业务请求量膨胀的扩容技术实践
项目早期无论是从成本考虑,或者是业务模型考虑,往往难以估量长期的业务变化发展,尤其是数据库的扩容,项目的设计成员往往会单纯得以为,等到数据量膨胀以后,直接扩容数据库的规格,通过堆硬件的方式来解决数据库负载的问题。
在笔者的从业经验来看,这样的思想几乎是行业的“主流思想”,这也无可厚非,从业务角度,底层做得越透明,往往是越成功的。但从数据库的角度来看,单纯的堆硬件扩容依然存在非常大的性能隐患。
如果早期的时候,使用了8C 16G的RDS规格,以支撑1w QPS的数据库吞吐还算合情合理,等到业务发展到一定规模,业务请求成倍数增长,通过扩容规格,却发现难以支撑更高的请求量。这当中有多个原因:
- 并发带来的锁的问题,影响了吞吐的提升。
1w QPS提高到2w QPS不是简单的2倍概念,如果有热点问题,虽然请求量提高1倍,但在数据库中,QPS却提高不到1倍,这就是因为锁会阻塞并发的请求。
- 请求并不是平均的,而是有峰谷的。
峰值的请求往往伴随热点的争抢,针对热点的优化,我们在《云数据库架构》一书的2.3节中将详细阐述优化的方案。
这当中有多种思路。
01
使用分布式削峰
如《云数据库架构》第一章节介绍的,share nothing模式的分布式,就是一个典型的解决方案。因为sharding的方式,可以相对随机的切割分表,热点有概率会被切割到不同的分表上,这等价于把一把大锁,分拆到多把小锁里,锁的等待队列会变短。
这里举一个新零售行业的例子,来看看分布式削峰如何破局。我们知道,零售行业的业务请求量,除了搞活动的时间窗口以外,主要是和线下门店、线上网店的数量和规模有关。同时,除了订单系统外,容易忽略的是,订单背后的复杂采购、库存、划拨等一系列操作,都要落账,都是数据库的行为。
因此,当规模达到一定程度,不仅数据量剧增,更棘手的是,促销的常态化,流量请求变得更加集中,多点写入导致冲突更加频繁,等待时间冗长;同时,报表系统不堪重负,负载的SQL难以跑出,甚至要等待二十分钟。
围绕这个特点,我们通过改造成PolarDB-X的分布式集群,可以支持客户15-25TB的数据容量,同时支撑1.5W TPS, 20W QPS,解决峰值压力的问题。
第一步,我们要梳理业务,把相对独立的业务,做资源隔离。比如订单系统,和库存系统的数据,就分开存放,方便管理,也能保证系统之间尽可能解耦,避免相互资源竞争。
第二步,就是做水平拆分。通过PolarDB-X的水平拓展能力,把核心业务库表进行平拆,分散到不同的底层物理RDS。因为第一步已经从业务上隔离了,所以即使分散到不同的物理节点,但业务在物理节点上也等于上隔离的。
水平拆分的重要性,就是为了支撑前面谈到的容量和请求量,用更多的分布式节点,来支撑更多的业务请求。之前的热表,比如库存表,因为被打细以后,及时多个门店来提交信息,也能够从容应对并发。
水平拆分的另外一个重要性,是给系统留有弹性。比如当前的规模只需要128Core的集群,但如果规模需要提高,水平拆分的系统具备更好的拓展性,可以很快的提升规模。
第三步,解决了实时性要求高的并发请求后,就要着手解决报表的问题。
PolarDB-X 支持两种解决方案。
一种是传统的,读写分离方案。
本例中,当时客户也是选择使用PolarDB-X的只读集群,抗住常规只读请求,特别复杂的计算,通过DTS,同步到ADB for MySQL里,通过ADB 来解决。ADB的强大计算能力,原本十几分钟的报表,现在30秒内就能计算完成。
这个方式比较主流,TP 业务使用TP分布式系统解决,AP业务使用AP数据库解决,中间链路使用DTS搭起桥梁。
另一种方案,是使用PolarDB-X的HTAP 能力来支持。
TP流量依然使用TP引擎来支撑,同时一套MPP架构的只读集群,可以支持相关的业务请求。这就去除了DTS的中间链路,把数据分布方式、计算器全部做在了存储引擎层面解决。
通过以上三步,再稍微做一些精修,比如增加一组全局Redis来扛起请求量,部分冷数据可以直接归档到OSS里,就得到了我们最后的结构。
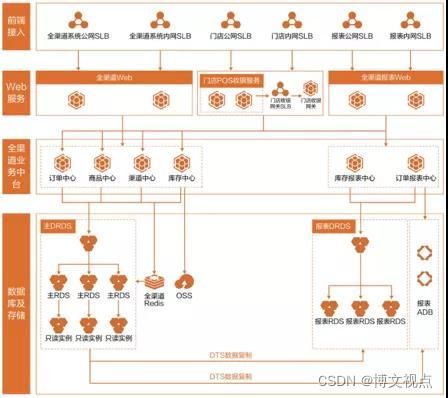
通过这个例子,我们可以看到削峰的思想非常重要,在解决TP峰值的同时,还可以顺手分流AP的流量,通过合适的引擎来解决。
02
用缓存技术,代替单一的关系型强一致请求题
并不是所有数据库请求都是强一致,需要同步返回的。
理解这点,在代码层面的意义就是,并不是所有数据库请求,都需要使用事务。
举一个具体的场景来说明业务请求量的膨胀,比如秒杀场景,秒杀的时候,业务请求是远超平时的量,单纯的堆硬件往往无法还是会被热点锁,把系统打死。
秒杀系统的流量虽然很高,但是实际有效流量是十分有限的。利用系统的层次结构,在每个阶段提前校验,拦截无效流量,可以减少大量无效的流量涌入数据库。
下面是比较通用的分层拦截流量的主要步骤,对每个步骤的具体实现的讲解详见《云数据库架构》书籍内容,在此限于篇幅不再展开。
-
利用浏览器缓存和CDN抗压静态页面流量。
-
利用读写分离Redis缓存拦截流量。
-
利用主从版Redis缓存加速库存扣量。
-
使用主从版Redis实现简单的消息队列异步下单入库。
-
数据控制模块管理秒杀数据同步。
本文摘自《云数据库架构》一书,本书全面介绍了主流数据库的技术特点,并结合业务场景讲解了数据库技术选型和数据库架构的最佳实践,欢迎阅读本书了解更多云数据库架构的内容!

▊《云数据库架构》
朱明 等 著
引领云数据库技术,详解9大云数据库引擎,5大行业技术选型!
阿里云数据库产品事业部总裁、达摩院数据库与存储实验室负责人李飞飞力荐
“阿里云数字新基建系列”包括5本书,涉及Kubernetes、混合云架构、云数据库、CDN原理与流媒体技术、云服务器运维(Windows),囊括了领先的云技术知识与阿里云技术团队独到的实践经验,是国内IT技术图书又一重磅作品。
数据库技术,被称为“计算机三驾马车”之一,几十年来,持续支持着全球亿万数字业务的运行,而云计算的出现,赋予了数据库新的能力。云数据库按引擎能力,可以分为关系型数据库、非关系型数据库、数据仓库和分布式新型数据库。本书从技术原理入手,讲解各种数据库的特点,分析不同场景的架构选型和数据库优化,继而展开到云数据库的迁移、云数据库的运维工作,期望能帮助读者了解和掌握云数据库相关知识与技能。

(京东满100减50,快快扫码抢购吧!)
