node.js
nvm-window
下载nvm-window
推荐下载nvm-setup.zip可以避免环境配置
nvm list available 查看所有node版本
nvm install latest 安装最新版本node
nvm install lts
nvm node mirror https://npm.taobao.org/mirrors/node/
nvm npm mirror https://npm.taobao.org/mirrors/npm/
nvm use 版本号
nvm list 当前可用版本
在你nvm的安装路径下,找到settings.txt打开,在后面加加上
node_mirror: https://npm.taobao.org/mirrors/node/
npm_mirror: https://npm.taobao.org/mirrors/npm/
Node程序传递参数
在某些情况下执行node程序的过程中,我们可能希望给node传递一些参数:
node index.js env=development xiaoming
我们可以通过process内置对象中获取参数,如果我们直接打印这个内置对象,它里面包含很多信息,比如版本、操作系统等。
process {
version: 'v14.15.0',
versions: {
node: '14.15.0',
v8: '8.4.371.19-node.17',
uv: '1.40.0',
zlib: '1.2.11',
brotli: '1.0.9',
ares: '1.16.1',
modules: '83',
nghttp2: '1.41.0',
napi: '7',
llhttp: '2.1.3',
openssl: '1.1.1g',
cldr: '37.0',
icu: '67.1',
tz: '2020a',
unicode: '13.0'
},
arch: 'x64',
platform: 'win32',
release: {
name: 'node',
lts: 'Fermium',
sourceUrl: 'https://nodejs.org/download/release/v14.15.0/node-v14.15.0.tar.gz',
headersUrl: 'https://nodejs.org/download/release/v14.15.0/node-v14.15.0-headers.tar.gz',
libUrl: 'https://nodejs.org/download/release/v14.15.0/win-x64/node.lib'
},
_rawDebug: [Function: _rawDebug],
moduleLoadList: [
'Internal Binding stream_wrap',
'Internal Binding tcp_wrap',
'Internal Binding pipe_wrap',
'NativeModule internal/stream_base_commons',
... 9 more items
],
binding: [Function: binding],
_linkedBinding: [Function: _linkedBinding],
_events: [Object: null prototype] {
newListener: [Function: startListeningIfSignal],
removeListener: [Function: stopListeningIfSignal],
warning: [Function: onWarning],
SIGWINCH: [Function (anonymous)]
},
_eventsCount: 4,
_maxListeners: undefined,
domain: null,
_exiting: false,
config: {
target_defaults: {
cflags: [],
default_configuration: 'Release',
defines: [],
include_dirs: [],
libraries: []
},
variables: {
asan: 0,
build_v8_with_gn: false,
coverage: false,
v8_trace_maps: 0,
v8_use_siphash: 1,
want_separate_host_toolset: 0
}
},
dlopen: [Function: dlopen],
uptime: [Function: uptime],
_getActiveRequests: [Function: _getActiveRequests],
_getActiveHandles: [Function: _getActiveHandles],
reallyExit: [Function: reallyExit],
_kill: [Function: _kill],
hrtime: [Function: hrtime] {
bigint: [Function: hrtimeBigInt] },
cpuUsage: [Function: cpuUsage],
resourceUsage: [Function: resourceUsage],
memoryUsage: [Function: memoryUsage],
kill: [Function: kill],
exit: [Function: exit],
openStdin: [Function (anonymous)],
allowedNodeEnvironmentFlags: [Getter/Setter],
assert: [Function: deprecated],
features: {
inspector: true,
debug: false,
uv: true,
ipv6: true,
tls_alpn: true,
tls_sni: true,
tls_ocsp: true,
tls: true,
cached_builtins: true
},
_fatalException: [Function (anonymous)],
setUncaughtExceptionCaptureCallback: [Function: setUncaughtExceptionCaptureCallback],
hasUncaughtExceptionCaptureCallback: [Function: hasUncaughtExceptionCaptureCallback],
emitWarning: [Function: emitWarning],
nextTick: [Function: nextTick],
_tickCallback: [Function: runNextTicks],
_debugProcess: [Function: _debugProcess],
_debugEnd: [Function: _debugEnd],
_startProfilerIdleNotifier: [Function (anonymous)],
_stopProfilerIdleNotifier: [Function (anonymous)],
stdout: [Getter],
stdin: [Getter],
stderr: [Getter],
abort: [Function: abort],
umask: [Function: wrappedUmask],
chdir: [Function: wrappedChdir],
cwd: [Function: wrappedCwd],
env: {
ALLUSERSPROFILE: 'C:\\ProgramData',
APPDATA: 'C:\\Users\\hp\\AppData\\Roaming',
},
title: 'C:\\WINDOWS\\System32\\WindowsPowerShell\\v1.0\\powershell.exe',
argv: [
'D:\\nodejs\\node.exe',
'D:\\qdcode\\node.js\\node传递参数\\01-dome.js'
],
execArgv: [],
pid: 14472,
ppid: 18452,
execPath: 'D:\\nodejs\\node.exe',
debugPort: 9229,
argv0: 'D:\\nodejs\\node.exe',
_preload_modules: [],
mainModule: Module {
id: '.',
path: 'D:\\qdcode\\node.js\\node传递参数',
exports: {
},
parent: null,
filename: 'D:\\qdcode\\node.js\\node传递参数\\01-dome.js',
loaded: false,
children: [],
paths: [
'D:\\qdcode\\node.js\\node传递参数\\node_modules',
'D:\\qdcode\\node.js\\node_modules',
'D:\\qdcode\\node_modules',
'D:\\node_modules'
]
},
[Symbol(kCapture)]: false
}
找到其中的argv属性:我们发现他是一个数组,里面包含我们传递的参数。
console.log(process.argv);
[
'D:\\nodejs\\node.exe',
'D:\\qdcode\\node.js\\node传递参数\\01-dome.js',
'env=development',
'xiaoming'
]
全局对象
Node中给我们提供了一些全局对象,方便我们进行一些操作

Buffer模块转换二进制
对于前段开发来说,通常很少会和二进制打交道,但是对于服务器端为了做很多功能,我们必须直接去操作器二进制的数据。
所以node为了可以方便开发者完成更多功能,提供了我们一个类Buffer,并且它是全局的
Buffer可以看成一个存储二进制的数组,数组的每一项可以保存8位二进制。
Buffer和字符串
Buffer相当于是一个字节的数组,每个数组中每一项对应一个字节的大小
//const buffer = new Buffer('nono') //会有警告不建议使用
const buffer01 = Buffer.from('hello');
const buffer02 = Buffer.from('礼拜')
console.log(buffer01);
console.log(buffer02);
<Buffer 68 65 6c 6c 6f>
<Buffer e7 a4 bc e6 8b 9c>
 可以传递参数,按什么编码
可以传递参数,按什么编码
const buffer03 = Buffer.from('李白','utf16le');
console.log(buffer03);
console.log(buffer03.toString());
console.log(buffer03.toString('utf16le'));
<Buffer 4e 67 7d 76>
Ng}v
李白
Buffer的其他创建

通过alloc的方式创建Buffer
const buffer = Buffer.alloc(8);
console.log(buffer);
buffer[0] = 88;
buffer[1] = 0x88
console.log(buffer);
读取文件
const fs = require('fs');
fs.readFile('./test.txt',(err,data)=>{
//没有定义解码类型
console.log(data);//data为一个Buffer数组 读取图片
const fs = require('fs');
fs.readFile('./banner.png',(err,data)=>{
console.log(data);
fs.writeFile('./banner1.png',data,(err)=>{
})
})
<Buffer 89 50 4e 47 0d 0a 1a 0a 00 00 00 0d 49 48 44 52 00 00 07 80 00 00 00 b4 08 02 00 00 00 fa 8c a6 a4 00 00 00 19 74 45 58 74 53 6f 66 74 77 61 72 65 00 ... 304469 more bytes>

特殊的全局对象
其中有一些特殊的全局变量,这些全局对象实际上是模块中的变量,只是每个模块都有,看起来像是全局变量;
但是在命令交互中是不可以使用的;
包括:__dirname、__filename、exports、module、require()
__dirname:获取当前文件所在的路径(不包括后面的文件名)
__filename:获取当前文件所在的路径和文件名称(包括后面的文件名称)
console.log(__dirname); //D:\qdcode\node.js\node传递参数
console.log(__filename); //D:\qdcode\node.js\node传递参数\01-dome.js
常见的全局对象
process对象:提供了Node进程中相关的信息:
- 比如Node的运行环境、参数信息;
- 将一些环境变量读取到process的env中;
console对象:提供了简单的调试控制台
定时器参数:在Node中使用定时器有好几种方式:
- setTimeout(callback,delay[,…args]):callback在delay毫秒后执行一次;
- setInterval(callback,delay[,…args]):callback每delay毫秒重复执行一次;
- setImmediate(callback[,…args]):callback I/O事件后的回调的立即执行;
- process.nextTick(callback[,…args]):添加到下一次tick队列中
global和window的区别
在浏览器中,全局变量都是window上的,比如document、setInterval、alert、console等。
在Node中也有一个global属性,看起来它里面也有很多其他对象。
但是在浏览器中执行js代码,如果我们在顶级范围内通过var定义一个属性,默认会被添加到window对象上
var name = 'zhangsan'
console.log(window.name) //zhangsan
但是在node中,我们通过var定义一个变量,他只是当前模块中有一个变量,不会放到全局中
var name = 'zhangsan'
console.log(window.name) //undefined
模块化开发
事实上模块化开发最终目标是将程序划分成一个个小的结构,这个结构中编写属于自己的逻辑代码,有自己的作用域,不会影响到其他的结构。
这个结构可以将自己希望暴露的变量、函数、对象导出给其他结构使用。
也可以通过某种方法,导入另外结构中的变量、函数、对象等。
上面提到的结构就是模块;安装这种那个结构划分开发程序的过程,就是模块化开发的过程。
模块化已经是js一个非常迫切的需求:
- 但是js本身,知道es才推出了自己的模块化方案;
- 在此之前,为了让js支持模块化,涌现了很多不同的模块化规范:AMD、CMD、CommentJS等。
没有模块化的问题
小明编写的xiaoming.js
var name = '小明'
小红编写的xiaohong.js也使用的name
var name = '小红'
小明又在sayName.js中调用了name变量
console.log(name);
这样的顺序引入js会导致小明的代码被小红的代码覆盖。从而输出错误的信息。
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<script src="./xiaoming.js"></script>
<script src="./xiaohong.js"></script>
<script src="./sayName.js"></script>
</head>
这种情况我们可以采用立即执行函数结果(IIFE)
xiaoming.js
var xiaoming = (function(){
var name = 'xiaoming';
return{
name
}
})()
xiaohong.js
var xiaohong =(function(){
var name = 'xiaohong'
return {
name
}
})()
sayName.js
console.log(xiaoming.name); //xiaoming
console.log(xiaohong.name); //xiaohong
使用立即执行函数我们不必关注js引入的顺序
但是这样也有新的问题:
- 我们必须记住每一个模块中返回对象的命名,才能在其他模块使用过程中正确的使用;
- 每个文件中的代码都需要包裹在一个匿名函数中
- 没有合适的规范中,每个人都可能会任意命名、甚至出现模块名称相同的情况。
CommonJS
我们需要知道CommonJS是一个规范,最初提出来是在浏览器以外的地方使用,并且当时被命名为ServerJS,后来为了体现它的广泛性,修改为CommentJS。
- Node是CommentJS在服务器端一个具有代表性的实现。
- Browserify是CommentJS在浏览器中的一种实现;
- webpack打包工具具备对CommentJS的支持和转换;
所以,Node中对CommentJS进行了支持和实现,让我们在开发node的过程中可以方便的进行模块化开发:
- 在Node中每一个js文件都是一个单独的模块;
- 模块中包括CommentJS规范的核心变量:exports、module.exports、require;
- exports和module.exports可以负责对模块中的内容进行导出;
- require函数可以帮助我们导入其他模块(自定义模块、系统模块、第三方库模块)中的内容。
基本使用
Bar.js 暴露方法和变量 可以通过module.exports和exports.属性暴露。
const name = 'xiaoming';
const age = 18;
const sayHello = ()=>{
console.log('hello!!!');
}
console.log(exports) //{} 空对象
//方法一:
module.exports = {
name,age,sayHello
}
//方法二:
exports.name = name;
exports.age = age;
exports.sayHello = sayHello;
Main.js
const Person = require('./Bar')
console.log(Person.name); //xiaoming
console.log(Person.age); //18
Person.sayHello(); //hello!!!
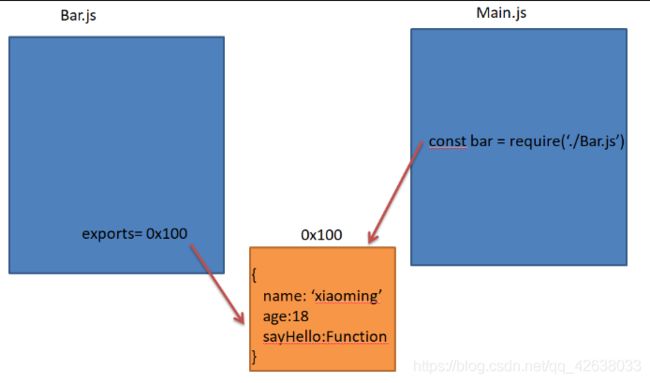
require(’./Bar’)引入的bar其实是Bar.js中暴露出的对象exports的一个浅拷贝(引用赋值)。
当修改bar中的name值时,Bar.js暴露的exports对象中的name也跟着改变。
module.exports和exports的区别
在Node中我们经常使用module.exports导出,这两种方式有什么区别呢?
CommentJS中是没有module.pexorts的概念的,但是为了实现模块的导出,Node中使用的是Module的类,每一个模块都是Module的示例,也就是module。
所以在Node中真正用于导出的其实根本不是exports,而是module.exports。因为module才是导出的真正实现者。
为什么exports也可以导出呢?
这是因为module对象的exports属性是exports对象的一个引用。
也就是说 exports=module.exports
Bar.js
const name = 'xiaoming';
const age = 18;
const sayHello = ()=>{
console.log('hello!!!');
}
const car = '奥迪';
const color = 'red';
const sayRun = () =>{
console.log('红色的奔驰嗖嗖的跑');
}
module.exports = {
car,color,sayRun
}
exports.name = name;
exports.age = age;
exports.sayHello = sayHello;
Main.js
const bar = require('./Bar')
console.log(bar); //{ car: '奥迪', color: 'red', sayRun: [Function: sayRun] }
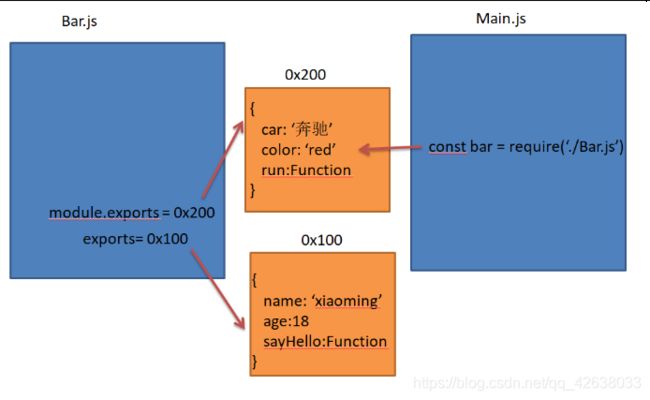
require的值最终取决于module.exports暴露的对象。当设置了module.exports就不带exports玩了。
强调一次:exports =module.exports 。
Bar.js
//module.exports = exports 先执行的
exports = 123
Main.js
const bar = require('./Bar')
console.log(bar); //{}
初始状态,exports默认为{}空对象。module.exports = exports
 exports = 123时,因为123是值传递所以直接把地址改成值。取消了对{}的引用。但是不影响module.exports的指向。
exports = 123时,因为123是值传递所以直接把地址改成值。取消了对{}的引用。但是不影响module.exports的指向。

require的细节
require是一个函数,可以帮助我们引入一模块中导出的对象。
总结一下比较常见的查找规则:导入格式如下:require(X)
情况一:X是一个核心模块,比如path、http,直接返回核心模块,并且停止查找。
情况二:X是以./或…/或/(根目录)开头的
第一步:将X当做一个文件在对应的目录下查找;
如果有后缀名,按照后缀名的格式查找对应的文件
如果没有后缀名,则先查找文件X,没有就查找X.js文件,再查找X.json文件,最后查找X.node文件。
第二步:没有找到对应的文件,将X作为一个目录
查找目录下面的index文件,没有就查找X/index.js文件,X/index.json文件,X/index.node文件。
都没有找到就返回not found。
情况三:直接是一个X(没有路径)类似情况一,但是X也不是核心模块。
paths: [
'D:\\qdcode\\node.js\\01-CommonJs\\node_modules',
'D:\\qdcode\\node.js\\node_modules',
'D:\\qdcode\\node_modules',
'D:\\node_modules'
]
它会逐层查找node_modules,知道找到X为止,找不到就not found错误
模块的加载过程
结论一:模块在被第一次引用时,模块中的js代码会被运行一次。
bar.js
const name = 'xiaoming';
const age = 18;
const sayHello = ()=>{
console.log('hello!!!');
}
exports = {
name,age,sayHello
}
console.log('bar运行了');
foo.js
const bar = require('./bar')
![]()
结论二:模块被多次引入时,会缓存,最终只加载(运行)一次
这是因为每个模块对象module都有一个属性:loaded。如果loaded为false表示模块还没有加载,为true则表示已经加载了。
bar.js
const name = 'xiaoming';
const age = 18;
const sayHello = ()=>{
console.log('hello!!!');
}
exports = {
name,age,sayHello
}
console.log(module); //打印module查看loaded的状态
console.log('bar运行了');
foo.js 引入两次bar模块,最终只执行一次bar.js代码
require('./bar')
console.log(module);//打印module查看loaded的状态
require('./bar')
下面为命令行的结果
PS D:\qdcode\node.js\01-CommonJs> node .\foo.js
<ref *1> Module {
id: 'D:\\qdcode\\node.js\\01-CommonJs\\bar.js',
path: 'D:\\qdcode\\node.js\\01-CommonJs',
exports: {
},
parent: Module {
id: '.',
path: 'D:\\qdcode\\node.js\\01-CommonJs',
exports: {
},
parent: null,
filename: 'D:\\qdcode\\node.js\\01-CommonJs\\foo.js',
loaded: false, //这里没有加载bar模块,为bar.js打印的结果
children: [ [Circular *1] ],
paths: [
'D:\\qdcode\\node.js\\01-CommonJs\\node_modules',
'D:\\qdcode\\node.js\\node_modules',
'D:\\qdcode\\node_modules',
'D:\\node_modules'
]
},
filename: 'D:\\qdcode\\node.js\\01-CommonJs\\bar.js',
loaded: false,
children: [],
paths: [
'D:\\qdcode\\node.js\\01-CommonJs\\node_modules',
'D:\\qdcode\\node.js\\node_modules',
'D:\\qdcode\\node_modules',
'D:\\node_modules'
]
}
bar运行了
<ref *1> Module {
id: '.',
path: 'D:\\qdcode\\node.js\\01-CommonJs',
exports: {
},
parent: null,
filename: 'D:\\qdcode\\node.js\\01-CommonJs\\foo.js',
loaded: false,
children: [
Module {
id: 'D:\\qdcode\\node.js\\01-CommonJs\\bar.js',
path: 'D:\\qdcode\\node.js\\01-CommonJs',
exports: {
},
parent: [Circular *1],
filename: 'D:\\qdcode\\node.js\\01-CommonJs\\bar.js',
loaded: true, //这里的bar模块已经加载,修改为true不会重复加载
children: [],
paths: [Array]
}
],
paths: [
'D:\\qdcode\\node.js\\01-CommonJs\\node_modules',
'D:\\qdcode\\node.js\\node_modules',
'D:\\qdcode\\node_modules',
'D:\\node_modules'
]
}
结论三: 如果有循环引入,那么加载顺序是什么?
如图
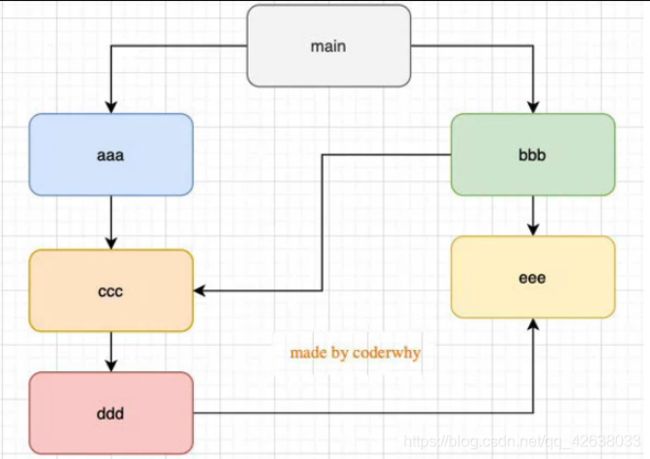
这种模块的引用关系,加载的顺序是什么呢?
这个其实是一个中图结构。Node采用的深度优先算法:main -> aaa -> ccc -> ddd -> eee -> bbb
CommonJS规范的缺点
CommonJS加载模块是同步的:
同步意味着只有等到对应的模块加载完毕,当前模块中的内容才能被运行;这个在服务器不会有什么问题,因为服务器加载js文件都是本地文件,加载速度非常快。
但是在浏览器加载js文件需要从服务器将文件下载下来,之后再加载运行;那么采用同步的commonJS就意味着后续的js代码都无法正常运行,即时是一些简单的DOM操作。
所以在浏览器中,我们通常不使用CommonJS规范。webpack中使用CommonJS除外,因为它会将我们的代码转化成浏览器可以直接执行的代码。
ES Module
js没有模块化一直是它的痛点,所以才会产生CommonJS。但是ES Module推出后弥补了这一缺点。
它采用编译器的静态分析,并且也加入了动态引入的方式。
ES Module模块采用export和import关键字来实现模块化
- export负责将模块内的内容导出
- import负责从其他模块导入内容
采用ES Module将自动采用严格模式:use strict
基本使用
在html引入script时要把type设置成module,声明它是一个模块
<script src="./bar.js" type="module"></script>
<script src="./foo.js" type="module"></script>
把js的后缀名修改为mjs否则会报错
(node:4288) Warning: To load an ES module, set "type": "module" in the package.json or use the .mjs extension.
(Use `node --trace-warnings ...` to show where the warning was created)
D:\qdcode\node.js\03-esModules\foo.js:2
import {
name,age,play} from './bar.js '
bar.mjs导出变量与方法
const name ='张三';
const age = 18;
export const hoddy = 'dsf'
function play(){
console.log(name + '喜欢玩');
}
export {
name,age,play
}
foo.mjs引用变量与方法
import {
name,age,play,hoddy} from './bar.mjs '
console.log(name,age,hoddy);
play();
default默认导出用法
默认到处export时可以不需要指定名字,在导入时不需要使用{},并且可以自己来指定名字。它也方便我们和现有的CommonJS等规范互相操作。
在一个模块中,只能有一个默认导出(default export)
import函数
通过import加载一个模块,是不可以放到逻辑代码中的
因为ES Module在被JS引擎解析时,必须知道它的依赖关系。由于这个时候js代码没有任何的运行,所以无法在进行类似于if判断中根据代码的执行情况
if(true){
import bar from './bar.js'
}
如果根据不同的条件,动态选择加载路径。这个时候我们可以使用import()函数来动态加载,它返回的是一个promise
foo.mjs
if (true) {
const response = import('./bar.mjs ')
response.then((data) => {
const {
name,age,play,hoddy} = data;
console.log(name, age, hoddy);
play();
})
}
bar.mjs不变。
画图理解
bar.mjs
const name ='张三';
const age = 18;
const car ={
color:'red'
}
export {
name,age,car
}
foo.mjs
import {
name,age,car} from './bar.mjs '
console.log(name);
console.log(age);
console.log(car);
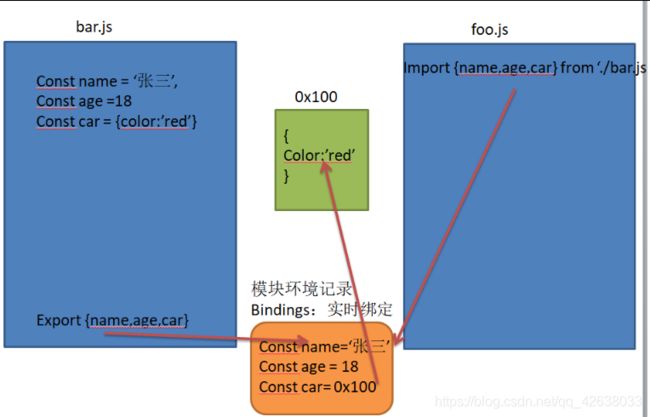
当修改bar.js中的值时,foo.js获取到的值也会随之更新。当bar的值修改时,模块环境记录会用新的值把以前的值给替换掉,生成新的const常量值。
但是foo.js中引入的值不可修改,直接修改foo引入的值不会通过模块环境记录修改,而是直接修改const常量值。从而报错TypeError: Assignment to constant variable.,常量值不可修改。
但是可以修改对象引用类型。
bar.mjs
const name ='张三';
let age = 18;
const car ={
color:'red'
}
setTimeout(() => {
age = 19
}, 1000);
export {
name,age,car
}
foo.mjs
import {
name,age,car} from './bar.mjs '
// name = '12'
car.name = '奔驰'
console.log(name);
console.log(age);
console.log(car);
setTimeout(() => {
console.log(age);
}, 2000);
输出结果
张三
18
{
color: 'red', name: '奔驰' }
19
加载过程
ES Module加载js文件的过程是编译时加载的,并且是异步的:
编译时加载,意味着import不能和运行时相关的内容放在一起使用。
异步的意味着:JS引擎在遇到import时会去获取这个js文件,但是这个获取的过程是异步的,不会阻塞主线程继续执行;
也就是说设置了type=module的代码,相当于在script标签上也加上了async属性;
如果我们后面有普通的srcipt标签以及对于的代码,那么ES Moudle对应的js文件和代码不会阻塞它们的执行;
<script src="./bar.mjs" type="module"></script>
<script src="./foo.mjs" ></script> //不会影响这个js的执行
CommonJS和ES Module交互
结论一: 通常情况下,CommonJS不能加载ES Module
因为CommonJS是同步加载的,但是ES Module必须经过静态分析等,无法在这个时候执行js代码。
但是这个并非绝对的,某些平台在实习的时候可以对代码进行针对性解析,也可能会支持。但是node中是不支持的。
结论二 :多数情况下,ES Module可以加载CommentJS
ES Module在加载CommonJS时,会将其module.exports导出的内容作为default导出方式使用;
这个依然需要看具体的实现,比如webpack中是支持的、node也是支持的。
但是要注意使用commonJS时要把后缀mjs换成js
export和import结合使用
export {name} from './bar.js
在开发和封装一个功能库时,通常我们希望将暴露的所有接口放到一个文件中,这样方便指定统一的接口规范。
常用的内置模块
path路径和文件进行处理
在Mac OS 、Linux和window上的路径表示不一样
- window上回使用 \ 或者 \\ 来作为文件路径的分隔符,目前也支持/ 。
- 但是在Mac OS 、Linux的Unix操作系统上使用/来作为文件路径的分隔符。
如果在window使用 \ 作为分隔符开发了一个应用程序,要部署到Linux上面显示路径可能会出现一些问题。
所以为了屏蔽他们之间的差异,在开发中对于路径的操作我们可以使用path模块
path常用API
从路径中获取信息
dirname:获取文件的父文件夹
basename:获取文件名
extname:获取文件扩展名
路径的拼接
如果我们希望将多个路径进行连接,但是不同的操作系统可能使用的是不同的分隔符。这个时候我们可以使用path.join函数。
将文件和某个文件夹拼接
如果我们希望某个文件和文件夹拼接,可以使用 path.resovle。
它会判断我们拼接的路径前面是否有 ./ 或者 . ./ 或者 / 。 如果有就把./ 或者 . ./ 或者 / 转为为实际的路径,返回对应的拼接路径。如果没有那么会和当前执行文件所在的文件夹进行路径的拼接。
const path = require('path');
let path1 = '../01-CommonJs'
let path2 = 'path.js'
let resultPath = path.resolve(path1,path2);
console.log(path.join(path1,path2));
console.log(path.resolve(path1,path2));
console.log(path.dirname(resultPath));
console.log(path.basename(resultPath));
console.log(path.extname(resultPath));
//..\01-CommonJs\path.js
//D:\qdcode\node.js\02-内置模块\01-CommonJs\path.js
//D:\qdcode\node.js\02-内置模块\01-CommonJs
//path.js
//.js
在webpack中获取路径或者起别名的地方可以使用
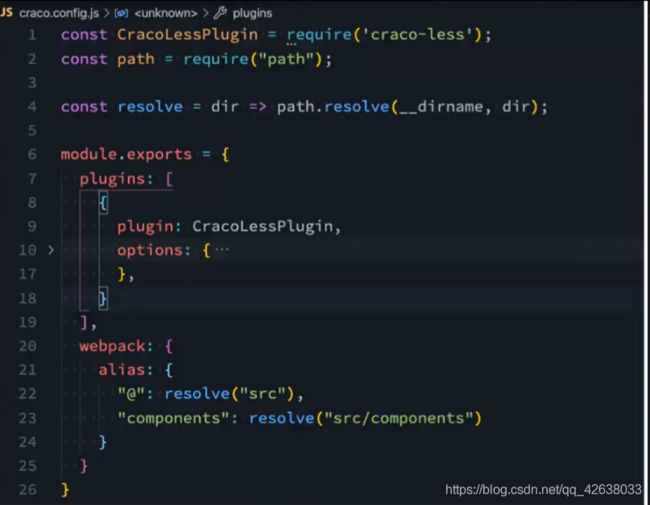
fs文件系统
借助于node帮我们封装的文件系统,我们可以在任何的操作系统上面直接去操作文件;这也是node可以开发服务器的一大原因,也是它可以成为前端自动化脚本等热门工具的原因。
fs的API大多数都提供了三种操作方式:
1.同步操作文件:代码会被阻塞,不会执行
2.异步回调函数操作系统:代码不会被阻塞,需要传入回调函数。当获取到结果时,回到函数被执行。
3.异步Promise操作方式:代码不会被阻塞,通过fs.promises调用方法操作,会返回一个porimse。可以通过then、catch进行处理。
stat获取一个文件的状态
const fs = require('fs');
//同步方式
const state = fs.statSync('./abc.txt');
console.log(state);
//异步回调方式
fs.stat('./abc.txt',(err,state)=>{
console.log(state);
})
//promise
fs.promises.stat('./abc.txt').then((state)=>{
console.log(state);
console.log(state.isDirectory());
}).catch((err)=>{
console.log(err);
})
Stats {
dev: 1916129544,
mode: 33206,
nlink: 1,
uid: 0,
gid: 0,
rdev: 0,
blksize: 4096,
ino: 17169973581082606,
size: 0,
blocks: 0,
atimeMs: 1626507722721.5305,
mtimeMs: 1626507722721.5305,
ctimeMs: 1626507722721.5305,
birthtimeMs: 1626507722721.5305,
atime: 2021-07-17T07:42:02.722Z,
mtime: 2021-07-17T07:42:02.722Z,
ctime: 2021-07-17T07:42:02.722Z,
birthtime: 2021-07-17T07:42:02.722Z
}
false
文件描述符 fs.open()
在POSIX系统上,对于每个进程,内核都维护着一张当前打开着的文件和资源的表格。
每个打开的文件都分配了一个称为文件描述符的简单的数字标识符。
在系统层,所有文件系统操作都使用这些文件描述符来标识和跟踪每个特定的文件。
Windows系统使用了一个虽然不同但概念上类似的机制来跟踪资源。
为了简化用户的工作,node.js抽象出操作系统之间的特定差异,并未所有打开的文件分配一个数字型的文件描述符。
fs.open()方法用户分配新的文件描述符
一旦被分配,则文件描述符可用于从文件读取数据、向文件写入数据、或请求关于文件的信息
fs.open('./abc.txt',(err,fd)=>{
console.log(fd); //获取文件描述符
fs.fstat(fd,(err,state)=>{
console.log(state);
})
})
任何操作都需要获取文件描述符。fstat就是需要文件描述符才可以获取文件的夹的状态信息,fs.stat(),fs.writeFile()、fs.readFile()都是基于fs.open()的
下面为结果
3
Stats {
dev: 1916129544,
mode: 33206,
nlink: 1,
uid: 0,
gid: 0,
rdev: 0,
blksize: 4096,
ino: 17169973581082606,
size: 0,
blocks: 0,
atimeMs: 1626507722721.5305,
mtimeMs: 1626507722721.5305,
ctimeMs: 1626507722721.5305,
birthtimeMs: 1626507722721.5305,
atime: 2021-07-17T07:42:02.722Z,
mtime: 2021-07-17T07:42:02.722Z,
ctime: 2021-07-17T07:42:02.722Z,
birthtime: 2021-07-17T07:42:02.722Z
}
文件的读写 fs.writeFile fs.readFile()
在文件中写入内容:fs.writeFile(file, data[, options], callback)
读取文件中的内容: fs.readFile(path[, options], callback)
fs.writeFile('./abc.txt','写入的内容',{
flag: 'a',encoding: "utf-8"},(err)=>{
console.log(err);
})
fs.readFile('./abc.txt',{
encoding: "utf-8"},(err,value)=>{
console.log(value);
})
// null 写入的内容写入的内容
flag的参数
'a': 打开文件进行追加。 如果文件不存在,则创建该文件。
'ax': 类似于 'a' 但如果路径存在则失败。
'a+': 打开文件进行读取和追加。 如果文件不存在,则创建该文件。
'ax+': 类似于 'a+' 但如果路径存在则失败。
'as': 以同步模式打开文件进行追加。 如果文件不存在,则创建该文件。
'as+': 以同步模式打开文件进行读取和追加。 如果文件不存在,则创建该文件。
'r': 打开文件进行读取。 如果文件不存在,则会发生异常。
'r+': 打开文件进行读写。 如果文件不存在,则会发生异常。
'rs+': 以同步模式打开文件进行读写。 指示操作系统绕过本地文件系统缓存。
这主要用于在 NFS 挂载上打开文件,因为它允许跳过可能过时的本地缓存。 它对 I/O 性能有非常实际的影响,因此除非需要,否则不建议使用此标志。
这不会将 fs.open() 或 fsPromises.open() 变成同步阻塞调用。 如果需要同步操作,应该使用类似 fs.openSync() 的东西。
'w': 打开文件进行写入。 创建(如果它不存在)或截断(如果它存在)该文件。
'wx': 类似于 'w' 但如果路径存在则失败。
'w+': 打开文件进行读写。 创建(如果它不存在)或截断(如果它存在)该文件。
'wx+': 类似于 'w+' 但如果路径存在则失败。
文件夹操作
新建一个文件夹fs.mkdir()或者fs.mkdirSync()
fs.mkdir('../fs/new',(e)=>{
console.log(e);
})
递归获取文件夹内所有文件
const fs = require('fs');
const path = require('path')
function readFolders(folder){
fs.readdir(folder,{
withFileTypes:true},(err,files)=>{
files.forEach(file=>{
if(file.isDirectory()){
const mikPath = path.resolve(folder,file.name)
readFolders(mikPath)
}else{
console.log(file);
}
})
})
}
readFolders('../fs')
认识流
程序中的流我们可以想象,从一个文件中读取数据时,文件的字节数据会源源不断的被读取到我们程序中。
流是连续字节的一种表现形式和抽象概念,流应该是可读的,也是可写的。
流和readFile或者writeFile方式读写文件有什么区别?
直接读写文件的方式,虽然简单,但是无法控制一些细节的操作,比如从什么位置开始读、读到什么位置、一次性读取多少个字节。读到某个位置后,暂停读取,某个时刻恢复读取等等。或者这个文件非常大,比如一个视频,一次性全部读取并不合适。
事实上node中很多对象都是基于流实现的。
http模块的esquest和response对象
process.stdout对象
node.js中有四种基本流类型:
writable:可以向其写入数据的流(比如fs.createWriteStream())。
readable:可以从中读取数据的流(例如fs.createReadStream())。
duplex:同时为Readable和的流writable(例如net.Socket)。
transform:Duplex可以在写入和读取数据时修改或转换数据的流(比如zlib.createDeflate())。
createReadStream(Readable)
我们可以使用createReadStream解决一次性将一个文件中所有的内容都读取内容中引发的文件过大、读取的位置、结束的位置、一次读取的大小无法确定的问题。
start:文件读取开始的位置
end:文件读取结束的位置
highWaterMark:一次性读取字节的长度。
const fs = require('fs')
const reader = fs.createReadStream('./abc.txt',{
start:2,end:6,highWaterMark:2})
reader.on('data',(data)=>{
console.log(data);
reader.pause();
setTimeout(() => {
//每次读取暂停一秒
reader.resume()
}, 1000);
})
reader.on('open',()=>{
console.log('文件被打开');
})
reader.on('close',()=>{
console.log('文件被关闭');
})
createWriteStream (Writerable)
const writer = fs.createWriteStream('./abc.txt',{
flags: 'a',start:4});
writer.write('你好啊');
writer.write('小明');
// writer.close(); //关闭写入
writer.end('写入最后一句话,并且关闭写入');
events模块
node中的核心API都是基于异步事件的驱动:
在这个体系中,某些对象(发射器(Emitters))发出某个事件。
我们可以监听这个事件(监听器Listeners),并且传入的回调函数,这个回调函数会在监听到事件时调用;
发出事件和箭监听事件都是通过EventEmitter类来完成的,它们都属于events对象。
emitter.on(eventName,listener):监听事件,也可以使用addListener。
emitter.off(eventName,listener):移除事件监听,也可以使用removeListener。
emitter.emit(eventName[,…args]):发出事件,可以携带一些参数
const EventEmitter = require('events');
const emitter = new EventEmitter();
emitter.on('click',(name)=>{
console.log(name);
})
setTimeout(()=>{
emitter.emit('click','zhangsan');
},1000)
console.log(emitter.eventNames());//返回当前EventEmitter对象注册的事件字符串数组
console.log(emitter.getMaxListeners());//返回当前EventEmitter对象的最大监听器数量
console.log(emitter.listenerCount('click'));//返回当前EventEmitter对象某一个事件名称,监听器个数。
console.log(emitter.listeners('click'));//返回当前EventEmitter对象某个事件监听器上所有的监听器数组
emitter.once事件监听一次
emitter.prependListener:将监听事件添加到最前面
emitter.prependOnceListener():将监听事件添加到最前面,但是只监听一次
emitter.removeAllListeners():移除所有的监听器
url模块
下面介绍方法有parse,format,resolve。还有URLSearchParams对象。
const url = require('url');
const log4js = require('log4js');
log4js.configure({
appenders: {
fileout: {
type: "file",
filename: "fileout.log"
},
datafileout: {
type: "dateFile",
filename: "datafileout.log",
pattern: ".yyyy-MM-dd-hh-mm-ss-SSS"
},
consoleout: {
type: "console"
},
},
categories: {
default: {
appenders: ["fileout", "consoleout"],
level: "debug"
},
anything: {
appenders: ["consoleout"],
level: "debug"
}
}
});
let logger = log4js.getLogger('debug');
// logger.info("info")
// logger.warn("info")
// logger.error("error")
// logger.fatal("fatal")
const urlString = 'https://www.baidu.com:443/ad/index.html?id=8&name=mouse#tag=110';
const urlObj ={
protocol: 'https:',
slashes: true,
auth: null,
host: 'www.baidu.com:443',
port: '443',
hostname: 'www.baidu.com',
hash: '#tag=110',
search: '?id=8&name=mouse',
query: 'id=8&name=mouse',
pathname: '/ad/index.html',
path: '/ad/index.html?id=8&name=mouse',
href: 'https://www.baidu.com:443/ad/index.html?id=8&name=mouse#tag=110'
}
logger.debug(url.parse(urlString)) //把url解析成对象
logger.debug(url.format(urlObj)); //把解析对象还原成url
logger.debug(url.resolve);
logger.debug(new url.URLSearchParams(urlObj.search)); //把?id=8&name=mouse 参数转换为对象
var a = url.resolve('/one/two/three', 'four')
var b = url.resolve('http://example.com/', '/one')
var c = url.resolve('http://example.com/one', '/two')
logger.debug(a + "," + b + "," + c)
输出的日志为:
[2021-07-14T17:52:19.950] [DEBUG] debug - Url {
protocol: 'https:',
slashes: true,
auth: null,
host: 'www.baidu.com:443',
port: '443',
hostname: 'www.baidu.com',
hash: '#tag=110',
search: '?id=8&name=mouse',
query: 'id=8&name=mouse',
pathname: '/ad/index.html',
path: '/ad/index.html?id=8&name=mouse',
href: 'https://www.baidu.com:443/ad/index.html?id=8&name=mouse#tag=110'
}
[2021-07-14T17:53:40.663] [DEBUG] debug - https://www.baidu.com:443/ad/index.html?id=8&name=mouse#tag=110
[2021-07-14T17:57:01.612] [DEBUG] debug - URLSearchParams {
'id' => '8', 'name' => 'mouse' }
[2021-07-14T18:00:10.904] [DEBUG] debug - /one/two/four,http://example.com/one,http://example.com/two
querystring模块
const querystring = require('querystring');
const query ='id=8&name=mouse';
const queryObj = {
id: '8', name: 'mouse' };
const queryEscape ='id%3D8%26name%3Dmouse'
console.log(querystring.parse(query)); //{ id: '8', name: 'mouse' }
console.log(querystring.stringify(queryObj)); //id=8&name=mouse
console.log(querystring.escape(query)); //id%3D8%26name%3Dmouse
console.log(querystring.unescape(queryEscape)); //id=8&name=mouse
http 模块
Web服务器
当应用程序(客户端)需要某一个资源时,可以通过http请求向一台服务器获取到这个资源。提供资源的这个服务器,就是一个Web服务器。
 目前很多开源的web服务器:Nginx、Apache(静态)、Apache Tomcat(静态、动态)、node.js
目前很多开源的web服务器:Nginx、Apache(静态)、Apache Tomcat(静态、动态)、node.js
创建服务器的两种方式
创建服务器的两种方式,这两种方式实际上是一样的。都是new Server类的方式创建服务器。
server.listen方法监听服务器
监听成功后可以在createServer的回调函数中操作
const http = require('http')
const server1 = http.createServer((request,response)=>{
response.end('server1 response')
})
server1.listen('8000','localhost',()=>{
console.log('服务器1开启成功');
})
const server2 = new http.Server((request,response)=>{
response.end('server2 response')
});
server2.listen('8001','localhost',()=>{
console.log('服务器2开启成功');
})
nodemon
全局下载 nodemon当代码改变后不需要手动重启服务器
使用url和querystring获取参数
输入地址 http://localhost:8000/login?username=zhangsan&password=123
const http = require('http');
const url = require('url')
const qs = require('querystring')
const server = http.createServer((req, res) => {
//获取请求的地址
console.log(req.url); ///login?username=zhangsan&password=123
//获取url的pathname
console.log(url.parse(req.url));
/*
Url {
protocol: null,
slashes: null,
auth: null,
host: null,
port: null,
hostname: null,
hash: null,
search: '?username=zhangsan&password=123',
query: 'username=zhangsan&password=123',
pathname: '/login',
path: '/login?username=zhangsan&password=123',
href: '/login?username=zhangsan&password=123'
}
*/
const {
pathname, query} = url.parse(req.url);
//解析query获取参数
console.log(qs.parse(query)); //{ username: 'zhangsan', password: '123' }
const {
username,password} = qs.parse(query)
res.end(username + ' ' + password)
})
server.listen('8000', () => {
console.log('服务器开启');
})
post请求获取参数
如果是post的请求可以通过,http的on方法监听data事件。data事件的回调函数中可以获取传递的参数。获取到之后是Buffer数组,可以通过toString方法转换成字符串,也可以通过 req.setEncoding(‘utf-8’)转换字符串。最后通过JSON.parse把字符串转换为JSON对象
{
“username”:“zhangsan”,
“password”:“123”
}
const http = require('http')
const server = http.createServer((req, res) => {
if (req.method === 'POST') {
//拿到body中的数据
req.setEncoding('utf-8') //设置编码否则会出现Buffer数组 也可用toString方法转换
req.on('data', (data) => {
//获取到的是字符串类型
console.log(JSON.parse(data)); //{ username: 'zhangsan', password: '123' }
})
}
res.end()
})
server.listen('8000', () => {
console.log('开启服务器');
})
header属性
在request对象的header中包含很多有用的信息,客户端会默认传递过来。
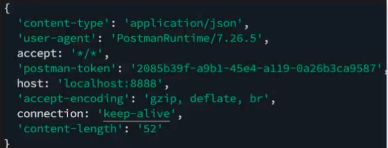
content-type是这次请求携带的数据的类型:
- application/json表示是一个json类型
- text/plain表示是文本类型
- application/xml表示是xml类型
- multipart/form-data表示是上次文件
content-length:文件的大小和长度
keep-alive:http是基于tcp协议的,但是通常在进行一次请求和响应结束后立即中断。在http1.1中,所有连接默认是connection:keep-alive的。不同的web浏览器会有不同的保持 keep-alive的时间,node中默认为5s
accept-encoding:告知服务器,客户端支持的文件压缩格式,比如js文件可以使用gzip编码,对应.gz文件
accept:告知服务器,客户端可接受文件的格式类型
user-agent:客户端相关的信息
设置请求头
res.setHeader(‘Content-Type’,‘text/plain’)
返回状态码
http状态码是用来标识http响应状态的数字代码
- http状态码非常多,可以根据不同的情况,给客户端返回不同的状态码

设置状态码
方式一:直接给属性赋值
res.statusCode = 400;
方式二:和Head一起设置
res.writeHead(503)
更多使用方法 http://nodejs.cn/api/
包管理工具
npm(Node Package Manage)
npm也就是Node包管理器,但是目前已经不仅仅是Node包管理器了,在前端项目中我们也在使用它来管理依赖的包。
比如express、koa、react、react-dom。
npm管理的包可以在https://www.npmjs.com/ 查看搜索
我们发布自己的包其实是发布到registry上面的,当我们安装一个包时其实是从registry上面下载的包。
npm install命令
安装npm包会分为两种情况
- 全局安装:npm install yarn -g
- 局部安装:npm install axios
卸载某个依赖包 npm uninstall package
强制重新build npm rebuild
清除缓存 npm cache clean
全局安装
全局安装是直接将某个包安装到全局
比如yarn的全局安装
npm install yarn -g
通常使用npm全局安装的包都是一些工具包:yarn、webpack等。主要安装的是在终端使用的包。
并不是类似于axios、express、koa等库文件
所以全局安装了之后并不能让我们在所有的项目中使用axios等库。
局部安装
局部安装会在当前目录下产生一个node_modules文件夹。
局部安装分为开发时依赖和生产时依赖:
安装开发和生产依赖 npm i axios
开发依赖npm i webpack -D
根据package.json中的依赖包 npm install
npm install 原理
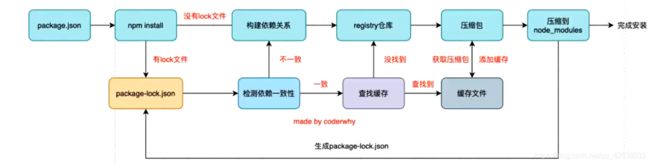 npm install 会检测是否有package-lock.json文件:
npm install 会检测是否有package-lock.json文件:
没有lock文件
- 分析依赖关系,这是因为可能包会依赖其他的包,并且多个包之间会产出相同依赖的情况。
- 从registry仓库中下载压缩包,如果设置了镜像,就从镜像服务器下载
- 获取到压缩包后会对压缩包进行缓存(从npm5开始有的)
- 将压缩包解压到node_modules文件中
有lock文件
- 检测lock包的版本时候和package.json中一致(如果不一致,会重新构建依赖关系,直接从顶层的流程)
- 一致的情况下,会去优先查找缓存(如果没有,从registry仓库下载,直接走顶层流程)
- 找到后,会获取缓存中的压缩文件,并解压到node_modules文件夹中。
yarn 工具
yarn是为了弥补npm的一些缺陷而存在的,早期npm存在很多的缺陷,比如安装依赖速度很慢,版本依赖混乱等一系列问题。但从npm5版本开始,进行了很多的升级和改进,但是依然很多人喜欢使用yarn
npm install yarn -g 全局安装
yarn 命令和npm对比

项目配置文件
我们每个项目都会有一个对应的配置文件,无论是前端项目还是后端项目。
这个配置文件会记录着你项目的名称、版本号、项目描述等。也会记录你项目所依赖的其他库的信息和依赖库的版本号。
这个配置文件在node环境下面就是package.json。
常见属性
必填写属性:name、version
- name是项目的名称
- version是当前项目的版本号
- description是描述信息,很多时候是作为项目的基本描述
- author是作者相关信息(发布时用到)
- license是开源协议(发布时用到)
private属性:
- private属性记录当前的项目是否是私有的
- 当值为true时,npm是不能发布它的,这是防止私有项目或模块发布出去的方式。
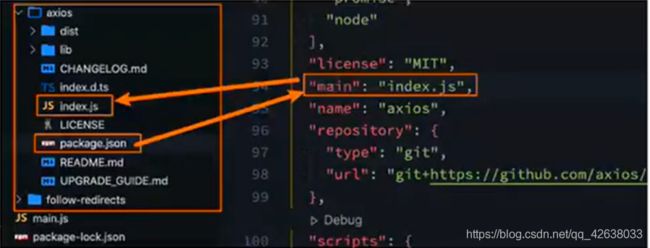
main属性:
设置程序的入口。
很多人会有疑惑,webpack不是会自动找到程序的入口吗?
这个入口和webpack打包的入口并不冲突,它是在发布一个模块的时候会用到。比如我们使用axios模块 const axios = require(‘axios’),实际上是通过找对应的main属性查找文件的
scripts属性
scripts属性用于配置一些脚本命令,以键值对的形式存在。
配置后可以通过npm run key的方式执行。
npm state和npm run start是对等的,对于start、test、stop、restart可以绳轮run直接运行。
dependencies属性
dependencies属性是指定无论开发环境还是生产环境都需要依赖的包。
通过是我们项目实际开发用到的一些库模块。
devDependencies属性
一些包在生产环境是不需要的,比如webpack、babel等
这个时候我们通过npm install webpack --save-dev,将它安装到devDependencies属性中。
engines属性
- engines属性用于指定node和npm的版本号。
- 在安装的过程中,会先检查对应的引擎版本,如果不符合就会报错
- 事实上也可以指定所在的操作系统 os:[‘darwin’,‘linux’],只是很少用到。
browserslist属性
- 用于配置打包后的js浏览器的兼容情况
- 否则我们需要手动的添加polyfills来让支持某些语法。
- 也就是说它是webpack等打包工具服务的一个属性
版本管理问题
我们会发现安装依赖版本出现^ 2.0.3 或~ 2.0.3这是什么意思呢?
npm的包通常需要遵循semver版本规范
semver版本规范是x.y.z:
- X主版本号(major):当你做了不兼容的API修改(可能不兼容之前的版本)。
- Y次版本号(minor):当你做了向下兼容的功能性新增(新功能增加,但是兼容之前的版本);
- Z修订号(patch):当你做了向下兼容的问题修正(没有新功能,但修复了之前版本的bug)
^x.y.z:表示x是保持不变的,y和z永远安装最新的版本
~x.y.z:表示x和y保持不变的,z永远安装最新的版本
package-lock.json
文件解析
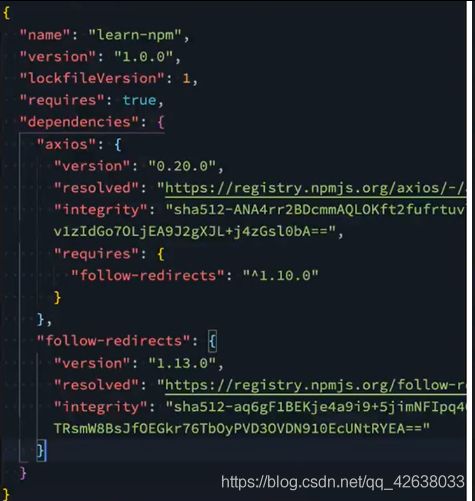
- name:项目的名称
- version:项目的版本
- lockfileVersion:lock文件的版本
- requires:使用requires来跟踪模块的依赖关系
- dependencies:项目的依赖
- 当前项目依赖axios,axios依赖follow-redireacts
- axios中的属性如下:
- version表示实际安装的axios版本
- resplved用于记录下载的地址,registry仓库的位置
- requires记录当前模块的依赖
- integrity用于从缓存中获取依赖,再通过索引去获取压缩包文件。
事件循环和浏览器执行
事件循环是什么?
我们编写JavaScript和浏览器或者node之间的一个桥梁。
浏览器的事件循环是一个我们编写的JavaScript代码和浏览器api调用(setTimeout/AJAX/监听事件)的一个桥梁,桥梁之间通过回调函数进行沟通。
node事件循环是一个我们编写的JavaScript代码和系统调用之间的一个桥梁,桥梁之间通过回调函数进行沟通。

进程和线程
线程和进程是操作系统的两个概念:
- 进程(process):计算机已经运行的程序
- 线程(thread):操作系统能够运行运算调度的最小单位。
进程我们可以认为,启动一个应用程序,就默认启动一个或多个进程。
每一个进程中都会启动一个线程用来执行程序中的代码,这个线程被称之为主线程、
所以我们也可以说进程是线程的容器。
操作系统类似于一个工厂
工厂中里面有很多车间,车间就是进程。
每个车间可能有一个以上的工人在工厂,这个工人就是线程
多进程多线程开发
操作系统是如何做到同时让多个进程同时工作的呢?
- 这是因为cpu的运算速度非常快,它可以快递的在多个进程之间迅速的切换。
- 当我们的进程中的线程获取到时间片时,就可以快速执行我们编写的代码。
- 对于用户来说是感受不到这种快递的切换的。
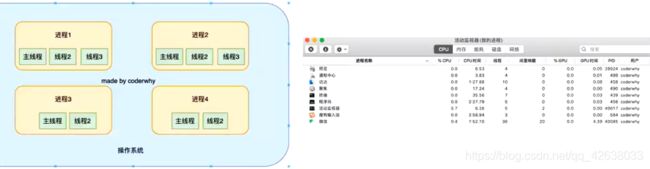
浏览器和JavaScript
我们经常说JavaScript是单线程的,但是JavaScript的线程应该有自己的容器进程:浏览器或者node
浏览器是一个进程吗,它里面只有一个线程吗?
- 目前多数的浏览器其实都是多进程的,当我们打开一个tab页面时就会开启一个新的进程,这是为了防止一个页面卡死而造成所有页面无法响应,整个浏览器需要强制退出
- 每个进程中有很多的线程,其中包括执行JavaScript代码的线程
但是JavaScript代码执行是在一个单独的线程中执行的:
- 这就意味着JavaScript的代码,在同一个时刻只能做一件事;
- 如果这个事是非常耗时的,就意味着当前的线程就会被阻塞。
JavaScript执行过程
const name = 'zhangsan';
console.log(name);
function sum (num1,num2){
return num1 + num2;
}
function bar (){
return sum(20,30);
}
const result = bar();
console.log(result);
分析代码的执行过程
- 定义变量name
- 执行log函数,函数会被放入函数调用栈中执行,执行完立即弹出
- 调用bar函数,压入栈
- 把sum压入栈中,运行完毕出栈。
- sum出栈,获取到结果
- log函数压入栈内打印最终结果出栈。
浏览器的事件循环
如果在JavaScript代码的过程中,有异步操作呢?
中间我们插入了一个setTimeout的函数调用。
这个函数被导入了调用栈中,执行会立即结束,并不会阻塞后续代码的执行。
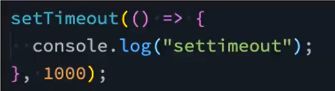
那么,传入的回调函数会在什么时候执行呢?
事实上,setTimeout是调用了web api,在合适的事迹,会将回调函数加入到一个事件队列(宏任务)中。
事件队列中的函数,会被放入到调用栈中,被执行
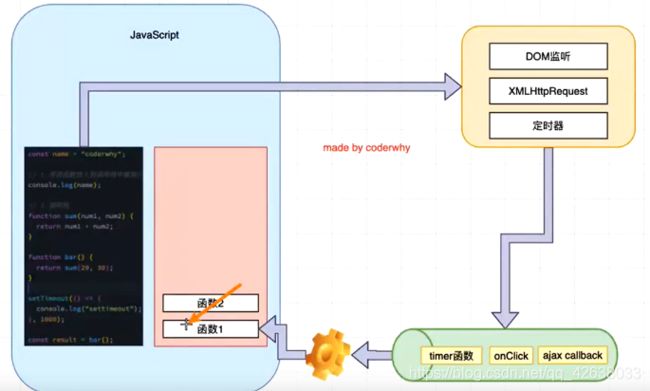
宏任务和微任务
事件循环中并非只维护着一个队列,事实上有两个队列
- 宏任务队列:ajax,setTimeout,setInterval、DOM监听、UI Rendering等。基本都是回调函数
- 微任务(microtask queue):Promise的then回调、Mutation Observer API、queueMicrotask()。
事件循环对于两个队列的优先级
- main script中的代码优先执行
- 在执行任何一个宏任务之前,都要先查看微任务队列中是否有任务需要执行。
也就是说宏任务执行之前,必须保持微任务队列是空的。
如果不为空,那么就优先执行微任务队列的任务(回调)。
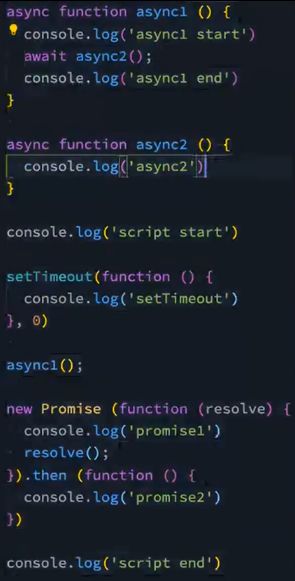
面试题
await代码同步执行,await下面的代码可以当成then回调中的代码。
node的架构分析
浏览器中的EventLoop是根据html5定义的规范来实现的,不同浏览器可能会有不同的实现,而node中中是由libuv实现的

libuv中主要维护了一个EventLoop和worker threads(线程池);
eventLoop负责调用系统的一些其他操作:文件的I/O、Network、child-processes等
libuv是一个多平台专注于异步IO库,它最初是为了Node开发的,但现在也被使用到Luvit、Julia、pyuv等其他地方。
阻塞IO和非阻塞IO
如果我们希望对程序中的一个文件进行操作,那么我们需要通过文件描述符打开这个文件。
JavaScript看起来可以直接对一个文件进行操作,但是事实上我们任何程序中的文件操作都是需要进行系统调用(操作系统的文件系统)。事实上对文件的操作,是一个操作系统的系统调用(IO系统)。
操作系统通常为我们提供了两种方式:阻塞式调用和非阻塞式调用:
阻塞式调用:调用结果返回之前,当前线程处于阻塞态(阻塞态cpu是不会分配时间片的),调用线程只有在得到调用结果之后才会继续执行
非阻塞式调用:调用执行之后,当前线程不会停止执行,只需要过一段时间来检查一下有没有结果返回即可。
所以我们开发中很多耗时操作,都可以基于这样的非阻塞式调用:
比如文件读写IO操作,我们可以使用操作系统提供的基于事件的回调机制。
比如网络请求本身使用了Socket通讯,而Socket本身提供了select模型,可以进行非阻塞方式的工作。
非阻塞io的问题
我们需要频繁的去确定读取到的数据是否是完整的,为了可以知道是否读取到了完整的数据。这个过程是轮询操作。
轮训操作由谁来完成?
如果我们的主线程频繁的去进行轮训的工作,那么必然会大大降低性能,并且开发中我们可能不是一个文件的读写,可能是多个文件。而且可能是多个功能:网络的IO、数据库的IO。
libuv提供了一个线程池(Thead Pool)
线程池会负责所有相关的操作,并且会通过轮训或者其他的方式等待结果。
当获取到结果时,就可以将对应的回调放到事件循环(某一个事件队列)中。
事件循环就可以负责接管后续的回调工作,告知JavaScript应用程序执行对应的回调函数。

阻塞非阻塞和同步异步的区别
阻塞和非阻塞式对于被调用者来说的,在我们这里就是系统调用,操作系统为我们提供了阻塞调用和非阻塞调用。
同步和异步是对于调用者来说的,在我们这里就是自己的程序,如果我们在发起调用之后,不会进行其他任何操作,只是等待结果,这个过程就被称之为同步调用。
如果我们再发起调用之后,并不会等待结果,继续完成其他的工作,等到有回调时再去执行,这个过程就是异步调用;
Libuv采用的就是非阻塞异步IO调用方式。
node事件循环的阶段
事件循环就像是一座桥梁,无论是我们的文件IO、网络IO、定时器、子进程,函数都会放到事件循环(任务队列)中。事件循环会不断的从任务队列中取出对应的事件(回调函数)来执行。
一次完整的事件循环Tick分成了很多个阶段:
- 定时器(Timers):本阶段执行已经被setTimeout和setInterval调度的回调函数。
- 待定回调(Pending Callback):对某些系统操作(如TCP错误类型)执行回调,比如TCP连接时接收到ECONNERFUSED.
- idle,prepare:仅系统内部使用。
- 轮训(Poll):检索新的I/O事件,执行与I/O相关的回调。
- 检测:setImmediate()回调函数在这里执行。
- 关闭的回调函数:一些关闭的回调函数。如:socket.on(‘close’,…)。
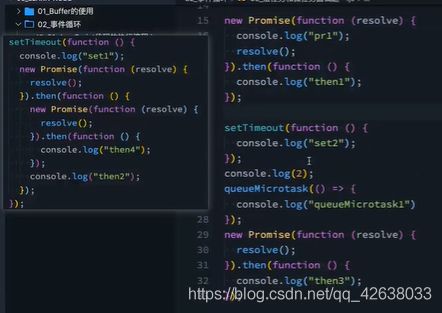
node的微任务和宏任务
我们会发现一次事件循环Tick来说,node的事件循环更复杂,它也分为微任务和宏任务。
宏任务:setTimeout,setInterval、IO事件、setImmediate、close事件
微任务:promise的then回调、process.nextTick、queueMicrotask。
但是,node的事件循环不只是微任务和宏任务队列。
执行顺序如下
微任务队列:
- next tick queue:process.nextTick
- other queue:Promise的then回调、queueMicrotask
宏任务队列:
- timer queue:setTimeout、setInterval
- poll queue:IO事件
- check queue:setImmediate
- close queue:close事件。
面试题1
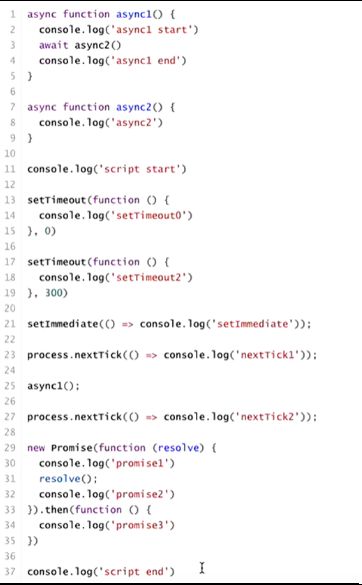 script start
script start
async1 start
async2
promise1
promse2
script end
nextTick1
nextTick2
async1 end
promise3
setTimeout0
setImmediate
setTimeout2
面试题2

情况一,如果事件循环开启的时间小于setTimeout函数的执行时间。也就意味着先开启了event-loop,这个时候定时器的回调函数没有进入事件队列中,但是setImmediate进入了。所以优先显示setImmediate等到下一次循环setTimeout的回调放入了事件队列中再显示setTimeout。
情况二:如果事件循环开启的事件大于setTimeout函数的执行时间。这一次setTimeout放入到了事件队列中,因为setTimeout的优先级大于setImmediate所以会优先显示setImmediate。
express
原生http在进行很多处理时,会比较复杂。
有URL判断,method判断,参数处理,逻辑代码处理等,都需要我们自己来处理和封装。
目前在node中比较流行的web服务器框架是express、koa
express早于koa出现,并且在node社区中迅速流行起来
我们可以基于express快速、方便的开发自己的web服务器,并且可以通过一些实用工具和中间件来扩展自己功能。
express的安装
express的使用过程有两种方式:
- 方式一:通过express提供的脚手架,直接创建一个应用的骨架。
- 方式二:从零搭建自己的express应用
方式一:安装express-generator
安装脚手架
npm install -g express-generator
创建项目
express express-demo
安装依赖
npm intall
启动项目
node bin/www
express的基本使用
第一步引入express
第二步执行express函数得到app对象
第三步通过对象的use方法或者post,get方法创建路由
第四部步listen方法监听服务器在哪个端口打开
const express = require('express')
const app = express();
app.use('/',(req,res,next)=>{
res.write('123');
next();
})
app.get('/',(req,res)=>{
res.end('123')
})
app.listen(8000,()=>{
console.log('服务器启动成功');
})
请求的路径中如果有一些参数
/users/:userId
在request对象中要获取可以通过req.params.userId的方式获取。
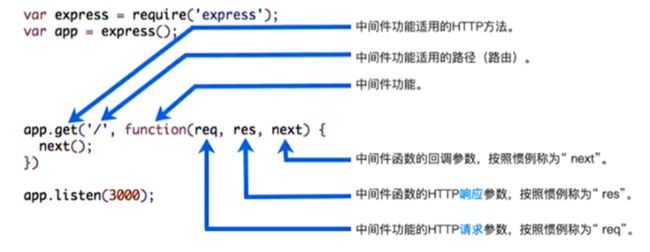
认识中间件
express是一个路由和中间件的web框架,它本身的功能非常少
express应用程序本质上是一系列中间件函数的调用
中间件是什么?
中间件的本质是传递给express的一个回调函数
这个回调函数接收三个参数
- 请求对象(request)
- 响应对象(response)
- next函数(在express中定义的用于执行一下个中间件的函数)
中间件中可以执行哪些任务?
- 执行任何代码
- 更改请求(request)和响应(response)对象
- 结束请求-响应周期(返回数据 end返回)
- 调用栈中的下一个中间件(next函数)
如果当前中间件功能没有结束请求-响应周期,则必须调用next()将控制权传递给下一个中间件功能,否则请求将被挂起。
应用中间件-自己编写
那么,如果将一个中间件应用到我们的应用程序中呢?
- express主要提供了两种方式:app/router.user和app/router.methods
- 可以试app,也可以是router
- methods指的是常用的请求方式,比如:app.get或app.post等
methods的方式本质是use的特殊情况
案例一:最普通的中间件
不管是什么请求都会经过普通中间件,有很多匹配的中间件时,默认只会匹配第一个中间件。想要经过后面的中间件要调用next()方法。
一般在最后的中间件调用end
const express = require('express');
const app = express();
app.use((req,res,next)=>{
res.write('第一个中间件')
next();
})
app.use((req,res,next)=>{
res.write('第二个中间件')
next();
})
app.use((req,res,next)=>{
res.write('第三个中间件')
res.end('结束了')
})
app.listen(8000,()=>{
console.log('服务器开启');
})
案例二:path匹配的中间件
use的第一个参数可以传递请求path路径,经过第一个普通中间件时有next()方法会继续向下执行,要是没有next只会经过第一个中间件。尽管请求的路径是/user,但是也会优先匹配普通中间件,因为普通中间件在前面
const express = require('express')
const app = express();
app.use((req, res, next) => {
console.log('第一个普通中间件');
next();
})
app.use('/user', (req, res, next) => {
console.log('第一个user中间件');
next();
})
app.use('/user', (req, res, next) => {
console.log('第二个user中间件');
res.end();
})
app.listen(8001,()=>{
console.log("服务器启动");
})
案例三:path和method匹配中间件
const express = require('express');
const app = express();
app.get('/article',(req,res,next)=>{
console.log('get请求 /article 中间件');
res.end();
})
app.post('/article',(req,res,next)=>{
console.log('post请求 /article 中间件');
res.end();
})
app.listen(8000,()=>{
console.log("服务器开启");
})
案例四:注册多个中间件
注册多个中间件时也要使用next()方法,否则只会调用第一个中间件。
const express = require('express')
const app = express();
app.get('/products',(req,res,next)=>{
//注册多个中间件与这种方式相同
console.log('中间件');
next();
})
app.get('/products',(req,res,next)=>{
console.log('第一个中间件');
next();
},(req,res,next)=>{
console.log('第二个中间件');
next();
},(req,res,next)=>{
console.log('第三个中间件');
next();
},(req,res,next)=>{
console.log('第四个中间件');
res.end()
})
app.listen(8000,()=>{
console.log('服务器开启');
})
应用中间件-body解析
并非所有的中间件都需要我们从零去编写:
- express有内置一些帮助我们完成对request解析的中间件。
- registry仓库中也有很多可以辅助我们开发的中间件
在客户端发送post请求时,会将数据放入body中:
- 客户端可以通过json的方式传递
- 也可以通过form表单的方式传递
编写中间件接收post的参数
通过编写中间件来判断请求是否是post请求,传递的参数是否为json数据。
要是要接收其他方式传递的数据需要继续使用if判断。
在第一个中间件接收之后,传入到request的body中。后面直接使用body即可获取传递的参数。
const express = require('express')
const app = express();
app.use((req,res,next)=>{
if(req.headers['content-type']==='application/json'){
req.on('data',(data)=>{
req.body = JSON.parse(data.toString());
console.log(req.body);
})
req.on('end',()=>{
next();
})
}else{
next();
}
})
app.post('/user',(req,res)=>{
const {
username,password} = req.body;
console.log(username+' '+password);
res.end();
})
app.listen(8888,()=>{
console.log('服务器开启');
})
应用中间件-express提供
但是,事实上我们可以使用express内置的中间件或者使用body-parser来完成
const express = require('express')
const app = express();
app.use(express.json()); //使用json传递参数
app.use(express.urlencoded({
extended:true}))//使用application/x-www-form-urlencoded传递参数
app.post('/user',(req,res,next)=>{
console.log(req.body);
res.end();
})
app.post('/user',(req,res,next)=>{
console.log(req.body);
res.end();
})
app.listen(8888,()=>{
console.log('启动服务器');
})
使用multer接收form-data类型
确保你总是处理了用户的文件上传。永远不要将multer作为全局中间件使用,因为恶意用户可以上传文件到一个你没有预料到的路由,应该只在你需要处理上传文件的路由上使用。
const express = require('express');
const multer = require('multer');
const app = express();
const upload = multer();
app.post('/login',upload.any(),(req,res,next)=>{
console.log(req.body);
res.end();
})
app.listen(8888,()=>{
console.log('服务器启动');
})
使用multer接收文件upload
const express = require('express');
const multer = require('multer');
const app = express();
const upload = multer({
dest: './picture'}); //配置文件上传路径
//upload.single('file')是连续注册中间件的应用
app.post('/upload',upload.single('file'),(req,res,next)=>{
console.log(req.file); //上传文件的信息
res.end();
})
app.listen(8888,()=>{
console.log('服务器启动');
})
//console.log(req.file) 上传文件的信息
{
fieldname: 'file',
originalname: 'adv.png',
encoding: '7bit',
mimetype: 'image/png',
destination: './picture',
filename: '8e10f4c84183e3af3ac7f88ec5251b42',
path: 'picture\\8e10f4c84183e3af3ac7f88ec5251b42',
size: 18596
}
但是上面的方式保存的文件没有后缀名,我们可以通过配置multer的方式来自动生成后缀名,或者文件名
query和params获取参数
const express = require('express');
const app = express();
app.get('/user/:id/:name',(req,res,next)=>{
//http://localhost:8888/user/1/zhangsan
console.log(req.params); //{ id: '1', name: 'zhangsan' }
res.end()
})
app.get('/login',(req,res,next)=>{
//http://localhost:8888/login?username=123&password=123
console.log(req.query); //{ username: '123', password: '123' }
res.end()
})
app.listen(8888,()=>{
console.log('服务器启动');
})
响应返回数据和响应码
const express = require('express');
const app = express();
app.get('/user/:id/:name',(req,res,next)=>{
//http://localhost:8888/user/1/zhangsan
console.log(req.params); //{ id: '1', name: 'zhangsan' }
const {
id,name} = req.params
res.status(404);
res.json({
userId: id,username:name})//返回json数据
})
app.listen(8888,()=>{
console.log('服务器启动');
})
express的路由
如果我们把所有代码逻辑都在app中,那么app会变得越来越复杂。
- 一方面完整的web服务器包含非常多的处理逻辑
- 另一方面有些处理逻辑其实是一个整体,我们应该把它们放在一起:比如对users相关的处理
获取用户列表
获取某个用户信息
创建一个新用户
删除一个用户
更新一个用户
我们可以使用express.Router来创建一个路由处理程序
一个Router实例拥有完整的中间件和路由系统
编写路由
const express = require('express');
const userRouter = express.Router();
userRouter.get('/',(req,res,next)=>{
res.end("用户列表")
})
userRouter.delete('/',(req,res,next)=>{
res.end('删除用户');
})
userRouter.post('/',(req,res,next)=>{
res.end('创建用户')
})
module.exports={
userRouter
}
引入路由
const express = require('express')
const {
userRouter} = require('./router/userRouter')
const app = express();
app.use('/user',userRouter)
app.listen(8000,()=>{
console.log('服务器启动成功');
})
错误处理
next方法里面传值,就表示发生错误。不会继续向下执行,会去错误处理中间件。use里面传4个参数说明用于处理错误。
const express =require('express');
const app = express();
const USERNAME_DOES_NOT_EXISTS = 'USERNAME_DOES_NOT_EXISTS'
const USERNAME_ALERADY_EXISTS = 'USERNAME_ALERADY_EXISTS'
app.get('/',(req,res,next)=>{
let flag =false
if(!flag){
next(new Error(USERNAME_DOES_NOT_EXISTS))
}
})
app.post('/',(req,res,next)=>{
let flag =false
if(!flag){
next(new Error(USERNAME_ALERADY_EXISTS))
}
})
app.use((err,req,res,next)=>{
let status = 400;
let message = '';
switch(err.message){
case USERNAME_ALERADY_EXISTS:
message = 'USERNAME_ALERADY_EXISTS'
break;
case USERNAME_DOES_NOT_EXISTS:
message = 'USERNAME_DOES_NOT_EXISTS'
break
default:
message = 'not found'
}
res.status(status);
res.end(message)
})
app.listen(8000,()=>{
console.log('开启');
})
静态服务器
const express = require('express')
const app = express();
app.use(express.static('./build'));
app.listen(8000,()=>{
console.log('路由服务器启动')
})
koa
koa是express同一个团队开发的一个全新的web框架。
koa旨在为web应用程序和api提供更小,更丰富和更强大的能力
相对express具有更强的异步处理能力
koa的核心代码只有1600行,是一个更加轻量级的框架,我们可以根据需要安装和使用中间件。
koa初体验
koa注册的中间件提供了两个参数
ctx:上下文(Context)对象
- koa并没有像express一样,将req和res分开,而是将它们作为ctx的属性
- ctx代表依次请求的上下文对象
- ctx.request:获取请求对象
- ctx.response:获取响应对象
next:本质上是一个dispatch,类似于之前的next
const Koa = require('koa');
const app = new Koa();
app.use((ctx,next)=>{
ctx.response.body='hello world'
})
app.listen(8000,()=>{
console.log('koa服务器开启');
})
路由的使用
koa官方并没有给我们提供路由的库,我们可以使用第三方库:koa-router
我们可以先封装一个user.router.js的文件
在app中将router.routes()注册为中间件
注意:allowedMethods用于判断某一个method是否支持;
- 如果我们请求get,那么是正常的请求,因为我们有实现get
- 如果我们请求put、delete那么会自动保存:Method Not Allowed,状态码405
- 如果我们请求link、copy、lock,那么就自动报错:Not Implemented,状态码501.
user.js
const Router = require('koa-router');
const userRouter = new Router({
prefix:'/users'});
userRouter.get('/',(ctx,next)=>{
ctx.response.body = 'user list';
})
userRouter.post('/',(ctx,next)=>{
ctx.response.body = 'create user info'
})
module.exports = {
userRouter
}
index.js
const Koa = require('koa');
const app = new Koa();
const {
userRouter} = require('./router/user')
app.use(userRouter.routes());
app.use(userRouter.allowedMethods())
app.listen(8000,()=>{
console.log('koa服务器开启');
})
params query 参数解析
const Router = require('koa-router');
const userRouter = new Router({
prefix:'/users'});
//获取params
userRouter.get('/:id',(ctx,next)=>{
const id = ctx.params.id
ctx.response.body = id+'user';
})
//获取query
userRouter.post('/',(ctx,next)=>{
const user = ctx.request.query
ctx.response.body = user.username+'login success'
})
module.exports = {
userRouter
}
接收客户端传递的json数据(参数解析:json)
安装依赖 yarn add koa-bodyparser
使用koa-bodyparser
请求url http://localhost:8000/users/add
body是json格式
{
“username”:“zhangsan”,
“password”:“123”
}
在index.js引入依赖
const Koa = require('koa');
const bodyParser = require('koa-bodyparser');
const app = new Koa();
app.use(bodyParser())
const {
userRouter} = require('./router/user')
app.use(userRouter.routes());
app.use(userRouter.allowedMethods())
app.listen(8000,()=>{
console.log('koa服务器开启');
})
在user.router.js中编写新的接口
userRouter.post('/add',(ctx,next)=>{
// const {username,password} = ctx.request.body;
console.log(ctx.request.body);
ctx.response.body=ctx.request.body
//{ username: 'zhangsan', password: '123' }
})
参数解析:x-www-form-urlencoded
body是x-www-form-urlencoded格式
和获取json一样,都是通过koa-bodyparser中间件
也都是保存在ctx.request.body中
使用中间件方法同上
userRouter.post('/',(ctx,next)=>{
console.log(ctx.request.body);
ctx.response.body = ctx.request.body
})
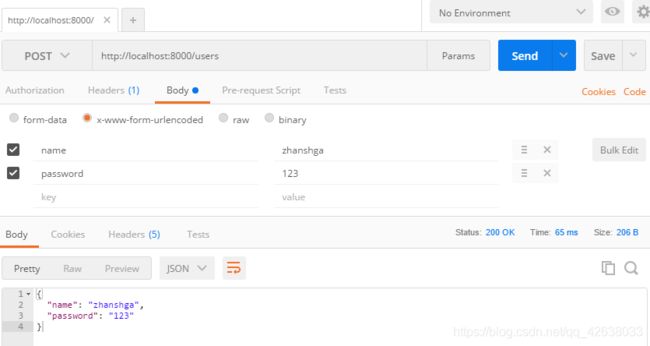
参数解析:form-data
解析body中的数据,安装依赖 yarn add koa-multer
在user.router.js中 获取传递的数值
const multer = require('koa-multer');
const upload = multer();
userRouter.post('/info',upload.any(),(ctx,next)=>{
console.log( ctx.req.body);
ctx.body = ctx.req.body; //[Object: null prototype] { name: 'lisi' }
})
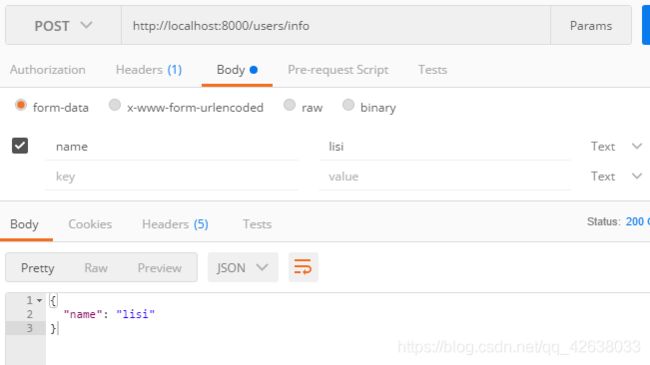
获取上传的文件
在user.router.js中
const multer = require('koa-multer');
const upload2 = multer({
dest:'./upload'})
userRouter.post('/upload',upload2.single('file'),(ctx,next)=>{
console.log(ctx.req.file);
ctx.body = ctx.req.file
})
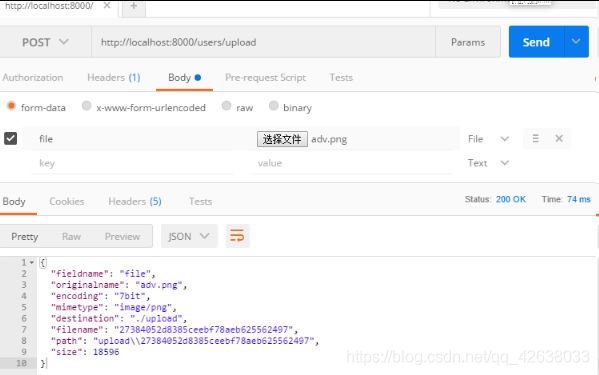
{
fieldname: 'file',
originalname: 'adv.png',
encoding: '7bit',
mimetype: 'image/png',
destination: './upload',
filename: '27384052d8385ceebf78aeb625562497',
path: 'upload\\27384052d8385ceebf78aeb625562497',
size: 18596
}
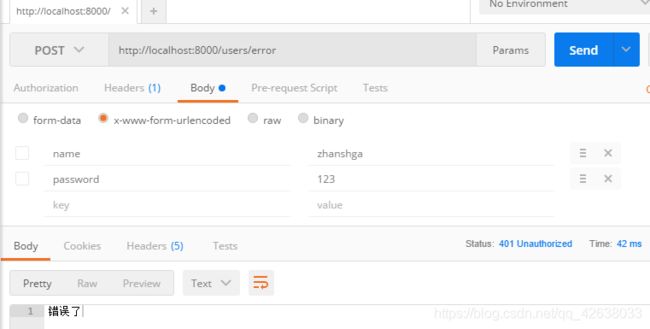
错误处理
index.js监听错误
//错误处理
app.on('error',(err,ctx)=>{
ctx.status = 401;
ctx.body = err.message;
})
user.router.js 抛出错误
//抛出错误
userRouter.post('/error',(ctx,next)=>{
ctx.app.emit('error', new Error("错误了"),ctx)
})
Mysql2
基本使用
const mysql = require('mysql2');
const connection = mysql.createConnection({
password:'123456',
user: 'root',
database: 'blog',
port: 3306
})
connection.query('select * from article',(err,results,fields)=>{
console.log(results);
})
Prepared Statment
提高性能:将创建的语句模块发送给mysqL,然后Mysql编译语句模块,并存储它但不执行,之后我们在真正执行时会给?提供实际的参数才会执行;就算执行多次,也只会编译一次,所以性能是更高的;
防止sql注入,之后传入的值不会像模块引用那也编译。
const mysql = require('mysql2');
const connection = mysql.createConnection({
database: 'blog',
user: 'root',
password: '123456',
port: 3306
})
connection.execute('select * from article where id = ?',[36],(err,results)=>{
console.log(results);
})
如果再次执行该语句,它会从LRU(Leact Recently Used)Cache中获取,省略了编译statement的时间来提高性能。
连接池
const mysql = require('mysql2');
//创建连接池
const connections = mysql.createPool({
host:'localhost',
port: 3306,
database: 'mmall',
user: 'root',
password: '123456',
connectionLimit: 10
})
const statement = `select * from product where price > ?`;
//使用连接池
connections.execute(statement,[1000] ,(err, result)=>{
console.log(result);
})
Promise方式
mysql2支持promise。所以我们可以使用async和await语法。
const mysql = require('mysql2');
const connections = mysql.createPool({
user: 'root',
connectionLimit: 10,
password: '123456',
database: 'mmall',
port: 3306,
host: 'localhost'
})
const statement = 'select * from product where price> ? and price < ?';
connections.promise().execute(statement,[1000,6000]).then(([results,fields])=>{
console.log(results);
});
项目
dotdev
可以把.dev中的配置加入到process.env中
dotdev使用方法