面试必问题:缓存击穿、缓存穿透、缓存雪崩,你还傻傻分不清
当我们服务器QPS比较高,并且对数据的实时性要求不高时,往往会接入缓存以达到快速Response、降低数据库压力的作用,常用来做缓存的中间件如Redis等,面试时经常会被面试官提问,作为里面最常见,几乎是必考题的缓存击穿、穿透、雪崩场景,你真的了解了吗?
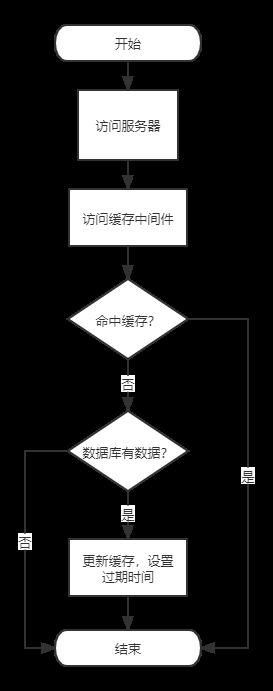
前端发起一个请求,经历过三次握手后连接到服务器,想要获取相应的数据,那么服务器接入了缓存中间件后,从接收到Request到最后的Response,到底是怎样的一个流程呢?以下探讨忽略掉参数校验等逻辑,直接讲最核心的链路。
调用链路
一个请求Request过来,服务器首先和缓存中间件建立连接,传输对应key到缓存中间件中获取相对应的数据,服务器拿到返回的结果后,判断返回的结果是否有数据,如果有数据,则返回从缓存中拿到的结果。如果缓存中间件中没有数据,则建立数据库连接,访问数据库服务器,按照相应逻辑拿到返回结果,判断结果中是否有数据,如果有则返回对应数据,如果没有则按照业务场景要求,返回对应结果(一般为null或者new一个空对象)。
缓存击穿
含义:
什么是缓存击穿?通俗的讲指的是缓存中没有数据,但数据库中有数据的场景。那为什么缓存中会没有数据呢?一般是由于设置了缓存时间导致缓存过期,所以没有数据。那缓存找不到数据去数据库查询就好了呀,为啥又叫击穿?是因为要查询这个key对应的数据是一个热点数据,并发访问的量大,同时去查询数据库,导致数据库压力骤增,严重会打崩数据库。

解决方案:
1、如果是不改变的数据,如一些常量值,则可以设置对应热点key永不过期。
2、加上互斥锁,防止同一台服务器同一时间有多个连接访问数据库。
// 伪代码
public class Main {
// 双重检测锁
public static String getHotData(String key) {
// 先从缓存中间件获取对应热点key数据
String response = redis.get(key);
// 缓存没有数据
if(Objects.isNull(response)) {
// 保证一台服务器同一时间只有一个线程访问
synchronized (Main.class) {
// 假设A线程访问进synchronized里,线程B, C阻塞在synchronsized外面
// 线程A退出synchronized后,线程B和C应该从redis中拿而不是再访问数据库
response = redis.get(key);
// 访问数据库 拿到数据后 写进redis中
if(Objects.isNull(response)) {
response = loadDataFromMySQL(key);
redis.set(key, response);
}
}
}
return response;
}
}
3、加上分布式锁,全局保证只有一个线程访问数据库。
// 伪代码
public class Main {
// 分布式唯一key
public static String getHotData(String key, int tryTime) throws InterruptedException {
if(tryTime >= 4) {
return "";
}
// 先从缓存中间件获取对应热点key数据
String response = redis.get(key);
// 缓存没有数据
if(Objects.isNull(response)) {
// 保证整个服务集群同一时间只有一个线程访问
if (redis.tryLock()) {
try {
// 访问数据库 拿到数据后 写进redis中
if(Objects.isNull(response)) {
response = loadDataFromMySQL(key);
redis.set(key, response);
}
} finally {
redis.unlock();
}
} else {
TimeUnit.MILLISECONDS.sleep(100);
getHotData(key, tryTime + 1);
}
}
return response;
}
}
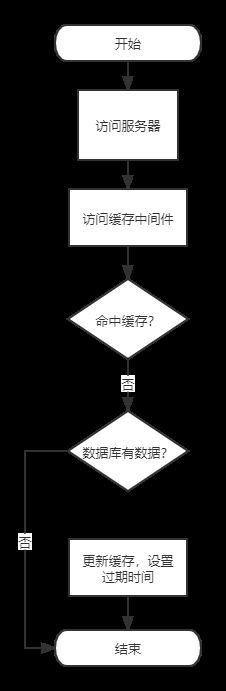
缓存穿透
含义:缓存穿透指的是缓存中间件和数据库都没有对应的数据,但是不断接收到请求获取该key的数据,导致数据库压力过大,甚至崩溃。
解决方案:
1、访问数据库也拿不到数据后,可以按照具体业务要求,在缓存层加上一个该key的值,设置一个过期时间,比如10s或者1min等。那为什么不设不过期呢?第一个是说因为该key可能有对应的业务含义,有可能只是该时间点还没有数据,所以不能设置不过期;第二个是说如果真的是恶意访问,那么可能过一段时间就没有类似请求,那么我们没有必要一直把该数据留在缓存里。
2、增加校验,如果是不符合预期的请求可以直接过滤,比如说缓存中存放了用户信息,对应的缓存key是和id有关系,那么如果你的id都是大于等于0的,对于小于0的id可以直接做过滤。
@Controller
public class Controller {
@RequestMapping(value="/test")
public String printHello(Integer id) {
if(Objects.isNull(id) || id < 0) {
return null;
}
// 处理对应逻辑
}
}
缓存雪崩
含义:
缓存雪崩指的是在同一个时间点,缓存中的大批量数据过期,并且还都是热点数据,导致同一时间并发压力都打到了数据库中,导致数据库压力骤增,甚至宕机。有的人就会问了,这和缓存击穿不是一个意思吗?缓存击穿指的是并发查询某条热点key数据,缓存雪崩指的是大批量。出现场景之一是在某些核心页面,该页面的内容都放入了缓存,并且都设置了同样的缓存时间。

解决方案:
1、最简单的就是设置热点数据不过期,但要结合对应业务场景来看。
2、在给每个热点key设置过期时间时,加上一个随机值,使得热点数据离散开来,不会同一时间大批量过期。
3、使用缓存击穿场景讲到的互斥锁、分布式锁。

愿每个人都能带着怀疑的态度去阅读文章并探究其中原理。
道阻且长,往事作序,来日为章。
期待我们下一次相遇!