大数据系统与大规模数据分析--第一次作业操作,HDFS、HBase编程
第一次作业操作
大家好,我是【豆干花生】,这次我带来了大数据的第一次实践作业~
可以说十分具体了,包含了具体操作、代码指令、各个步骤截图。
文章目录
- 第一次作业操作
-
- 一.作业内容
- 二.准备工作
- 三.编写程序
- 四.运行程序
- 五.保存
一.作业内容

这里选择docker来配置环境



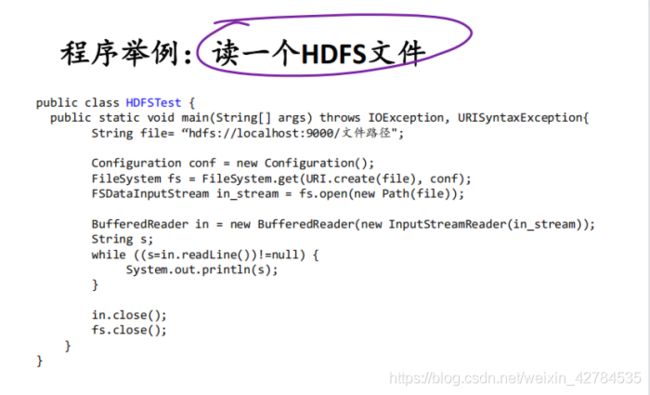
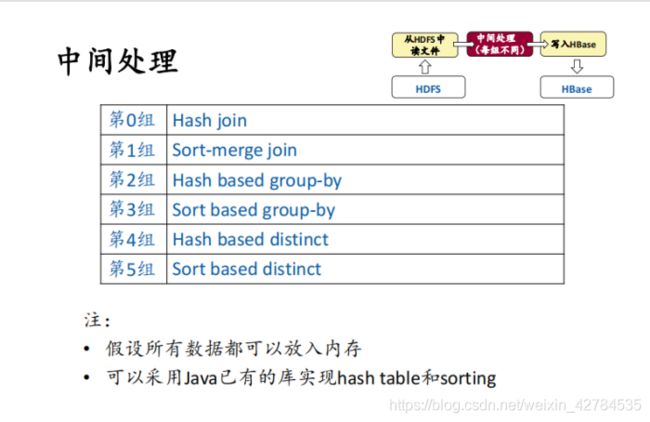
这里采用第0组的中间处理








二.准备工作
docker里已经配置好的环境:

1.进入容器

docker run -itd dingms/ucas-bdms-hw-u64-2019:16.04 /bin/bash
docker ps
docker exec -it /bin/bash
2.开启ssh(hdfs和hbase好像是通过ssh来连接的)

service ssh start(每次重启容器,似乎都要重新开启ssh)
3.可以阅读说明文件(关于hdfs和hbase的操作)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LcBlY1Xg-1628670451216)(C:\Users\YUANMU\AppData\Roaming\Typora\typora-user-images\image-20210420194637746.png)]](http://img.e-com-net.com/image/info8/8483040a07774de5a8278ce3b3223ee9.jpg)
![]()
--------------------------------------------------------------------------------
2 README
3 --------------------------------------------------------------------------------
4
5 PLEASE save your code and data to your drive!
6 WARNING: this VM will be cleaned without notice after you log out.
7 Your code and data on the VM will be lost!!!
8
9 ## Directory Layout
10
11 * example: example codes for HDFS and HBase
12 * input: input test data for homework 1
13
14
15
16 Please enter example, in order to follow the guide.
17
18 $ cd example
19
20
21 ## HDFS Usage:
22
23 ### Start and Stop
24
25 $ start-dfs.sh
26
27 then, run 'jps' to check whether following processes have been started:
28
29 * NameNode
30 * DataNode
31 * SecondaryNameNode
32
33
34 To stop HDFS, run
35
36 $ start-dfs.sh
37
38
39 ### HDFS Command List
40
41 $ hadoop fs
42
43 hdfs directory layout:
44
45 $ hadoop fs -ls /
46
47
48 ###. Run Example
49 Description:
50 put a file into HDFS by HDFS commands, and then write a Java program to
51 read the file from HDFS
52
53 1. put file to HDFS
54
55 $ hadoop fs -mkdir /hw1-input
56 $ hadoop fs -put README.md /hw1-input
57 $ hadoop fs -ls -R /hw1-input
58
59 2. write a Java program @see ./HDFSTest.java
60
61 3. compile and run Java program
62
63 $ javac HDFSTest.java
64
65 $ java HDFSTest hdfs://localhost:9000/hw1-input/README.md
66
67
68
69 ## HBase Usage:
70
71 ### Start and Stop
72
73 Start HDFS at first, then HBase.
74 $ start-dfs.sh
75 $ start-hbase.sh
76
77 then, run 'jps' to check whether following processes have been started:
78
79 * NameNode
80 * DataNode
81 * SecondaryNameNode
82 * HMaster
83 * HRegionServer
84 * HQuorumPeer
85
86 To stop HDFS, run
87
88 $ stop-hbase.sh
89 $ start-dfs.sh
90
91
92 ###. Run Example
93 Description:
94 put records into HBase
95
96 1. write a Java program @see ./HBaseTest.java
97
98 2. compile and run Java program
99
100 $ javac HBaseTest.java
101
102 $ java HBaseTest
103
104 3. check
105
106 $ hbase shell
107
108 hbase(main):001:0> scan 'mytable'
109 ROW COLUMN+CELL
110 abc column=mycf:a, timestamp=1428459927307, value=789
111 1 row(s) in 1.8950 seconds
112
113 hbase(main):002:0> disable 'mytable'
114 0 row(s) in 1.9050 seconds
115
116 hbase(main):003:0> drop 'mytable'
117 0 row(s) in 1.2320 seconds
118
119 hbase(main):004:0> exit
120
121 --------------------------------------------------------------------------------
122 version: 2019-spring
4.开启hdfs和hbase

5.可以进一步查阅示例文件,参考如何编写hbase和hdfs
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mcEKISQd-1628670451218)(C:\Users\YUANMU\AppData\Roaming\Typora\typora-user-images\image-20210420195104856.png)]](http://img.e-com-net.com/image/info8/60df46b286bc403eadf50a3f4ac64652.jpg)
HBaseTest.java
/*
2 * Make sure that the classpath contains all the hbase libraries
3 *
4 * Compile:
5 * javac HBaseTest.java
6 *
7 * Run:
8 * java HBaseTest
9 */
10
11 import java.io.IOException;
12
13 import org.apache.hadoop.conf.Configuration;
14 import org.apache.hadoop.hbase.HBaseConfiguration;
15 import org.apache.hadoop.hbase.HColumnDescriptor;
16 import org.apache.hadoop.hbase.HTableDescriptor;
17 import org.apache.hadoop.hbase.MasterNotRunningException;
18 import org.apache.hadoop.hbase.TableName;
19 import org.apache.hadoop.hbase.ZooKeeperConnectionException;
20 import org.apache.hadoop.hbase.client.HBaseAdmin;
21 import org.apache.hadoop.hbase.client.HTable;
22 import org.apache.hadoop.hbase.client.Put;
23
24 import org.apache.log4j.*;
25
26 public class HBaseTest {
27
28 public static void main(String[] args) throws MasterNotRunningException, ZooKeeperConnectionException, IOException {
29
30 Logger.getRootLogger().setLevel(Level.WARN);
31
32 // create table descriptor
33 String tableName= "mytable";
34 HTableDescriptor htd = new HTableDescriptor(TableName.valueOf(tableName));
35
36 // create column descriptor
37 HColumnDescriptor cf = new HColumnDescriptor("mycf");
38 htd.addFamily(cf);
39
40 // configure HBase
41 Configuration configuration = HBaseConfiguration.create();
42 HBaseAdmin hAdmin = new HBaseAdmin(configuration);
43
44 if (hAdmin.tableExists(tableName)) {
45 System.out.println("Table already exists");
46 }
47 else {
48 hAdmin.createTable(htd);
49 System.out.println("table "+tableName+ " created successfully");
50 }
51 hAdmin.close();
52
53 // put "mytable","abc","mycf:a","789"
54
55 HTable table = new HTable(configuration,tableName);
56 Put put = new Put("abc".getBytes());
57 put.add("mycf".getBytes(),"a".getBytes(),"789".getBytes());
58 table.put(put);
59 table.close();
60 System.out.println("put successfully");
61 }
62 }
HBaseTest.java
HDFSTest.java
1 import java.io.*;
2 import java.net.URI;
3 import java.net.URISyntaxException;
4
5 import org.apache.hadoop.conf.Configuration;
6 import org.apache.hadoop.fs.FSDataInputStream;
7 import org.apache.hadoop.fs.FSDataOutputStream;
8 import org.apache.hadoop.fs.FileSystem;
9 import org.apache.hadoop.fs.Path;
10 import org.apache.hadoop.io.IOUtils;
11
12 /**
13 *complie HDFSTest.java
14 *
15 * javac HDFSTest.java
16 *
17 *execute HDFSTest.java
18 *
19 * java HDFSTest
20 *
21 */
22
23 public class HDFSTest {
24
25 public static void main(String[] args) throws IOException, URISyntaxException{
26 if (args.length <= 0) {
27 System.out.println("Usage: HDFSTest ");
28 System.exit(1);
29 }
30
31 String file = args[0];
32
33 Configuration conf = new Configuration();
34 FileSystem fs = FileSystem.get(URI.create(file), conf);
35 Path path = new Path(file);
36 FSDataInputStream in_stream = fs.open(path);
37
38 BufferedReader in = new BufferedReader(new InputStreamReader(in_stream));
39 String s;
40 while ((s=in.readLine())!=null) {
41 System.out.println(s);
42 }
43
44 in.close();
45
46 fs.close();
47 }
48 }
HDFSTest.java
三.编写程序
作业要求如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fipdBfWE-1628670451218)(C:\Users\YUANMU\AppData\Roaming\Typora\typora-user-images\image-20210420195312210.png)]
需要实现三部分:从hdfs中读取文件,根据自己的要求处理文件,将处理好后的文件写入hbase
根据之前的两个example文件和课件上的程序,进行编写程序:
//引入对应的包
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import java.io.*;
import java.net.URI;
import java.net.URISyntaxException;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.LinkedList;
import java.util.Map.Entry;
import java.util.AbstractMap.SimpleEntry;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.MasterNotRunningException;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.ZooKeeperConnectionException;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.log4j.*;
//建立public类
public class Hw1Grp0 {
private static String fileR; //File R name
private static String fileS;
private static int joinR; // R join key
private static int joinS;
private static ArrayList<Integer> resRs = new ArrayList<> (); //R result column number array
private static ArrayList<Integer> resSs = new ArrayList<> ();
private static ArrayList<String> resRStrs = new ArrayList<> ();//R column family string array
private static ArrayList<String> resSStrs = new ArrayList<> ();
private static boolean isREmpty = true; //Does res contain R's column
private static boolean isSEmpty = true;
/**
* hashmap used for join
* the String type key is the join key
* the Entry's key is the LinkedList of R's columns that in the res
* the Entry's value is the LinkedList of S's columns that in the res
*/
//使用Java内置的hashmap生成哈希表
private static HashMap<String, Entry<LinkedList<LinkedList<String>>,LinkedList<LinkedList<String>>>> joinMap = new HashMap<> ();
private static HTable table;
/**
* process the arguments
* retracts the file name, join key, and res column from the args into the member variable.
* @param input-arguments
* @return void
*/
//进行join连接
private static void processArgs(String[] args)
{
int index = 0;
String resStr;
if(args.length!=4)
{
//进行join连接
System.out.println("Usage: Hw1Grp0 R= S= join:R*=S* res=R*,S*" );
System.exit(1);
}
//打开文件
fileR = args[0].substring(2);
fileS = args[1].substring(2);
index = args[2].indexOf('=');
joinR = Integer.valueOf(args[2].substring(6,index));
joinS = Integer.valueOf(args[2].substring(index+2));
index = args[3].indexOf(',');
resStr = args[3].substring(4);
String[] resStrs = resStr.split(",");
for(String s : resStrs)
{
System.out.println(s);
if(s.startsWith("R"))
{
resRs.add(Integer.valueOf(s.substring(1)));
resRStrs.add(s);
isREmpty = false;
}
else
{
resSs.add(Integer.valueOf(s.substring(1)));
resSStrs.add(s);
isSEmpty = false;
}
}
}
/**
* Read File R and File S from HDFS line by line and Map them into the joinMap.
* @param void
* @return void
*/
private static void readFileFromHDFS() throws IOException, URISyntaxException
{
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
Path pathR = new Path(fileR);
Path pathS = new Path(fileS);
FSDataInputStream in_streamR = fs.open(pathR);
FSDataInputStream in_streamS = fs.open(pathS);
BufferedReader inR = new BufferedReader(new InputStreamReader(in_streamR));
BufferedReader inS = new BufferedReader(new InputStreamReader(in_streamS));
String r, s;
while((r=inR.readLine())!=null)
{
String[] tmp = r.split("\\|");
String joinKey = tmp[joinR];
LinkedList<String> joinValues = new LinkedList<String> ();
if(joinMap.containsKey(joinKey))
{
for(int i : resRs)
{
joinValues.add(tmp[i]);
}
if(isREmpty)
{
joinValues.add("");
}
joinMap.get(joinKey).getKey().add(joinValues);
}
else
{
for(int i : resRs)
{
joinValues.add(tmp[i]);
}
if(isREmpty)
{
joinValues.add("");
}
LinkedList<LinkedList<String>> rValues = new LinkedList<> ();
LinkedList<LinkedList<String>> sValues = new LinkedList<> ();
rValues.add(joinValues);
Entry<LinkedList<LinkedList<String>>, LinkedList<LinkedList<String>>> pair = new SimpleEntry<>(rValues, sValues);
joinMap.put(joinKey, pair);
}
}
while((s=inS.readLine())!=null)
{
String[] tmp = s.split("\\|");
String joinKey = tmp[joinS];
LinkedList<String> joinValues = new LinkedList<String> ();
if(joinMap.containsKey(joinKey))
{
for(int i : resSs)
{
joinValues.add(tmp[i]);
}
if(isSEmpty)
joinValues.add("");
joinMap.get(joinKey).getValue().add(joinValues);
}
}
inR.close();
inS.close();
fs.close();
}
/**
* create Result table in HBase
* @param: void
* @return: void
*/
private static void createHBaseTable() throws IOException, URISyntaxException
{
Logger.getRootLogger().setLevel(Level.WARN);
// create table descriptor
String tableName= "Result";
HTableDescriptor htd = new HTableDescriptor(TableName.valueOf(tableName));
// create column descriptor
HColumnDescriptor cf = new HColumnDescriptor("res");
htd.addFamily(cf);
// configure HBase
Configuration configuration = HBaseConfiguration.create();
HBaseAdmin hAdmin = new HBaseAdmin(configuration);
if (hAdmin.tableExists(tableName)) {
System.out.println("Table already exists");
hAdmin.disableTable(tableName);
hAdmin.deleteTable(tableName);
System.out.println("Table has been deleted");
}
hAdmin.createTable(htd);
System.out.println("table "+tableName+ " created successfully");
hAdmin.close();
table = new HTable(configuration,tableName);
table.setAutoFlush(false);
table.setWriteBufferSize(64*1024*1024);
}
/**
* Use the joinMap to decide which record to put into the Result table.
* @param: void
* @return: void
*/
private static void hashJoin() throws IOException, URISyntaxException
{
for(String joinKey : joinMap.keySet())
{
int count = 0;
Entry<LinkedList<LinkedList<String>>, LinkedList<LinkedList<String>>> entry = joinMap.get(joinKey);
LinkedList<LinkedList<String>> rValues = entry.getKey();
LinkedList<LinkedList<String>> sValues = entry.getValue();
if(sValues.size()==0)
continue;
for(LinkedList<String> rValue : rValues)
{
for(LinkedList<String> sValue : sValues)
{
String countStr = "";
if(count != 0)
{
countStr = "." + Integer.toString(count);
}
if(!isREmpty)
{
for(int i = 0; i < rValue.size(); i++ )
{
Put put = new Put(joinKey.getBytes());
put.add("res".getBytes(), (resRStrs.get(i) + countStr).getBytes(), rValue.get(i).getBytes());
table.put(put);
}
}
if(!isSEmpty)
{
for(int i = 0; i < sValue.size(); i++ )
{
Put put = new Put(joinKey.getBytes());
put.add("res".getBytes(), (resSStrs.get(i) + countStr).getBytes(), sValue.get(i).getBytes());
table.put(put);
}
}
count++ ;
}
}
}
table.flushCommits();
table.close();
}
public static void main (String[] args) throws IOException, URISyntaxException
{
//进行join的方法
processArgs(args);
//从hbase中读取的方法
readFileFromHDFS();
//创建哈希表
createHBaseTable();
//进行 连接
hashJoin();
return;
}
}
四.运行程序
这里要使用老师上传的文件:
![]()

先将check文件夹传入ubuntu:

对应的Java程序也拖入其中:

使用cp指令将文件传入docker中:

![]()
![]()
sudo docker cp /home/abc/bigdata/hw1-check/0_202028018629028_hw1.java 9d44ee5dfe3b:/home/bdms
sudo docker cp /home/abc/bigdata/hw1-check-v1.1.tar.gz 9d44:/home/bdms/homework/hw1
注意:这里的容器名称只写前几位就行
在容器中。可以找到对应的java文件和check文件夹:

![]()
按照check文件里的readme.md的指示,进行操作:
//readme.md
0. set language to POSIX
$ export LC_ALL="POSIX"
1. make sure ssh is running
$ service ssh status
if not, then run sshd (note that this is necessary in a docker container)
$ service ssh start
2. make sure HDFS and HBase are successfully started
$ start-dfs.sh
$ start-hbase.sh
check if hadoop and hbase are running correctly
$ jps
5824 Jps
5029 HMaster
5190 HRegionServer
4950 HQuorumPeer
4507 SecondaryNameNode
4173 NameNode
4317 DataNode
3. put input files into HDFS
$ ./myprepare
4. check file name format
$ ./check-group.pl
5. check if the file can be compiled
$ ./check-compile.pl
6. run test
$ ./run-test.pl ./score
Your score will be in ./score. The run-test.pl tests 3 input cases, you will
get one score for each case. So the output full score is 3.
To run the test again, you need to first remove ./score
$ rm ./score
$ ./run-test.pl ./score

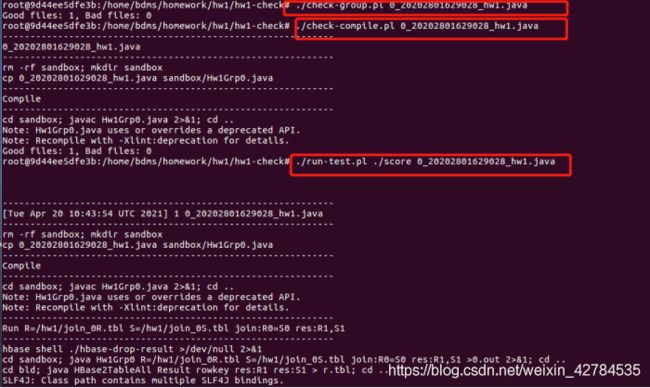
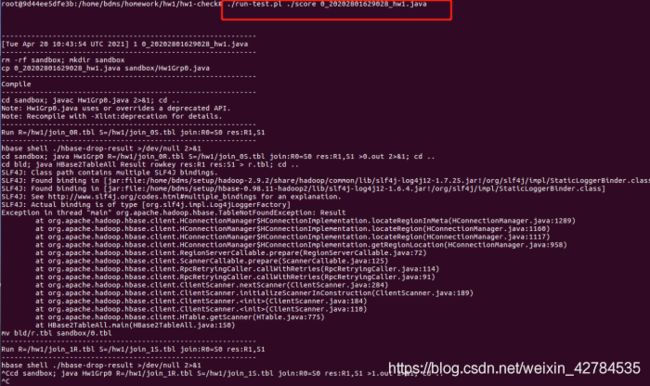


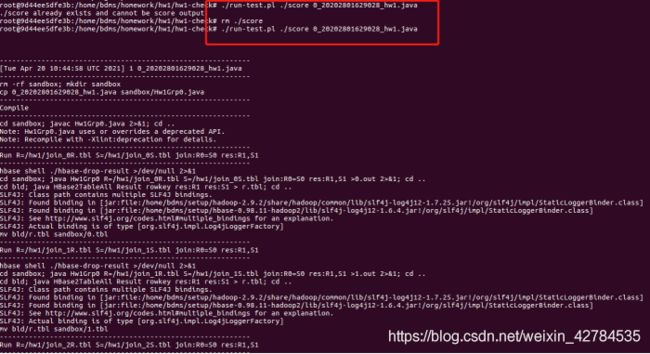
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pc8HCbF0-1628670451231)(C:\Users\YUANMU\AppData\Roaming\Typora\typora-user-images\image-20210420202646795.png)]](http://img.e-com-net.com/image/info8/cd1d8c9559864660859810be035c632a.jpg)
最后结果输出为3,说明三个测试都通过所以完成。
但是这个测试结果不输出中间结果,只保存最后的结果。
五.保存
由于容器中的操作结果不被自动保存
https://docs.docker.com/desktop/backup-and-restore/


码字不易,都看到这里了不如点个赞哦~
我是【豆干花生】,你的点赞+收藏+关注,就是我坚持下去的最大动力~

亲爱的朋友,这里是我新成立的公众号,欢迎关注!
公众号内容包括但不限于人工智能、图像处理、信号处理等等~之后还将推出更多优秀博文,敬请期待! 关注起来,让我们一起成长!
