Redis 下载安装 单机 主从 哨兵 集群
博文目录
文章目录
- 环境准备
- 下载安装
- 单机模式
-
- 修改配置
- 编写便于操作的脚本
- 主从模式
-
- 修改配置
- 编写便于操作的脚本
- 主从工作原理
-
- 数据全量复制
- 数据部分复制
- 主从复制风暴
- 哨兵模式
-
- 修改配置
- 编写便于操作的脚本
- 选举主节点
- 集群模式
-
- 哨兵与集群的对比
- 修改配置
- 编写便于操作的脚本
- 用redis-cli创建整个redis集群
- 验证集群
环境准备
先在根目录下创建一个目录 application,后续所有软甲都装在该目录下
安装好redis后,在redis的目录下再创建一个mrathena目录,用于存放我自己写的便于使用的脚本和各种配置
下载安装
Redis官网
Redis官网下载
cd /application
yum install gcc # gcc环境
wget http://download.redis.io/releases/redis-5.0.10.tar.gz
tar zxf redis-5.0.10.tar.gz
cd redis-5.0.10
make # 报错一般都是gcc环境缺失,安装即可
# 启动程序就在 src 目录下, redis-server, redis-cli
【Redis实战】解决Redis安装时的编译报错问题
单机模式
修改配置
# NETWORK
# bind 127.0.0.1 # 要注释掉, 不然只能本机链接
# protected-mode no # 如果外部访问或多个server节点相互连接,不配密码也不配bind,则protected-mode应该配置成no,不然无法连接
port 6379
# GENERAL
daemonize yes # 后台启动
pidfile pidfile.redis.server.6379.pid # pidfile文件,会创建在运行redis-server的目录下
logfile "logfile.redis.server.6379.log" # logfile文件,会创建在运行redis-server的目录下
# SNAPSHOTTING
# save 900 1 # 注释掉所有save即可关闭RDB持久化
# save 300 10 # 注释掉所有save即可关闭RDB持久化
# save 60 10000 # 注释掉所有save即可关闭RDB持久化
dbfilename rdbfile.redis.server.6379.dump.rdb
dir ./ # dbfile目录,会创建在运行redis-server的目录下
# SECURITY
requirepass mypassword # 连接密码,如果是云服务器, 且没有修改端口, 强烈建议开启验证, 因为很容易被人挂挖矿木马
# APPEND ONLY MODE
appendonly yes # 开启AOF持久化
appendfilename "aoffile.redis.server.6379.appendonly.aof" # aof文件,会创建在运行redis-server的目录下
appendfsync everysec # 每秒同步一次aof文件
auto-aof-rewrite-percentage 100 # aof文件自上一次重写后文件大小增长了100%(这里是64M即128M)则再次触发重写
auto-aof-rewrite-min-size 64mb # aof文件至少要达到64M才会自动重写,文件太小恢复速度本来就很快,重写的意义不大
aof-use-rdb-preamble yes # 开启AOF混合持久化
启动
src/redis-server redis.conf
连接
src/redis-cli # 默认6379端口
src/redis-cli -p 6380
src/redis-cli -a mypassword -h localhost -p 6379
quit # 退出客户端
退出redis服务
pkill redis-server
kill 进程号
src/redis-cli shutdown
查看配置
config get maxclients # redis-cli 连接后执行
编写便于操作的脚本
redis.config.original.6379,拷贝于 redis.conf,然后修改了单机配置
redis.server.standalone.start.sh,用于启动 redis server 单机模式
#!/bin/sh
# 删掉不用的配置文件(如果存在)
rm -rf redis.config.6379
# 拷贝一份儿原始配置作为启动 redis server 使用的新配置
cp redis.config.original.6379 redis.config.6379
# 启动 redis server
../src/redis-server redis.config.6379
redis.server.standalone.stop.sh,用于停止 redis server 单机模式
#!/bin/sh
# 直接杀掉pid文件里面记录的线程id
kill -9 `cat pidfile.redis.server.6379.pid`
# 删除不用的配置文件
rm -rf redis.config.6379
redis.client.6379.sh,用于连接 redis server 单机模式
#!/bin/sh
../src/redis-cli -p 6379
主从模式
修改配置
6379作为主节点,6380,6381作为从节点
拷贝 redis.config.original.6379 为 redis.config.original.6380,修改其中以下参数
port 6380
pidfile pidfile.redis.server.6380.pid # pidfile文件,会创建在运行redis-server的目录下
logfile "logfile.redis.server.6380.log" # logfile文件,会创建在运行redis-server的目录下
dbfilename rdbfile.redis.server.6380.dump.rdb # rdbfile文件,会创建在运行redis-server的目录下
appendfilename "aoffile.redis.server.6380.appendonly.aof" # aof文件,会创建在运行redis-server的目录下
# REPLICATION
replicaof 172.16.138.202 6379 # 是 172.16.138.202:6379 的从, 172.16.138.202 是内网IP
replica-read-only yes # 从只读
masterauth password # 主节点的密码, 需要的话配置
编写便于操作的脚本
redis.server.masterslave.start.sh,用于开启主从3个 redis server
#!/bin/sh
# 删掉不用的配置文件(如果存在)
rm -rf redis.config.6379
rm -rf redis.config.6380
rm -rf redis.config.6381
# 拷贝一份儿原始配置作为启动 redis server 使用的新配置
cp redis.config.original.6379 redis.config.6379
cp redis.config.original.6380 redis.config.6380
cp redis.config.original.6381 redis.config.6381
# 启动 redis server
../src/redis-server redis.config.6379
../src/redis-server redis.config.6380
../src/redis-server redis.config.6381
redis.server.masterslave.stop.sh,用于关闭主从3个 redis server
#!/bin/sh
# 直接杀掉pid文件里面记录的线程id
kill -9 `cat pidfile.redis.server.6379.pid`
kill -9 `cat pidfile.redis.server.6380.pid`
kill -9 `cat pidfile.redis.server.6381.pid`
# 删除不用的配置文件
rm -rf redis.config.6379
rm -rf redis.config.6380
rm -rf redis.config.6381
redis.client.6380.sh,用于连接 redis server 主
#!/bin/sh
../src/redis-cli -p 6380
redis.client.6381.sh,用于连接 redis server 从
#!/bin/sh
../src/redis-cli -p 6381
主从工作原理
如果你为master配置了一个slave,不管这个slave是否是第一次连接上Master,它都会发送一个PSYNC命令给master请求复制数据。
master收到PSYNC命令后,会在后台进行数据持久化通过bgsave生成最新的rdb快照文件,持久化期间,master会继续接收客户端的请求,它会把这些可能修改数据集的请求缓存在内存中。当持久化进行完毕以后,master会把这份rdb文件数据集发送给slave,slave会把接收到的数据进行持久化生成rdb,然后再加载到内存中。然后,master再将之前缓存在内存中的命令发送给slave。
当master与slave之间的连接由于某些原因而断开时,slave能够自动重连Master,如果master收到了多个slave并发连接请求,它只会进行一次持久化,而不是一个连接一次,然后再把这一份持久化的数据发送给多个并发连接的slave。
数据全量复制
- slave连接master
- slave发送psync命令
- master收到psync命令,执行bgsave生成最新rdb快照数据,同时把后续写命令都缓存起来
- master发送rdb数据给slave
- slave清空老数据并加载rdb数据
- master发送缓存数据给slave
- slave执行缓存里的命令
- master通过长连接持续把写命令发送给从节点
数据部分复制
当master和slave断开重连后,一般都会对整份数据进行复制。但从redis2.8版本开始,redis改用可以支持部分数据复制的命令PSYNC去master同步数据,slave与master能够在网络连接断开重连后只进行部分数据复制(断点续传)。
master会在其内存中创建一个复制数据用的缓存队列,缓存最近一段时间的数据,master和它所有的slave都维护了复制的数据下标offset和master的进程id,因此,当网络连接断开后,slave会请求master继续进行未完成的复制,从所记录的数据下标开始。如果master进程id变化了,或者从节点数据下标offset太旧,已经不在master的缓存队列里了,那么将会进行一次全量数据的复制。
- slave断开master
- master把slave断开后的后续写命令进行缓存(repl backlog buffer)
- slave连接master
- slave发送psync(offset)命令
- master收到psync(offset)命令,判断该slave传来的offset,在 repl backlog buffer 中是否存在,存在的话,master会将offset之后的数据一次性同步给slave,不存在的话,做全量同步
- slave执行缓存里的命令
- master通过长连接持续把写命令发送给从节点
主从复制风暴
如果有很多从节点,为了缓解主从复制风暴(多个从节点同时复制主节点导致主节点压力过大),可以让部分从节点与从节点(与主节点同步)同步数据,即一颗树
哨兵模式
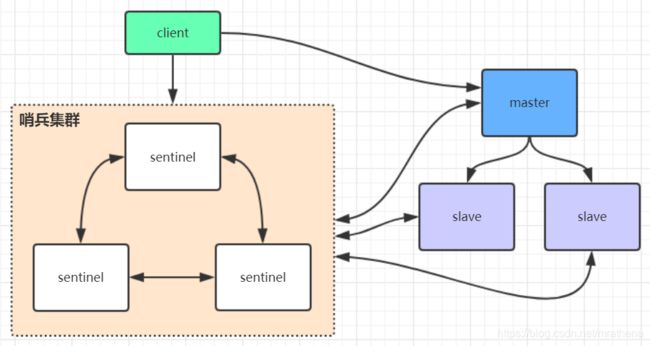
sentinel哨兵是特殊的redis服务,不提供读写服务,主要用来监控redis实例节点。
哨兵架构下client端第一次从哨兵找出redis的主节点,后续就直接访问redis的主节点,不会每次都通过sentinel代理访问redis的主节点,当redis的主节点发生变化,哨兵会第一时间感知到,并且将新的redis主节点通知给client端(这里面redis的client端一般都实现了订阅功能,订阅sentinel发布的节点变动消息)
修改配置
复制 sentinel.conf 为 redis.sentinel.config.original.26379 并修改
port 26379
daemonize yes
pidfile pidfile.redis.sentinel.26379.pid
logfile "logfile.redis.sentinel.26379.log"
dir ./
# quorum是一个数字,指明当有多少个sentinel认为一个master失效时(值一般为:sentinel总数/2 + 1),master才算真正失效
# 如果要通过公网访问,这个ip地址需要配置成公网ip,如果用内网ip的话,程序拿到的就是内网ip,不在本机上运行程序的话,是连接不上的
sentinel monitor mymaster 116.62.162.48 6379 2 # mymaster这个名字随便取,客户端访问时会用到,一组哨兵可以监控多组主从,就是靠这个名字做区分的
启动
src/redis-sentinel sentinel-26379.conf
查看哨兵信息
src/redis-cli -p 26379
127.0.0.1:26379>info
127.0.0.1:26379>sentinel master mymaster
127.0.0.1:26379>sentinel slaves mymaster
127.0.0.1:26379>sentinel sentinels mymaster
sentinel集群都启动完毕后,会将哨兵集群的元数据信息写入所有sentinel的配置文件里去(追加在文件的最下面)
# redis.sentinel.config.26379
protected-mode no
sentinel known-replica mymaster 116.62.162.48 6381 # redis主节点的从节点
sentinel known-replica mymaster 116.62.162.48 6380 # redis主节点的从节点
sentinel known-sentinel mymaster 172.16.138.202 26380 1dc91dc3f62a2f013c47494aa28f1743c145fd84 # 感知到的其它哨兵节点
sentinel known-sentinel mymaster 172.16.138.202 26381 8f0c9a7a2fbab7f0cb5c32ef51b777f13d03c341 # 感知到的其它哨兵节点
sentinel current-epoch 0
# redis.sentinel.config.26380
protected-mode no
sentinel known-replica mymaster 116.62.162.48 6381
sentinel known-replica mymaster 116.62.162.48 6380
sentinel known-sentinel mymaster 172.16.138.202 26379 c8b723802b2da8f38ebe475b23d9c0e58b5b4512
sentinel known-sentinel mymaster 172.16.138.202 26381 8f0c9a7a2fbab7f0cb5c32ef51b777f13d03c341
sentinel current-epoch 0
编写便于操作的脚本
redis.server.sentinel.start.sh,用于启动整个哨兵体系的脚本,会把旧的配置覆盖掉(主要是哨兵感知并记录在哨兵配置中的信息)
#!/bin/sh
# 删掉不用的配置文件(如果存在)
rm -rf redis.config.6379
rm -rf redis.config.6380
rm -rf redis.config.6381
# 拷贝一份儿原始配置作为启动 redis server 使用的新配置
cp redis.config.original.6379 redis.config.6379
cp redis.config.original.6380 redis.config.6380
cp redis.config.original.6381 redis.config.6381
# 启动 redis server
../src/redis-server redis.config.6379
../src/redis-server redis.config.6380
../src/redis-server redis.config.6381
# 删掉不用的哨兵配置文件
rm -rf redis.sentinel.config.26379
rm -rf redis.sentinel.config.26380
rm -rf redis.sentinel.config.26381
# 拷贝一份儿原始哨兵配置作为启动 redis sentinel 使用的新配置
cp redis.sentinel.config.original.26379 redis.sentinel.config.26379
cp redis.sentinel.config.original.26380 redis.sentinel.config.26380
cp redis.sentinel.config.original.26381 redis.sentinel.config.26381
# 启动 redis sentinel
../src/redis-sentinel redis.sentinel.config.26379
../src/redis-sentinel redis.sentinel.config.26380
../src/redis-sentinel redis.sentinel.config.26381
redis.server.sentinel.stop.sh, 用于停止整个哨兵体系的脚本
#!/bin/sh
# 杀掉哨兵进程
kill -9 `cat pidfile.redis.sentinel.26379.pid`
kill -9 `cat pidfile.redis.sentinel.26380.pid`
kill -9 `cat pidfile.redis.sentinel.26381.pid`
# 删除不用的哨兵配置文件
rm -rf redis.sentinel.config.26379
rm -rf redis.sentinel.config.26380
rm -rf redis.sentinel.config.26381
# 直接杀掉pid文件里面记录的进程id
kill -9 `cat pidfile.redis.server.6379.pid`
kill -9 `cat pidfile.redis.server.6380.pid`
kill -9 `cat pidfile.redis.server.6381.pid`
# 删除不用的配置文件
rm -rf redis.config.6379
rm -rf redis.config.6380
rm -rf redis.config.6381
选举主节点
当redis主节点如果挂了,哨兵集群会重新选举出新的redis主节点,同时会修改所有sentinel节点配置文件的集群元数据信息,比如6379的redis如果挂了,假设选举出的新主节点是6380,则sentinel文件里的集群元数据信息会变成如下所示:
redis.sentinel.config.26379
sentinel known-replica mymaster 116.62.162.48 6379
sentinel known-replica mymaster 116.62.162.48 6381
sentinel known-sentinel mymaster 172.16.138.202 26380 1012f4eb61156494a10eec863b4f698c160487c6
sentinel known-sentinel mymaster 172.16.138.202 26381 aba18c9c846e272ad147cfac9245554801aa8701
同时还会修改sentinel文件里之前配置的mymaster对应的6379端口,改为6380
redis.sentinel.config.26379
sentinel monitor mymaster 116.62.162.48 6380 2
当6379的redis实例再次启动时,哨兵集群根据集群元数据信息就可以将6379端口的redis节点作为从节点加入集群
也可从哨兵日志中看到选举过程
logfile.redis.sentinel.26379.log
14899:X 04 Nov 2020 13:39:40.901 # Configuration loaded
14900:X 04 Nov 2020 13:39:40.908 * Running mode=sentinel, port=26379.
14900:X 04 Nov 2020 13:39:40.908 # WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.
14900:X 04 Nov 2020 13:39:40.912 # Sentinel ID is 8902bc48943a310b9877ce7705fe6fdf05427e78
14900:X 04 Nov 2020 13:39:40.912 # +monitor master mymaster 116.62.162.48 6379 quorum 2
14900:X 04 Nov 2020 13:39:40.913 * +slave slave 116.62.162.48:6380 116.62.162.48 6380 @ mymaster 116.62.162.48 6379
14900:X 04 Nov 2020 13:39:40.915 * +slave slave 116.62.162.48:6381 116.62.162.48 6381 @ mymaster 116.62.162.48 6379
14900:X 04 Nov 2020 13:39:42.912 * +sentinel sentinel 1012f4eb61156494a10eec863b4f698c160487c6 172.16.138.202 26380 @ mymaster 116.62.162.48 6379
14900:X 04 Nov 2020 13:39:42.933 * +sentinel sentinel aba18c9c846e272ad147cfac9245554801aa8701 172.16.138.202 26381 @ mymaster 116.62.162.48 6379
14900:X 04 Nov 2020 13:41:26.744 # +sdown master mymaster 116.62.162.48 6379
14900:X 04 Nov 2020 13:41:26.891 # +new-epoch 1
14900:X 04 Nov 2020 13:41:26.894 # +vote-for-leader 1012f4eb61156494a10eec863b4f698c160487c6 1
14900:X 04 Nov 2020 13:41:27.286 # +config-update-from sentinel 1012f4eb61156494a10eec863b4f698c160487c6 172.16.138.202 26380 @ mymaster 116.62.162.48 6379
14900:X 04 Nov 2020 13:41:27.287 # +switch-master mymaster 116.62.162.48 6379 116.62.162.48 6380
14900:X 04 Nov 2020 13:41:27.287 * +slave slave 116.62.162.48:6381 116.62.162.48 6381 @ mymaster 116.62.162.48 6380
14900:X 04 Nov 2020 13:41:27.287 * +slave slave 116.62.162.48:6379 116.62.162.48 6379 @ mymaster 116.62.162.48 6380
集群模式
哨兵与集群的对比
在redis3.0以前的版本要实现集群一般是借助哨兵sentinel工具来监控master节点的状态,如果master节点异常,则会做主从切换,将某一台slave作为master,哨兵的配置略微复杂,并且性能和高可用性等各方面表现一般,特别是在主从切换的瞬间存在访问瞬断的情况,而且哨兵模式只有一个主节点对外提供服务,没法支持很高的并发,且单个主节点内存也不宜设置得过大,否则会导致持久化文件过大,影响数据恢复或主从同步的效率

redis集群是一个由多个主从节点群组成的分布式服务器群,它具有复制、高可用和分片特性。Redis集群不需要sentinel哨兵·也能完成节点移除和故障转移的功能。需要将每个节点设置成集群模式,这种集群模式没有中心节点,可水平扩展,据官方文档称可以线性扩展到上万个节点(官方推荐不超过1000个节点)。redis集群的性能和高可用性均优于之前版本的哨兵模式,且集群配置非常简单
修改配置
redis集群需要至少三个master节点,我们这里搭建三个master节点,并且给每个master再搭建一个slave节点,总共6个redis节点,为了方便只用一台节点,搭一个伪集群,别忘了关闭防火墙
systemctl stop firewalld # 临时关闭防火墙
systemctl disable firewalld # 禁止开机启动
拷贝 redis.config.original.6379 为 redis.cluster.config.original.8001,修改如下内容,然后拷贝另外的5份,8002-8006,批量替换可以在编辑文件时底行模式下使用命令 :%s/源字符串/目的字符串/g
# NETWORK
# bind 127.0.0.1 # 要注释掉, 不然只能本机链接
# protected-mode no # 如果外部访问或多个server节点相互连接,不配密码也不配bind,则protected-mode应该配置成no,不然无法连接
port 8001
# GENERAL
daemonize yes # 后台启动
pidfile pidfile.redis.server.8001.pid # pidfile文件,会创建在运行redis-server的目录下
logfile "logfile.redis.server.8001.log" # logfile文件,会创建在运行redis-server的目录下
# SNAPSHOTTING
# save 900 1 # 注释掉所有save即可关闭RDB持久化
# save 300 10 # 注释掉所有save即可关闭RDB持久化
# save 60 10000 # 注释掉所有save即可关闭RDB持久化
dbfilename rdbfile.redis.server.8001.dump.rdb
dir ./ # dbfile目录,会创建在运行redis-server的目录下
# SECURITY
requirepass mypassword # 设置连接redis的密码,看需要,如果要配置的话,整个集群的节点要全都配成一样的
masterauth mypassword # 设置集群节点间访问密码,跟上面一致
# APPEND ONLY MODE
appendonly yes # 开启AOF持久化
appendfilename "aoffile.redis.server.8001.appendonly.aof" # aof文件,会创建在运行redis-server的目录下
appendfsync everysec # 每秒同步一次aof文件
auto-aof-rewrite-percentage 100 # aof文件自上一次重写后文件大小增长了100%(这里是64M即128M)则再次触发重写
auto-aof-rewrite-min-size 64mb # aof文件至少要达到64M才会自动重写,文件太小恢复速度本来就很快,重写的意义不大
aof-use-rdb-preamble yes # 开启AOF混合持久化
# REDIS CLUSTER
cluster-enabled yes # 开启集群模式
cluster-config-file node.redis.cluster.8001.conf # 保存集群信息,下次启动直接读取,无需重新搭建集群
cluster-node-timeout 10000 # 表示当某个节点持续 timeout 的时间失联时,才可以认定该节点出现故障,需要进行主从切换
分别启动6个redis实例,然后检查是否启动成功,这时候才仅仅是启动,还没有把这些节点组成一个集群
编写便于操作的脚本
redis.server.cluster.start.sh,启动整个集群的所有机器
#!/bin/sh
# 删掉不用的配置文件(如果存在)
rm -rf redis.cluster.config.8001
rm -rf redis.cluster.config.8002
rm -rf redis.cluster.config.8003
rm -rf redis.cluster.config.8004
rm -rf redis.cluster.config.8005
rm -rf redis.cluster.config.8006
# 拷贝一份儿原始配置作为启动 redis server 使用的新配置
cp redis.cluster.config.original.8001 redis.cluster.config.8001
cp redis.cluster.config.original.8002 redis.cluster.config.8002
cp redis.cluster.config.original.8003 redis.cluster.config.8003
cp redis.cluster.config.original.8004 redis.cluster.config.8004
cp redis.cluster.config.original.8005 redis.cluster.config.8005
cp redis.cluster.config.original.8006 redis.cluster.config.8006
# 启动 redis server
../src/redis-server redis.cluster.config.8001
../src/redis-server redis.cluster.config.8002
../src/redis-server redis.cluster.config.8003
../src/redis-server redis.cluster.config.8004
../src/redis-server redis.cluster.config.8005
../src/redis-server redis.cluster.config.8006
redis.server.cluster.stop.sh
#!/bin/sh
# 杀掉哨兵进程
kill -9 `cat pidfile.redis.server.8001.pid`
kill -9 `cat pidfile.redis.server.8002.pid`
kill -9 `cat pidfile.redis.server.8003.pid`
kill -9 `cat pidfile.redis.server.8004.pid`
kill -9 `cat pidfile.redis.server.8005.pid`
kill -9 `cat pidfile.redis.server.8006.pid`
# 删除不用的哨兵配置文件
rm -rf redis.cluster.config.8001
rm -rf redis.cluster.config.8002
rm -rf redis.cluster.config.8003
rm -rf redis.cluster.config.8004
rm -rf redis.cluster.config.8005
rm -rf redis.cluster.config.8006
用redis-cli创建整个redis集群
redis5以前的版本集群是依靠ruby脚本redis-trib.rb实现
# 创建集群,如果没有密码可不写 -a mypassword 这部分参数,注意不关防火墙的话,要把18001-18006端口放开,redis集群节点内部通讯使用这些端口(server端口+10000),不然会卡在 Waiting for the cluster to join
# 如果要通过公网访问,这个ip地址需要配置成公网ip,如果用内网ip的话,不在本机上运行程序的话,是连接不上的
redis-cli -a mypassword --cluster create --cluster-replicas 1 172.16.138.202:8001 172.16.138.202:8002 172.16.138.202:8003 172.16.138.202:8004 172.16.138.202:8005 172.16.138.202:8006
redis.server.cluster.create.sh,同样可以做成脚本,不然输入很麻烦
../src/redis-cli --cluster create --cluster-replicas 1 172.16.138.202:8001 172.16.138.202:8002 172.16.138.202:8003 172.16.138.202:8004 172.16.138.202:8005 172.16.138.202:8006
[/application/redis-5.0.10/mrathena]# ./redis.server.cluster.create.sh
>>> Performing hash slots allocation on 6 nodes...
Master[0] -> Slots 0 - 5460
Master[1] -> Slots 5461 - 10922
Master[2] -> Slots 10923 - 16383
Adding replica 172.16.138.202:8005 to 172.16.138.202:8001
Adding replica 172.16.138.202:8006 to 172.16.138.202:8002
Adding replica 172.16.138.202:8004 to 172.16.138.202:8003
>>> Trying to optimize slaves allocation for anti-affinity
[WARNING] Some slaves are in the same host as their master
M: 7d944fb0c260809de7027916cc515347d9b0e64b 172.16.138.202:8001
slots:[0-5460] (5461 slots) master
M: 6864125aa1a00d8fbfa58c548c7fed558646341c 172.16.138.202:8002
slots:[5461-10922] (5462 slots) master
M: f6fd2a12c994fd0a3d8166b58e93ad455df80ba7 172.16.138.202:8003
slots:[10923-16383] (5461 slots) master
S: 11830b16c716c52e53cb6e4e5f004f63aca56e2e 172.16.138.202:8004
replicates 6864125aa1a00d8fbfa58c548c7fed558646341c
S: 5e694729125dc93a6f06accc951123642bb2b89a 172.16.138.202:8005
replicates f6fd2a12c994fd0a3d8166b58e93ad455df80ba7
S: dd32d87b7832217c178cea1a0b41b128a42116f9 172.16.138.202:8006
replicates 7d944fb0c260809de7027916cc515347d9b0e64b
Can I set the above configuration? (type 'yes' to accept): yes
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending CLUSTER MEET messages to join the cluster
Waiting for the cluster to join
>>> Performing Cluster Check (using node 172.16.138.202:8001)
M: 7d944fb0c260809de7027916cc515347d9b0e64b 172.16.138.202:8001
slots:[0-5460] (5461 slots) master
1 additional replica(s)
S: 5e694729125dc93a6f06accc951123642bb2b89a 172.16.138.202:8005
slots: (0 slots) slave
replicates f6fd2a12c994fd0a3d8166b58e93ad455df80ba7
S: 11830b16c716c52e53cb6e4e5f004f63aca56e2e 172.16.138.202:8004
slots: (0 slots) slave
replicates 6864125aa1a00d8fbfa58c548c7fed558646341c
M: f6fd2a12c994fd0a3d8166b58e93ad455df80ba7 172.16.138.202:8003
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
M: 6864125aa1a00d8fbfa58c548c7fed558646341c 172.16.138.202:8002
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
S: dd32d87b7832217c178cea1a0b41b128a42116f9 172.16.138.202:8006
slots: (0 slots) slave
replicates 7d944fb0c260809de7027916cc515347d9b0e64b
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
验证集群
- 连接任意一个客户端即可:./redis-cli -c -h -p (-a访问服务端密码,-c表示集群模式,指定ip地址和端口号)
如:…/src/redis-cli -c -h 172.16.138.202 -p 8001 - 进行验证: cluster info(查看集群信息)、cluster nodes(查看节点列表)
- 进行数据操作验证
- 关闭集群则需要逐个进行关闭,使用命令:…/src/redis-cli -c -h 172.16.138.202 -p 8001 shutdown
127.0.0.1:8001> cluster info
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:3
cluster_current_epoch:6
cluster_my_epoch:1
cluster_stats_messages_ping_sent:469
cluster_stats_messages_pong_sent:461
cluster_stats_messages_sent:930
cluster_stats_messages_ping_received:456
cluster_stats_messages_pong_received:469
cluster_stats_messages_meet_received:5
cluster_stats_messages_received:930
127.0.0.1:8001> cluster nodes
7d944fb0c260809de7027916cc515347d9b0e64b 172.16.138.202:8001@18001 myself,master - 0 1604592244000 1 connected 0-5460
5e694729125dc93a6f06accc951123642bb2b89a 172.16.138.202:8005@18005 slave f6fd2a12c994fd0a3d8166b58e93ad455df80ba7 0 1604592245000 5 connected
11830b16c716c52e53cb6e4e5f004f63aca56e2e 172.16.138.202:8004@18004 slave 6864125aa1a00d8fbfa58c548c7fed558646341c 0 1604592243000 4 connected
f6fd2a12c994fd0a3d8166b58e93ad455df80ba7 172.16.138.202:8003@18003 master - 0 1604592246000 3 connected 10923-16383
6864125aa1a00d8fbfa58c548c7fed558646341c 172.16.138.202:8002@18002 master - 0 1604592245000 2 connected 5461-10922
dd32d87b7832217c178cea1a0b41b128a42116f9 172.16.138.202:8006@18006 slave 7d944fb0c260809de7027916cc515347d9b0e64b 0 1604592246731 6 connected
通过验证发现,集群搭建正确,主从关系也正确,数据也可以同步,但是从节点执行 get 会重定向到主节点,可以在从节点执行 readonly 命令让其提供查询服务