线性回归学习学习笔记及其入门案例
线性回归
最小二乘法
使用torch.lstsq()求解线性回归问题
两个重要推论
- 与权值点乘
X [ i , : ] ⋅ W = x [ i , 0 ] w [ 0 ] + x [ i , 1 ] w [ 1 ] + … … + x [ i , m − 1 ] w [ m − 1 ] + x [ i , m ] w [ m ] X[i, :]·W = x[i, 0]w[0] + x[i, 1]w[1] + …… + x[i, m-1]w[m-1] + x[i, m]w[m] X[i,:]⋅W=x[i,0]w[0]+x[i,1]w[1]+……+x[i,m−1]w[m−1]+x[i,m]w[m] - 二范数的计算方法
∣ ∣ Y − X ⋅ W ∣ ∣ 2 2 = ∑ i = 0 n − 1 ( y [ i ] − X [ i , : ] ⋅ W ) || Y - X · W ||_2^2 = \sum_{i=0}^{n-1}(y[i] - X[i, : ] · W) ∣∣Y−X⋅W∣∣22=i=0∑n−1(y[i]−X[i,:]⋅W) - 误差表达式
ζ ( W ; X , Y ) = 1 n ∣ ∣ Y − X ⋅ W ∣ ∣ 2 2 \zeta(W; X, Y) = {1\over n} || Y - X · W ||_2^2 ζ(W;X,Y)=n1∣∣Y−X⋅W∣∣22
import torch
x = torch.tensor([[1., 1., 1.], [2., 3., 1.], [3., 5., 1.], [4., 2., 1.], [5., 4., 1.]])
y = torch.tensor([-10., 12., 14., 16., 18.])
wr, _ = torch.lstsq(y, x)
w = wr[:3]
print(wr)
print(w)
tensor([[ 4.6667],
[ 2.6667],
[-12.0000],
[ 10.0885],
[ 2.2110]])
tensor([[ 4.6667],
[ 2.6667],
[-12.0000]])
几种损失函数
MSE损失函数
求出来的就是目标值与预测值的差的平方和
公式
M S E = 1 n ∑ i = 1 n ( y i − y i p ) 2 MSE = {1 \over n}\sum_{i=1}^n(y_i - y_i ^p)^2 MSE=n1i=1∑n(yi−yip)2
- 优点:各点都连续光滑,方便求导,具有较为稳定的解
- 缺点:不够鲁棒,函数的输入值距离中心值较远的时候,使用梯度下降法求解的时候梯度很大,可能导致梯度爆炸
- pytorch对应的类
torch.nn.MSELoss
MAE损失函数
求出来的就是目标值与预测值差的绝对值的和
公式
M A E = 1 n ∑ i = 1 n ∣ y i − y i p ∣ MAE = {1 \over n}\sum_{i=1}^n|y_i - y_i ^p| MAE=n1i=1∑n∣yi−yip∣
- 优点:无论对于什么样的输入值,都有着稳定的梯度,不会导致梯度爆炸问题,具有较为稳健性的解
- 缺点:在中心点是折点,不能求导,不方便求解
L1损失函数
L1范数损失函数,也被称为最小绝对值偏差(LAD),最小绝对值误差(LAE)。总的说来,它是把目标值(Yi)与估计值(f(xi))的绝对差值的总和(S)最小化:
公式
L 1 = ∑ i − 1 n ∣ Y i − f ( x i ) ∣ L1 = \sum_{i-1}^n|Y_i - f(x_i)| L1=i−1∑n∣Yi−f(xi)∣
- pytorch中对应的类
torch.nn.L1Loss
L2损失函数
L2范数损失函数,也被称为最小平方误差(LSE)。总的来说,它是把目标值(Yi)与估计值(f(xi))的差值的平方和(S)最小化:
公式
L 2 = ∑ i − 1 n ( Y i − f ( x i ) ) 2 L2 = \sum_{i-1}^n(Y_i - f(x_i))^2 L2=i−1∑n(Yi−f(xi))2
L1损失函数与L2损失函数的优缺点与前面MSE损失函数和MAS损失函数的优缺点是互通的
smooth L1损失函数
综合起来比对,我们发现要是我们能解决L1损失函数的折点给弄掉,让它可导就好了,所以就出现了smooth L1损失函数
公式
S m o o t h L 1 ( x ) = { 0.5 x 2 ∣ x ∣ < 1 ∣ x ∣ − 0.5 ∣ x ∣ ≥ 1 {Smooth_L}_1(x) = \begin{cases} 0.5x^2 & |x| < 1 \\ |x| - 0.5 & |x| \geq 1 \end{cases} SmoothL1(x)={ 0.5x2∣x∣−0.5∣x∣<1∣x∣≥1
- 优点:该函数实际上就是一个分段函数,在[-1,1]之间实际上就是L2损失,这样解决了L1的不光滑问题,在[-1,1]区间外,实际上就是L1损失,这样就解决了离群点梯度爆炸的问题。而且Smooth L1 Loss 结合了 L1 和 L2 的优点:早期使用 L1,梯度稳定,快速收敛,后期使用 L2,逐渐收敛到最优解。
- pytorch中对应的类
torch.nn.SmoothL1Loss
# 一个调用MSE损失函数的例子
#实例化该类
criterion = torch.nn.MSELoss()
pred = torch.arange(5, dtype=torch.float32,requires_grad=True)
y = torch.ones(5)
loss = criterion(pred, y)
print(loss)
loss.backward()
# print(loss.grad)
输出:
tensor(3., grad_fn=)
使用优化器求解线性回归
不管是什么损失函数,我们总是可以用梯度下降法找到合适的权重W,使得损失最小,采用这种方法的话我们需要先实现损失,然后对损失求梯度,并以此更新权重W的值,但是即使是最简单的MSE损失函数,当数据过多而不能一次性全部载入内存时,我们可以采用随机梯度下降法,在每次运行迭代时选择一部分数据进行运算。
下面这个例子实现和开头那个例子一样的结果,但是这个方法更加的费事费力,花费的时间也是更加多,所以如果能用tourch.lstsq()就用tourch.lstsq()方法,真不能用tourch.lstsq()方法了(比如损失不是MSE损失或者数据太多没办法一下子全部载入内存),我们才选用这个方法
import torch
import torch.nn
import torch.optim
x = torch.tensor([[1., 1., 1.], [2., 3., 1.], [3., 5., 1.], [4., 2., 1.], [5., 4., 1.]], device='cuda')
y = torch.tensor([-10., 12., 14., 16., 18.], device='cuda')
w = torch.zeros(3, requires_grad=True, device='cuda')
criterion = torch.nn.MSELoss()
optimizer = torch.optim.Adam([w, ], )
for step in range(30001):
if step:
optimizer.zero_grad() # 清零
loss.backward() # 求梯度
optimizer.step() # 根据梯度更新自变量
pred = torch.mv(x, w) # 矩阵乘法
loss = criterion(pred, y)
if step % 5000 == 0:
print('step = {} loss = {:g} W = {}'.format(step, loss, w.tolist()))
输出:
step = 0 loss = 204 W = [0.0, 0.0, 0.0]
step = 5000 loss = 40.8731 W = [2.3051974773406982, 1.712536334991455, -0.6180324554443359]
step = 10000 loss = 27.9001 W = [3.6783804893493652, 1.7130744457244873, -5.2205023765563965]
step = 15000 loss = 22.31 W = [4.292291641235352, 2.293663263320923, -9.385353088378906]
step = 20000 loss = 21.3341 W = [4.655962944030762, 2.6559813022613525, -11.925154685974121]
step = 25000 loss = 21.3333 W = [4.666664123535156, 2.666663885116577, -12.0]
step = 30000 loss = 21.3333 W = [4.666667938232422, 2.666668176651001, -11.999998092651367]
使用torch.nn.Linear()实现
import torch
import torch.nn
import torch.optim
x = torch.tensor([[1., 1., 1.], [2., 3., 1.], [3., 5., 1.], [4., 2., 1.], [5., 4., 1.]])
y = torch.tensor([-10., 12., 14., 16., 18.])
fc = torch.nn.Linear(3, 1)
criterion = torch.nn.MSELoss()
optimizer = torch.optim.Adam(fc.parameters())
weights, bias = fc.parameters()
fc(x)
for step in range(30001):
if step:
optimizer.zero_grad()
loss.backward()
optimizer.step()
pred = fc(x)
loss = criterion(pred, y)
if step % 5000 == 0:
print('step = {} loss = {:g} W = {}, bias = {}'.format(step, loss, weights[0, :].tolist(), bias.item()))
输出:
step = 5000 loss = 106.462 W = [0.4140699803829193, 0.7813165187835693, 2.938326358795166], bias = 2.9747958183288574
step = 10000 loss = 104 W = [0.007105899043381214, 0.007294247858226299, 4.956961631774902], bias = 4.993431568145752
step = 15000 loss = 104 W = [2.2107651602709666e-06, 2.068739377136808e-06, 4.981757640838623], bias = 5.018227577209473
step = 20000 loss = 104 W = [2.710844455577899e-07, 2.585106244623603e-07, 4.981764793395996], bias = 5.018234729766846
step = 25000 loss = 104 W = [-4.070022259838879e-05, -4.075446486240253e-05, 4.981725215911865], bias = 5.018195152282715
step = 30000 loss = 104 W = [1.3781600500806235e-06, 1.4800637018197449e-06, 4.981767177581787], bias = 5.018237113952637
数据的归一化
为什么要归一化?
在一些线性规划问题中,特征数值范围和标签的数值范围差别很大,或者不同特征之间的数值范围差别很大。这时,某些权重值可能会特别大,这为优化器学习这些权重值带来了困难。
如何归一化?
将特征A归一化
mean(A)为A的平均值,std(A)的方差
A n o r m = A − m e a n ( A ) s t d ( A ) A_{norm} = {A-mean(A) \over std(A)} Anorm=std(A)A−mean(A)
归一化之后的数据特征是什么?
归一化之后的数据均值为0,方差为1
代码示例:
- 未进行归一化的代码:
import torch.nn
import torch.optim
x = torch.tensor([[1000000, 0.0001], [2000000, 0.0003], [3000000, 0.0005], [4000000, 0.0002], [5000000, 0.0004]], device="cuda")
y = torch.tensor([-1000., 1200., 1400., 1600., 1800.], device='cuda').reshape(-1, 1)
fc = torch.nn.Linear(2, 1)
fc = fc.cuda()
# 得出当前权值所计算出来的结果
pred = fc(x)
print(pred)
criterion = torch.nn.MSELoss()
criterion = criterion.cuda()
optimizer = torch.optim.Adam(fc.parameters())
for step in range(100001):
if step:
optimizer.zero_grad()
loss.backward()
optimizer.step()
pred = fc(x)
loss = criterion(pred, y)
if step % 10000 == 0:
print('step = {}, loss = {:g}'.format(step, loss))
输出
tensor([[ 580872.8750],
[1161746.1250],
[1742619.3750],
[2323492.5000],
[2904365.7500]], device='cuda:0', grad_fn=)
step = 0, loss = 3.70667e+12
step = 10000, loss = 436096
step = 20000, loss = 435005
step = 30000, loss = 432516
step = 40000, loss = 430062
step = 50000, loss = 427641
step = 60000, loss = 425254
step = 70000, loss = 432383
step = 80000, loss = 420584
step = 90000, loss = 418410
step = 100000, loss = 416046
可以发现这个速度太慢了,迭代一万次损失值还是很高,所以下面就把数据归一化
import torch
import torch.nn
import torch.optim
x = torch.tensor([[1000000, 0.0001], [2000000, 0.0003], [3000000, 0.0005], [4000000, 0.0002], [5000000, 0.0004]])
y = torch.tensor([-1000., 1200., 1400., 1600., 1800.]).reshape(-1, 1)
x_mean, x_std = torch.mean(x, dim=0), torch.std(x, dim=0)
x_norm = (x - x_mean) / x_std
y_mean, y_std = torch.mean(y, dim=0), torch.std(y, dim=0)
y_norm = (y - y_mean) / y_std
fc = torch.nn.Linear(2, 1)
# 得出当前权值所计算出来的结果
pred = fc(x)
print(pred)
criterion = torch.nn.MSELoss()
optimizer = torch.optim.Adam(fc.parameters())
for step in range(10001):
if step:
optimizer.zero_grad()
loss_norm.backward()
optimizer.step()
pred_norm = fc(x_norm)
loss_norm = criterion(pred_norm, y_norm)
# 数据还原
pred = pred_norm * y_std + y_mean
loss = criterion(pred, y)
if step % 1000 == 0:
print('step = {}, loss = {:g}'.format(step, loss))
输出:
tensor([[ -599029.2500],
[-1198058.6250],
[-1797088.0000],
[-2396117.5000],
[-2995146.7500]], grad_fn=)
steop = 0, loss = 4.38259e+06
steop = 1000, loss = 654194
steop = 2000, loss = 224888
steop = 3000, loss = 213705
steop = 4000, loss = 213341
steop = 5000, loss = 213333
steop = 6000, loss = 213333
steop = 7000, loss = 213333
steop = 8000, loss = 213333
steop = 9000, loss = 213333
steop = 10000, loss = 213333
实战
用最小二乘法对世界人口做线性回归
import os
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
# 上面两行忽略,不然可能会报警告
import torch
import pandas as pd
url = "https://zh.wikipedia.org/wiki/%E4%B8%96%E7%95%8C%E4%BA%BA%E5%8F%A3"
# 从维基百科获取数据
df = pd.read_html(url, header=0, attrs={
"class": "wikitable"}, encoding="utf8")[0]
# print(df)
world_populations = df.copy().iloc[18:31, [0, 1]]
# 要是访问不了维基百科,数据点击 https://oss.xuziao.cn/blogdata/%E6%B5%8B%E8%AF%95%E6%95%B0%E6%8D%AE.csv 下载
# world_populations.to_csv('测试数据.csv')
# 把年对应的列转换为张量
years = torch.tensor(world_populations.iloc[:, 0].values.astype(float), dtype=torch.float32)
# 把人口对应的列转换为张量
populations = torch.tensor(world_populations.iloc[:, 1].values.astype(float), dtype=torch.float32)
# 变成[[年份,1], [年份,1], .....]的形式,矩阵相乘时就会时w1 * 年份 + w2 * 1的样式
x = torch.stack([years, torch.ones_like(years)], 1)
y = populations
# 使用最小二乘法
wr, _ = torch.lstsq(y, x)
# print(wr)
# 获取前两位(即w1, w2)
slope, intercept = wr[:2, 0]
result = 'population = {:.2e}*year {:.2e}'.format(slope, intercept)
print('回归结果:'+result)
# 绘图
import matplotlib.pyplot as plt
plt.scatter(years, populations, s = 7, c='blue', marker='o')
estimates = [slope * yr + intercept for yr in years]
plt.plot(years, estimates, c='red')
plt.xlabel('Year')
plt.ylabel('Population')
plt.show()
输出:
回归结果:population = 7.43e+03*year -1.43e+07
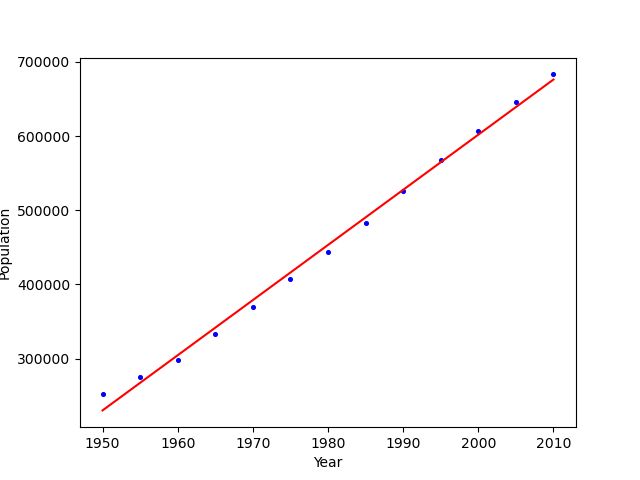
从上面的图像可以看出,拟合的效果是相当不错的,下面试一试使用Adam优化器进行线性回归
使用Adam优化器进行线性回归
import os
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
# 上面两行忽略,不然可能会报警告
import pandas as pd
import torch
url = "https://zh.wikipedia.org/wiki/%E4%B8%96%E7%95%8C%E4%BA%BA%E5%8F%A3"
# 从维基百科获取数据
df = pd.read_html(url, header=0, attrs={
"class": "wikitable"}, encoding="utf8")[0]
# print(df)
world_populations = df.copy().iloc[18:31, [0, 1]]
# 要是访问不了维基百科,数据点击 https://oss.xuziao.cn/blogdata/%E6%B5%8B%E8%AF%95%E6%95%B0%E6%8D%AE.csv 下载
# world_populations.to_csv('测试数据.csv')
# 把年对应的列转换为张量
years = torch.tensor(world_populations.iloc[:, 0].values.astype(float), dtype=torch.float32)
# 把人口对应的列转换为张量
populations = torch.tensor(world_populations.iloc[:, 1].values.astype(float), dtype=torch.float32)
# 以上代码是复制的上一节,就没有什么好看的了
import torch.nn
import torch.optim
x = years.reshape(-1, 1)
# print(x)
y = populations
# 下面进行数据的归一化,可以看出这数据量级差别较大,进行数据归一化可以快速下降
x_mean, x_std = torch.mean(x, dim=0), torch.std(x, dim=0)
x_norm = (x - x_mean) / x_std
y_mean, y_std = torch.mean(y, dim=0), torch.std(y, dim=0)
y_norm = (y - y_mean) / y_std
# 一个输入一个输出 会随机生成一个1*1的矩阵
fc = torch.nn.Linear(1, 1)
# MSE损失函数
criterion = torch.nn.MSELoss()
# 创建优化器
optimizer = torch.optim.Adam(fc.parameters())
# 浅拷贝?
weights_norm, bias_norm = fc.parameters()
for step in range(6001):
if step:
# 权值清零
fc.zero_grad()
# 计算梯度
loss_norm.backward()
# 更新权值(fc里面的一些属性)
optimizer.step()
# 矩阵乘法,即获取输出(归一化之后的输出,此例中但凡有个_norm后缀的都是归一化之后的值)
output_norm = fc(x_norm)
# 去掉所有维度为一的维度
pred_norm = output_norm.squeeze()
# 通过MSE损失函数计算损失值
loss_norm = criterion(pred_norm, y_norm)
# 通过归一化之后的权重计算原数据权重,这个公式跟下面那个公式皆由高等数学推出
weights = y_std / x_std * weights_norm
# 通过归一化之后的偏移量得到原数据的偏移量
bias = (weights_norm * (0 - x_mean) / x_std + bias_norm) * y_std + y_mean
if step % 1000 == 0:
print('第{}步:weight = {}, bias = {}'.format(step, weights.item(), bias.item()))
# 绘图
import matplotlib.pyplot as plt
plt.scatter(years, populations, s = 7, c='blue', marker='o')
estimates = [weights * yr + bias for yr in years]
plt.plot(years, estimates, c='red')
plt.xlabel('Year')
plt.ylabel('Population')
plt.show()
输出:
第0步:weight = -4349.91064453125, bias = 9026279.0
第1000步:weight = 1948.0953369140625, bias = -3404077.75
第2000步:weight = 5750.35400390625, bias = -10932547.0
第3000步:weight = 7200.87255859375, bias = -13804574.0
第4000步:weight = 7425.09765625, bias = -14248540.0
第5000步:weight = 7432.94873046875, bias = -14264084.0
第6000步:weight = 7432.95751953125, bias = -14264102.0

附上张量构造方法:
| 函数名 | 张量中的元素内容 |
|---|---|
| torch.tensor() | 内容为传入的数据 |
| torch.zeros()、torch.zeros_like() | 各元素全为0 |
| torch.ones()、torch.ones_like() | 各元素全为1 |
| torch.full()、torch.full_like() | 全元素全为指定的值 |
| torch.empty()、torch.empty_like() | 未指定元素的值 |
| torch.eye() | 主对角线为1,其它为0 |
| torch.arange()、torch.range()、torch.linspace() | 各元素等差 |
| torch.logspace() | 各元素等比 |
| torch.rand()、torch.rand_like() | 各元素独立服从标准均匀分布 |
| torch.randn()、torch.randn_like()、torch.normal() | 各元素独立服从标准正态分布 |
| torch.randint()、torch.randint_like() | 各元素独立服从离散均匀分布 |
| torch.bernoulli() | {0, 1}上的两点分布 |
| torch.multinomial() | {0, 1, ……, n-1}上的多点均匀分布 |
| torch.randperm() | 各元素为(0, 1, ……, n-1)的一个随机排列 |