CNN到底每层学到了什么?
本文仅针对CNN初学者,为了让其更好的了解CNN模型到底学到了什么,这里花了一点时间做了一个简单的可视化。大佬轻喷,这代码写的着实垃圾。
模型和数据集
本文使用的数据集是一个自制的10分类的ImageNet数据集,主要有以下10类:多谢伟大的ImageFolder,让我这种人能直接用scp1分钟制作数据集。
关于模型本文的vgg模型也是自制的,因为后面要将所有的特征图可视化出来,所有通道数这里做了删减(为什么可以删减通道?详细可以去了解我的剪枝专栏,虽然现在不做剪枝了),用上面的数据集训练了一个Top-1 acc 86.40, Top-5 acc 97.80的预训练模型,然后!!!我还是用了训练集的图片来可视化,唉就是玩。就是这张,是不是很阴间。
注意,下面所有的图都是归一化以后的!!!
注意下面多图警告!!!
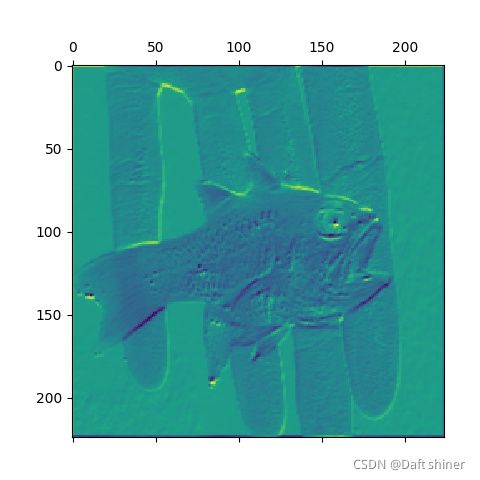
conv1_0的特征图:
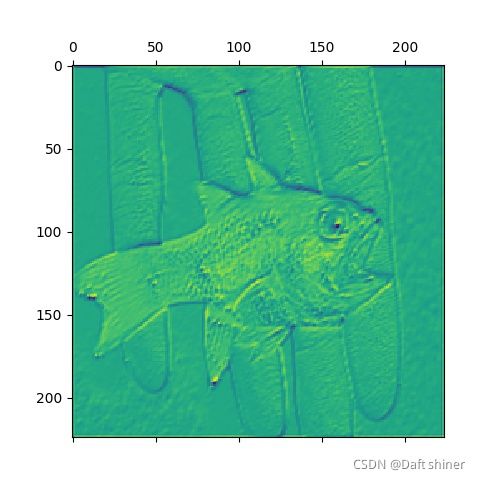
conv2_0的特征图:
conv3_0的特征图:
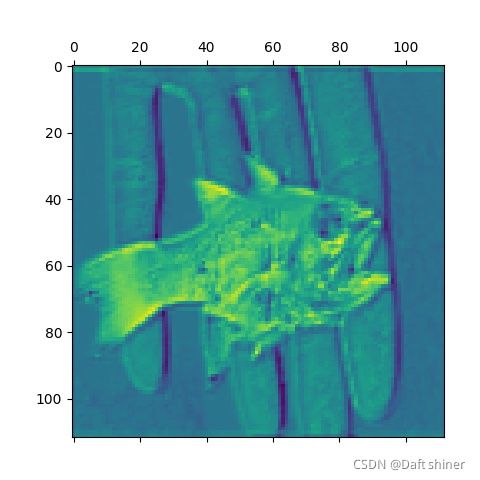
conv4_0的特征图:
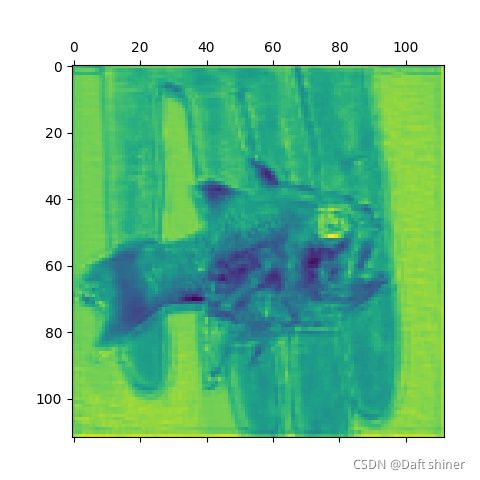
conv5_0的特征图:
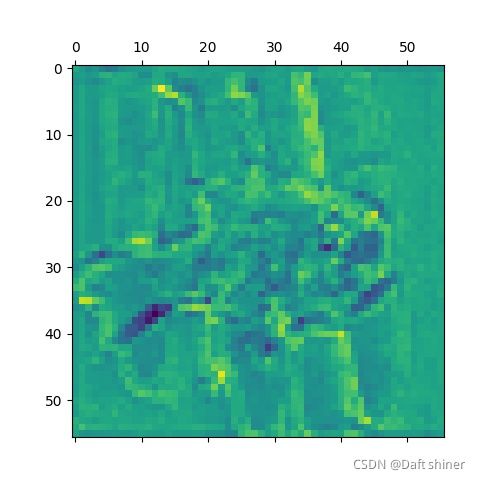
conv6_0的特征图:
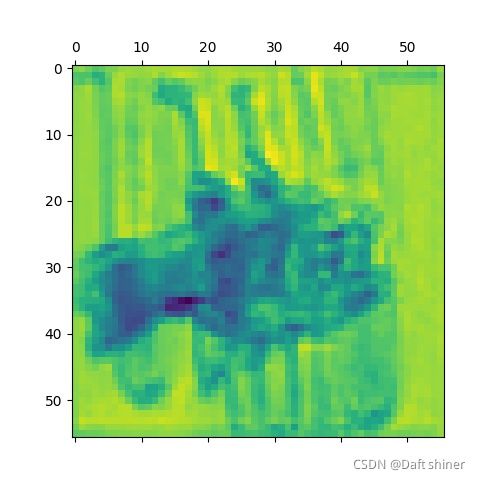
conv7_0的特征图:
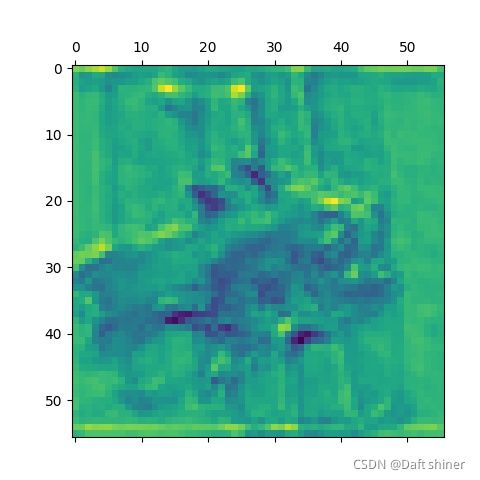
conv8_0的特征图:
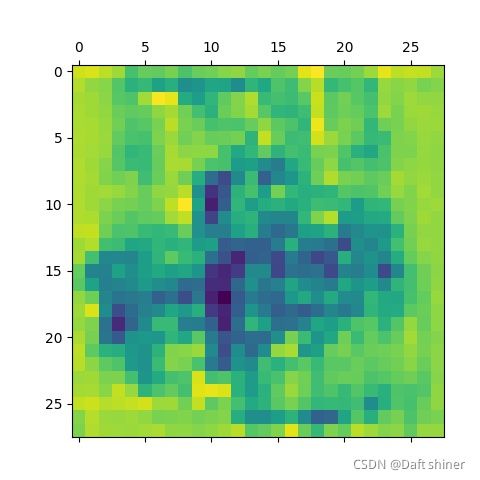
conv9_0的特征图:
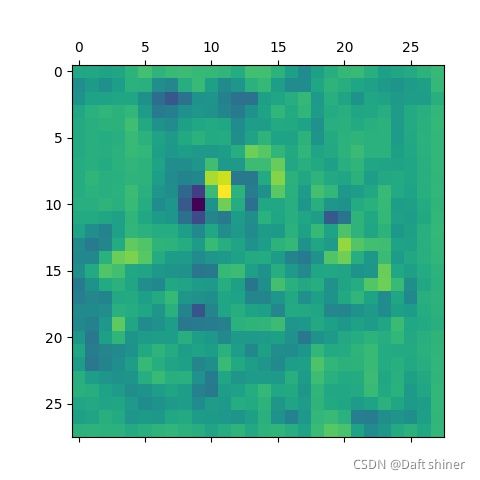
conv10_0的特征图:
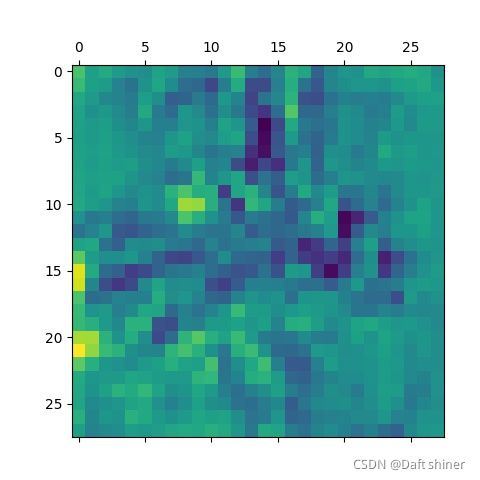
conv11_0的特征图:
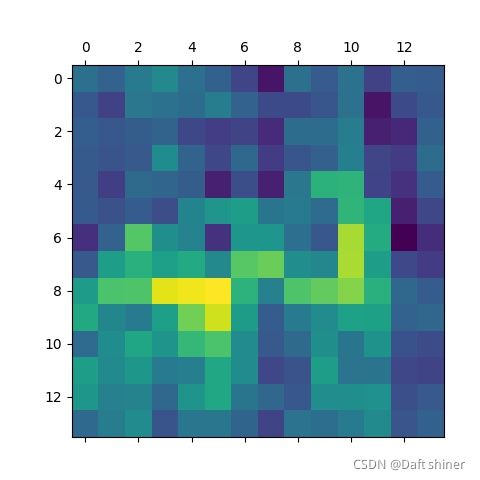
conv12_0的特征图:
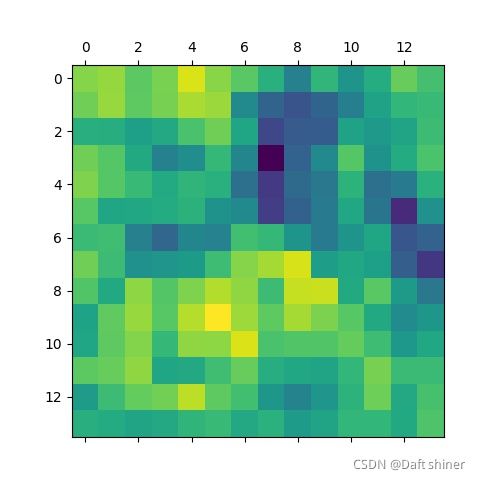
conv13_0的特征图:
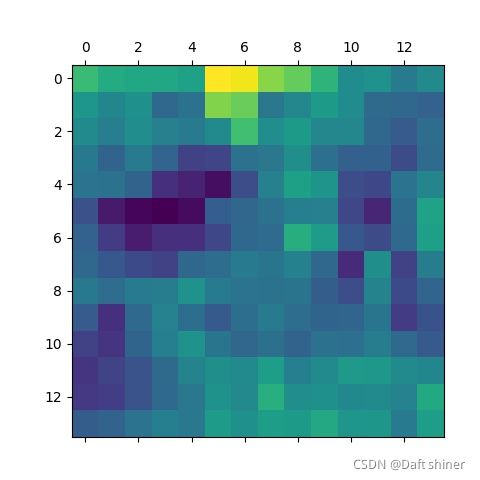
从这里还是能很清楚的看出模型是怎么一步提取特征的,不过当然可能是vgg比较简单,不知道resnet这种带残差的结构会怎么样,有空来做。
conv1全特征图
conv2全特征图

conv3全特征图
conv4全特征图
conv5全特征图
conv6全特征图
conv7全特征图
conv8全特征图
conv9全特征图
conv10全特征图
conv11全特征图
conv12全特征图
conv13全特征图
好像可视化了个寂寞,啥都看不出来,主要太小了。
代码
visualize_all_feature.py
import os
import PIL
import numpy as np
import torch
import torch.nn.functional as F
import matplotlib.pyplot as plt
from model.detailed_vgg_bn import detailed_VGG
import torch.nn as nn
def denormalize(tensor, mean, std):
if not tensor.ndimension() == 4:
raise TypeError('tensor should be 4D')
mean = torch.FloatTensor(mean).view(1, 3, 1, 1).expand_as(tensor).to(tensor.device)
std = torch.FloatTensor(std).view(1, 3, 1, 1).expand_as(tensor).to(tensor.device)
return tensor.mul(std).add(mean)
def normalize(tensor, mean, std):
if not tensor.ndimension() == 4:
raise TypeError('tensor should be 4D')
mean = torch.FloatTensor(mean).view(1, 3, 1, 1).expand_as(tensor).to(tensor.device)
std = torch.FloatTensor(std).view(1, 3, 1, 1).expand_as(tensor).to(tensor.device)
return tensor.sub(mean).div(std)
class Normalize(object):
def __init__(self, mean, std):
self.mean = mean
self.std = std
def __call__(self, tensor):
return self.do(tensor)
def do(self, tensor):
return normalize(tensor, self.mean, self.std)
def undo(self, tensor):
return denormalize(tensor, self.mean, self.std)
def __repr__(self):
return self.__class__.__name__ + '(mean={0}, std={1})'.format(self.mean, self.std)
if __name__ == "__main__":
img_dir = 'images'
img_name = 'n01443537_10025.JPEG'
img_name = 'n01443537_10034.JPEG'
img_path = os.path.join(img_dir, img_name)
pil_img = PIL.Image.open(img_path)
normalizer = Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
torch_img = torch.from_numpy(np.asarray(pil_img)).permute(2, 0, 1).unsqueeze(0).float().div(255).cuda()
torch_img = F.upsample(torch_img, size=(224, 224), mode='bilinear', align_corners=False)
normed_torch_img = normalizer(torch_img)
criterion = nn.CrossEntropyLoss().cuda()
vgg = detailed_VGG(num_classes=10)
cpkt = torch.load('pretrained_model/detailed_VGG/small_imagenet/scores.pt')
vgg.load_state_dict(cpkt)
vgg.eval()
vgg.cuda()
# print(vgg)
out = vgg(normed_torch_img)
feat = vgg.get_dict()
for i in range(len(feat)):
feat[i] = feat[i].squeeze()
dim0, dim1 = feat[i].shape[0], feat[i].shape[1]
print(dim0, dim1)
a = dim0 / 10
b = 10
plt.matshow(feat[i].reshape(int(a * dim1), int(b * dim1)).cpu().detach().numpy())
# plt.matshow(feat[i][0].cpu().detach().numpy())
plt.savefig('conv%d.jpg' % i)
# normed_torch_img = normed_torch_img.permute(0, 2, 3, 1)
# normed_torch_img = normed_torch_img.squeeze()
# plt.imshow(normed_torch_img.cpu().numpy())
# plt.savefig('original_image.jpg')
plt.show()
detailed_vgg_bn.py
import torch
import torch.nn as nn
import torch.nn.functional as F
class detailed_VGG(nn.Module):
def __init__(self, num_classes=10, init_weights=True):
super(detailed_VGG, self).__init__()
self.dict = []
self.conv1 = nn.Conv2d(3, 40, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(40, 40, kernel_size=3, padding=1)
self.conv3 = nn.Conv2d(40, 60, kernel_size=3, padding=1)
self.conv4 = nn.Conv2d(60, 60, kernel_size=3, padding=1)
self.conv5 = nn.Conv2d(60, 80, kernel_size=3, padding=1)
self.conv6 = nn.Conv2d(80, 80, kernel_size=3, padding=1)
self.conv7 = nn.Conv2d(80, 80, kernel_size=3, padding=1)
self.conv8 = nn.Conv2d(80, 100, kernel_size=3, padding=1)
self.conv9 = nn.Conv2d(100, 100, kernel_size=3, padding=1)
self.conv10 = nn.Conv2d(100, 100, kernel_size=3, padding=1)
self.conv11 = nn.Conv2d(100, 100, kernel_size=3, padding=1)
self.conv12 = nn.Conv2d(100, 100, kernel_size=3, padding=1)
self.conv13 = nn.Conv2d(100, 100, kernel_size=3, padding=1)
self.maxpool1 = nn.MaxPool2d(kernel_size=2, stride=2)
self.maxpool2 = nn.MaxPool2d(kernel_size=2, stride=2)
self.maxpool3 = nn.MaxPool2d(kernel_size=2, stride=2)
self.maxpool4 = nn.MaxPool2d(kernel_size=2, stride=2)
self.maxpool5 = nn.MaxPool2d(kernel_size=2, stride=2)
self.avgpool = nn.AdaptiveAvgPool2d((7, 7))
self.classifier = nn.Sequential(
nn.Linear(100 * 7 * 7, 512),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(512, 512),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(512, num_classes),
)
if init_weights:
self._initialize_weights()
def forward(self, x):
x = self.conv1(x)
self.dict.append(x)
x = F.relu(x)
x = self.conv2(x)
self.dict.append(x)
x = self.maxpool1(F.relu(x))
x = self.conv3(x)
self.dict.append(x)
x = F.relu(x)
x = self.conv4(x)
self.dict.append(x)
x = self.maxpool2(F.relu(x))
x = self.conv5(x)
self.dict.append(x)
x = F.relu(x)
x = self.conv6(x)
self.dict.append(x)
x = F.relu(x)
x = self.conv7(x)
self.dict.append(x)
x = self.maxpool3(F.relu(x))
x = self.conv8(x)
self.dict.append(x)
x = F.relu(x)
x = self.conv9(x)
self.dict.append(x)
x = F.relu(x)
x = self.conv10(x)
self.dict.append(x)
x = self.maxpool4(F.relu(x))
x = self.conv11(x)
self.dict.append(x)
x = F.relu(x)
x = self.conv12(x)
self.dict.append(x)
x = F.relu(x)
x = self.conv13(x)
self.dict.append(x)
x = self.maxpool5(F.relu(x))
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
def get_dict(self):
return self.dict
if __name__ == "__main__":
import torch
input = torch.randn(2, 3, 224, 224)
model = detailed_VGG()
output = model(input)
print(output)
dict = model.get_dict()
for i in range(len(dict)):
print(dict[i].shape)
最后如果想要我的数据集或者预训练模型,请联系我:[email protected]