什么是DQL?其含义及其常用命令解析
写在前面:本文为本人的学习记录,若有错误欢迎指出,看到立马改正.
DDL、DQL、DML、DCL会分为四部分写,本篇写DQL。
文章目录
-
- 什么是DQL?
-
- 查询所有列
- 结果集
- 查询指定列的数据
- 条件查询
-
- 使用
- 模糊查询(属于条件查询的一种)
- 字段控制查询
-
- 去重
- 排序
- 聚合函数
- 分组查询
- SQL语句的书写顺序
- SQL语句的执行顺序
- LIMIT 分页查询
什么是DQL?
DQL:数据查询语言,用来查询数据
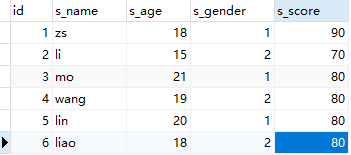
首先贴一张表,下面的查询内容会用到(仅供参考)
查询所有列
-- SELECT * FROM 表名;
SELECT * FROM stu;
结果集
- 数据库执行DQL语句不会对数据进行改变,而是让数据库发送结果集给客户端。
- 结果集:通过查询语句查询出来的数据以表的形式展示我们称这个表为虚拟结果集,存放在内存中。查询返回的结果集是一张虚拟表。
查询指定列的数据
-- SELECT 列名1,列名2 FROM 表名;
SELECT s_name,s_age FROM stu;
条件查询
条件查询就是在查询时给出WHERE子句,在WHERE子句中可以使用一些运算符及关键字;
关键字有:=(等于)、!=(不等于)、<>(不等于)、
<(小于)、<=(小于等于)、>(大于)、>(大于等于)
BETWEEN...AND;值在什么范围
lN(set);
IS NULL;(为空)IS NOT NULL(不为空)
AND;与
OR;或
NOT;非
使用
- 查询性别为男(1),且年龄为20的学生记录
SELECT * FROM stu WHERE s_gender =1 and s_age=20;
- 查询学号为1或者名为zs的记录
SELECT * FROM stu WHERE id=1 OR s_name='zs';
- 查询学号为1、2、3的记录
SELECT * FROM stu WHERE id=1 OR id=2 OR id=3;
- 查询年龄在18到20之间的学生记录
SELECT * FROM stu WHERE s_age BETWEEN 18 AND 20;
- 查询性别非男的学生记录
SELECT * FROM stu WHERE s_gender !=1;
- 查询姓名不为nul的学生记录
SELECT * FROM stu WHERE s_name IS NOT NULL;
模糊查询(属于条件查询的一种)
根据指定的关锥进行直询,使用LIKE关键字后跟通符
通配符:
_:任意一个字母
%:任意0~n个字母
使用
香问姓名由3个字母构成的学生记录
-- 三个横线
SELECT * FROM stu WHERE s_name LIKE '___';
查询姓名由4个字母构成,并且第4个字母为“g”的学生记录
-- 三个横线+g
SELECT * from stu WHERE s_name like '___g';
查询姓名以“m”开头的学生记录
SELECT * FROM stu WHERE s_name like 'm%';
查询姓名中第2个字母为“i”的学生记录
SELECT * FROM stu WHERE s_name like '_i%';
直询姓名中包含“l”字母的学生记录
SELECT * FROM stu WHERE s_name like '%l%';
字段控制查询
去重
-- 使用DISTINCT关键字
-- 查询学生名字并去除重复记录
SELECT DISTINCT s_name FROM students;
把查询字段的结果进行运算,必须都要局数值型
-- 查询年龄+分数的和
-- SELECT*.宁段1+字段2 FROM表名;
SELECT s_age+s_score FROM stu;
如果列表值存在null,那么结果为null,可以把值转换为0,这样依旧可以算出结果
SELECT *,IF NULL(s_age,0 )+IFNULL (s_score,O) FROM stu;
上面查询语句执行后,出现新的一列,列名为“s_age+s_+score”,不好看,所以我们可以给列起别名
SELECT *,IFNULL(s_age,0 )+IFNULL(s_score,0)AS total FROM stu;
排序
升序(ASC)和降序(DESC)
查询学生表并按照分数进行排序
-- 升序
SELECT * FROM stu ORDER BY s_score ASC;
-- 降序
SELECT * FROM stu ORDER BY s_score DESC;
聚合函数
对查询的结果进行统计计算
常用聚合函数
- COUNT():统计指定列不为NULL的记录行数;
- MAX():计算指定列的最大值,如果指定列是字符串类型,那么使用字符串排序算;
- MIN():计算指定列的最小值,如果指定列是字符串类型,那么使用字符串排序算;
- SUM():计算指定列的数值和,如果指定列类型不是数值类型,那么计算结果为0;
- AVG():计算指定列的平均值,如果指定列类型不是数值类型,那么计算结果为0;
使用
COUNT:
查询表中有分数的人数
SELECT COUNT(s_score) FROM stu;
查询表中分数大于80的人数
SELECT COUNT(*) FROM stu WHERE s_score>80;
查询表中分数+年龄大于80的人数
SELECT COUNT(*) FROM stu WHERE s_age+s_score>80;
SELECT COUNT(*) FROM stu WHERE IFNULL(s_age,0)+IFNULL(s_score,0)>80;
查询表中所有人的分数和
SELECT SUM(s_score) FROM stu;
查询表中所有人的分数年龄和
SELECT SUM(s_age+s_score) FROM stu;
查询表中所有人分数的平均数
SELECT AVG(s_score) FROM stu;
分组查询
将查询结果按照1个或多个字段进行分组,字段值相同的为一组
分组使用
SELECT * FROM stu GROUP BY s_gender;
根据gender字段来分组,gender字段的全部值只有两个(1和2’),所以分为了两组
当group by单独使用时,只显示出每组的第一条记录
所以group by单独使用时的实际意义不大
查询所有学生姓名、性别并按照性别分组
SELECT s_gender,GROUP_CONCAT(s_name) FROM stu GROUP BY s_gender;
注意事项
在使用分组时,select后面直接跟的字段一般都出现在group by后
group by+ group_concat()
- group_concat(字段名)可以作为一个输出字段来使用
- 表示分组之后,根据分组结果,使用group_concat()来放置每一组的某字段的值的集合
group by + 聚合函数
按性别分组查询分数以及分数总和
SELECT s_gender, GROUP_CONCAT(s_score),SUM(s_score) FROM stu GROUP BY s_gender;
通过group concatO的启发,我们既然可以统计出每个分组的某字段的值的集合,那么我们也可以通过集合函数来对这个"值的集合"做一些操作
查询两种性别以及两种性别中分数大于70的学生
SELECT s_gender,GROUP_CONCAT(s_score) FROM stu WHERE s_score>70 GROUP BY s_gender;
group by + having
- 用来分组查询后指定一些条件来输出查询结果
- having作用和where一样,但having只能用于group by
- having与where的区别
having是在分组后对都据进行过滤.where是在分组前对数据进行过滤
having后面可以使用聚合函数,而where后面不可以使用聚合函数
WHERE是对分组前记录的条件。如果某行记录没有满足WHERE子句的条件,那么这行记录不会参加分组;而HAVING是对分组后数据的约束。
查询分数总和大于240的性别以及分数总和
SELECT s_gender,GROUP_CONCAT(s_score) , SUM(s_score)FROM stu
GROUP BY s_gender HAVING SUM(s_score)>240;
查询分数大于70的,分数总和大于240的性别以及分数和
SELECT s_gender, GROUP_CONCAT(s_score),SUM(s_score) FROM stu
WHERE s_score>70
GROUP BY s_gender HAVING SUM(s_score)>240;
SQL语句的书写顺序
![]()
SQL语句的执行顺序
![]()
LIMIT 分页查询
- 从哪一行开始查,总共要查几行
- Limit参数1(从哪行开始),参数2(一共查几行)
- 角标是从0开始的
- 分页思路

SELECT * FROM STU LIMIT (curPage-1)*pageSize,pageSize;
查询表中前三条记录
SELECT * FROM stu LIMIT 0,3;