YOLOV5训练自定义数据集(PyCharm超详细版)
文章目录
- 环境准备
- 一、制作自己的数据集
-
- 1.标注图片
- 2.分配训练数据集和测试集
- 二、配置文件
-
- 1.配置数据集的配置文件
- 2.配置模型文件
- 3.下载权重文件
- 三、训练模型
- 四、推理模型
环境准备
克隆YoLov5工程代码,仓库地址:https://github.com/ultralytics/yolov5

git克隆可能会失败,所以直接点击DownLoad Zip下载。zip文件解压后,通过cmd终端,切换到requirements.txt路径,通过pip install -r requirements.txt命令安装工程所有依赖的包。
一、制作自己的数据集
1.标注图片
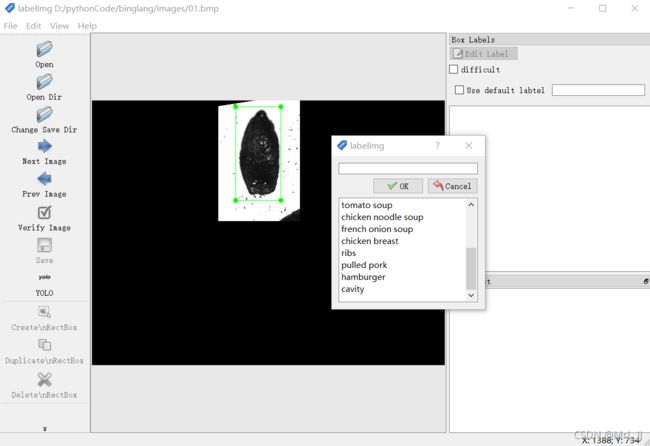
标注自己数据集的方法有很多种,本文采用LabelImg工具对图像进行标注。
labelImg下载地址:https://github.com/tzutalin/labelImg/releases
本文一开始采取下载压缩包直接运行exe的方式,失败(有机会再研究)。后来只好源码安装。除了python3以上的环境外,还需要lxml包,可通过pip list查看电脑有没有lxml包,没有的话通过pip install lxml安装即可。
解压完压缩包之后,打开Anaconda Prompt 切换至解压缩后的LabelImg目录,安装pyqt5:
conda install pyqt=5
pyrcc5 -o resources.py resources.qrc
安装成功打开labelImg工具:
python labelImg.py
详细的使用方法可以参考网上的文章,labelImg工具可以生成yolo格式,将所有文件存放在labels文件夹中。
每个图像对应一个txt文件,文件每一行为一个目标的信息,包括class, x_center, y_center, width, height格式。内容如下图所示:

2.分配训练数据集和测试集
采用脚本分配训练和测试数据集,代码如下:
class DivideImages():
def __init__(self,imagePath,outputDir):
self.imageDir = imagePath
self.listPathFile = outputDir+"/imagesPathAll.txt"
self.outputDir = outputDir+"/"
self.makeAllImagesPath(self.imageDir)
self.DivideImagePath()
def makeAllImagesPath(self, ImageDir):
imagesList = os.listdir(ImageDir)
imagesList = [x for x in imagesList if self.IsImage(x)]
id2Name = [(osp.splitext(x)[0], x) for x in imagesList]
res = dict(id2Name)
lines = list(res.values())
with open(self.listPathFile, 'w') as f:
for x in lines:
#y = x.strip() + "\n"
y = self.imageDir + x + "\n"
f.write(y)
def IsImage(self,fileName):
""" whether filename is an image or not """
imgType = ['.bmp', '.jpg', '.jpeg', '.png', '.tif']
basename = osp.basename(fileName)
basenameExt = osp.splitext(basename)[-1]
return (basenameExt in imgType) and (not basename.startswith("."))
def DivideImagePath(self):
pathList = np.asarray(self.readImgPathFromfile(self.listPathFile))
imgSum = len(pathList)
np.random.seed(7)
np.random.shuffle(pathList)
numTest = int(imgSum * 0.15)
numTrain = imgSum - numTest
testList = pathList[:numTest]
trainList = pathList[numTest:]
with open(osp.join(self.outputDir, "test.txt"), 'w') as f:
for x in testList:
y = x.strip() + "\n"
f.write(y)
with open(osp.join(self.outputDir, "train.txt"), 'w') as f:
for x in trainList:
y = x.strip() + "\n"
f.write(y)
def readImgPathFromfile(self,filename):
with open(filename, 'r') as f:
lines = f.readlines()
lines = [x.strip() for x in lines]
return lines
if __name__ == '__main__':
#参数1:收集的图片文件,参数2:生成训练集和测试集文件的路径
divide = DivideImages("D:/pythonCode/binglang/images","D:/pythonCode/binglang")
根据自己的实际情况,修改DivideImages构造函数的两个参数。
执行脚本会生成如下两个文本文件,里面记录着每张图片对应的路径。
![]()
二、配置文件
1.配置数据集的配置文件
在YOLOV5目录下的data文件夹下拷贝一份coco.yaml文件,重命名为自己的名字,修改自己数据集文件的路径、类别数和类别名称。

其中,train和val分别是之前生成的训练集和测试集的文本文档路径,nc表示目标的类别数目;names表示具体类别列表。
2.配置模型文件
本文选择的是yolo5s版本。打开yolo5s.yaml文件,将nc类别数改为自己需要的类别数量即可。

到次,我们得到了labels文件,Images文件,test.py和train文本,将其一并放到yolov5工程文件的data文件夹里。
3.下载权重文件
在YOLOV5目录下创建一个weigths文件夹,然后把data/scripts文件下的download_weights.sh放在weights文件下。下载如下所示文件。

三、训练模型
修改YOLOV5目录下train.py文件的参数:
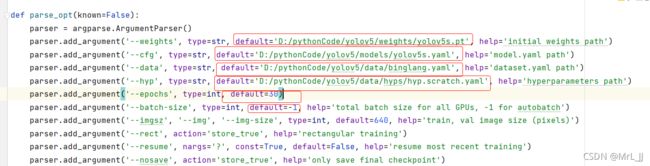
其中, ‘–weigths’:自己的权重文件路径。
‘–cfg’:自己模型所在的路径。
‘–data’:之前配置数据集文件路径。
‘–epochs’:指的是训练过程中整个数据集将被迭代多少次。
‘–batch-size’:一次看完多少张图片才进行权重更新。
‘–images-size’:输入图片宽高。
以下为训练过程中,pycharm打印输出信息。
训练好的模型会被保存在yolov5目录下的runs/train/exp9/weights/last.pt和best.pt,

四、推理模型
最后,在YOLOV5目录下的detect.py文件下修改参数以推理模型:

其中,weights是最满意的训练模型,source是所有测试图片的文件夹路径;
conf-thres表示置信度阈值; 测试完毕后会在runs/detect/exp/下生成图片以及对应的labels: