MySQL——数据查询
每日一语:孤独会使你变的强大!!!
目录
检索数据(select的使用)
单表查询
1.单列检索(select)
2.检索多个列
3.检索所有列(*)
4.检索不同的行(DISTINCT)
5.限制结果(limit)
6.使用完全限定的表名
连接查询
1.等值与非等值连接查询
2.自身链接
3.多表连接
嵌套查询
嵌套查询的介绍
带有exists谓语的子查询
集合查询
1.UNION(并集)
2.INTERSECT(交集)
检索数据(select的使用)
单表查询
1.单列检索(select)
我们将从简单的SQL SELECT语句开始介绍,此语句如下所示:
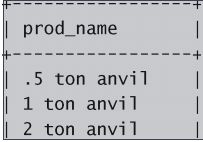
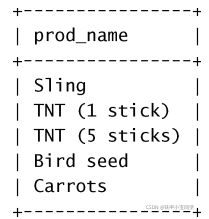
select pro_name from products;分析:
上述语句利用SELECT语句从products表中检索一个名为prod_name的列。所需的列名在SELECT
关键字之后给出,FROM关键字指出从其中检索数据的表名。
输出:
笔记:
未排序数据
如果读者自己试验这个查询,可能会发现显示输出的数据顺序与这里的不同。出现这种情况
很正常。如果没有明确排序查询结果,则返回的数据的顺序没有特殊意义。返回数据的顺序
可能是数据被添加到表中的顺序,也可能不是。只要返回相同数目的行,就是正常的。
2.检索多个列
要想从一个表中检索多个列,使用相同的SELECT语句。唯一的不同 是必须在SELECT关键字后
给出多个列名,列名之间必须以逗号分隔。
例如:
输入:
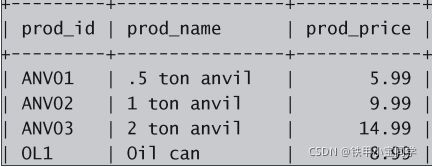
select pro_id,pro_name ,pro_price from products;分析:
与前一个例子一样,这条语句使用SELECT语句从表products中选择数据。在这个例子中,指定了
3个列名,列名之间用逗号分隔。此语句的输出如下:

3.检索所有列(*)
输入:
select * from products;分析:
* 号代表的是通配符,表示直接查询所有列。
4.检索不同的行(DISTINCT)
正如所见,SELECT返回所有匹配的行。但是,如果你不想要每个值 每次都出现,怎么办?例
如,假如你想得出products表中产品的所有供应商ID:
select vend_id from products;输出:

如果我们不想要重复的值该怎么办呢?
解决办法是使用DISTINCT关键字,顾名思义,此关键字指示MySQL只返回不同的值。
例如:
select distinct vend_id from products ;
注 !!!
如果使用DISTINCT关键字,它必须直接放在列名的前面。
不能部分使用DISTINCT DISTINCT关键字应用于所有列而不仅是前置它的列。如果给出SELECT
DISTINCT vend_id,prod_price,除非指定的两个列都不同,否则所有行都将被检索出来。
5.限制结果(limit)
SELECT语句返回所有匹配的行,它们可能是指定表中的每个行。为了返回第一行或前几行,可使
用LIMIT子句。下面举一个例子:
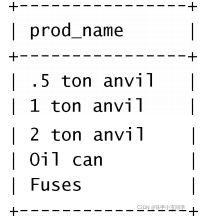
select vend_name from products limit 5;分析:
此语句使用SELECT语句检索单个列。LIMIT 5指示MySQL返回不多于5行。此语句的输出如下所示:
为得出下一个5行,可指定要检索的开始行和行数,如下所示:
select vend_name from products limit 5,5;分析:
LIMIT 5, 5指示MySQL返回从行5开始的5行。第一个数为开始位置,第二个数为要检索的行数。此
语句的输出如下所示:
所以,带一个值的LIMIT总是从第一行开始,给出的数为返回的行数。带两个值的LIMIT可以指定
从行号为第一个值的位置开始。
笔记:
在行数不够时 LIMIT中指定要检索的行数为检索的最大行数。如果没有足够的行(例如,给
出LIMIT 10, 5,但只有13行),MySQL将只返回它能返回的那么多行。
6.使用完全限定的表名
输入:
select products.prod_name from products;分析:
这个等同于:
select prod_name from products;有一些情形需要完全限定名。现在,需要注意这个语法,以便在遇到时知道它的作用。
连接查询
概念:如果一个查询同时涉及两个以上的表,则称之为连接查询。
1.等值与非等值连接查询
连接查询的where子句中用来连接两个表的条件成为连接条件或连接谓词。
格式:<表名1>.<列名1><比较运算符><表名2>.<列名2>
其中比较运算符主要有=,>,<,>=,<=,!=(或<>)等。

此外连接谓词还可以使用下面的格式:
<表名1>.<列名1>between<表名2>.<列名2>and<表名2>.<列名3>
当连接运算符为=时,称为等值连结。使用其他运算符称为非等值连接 。
接下来我们看一个例子:

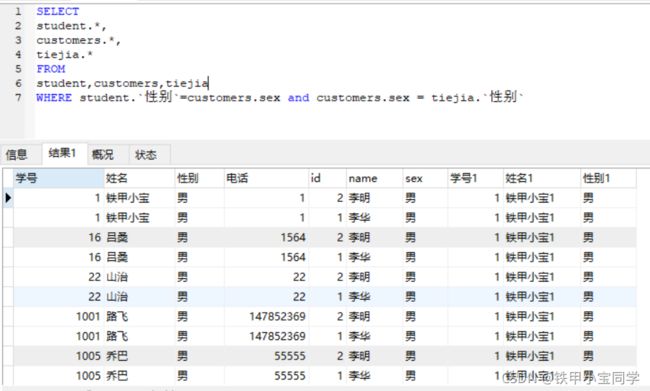
我们可以用看到属性名前都加了表的前缀名,这是为了避免混淆。如果属性名在参加连接的个表中是唯一的,则可以省略表前缀名。
关系数据库管理系统执行该连接操作的一种过程可能是:首先在customers中找到第一个元组,然后在从头开始扫描student,逐一找查和customers中性别相等的元素,找到后拼接起来,形成一个元组,当student中扫描完毕,就在从customers中的第二个元素开始,重复上诉操作,直到第一个表中的元素全部处理完,这个就是嵌套循环连接算法的基本思想。
自然连接:
把目标列中的重复的属性列去掉则为自然连接 。
2.自身链接
连接操作不仅仅可以在两个表之间进行,也可以是一个表与其自己连接,称为表的自身连接。
注:在自身连接的时候我们需要把本身的表转换为两个不同的表名,然后在去使用连接查询。
3.多表连接
连接操作除了可以是两表连接,一个表与其自身连接外,还可以是两个以上的表进行连接,后者通常成为多表连接。
例:
通常是先经行两个表的连接操作,在将其连接结果与第三个表进行连接。
嵌套查询
嵌套查询的介绍
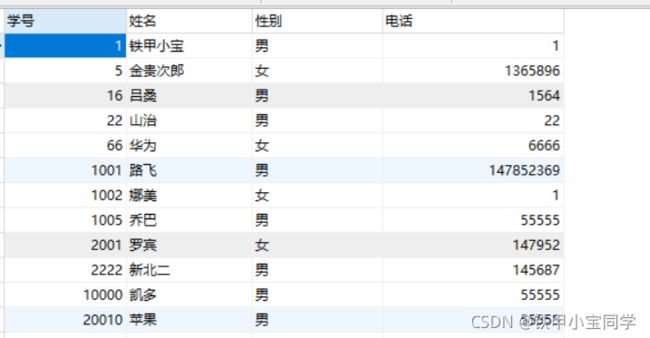
在SQL语言中,一个select-from-where 语句称为一个查询块。将一个查询块嵌套在另一个查询块中的where子句或having短语的条件中的查询条件称为嵌套查询。
例如:
select sname
from student //外层查询
where sno in
(select sno from sc where cno = '2');内层查询嵌套插叙使用户可以使用多个简单查询构成复杂的查询,从而增强SQL的查询能力。以层层嵌套的方式来构造程序是SQL中 结构化 的含义所在。
子查询中的查询条件不依赖于父查询,称为不相关子查询。
如果子查询的查询条件依赖于父查询,这类子查询称为相关子查询,整个查询语句称为相关嵌套查询语句。
带有exists谓语的子查询
带有exists谓词的子查询不能返回,任何数据,只产生逻辑真‘true’或逻辑假值‘false'。
例如:
select sname
from student
where exists
(select * from sc where sno = student.sno and cno = '1');
使用存在量词exists后,如果内层查询结果非空,则外层的where 子句返回真值,否者返回假值。
与exists谓词相对应的是not exists 谓词。使用存在量词not exists后,如果内层查询结果为空,则外层的where子句返回真值,否者返回假值。
集合查询
1.UNION(并集)
例如:
SELECT 姓名
from student
where 性别 = '男'
UNION
SELECT 姓名
FROM student
where 学号 >= 666;
分析:
注:union在查询中是默认去掉重复行,如果我们不想去掉重复行我们可以使用 all union。
2.INTERSECT(交集)
我们对这个可以直接上例子来看:
查询计算机科学系的学生与年龄不大于19岁的学生的交集。
select*
from student
where sdept ='cs'
intersect
select *
from student
where sage<19;实际上我们可以这样写:
select *
from
student
where sdept = 'cs' and
sage <= 19;本期就到这里了哦,我们下期再见!!!