当我们在浏览器访问某个网址时,这背后会发生什么呢?
前言
当我们向浏览器输入网址后会发生什么呢,大家有没有想过,这背后有着什么神奇的事情发生,今天,蛋蛋我就一层一层为大家揭秘浏览器背后的故事。
本文会从如何生成 HTTP 消息展开,接着介绍 DNS 服务器是怎么帮我们查询 IP 地址的,最后介绍协议栈最终是怎么把消息发送出去的,文章很长,你要忍住。
一、生成 HTTP 请求消息
1.1 解析 URL
网址,其实应该叫 URL 。一般网址都是以 “http://" 开头,但也不乏有其他开头的,例如:“ftp://” , “file://” 等等。
这部分文字表示的是浏览器使用的访问方法。当访问 Web 服务器时,使用 HTTP 协议,访问 FTP 服务器则使用的是 FTP 协议。
整个 URL 除了有开头需要指定的协议方法,还会包含服务器的域名和要访问的文件路径名等,如下图所示: 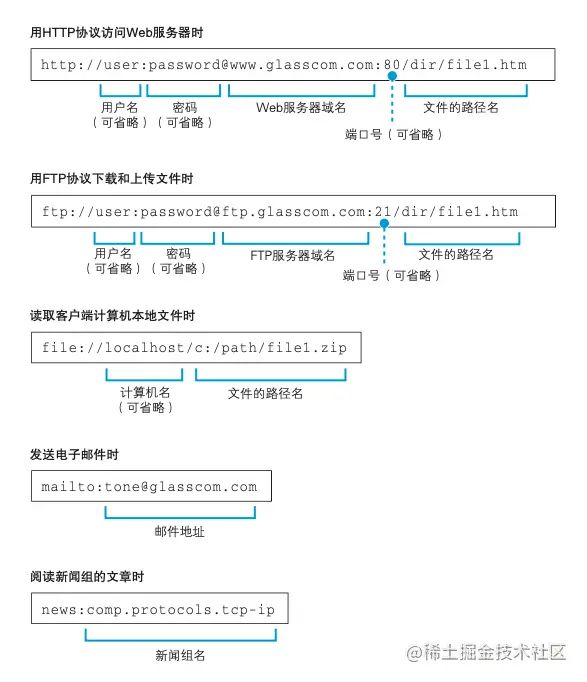
我们以 HTTP 的协议来进行举例讲解:www.lab.glasscom.com 表示要访问的服务器地址,而后面的路径名 /dir/file1.html 表示访问该服务器这个路径下的 file1.html 文件。
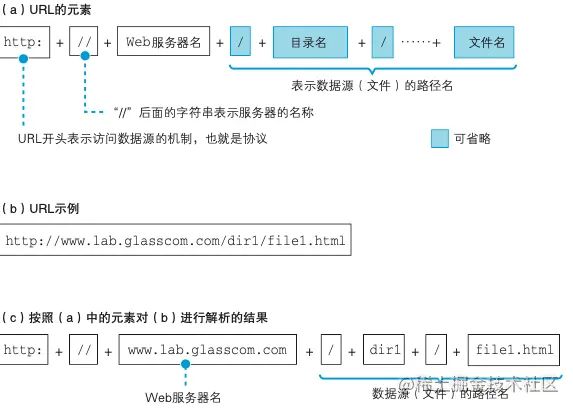
可能有些小伙伴就有些疑问了,日常生活中我们有时候访问的网站地址没有指定具体要访问的文件名,只有一个简单的域名,一般这种情况服务器大多数会设置一个默认的访问路径,例如是 index.html 或者是 default.htm 等。
这就是浏览器工作的第一步,对 URL 进行解析。
1.2 HTTP 基本工作原理
通过对 URL 进行解析,我们已经知道访问的目的地是哪了,接下来浏览器就会通过 HTTP 协议 来访问 Web 服务器,HTTP 协议是一个很重要的知识点,后期我会专门出个专栏进行详细讲解,这里我先简单介绍下,让大家有个概念。
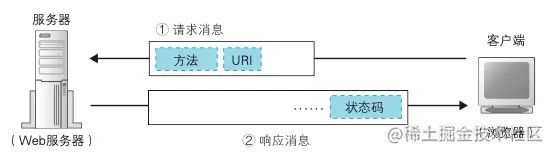
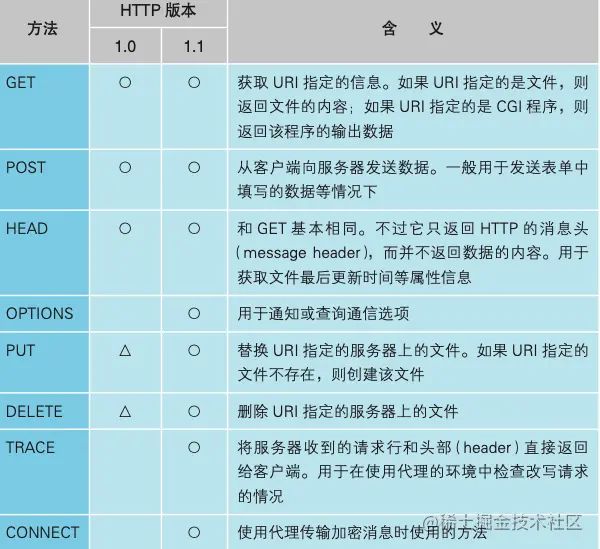
HTTP 协议定义了客户端和服务器之间交互的消息内容与步骤。如上图所示,客户端会向服务器发送请求消息,请求可以有不同的操作,HTTP 通过方法来表示不同的操作:
Web 服务器收到请求后,完成自己的处理,会将处理的结果存放在响应消息中,响应消息会发生回客户端,然后客户端读取结果进行展示。
1.3 HTTP 请求消息生成
HTTP 请求消息对格式是有要求的,因此浏览器会按照规定的格式来生成请求消息。
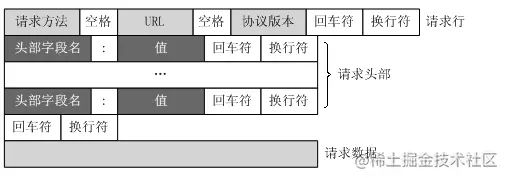
- 请求行:请求消息的第一行叫作请求行,这里面有三个重要的参数,请求方法,告诉了服务器应该进行怎样的操作;URL :指定了需要访问的服务器地址及路径,最后是协议版本,HTTP 协议有不同的版本,需要标明 HTTP 的版本号。
- 请求头:请求头用来放置一些额外的详细信息,例如客户端支持的数据类型、语言、压缩格式、日期等。
- 消息体:这里存放你需要发送的数据。
这里我给大家举个真实的例子,来一探究竟。
例如我们访问 www.baidu.com

第一行就是请求行,从请求行可以看出,是 GET 请求,访问路径是 / ,协议版本是 1.1
从第一行往下都是请求头,因为没有需要发送的数据,所以没有请求体。
1.4 请求消息后收到响应
响应消息的格式和请求消息大致是相同的,区别只在第一行。
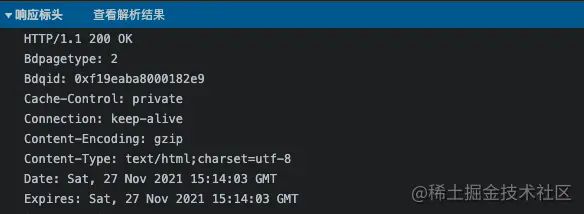
响应消息的第一行内容为请求协议、状态码和响应短语,用来表示请求的执行结果是成功还是出错。
二、如何查询 IP 地址
2.1 IP 地址的基本知识
生成 HTTP 消息后,我们就会通过操作系统将消息发送给你 Web 服务器。通过操作系统发消息之前,还有一件重要的事情要做,就是查询域名对应的 IP 地址。
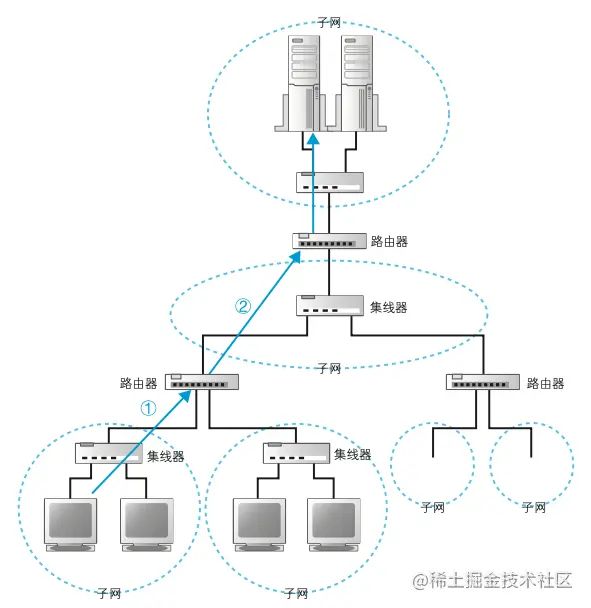
互联网中的局域网都是基于 TCP/IP 来设计的。通过一些小的子网,使用路由器连接起来组成一个大的网络,就形成了一个网络。网络中,所有设备都会被分配一个地址,就像你住的地方,叫“xx 号 xx 室”, 这个号就是分配给整个子网的,室是分配给子网中的计算机的,整体就叫作 IP 地址。发送者发出的消息首先会经过子网的集线器转发到距离最近的路由器,再由路由器根据目的地地址发送给下一个路由器,不断重复这个过程最终抵达目的地。
2.2 域名和 IP 地址为何要共用
首先抛出两个问题,大家先思考一下:
- 我们通过 IP 地址就能直接确定目标地址,为啥还要用域名呢?
- 能不能直接用域名确定访问对象?
先解答第一个问题,IP 地址是一串数字,但是想想实际情况,如果每次让你访问网站都输入 IP 地址,估计你很难记得住,而使用名称就好记的多,而且更有辨识度。
再来说说第二个问题,用域名来直接确定访问对象,绕过 IP ,从实际运行效率来说,这是不可行的,IP 地址长度是 4 个字节,域名即使最短的也需要几十个字节,字节越长,路由器处理数据时间会越长,路由器的速度是有极限的,目前的现实情况路由器性能已经快达到饱和了,所以直接访问是行不通的,那有什么好办法吗?
就是通过让人来使用名称,让路由器来使用 IP 地址,谁来建立域名和IP地址的关系呢,这个桥梁就是 DNS。
2.3 如何查询 IP 地址
通过 DNS 服务器 我们就可以查到 IP 地址。我们计算机都会有一个 DNS 客户端 用来向 DNS 服务器发起请求,我们把它叫作 DNS解析器,通过 DNS 查询 IP 地址的操作就是域名解析。
三、 DNS 服务器详解
3.1 DNS 服务器基本工作流程
其基本工作就是接收来自客户端的查询消息,然后根据消息内容返回响应信息。
一般来说,客户端的查询消息会包含三个部分:
-
域名:服务器的名字
-
Class : Class 的值永远是代表互联网的 IN
-
记录类型:表示域名对应的类型。类型为 A ,表示域名对应的是 IP 地址,类型为 MX ,表示域名对应的是邮件服务器。
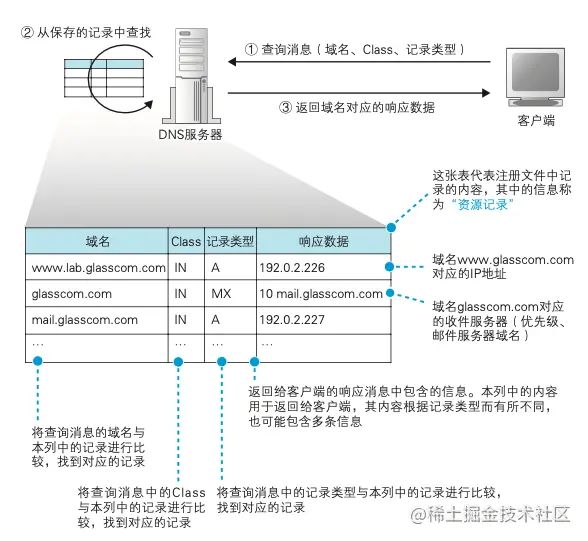
DNS 服务器 会从域名与 IP 地址的对照表中查找相应的记录进行返回。
3.2 如何根据域名的结构快速查找
当前域名的数量是海量的,不可能都放在一台 DNS 服务器中,因此这些信息会被分布保存在多台 DNS 服务器 中,这些 DNS 服务器相互接力配合,查找出最终的结果。
DNS 中的域名是用句点来分隔的,例如 www.lab.glasscom.com ,如果按照公司的组织架构,com 就代表 集团,glass com 代表事业部 ,lab 代表 小组。在一个层级的部分叫作域。
一个域的信息会作为一个整体存放在 DNS 服务器中,一台服务器可以存放多个域的信息。
我们怎么找到要访问的服务器的信息归宿哪一台 DNS 服务器管呢? 首先,我们可以将负责管理下级域的 DNS 服务器的 IP 地址 注册到 其上级 DNS 服务器中,然后上级 DNS 服务器 的 IP 地址再注册到更上一级的 DNS 服务器,以此类推。这样做的好处是什么呢?假如我们要查询 www.lab.glasscom.com,那么我们可以通过 com 域的 DNS 服务器向下查到 保存 glasscom.com 域的 DNS 服务器,一直往下,最终我们就能查到需要的 域名所对应的 IP 地址。
在现实生活中,有一种保存根域的服务器,什么是根域,就是比 com 还要上一级的域,一般不会在 域名中体现,但其是真实存在的,它管理着所有下级 DNS 服务器的信息,根域服务器的 IP 地址全世界只有 13 个。这些地址不会发生改变,因此所有的 DNS 服务器都会保存这 13 个 IP 地址。
我们来看下具体是怎么找目标 DNS 服务器的。
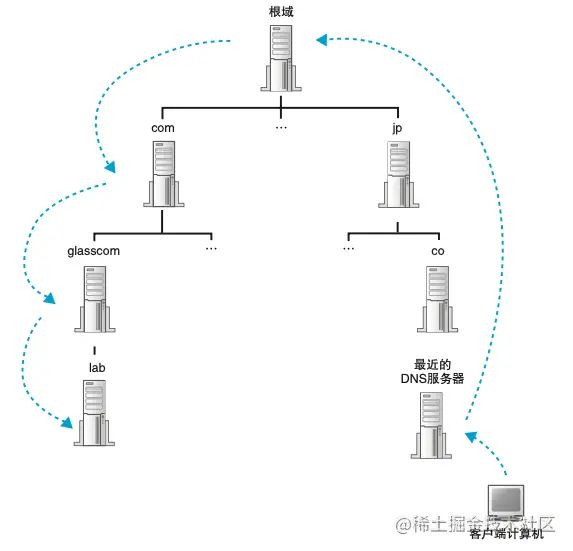
客户端首先会访问最近的一台 DNS 服务器,然后因为最近的 DNS 服务器没有保存我们需要的域名对应的 IP 地址,因此我们需要从顶层往下找,通过根域服务器向下查找,直到找到目标 DNS 服务器,从而获得我们需要的 IP 地址。
一般来说,如果是我们经常查询的域名信息, DNS 服务器本身具有缓存功能,会记录你之前查询过的域名,这样当你请求的域名信息在缓存中时,DNS 服务器就会直接返回响应,省去了每次从根域找起的麻烦,减少了查询的时间。
四、委托协议栈发送消息
4.1 数据收发过程
当我们通过 DNS 服务器拿到需要的 IP 地址后,就能够让操作系统内部的协议栈向目标 IP 发送消息了。
收发数据是通过 使用 Socket 库来完成的,如下图所示: 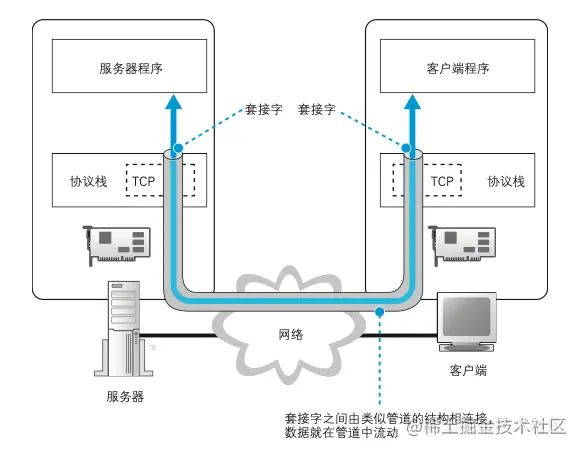
在收发数据之前,客户端和服务端都要先建立起管道,这个管道的关键就是管道的数据出入口,我们把它叫作套接字。
所以我们需要先创建套接字,才能建立起管道。服务器会先创建套接字,客户端也会创建一个套接字,然后连接到服务端上。当数据都发送完,连接到管道就会断开,通信擦操作就结束了。
我们把这个过程可以分为 4 个阶段:
-
创建套接字
-
将管道连接到服务端套接字上
-
收发数据
-
断开管道并删除套接字
4.2 创建套接字
套接字是怎么创建的呢?其实就是调用 Socket 库中的 socket 组件,创建好后,协议栈会返回一个描述符,程序收到这个描述符存放在内存当中,这个描述符是用来识别不同的套接字,因为浏览器可能会存在多个请求,那么就会创建多个套接字,所以就要有一个标志来识别。
例如当大家住酒店的时候,多个人同时来办理入住,为了确保大家入住不同的房间,会给每个人发一个房间卡来当作唯一标识,这样服务员就能根据房间卡来找到对应的人。
4.3 怎么连接管道
套接字创建好后,我们需要和服务端进行连接,这里调用了 Socket 库中的 connect 组件来完成,调用connect组件需要传递描述符、服务器 IP 地址和端口号这3个参数。
前面两个参数大家都已经知道,这个端口号是起什么作用呢?
大家想象一下,IP 地址可以让我们找到对应服务器,但是服务器可能会部署多个应用,例如部署两个web服务,我们单纯根据 IP 是无法识别的,因此我们还需要加上端口号来找到具体的服务。可能会有人说了,咱不是有描述符吗,这个是唯一的啊?这个是行不通的,因为服务端是无法知晓这个描述符的。
4.4 传递消息及收发数据结束
传递消息就很简单了,就是将数据送入套接字,就会被发送到对方的套接字中。这个过程也是通过 Socket 库的 write 程序组件来完成的。
当消息返回后,接收消息是通过 Socket 库中的 read 组件来完成。
当服务器发送完响应消息后,就会主动执行断开操作,通过 调用 close 组件来完成。当客户端接收完数据后,也会调用 close 来进行断开。
总结
当浏览器输入网址后,浏览器首先会进行 URL 解析,然后我们会生成 HTTP 请求消息并介绍了 HTTP 协议基本概念,因为我们是通过域名访问,所以需要借助 DNS 拿到目标访问对象的 IP 地址,最后我们介绍了借助 协议栈(TCP IP)真正将消息发送给服务端,并完成数据接收。
一个网址的请求背后涉及到的知识是多方面的,做到知其然,知其所以然,才能真正学到更有价值的知识,关注小蛋,带你在技术的海洋中遨游,一起进步,一起成长。