[源码解析] PyTorch分布式优化器(2)----数据并行优化器
- [源码解析] PyTorch分布式优化器(2)----数据并行优化器
- 0x00 摘要
- 0x01 前文回顾
- 0x02 DP 之中的优化器
- 2.1 流程
- 2.2 使用
- 0x03 DDP 之中的优化器
- 3.1 流程
- 3.2 优化器状态
- 3.3 使用
- 0x04 Horovod 的优化器
- 4.1 hook 同步梯度
- 4.1.1 注册 hooks
- 4.1.2 归并梯度
- 4.1.2.1 MPI 函数
- 4.1.2.2 原理图
- 4.2 step 同步梯度
- 4.2.1 synchronize
- 4.2.2 梯度裁剪
- 4.2.3 实现
- 4.2.4 MPI 同步操作
- 4.2.5 图示
- 4.1 hook 同步梯度
- 0xFF 参考
0x00 摘要
本系列介绍分布式优化器,分为三篇文章,分别是基石篇,DP/DDP/Horovod 之中数据并行的优化器,PyTorch 分布式优化器,按照深度递进。
本文介绍数据并行DP/DDP/Horovod 之中的优化器。
PyTorch分布式其他文章如下:
深度学习利器之自动微分(1)
深度学习利器之自动微分(2)
[源码解析]深度学习利器之自动微分(3) --- 示例解读
[源码解析]PyTorch如何实现前向传播(1) --- 基础类(上)
[源码解析]PyTorch如何实现前向传播(2) --- 基础类(下)
[源码解析] PyTorch如何实现前向传播(3) --- 具体实现
[源码解析] Pytorch 如何实现后向传播 (1)---- 调用引擎
[源码解析] Pytorch 如何实现后向传播 (2)---- 引擎静态结构
[源码解析] Pytorch 如何实现后向传播 (3)---- 引擎动态逻辑
[源码解析] PyTorch 如何实现后向传播 (4)---- 具体算法
[源码解析] PyTorch 分布式(1)------历史和概述
[源码解析] PyTorch 分布式(2) ----- DataParallel(上)
[源码解析] PyTorch 分布式(3) ----- DataParallel(下)
[源码解析] PyTorch 分布式(4)------分布式应用基础概念
[源码解析] PyTorch分布式(5) ------ DistributedDataParallel 总述&如何使用
[源码解析] PyTorch分布式(6) ---DistributedDataParallel -- 初始化&store
[源码解析] PyTorch 分布式(7) ----- DistributedDataParallel 之进程组
[源码解析] PyTorch 分布式(8) -------- DistributedDataParallel之论文篇
[源码解析] PyTorch 分布式(9) ----- DistributedDataParallel 之初始化
[源码解析] PyTorch 分布式(10)------DistributedDataParallel 之 Reducer静态架构
[源码解析] PyTorch 分布式(11) ----- DistributedDataParallel 之 构建Reducer和Join操作
[源码解析] PyTorch 分布式(12) ----- DistributedDataParallel 之 前向传播
[源码解析] PyTorch 分布式(13) ----- DistributedDataParallel 之 反向传播
[源码解析] PyTorch 分布式 Autograd (1) ---- 设计
[源码解析] PyTorch 分布式 Autograd (2) ---- RPC基础
[源码解析] PyTorch 分布式 Autograd (3) ---- 上下文相关
[源码解析] PyTorch 分布式 Autograd (4) ---- 如何切入引擎
[源码解析] PyTorch 分布式 Autograd (5) ---- 引擎(上)
[源码解析] PyTorch 分布式 Autograd (6) ---- 引擎(下)
[源码解析] PyTorch分布式优化器(1)----基石篇
为了更好的说明,本文代码会依据具体情况来进行相应精简。
0x01 前文回顾
常规优化器主要功能就是使用梯度来进行优化,然后更新当前参数 : w.data -= w.grad * lr,而且是严格有条理的进行。
数据并行之中的优化器就是另外一种情况,因为每个worker自己计算梯度,所以优化器主要技术难点是:
- 每个worker有自己的优化器?还是只有一个worker才有优化器,由他统一做优化?
- 如果只有一个优化器,如何把各个worker的梯度合并起来,每个worker都传给这唯一的优化器?
- 如果每个worker有自己优化器,本地优化器优化到本地模型之中,如何确保每个worker之中的模型始终保持一致?
这随着具体框架方案不同而有具体分别。
0x02 DP 之中的优化器
2.1 流程
DP 之中,我们需要注意的是,PyTorch 使用了多线程并行,所以应用之中只有一个优化器,这个优化器也是普通类型的优化器,其流程如下:
-
- 每个 GPU 在单独的线程上将针对各自的输入数据独立并行地进行 forward 计算,计算输出。
-
- 在 master GPU 之上收集(gather)输出。
-
- 在主GPU之上 计算损失。
-
- 把损失在 GPUs 之间 scatter。
-
- 在各个GPU之上运行后向传播,计算参数梯度。
-
- 在 GPU 0 之上归并梯度。
-
- 进行梯度下降,并用梯度更新主GPU上的模型参数。
-
- 将更新后的模型参数复制到剩余的从属 GPU 中,进行后续迭代。
DP 修改了 forward 和 backward 方法,把每个线程的梯度归并在一起然后做优化,所以虽然是数据并行,但是优化器不需要做修改。
2.2 使用
具体使用如下:
model=torch.nn.DaraParallel(model);
optimizer = torch.optim.SGD(model.parameters(), args.lr,
momentum=args.momentum,
weight_decay=args.weight_decay)
for batch_idx, (data, label) in pbar:
if args.cuda:
data,label= data.cuda(),label.cuda(); # 数据放到了默认GPU
data_v = Variable(data)
target_var = Variable(label)
prediction= model(data_v,target_var,args) # 多线程并行前向传播
criterion = nn.CrossEntropyLoss()
loss = criterion(prediction,target_var) # 在默认GPU之上计算loss
optimizer.zero_grad()
loss.backward() # 多线程并行后向传播
optimizer.step() # 更新参数
我们给出一个简化的图示如下,每个thread进行梯度计算,最后把梯度归并到GPU 0,在GPU 0之上进行优化:
Forward Backward
+-------------------+ +------------------+
+-->+ Thread 0 on GPU0 +--+ +-->+ Thread 1 on GPU0 +-+
| +-------------------+ | GPU 0 | +------------------+ |
| +-------------------+ | output +---------------+ loss | +------------------+ |
+---->+ Thread 1 on GPU1 +---------> | Compute Loss +---------->+ Thread 2 on GPU1 +---+
| | +-------------------+ | +---------------+ | +------------------+ | |
| | +-------------------+ | | +------------------+ | |
| +-->+ Thread 2 on GPU2 +--+ +-->+ Thread 3 on GPU2 +-+ |
| +-------------------+ +------------------+ |
| |
| |
| GPU 0 |
| Model +-------------------------+ gradient |
+--------------------------+ optimizer.step | <--------------------------------+
+-------------------------+
0x03 DDP 之中的优化器
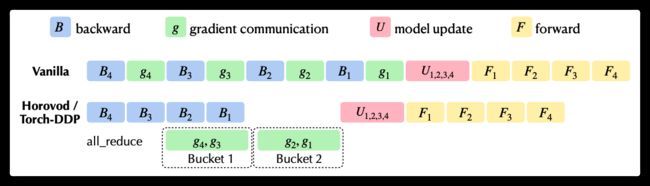
下图来自快手八卦的论文,图中罗列了原生训练过程与DDP/Horovod的对比。
- 上面的 vanilla 就是原生训练过程,其中 U 部分对应的就是优化器过程。常规优化器主要功能就是根据梯度来更新模型当前参数 :
w.data -= w.grad * lr。 - 下面部分就是DDP/Horovod优化过程,可以看到,其后向计算和归并梯度是部分并行的。
3.1 流程
DDP 之中,依然使用的是普通优化器,但采用的是多进程方式,每个进程都完成训练的全部流程,只是在后向计算时候需要使用 all-reduce 来归并梯度。每个进程拥有自己独立的优化器,优化器也是常规优化器。
这里有两个特点:
- 每个进程维护自己的优化器,并在每次迭代中执行一个完整的优化步骤。虽然这可能看起来是多余的,但由于梯度已经聚合(gather)并跨进程平均,因此梯度对于每个进程都是相同的,这意味着不需要参数广播步骤,减少了在节点之间传输张量所花费的时间。
- All-Reduce 操作是在后向传播之中完成的。
- 在 DDP 初始化时候会生成一个Reducer,其内部会注册 autograd_hook。
- autograd_hook 在反向传播时候进行梯度同步。
DDP 选择了在 PyTorch 内核角度修改,在 DistributedDataParallel 模型的初始化和前向操作中做了处理。
具体逻辑如下:
- DDP 使用多进程并行加载数据,在 host 之上,每个worker进程都会把数据从硬盘加载到 page-locked memory。分布式 minibatch sampler 保证每个进程加载到的数据是彼此不重叠的。
- 不需要广播数据,而是并行把 minibatch 数据从 page-locked memory 加载到每个GPU,每个GPU都拥有模型的一个副本,所以也不需要拷贝模型。
- 在每个GPU之上运行前向传播,计算输出,每个GPU都执行同样的训练,不需要有主 GPU。
- 在每个GPU之上计算损失,运行后向传播来计算梯度,在计算梯度同时对梯度执行all-reduce操作。
- 更新模型参数。因为每个GPU都从完全相同的模型开始训练,并且梯度被all-reduced,因此每个GPU在反向传播结束时最终得到平均梯度的相同副本,所有GPU上的权重更新都相同,这样所有 worker 上的模型都一致,也就不需要模型同步了。
因为也是在模型的前向后向操作之中进行修改,所以优化器也不需要修改,每个worker分别在自己本地进程之中进行优化。
3.2 优化器状态
这里要留意的是,如何保证各个进程的优化器状态相同?
DDP 与优化器实际上没有关联,DDP不对此负责,所以需要用户协同操作来保证各进程之间的优化器状态相同。这就围绕着两个环节:
- 优化器参数初始值相同。
- 优化器初始值相同由 "用户在DDP模型创建后才初始化optimizer" 来确保。
- 优化器参数每次更新值相同。
- 每次更新的梯度都是all-reduce过的,所以各个优化器拿到的梯度delta数值是一样的。
3.3 使用
其示例如下:
model = ToyModel().to(rank)
# 构造DDP model
ddp_model = DDP(model, device_ids=[rank])
loss_fn = nn.MSELoss()
# 优化器要在构造DDP model之后,才能初始化。
optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)
optimizer.zero_grad()
outputs = ddp_model(torch.randn(20, 10))
labels = torch.randn(20, 5).to(rank)
loss_fn(outputs, labels).backward()
optimizer.step()
图示如下:
+--------------------------------------------------------------------------------------+
| Process 1 on GPU 1 |
| +------------------------------+ |
| | Backward | |
| | | |
| Forward +----> Loss +-----> | Compute +----> ALL+REDUCE | +----> Optimizer.step |
| | ^ | |
| | | | |
| +------------------------------+ |
| | |
| | |
+--------------------------------------------------------------------------------------+
|
|
|
|
+
SYNC GRADS
+
|
|
|
+--------------------------------------------------------------------------------------+
| Process 2 on GPU 2 | |
| | |
| +------------------------------+ |
| | Backward | | |
| | v | |
| Forward +----> Loss +-----> | Compute +----> ALL+REDUCE | +----> Optimizer.step |
| | | |
| | | |
| +------------------------------+ |
| |
+--------------------------------------------------------------------------------------+
0x04 Horovod 的优化器
Horovod 并没有对模型 fw/bw 进行修改(可能因为没有Facebook自己修改那么顺手),而是对优化器进行了修改,实现了一个 DistributedOptimizer。
我们以 horovod/torch/optimizer.py 为例。
An optimizer that wraps another torch.optim.Optimizer, using an allreduce to
combine gradient values before applying gradients to model weights.
Allreduce operations are executed after each gradient is computed by ``loss.backward()``
in parallel with each other. The ``step()`` method ensures that all allreduce operations are
finished before applying gradients to the model.
DistributedOptimizer 包装了另一个torch.optim.optimizer,其作用是:
- 在worker 并行执行
loss.backward()计算出每个梯度之后,在 "将梯度应用于模型权重之前“ 这个时间点使用allreduce来合并梯度。 - 使用
step()方法来确保所有allreduce操作在将梯度应用于模型之前会完成。
其具体实现是 _DistributedOptimizer,而_DistributedOptimizer对于梯度的归并有两个途径,一个是通过 hook,一个是显性调用了 synchronize 函数,我们接下来逐一介绍。
4.1 hook 同步梯度
hook 就是采用了 PyTorch 的 hook 方法,和 DDP 的思路非常类似,即在梯度计算函数之上注册了hook,其作用是在计算完梯度之后调用hook,这样all-reduce 就是在计算梯度过程中自动完成的,不需要等待 step 方法显式调用来完成(类似 DP 那样),具体来说就是:
- 在每个GPU之上计算损失,运行后向传播来计算梯度,在计算梯度同时对梯度执行all-reduce操作。
- 更新模型参数。因为每个GPU都从完全相同的模型开始训练,并且梯度被all-reduced,因此每个GPU在反向传播结束时最终得到平均梯度的相同副本,所有GPU上的权重更新都相同,也就不需要模型同步了。
注:代码主要分为两部分,处理 groups 相关 和 普通情况。
groups 是 PyTorch 的相关配置,作用是把梯度 allreduce 操作放在一起进行,因为代码比较复杂并且与本文主体逻辑不相关,所以我们略过这部分,只看普通非分组情况。
groups: The parameter to group the gradient allreduce ops. Accept values is a
non-negative integer or a list of list of tf.Variable.
If groups is a non-negative integer, it is the number of groups to assign
gradient allreduce ops to for explicit grouping.
If groups is a list of list of tf.Variable. Variables in the same
inner list will be assigned to the same group, while parameter that does
not appear in any list will form a group itself.
Defaults as None, which is no explicit groups.
4.1.1 注册 hooks
Hook 功能分为两步骤,第一部分是注册 hooks。
def _register_hooks(self):
if self._groups is not None: # groups,有兴趣同学可以自行研究,可以理解为把梯度分组
p_list = []
# Get list of parameters with grads
for param_group in self.param_groups:
for p in param_group['params']:
if p.requires_grad:
p_list.append(p)
# To ensure parameter order and group formation is consistent, broadcast p_list order
# from rank 0 and use for every worker
p_list_names = [self._parameter_names.get(p) for p in p_list]
p_list_names = broadcast_object(p_list_names, root_rank=0)
p_list = sorted(p_list, key=lambda p : p_list_names.index(self._parameter_names.get(p)))
# Form groups
if isinstance(self._groups, list):
p_groups = []
grouped_id = set()
p_list_ids = [id(p) for p in p_list]
for group in self._groups:
p_groups.append([p for p in group if id(p) in p_list_ids])
for p in p_groups[-1]:
grouped_id.add(id(p))
for p in p_list:
if id(p) not in grouped_id:
p_groups.append([p])
else:
p_groups = split_list(p_list, self._groups)
p_groups = [tuple(p) for p in p_groups]
for group in p_groups:
for p in group:
self._p_to_group[p] = group
self._group_counts[group] = 0
# 注册hooks
for param_group in self.param_groups: # 遍历组
for p in param_group['params']: # 遍历组中的参数
if p.requires_grad: # 如果需要计算梯度
p.grad = p.data.new(p.size()).zero_()
self._requires_update.add(p)
p_tmp = p.expand_as(p)
grad_acc = p_tmp.grad_fn.next_functions[0][0] # 获取梯度函数
grad_acc.register_hook(self._make_hook(p)) # 注册hook到梯度函数之上
self._grad_accs.append(grad_acc)
_make_hook 会构建 hooks,返回了 hook 函数,该函数会在反向传播时候被调用,其内部执行了all-reduce。
def _make_hook(self, p):
def hook(*ignore):
# 省略部分代码
handle, ctx = None, None
self._allreduce_delay[p] -= 1
if self._allreduce_delay[p] == 0:
if self._groups is not None: # 处理 groups 相关部分,我们略过
group = self._p_to_group[p]
self._group_counts[group] += 1
if self._group_counts[group] == len(group):
handle, ctxs = self._grouped_allreduce_grad_async(group) # 被调用时候会进行all-reduce
self._handles[group] = (handle, ctxs)
# Remove any None entries from previous no-op hook calls
for gp in group:
self._handles.pop(gp, None)
self._group_counts[group] = 0
return
else:
handle, ctx = self._allreduce_grad_async(p) # 被调用时候会进行all-reduce
self._handles[p] = (handle, ctx) # 把handle注册到本地,后续会使用
return hook
4.1.2 归并梯度
第二个阶段是归并,就是在反向传播阶段调用了 hook 函数,进行 all-reduce。
def _allreduce_grad_async(self, p):
name = self._parameter_names.get(p)
tensor = p.grad
tensor_compressed, ctx = self._compression.compress(tensor)
if self.op == Average:
# Split average operation across pre/postscale factors
# C++ backend will apply additional 1 / size() factor to postscale_factor for op == Average.
prescale_factor = 1.0 / self.gradient_predivide_factor
postscale_factor = self.gradient_predivide_factor
else:
prescale_factor = 1.0
postscale_factor = 1.0
# 调用 allreduce_async_ 完成 MPI 调用
handle = allreduce_async_(tensor_compressed, name=name, op=self.op,
prescale_factor=prescale_factor,
postscale_factor=postscale_factor)
return handle, ctx
def _grouped_allreduce_grad_async(self, ps):
name = self._parameter_names.get(ps[0])
tensors_compressed, ctxs = zip(*[self._compression.compress(p.grad) for p in ps])
handle = grouped_allreduce_async_(tensors_compressed, name=name, op=self.op)
return handle, ctxs
4.1.2.1 MPI 函数
具体 MPI 函数位于 horovod/torch/mpi_ops.py
这里要点是:allreduce_async_ 返回了一个 handle,后续可以控制,比如 poll 或者 synchronize。
def allreduce_async_(tensor, average=None, name=None, op=None,
prescale_factor=1.0, postscale_factor=1.0):
"""
A function that performs asynchronous in-place averaging or summation of the input
tensor over all the Horovod processes.
The reduction operation is keyed by the name. If name is not provided, an incremented
auto-generated name is used. The tensor type and shape must be the same on all
Horovod processes for a given name. The reduction will not start until all processes
are ready to send and receive the tensor.
Arguments:
tensor: A tensor to reduce.
average:
.. warning:: .. deprecated:: 0.19.0
Use `op` instead. Will be removed in v0.21.0.
name: A name of the reduction operation.
op: The reduction operation to combine tensors across different ranks. Defaults to
Average if None is given.
prescale_factor: Multiplicative factor to scale tensor before allreduce.
postscale_factor: Multiplicative factor to scale tensor after allreduce.
Returns:
A handle to the allreduce operation that can be used with `poll()` or
`synchronize()`.
"""
op = handle_average_backwards_compatibility(op, average)
return _allreduce_async(tensor, tensor, name, op, prescale_factor, postscale_factor)
_allreduce_async 位于 horovod/torch/mpi_ops.py,其从 MPI 库之中提取函数进行处理。
def _allreduce_async(tensor, output, name, op, prescale_factor, postscale_factor):
# Set the divisor for reduced gradients to average when necessary
if op == Average:
if rocm_built():
# For ROCm, perform averaging at framework level
divisor = size()
op = Sum
else:
divisor = 1
elif op == Adasum:
if tensor.device.type != 'cpu' and gpu_available('torch'):
if nccl_built():
if rocm_built():
# For ROCm, perform averaging at framework level
divisor = local_size()
else:
divisor = 1
else:
divisor = 1
else:
divisor = 1
else:
divisor = 1
function = _check_function(_allreduce_function_factory, tensor)
try:
handle = getattr(mpi_lib, function)(tensor, output, divisor,
name.encode() if name is not None else _NULL, op,
prescale_factor, postscale_factor)
except RuntimeError as e:
raise HorovodInternalError(e)
_handle_map[handle] = (tensor, output)
return handle
4.1.2.2 原理图
这个图和DDP类似,因此略过。
4.2 step 同步梯度
step 是另外一个进行all-reduce 操作的途径。
step函数定义如下,可以看到,如果需要强制同步,就调用self.synchronize(),否则就调用基类的 step 函数来更新参数。
def step(self, closure=None):
if self._should_synchronize:
if self._synchronized:
warnings.warn("optimizer.step() called without "
"optimizer.skip_synchronize() context after "
"optimizer.synchronize(). This can cause training "
"slowdown. You may want to consider using "
"optimizer.skip_synchronize() context if you use "
"optimizer.synchronize() in your code.")
self.synchronize()
self._synchronized = False
return super(self.__class__, self).step(closure)
4.2.1 synchronize
上面提到了 synchronize,我们下面就仔细研究一下。
从注释中可以了解,synchronize() 是用来强制allreduce 操作完成,这对于梯度裁剪(gradient
clipping)或者其他有 in place 梯度修改的操作特别有用,这些操作需要在step()之前完成。
synchronize() 需要和 optimizer.skip_synchronize()一起合作。
DistributedOptimizer exposes the ``synchronize()`` method, which forces allreduce operations
to finish before continuing the execution. It's useful in conjunction with gradient
clipping, or other operations that modify gradients in place before ``step()`` is executed.
Make sure to use ``optimizer.skip_synchronize()`` if you're calling ``synchronize()``
in your code.
4.2.2 梯度裁剪
首先要了解什么是梯度爆炸,梯度爆炸指的是在模型训练过程之中,因为梯度变得太大而使得模型不稳定,容易直接跳过最优解。梯度裁剪(gradient clipping)就是一种解决梯度爆炸的技术 :如果梯度变得太大,那么就调节它使其保持较小的状态,这样可以避免模型越过最优点。
为了和梯度裁剪协同,需要在 step 之前调用 synchronize 以强制 all-reduce 完成。源码中的例子如下:
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.synchronize()
torch.nn.utils.clip_grad_norm_(model.parameters(), args.clip)
with optimizer.skip_synchronize():
optimizer.step()
4.2.3 实现
我们接下来看看 synchronize 的实现。这里最重要的是 outputs = synchronize(handle) 调用了 horovod.torch.mpi_ops.synchronize 完成了同步操作,这地方很容易让新手误解,因为名字相同,容易误会成递归。
from horovod.torch.mpi_ops import synchronize
def synchronize(self):
completed = set()
for x in self._handles.keys():
completed.update(x) if isinstance(x, tuple) else completed.add(x)
missing_p = self._requires_update - completed # 找到目前没有计算完毕的梯度
for p in missing_p:
handle, ctx = self._allreduce_grad_async(p) # 对于没有计算完毕的,显式进行all-reduce
self._handles[p] = (handle, ctx) # 记录下来本次计算的handle
for p, (handle, ctx) in self._handles.items():
if handle is None: # 如果没有记录调用过all-reduce
handle, ctx = self._allreduce_grad_async(p) # 进行all-reduce
self._handles[p] = (handle, ctx)
for p, (handle, ctx) in self._handles.items(): # 最后统一进行同步!
if isinstance(p, tuple):
# This was a grouped result, need to unpack
outputs = synchronize(handle) # 调用 mpi 同步操作
for gp, output, gctx in zip(p, outputs, ctx):
self._allreduce_delay[gp] = self.backward_passes_per_step
gp.grad.set_(self._compression.decompress(output, gctx))
else:
output = synchronize(handle) # 调用 mpi 同步操作
self._allreduce_delay[p] = self.backward_passes_per_step
p.grad.set_(self._compression.decompress(output, ctx))
self._handles.clear()
self._synchronized = True
4.2.4 MPI 同步操作
代码位于 horovod/torch/mpi_ops.py,直接调用了MPI 库函数,有兴趣同学可以自己深入研究。
def synchronize(handle):
"""
Synchronizes an asynchronous allreduce, allgather or broadcast operation until
it's completed. Returns the result of the operation.
Arguments:
handle: A handle returned by an allreduce, allgather or broadcast asynchronous
operation.
Returns:
An output tensor of the operation.
"""
if handle not in _handle_map:
return
try:
mpi_lib.horovod_torch_wait_and_clear(handle)
output = _handle_map.pop(handle)[-1]
return output
except RuntimeError as e:
raise HorovodInternalError(e)
4.2.5 图示
目前逻辑如下图所示:
+---------------------------------------------------------------------------------+
| Process 1 on GPU 1 |
| +----------------------------+ |
| | Optimizer | |
| | | |
| Forward +----> Loss +-----> Backward +----> | ALL-REDUCE +----> step | |
| | | |
| | ^ | |
| | | | |
| +----------------------------+ |
| | |
+---------------------------------------------------------------------------------+
|
|
|
|
|
SYNC|GRADS
|
|
|
|
+----------------------------------------------------------------------------------+
| Process 2 on GPU 2 | |
| | |
| +-----------------------------+ |
| | Optimizer | | |
| | | | |
| Forward +----> Loss +-----> Backward +----> | v | |
| | ALL-REDUCE +----> step | |
| | | |
| +-----------------------------+ |
| |
+----------------------------------------------------------------------------------+
至此,数据并行优化器分析完毕,下一篇我们介绍PyTorch 分布式优化器,敬请期待。
0xFF 参考
torch.optim.optimizer源码阅读和灵活使用
pytorch源码阅读(二)optimizer原理
pytorch 优化器(optim)不同参数组,不同学习率设置的操作
Pytorch——momentum动量
各种优化方法总结比较(sgd/momentum/Nesterov/adagrad/adadelta)
【优化器】优化器算法及PyTorch实现(一):永不磨灭的SGD
以optim.SGD为例介绍pytorch优化器
Pytorch学习笔记08----优化器算法Optimizer详解(SGD、Adam)
pytorch中使用torch.optim优化神经网络以及优化器的选择 - pytorch中文网
pytorch优化器详解:SGD
Pytorch里addmm()和addmm_()的用法详解
PyTorch下的可视化工具
PyTorch的优化器