四不帮你弄懂网络编程之最后一步
目录
1 Http原理
1.1 为啥会有应用层
1.2 什么是url
1.3 urlencode和urldecode
1.4 Http协议格式
1.5 Http的方法
1.6 Http的状态码
最常见的状态码, 比如 200(OK), 404(Not Found), 403(Forbidden), 302(Redirect, 重定向), 504(Bad Gateway)
1.7 Http常见的Header
2 Http server
3.1 用户信息
3.3 session
4 简单的html
4.1 html介绍
总结
1 Http原理
1.1 为啥会有应用层
我们已经学过
TCP/IP
,
已经知道目前数据能从客户端进程经过路径选择跨网络传送到服务器端进程
[
IP+Port
],
可
是,仅仅把数据从
A
点传送到
B
点就完了吗?这就好比,在淘宝上买了一部手机,卖家
[
客户端
]
把手机通过顺丰
[
传送
+
路径选择
]
送到买家
[
服务器
]
手里就完了吗?当然不是,买家还要使用这款产品,还要在使用之后,给卖家打分评
论。所以,我们把数据从
A
端传送到
B
端,
TCP/IP
解决的是顺丰的功能,而两端还要对数据进行加工处理或者使用,
所以我们还需要一层协议,不关心通信细节,关心应用细节!
这层协议叫做应用层协议。而应用是有不同的场景的,所以应用层协议是有不同种类的,其中经典协议之一的
HTTP
就是其中的佼佼者。那么,
Http
是解决什么应用场景呢?
早期用户,上网使用浏览器来进行上网,而用浏览器上网阅读信息,最常见的是查看各种网页【其实也是文件数据, 不过是一系列的 html
文档,当然还有其他资源如图片,
css
,
js
等】
,
而要把网页文件信息通过网络传送到客户
端,或者把用户数据上传到服务器,就需要
Http
协议【当然,
http
作用不限于此】
那如何理解应用层协议呢?再回到我们刚刚说的买手机的例子,顺丰相当于
TCP/IP
的功能,那么买回来的手机都附
带了说明书【产品介绍,使用介绍,注意事项等】,而该说明书指导用户该如何使用手机【虽然我们都不看,但是父
母辈有部分是有看说明书的习惯的:)】,此时的说明书可以理解为用户层协议
1.2 什么是url
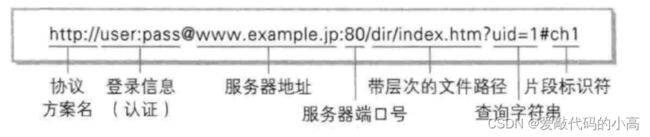
平时我们俗称的
"
网址
"
其实就是说的
URL
1.3 urlencode和urldecode
像
/ ? :
等这样的字符
,
已经被
url
当做特殊意义理解了
.
因此这些字符不能随意出现
.
比如
,
某个参数中需要带有这些特殊字符
,
就必须先对特殊字符进行转义
.
转义的规则如下
:
将需要转码的字符转为
16
进制,然后从右到左,取
4
位
(
不足
4
位直接处理
)
,每
2
位做一位,前面加上
%
,编码成
%XY
格式
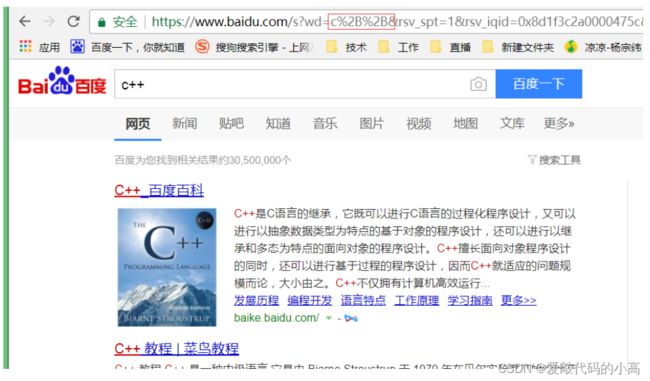
"+"
被转义成了
"%2B"
urldecode
就是
urlencode
的逆过程
;
1.4 Http协议格式
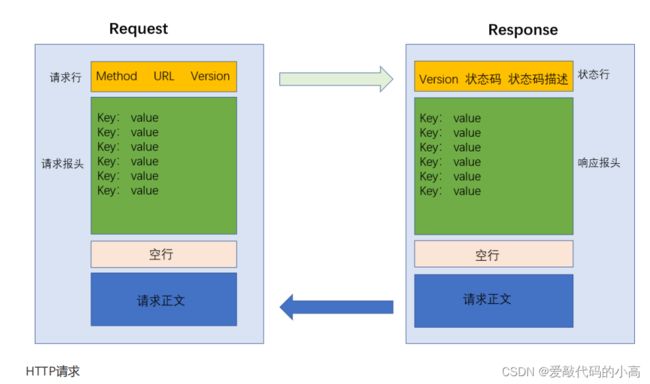
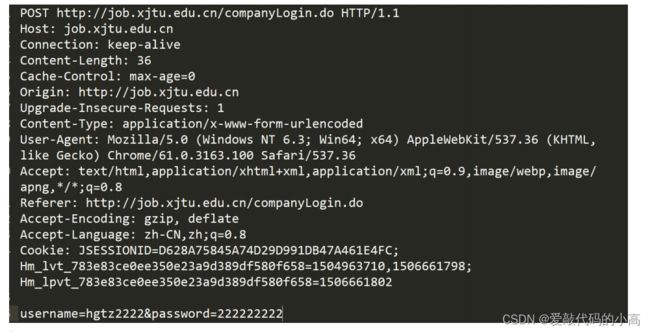
首行
: [
方法
] + [url] + [
版本
]
Header:
请求的属性
,
冒号分割的键值对
;
每组属性之间使用
\n
分隔
;
遇到空行表示
Header
部分结束
Body:
空行后面的内容都是
Body. Body
允许为空字符串
.
如果
Body
存在
,
则在
Header
中会有一个
Content
Length
属性来标识
Body
的长度
;
HTTP
响应
首行
: [
版本号
] + [
状态码
] + [
状态码解释
]
Header:
请求的属性
,
冒号分割的键值对
;
每组属性之间使用
\n
分隔
;
遇到空行表示
Header
部分结束
Body:
空行后面的内容都是
Body. Body
允许为空字符串
.
如果
Body
存在
,
则在
Header
中会有一个
Content
Length
属性来标识
Body
的长度
;
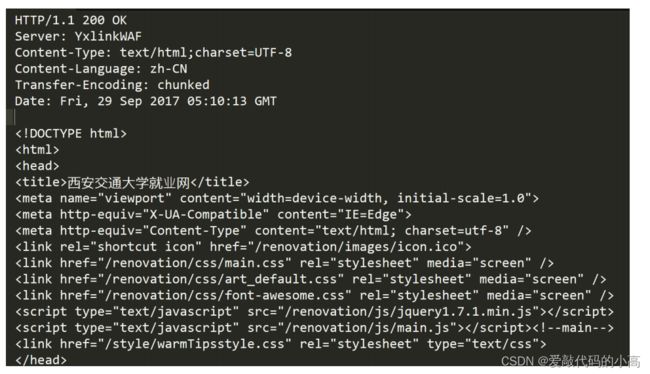
如果服务器返回了一个
html
页面
,
那么
html
页面内容就是在
body
中
.
1.5 Http的方法
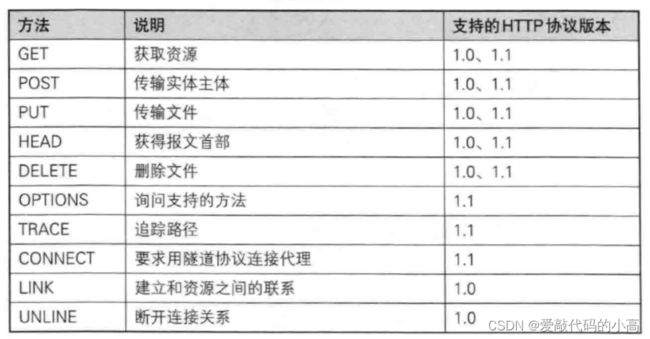
其中最常用的就是GET方法和POST方法.
1.6 Http的状态码
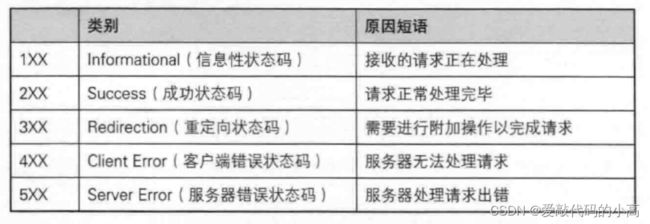 最常见的状态码, 比如 200(OK), 404(Not Found), 403(Forbidden), 302(Redirect, 重定向), 504(Bad Gateway)
最常见的状态码, 比如 200(OK), 404(Not Found), 403(Forbidden), 302(Redirect, 重定向), 504(Bad Gateway)
1.7 Http常见的Header
Content-Type:
数据类型
(text/html
等
)
Content-Length: Body
的长度
Host:
客户端告知服务器
,
所请求的资源是在哪个主机的哪个端口上
;
User-Agent:
声明用户的操作系统和浏览器版本信息
;
referer:
当前页面是从哪个页面跳转过来的
;
location:
搭配
3xx
状态码使用
,
告诉客户端接下来要去哪里访问
;
Cookie:
用于在客户端存储少量信息
.
通常用于实现会话
(session)
的功能
;
2 Http server


3 session 和cookie
3.1 用户信息
Http
是一个无状态协议
,
就是说这一次请求和上一次请求是没有任何关系的,互不认识的,没有关联的。这种无状态
的的好处是快速。坏处是需要进行用户状态保持的场景时
[
比如,登陆状态下进行页面跳转,或者用户信息多页面共
享等场景
]
,必须使用一些方式或者手段比如:
session
和
cookie
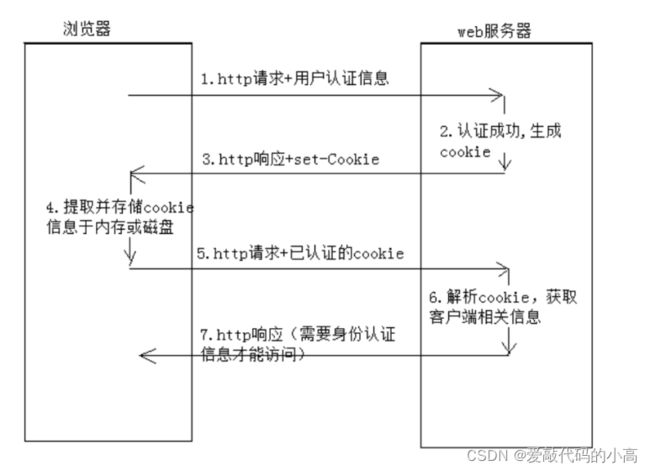
3.2 cookie
如上所述,
Http
是一个无状态的协议,但是访问有些资源的时候往往需要经过认证的账户才能访问,而且要一直保
持在线状态,所以,
cookie
是一种在浏览器端解决的方案,将登陆认证之后的用户信息保存在本地浏览器中,后面每
次发起
http
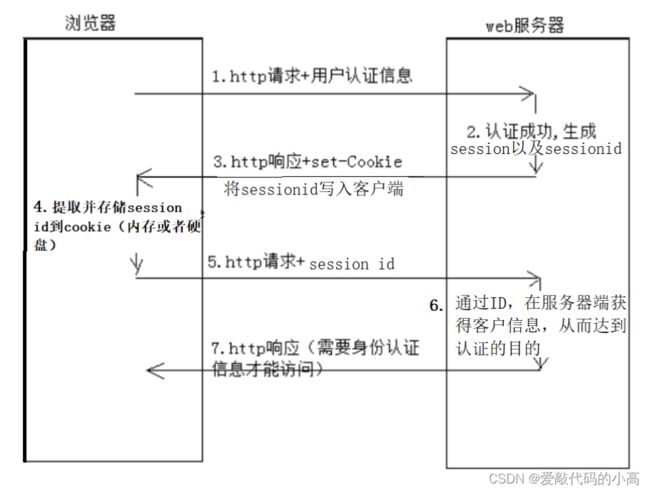
请求,都自动携带上该信息,就能达到认证用户,保持用户在线的作用,具体如下图:
3.3 session
而将用户敏感信息放到本地浏览器中,能解决一定的问题,但是又引进了新的安全问题,一旦
cookie
丢失,用户信息
泄露,也很容易造成跨站攻击,所以有了另一种解决方法,将用户敏感信息保存至服务器,而服务器本身采用
md5
算
法或相关算法生成唯一值(
session id
),将该值保存值客户端浏览器,随后,客户端的后续请求,浏览器都会自动
携带该
id
,进而再在服务器端认证,进而达到状态保持的效果
3.4 cookie和session的区别
Cookie
以文本文件格式存储在浏览器中,而
session
存储在服务端
因为每次发起
Http
请求,都要携带有效
Cookie
信息,所以
Cookie
一般都有大小限制,以防止增加网络压力
,
一
般不超过
4k
可以轻松访问
cookie
值但是我们无法轻松访问会话值,因此
session
方案更安全
4 简单的html
4.1 html介绍
HTML
是用于创建网页的语言。我们通过使用
HTML
标记标签创建
html
文档来创建网页。
HTML
代表超文本标记
语言。
HTML
是一种标记语言,它是标记标签的集合。
HTML
标签是由尖括号括起来的词,如
,
。标签通常成对出现,例如
和
。
一对中的第一个标签是开始标签
;
第二个标签是结束标签。如是开始标签,而
是结束标签,我们还可以
将开始标签称为起始标签,结束标签称为闭合标签。
HTML
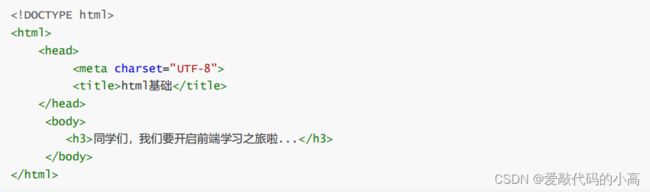
文档结构至少要包括
head, body
两部分
.
如
:
总结
本次的网络编程分享到此为止,内容指定有很多不足,但学习本就是一个循序渐进的过程,我也会继续学习相关知识,继续和大家一起来分享,大家务必不吝赐教,在此感激不尽!!!越来越好!