对 , S t + 1 , A t + 1 ,S_{t+1},A_{t+1} ,St+1,At+1 的期望,直接计算很困难,因此可以使用 MC 近似。将 R t R_t Rt 近似为观测到的奖励 r t r_t rt,将 , S t + 1 , A t + 1 ,S_{t+1},A_{t+1} ,St+1,At+1 近似为观测到的 s t + 1 , a t + 1 s_{t+1},a_{t+1} st+1,at+1。于是我们有:
Q π ( s t , a t ) = E [ R t + γ ⋅ Q π ( S t + 1 , A t + 1 ) ] ≈ r t + γ ⋅ Q π ( s t + 1 , a t + 1 ) Q_{\pi}\left(s_{t}, a_{t}\right)=\mathbb{E}\left[R_{t}+\gamma \cdot Q_{\pi}(S_{t+1},A_{t+1})\right]\approx r_{t}+\gamma \cdot Q_{\pi}\left(s_{t+1}, a_{t+1}\right) Qπ(st,at)=E[Rt+γ⋅Qπ(St+1,At+1)]≈rt+γ⋅Qπ(st+1,at+1)
把 r t + γ ⋅ Q π ( s t + 1 , a t + 1 ) r_{t}+\gamma \cdot Q_{\pi}\left(s_{t+1}, a_{t+1}\right) rt+γ⋅Qπ(st+1,at+1) 称为 TD target y t y_t yt。TD target 部分基于真实观测到的奖励,部分基于 Q π Q_\pi Qπ 做出的预测。
TD learning 就是想 让动作价值 Q π ( s t , a t ) Q_\pi(s_t,a_t) Qπ(st,at) 接近 y t y_t yt,这是因为 Q π Q_\pi Qπ 完全是估计,而 TD target y t y_t yt 部分基于真实观测的奖励。
2 Tabular Version
如果状态空间和动作空间都是有限的,我们想要学习 Q π ( s , a ) Q_\pi(s,a) Qπ(s,a),可使用表格法。表中的每个元素代表一个动作价值。我们要做的就是用 Sarsa 算法更新表格,每次更新一个元素。
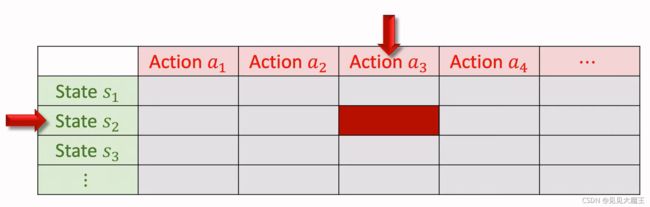
算法过程:
- 观测到一个 transition: ( s t , a t , r t , s t + 1 ) (s_t,a_t,r_t,s_{t+1}) (st,at,rt,st+1);
- 使用策略函数 a t + 1 ∼ π ( ⋅ ∣ s t + 1 ) a_{t+1} \sim \pi\left(\cdot \mid s_{t+1}\right) at+1∼π(⋅∣st+1) 选择下一个动作 a t + 1 a_{t+1} at+1;
- 计算 TD target: y t = r t + γ ⋅ Q π ( s t + 1 , a t + 1 ) y_t = r_{t}+\gamma \cdot Q_{\pi}\left(s_{t+1}, a_{t+1}\right) yt=rt+γ⋅Qπ(st+1,at+1),其中 r t r_t rt 是真实值, Q π ( s t + 1 , a t + 1 ) Q_{\pi}\left(s_{t+1}, a_{t+1}\right) Qπ(st+1,at+1) 可通过查表得出;
- 计算 TD error: δ t = Q π ( s t , a t ) − y t \delta_{t}=Q_{\pi}\left(s_{t}, a_{t}\right)-y_{t} δt=Qπ(st,at)−yt;
- 最后用 δ t \delta_{t} δt 去更新动作价值 Q π ( s t , a t ) Q_{\pi}\left(s_{t}, a_{t}\right) Qπ(st,at): Q π ( s t , a t ) ← Q π ( s t , a t ) − α ⋅ δ t Q_{\pi}\left(s_{t}, a_{t}\right) \leftarrow Q_{\pi}\left(s_{t}, a_{t}\right)-\alpha \cdot \delta_{t} Qπ(st,at)←Qπ(st,at)−α⋅δt,其中 α \alpha α 为学习率。
3 Neural Network Version
可以使用 value network 来近似动作价值函数 Q π Q_\pi Qπ,把 value network(含参数 w w w)记为函数 q ( s , a ; w ) q(s,a;w) q(s,a;w)。参数 w w w 是随机初始化的,根据观测到的奖励来更新 w w w。
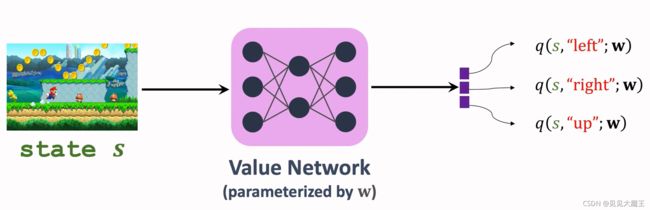
这里的 value network 也就是 actor-critic 中的 critic,用来评价 actor。
算法过程:
- 计算 TD target: y t = r t + γ ⋅ q ( s t + 1 , a t + 1 ; w ) y_{t}=r_{t}+\gamma \cdot q\left(s_{t+1}, a_{t+1} ; \mathbf{w}\right) yt=rt+γ⋅q(st+1,at+1;w);
- 计算 TD error: δ t = q ( s t , a t ; w ) − y t \delta_{t}=q\left(s_{t}, a_{t} ; \mathbf{w}\right)-y_{t} δt=q(st,at;w)−yt;
- 损失函数定义为: δ t 2 / 2 \delta_{t}^{2} / 2 δt2/2;
- 计算梯度: ∂ δ t 2 / 2 ∂ w = δ t ⋅ ∂ q ( s t , a t ; w ) ∂ w \frac{\partial \delta_{t}^{2} / 2}{\partial \mathbf{w}}=\delta_{t} \cdot \frac{\partial q\left(s_{t}, a_{t} ; \mathbf{w}\right)}{\partial \mathbf{w}} ∂w∂δt2/2=δt⋅∂w∂q(st,at;w);
- 根据梯度更新参数 w w w: w ← w − α ⋅ δ t ⋅ ∂ q ( s t , a t ; w ) ∂ w \mathbf{w} \leftarrow \mathbf{w}-\alpha \cdot \delta_{t} \cdot \frac{\partial q\left(s_{t}, a_{t} ; \mathbf{w}\right)}{\partial \mathbf{w}} w←w−α⋅δt⋅∂w∂q(st,at;w)。
Summary
- SARSA 的目标是学习 state-action 值函数 Q π Q_\pi Qπ。
- 表格法的 SARSA 学习的是 Q π Q_\pi Qπ,使用条件是其动作空间和状态空间是有限集。
- 价值网络的 SARSA 学习的是动作价值函数 Q π Q_\pi Qπ 的近似 q q q,每次迭代更新的是近似函数 q q q 的参数。
Reference
https://www.youtube.com/watch?v=-cYWdUubB6Q&list=PLvOO0btloRnvWZCkAUrBbVB5ZjDI2hUAM