【数据结构与算法_java】面试题及答案汇总
文章目录
- 一、剑指offer:50道金典面试题
-
- 面试题1:赋值运算符函数
- 面试题2:实现单例模式
- 面试题3:二维数组中的查找
- 面试题4:替换空格
- 面试题5:反向打印链表
- 面试题6:重建二叉树
- 面试题7:用两个栈实现队列(附带用两个队列实现栈)
- 面试题8:旋转数组的最小数字
- 面试题9:斐波那契数列
- 面试题10:二进制中 1 的个数
- 面试题11:数值的整数次方
- 面试题12:打印 1 到最大的 n 位数
- 面试题13:在O(1)时间删除链表结点
- 面试题14:调整数组顺序使数组中奇数位于偶数前
- 面试题15:链表中倒数第K个结点
- 面试题16:反转链表
- 面试题17:合并两个排序的链表
- 面试题18:树的子结构
- 面试题19:二叉树的镜像
- 面试题20:顺时针打印矩阵
- 面试题21:包含 min 函数的栈
- 面试题22:栈的压人、弹出序列
- 面试题23:从上往下打印二叉树
- 面试题24:二叉搜索树的后序遍历序列
- 面试题25:二叉树中和为某一值的路径
- 面试题26:复杂链表的复制
- 面试题27:二叉搜索树和双向链表
- 面试题28:字符串的排序
- 面试题29:数组中出现次数超过一半的数字
- 面试题30:最小的 k 个数
- 面试题31:连续子数组的最大和(动态规划思想)
- 面试题32:从1到n整数中1出现的次数
- 面试题33:把数组排成最小的数
- 面试题34:丑数
- 面试题35:第一个只出现一次的字符
- 面试题36:数组中的逆序对
- 面试题37:两个链表的第一个公共节点
- 面试题38:数字在排序数组中出现的次数
- 面试题39:二叉树的深度
- 面试题40:数组中只出现一次的数字
- 面试题41:和为s的两个数字与和为s的连续正数序列
- 面试题42:翻转单词顺序与左旋转字符串
- 面试题43:n个骰子的点数(动态规划)
- 面试题44:扑克牌的顺子
- 面试题45:圆圈中最后剩下的数字(约瑟夫环问题)
- 面试题46:求1+2+...+n
- 面试题47:不用加减乘除做加法(位运算)
- 面试题48:设计一个不能被继承的类(final修饰 )
- 面试题49:字符串转整数
- 面试题50:二叉树两个结点的最低公共祖先
- 二、LeetCode上经典题目
- 三、其他面试题(理论知识)
-
- 1.说说常见的集合有哪些。
- 2. HashMap 与 HashTable 的区别。
- 3. HashMap 是怎么解决哈希冲突的
- 4. HashMap 中为什么数组长度要保证 2 的幂次方。
- 5.什么是 Java 集合的快速失败机制“fail-fast”, 以及安全失败“fail-safe”。
- 6. ArrayList 和 LinkedList 的区别。
- 7. HashSet 是如何保证数据不可重复的。
- 8. BlockingQueue 是什么。
- 9. JDK8 中 HashMap 为什么选用红黑树而不是 AVL 树
- 10. JDK8 中 HashMap 链表转红黑树的阈值为什么选 8?
- 11. 说下几种常见的排序算法及其复杂度
- 12. Hashmap 什么时候进行扩容呢?
- 13. HashSet 和 TreeSet 有什么区别?
- 14. LinkedHashMap 的实现原理?
- 15. 什么是迭代器 (Iterator)?
- 16. Iterator 和 ListIterator 的区别是什么?
- 17. Collection 和 Collections 的区别。
|
|
本文将收录《剑指offer:50道金典面试题》、LeetCode上部分经典题目以及其他【据结构和算法】数面试题。
PS:目录中有粉红色标注的题目是已经附带答案的
|
|
一、剑指offer:50道金典面试题
面试题1:赋值运算符函数
![]()
class CMyString
{
public:
CMyString(char* pData = NULL);
CMyString(const CMyString& str);
~CMyString(void);
private:
char* m_pData;
}
\qquad
|
|
面试题2:实现单例模式

\qquad
|
|
public class Singleton {
private static Singleton instance = new Singleton();
// 私有化构造方法
private Singleton() {
}
public static Singleton getInstance() {
return instance;
}
}
饿汉式是典型的空间换时间,当类装载的时候就会创建类实例,不管你用不用,先创建出来,然后每次调用的时候,就不需要判断了,节省了运行时间。
\qquad
|
|
public class Singleton {
//2.本类内部创建对象实例
private static Singleton instance = null;
/**
* 1.构造方法私有化,外部不能new
*/
private Singleton() {
}
//3.提供一个公有的静态方法,返回实例对象
public static Singleton getInstance() {
if (instance == null) {
instance = new Singleton();
}
return instance;
}
}
调用顺序时序图:

单例模式的懒汉式体现了缓存的思想,延时加载就是一开始不要加载资源或者数据,一直 等,等到马上就要使用这个资源的或者数据了,躲不过去了才去加载。
懒汉式是定性的时间换空间,不加同步的懒汉式是线程不安全的,如下示例:
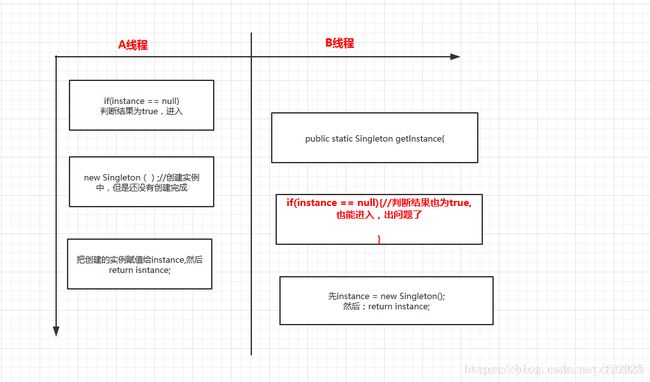
那么如何解决这个问题呢?
就是接下来我们要讲的解法三——使用双重检查加锁机制实现单例模式
\qquad
|
|
public class Singleton {
private volatile static Singleton instance = null;
// 私有化构造方法
private Singleton() {
}
public static Singleton getInstance() {
if (instance == null) {
synchronized (Singleton.class) {
if (instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
}
\qquad
|
|
public class Singleton {
private static class SingletonHoler {
/**
* 静态初始化器,由JVM来保证线程安全
*/
private static Singleton instance = new Singleton();
}
private Singleton() {
}
public static Singleton getInstance() {
return SingletonHoler.instance;
}
}
\qquad
|
|
public enum Singleton {
uniqueInstance;// 定义一个枚举的元素,它 就代表了Singleton的一个实例
public void singletonOperation() {
// 功能处理
System.err.println("功能处理");
}
}
\qquad
|
|
java 单例模式的几种实现方式(包含防止单例模式被破坏的解决方案)
面试题3:二维数组中的查找

|
|
别从左到右一个一个比,先比右上角的或左下角的,如果要找的数比这个数小,剔除这一列,比较前一列的第一个数。如果大,剔除这一行,再比较该列下一个数。
注意:如果先比左上角或右下角的是不行的。
|
|
import java.util.Scanner;
public class Find{
public static void main(String[] args){
int[][] array = input();
if(array != null){
System.out.println("请输入要找的数:");
Scanner sc = new Scanner(System.in);
int target = sc.nextInt();
if(find(array,target) == true){
System.out.println("找到了!");
}else{
System.out.println("没找到!");
}
}
}
static int[][] input(){
Scanner sc = new Scanner(System.in);
System.out.println("请输入二维数组行数:");
int rowNumber = sc.nextInt();
System.out.println("请输入二维数组列数:");
int colNumber = sc.nextInt();
int[][] array = new int[rowNumber][colNumber];
if(rowNumber != 0 && colNumber != 0){
for(int i=0;i<rowNumber;i++){
System.out.println("请输入第"+(i+1)+"行的"+(colNumber)+"个数。");
for(int j=0;j<colNumber;j++){
array[i][j] = sc.nextInt();
}
}
return array;
}else {
System.out.println("输入有误!数组为空!");
return null;
}
}
static boolean find(int[][] array,int target){
int row = 0;
int col = array[0].length-1;
while(row<array.length && col>=0){
if(array[row][col] == target){
return true;
}
else if(array[row][col] > target){
col--;
}else{
row++;
}
}
return false;
}
}
面试题4:替换空格

面试题5:反向打印链表

面试题6:重建二叉树

面试题7:用两个栈实现队列(附带用两个队列实现栈)

\qquad
|
|
\qquad
|
|
public class CQueue {
private Stack<Integer> stack1 = new Stack<>();
private Stack<Integer> stack2 = new Stack<>();
public void appendTail(int elem){
//添加元素就直接向stack1添加
stack1.push(elem);
System.out.println("stack1:" + stack1.toString());
}
public void deleteHead(){
//删除分三种情况:1,stack2不空,直接从它里头弹出。2,stack2空,stack1不空,把1中先弹再压到2,再从2弹出。3,两都空。
if(!stack2.isEmpty()){
stack2.pop();
}else if(!stack1.isEmpty()){
while(!stack1.isEmpty()){
stack2.push(stack1.pop());
}
stack2.pop();
}else{
System.out.println("两个栈都空了");
}
System.out.println("stack1:" + stack1.toString());
System.out.println("stack2:" + stack2.toString());
}
public static void main(String[] args) {
CQueue test = new CQueue();
test.appendTail(1);
test.appendTail(2);
test.appendTail(3);
test.deleteHead();
test.deleteHead();
test.appendTail(4);
test.deleteHead();
}
}
\qquad
|
|
\qquad
|
|
\qquad
|
|
import java.util.Queue;
import java.util.LinkedList;
//以下是相关题,两个队列实现栈。
public class CStack {
//是LinkedList类实现了Queue接口
private static Queue<Integer> queue1 = new LinkedList<>();
private static Queue<Integer> queue2 = new LinkedList<>();
private void appendTail(int elem){
//Queue使用时要尽量避免Collection的add()和remove()方法,而是要使用offer()来加入元素,使用poll()来获取并移出元素。
//它们的优点是通过返回值可以判断成功与否,add()和remove()方法在失败的时候会抛出异常。
//如果要使用前端而不移出该元素,使用element()或者peek()方法。
//这里是向非空的队列里添加值。都为空的话向队列1添加。
if(!queue2.isEmpty()){
queue2.offer(elem);
}else{
queue1.offer(elem);
}
System.out.println("queue1:" + queue1.toString());
System.out.println("queue2:" + queue2.toString());
}
private void deleteHead(){
//一个表示空队列,一个表示非空队列
Queue<Integer> emptyQueue = queue1;
Queue<Integer> notEmptyQueue = queue2;
if(!emptyQueue.isEmpty()){
emptyQueue = queue2;
notEmptyQueue = queue1;
}
//除了非空队列的最后一个元素,别的都按顺序移到空队列
while(notEmptyQueue.size()!=1){
emptyQueue.offer(notEmptyQueue.poll());
}
//删除刚才留下的最后一个元素
notEmptyQueue.poll();
System.out.println("queue1:" + queue1.toString());
System.out.println("queue2:" + queue2.toString());
}
public static void main(String[] args) {
CStack test = new CStack();
test.appendTail(1);
test.appendTail(2);
test.appendTail(3);
test.deleteHead();
test.appendTail(4);
test.deleteHead();
}
}
面试题8:旋转数组的最小数字

\qquad
面试题9:斐波那契数列

\qquad
| 被面试官鄙视的解法 |
public class Fibonacci {
/**
* 递归实现
*/
public static long fib_rec(int n){
int[] arr = {
0,1};
if(n <= 2){
return arr[n-1];
}
return fib_rec(n-1)+fib_rec(n-2);
}
}
\qquad
| 面试官期待的解法 |
public class Fibonacci {
/**
* 数组+for循环实现(其实就是 动态规划 思想)
*/
public static long fib_for(int n){
int[] arr = {
0,1};
if(n < 2){
return arr[n];
}
long first,sencond,res;
first=0;
sencond=1;
res=0;
for (int i=2;i<n;i++){
res = first + sencond;
first = sencond;
sencond = res;
}
return res;
}
}
\qquad

这个题目可以使用动态规划来求解,可以参考我的 动态规划? so easy!!!
这篇文章里的 【题目实战】中的 【爬楼梯】的例子。
面试题10:二进制中 1 的个数

面试题11:数值的整数次方

面试题12:打印 1 到最大的 n 位数

面试题13:在O(1)时间删除链表结点

面试题14:调整数组顺序使数组中奇数位于偶数前

面试题15:链表中倒数第K个结点

面试题16:反转链表
面试题17:合并两个排序的链表


面试题18:树的子结构

面试题19:二叉树的镜像

面试题20:顺时针打印矩阵


面试题21:包含 min 函数的栈

面试题22:栈的压人、弹出序列

面试题23:从上往下打印二叉树

面试题24:二叉搜索树的后序遍历序列

面试题25:二叉树中和为某一值的路径

面试题26:复杂链表的复制

面试题27:二叉搜索树和双向链表

面试题28:字符串的排序

面试题29:数组中出现次数超过一半的数字

面试题30:最小的 k 个数

面试题31:连续子数组的最大和(动态规划思想)

这个题目可以使用动态规划来求解,可以参考我的 动态规划? so easy!!!
这篇文章里的 【题目实战】中的 【最大子序和】的例子。
面试题32:从1到n整数中1出现的次数

面试题33:把数组排成最小的数

面试题34:丑数

面试题35:第一个只出现一次的字符

面试题36:数组中的逆序对

面试题37:两个链表的第一个公共节点

面试题38:数字在排序数组中出现的次数

面试题39:二叉树的深度

面试题40:数组中只出现一次的数字

面试题41:和为s的两个数字与和为s的连续正数序列


面试题42:翻转单词顺序与左旋转字符串


面试题43:n个骰子的点数(动态规划)

面试题44:扑克牌的顺子

面试题45:圆圈中最后剩下的数字(约瑟夫环问题)

面试题46:求1+2+…+n

面试题47:不用加减乘除做加法(位运算)

面试题48:设计一个不能被继承的类(final修饰 )
面试题49:字符串转整数
面试题50:二叉树两个结点的最低公共祖先
二、LeetCode上经典题目
三、其他面试题(理论知识)
1.说说常见的集合有哪些。
Map 接口和Collection 接口是所有集合类框架的父接口:
Collcetion 接口的子接口包括:Set 接口和List 接口。
Map 接口的实现类主要有:HashMap、HashTable、ConcurrentHashMap 以及Properties
等。
Set 接口的实现类主要有:HashSet、TreeSet、LinkedHashSet 等。
List 接口的实现类主要有:ArrayList、LinkedList、Stack 以及 Vector 等。
2. HashMap 与 HashTable 的区别。
主要有以下几点区别。
HashMap 没有考虑同步,是线程不安全的;HashTable 在关键方法(put、get、contains、
size 等)上使用了Synchronized 关键字,是线程安全的。
HashMap 允许Key/Value 都为null,后者Key/Value 都不允许为null。
HashMap 继承自AbstractMap 类;而HashTable 继承自Dictionary 类。
在jdk1.8 中,HashMap 的底层结构是数组+链表+红黑树,而HashTable 的底层结构是
数组+链表。
HashMap 对底层数组采取的懒加载,即当执行第一次put 操作时才会创建数组;而
HashTable 在初始化时就创建了数组。
HashMap 中数组的默认初始容量是 16 ,并且必须是 2 的指数倍数,扩容时
newCapacity=2oldCapacity;而HashTable 中默认的初始容量是11,并且不要求必须是2 的
指数倍数,扩容时newCapacity=2oldCapacity+1。 在hash 取模计算时,HashTable 的模数一般为素数,简单的做除取模结果会更为均匀,
int index = (hash & 0x7FFFFFFF) % tab.length;
HashMap 的模数为2 的幂,直接用位运算来得到结果,效率要大大高于做除法,i = (n - 1) & hash。
3. HashMap 是怎么解决哈希冲突的
哈希冲突:当两个不同的输入值,根据同一散列函数计算出相同的散列值的现象,我们
就把它叫做哈希碰撞。
在Java 中,保存数据有两种比较简单的数据结构:数组和链表。数组的特点是:寻址
容易,插入和删除困难。链表的特点是:寻址困难,但插入和删除容易。所以我们将数组和
链表结合在一起,发挥两者的优势,使用一种叫做链地址法的方式来解决哈希冲突。这样我
们就可以拥有相同哈希值的对象组织成的一个链表放在hash 值对应的bucket 下,但相比
Key.hashCode() 返回的 int 类型,我们 HashMap 初始的容量大小
DEFAULT_INITIAL_CAPACITY = 1 << 4(即2 的四次方为16)要远小于int 类型的范围,所
以我们如果只是单纯的使用hashcode 取余来获取对应位置的bucket,这将会大大增加哈希
碰撞的几率,并且最坏情况下还会将HashMap 变成一个单链表。所以肯定要对hashCode 做
一定优化。
来看HashMap 的hash()函数。上面提到的问题,主要是因为如果使用hashCode 取余,
那么相当于参与运算的只有hashCode 的低位,高位是没有起到任何作用的,所以我们的思
路就是让**hashCode 取值出的高位也参与运算,进一步降低hash 碰撞的概率,使得数据分
布更平均,我们把这样的操作称为扰动,在JDK 1.8 中的hash()函数相比在JDK 1.7 中的4 次
位运算,5 次异或运算(9 次扰动),在1.8 中,只进行了1 次位运算和1 次异或运算(2 次
扰动),更为简洁了。两次扰动已经达到了高低位同时参与运算的目的,提高了对应数组存
储下标位置的随机性和均匀性。
通过上面的链地址法(使用散列表)和扰动函数,数据分布更为均匀,哈希碰撞也减少
了。但是当HashMap 中存在大量的数据时,假如某个bucket 下对应的链表中有n 个元素,
那么遍历时间复杂度就变成了O(n),针对这个问题,JDK 1.8 在HashMap 中新增了红黑树的
数据结构,进一步使得遍历复杂度降低至O(logn)。
简单总结一下HashMap 是如何有效解决哈希碰撞的:
使用链地址法(散列表)来链接拥有相同hash 值的元素;
使用2 次扰动(hash 函数)来降低哈希冲突的概率,使得概率分布更为均匀;
引入红黑树进一步降低遍历的时间复杂度。
4. HashMap 中为什么数组长度要保证 2 的幂次方。
只有当数组长度为 2 的幂次方时,h&(length-1)才等价于 h%length,可以用位运算来
代替做除取模运算,实现了 key 的定位,2 的幂次方也可以减少冲突次数,提高 HashMap 的
查询效率;
当然,HashTable 就没有采用 2 的幂作为数组长度,而是采用素数。素数的话是用简
单做除取模方法来获取下标 index,而不是位运算,效率低了不少,但分布也很均匀。
5.什么是 Java 集合的快速失败机制“fail-fast”, 以及安全失败“fail-safe”。
“fail-fast”是Java 集合的一种错误检测机制,当多个线程对集合进行结构上的改变
的操作时,有可能会产生fail-fast 机制。
例如:假设存在两个线程(线程1、线程2),线程1 通过Iterator 在遍历集合A 中的
元素,在某个时候线程2 修改了集合A 的结构(是结构上面的修改,而不是简单的修改集合
元素的内容),那么这个时候程序就会抛出ConcurrentModificationException 异常,从而
产生fail-fast 机制。
原因:迭代器在遍历时直接访问集合中的内容,并且在遍历过程中使用一个modCount 变
量。集合在被遍历期间如果内容发生变化,就会改变odCount的值。每当迭代器使用
hashNext()/next()遍历下一个元素之前,都会检测modCount 变量是否为expectedmodCount
值,是的话就返回遍历;否则抛出异常ConcurrentModification,终止遍历。
Java.util 包下的集合类都是快速失败机制,不能在多线程下发生并修改(迭代
过程中被修改)。
与“fail-fast”对应的是“fail-safe”。
采用安全失败机制的集合容器,在遍历时不是直接在集合内容上访问的,而是先copy 原
有集合内容,在拷贝的集合上进行遍历。由于迭代时是对原集合的拷贝的值进行遍历,所以在
遍历过程中对原集合所作的修改并不能被迭代器检测到 , 所以不会触发
ConcurrentModificationException 异常。
基于拷贝内容的迭代虽然避免了ConcurrentModificationException 异常,但同样地,
迭代器并不能访问到修改后的内容,简单来说,迭代器遍历的是开始遍历那一刻拿到的集合
拷贝,在遍历期间原集合发生的修改迭代器行为是不知道的。
Java.util.concurrent 包下的容器都是安全失败的,可以在多线程下并发使用,并发修
改。
6. ArrayList 和 LinkedList 的区别。
主要有以下几点区别:
LinkedList 实现了List 和Deque 接口,一般称为双向链表;ArrayList 实现了List 接
口,是动态数组。
LinkedList 在插入和删除数据时效率更高,ArrayList 在查找某个index的数据时效率
更高。
LinkedList 比ArrayList 需要更多内存。
7. HashSet 是如何保证数据不可重复的。
HashSet 的底层其实就是HashMap,只不过HashSet 是实现了Set 接口,并且把数据作
为Key 值,而Value 值一直使用一个相同的虚值来保存。由于ashMap 的K 值本身就不允许
重复,并且在HashMap 中如果K/V 相同时,会用新的V 覆盖掉旧的V,然后返回旧的V,那么
在HashSet 中执行这一句话始终会返回一个false,导致插入失败,这样就保证了数据的不
可重复性。
8. BlockingQueue 是什么。
Java.util.concurrent.BlockingQueue 是一个队列,在进行检索或移除一个元素的时
候,它会等待队列变为非空;当添加一个元素时,它会等待队列中的可用空间。BlockingQueue
接口是Java 集合框架的一部分,主要用于实现生产者-消费者模式。这样我们就不需要担心
等待生产者有可用的空间,以及消费者有可用的对象。因为它们都在BlockingQueue 的实现
类中被处理了。
Java 提供了几种 BlockingQueue 的实现,比如 ArrayBlockingQueue 、
LinkedBlockingQueue、PriorityBlockingQueue,、SynchronousQueue 等。
9. JDK8 中 HashMap 为什么选用红黑树而不是 AVL 树
在平常我们用HashMap的时候,HashMap里面存储的key是具有良好的hash算法的key(比
如String、Integer等包装类),冲突几率自然微乎其微,此时链表几乎不会转化为红黑树,
但是当key为我们自定义的对象时,我们可能采用了不好的hash算法,使HashMap中key的冲
突率极高,但是这时HashMap为了保证高速的查找效率,引入了红黑树来优化查询了。
因为从时间复杂度来说,链表的查询复杂度为o(n);而红黑树的复杂度能达到o(logn);
比如若hash算法写的不好,一个桶中冲突1024个key,使用链表平均需要查询512次,但是红
黑树仅仅10次,红黑树的引入保证了在大量hash冲突的情况下,HashMap还具有良好的查询
性能。
红黑树相比avl树,在检索的时候效率其实差不多,都是通过平衡来二分查找。但对于
插入删除等操作效率提高很多。红黑树不像avl树一样追求绝对的平衡,他允许局部很少的
不完全平衡,这样对于效率影响不大,但省去了很多没有必要的调平衡操作,avl树调平衡
有时候代价较大,所以效率不如红黑树。
10. JDK8 中 HashMap 链表转红黑树的阈值为什么选 8?
HashMap 在jdk1.8 之后引入了红黑树的概念,表示若桶中链表元素超过8 时,会自动
转化成红黑树;若桶中元素小于等于6 时,树结构还原成链表形式。
HashMap源码作者通过泊松分布算出,当桶中结点个数为8时,出现的几率是亿分之6的,
因此常见的情况是桶中个数小于8的情况,此时链表的查询性能和红黑树相差不多,因为红黑
树的平均查找长度是log(n),长度为8 的时候,平均查找长度为3,如果继续使用链表,平
均查找长度为8/2=4,这才有转换为树的必要。链表长度如果是小于等于6,6/2=3,虽然速
度也很快的,但是转化为树结构和生成树的时间并不会太短。
亿分之6这个几乎不可能的概率是建立在良好的hash算法情况下,例如String,Integer
等包装类的hash算法,如果一旦发生桶中元素大于8,说明是不正常情况,可能采用了冲突
较大的hash算法,此时桶中个数出现超过8的概率是非常大的,可能有n个key冲突在同一个
桶中,这个时候就必要引入红黑树了。
另外,上下阈值选择6 和8 的情况下,中间有个差值7 可以防止链表和树之间频繁的转
换。假设一下,如果设计成链表个数超过8 则链表转换成树结构,链表个数小于8 则树结构
转换成链表,如果一个HashMap 不停的插入、删除元素,链表个数在8 左右徘徊,就会频繁
的发生树转链表、链表转树,效率会很低。
11. 说下几种常见的排序算法及其复杂度
a. 快速排序:
i. 原理:快速排序采⽤用的是⼀种分治的思想,它先找⼀个基准数(⼀般选择第⼀个值),
然后将⽐这个基准数⼩的数字都放到它的左边,然后再递归调⽤,分别对左右两边快速排序,
直到每⼀边只有⼀个数字.整个排序就完成了.
1.选定⼀个合适的值(理想情况中值最好,但实现中⼀般使⽤用数组第⼀个值),称为
“枢轴”(pivot)。
2.基于这个值,将数组分为两部分,较⼩的分在左边,较⼤的分在右边。
3.可以肯定,如此⼀轮下来,这个枢轴的位置⼀定在最终位置上。
4.对两个⼦数组分别重复上述过程,直到每个数组只有⼀个元素。
5.排序完成。
ii. 复杂度:O(n)
b. 冒泡排序:
i. 原理:冒泡排序其实就是逐⼀⽐较交换,进⾏⾥外两次循环,外层循环为遍历所有数
字,逐个确定每个位置,⾥层循环为确定了了位置后,遍历所有后面没有确定位置的数字,与
该位置的数字进⾏⽐较,只要⽐该位置的数字⼩,就和该位置的
数字进⾏交换.
ii. 复杂度:O(n^2),最佳时间复杂度为O(n)
c. 直接插⼊入排序:
i. 原理:直接插⼊入排序是将从第⼆个数字开始,逐个拿出来,插⼊到之前排好序的数
列列⾥.
ii. 复杂度:O(n^2),最佳时间复杂度为O(n)
d. 直接选择排序:
i. 原理:直接选择排序是从第⼀个位置开始遍历位置,找到剩余未排序的数据⾥里里最 ⼩的,找到最⼩的后,再做交换。
ii. 复杂度:O(n^2)
12. Hashmap 什么时候进行扩容呢?
当 hashmap 中的元素个数超过数组大小 loadFactor 时,就会进行数组扩容,
loadFactor 的默认值为 0.75,也就是说,默认情况下,数组大小为 16,那么当 hashmap 中
元素个数超过 160.75=12 的时候,就把数组的大小扩展为 216=32,即扩大一倍,然后重新
计算每个元素在数组中的位置,而这是一个非常消耗性能的操作,所以如果我们已经预知
hashmap 中元素的个数,那么预设元素的个数能够有效的提高 hashmap 的性能。
比如说,我们有 1000 个元素 new HashMap(1000), 但是理论上来讲 new HashMap(1024)
更合适,不过上面已经说过,即使是 1000,hashmap 也自动会将其设置为 1024。 但是 new
HashMap(1024) 还不是更合适的,因为 0.75*1000 < 1000, 也就是说为了让 0.75 * size >
1000, 我们必须这样 new HashMap(2048) 才最合适,既考虑了 & 的问题,也避免了 resize
的问题。
13. HashSet 和 TreeSet 有什么区别?
HashSet 是由一个 hash 表来实现的,因此,它的元素是无序的。
TreeSet 是由一个树形的结构来实现的,它里面的元素是有序的。
14. LinkedHashMap 的实现原理?
LinkedHashMap 也是基于 HashMap 实现的,不同的是它定义了一个 Entry header,这
个 header 不是放在 Table 里,它是额外独立出来的。
LinkedHashMap 通过继承 hashMap 中 的 Entry, 并添加两个属性 Entry
before,after, 和 header 结合起来组成一个双向链表,来实现按插入顺序或访问顺序排
序。LinkedHashMap 定义了排序模式 accessOrder,该属性为 boolean 型变量,对于访问
顺序,为 true;对于插入顺序,则为 false。一般情况下,不必指定排序模式,其迭代顺
序即为默认为插入顺序。
15. 什么是迭代器 (Iterator)?
Iterator 接口提供了很多对集合元素进行迭代的方法。每一个集合类都包含了可以返
回迭代 器实例的迭代方法。迭代器可以在迭代的过程中删除底层集合的元素, 但是不可以
直接调用集合的 remove(Object Obj) 删除,可以通过迭代器的 remove() 方法删除。
16. Iterator 和 ListIterator 的区别是什么?
下面列出了他们的区别:
Iterator 可用来遍历 Set 和 List 集合,但是 ListIterator 只能用来遍历 List。
Iterator 对集合只能是前向遍历,ListIterator 既可以前向也可以后向。
ListIterator 实现了 Iterator 接口,并包含其他的功能,比如:增加元素,替换元
素,获取前一个和后一个元素的索引,等等。
17. Collection 和 Collections 的区别。
collection 是集合类的上级接口, 继承与它的接口主要是 set 和 list。
collections 类是针对集合类的一个帮助类. 它提供一系列的静态方法对各种集合的
搜索, 排序, 线程安全化等操作。
\qquad
|
|
本文主要汇总了《剑指offer》50道金典面试题,及部分LeetCode上经典题目。
PS 答案还在整理中,敬请期待~~