Hadoop2.7.3搭建伪分布式集群
目录
1.配置文件:hadoop-env.sh
2.配置文件:core-site.xml
3.配置文件:hdfs-site.xml(可选择性配置,副本默认值是3)
4.启动集群
5.操作集群
Hadoop的集群模式有3种,具体配置信息可以参考如下链接,本篇文章先讲述如何搭建伪分布式,并登陆HDFS的web界面操作文件。
Hadoop历史版本下载:http://archive.apache.org/dist/hadoop/core/或者https://archive.apache.org/dist/hadoop/common/
注意:搭建完伪分布式后,不能再使用local模式的方式测试本地程序。
- Local (Standalone) Mode
- Pseudo-Distributed Mode
- Fully-Distributed Mode
https://hadoop.apache.org/docs/r2.7.3/
1.配置文件:hadoop-env.sh
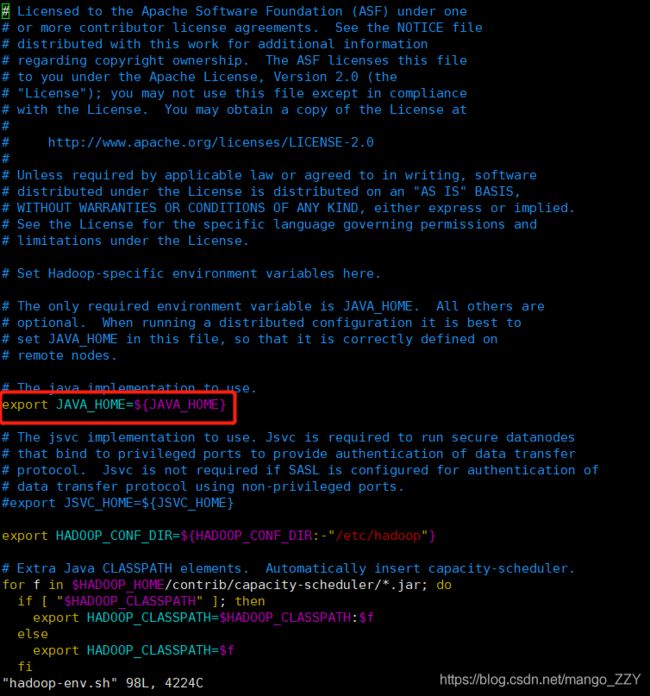
①首先,先在Linux系统中获取JDK的安装路径:
[root@hadoop01 hadoop-2.7.3]# echo $JAVA_HOME
/usr/local/java/jdk1.8.0_241②按照如图所示的方法,修改JAVA_HOME 路径:
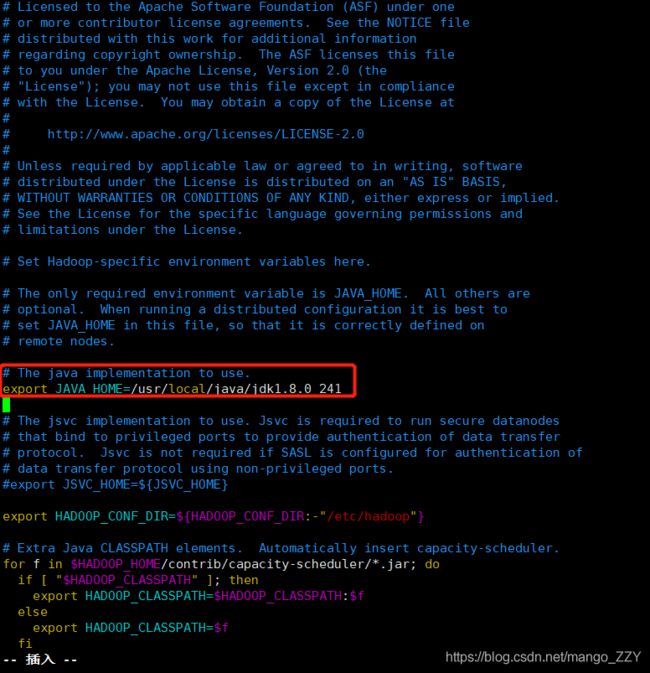
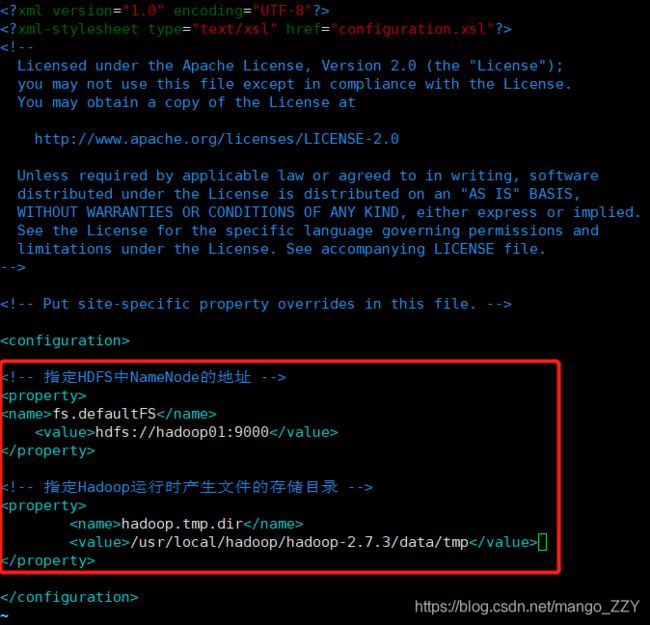
2.配置文件:core-site.xml
fs.defaultFS
hdfs://hadoop01:9000
hadoop.tmp.dir
/usr/local/hadoop/hadoop-2.7.3/data/tmp
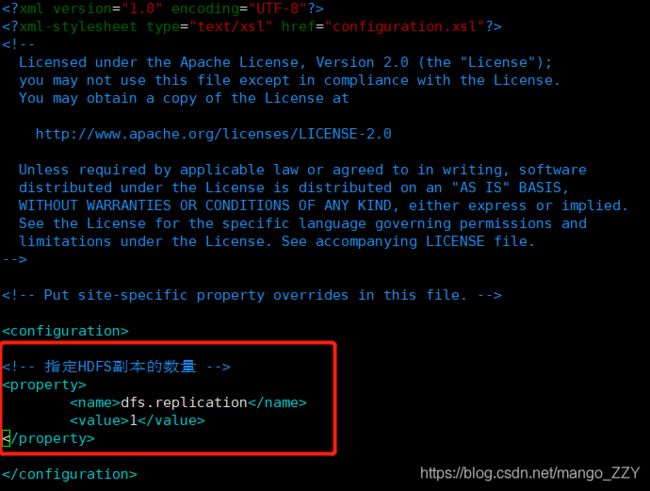
3.配置文件:hdfs-site.xml(可选择性配置,副本默认值是3)
dfs.replication
1
4.启动集群
(1)格式化NameNode(第一次启动时格式化,以后就不要总格式化)
[root@hadoop01 hadoop-2.7.3]# bin/hdfs namenode -format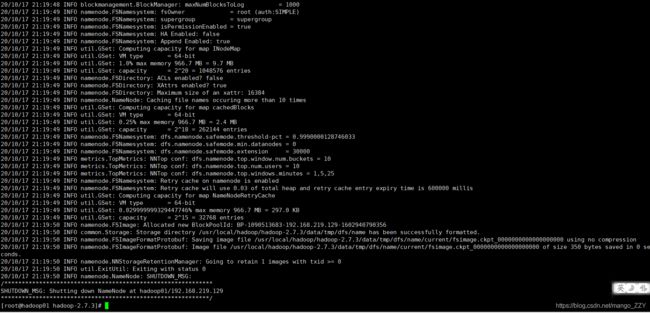
(2)启动NameNode,并使用jps命令查看是否成功
[root@hadoop01 hadoop-2.7.3]# sbin/hadoop-daemon.sh start namenode
(3)启动DataNote,并使用jps命令查看是否成功
[root@hadoop01 hadoop-2.7.3]# sbin/hadoop-daemon.sh start datanode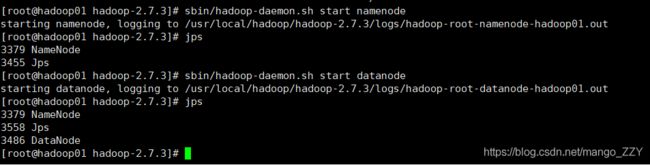
(4)web端查看HDFS系统,输入hadoop01:50070(或者192.168.219.129:50070)
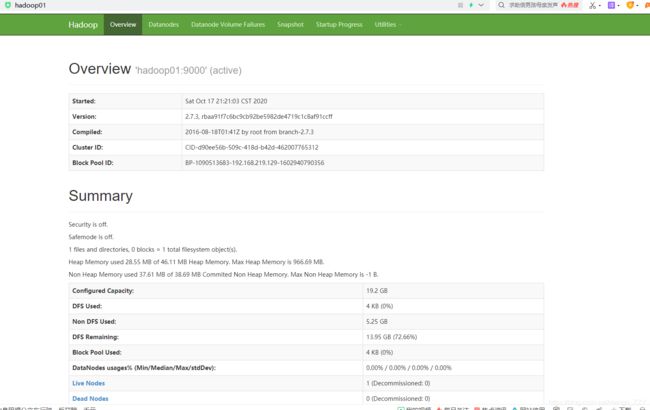
注意:每个集群都有唯一的Cluster ID。
5.操作集群
(1)在HDFS文件系统上创建一个input文件夹
[root@hadoop01 hadoop-2.7.3]# bin/hdfs dfs -mkdir -p /user/atguigu/input(2)将测试文件内容上传到文件系统上
[root@hadoop01 hadoop-2.7.3]# bin/hdfs dfs -put wcinput/wc.input /user/atguigu/input/ 
(3)查看上传的文件是否正确
[root@hadoop01 hadoop-2.7.3]# bin/hdfs dfs -ls /user/atguigu/input/
[root@hadoop01 hadoop-2.7.3]# bin/hdfs dfs -cat /user/atguigu/ input/wc.input 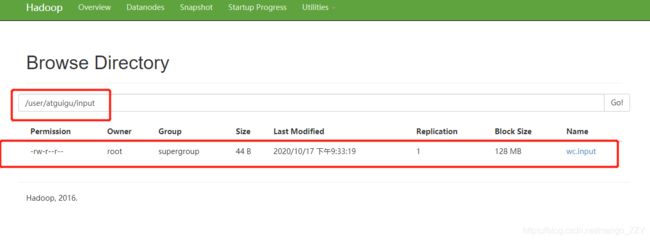
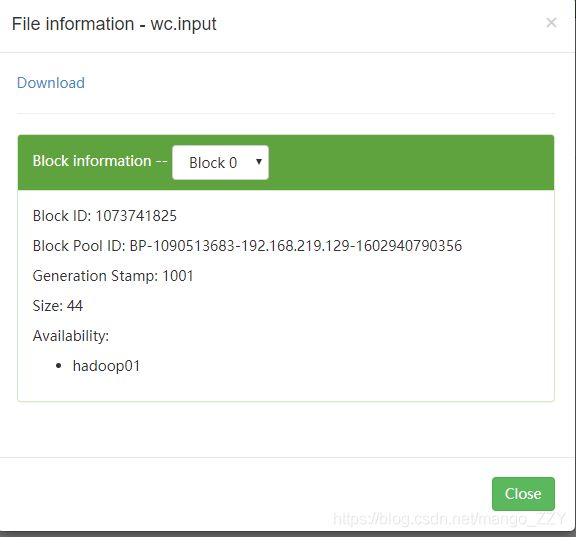
(4)运行MapReduce程序
[root@hadoop01 hadoop-2.7.3]# bin/hadoop jar
share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/atguigu/input/ /user/atguigu/output 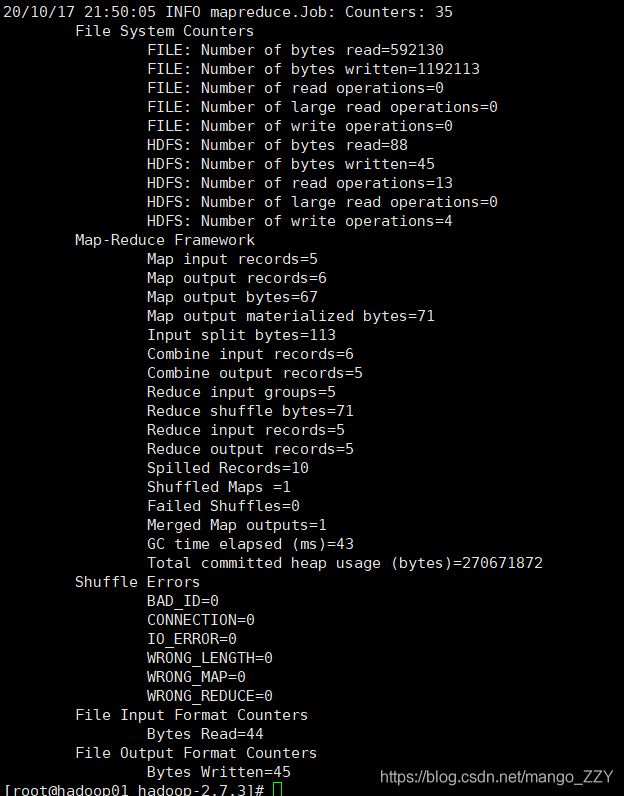
(5)查看输出结果
[root@hadoop01 hadoop-2.7.3]# bin/hdfs dfs -cat /user/atguigu/output/* 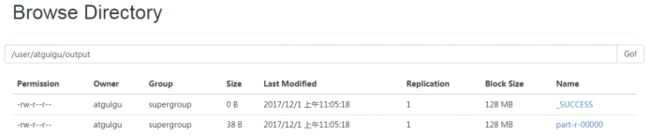
(6)将测试文件内容下载到本地(直接网页操作也可以)
[root@hadoop01 hadoop-2.7.3]# hdfs dfs -get /user/atguigu/output/part-r-00000 ./wcoutput/(7)删除输出结果
[root@hadoop01 hadoop-2.7.3]# hdfs dfs -rm -r /user/atguigu/output